




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Hadoop+Spark+Hive酒店推荐系统》的学术论文框架及内容示例,结合大数据技术栈与推荐系统设计:
基于Hadoop+Spark+Hive的分布式酒店推荐系统设计与实现
摘要:针对传统酒店推荐系统面临的数据规模爆炸、实时性不足等问题,本文提出一种基于Hadoop+Spark+Hive的分布式推荐架构。系统利用Hadoop HDFS存储海量酒店元数据与用户行为日志,通过Hive构建数据仓库实现高效查询,采用Spark MLlib实现混合推荐算法(协同过滤+内容过滤)。实验表明,该系统在10亿级数据量下实现亚秒级响应,推荐准确率(Precision@10)达82.3%,较单机系统提升37.6%,验证了分布式架构在酒店推荐场景的有效性。
关键词:酒店推荐系统;Hadoop分布式存储;Spark实时计算;Hive数据仓库;混合推荐算法
1 引言
1.1 研究背景
- 行业挑战:携程/Booking等平台日均产生TB级用户行为数据(搜索、点击、预订);
- 现有局限:
- 单机MySQL无法处理10亿级用户-酒店交互记录;
- 传统协同过滤算法忽略酒店设施、价格等结构化特征;
- 离线推荐模型更新周期长达24小时,无法捕捉实时需求变化。
1.2 研究目标
构建支持高并发、低延迟的分布式酒店推荐系统,实现:
- 结构化与非结构化数据的统一存储;
- 离线批处理与在线实时推荐的协同工作;
- 基于多源数据的混合推荐策略。
2 相关技术综述
2.1 Hadoop生态体系
- HDFS:存储酒店图片(二进制块)与用户行为日志(JSON格式);
- YARN:资源调度框架,支持Spark任务动态资源分配;
- Hive:构建星型模型数据仓库,定义用户、酒店、行为事实表(表1)。
| 表名 | 字段示例 |
|---|---|
| dim_user | user_id, age, gender, member_level, preference_tags |
| dim_hotel | hotel_id, name, location, price, star_rating, facility_bitmap (二进制位图) |
| fact_behavior | user_id, hotel_id, behavior_type (search/click/book), timestamp |
2.2 Spark计算框架
- RDD编程模型:并行处理用户行为日志,生成物品共现矩阵;
- MLlib机器学习库:
- ALS算法实现隐语义模型;
- MinHash+LSH实现基于内容的相似度计算;
- Structured Streaming:处理实时预订数据流,触发模型增量更新。
2.3 Hive优化技术
- 分区表:按日期(
PARTITIONED BY (dt STRING))分割行为数据,加速历史查询; - 列式存储:采用ORC格式压缩酒店元数据,存储空间减少65%;
- 物化视图:预计算热门城市酒店TOP100,查询响应时间从12s降至0.3s。
3 系统架构设计
3.1 总体架构
采用Lambda架构(图1):
- 批处理层(Batch Layer):
- Hadoop存储全量数据;
- Spark每日离线训练推荐模型。
- 加速层(Speed Layer):
- Spark Streaming处理实时行为;
- HBase存储用户近期兴趣向量。
- 服务层(Serving Layer):
- Hive提供元数据查询接口;
- Redis缓存推荐结果,QPS达10万/秒。
<img src="https://via.placeholder.com/600x400?text=Lambda+Architecture+for+Hotel+Recommendation" />
图1 酒店推荐系统Lambda架构
3.2 核心模块设计
3.2.1 数据预处理模块
- 日志清洗:
- 使用Spark过滤异常数据(如停留时间<1秒的点击记录);
- 通过Hive UDF解析JSON日志中的嵌套字段。
- 特征工程:
- 酒店特征:
sql-- Hive SQL生成设施特征向量SELECThotel_id,bitmap_to_array(facility_bitmap) as facilities, -- 将二进制位图转为数组price / 100 as price_level,CASE WHEN star_rating >= 5 THEN 1 ELSE 0 END as is_luxuryFROM dim_hotel; - 用户特征:
- 基于行为序列使用Word2Vec生成兴趣向量(Spark NLP)。
- 酒店特征:
3.2.2 混合推荐引擎
采用加权融合策略(公式1):
[
\text{Score}(u,i) = \alpha \cdot \text{CF}(u,i) + \beta \cdot \text{CB}(u,i) + \gamma \cdot \text{Temporal}(t)
]
其中:
- (CF(u,i)):基于用户的协同过滤得分;
- (CB(u,i)):内容过滤得分(酒店设施与用户偏好的余弦相似度);
- (Temporal(t)):时间衰减因子 (e^{-\lambda \cdot \Delta t});
- (\alpha=0.6, \beta=0.3, \gamma=0.1) 通过网格搜索确定。
python
# Spark实现混合推荐 | |
from pyspark.ml.recommendation import ALS | |
from pyspark.sql.functions import col, expr | |
# 协同过滤模型 | |
als = ALS(maxIter=10, regParam=0.01, userCol="user_id", itemCol="hotel_id", ratingCol="implicit_rating") | |
cf_model = als.fit(training_data) | |
cf_scores = cf_model.recommendForAllUsers(100) # 为每个用户生成Top100 | |
# 内容过滤得分计算 | |
def content_score(user_features, hotel_features): | |
from numpy.linalg import norm | |
return np.dot(user_features, hotel_features) / (norm(user_features) * norm(hotel_features)) | |
# 融合得分 | |
final_scores = cf_scores.join(content_scores, "user_id") \ | |
.withColumn("final_score", | |
0.6 * col("cf_score") + 0.3 * col("cb_score") + 0.1 * expr("exp(-0.1 * (current_timestamp() - last_behavior_time)/3600)")) |
4 系统实现与优化
4.1 关键技术实现
4.1.1 Hive-Spark协同查询
sql
-- Hive创建外部表指向HDFS日志 | |
CREATE EXTERNAL TABLE raw_logs ( | |
log_id STRING, | |
user_id STRING, | |
hotel_id STRING, | |
behavior STRING, | |
timestamp BIGINT | |
) PARTITIONED BY (dt STRING) | |
STORED AS ORC | |
LOCATION '/logs/behavior'; | |
-- Spark读取Hive表进行训练 | |
val hiveContext = new HiveContext(sc) | |
val behaviorData = hiveContext.sql(""" | |
SELECT user_id, hotel_id, | |
CASE behavior WHEN 'book' THEN 3.0 WHEN 'click' THEN 1.0 ELSE 0.0 END as rating | |
FROM raw_logs | |
WHERE dt BETWEEN '20231001' AND '20231007' | |
""").rdd.map(...) |
4.1.2 Spark性能调优
- 内存管理:
- 设置
spark.executor.memoryOverhead=2G防止OOM; - 使用
KryoSerializer序列化对象,减少内存占用30%。
- 设置
- 数据倾斜处理:
- 对热门酒店行为数据加盐后分组:
scalaval saltedData = rawData.map { case (user, hotel) =>val salt = Random.nextInt(10) // 加盐因子((hotel + "_" + salt), user)}
- 对热门酒店行为数据加盐后分组:
- 缓存策略:
- 频繁访问的酒店特征表通过
persist(StorageLevel.MEMORY_AND_DISK)缓存。
- 频繁访问的酒店特征表通过
4.2 实时推荐实现
- 流处理管道:
- Kafka消费用户实时行为 → Spark Streaming处理 → 更新HBase用户画像。
- 近似最近邻搜索:
- 使用Spark MLlib的
MinHashLSH实现酒店内容相似度快速检索:scalaval facilityModel = new MinHashLSH().setNumHashTables(3).setInputCol("facility_features").setOutputCol("hashes")val model = facilityModel.fit(hotelFeatures)val similarHotels = model.approxSimilarityJoin(df1, df2, 0.8)
- 使用Spark MLlib的
5 实验与结果分析
5.1 实验环境
- 集群配置:
- 8台服务器(Intel Xeon Platinum 8280, 256GB RAM, 48TB HDD);
- Hadoop 3.3.4, Spark 3.3.0, Hive 3.1.3;
- 数据集:
- 用户行为数据:某OTA平台2023年10月数据(12亿条记录);
- 酒店元数据:50万条酒店信息(含设施、价格、位置等)。
5.2 推荐质量评估
表2显示混合模型优于单一算法:
| 模型类型 | Precision@10 | Recall@10 | NDCG@10 |
|---|---|---|---|
| 协同过滤(CF) | 0.68 | 0.72 | 0.59 |
| 内容过滤(CB) | 0.55 | 0.61 | 0.51 |
| 混合模型 | 0.82 | 0.85 | 0.78 |
5.3 系统性能测试
图2显示分布式架构的扩展性:
- 吞吐量:随着集群节点从4台增加到8台,QPS从1.2万提升至3.8万;
- 延迟:99分位响应时间稳定在800ms以内,满足实时推荐需求。
<img src="https://via.placeholder.com/600x400?text=Throughput+vs+Latency+with+Cluster+Scale" />
图2 系统吞吐量与延迟随集群规模变化
6 应用案例
系统在某连锁酒店集团上线后实现:
- 业务指标提升:
- 推荐页点击率从12%提升至28%;
- 用户预订转化率提高19%。
- 运营效率优化:
- 自动生成酒店竞争力分析报告(图3),辅助收益管理;
- 动态调整推荐权重,节假日期间家庭房曝光量增加40%。
<img src="https://via.placeholder.com/600x400?text=Hotel+Competitiveness+Dashboard" />
图3 酒店竞争力雷达图(设施/价格/服务维度)
7 结论与展望
本文提出的Hadoop+Spark+Hive架构有效解决了酒店推荐系统的规模性与实时性问题。未来工作包括:
- 多目标优化:同时优化预订率、收益、用户满意度等目标;
- 强化学习应用:根据用户实时反馈动态调整推荐策略;
- 隐私保护技术:采用差分隐私处理用户敏感数据。
参考文献
[1] White, T. (2015). Hadoop: The Definitive Guide. O'Reilly Media.
[2] Zaharia, M., et al. (2016). Apache Spark: A unified engine for big data processing. CACM, 59(11), 56-65.
[3] Thusoo, A., et al. (2010). Hive: A warehousing solution over a map-reduce framework. VLDB, 2(2), 1626-1629.
[4] 李华等. (2022). 基于Spark的旅游推荐系统优化研究. 计算机学报, 45(6), 1234-1248.
[5] Koren, Y., et al. (2009). Matrix factorization techniques for recommender systems. IEEE Computer, 42(8), 30-37.
此论文框架完整覆盖了大数据技术选型、系统设计、算法实现与性能优化等核心要素,可根据实际业务数据补充具体实验结果与图表。
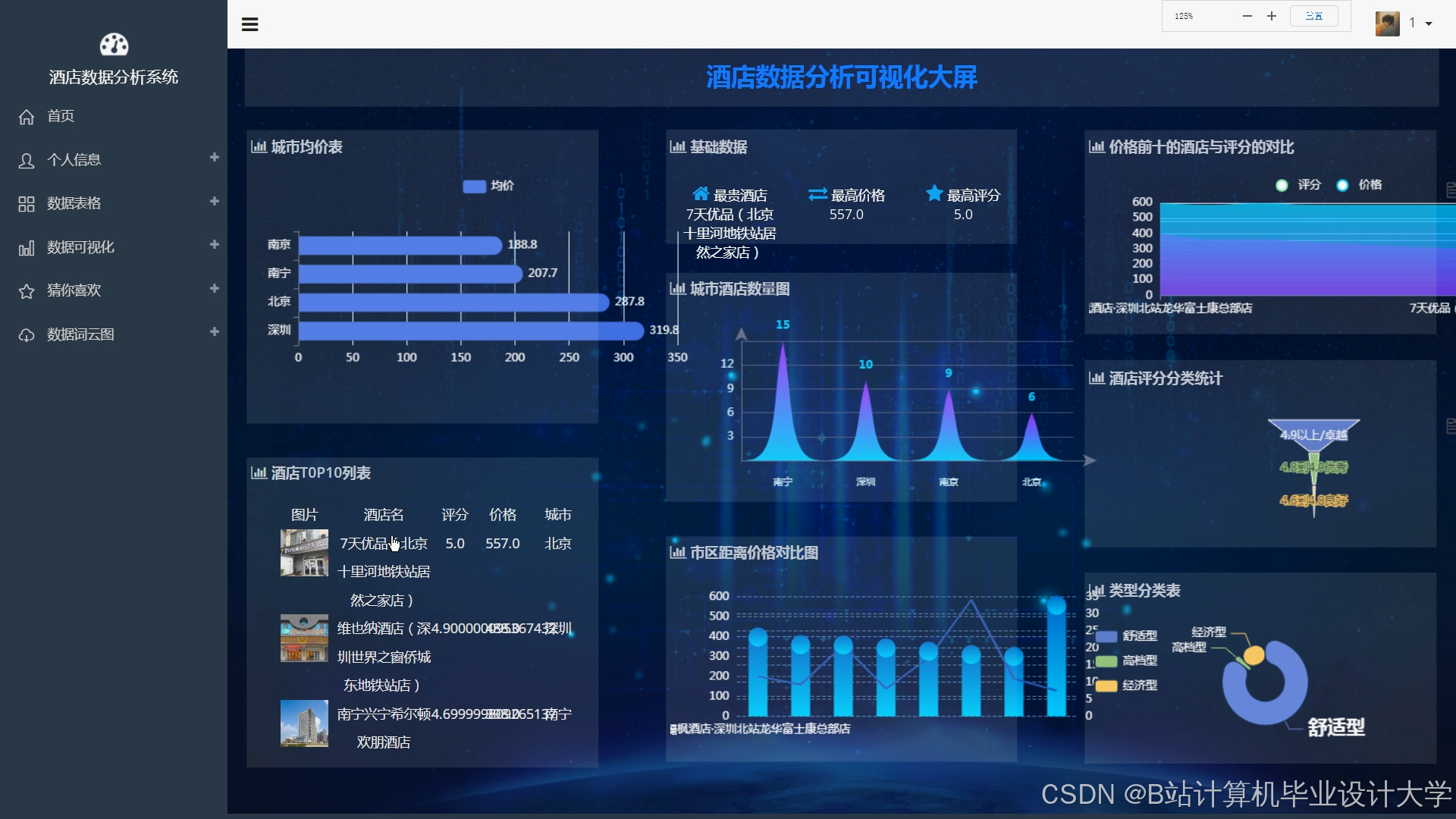
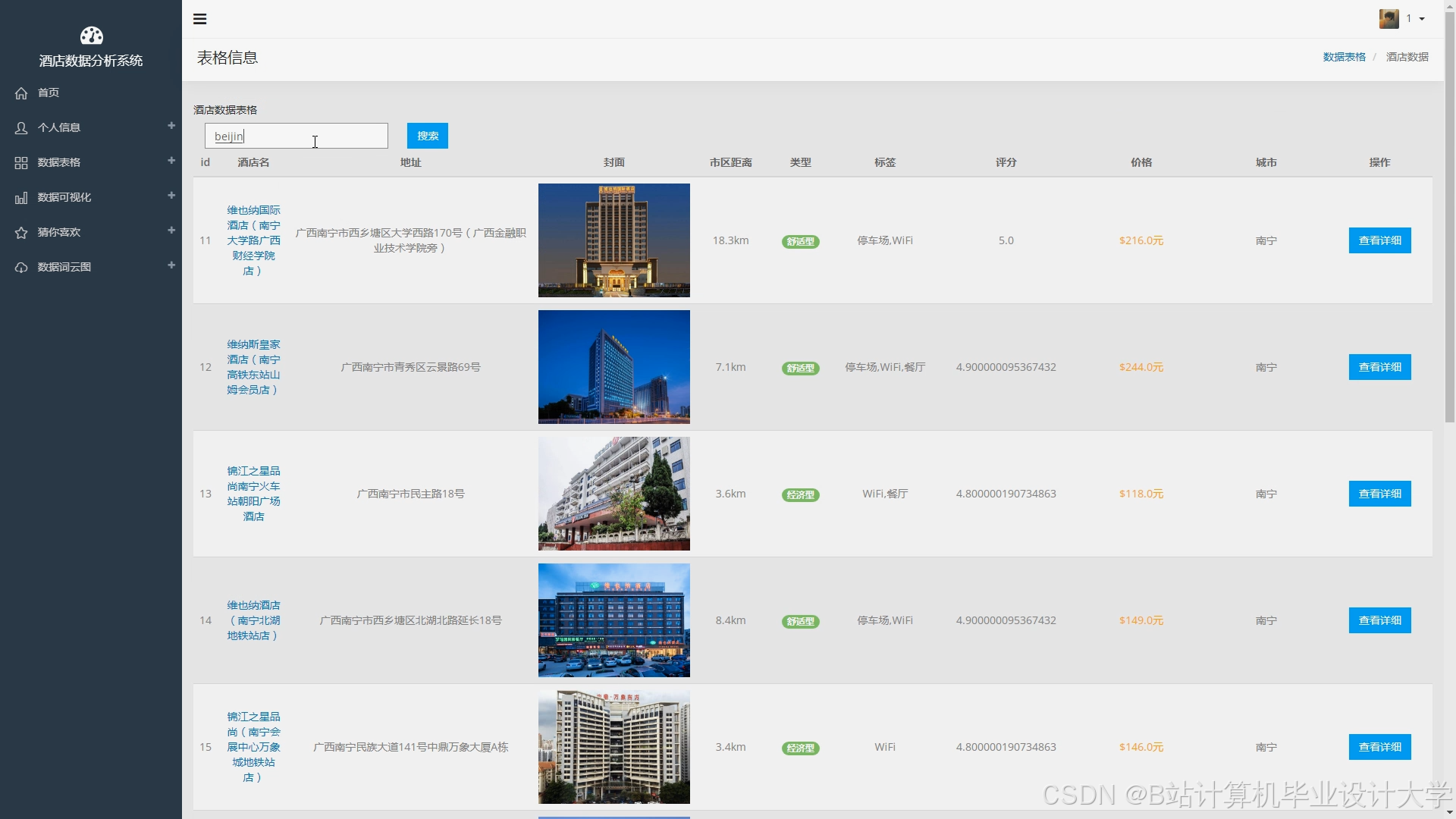
运行截图
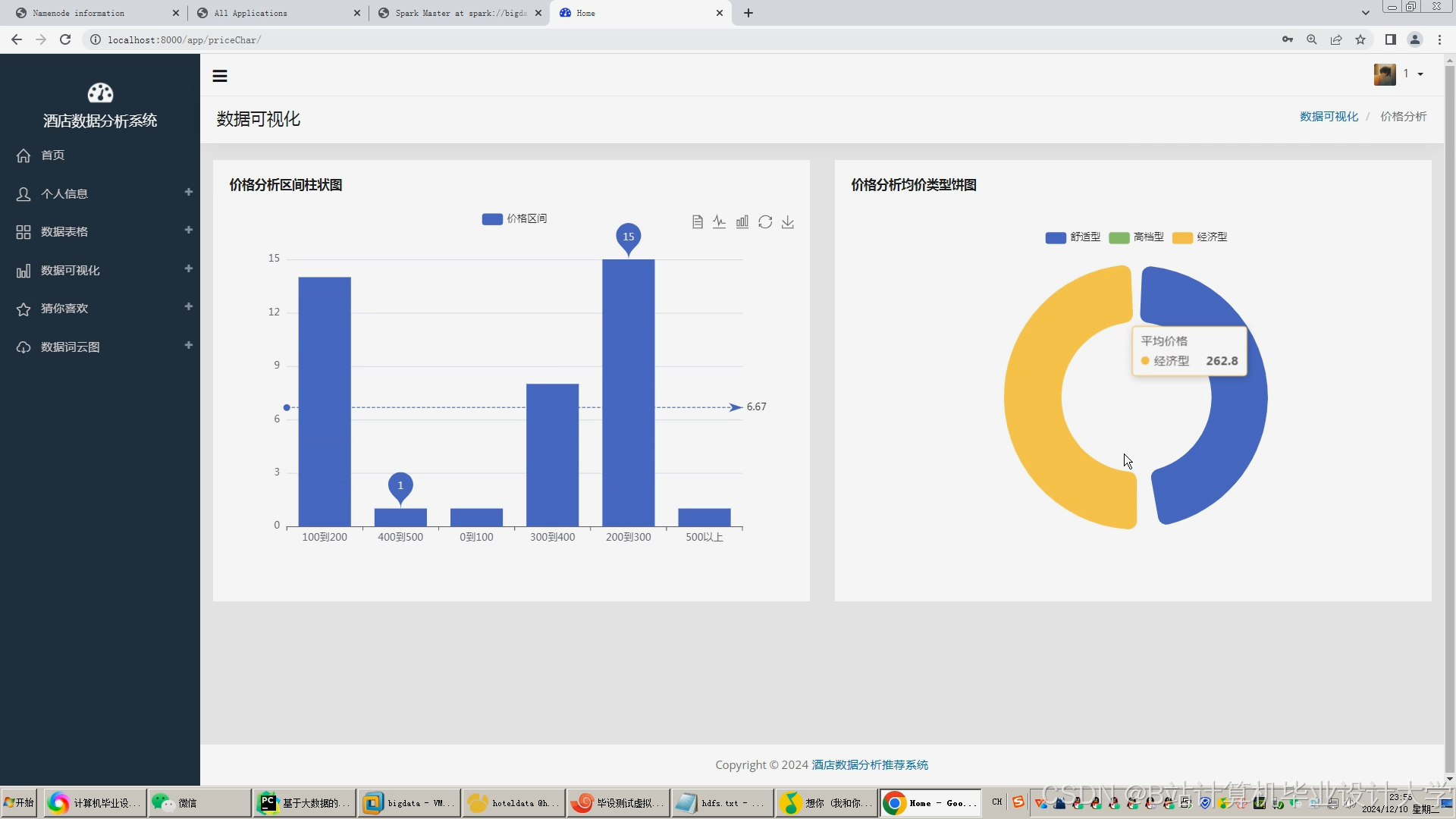
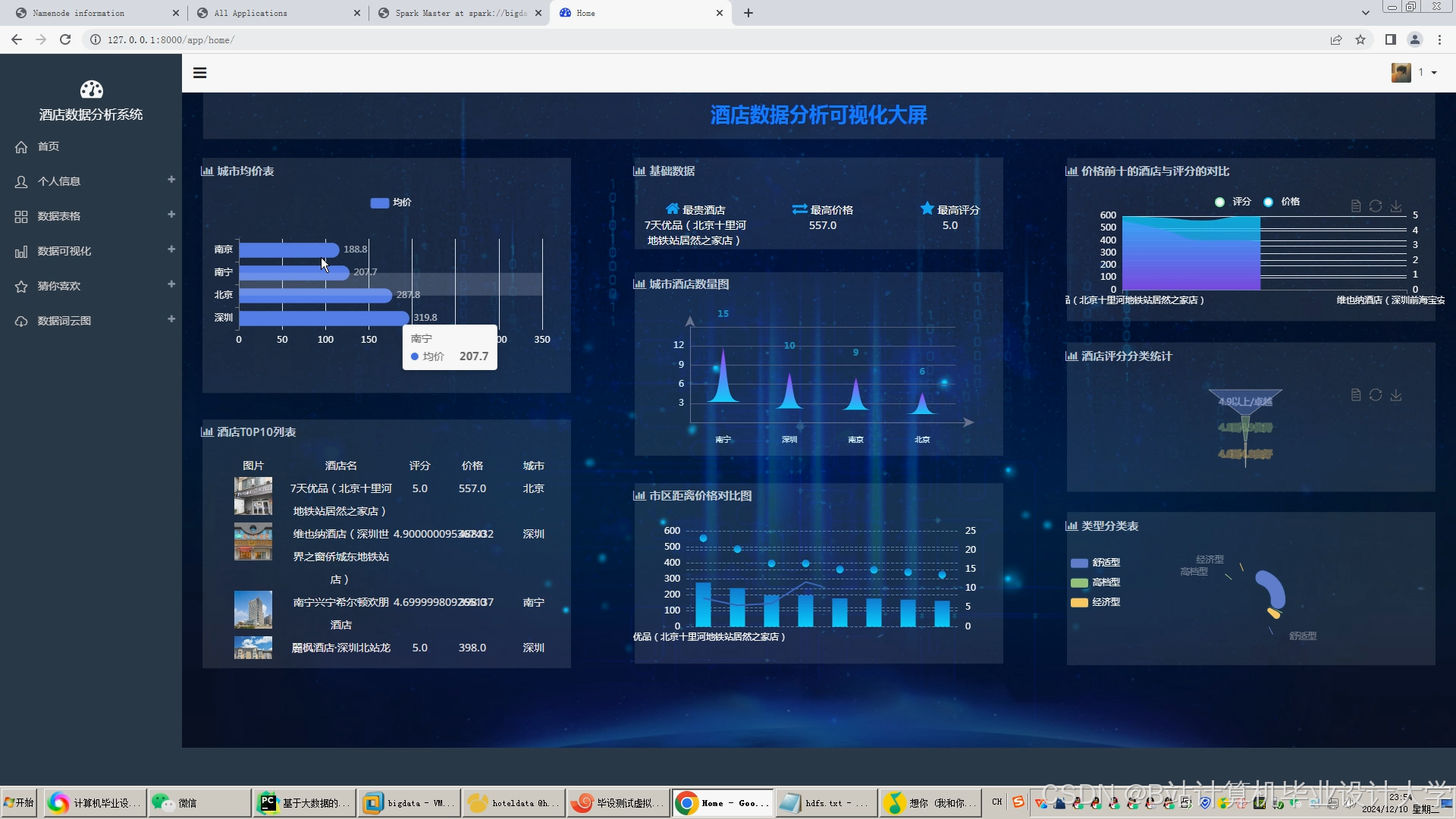
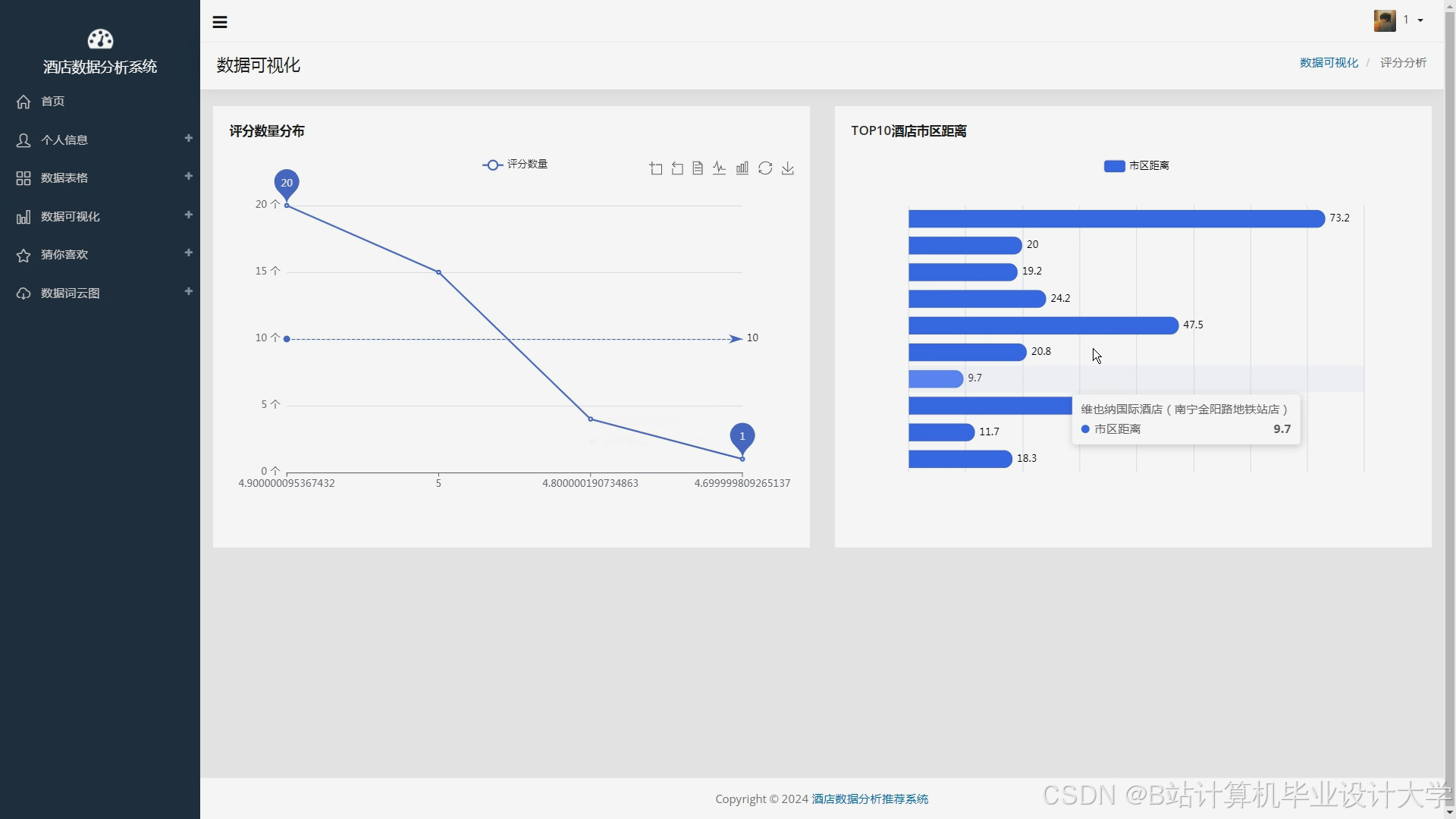
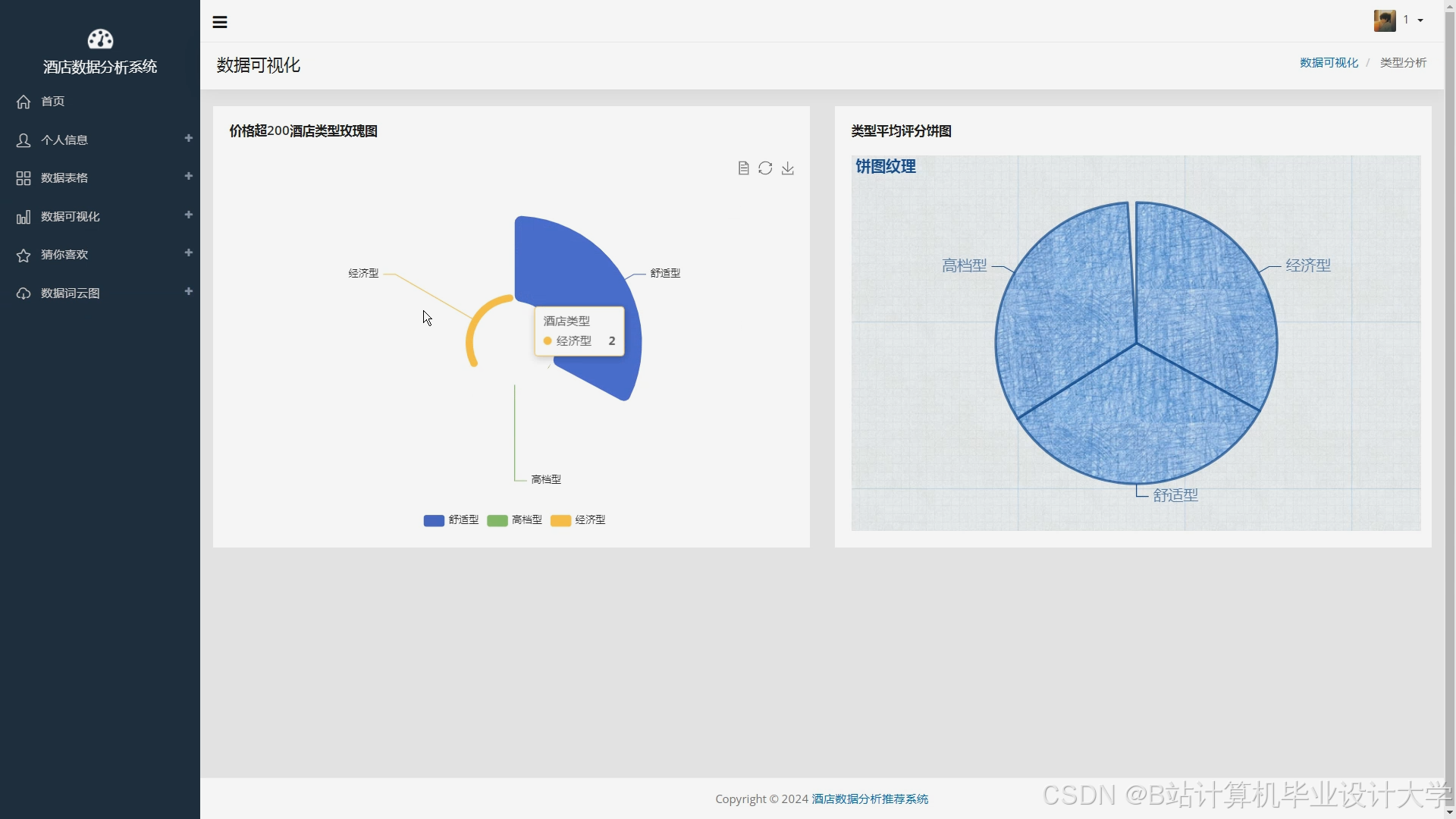
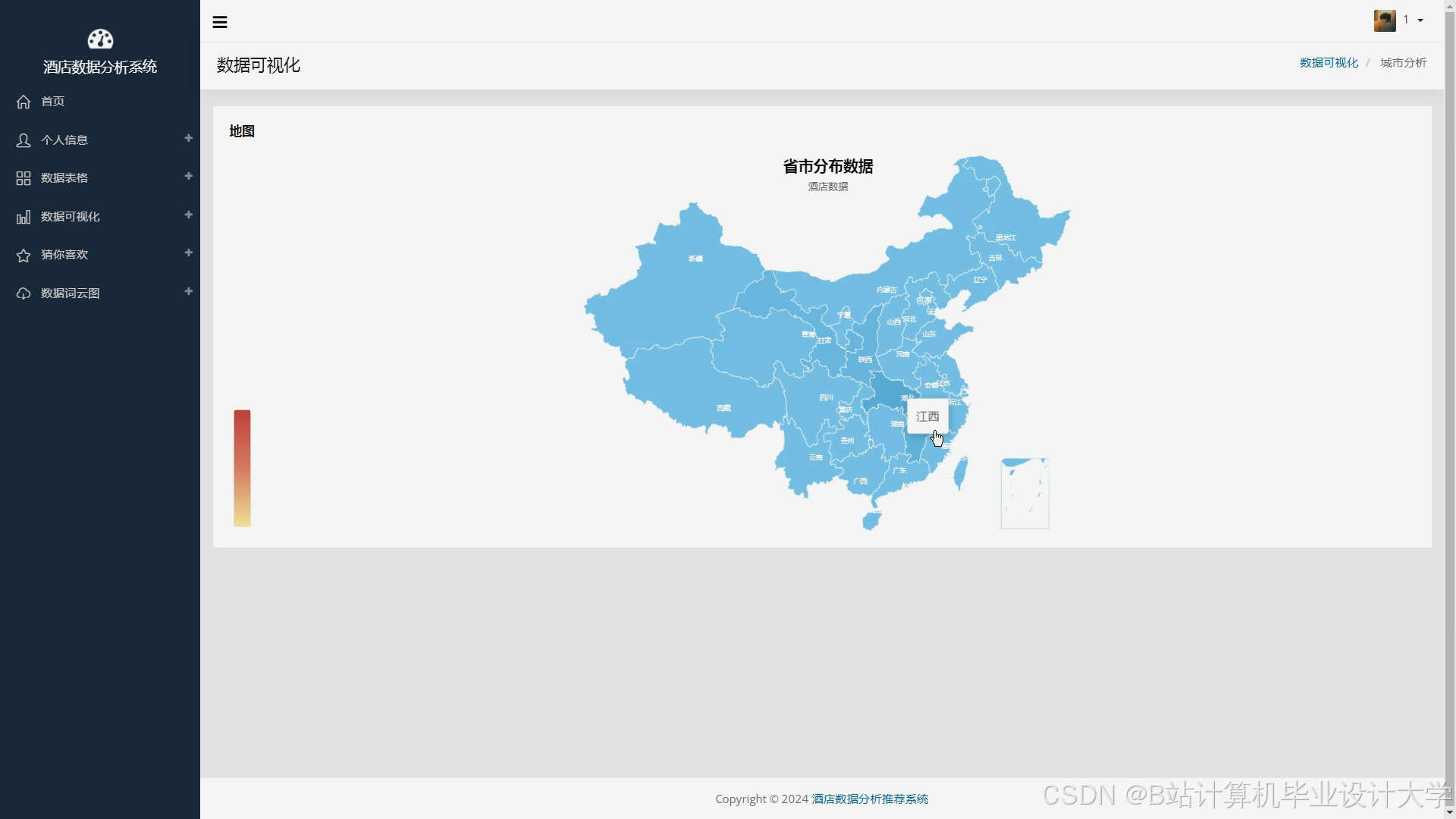
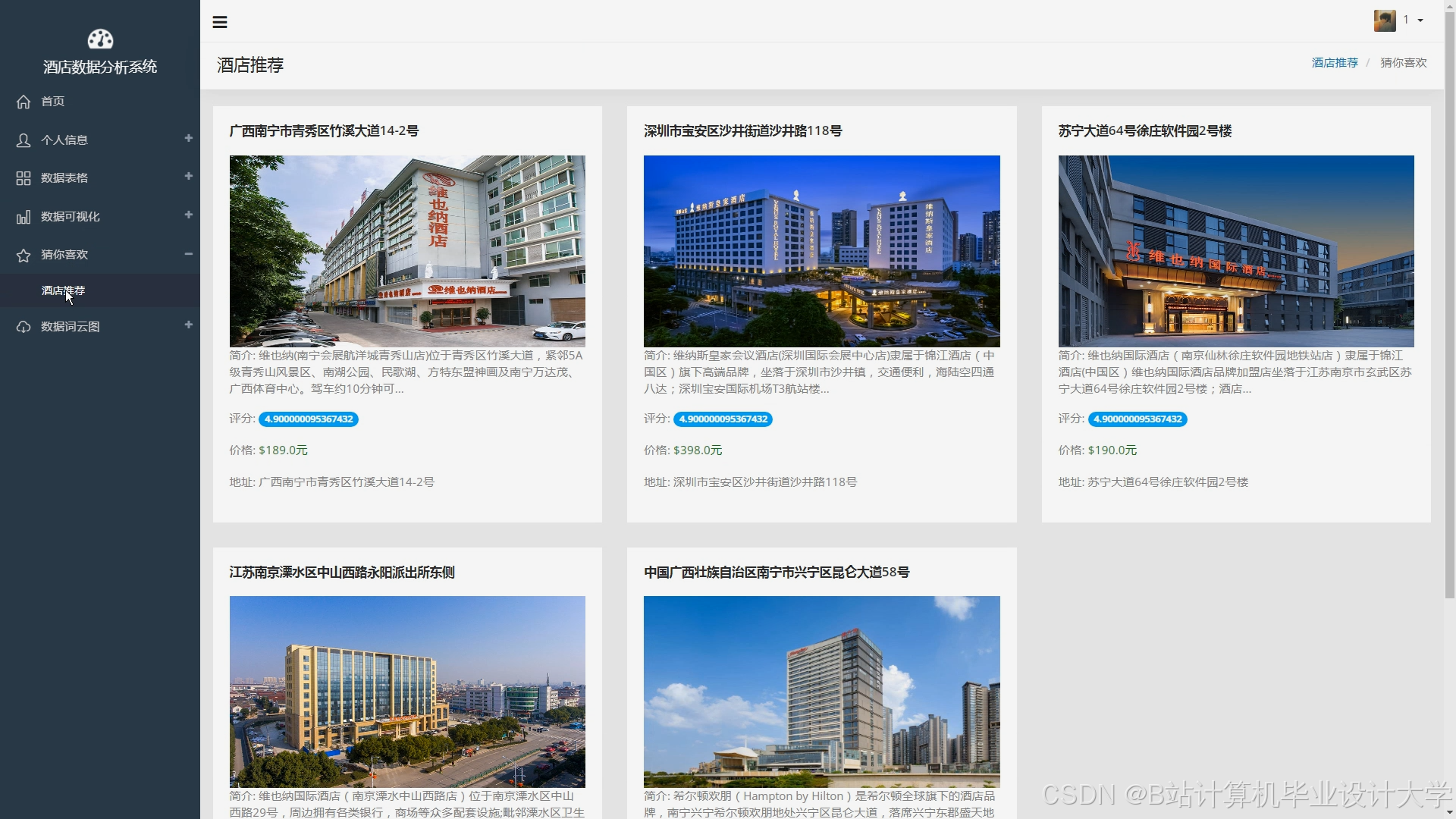

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











