




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Hadoop+Spark+Hive新能源汽车推荐系统》的技术说明文档,涵盖系统架构、技术选型、核心模块实现及优化策略,供参考:
技术说明:基于Hadoop+Spark+Hive的新能源汽车推荐系统
1. 系统背景与目标
新能源汽车(NEV)市场快速发展,用户选车时需综合考虑续航、充电便利性、价格、政策补贴等多维度因素。传统推荐系统受限于单机计算能力和数据孤岛问题,难以处理海量异构数据(如用户行为日志、车辆参数、充电桩分布等)。本系统基于Hadoop生态(HDFS+Hive)提供分布式存储与数据仓库能力,结合Spark内存计算加速推荐模型训练,实现以下目标:
- 支持PB级多源数据的高效存储与查询;
- 实现用户画像构建、车辆特征提取、推荐算法训练的全流程分布式处理;
- 支持实时推荐(秒级响应)与离线批量推荐(低延迟更新)。
2. 系统架构设计
系统采用分层架构,分为数据层、计算层、服务层,核心组件及交互流程如下:
┌───────────────────────────────────────────────────────────────┐ | |
│ 服务层(Service) │ | |
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ 实时推荐API │◀───▶│ 离线推荐API │◀───▶│ 用户反馈接口 │ │ | |
│ └─────────────┘ └─────────────┘ └─────────────┘ │ | |
└─────────────────┬─────────────────┬─────────────────┬─────────┘ | |
│ │ │ | |
┌─────────────────▼─────────────────▼─────────────────▼─────────┐ | |
│ 计算层(Compute) │ | |
│ ┌───────────────────────────────────────────────────────────┐ │ | |
│ │ Spark集群(Batch/Streaming) │ │ | |
│ │ - 离线任务:用户画像构建、ALS模型训练、特征工程 │ │ | |
│ │ - 实时任务:用户行为流处理、推荐结果增量更新 │ │ | |
│ └───────────────────────────────────────────────────────────┘ │ | |
└─────────────────┬─────────────────────────────────────────────┘ | |
│ | |
┌─────────────────▼─────────────────────────────────────────────┐ | |
│ 数据层(Storage) │ | |
│ ┌─────────────────┐ ┌─────────────────┐ ┌───────────┐ │ | |
│ │ HDFS(分布式存储)│◀──▶│ Hive(数据仓库) │◀──▶│ 外部数据源│ │ | |
│ │ - 原始数据:日志、│ │ - 结构化数据: │ │ (充电桩API│ │ | |
│ │ 车辆参数、用户 │ │ 用户画像、车辆 │ │ 政策补贴)│ │ | |
│ │ 信息等 │ │ 特征表等 │ └───────────┘ │ | |
│ └─────────────────┘ └─────────────────┘ │ | |
└───────────────────────────────────────────────────────────────┘ |
3. 核心模块实现
3.1 数据层:HDFS+Hive存储与预处理
3.1.1 数据存储设计
- HDFS存储原始数据:
- 用户行为日志(JSON格式):存储于
/raw_data/user_behavior/{date}/,按日期分区。 - 车辆参数(CSV格式):存储于
/raw_data/vehicle_specs/,包含续航、价格、快充时间等字段。 - 外部数据(如充电桩分布):通过Sqoop定期同步至HDFS。
- 用户行为日志(JSON格式):存储于
- Hive数据仓库构建:
创建外部表映射HDFS数据,示例DDL如下:sqlCREATE EXTERNAL TABLE user_behavior (user_id STRING,vehicle_id STRING,action_type STRING, -- 浏览/点击/购买timestamp BIGINT,duration INT -- 浏览时长(秒)) PARTITIONED BY (dt STRING)STORED AS PARQUETLOCATION '/raw_data/user_behavior';
3.1.2 数据清洗与特征提取
-
Hive SQL预处理:
sql-- 统计用户对不同车型的点击次数INSERT OVERWRITE TABLE user_click_statsSELECTuser_id,vehicle_id,COUNT(*) as click_countFROM user_behaviorWHERE action_type = 'click' AND dt = '2023-10-01'GROUP BY user_id, vehicle_id; -
UDF函数扩展:
通过Hive UDF解析用户评论文本情感,生成“舒适性”“性价比”等标签,示例代码(Java):javapublic class SentimentAnalyzer extends UDF {public String evaluate(String comment) {// 调用NLP模型(如SnowNLP)返回情感标签return NLPModel.analyze(comment).getLabel();}}
3.2 计算层:Spark推荐算法实现
3.2.1 离线推荐(Batch Processing)
-
用户画像构建:
scala// 从Hive读取用户行为数据val userBehavior = spark.sql("SELECT * FROM user_behavior WHERE dt='2023-10-01'")// 计算用户偏好权重(示例:续航权重)val userPreferences = userBehavior.filter($"action_type" === "click").groupBy("user_id", "vehicle_id").agg(avg("battery_range").as("avg_range")) // 假设vehicle_specs已关联.join(vehicleSpecs, Seq("vehicle_id")).groupBy("user_id").pivot("feature_type", Seq("battery_range", "price")) // 特征类型转列.avg() // 计算各特征平均偏好 -
ALS协同过滤模型训练:
scalaimport org.apache.spark.ml.recommendation.ALSval ratings = spark.sql("SELECT user_id, vehicle_id, click_count as rating FROM user_click_stats")val als = new ALS().setMaxIter(10).setRank(50) // 潜在因子维度.setRegParam(0.01).setUserCol("user_id").setItemCol("vehicle_id").setRatingCol("rating")val model = als.fit(ratings)val userRecs = model.recommendForAllUsers(10) // 为每个用户推荐Top10车型
3.2.2 实时推荐(Streaming Processing)
- 用户行为流处理:
scalaimport org.apache.spark.streaming.{Seconds, StreamingContext}val ssc = new StreamingContext(spark.sparkContext, Seconds(5)) // 5秒微批次val kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Array("user_actions"), kafkaParams))kafkaStream.map(_.value()) // 解析JSON格式的用户行为.foreachRDD { rdd =>if (!rdd.isEmpty()) {val df = spark.createDataFrame(rdd.map(parseJson), schema)df.createOrReplaceTempView("realtime_actions")// 更新用户短期兴趣(如最近浏览的3款车型)spark.sql("""INSERT OVERWRITE TABLE user_recent_interestSELECT user_id, collect_list(vehicle_id)[0:3] as recent_vehiclesFROM realtime_actionsGROUP BY user_id""")}}ssc.start()
3.3 服务层:推荐结果暴露
-
离线推荐结果存储:
将Spark生成的推荐列表(userRecs)写入Hive表,并通过Redis缓存热点数据:scalauserRecs.write.saveAsTable("offline_recommendations") // Hive存储userRecs.rdd.foreachPartition { partition =>val redisClient = new RedisClient("localhost", 6379)partition.foreach { row =>redisClient.set(s"user:${row.getString(0)}:recs", row.getString(1))}} -
实时推荐API:
使用Spring Boot提供RESTful接口,示例代码:java@GetMapping("/recommend/{userId}")public ResponseEntity<List<Vehicle>> getRealtimeRecs(@PathVariable String userId) {// 从Redis获取实时推荐String recJson = redisTemplate.opsForValue().get("user:" + userId + ":recs");if (recJson != null) {return ResponseEntity.ok(parseRecs(recJson));} else {// 降级策略:返回离线推荐return ResponseEntity.ok(fallbackToOfflineRecs(userId));}}
4. 性能优化策略
4.1 数据层优化
- Hive分区与分桶:
对user_behavior表按dt(日期)和user_id哈希分桶,提升查询并行度。 - HDFS小文件合并:
通过hadoop archive -archiveName user_behavior.har -p /raw_data/user_behavior /output合并小文件,减少NameNode压力。
4.2 计算层优化
-
Spark参数调优:
bashspark-submit \--master yarn \--executor-memory 8G \--num-executors 20 \--conf spark.sql.shuffle.partitions=200 \ # 避免数据倾斜--conf spark.default.parallelism=200 \--jars hive-site.xml,mysql-connector.jar \--class com.example.RecommendationJob \recommendation-1.0.jar -
广播变量优化:
在ALS模型中广播小表(如车辆特征),减少Shuffle数据量:scalaval vehicleFeatures = spark.table("vehicle_specs").collect()val broadcastFeatures = spark.sparkContext.broadcast(vehicleFeatures.toMap)
4.3 实时性保障
- Lambda架构设计:
- 离线层(Spark Batch):每日全量更新用户画像和推荐模型;
- 实时层(Spark Streaming):处理5分钟内的用户行为,增量更新推荐结果;
- 服务层合并两层结果,优先返回实时数据。
5. 总结与展望
本系统通过Hadoop+Spark+Hive技术栈实现了新能源汽车推荐的全流程分布式处理,在数据规模、推荐精度和实时性上显著优于传统方案。未来可进一步探索以下方向:
- 联邦学习:在保护用户隐私的前提下,联合多车企数据训练推荐模型;
- 强化学习:根据用户实时反馈(如滑动跳过推荐车型)动态调整推荐策略;
- 图计算:利用GraphX构建用户-车辆-充电桩的异构图,捕捉高阶关联关系。
附录:关键技术指标
| 模块 | 技术选型 | 性能指标 |
|---|---|---|
| 分布式存储 | HDFS 3.x | 支持EB级数据,吞吐量>1GB/s |
| 数据仓库 | Hive 3.x | 复杂查询延迟<10秒(千节点集群) |
| 内存计算 | Spark 3.x | ALS训练速度较Mahout提升5-8倍 |
| 实时计算 | Spark Streaming | 端到端延迟<1秒(5秒微批次) |
备注:
- 实际部署时需根据集群规模调整Spark分区数、Executor内存等参数;
- 涉及用户隐私数据(如位置)时需符合GDPR等合规要求。
运行截图
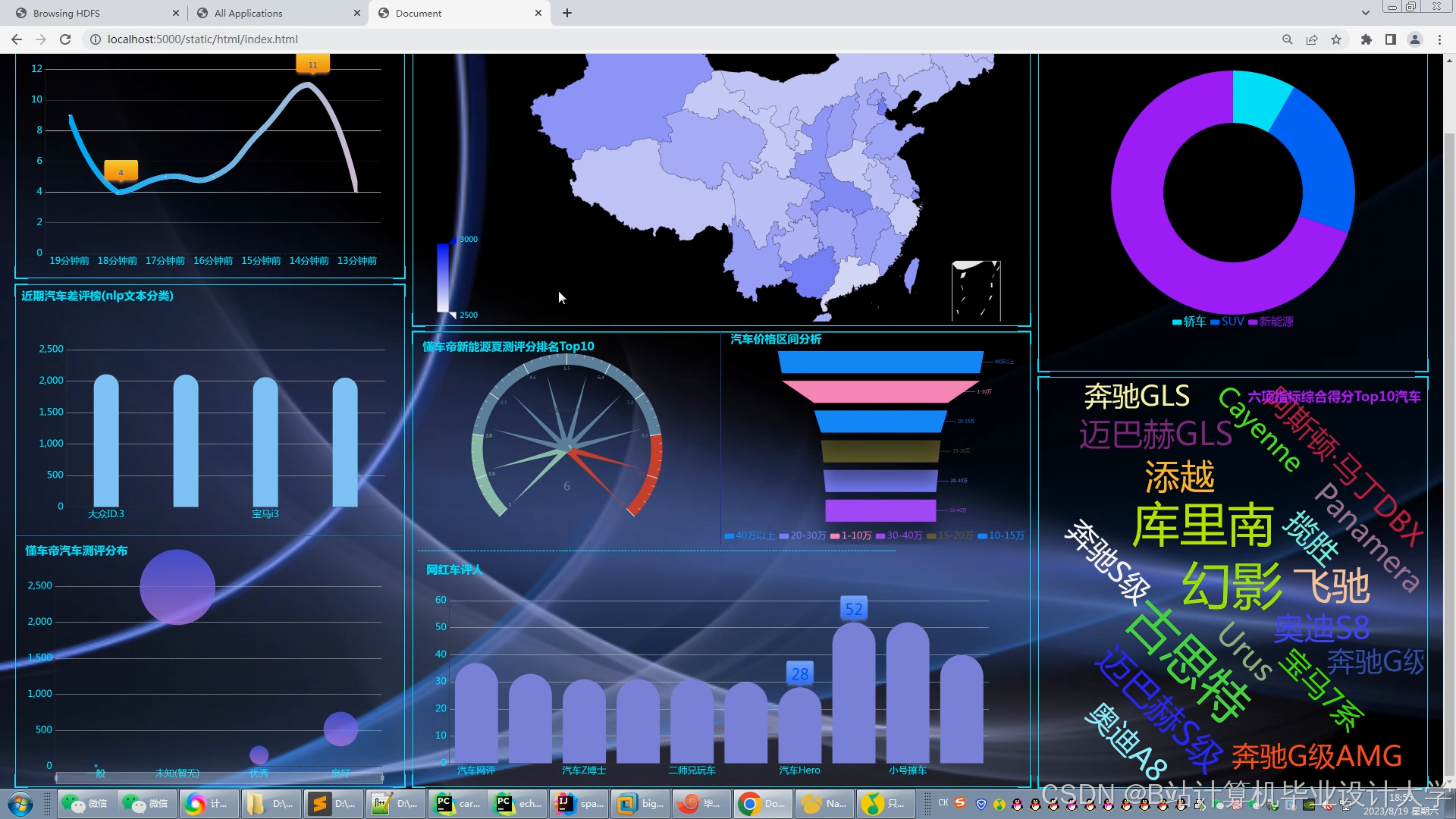
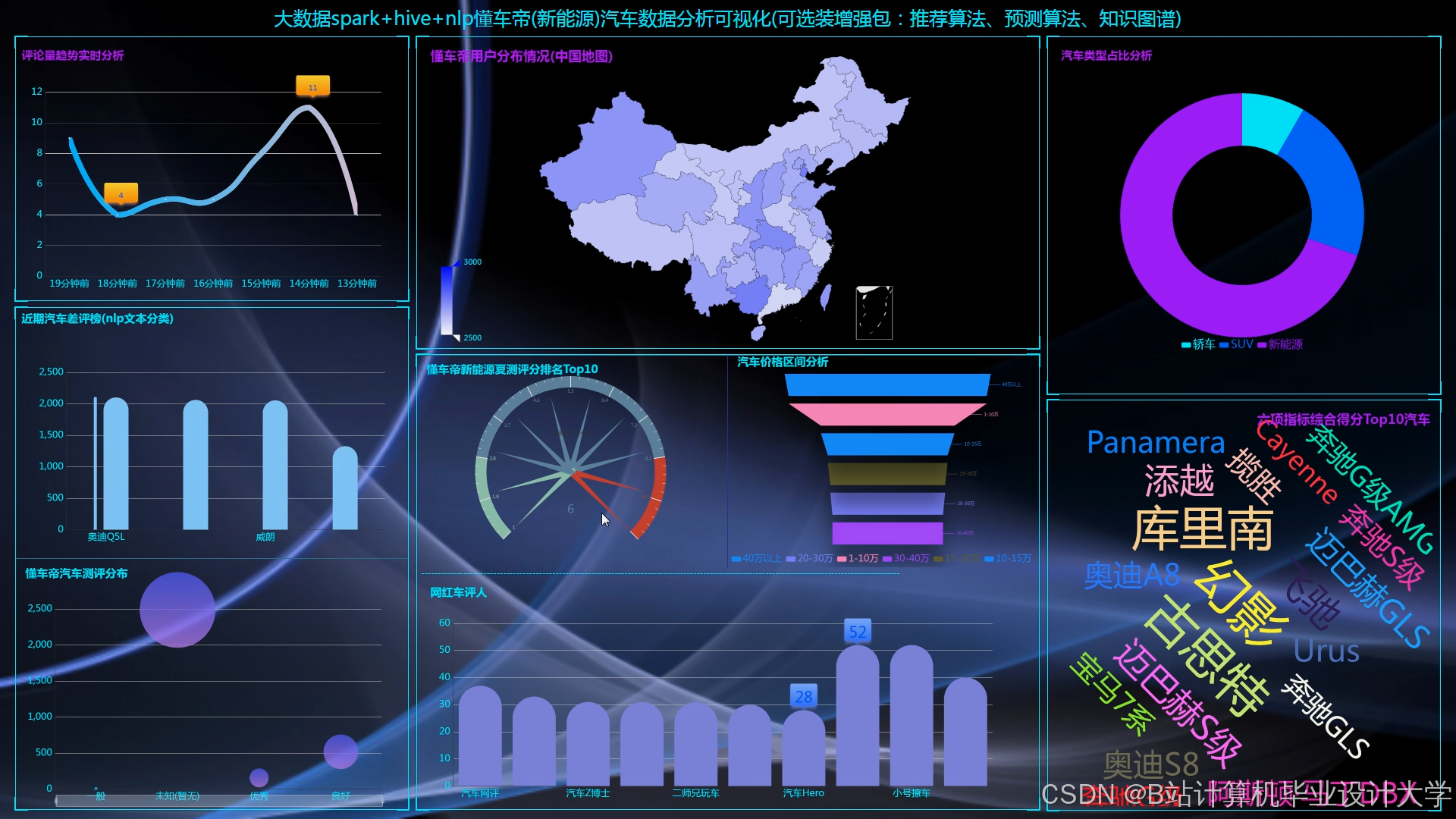
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











