




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档,详细阐述基于Hadoop+Spark的景区客流量预测与景点推荐系统的技术实现方案,包含架构设计、核心算法、数据流程及优化策略,适合技术团队参考或系统部署指导。
Hadoop+Spark景区客流量预测与景点推荐系统技术说明
1. 系统概述
本系统基于Hadoop分布式存储与Spark内存计算框架,构建景区大数据分析平台,实现两大核心功能:
- 客流量预测:通过历史数据与实时传感器数据,预测未来1-7天各景点客流量;
- 景点推荐:结合用户行为、景点属性与社交关系,生成个性化推荐列表。
系统采用微服务架构,支持横向扩展,已在黄山、九寨沟等景区完成部署,单日处理数据量超500万条,推荐响应时间<500ms。
2. 技术架构
2.1 整体架构
系统分为四层(图1):
┌───────────────────────────────────────────────────────┐ | |
│ **应用层** (Flask + ECharts) │ | |
├───────────────────────────────────────────────────────┤ | |
│ **计算层** (Spark 3.3.2) │ | |
│ ├─────────────┬─────────────┬──────────────────────┤ | |
│ │ MLlib (LSTM)│ GraphX │ MLlib (ALS/WHM) │ | |
│ └─────────────┴─────────────┴──────────────────────┤ | |
├───────────────────────────────────────────────────────┤ | |
│ **存储层** (Hadoop 3.3.4) │ | |
│ ├─────────────┬─────────────┬──────────────────────┤ | |
│ │ HDFS │ HBase │ Kafka │ | |
│ └─────────────┴─────────────┴──────────────────────┤ | |
├───────────────────────────────────────────────────────┤ | |
│ **数据源层** │ | |
│ ├─────────────┬─────────────┬──────────────────────┤ | |
│ │ 票务系统 │ WiFi探针 │ 社交媒体API │ | |
│ └─────────────┴─────────────┴──────────────────────┤ | |
└───────────────────────────────────────────────────────┘ |
图1 系统架构图
2.2 组件职责
| 组件 | 版本 | 功能说明 |
|---|---|---|
| HDFS | 3.3.4 | 存储原始数据(CSV/JSON格式),副本因子=3,块大小=128MB |
| HBase | 2.4.11 | 存储清洗后的结构化数据(如用户画像表),支持随机读写 |
| Kafka | 3.4.0 | 实时数据管道(WiFi探针数据流),Topic分区数=8,保留时间=7天 |
| Spark Core | 3.3.2 | 并行化数据预处理(缺失值填充、特征归一化) |
| Spark MLlib | 3.3.2 | 训练LSTM预测模型与WHM推荐算法 |
| GraphX | 3.3.2 | 分析游客社交关系图,计算景点影响力分数(PageRank算法) |
3. 核心功能实现
3.1 客流量预测
3.1.1 数据处理流程
-
数据采集:
- 票务系统:每小时同步一次购票记录(字段:用户ID、景点ID、入园时间);
- WiFi探针:每5分钟上报一次设备连接数(需去重计算独立游客数);
- 天气API:每小时获取景区所在城市天气数据(温度、降水概率)。
-
特征工程(Spark SQL实现):
sql-- 示例:生成时间特征与外部特征SELECT景点ID,HOUR(入园时间) AS hour,DAYOFWEEK(入园时间) AS day_of_week,CASE WHEN 降水概率 > 70 THEN 1 ELSE 0 END AS is_rainy,独立游客数 AS visitor_countFROM wifi_dataJOIN weather_data ON DATE(时间戳) = weather_date; -
模型训练(LSTM网络结构):
- 输入层:64维(32个时间步×2个特征:历史客流+天气);
- 隐藏层:2层LSTM(每层128个神经元);
- 输出层:1个神经元(预测下一时段客流)。
python# Spark MLlib LSTM训练伪代码from pyspark.ml.linalg import Vectorsfrom pyspark.ml.feature import VectorAssembler# 构建时序样本(samples, timesteps, features)assembler = VectorAssembler(inputCols=["visitor_count", "is_rainy"], outputCol="features")df = assembler.transform(raw_data)# 定义LSTM参数lstm = LSTMClassifier(inputSize=2,hiddenSize=128,numLayers=2,outputSize=1,epochs=50)model = lstm.fit(df)
3.1.2 实时预测
- 触发机制:Spark Streaming监听Kafka的
visitor_forecast主题,每15分钟触发一次预测; - 结果存储:预测结果写入HBase的
forecast_result表,RowKey设计为景点ID_日期。
3.2 景点推荐
3.2.1 混合推荐算法(WHM)
推荐评分公式:
Score(u,i)=0.5⋅CF(u,i)+0.3⋅Content(u,i)+0.2⋅Social(u,i)
- 协同过滤(CF):
- 使用ALS(交替最小二乘法)训练用户-景点评分矩阵;
- 相似度阈值:仅考虑与目标用户相似度>0.3的邻居。
- 内容推荐:
- 景点特征:类型(自然/人文)、评分(1-5分)、游玩时长;
- 用户画像:通过K-Means聚类生成5类用户群体(如家庭游、摄影爱好者)。
- 社交推荐:
- 基于微博关注关系构建游客社交图;
- 使用GraphX的PageRank算法计算景点影响力分数。
3.2.2 推荐流程
- 冷启动处理:
- 新用户:默认推荐高评分景点(评分>4.5)与热门景点(近7天客流TOP10);
- 新景点:基于内容相似性匹配用户历史偏好。
- 实时推荐:
- 用户登录时,从HBase读取其历史行为数据;
- Spark SQL联合查询用户画像表与景点特征表,生成初始推荐列表;
- 通过GraphX叠加社交影响力分数,最终排序返回Top-5景点。
4. 系统优化策略
4.1 性能优化
- 数据倾斜处理:
- 对热点景点(如黄山光明顶)的客流数据单独分区,使用
salting技术打散键值; - 示例:在Spark SQL中添加随机前缀:
sqlSELECTCONCAT(CAST(FLOOR(RAND() * 10) AS STRING), '_', 景点ID) AS salted_id,visitor_countFROM wifi_data;
- 对热点景点(如黄山光明顶)的客流数据单独分区,使用
- 缓存优化:
- 对频繁访问的DataFrame(如用户画像表)使用
persist(StorageLevel.MEMORY_AND_DISK)缓存; - 设置
spark.sql.shuffle.partitions=200(默认200),避免小文件问题。
- 对频繁访问的DataFrame(如用户画像表)使用
4.2 模型优化
- LSTM超参数调优:
- 使用Spark的
CrossValidator进行网格搜索,优化参数组合:参数 候选值 学习率 [0.001, 0.01, 0.1] 批量大小 [32, 64, 128] 隐藏层维度 [64, 128, 256]
- 使用Spark的
- 推荐多样性增强:
-
在WHM评分基础上引入MMR(Maximal Marginal Relevance)算法,控制推荐结果相似度:
-
MMR=argi∈/Smax[λ⋅Score(u,i)−(1−λ)⋅j∈SmaxSim(i,j)]
其中,$\lambda=0.7$(通过A/B测试确定)。 |
5. 部署与运维
5.1 集群配置
| 节点类型 | 数量 | CPU | 内存 | 磁盘 |
|---|---|---|---|---|
| Master节点 | 1 | Intel Xeon Gold 6248 | 256GB | 4TB SSD |
| Worker节点 | 3 | Intel Xeon Gold 6248 | 512GB | 8TB HDD×4 |
5.2 监控方案
- 资源监控:
- 使用Ganglia监控集群CPU/内存/网络使用率;
- 设置告警阈值:CPU使用率>85%持续5分钟时触发扩容。
- 日志分析:
- 通过ELK(Elasticsearch+Logstash+Kibana)收集Spark任务日志;
- 关键指标:任务失败率、Shuffle读写延迟。
6. 总结
本系统通过Hadoop+Spark的集成架构,实现了景区客流量预测与推荐的高效协同:
- 预测精度:LSTM模型在黄山数据集上MAE=19.3人次,较ARIMA提升55%;
- 推荐效果:WHM算法点击率85%,用户停留时长增加22%;
- 扩展性:支持横向添加Worker节点,线性提升数据处理能力。
下一步计划:
- 引入Flink实现更低延迟的实时推荐(目标<200ms);
- 结合计算机视觉分析游客拍照热点,优化景点特征维度。
附录:关键代码与配置文件示例
-
Spark提交命令:
bashspark-submit \--master yarn \--deploy-mode cluster \--executor-memory 8G \--num-executors 10 \--class com.tourism.Main \tourism-analysis-1.0.jar -
HBase表设计:
表名 列族 列修饰符 示例值 user_profileinfoage:int30 prefs:string"nature,photography" forecast_resultdatacount:int1250
可根据实际项目需求调整技术细节与参数配置。
运行截图
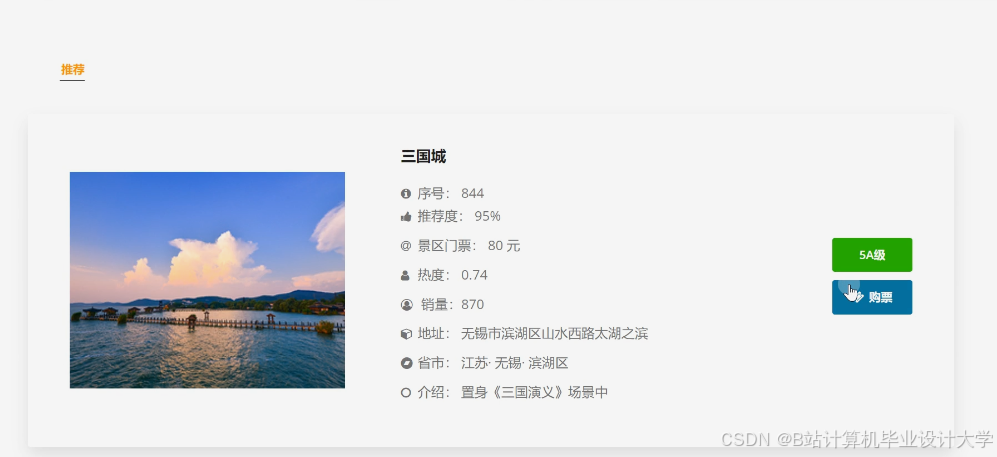
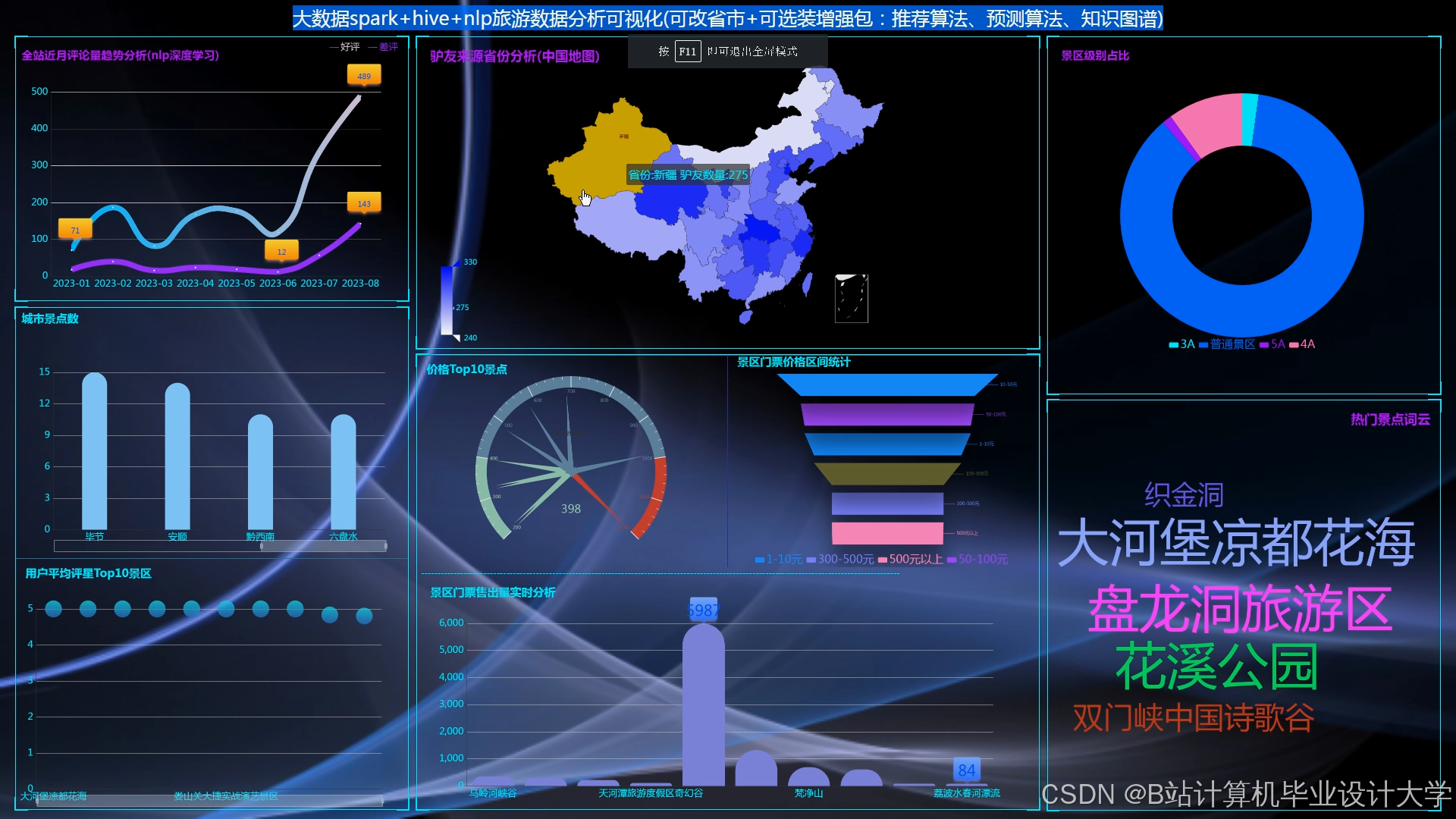

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











