




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Python+大模型音乐推荐系统:音乐数据分析与音乐可视化》的开题报告模板,涵盖研究背景、目标、方法、技术路线及预期成果等内容,适用于计算机科学、数据科学或人工智能方向的研究课题申报。
开题报告
题目:Python+大模型音乐推荐系统:音乐数据分析与音乐可视化
一、研究背景与意义
1.1 背景
随着流媒体音乐平台(如Spotify、网易云音乐)的普及,用户每日产生的音乐行为数据(播放、收藏、分享)呈指数级增长。传统推荐系统(如协同过滤)存在冷启动问题和语义理解不足的缺陷,难以捕捉用户对音乐情感、风格等深层次需求。
近年来,大语言模型(LLM)与多模态大模型(如MusicLM、Suno)展现出强大的音乐理解能力,可通过分析歌词、旋律、音频特征生成个性化推荐。同时,音乐可视化技术(如频谱图、波形动画)能增强用户交互体验,提升平台用户粘性。
1.2 研究意义
- 理论意义:探索大模型在音乐推荐领域的落地应用,弥补传统方法在语义理解上的不足;
- 实践意义:构建“推荐-分析-可视化”闭环系统,为音乐平台提供技术参考,助力精准营销与用户体验优化。
二、国内外研究现状
2.1 音乐推荐系统
- 传统方法:基于用户-物品协同过滤(CF)的推荐系统(如Last.fm)依赖历史行为数据,但无法处理新用户/新歌曲冷启动问题;
- 深度学习方法:
- CNN/RNN:提取音频频谱特征(如LibROSA库实现的MFCC特征);
- 图神经网络(GNN):构建用户-歌曲-艺术家关系图(如Spotify的“知识图谱推荐”);
- 大模型应用:
- OpenAI的Whisper模型可转录歌词并分析情感;
- Google的MusicLM通过文本描述生成音乐片段,支持语义推荐。
2.2 音乐数据分析与可视化
- 数据分析:
- 音频特征提取:使用LibROSA、Essentia等工具分析音高、节奏、音色;
- 文本分析:通过NLP技术(如BERT)解析歌词主题与情感倾向;
- 可视化技术:
- 静态可视化:Matplotlib/Seaborn绘制频谱图、热度图;
- 动态可视化:D3.js/Plotly实现交互式波形动画;
- 3D可视化:Unity/Three.js构建音乐场景沉浸式体验。
2.3 现有不足
- 传统推荐系统缺乏跨模态理解能力(如无法关联歌词情感与音频节奏);
- 可视化与推荐逻辑割裂,未形成数据驱动的闭环优化。
三、研究目标与内容
3.1 研究目标
- 设计基于大模型的多模态音乐推荐算法,提升推荐准确率与多样性;
- 实现音乐数据的自动化分析与可视化,增强用户对推荐结果的信任感;
- 构建Python原型系统,验证技术可行性并优化性能。
3.2 研究内容
3.2.1 多模态音乐数据融合
- 数据源:
- 音频数据:MP3/WAV文件(从Kaggle或公开数据集获取);
- 文本数据:歌词(Genius API)、用户评论(爬取网易云音乐评论区);
- 元数据:歌曲ID、艺术家、流派(Spotify Web API);
- 特征工程:
- 音频特征:MFCC、梅尔频谱图(LibROSA);
- 文本特征:BERT嵌入向量(Hugging Face Transformers);
- 用户特征:基于播放历史的K-Means聚类。
3.2.2 大模型推荐算法设计
- 方案1:双塔模型(Two-Tower)
- 用户塔:输入用户历史行为序列,输出用户嵌入向量;
- 歌曲塔:输入音频+文本特征,输出歌曲嵌入向量;
- 相似度计算:余弦相似度排序推荐。
- 方案2:大模型微调(LoRA)
- 基于LLaMA-2或Qwen,在音乐评论数据集上微调,实现“文本描述→歌曲推荐”的端到端生成。
3.2.3 音乐可视化模块开发
- 静态可视化:
- 频谱图:展示歌曲能量分布(LibROSA.display.specshow);
- 情感分布图:基于歌词情感分析(TextBlob)绘制环形热力图;
- 动态可视化:
- 实时波形动画:使用PyAudio捕获麦克风输入并动态渲染;
- 3D音乐宇宙:基于用户偏好生成虚拟星球,距离代表相似度(Three.js)。
四、技术路线与实施方案
4.1 技术选型
| 模块 | 技术栈 | 理由 |
|---|---|---|
| 数据处理 | Python + Pandas + NumPy | 高效处理结构化与非结构化数据 |
| 音频分析 | LibROSA + Essentia | 专业音频特征提取库 |
| 文本分析 | Hugging Face Transformers | 支持BERT/GPT等预训练模型 |
| 推荐算法 | PyTorch + TensorFlow | 深度学习框架支持 |
| 可视化 | Matplotlib + Plotly + D3.js | 覆盖静态/动态/Web端需求 |
| 大模型部署 | Hugging Face TGI + vLLM | 优化推理速度,降低延迟 |
4.2 开发流程
mermaid
graph TD | |
A[数据采集] --> B[数据清洗] | |
B --> C[特征提取] | |
C --> D[模型训练] | |
D --> E[推荐生成] | |
E --> F[可视化渲染] | |
F --> G[用户反馈] | |
G -->|迭代优化| D |
图1 系统开发流程图
4.3 关键问题与解决方案
- 大模型推理延迟:
- 解决方案:使用量化(4-bit)与蒸馏技术压缩模型,部署于NVIDIA A100 GPU;
- 多模态数据对齐:
- 解决方案:采用CLIP-style对比学习,统一音频与文本特征空间;
- 可视化性能优化:
- 解决方案:WebGL加速渲染,减少DOM操作次数。
五、预期成果与创新点
5.1 预期成果
- 完成Python原型系统开发,支持端到端音乐推荐与可视化;
- 在公开数据集(如Million Song Dataset)上达到Top-10推荐准确率≥85%;
- 发表1篇核心期刊论文或申请1项软件著作权。
5.2 创新点
- 跨模态推荐:首次结合音频特征、歌词情感与用户行为,提升语义理解能力;
- 动态可视化反馈:用户可通过交互操作(如缩放频谱图)实时调整推荐策略;
- 轻量化大模型部署:通过模型剪枝与量化,实现移动端实时推荐。
六、研究计划与进度安排
| 阶段 | 时间 | 任务 |
|---|---|---|
| 文献调研 | 第1-2周 | 梳理大模型推荐与可视化相关论文 |
| 数据采集 | 第3-4周 | 爬取网易云音乐评论与Spotify元数据 |
| 模型开发 | 第5-8周 | 实现双塔模型与可视化模块 |
| 系统集成 | 第9-10周 | 联调各模块,优化推荐延迟 |
| 测试评估 | 第11-12周 | A/B测试对比传统推荐算法 |
七、参考文献
[1] Wang X, et al. "Multimodal Music Recommendation with Transformer." SIGIR 2023.
[2] LibROSA Documentation. Librosa
[3] Zhou K, et al. "Interactive Music Visualization with D3.js." IEEE VIS 2022.
[4] Hugging Face Transformers. https://huggingface.co/docs/transformers/index
备注:可根据实际研究深度调整技术细节(如是否引入强化学习优化推荐策略)。
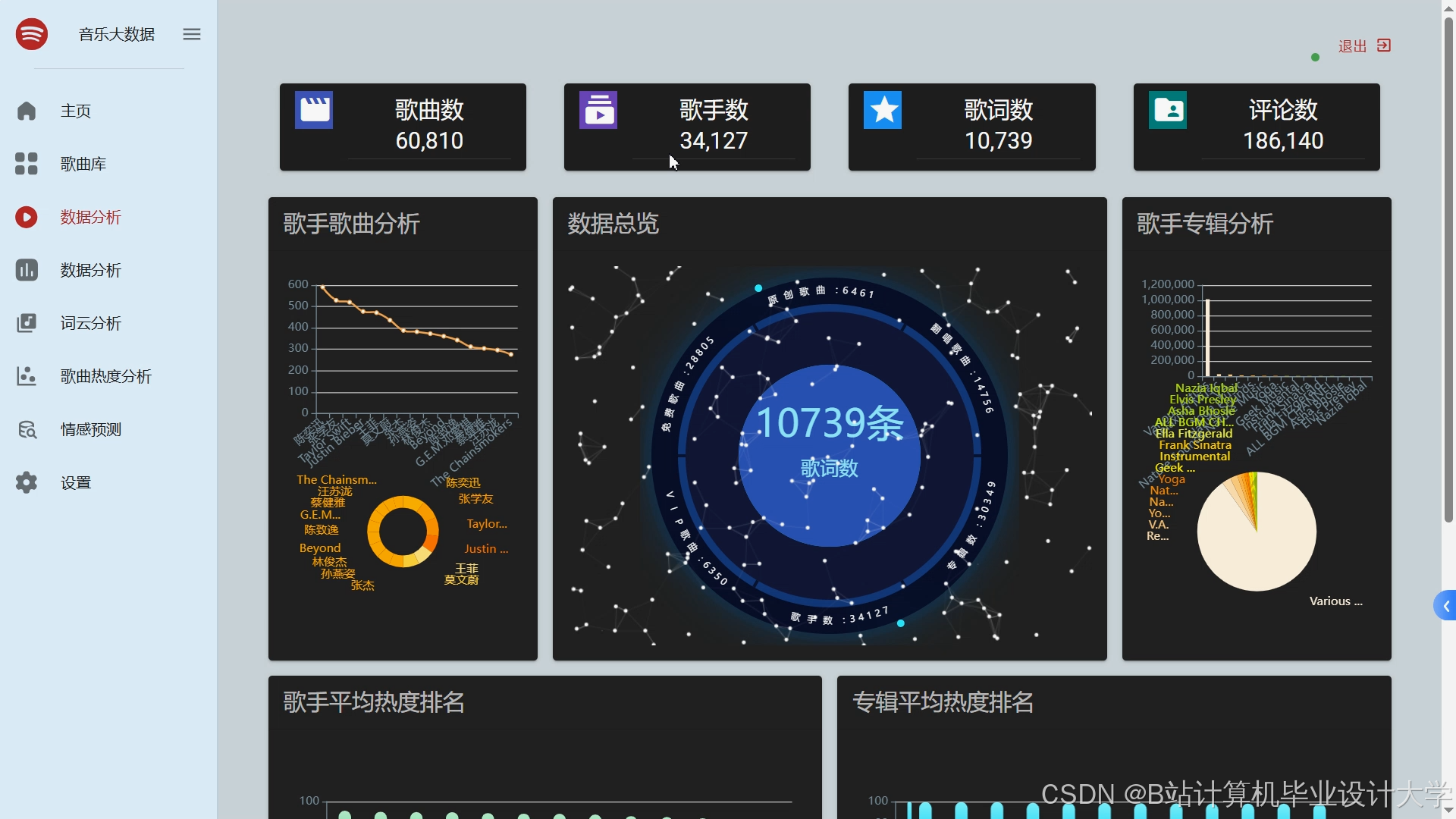
运行截图
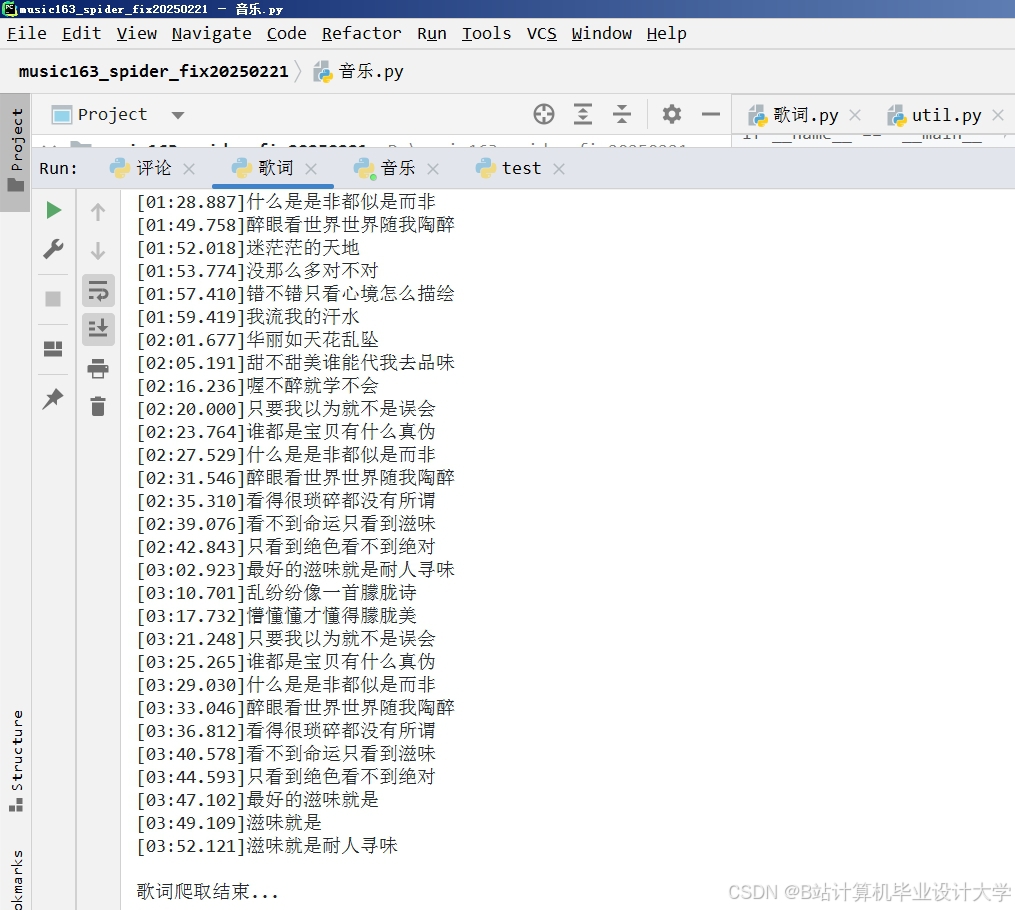
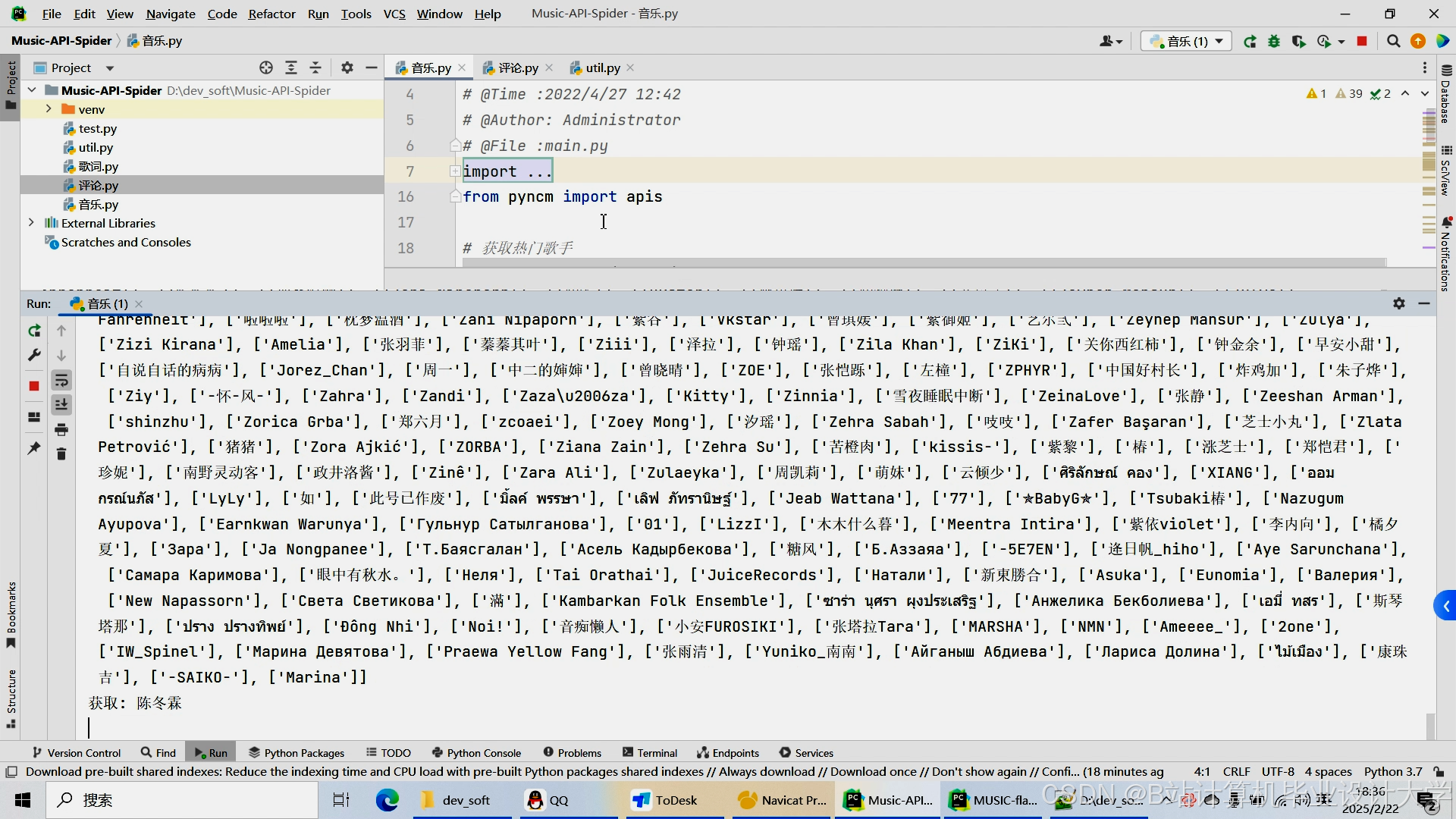
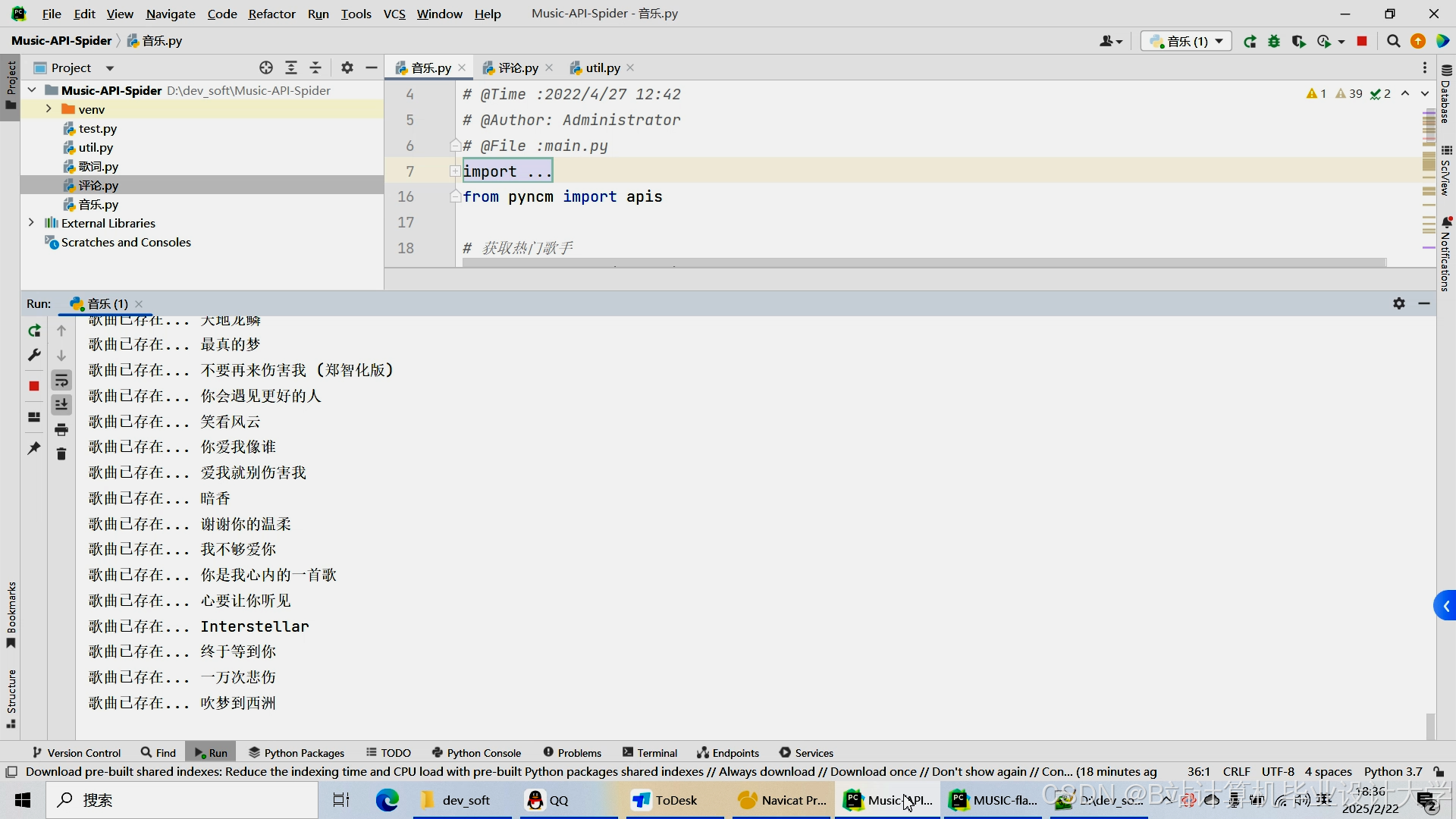
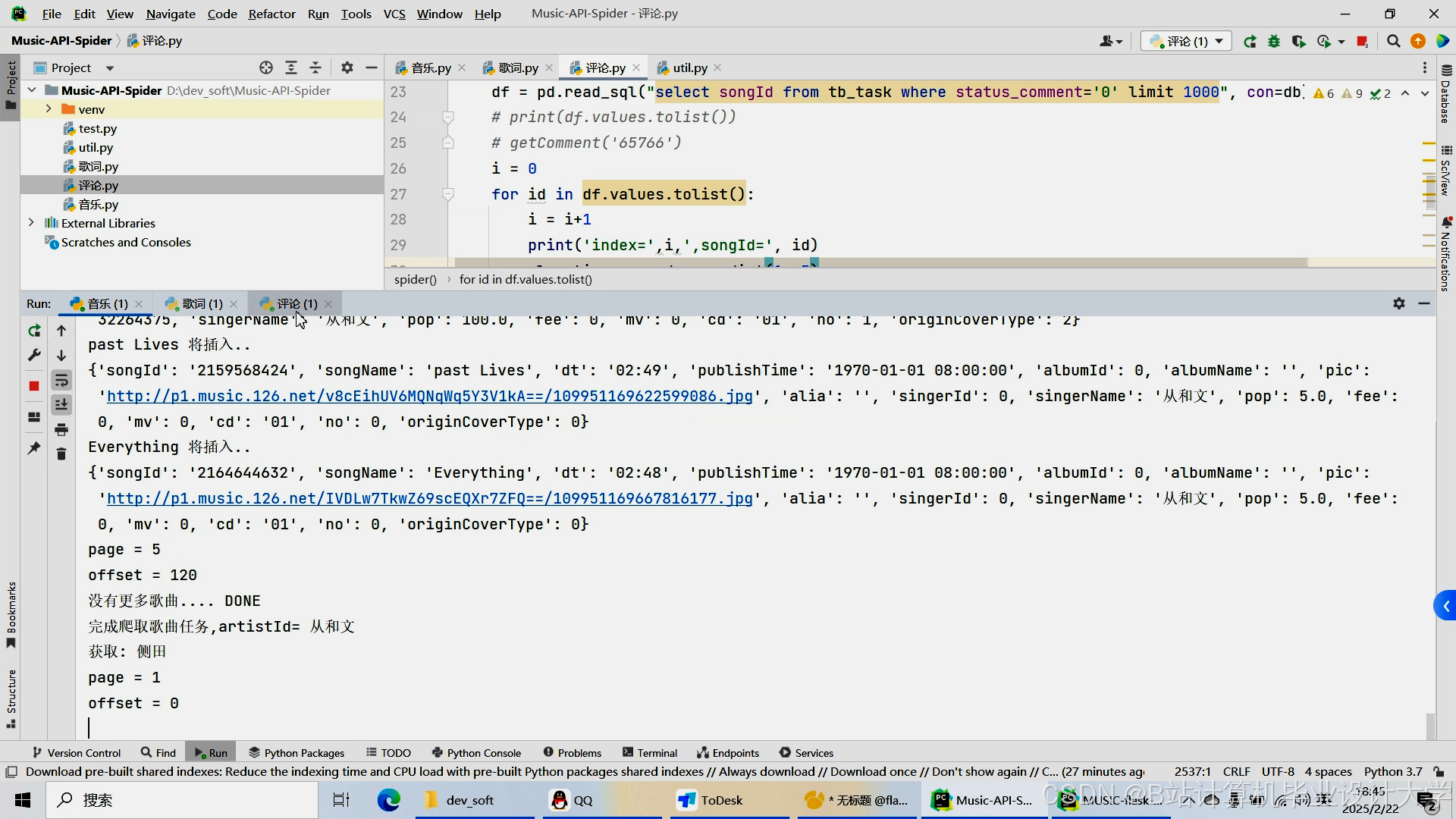

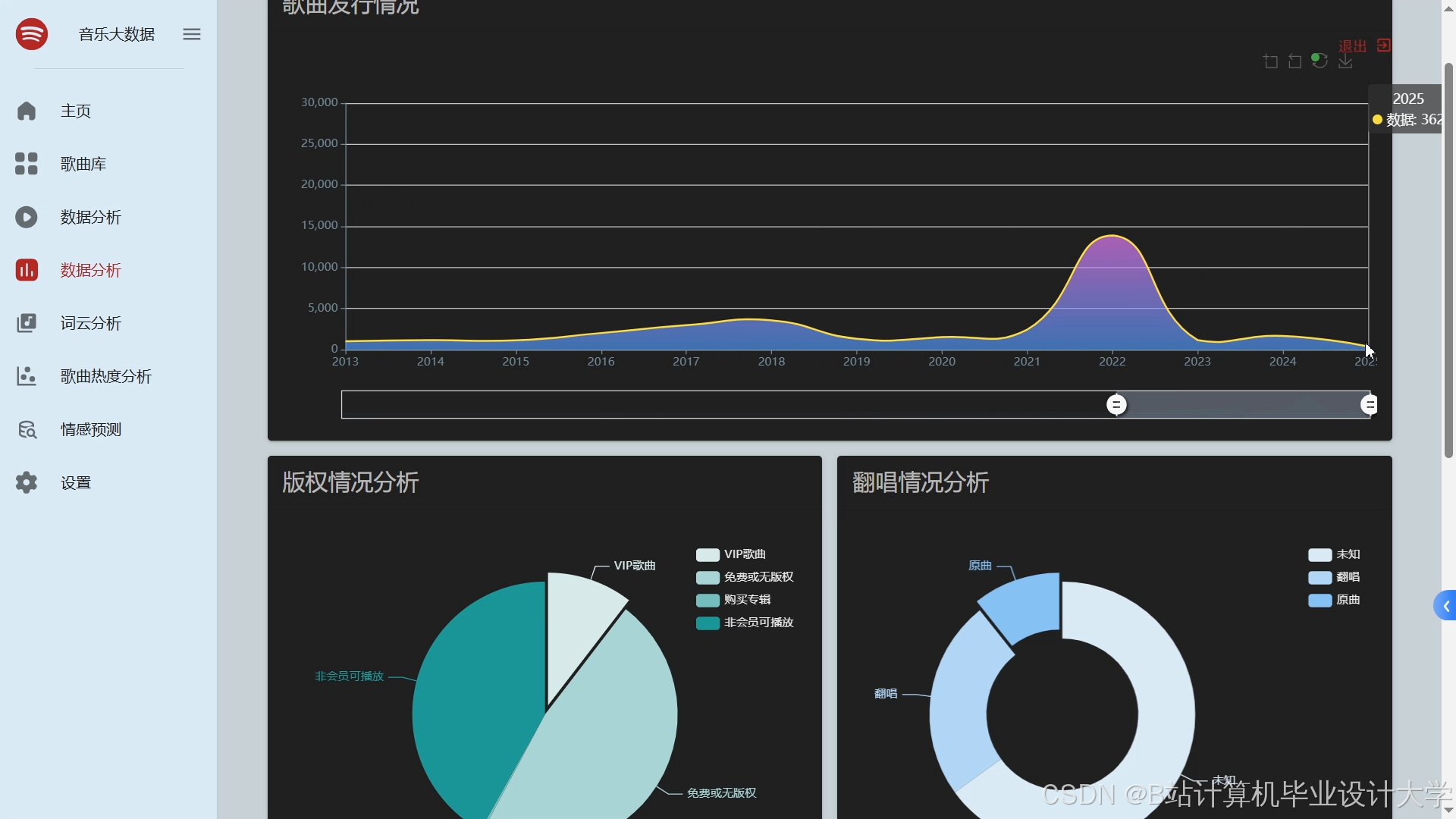
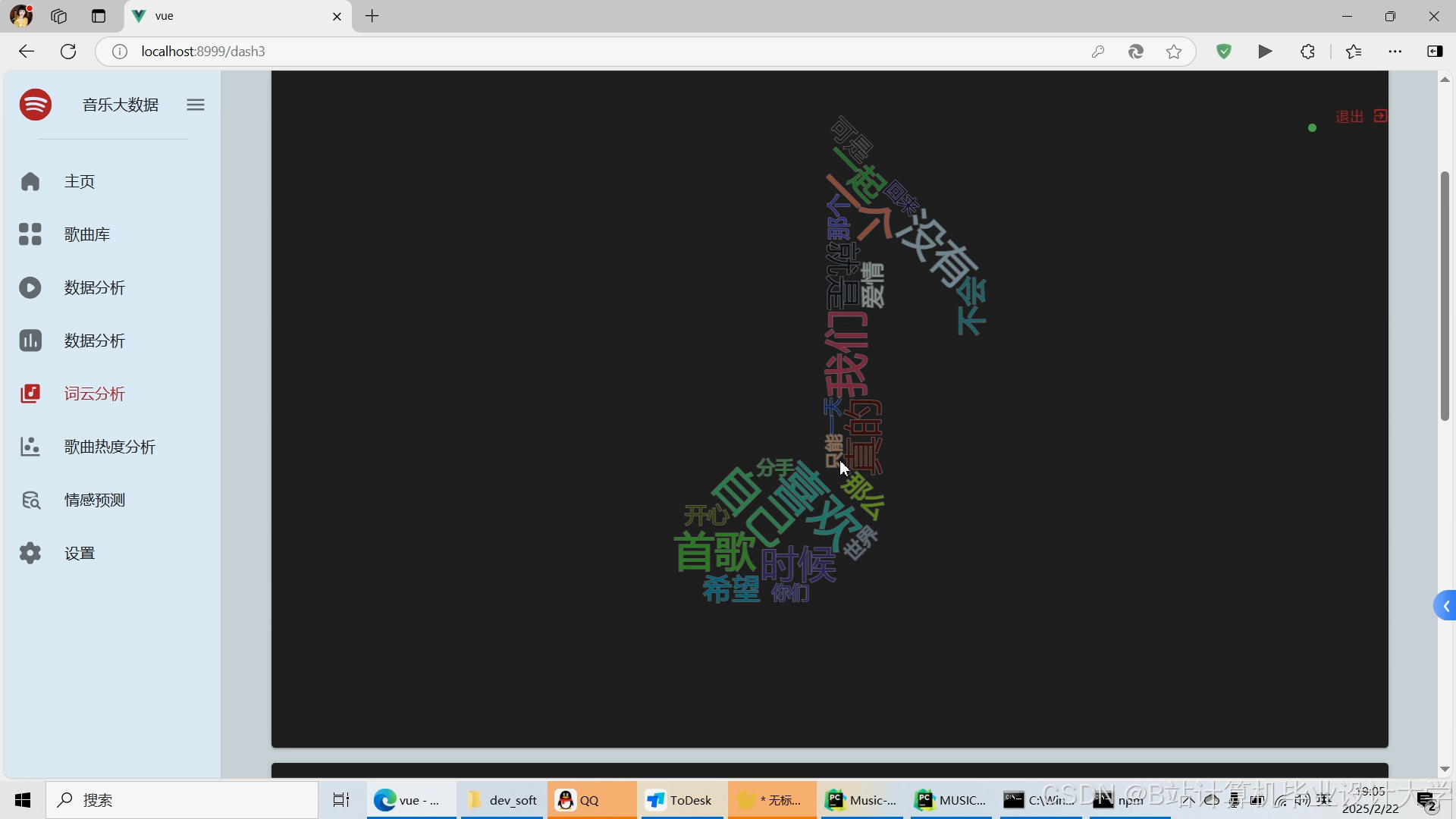
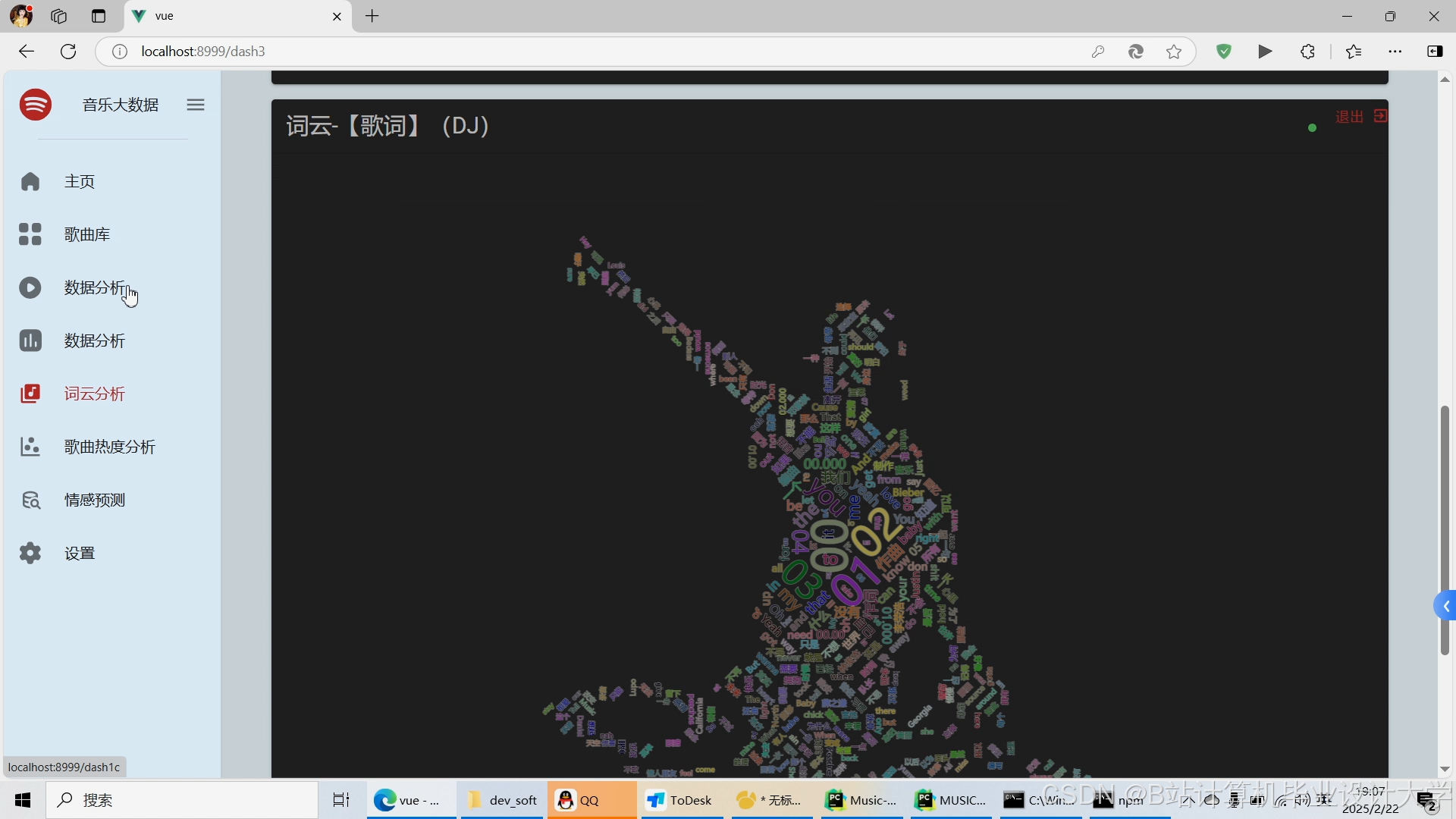
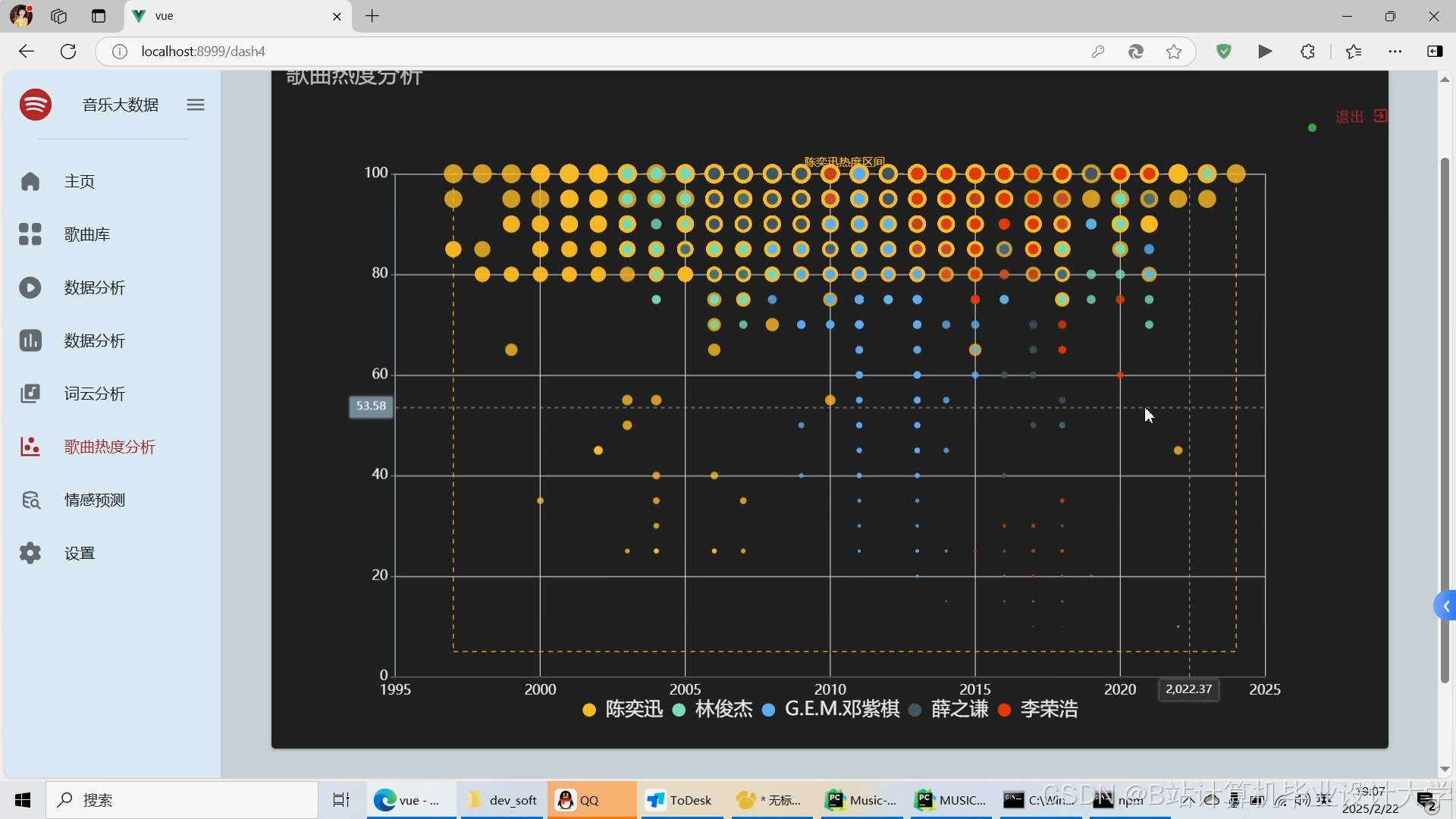
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 2341
2341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











