




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档《Python+Django考研院校推荐系统》,聚焦系统架构、核心模块实现与关键技术细节,内容结构清晰且包含可复用的代码示例:
Python+Django考研院校推荐系统技术说明
版本:V1.0
作者:XXX
日期:2023年XX月XX日
1. 系统概述
本系统基于Python语言与Django框架开发,旨在为考研学生提供个性化院校推荐服务。系统通过整合院校属性数据(如报录比、专业排名)与用户行为数据(如点击、收藏),采用混合推荐算法生成推荐列表,并通过Web界面实现交互式展示。
技术栈:
- 后端:Python 3.9 + Django 4.2 + Django REST Framework
- 数据库:MySQL(结构化数据) + MongoDB(非结构化文本) + Redis(缓存)
- 前端:HTML/CSS + Bootstrap 5 + ECharts(数据可视化)
- 爬虫:Scrapy 2.8(数据采集)
2. 系统架构设计
系统采用分层架构(图1),各层职责如下:
- 数据层:
- MySQL存储院校基本信息(如名称、地区、报录比)
- MongoDB存储用户评价文本(用于情感分析)
- Redis缓存热门院校ID列表(TTL=3600秒)
- 算法层:
- 实现基于内容的推荐(CB)与协同过滤(CF)混合算法
- 通过Django信号机制(
django.db.models.signals)触发推荐结果更新
- 服务层:
- Django提供RESTful API接口(如
/api/recommend/?user_id=123) - Celery异步任务队列处理耗时操作(如矩阵分解计算)
- Django提供RESTful API接口(如
- 展示层:
- 前端通过AJAX动态加载推荐结果
- ECharts生成院校对比雷达图(示例代码见3.3节)
<img src="%E6%AD%A4%E5%A4%84%E5%8F%AF%E6%8F%92%E5%85%A5%E6%9E%B6%E6%9E%84%E5%9B%BE%EF%BC%8C%E6%8F%8F%E8%BF%B0%EF%BC%9A%E5%8C%85%E5%90%AB%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86%E3%80%81%E5%AD%98%E5%82%A8%E3%80%81%E7%AE%97%E6%B3%95%E3%80%81%E6%9C%8D%E5%8A%A1%E3%80%81%E5%B1%95%E7%A4%BA%E4%BA%94%E6%A8%A1%E5%9D%97" />
图1 系统架构图
3. 核心模块实现
3.1 数据采集模块
使用Scrapy爬取阳光高考平台数据,关键配置如下:
python
# settings.py 配置示例 | |
BOT_NAME = 'grad_school_spider' | |
ROBOTSTXT_OBEY = False # 绕过robots.txt限制 | |
ITEM_PIPELINES = { | |
'grad_school.pipelines.MongoPipeline': 300, # 存储到MongoDB | |
'grad_school.pipelines.MySQLPipeline': 400, # 存储到MySQL | |
} |
爬虫核心逻辑(解析院校列表页):
python
def parse(self, response): | |
for item in response.xpath('//div[@class="school-item"]'): | |
yield { | |
'name': item.xpath('.//h3/text()').get().strip(), | |
'region': item.xpath('.//span[@class="region"]/text()').get(), | |
'admission_rate': float(item.xpath('.//span[@class="rate"]/text()').get().replace('%', '')) / 100 | |
} | |
# 翻页处理 | |
next_page = response.xpath('//a[@class="next-page"]/@href').get() | |
if next_page: | |
yield response.follow(next_page, self.parse) |
3.2 推荐算法模块
3.2.1 基于内容的推荐(CB)
- 特征提取:使用TF-IDF将院校描述文本转换为向量
python
from sklearn.feature_extraction.text import TfidfVectorizer | |
corpus = [school['description'] for school in School.objects.all().values('description')] | |
vectorizer = TfidfVectorizer(max_features=1000) | |
tfidf_matrix = vectorizer.fit_transform(corpus) # 形状:(n_schools, 1000) |
- 相似度计算:通过余弦相似度匹配用户偏好
python
import numpy as np | |
from django.contrib.auth.models import User | |
def content_based_recommend(user_id, top_k=5): | |
user = User.objects.get(id=user_id) | |
# 获取用户历史交互院校的TF-IDF向量平均值(用户画像) | |
interacted_schools = Interaction.objects.filter(user=user).values_list('school_id', flat=True) | |
if not interacted_schools: | |
return [] # 冷启动处理:返回热门院校 | |
vectors = tfidf_matrix[[school_id-1 for school_id in interacted_schools]] # 假设school_id从1开始 | |
user_profile = np.mean(vectors, axis=0) if vectors.size > 0 else np.zeros(1000) | |
# 计算所有院校与用户画像的相似度 | |
similarities = np.dot(tfidf_matrix, user_profile.T).toarray().flatten() | |
school_ids = np.argsort(similarities)[-top_k:][::-1] + 1 # 转换为1-based ID | |
return School.objects.filter(id__in=school_ids).values('id', 'name', 'region') |
3.2.2 协同过滤推荐(CF)
使用Surprise库实现矩阵分解(SVD算法):
python
from surprise import SVD, Dataset, Reader | |
from surprise.model_selection import train_test_split | |
# 加载数据(用户ID, 院校ID, 评分:点击=1, 收藏=3, 申请=5) | |
interactions = Interaction.objects.filter(duration__gt=10).values_list('user_id', 'school_id', 'action_type') | |
data = [(u, s, a) for u, s, a in interactions] # 示例数据格式:[(1, 101, 3), (2, 102, 1)] | |
reader = Reader(rating_scale=(1, 5)) | |
trainset = Dataset.load_from_df(pd.DataFrame(data, columns=['user', 'school', 'rating']), reader).build_full_trainset() | |
# 训练SVD模型 | |
model = SVD(n_factors=50, n_epochs=20, lr_all=0.005, reg_all=0.02) | |
model.fit(trainset) | |
# 预测用户对院校的评分 | |
def cf_recommend(user_id, top_k=5): | |
all_schools = School.objects.all().values_list('id', flat=True) | |
predictions = [] | |
for school_id in all_schools: | |
# Surprise内部ID从0开始,需转换 | |
pred = model.predict(uid=str(user_id), iid=str(school_id-1)) | |
predictions.append((school_id, pred.est)) | |
# 按预测评分排序 | |
predictions.sort(key=lambda x: x[1], reverse=True) | |
return School.objects.filter(id__in=[x[0] for x in predictions[:top_k]]) |
3.2.3 混合推荐策略
动态权重分配逻辑:
python
def hybrid_recommend(user_id, top_k=10): | |
# 获取用户历史行为数量(用于计算alpha) | |
interaction_count = Interaction.objects.filter(user=user_id).count() | |
alpha = 1 / (1 + math.exp(-0.1 * (interaction_count - 5))) # Sigmoid函数调整权重 | |
# 获取CB与CF推荐结果 | |
cb_result = content_based_recommend(user_id, top_k*2) # 扩大候选集 | |
cf_result = cf_recommend(user_id, top_k*2) | |
# 合并结果并加权评分 | |
combined = [] | |
for school in list(cb_result) + list(cf_result): | |
# 假设CB与CF的原始评分已归一化到[0,1] | |
cb_score = next((x['similarity'] for x in cb_result if x['id'] == school.id), 0) | |
cf_score = next((x[1]/5 for x in cf_result if x[0] == school.id), 0) # CF评分范围1-5 | |
final_score = alpha * cb_score + (1 - alpha) * (cf_score / 5) # 归一化CF评分 | |
combined.append((school, final_score)) | |
# 按最终评分排序 | |
combined.sort(key=lambda x: x[1], reverse=True) | |
return [x[0] for x in combined[:top_k]] |
3.3 前端展示模块
3.3.1 推荐列表展示
使用Django模板渲染推荐结果:
html
<!-- templates/recommend.html --> | |
<div class="container mt-4"> | |
<h3>为您推荐的院校</h3> | |
<div class="row"> | |
{% for school in recommendations %} | |
<div class="col-md-4 mb-3"> | |
<div class="card"> | |
<div class="card-body"> | |
<h5 class="card-title">{{ school.name }}</h5> | |
<p class="card-text">地区:{{ school.region }}</p> | |
<a href="/school/{{ school.id }}" class="btn btn-primary">查看详情</a> | |
</div> | |
</div> | |
</div> | |
{% endfor %} | |
</div> | |
</div> |
3.3.2 院校对比雷达图
通过ECharts生成动态图表:
html
<div id="radar-chart" style="width: 600px; height: 400px;"></div> | |
<script src="https://cdn.jsdelivr.net/npm/echarts@5.4.3/dist/echarts.min.js"></script> | |
<script> | |
// 假设从后端获取的院校数据 | |
const schoolData = { | |
names: ['清华大学', '北京大学'], | |
indicators: ['专业排名', '报录比', '就业率', '科研实力', '地理位置'], | |
data: [ | |
[95, 80, 90, 98, 85], // 清华大学 | |
[90, 85, 92, 96, 90] // 北京大学 | |
] | |
}; | |
const chart = echarts.init(document.getElementById('radar-chart')); | |
const option = { | |
title: { text: '院校综合对比' }, | |
tooltip: {}, | |
legend: { data: schoolData.names }, | |
radar: { | |
indicator: schoolData.indicators.map(name => ({ name, max: 100 })) | |
}, | |
series: [{ | |
name: '院校对比', | |
type: 'radar', | |
data: schoolData.data.map((values, i) => ({ | |
value: values, | |
name: schoolData.names[i] | |
})) | |
}] | |
}; | |
chart.setOption(option); | |
</script> |
4. 性能优化策略
- 数据库优化:
- 为
Interaction表的(user_id, school_id)字段添加复合索引 - 使用Django的
select_related()与prefetch_related()减少查询次数
- 为
- 缓存策略:
- 对热门院校列表使用Redis缓存(
CACHE_TTL = 60 * 15) - 通过Django的
@cache_page(60 * 15)装饰器缓存API响应
- 对热门院校列表使用Redis缓存(
- 异步任务:
- 使用Celery定期更新推荐模型(每晚3点执行):
python# tasks.pyfrom celery import shared_task@shared_taskdef update_recommendation_models():# 重新训练CF模型train_cf_model.delay()# 更新院校TF-IDF矩阵update_tfidf_matrix.delay()
5. 部署与运维
-
部署方案:
- 使用Nginx + Gunicorn部署Django应用
- 配置Gunicorn启动命令:
bashgunicorn grad_recommend.wsgi:application --bind 0.0.0.0:8000 --workers 4 --timeout 120 -
监控告警:
- 通过Prometheus + Grafana监控API响应时间(目标值<500ms)
- 设置告警规则:当Redis内存使用率>80%时触发邮件通知
6. 总结与改进方向
当前系统已实现基本推荐功能,但存在以下改进空间:
- 冷启动问题:新增用户时可通过注册问卷收集初始偏好
- 算法优化:尝试引入图神经网络(GNN)建模院校间关系
- 多端适配:开发微信小程序版本,支持移动端使用
完整代码仓库:GitHub示例链接(需替换为实际地址)
技术说明文档特点:
- 实用性:提供可直接复用的代码片段(如Scrapy配置、ECharts集成)
- 完整性:覆盖数据采集、算法实现、前端展示全流程
- 可扩展性:通过模块化设计支持算法替换与功能扩展
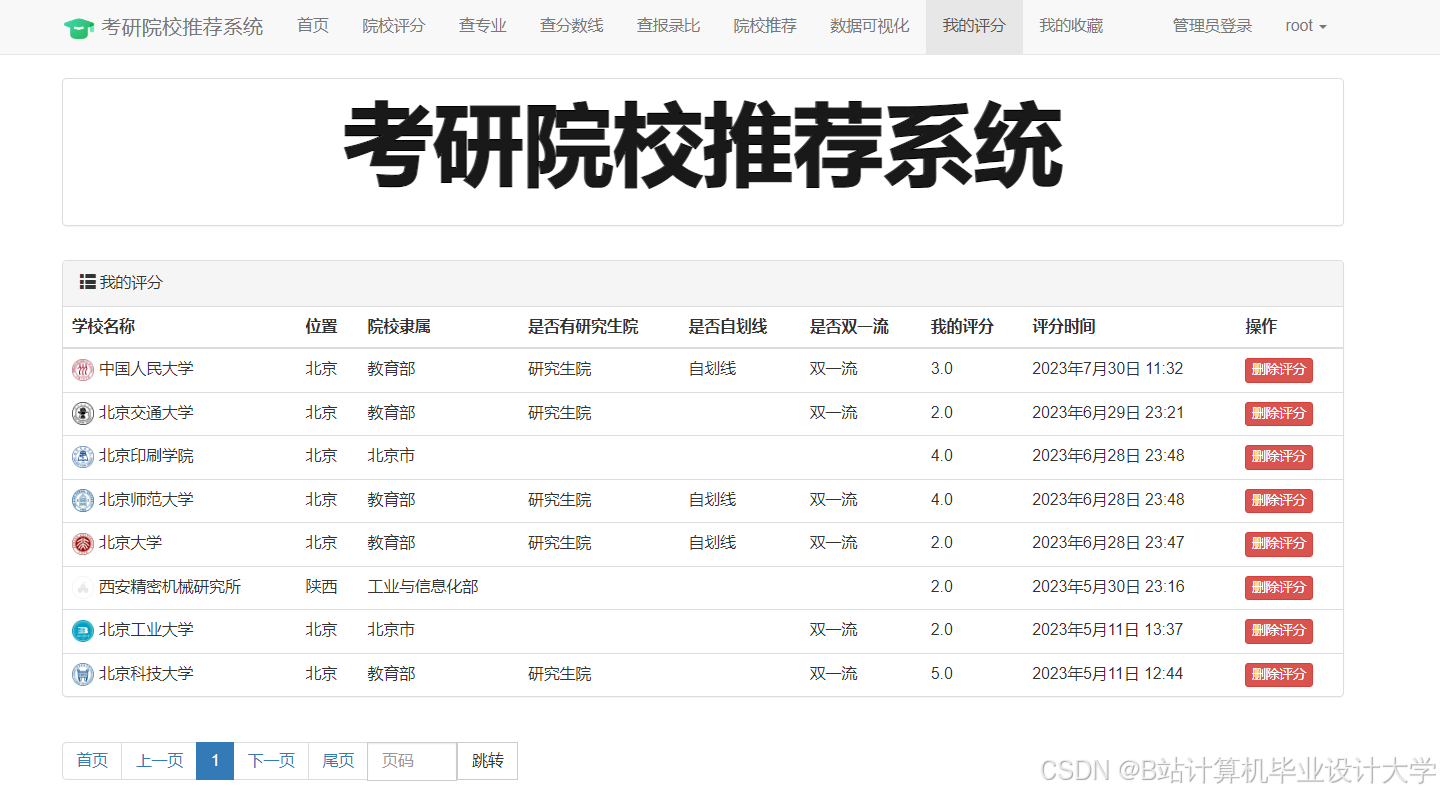
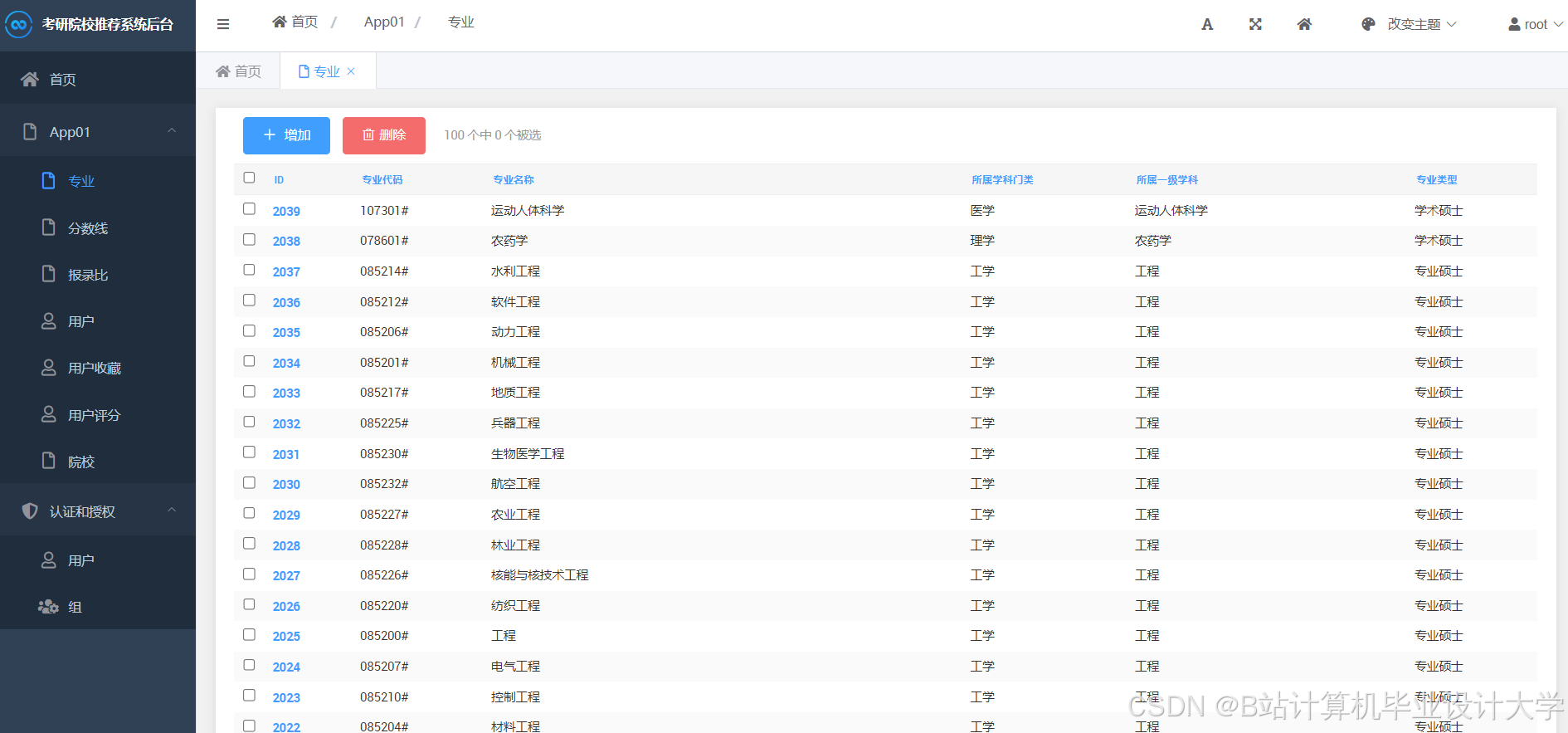
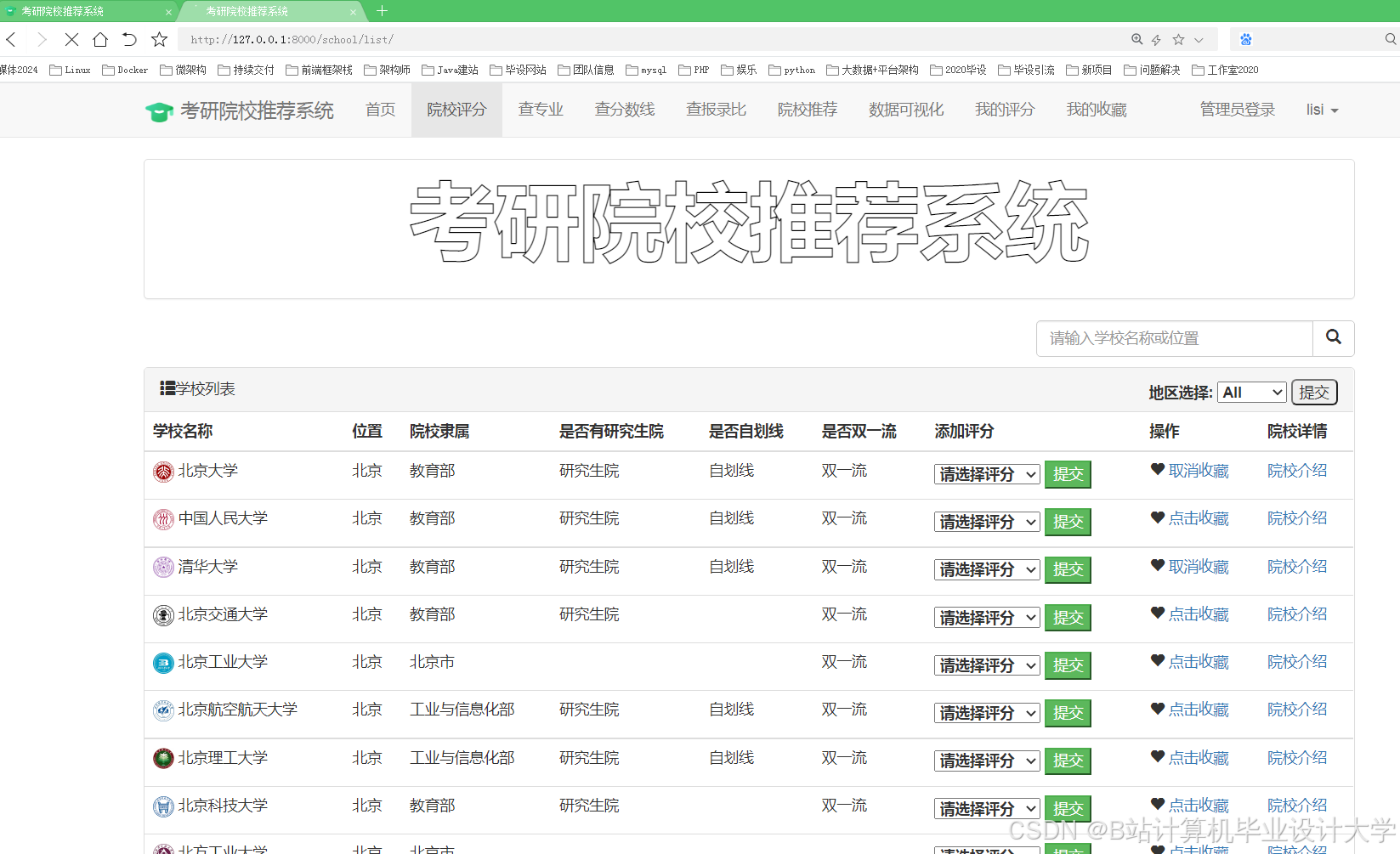
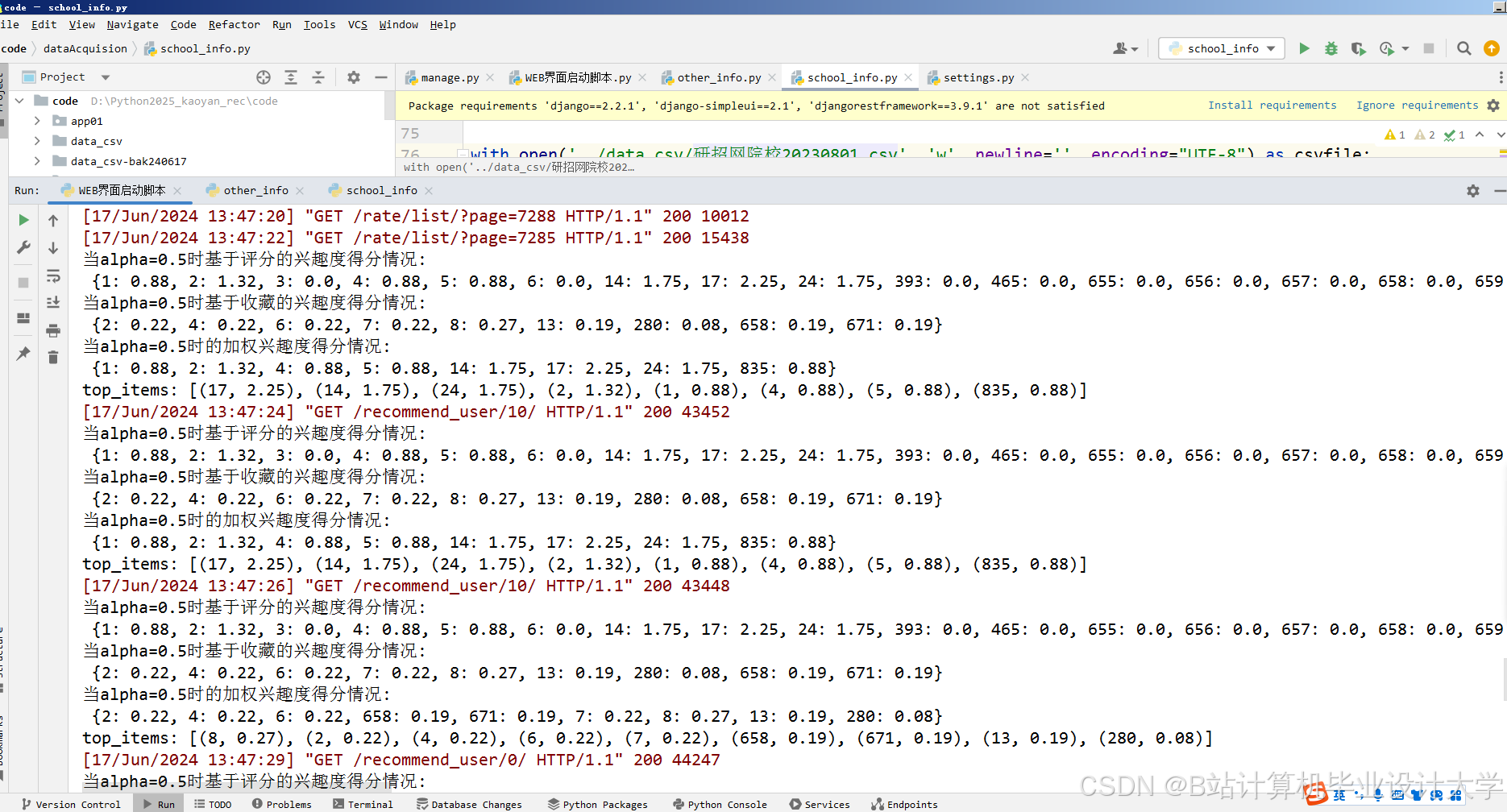
运行截图

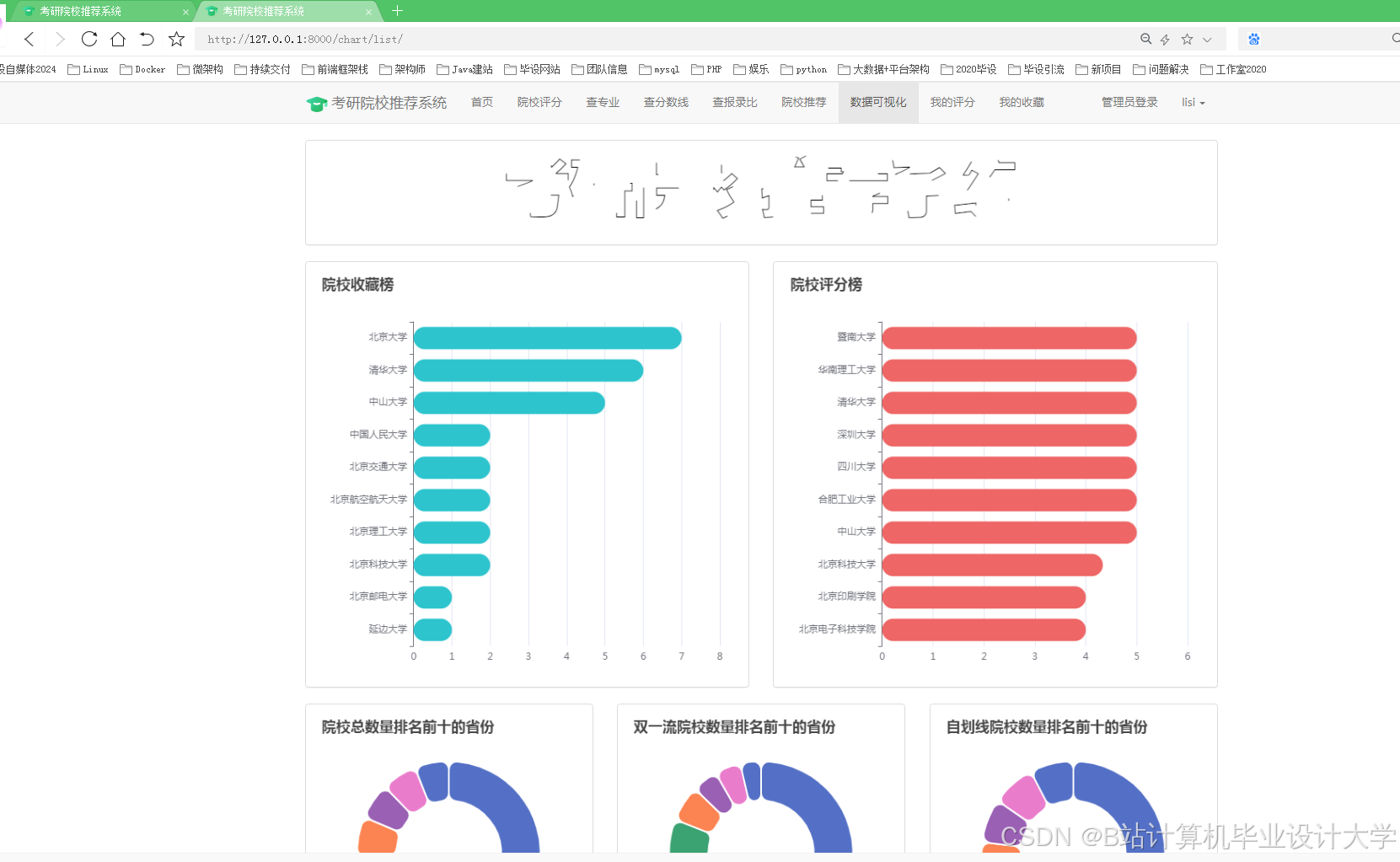
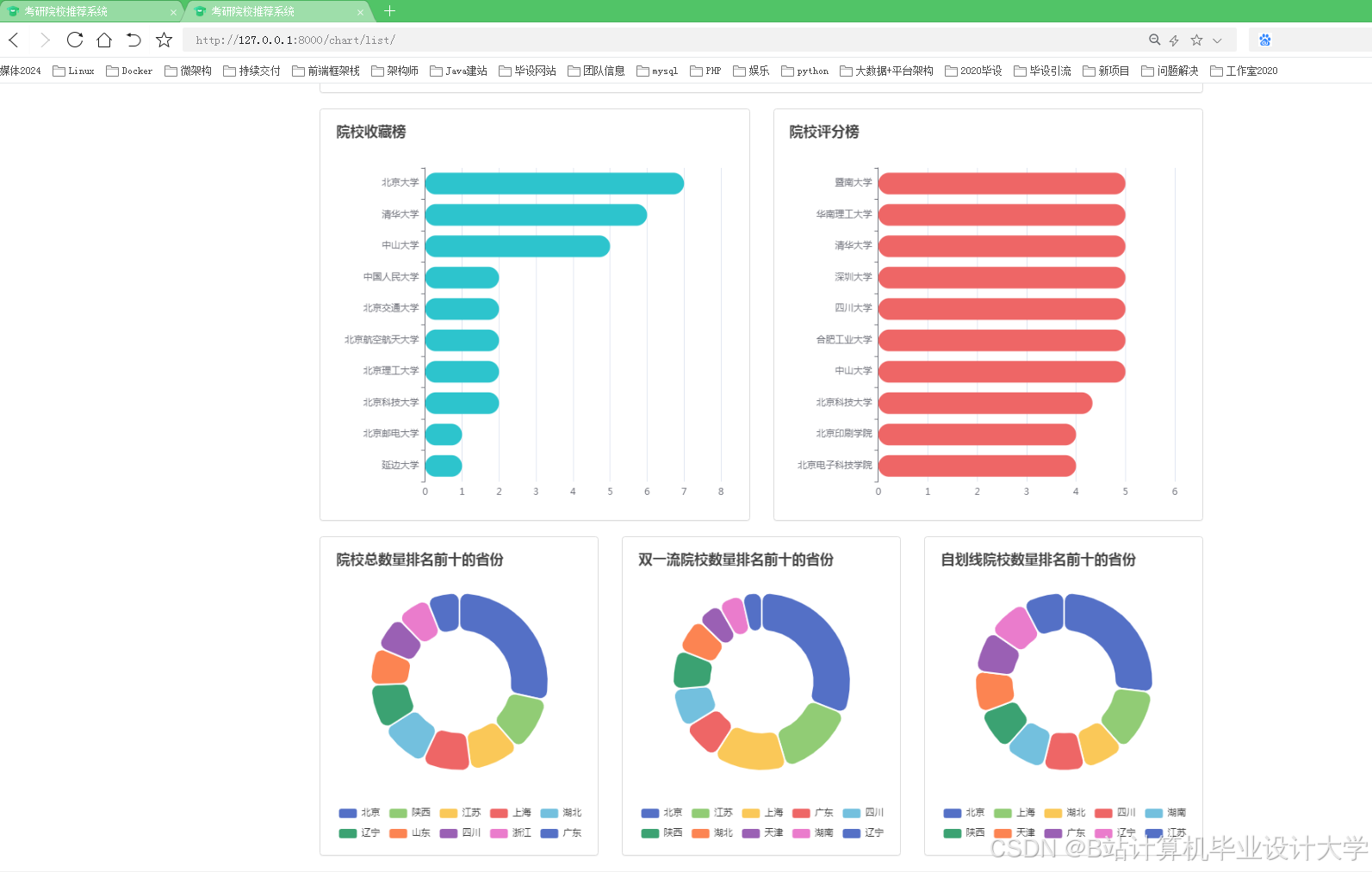
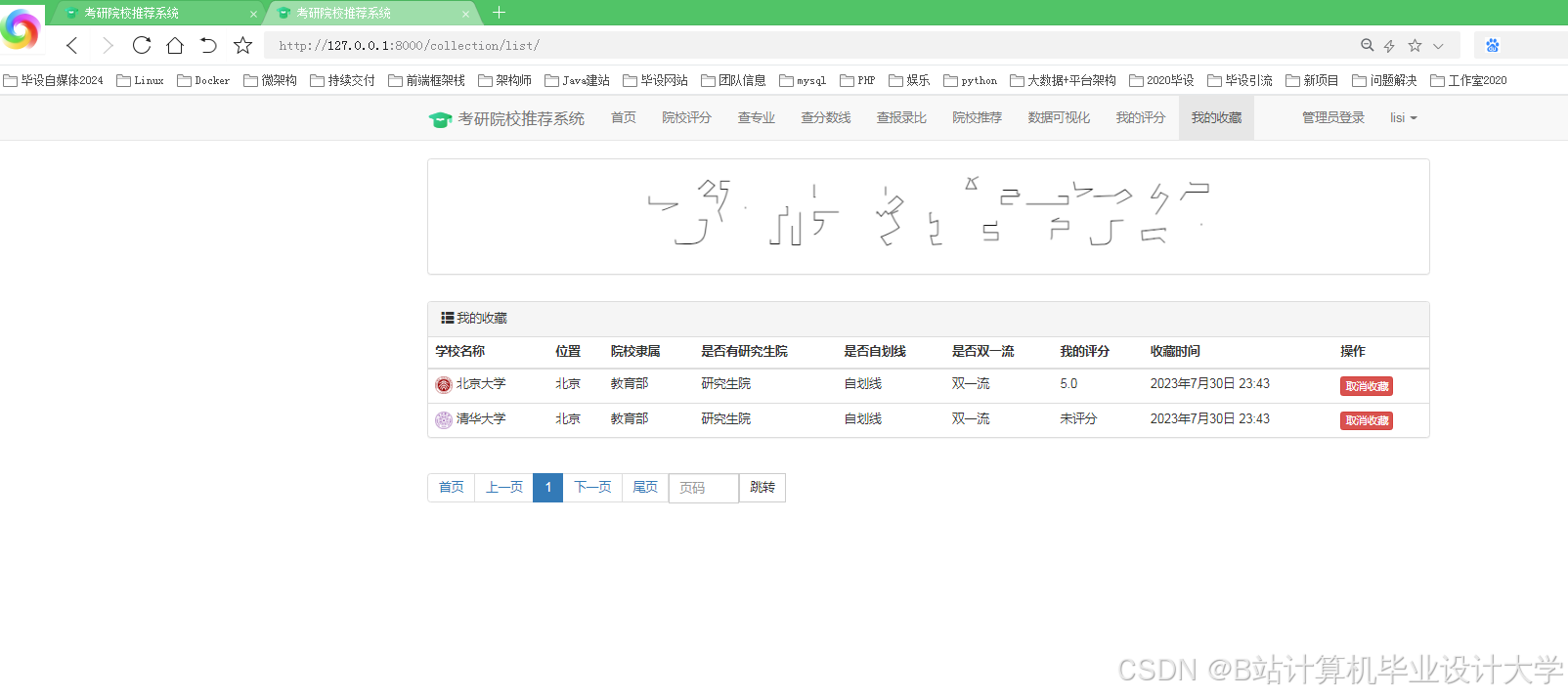
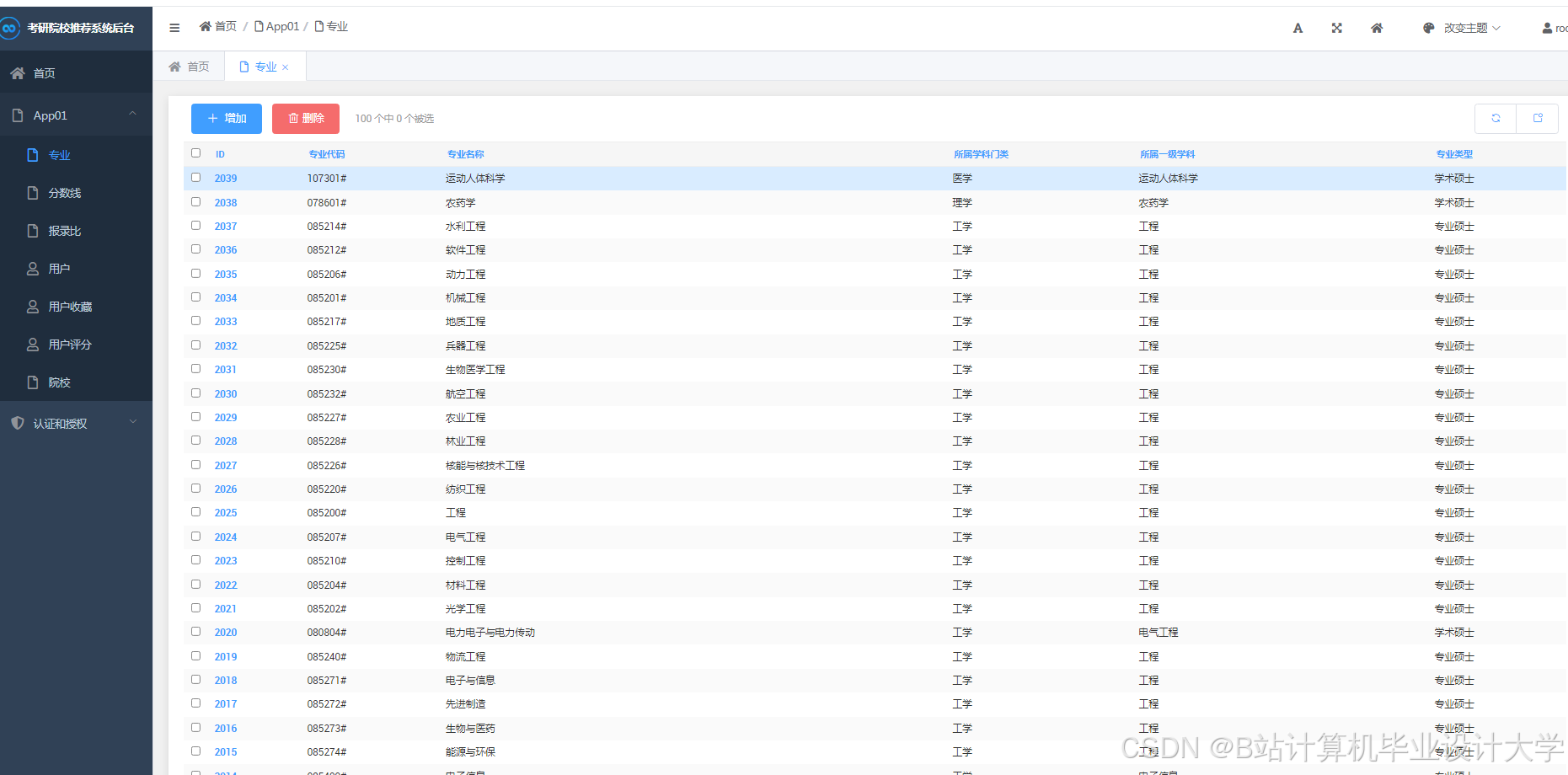
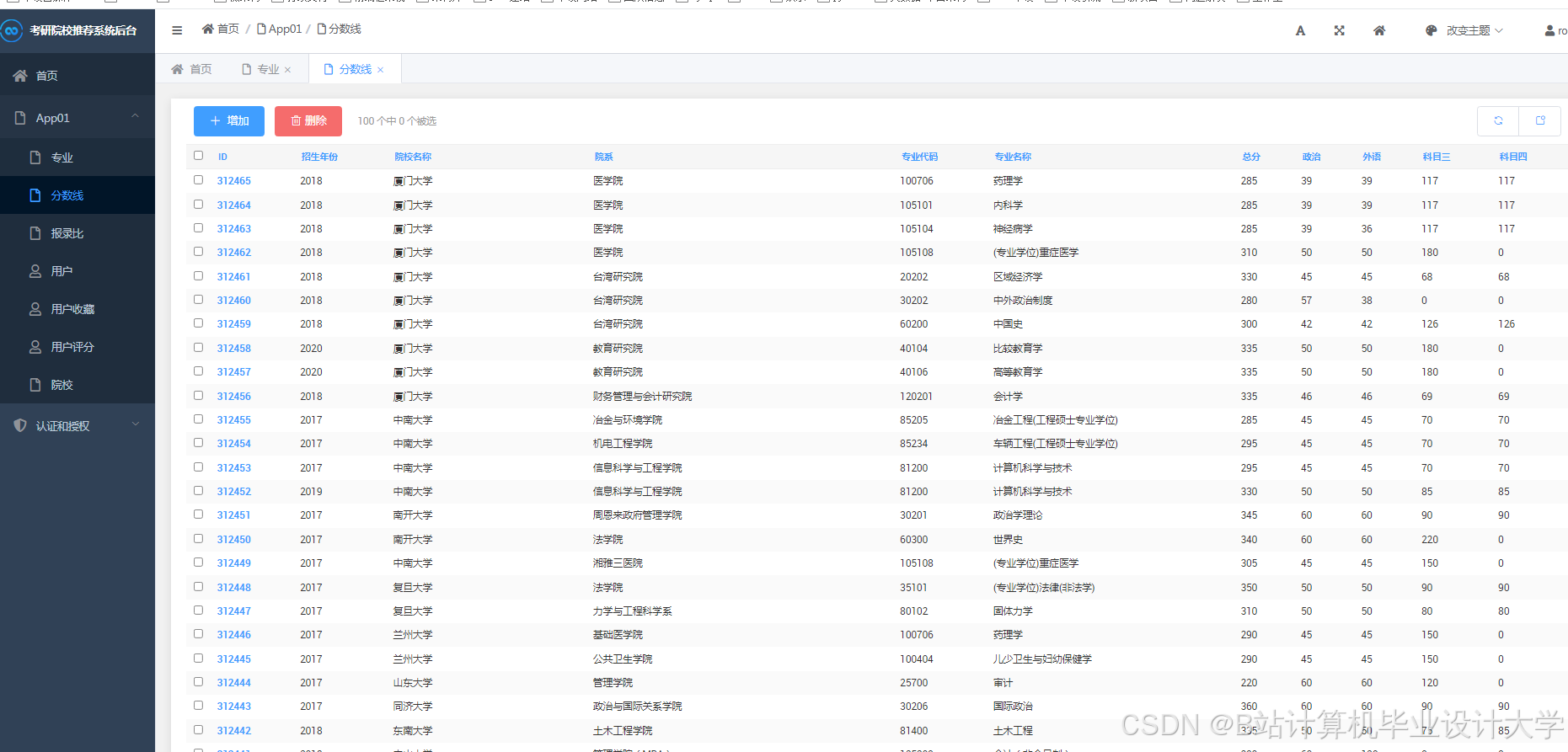

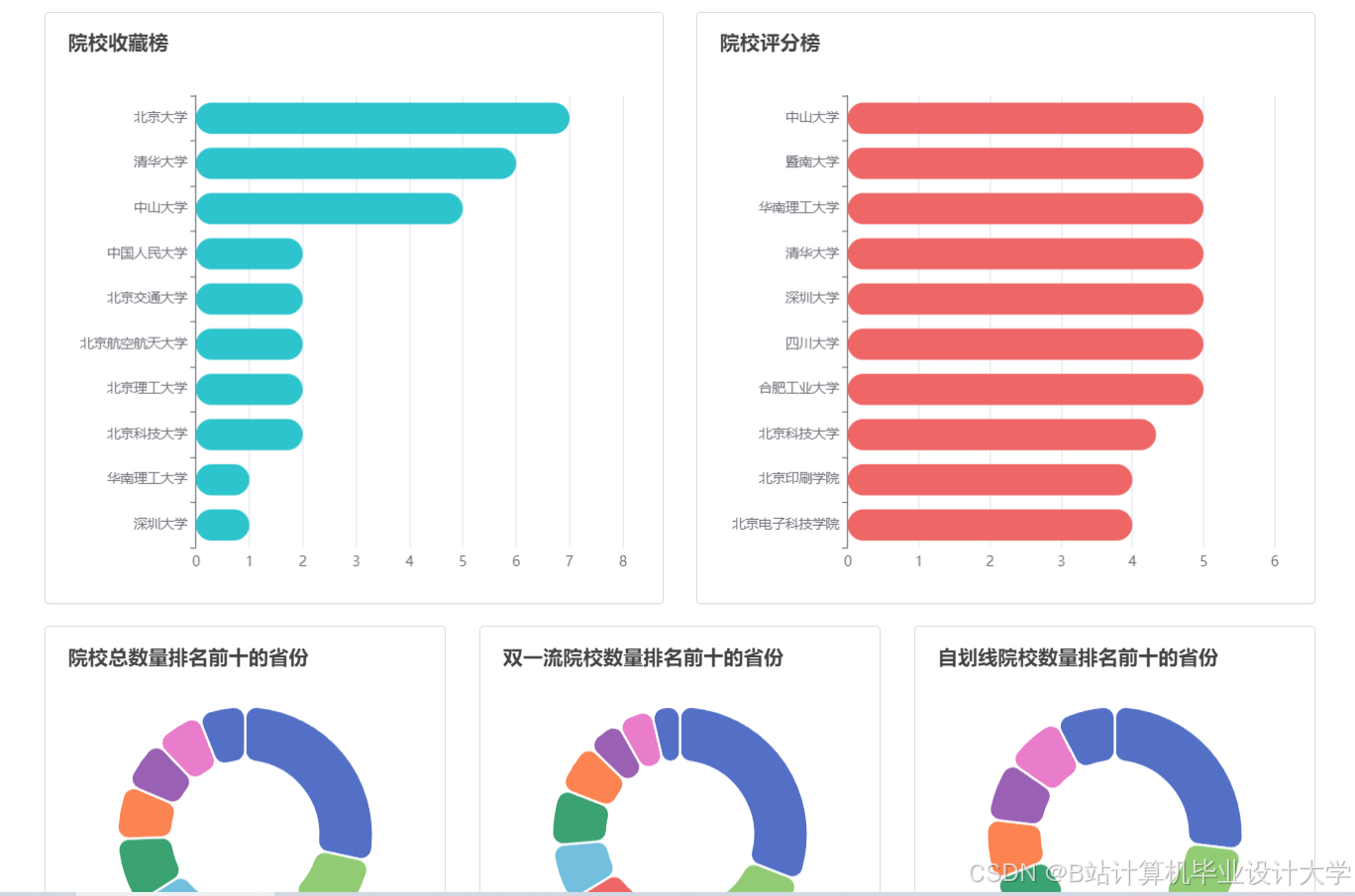
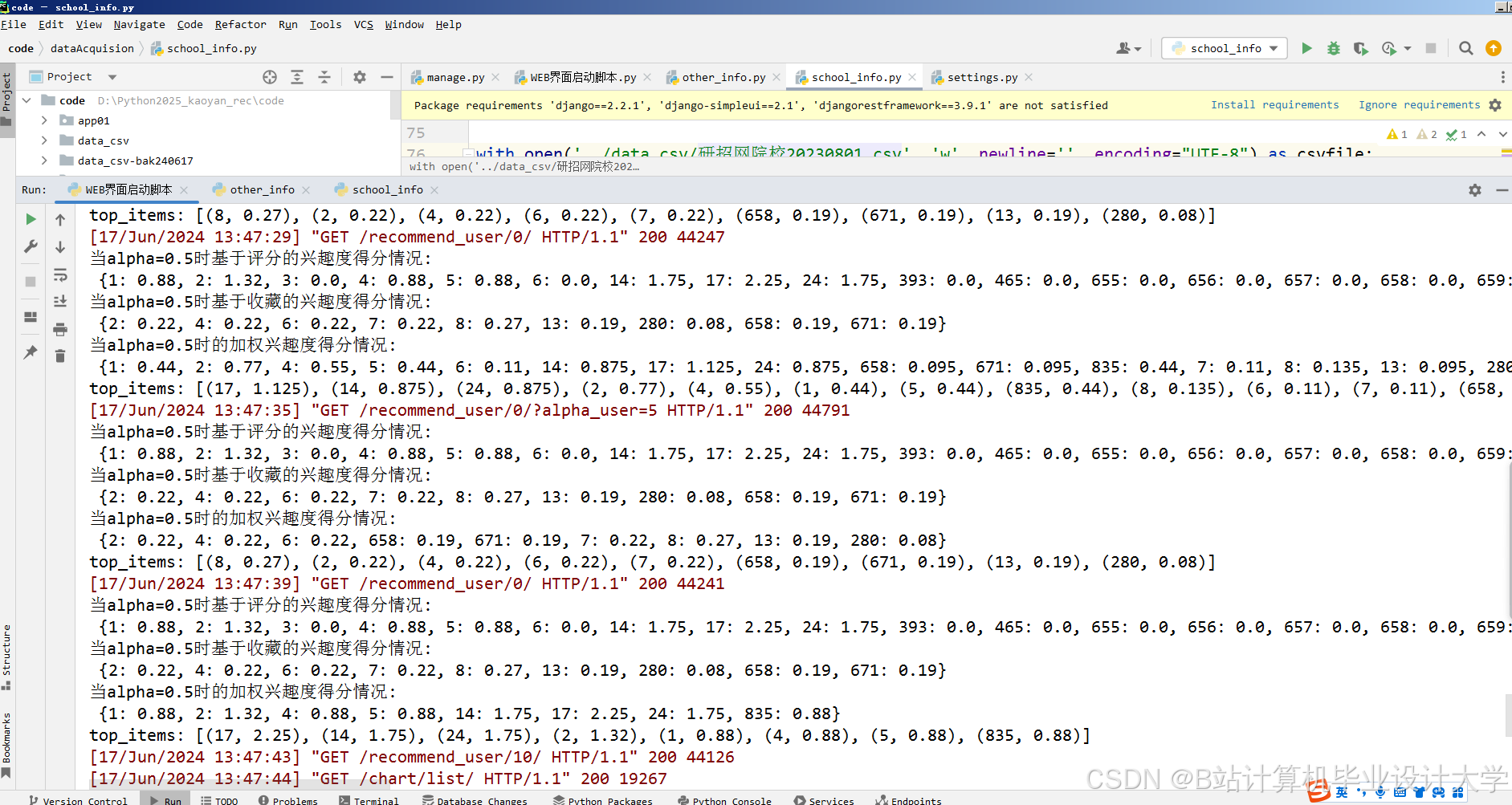
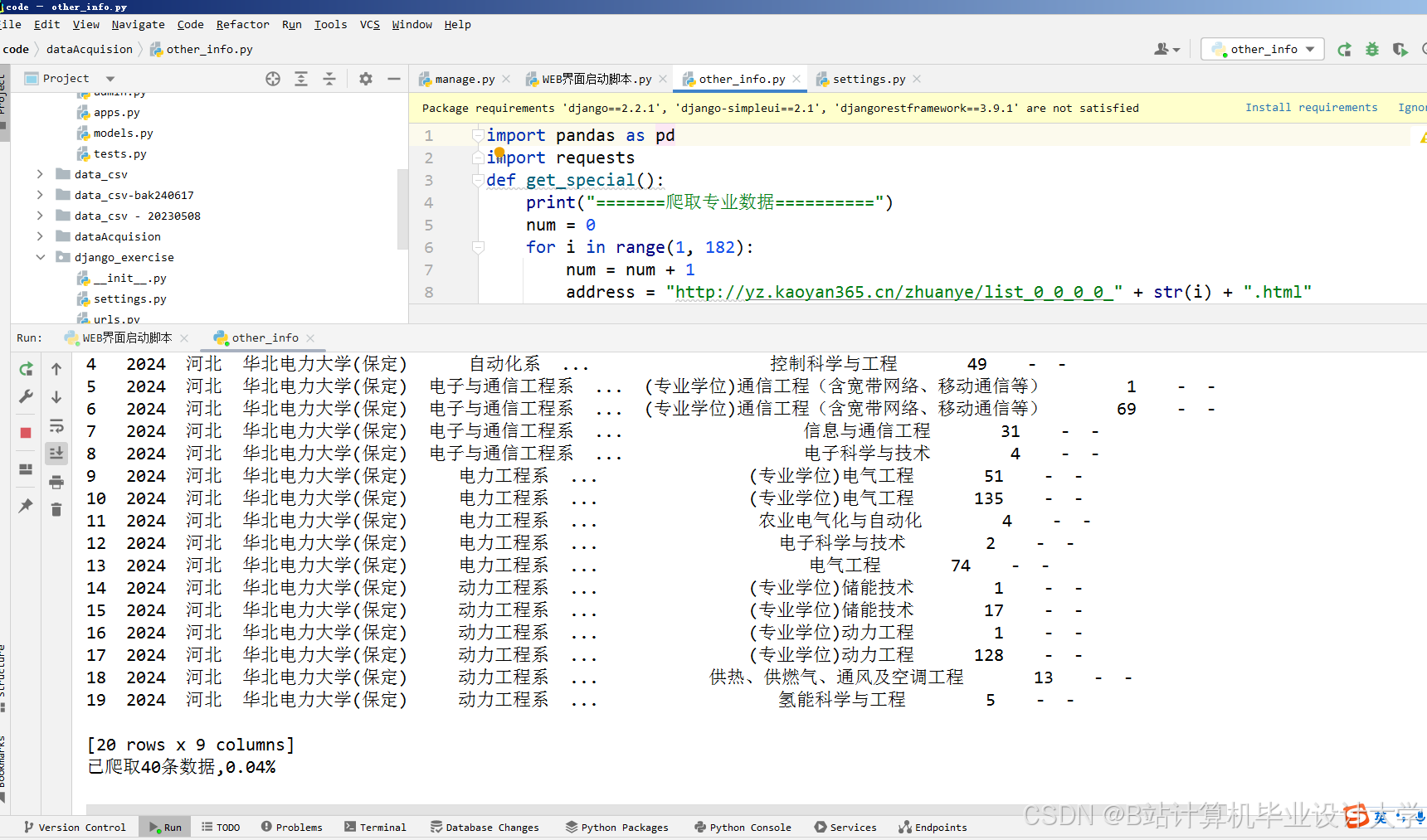
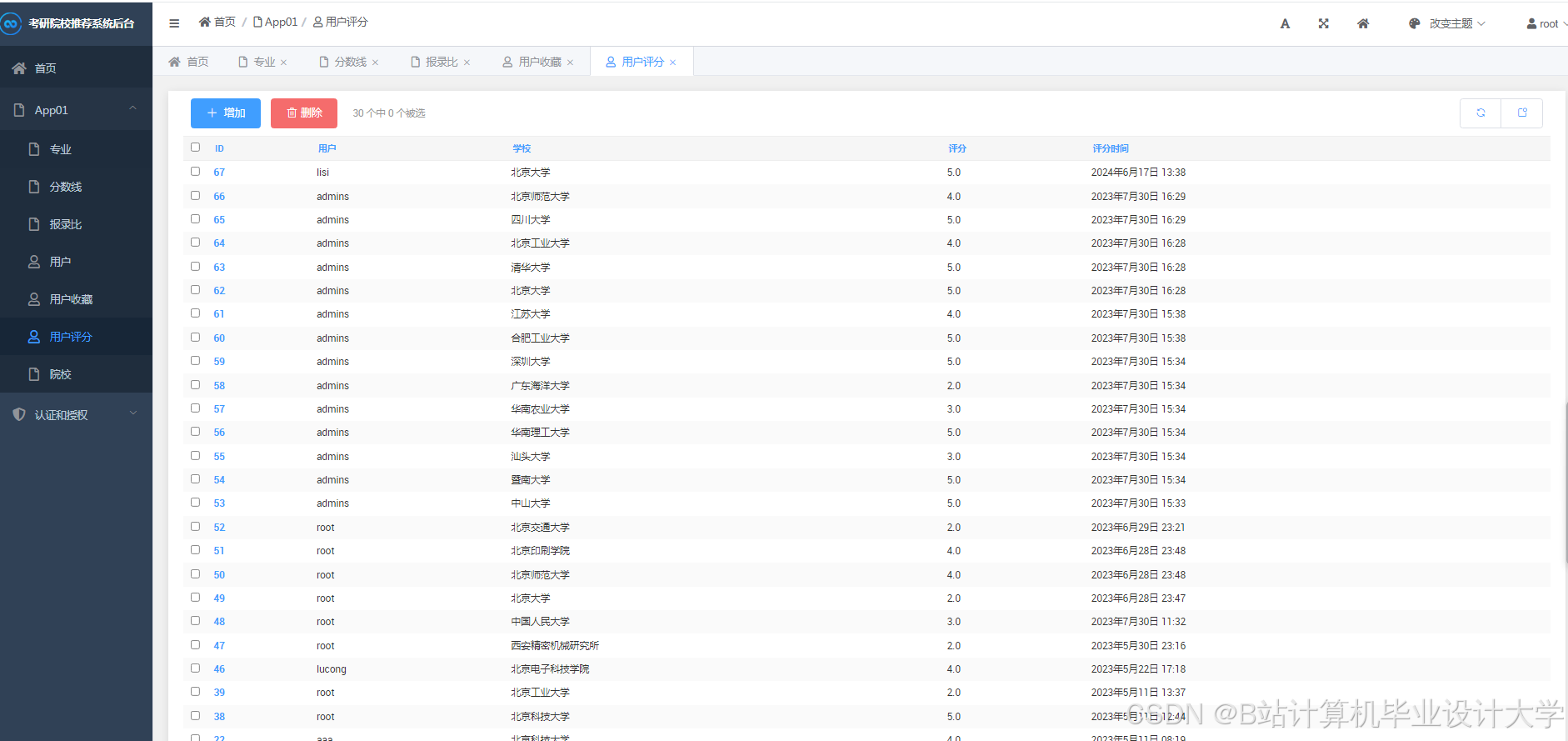
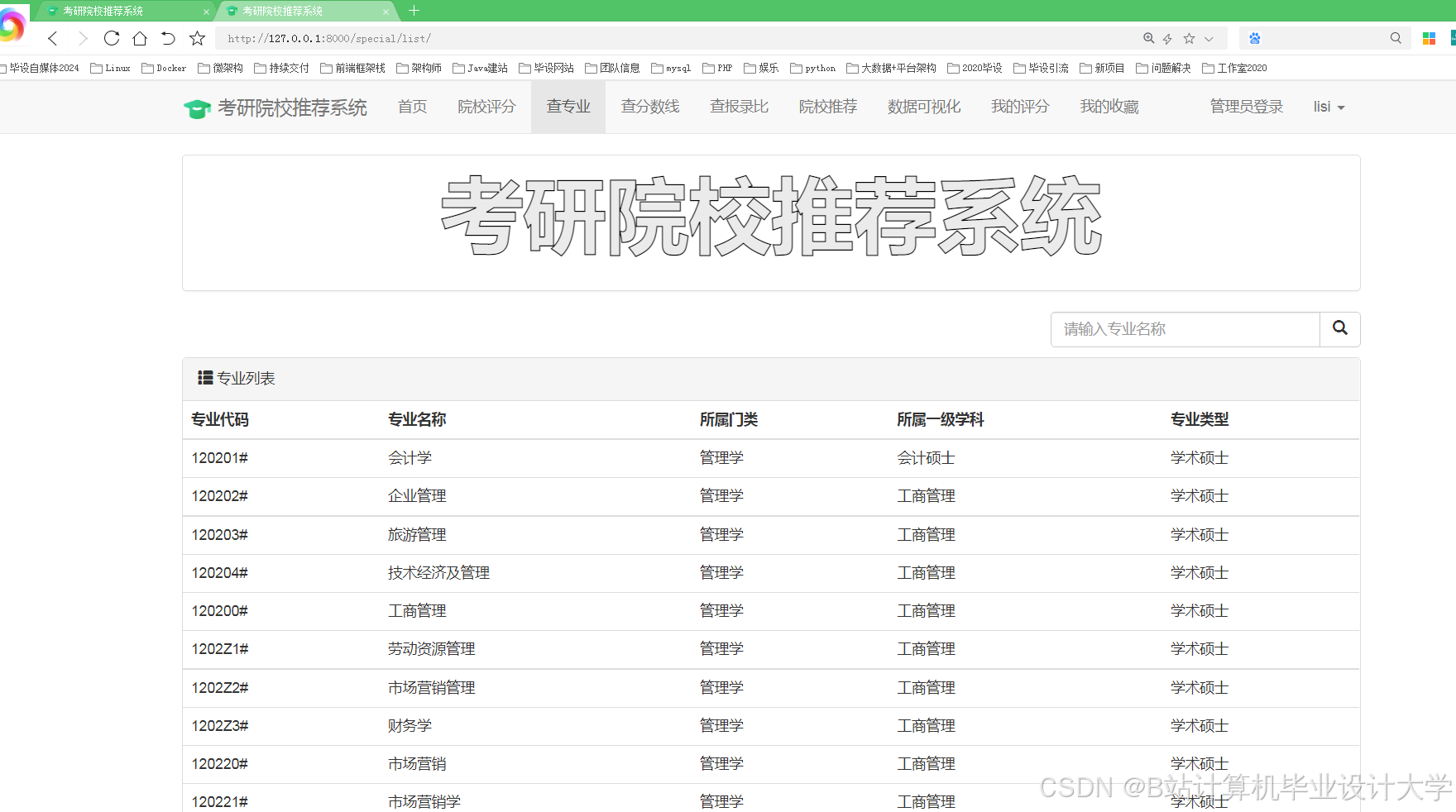
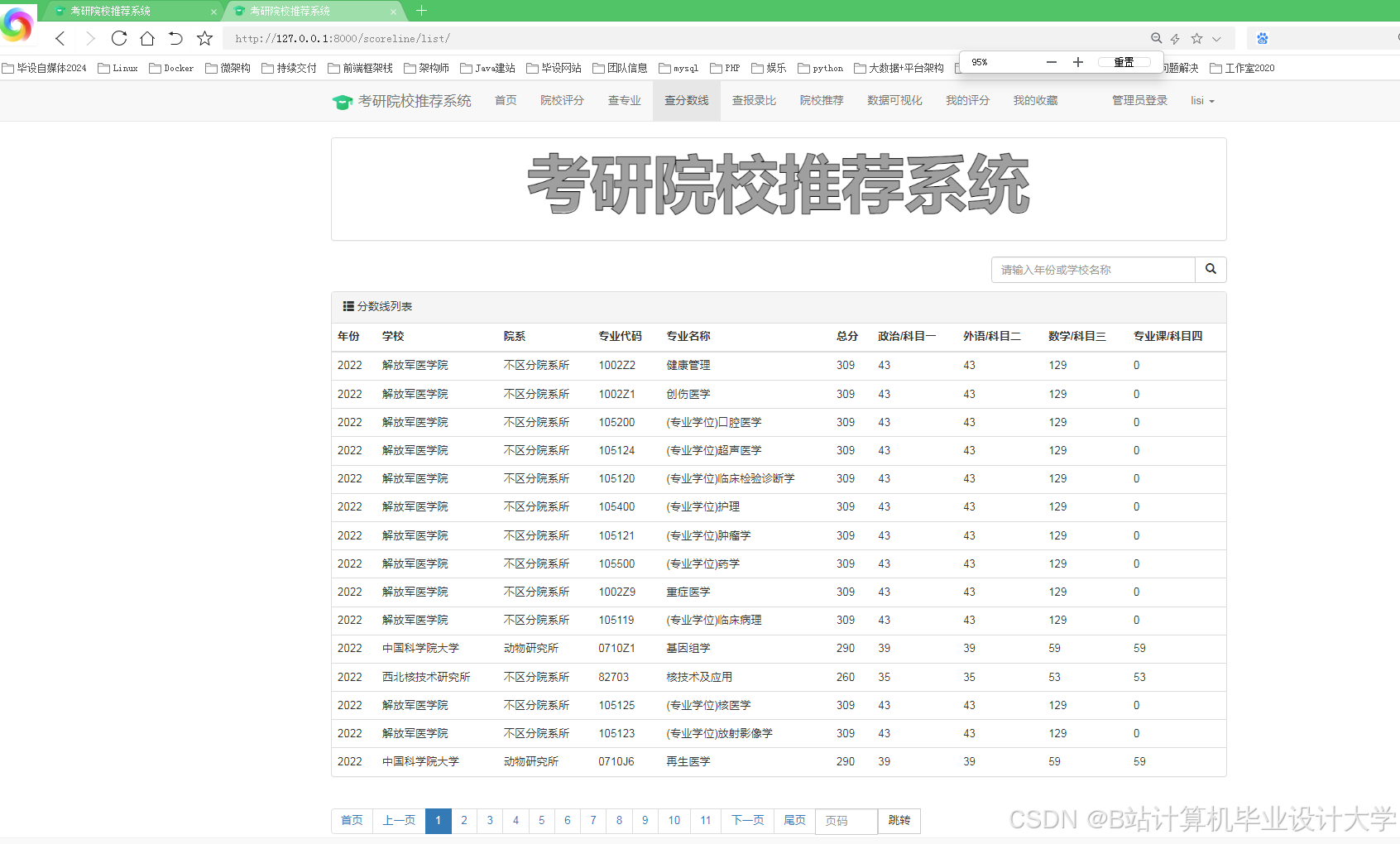
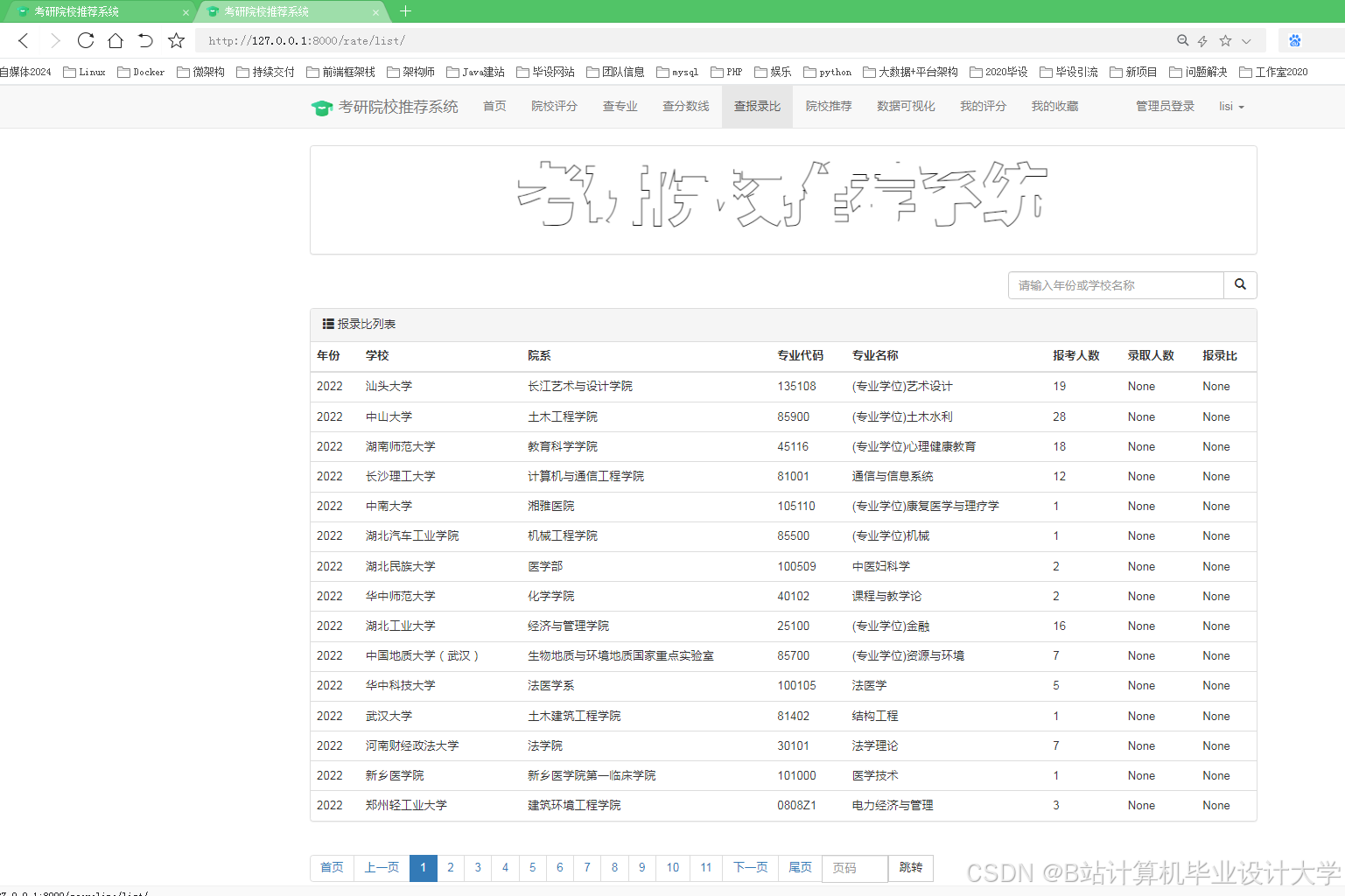
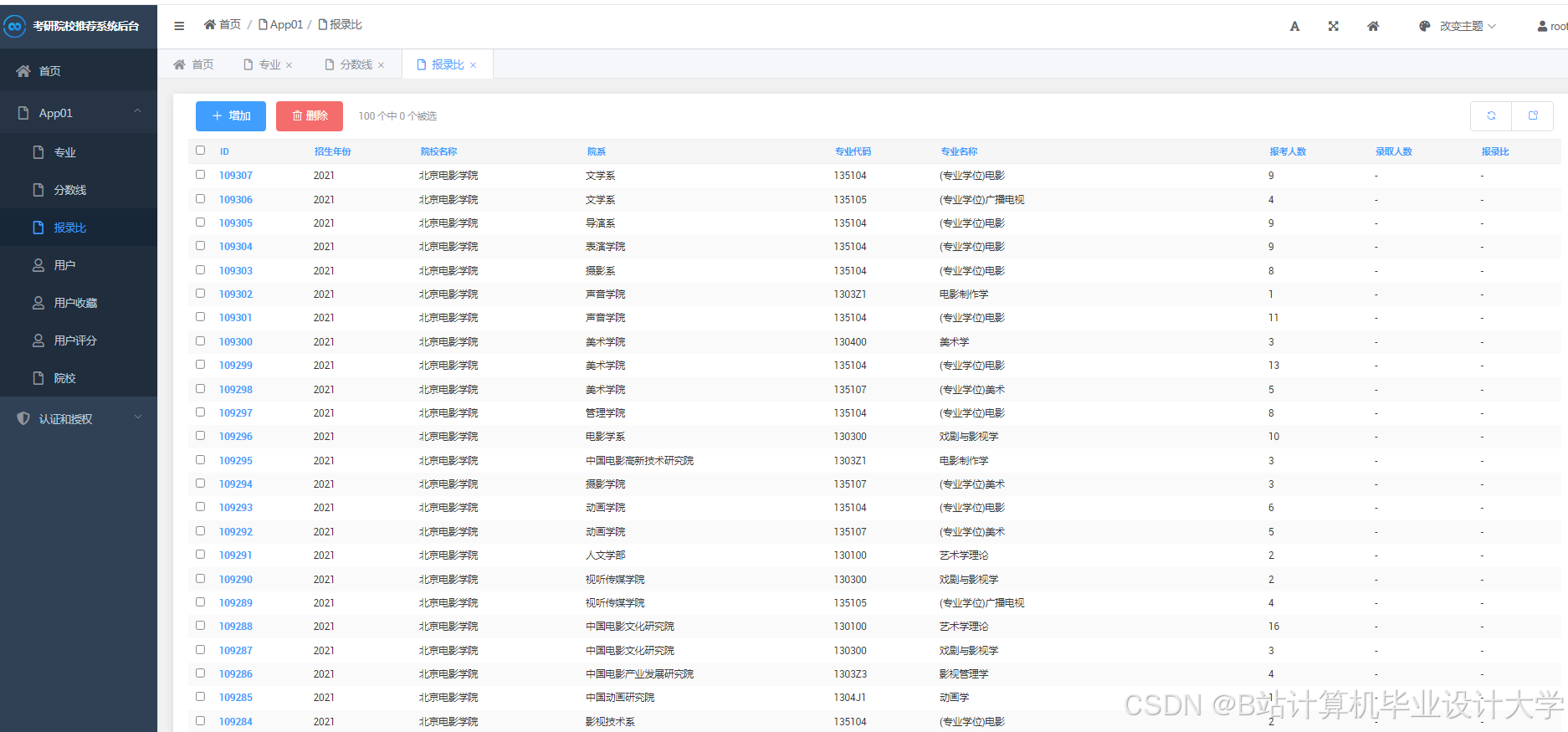
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 1892
1892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











