




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python深度学习股票行情分析预测技术说明
一、引言
股票市场作为金融体系的核心组成部分,其价格波动受宏观经济、政策法规、市场情绪等多重因素影响,呈现出高度非线性和动态不确定性特征。传统分析方法(如技术分析、基本面分析)在应对复杂市场环境时存在局限性,而深度学习凭借强大的非线性拟合能力和自动特征提取能力,为股票行情预测提供了新范式。Python凭借丰富的科学计算库(如TensorFlow、PyTorch、Pandas)和数据处理工具,成为深度学习在金融领域应用的主流编程语言。本文从技术实现角度,系统阐述Python深度学习在股票行情分析预测中的关键技术,包括数据获取与预处理、特征工程、模型构建与训练、量化交易策略设计及性能评估。
二、技术架构概述
Python深度学习股票行情分析预测系统主要由以下模块构成:
- 数据获取模块:通过金融数据接口(如Tushare、AKShare)或网络爬虫获取股票行情数据、新闻舆情数据及宏观经济数据。
- 数据预处理模块:对原始数据进行清洗、标准化、归一化等处理,消除数据噪声和量纲差异。
- 特征工程模块:提取技术指标、时间序列特征及多源数据融合特征,构建高维特征集。
- 模型构建模块:基于LSTM、Transformer等深度学习模型,构建股票价格预测模型。
- 量化交易策略模块:根据模型预测结果生成交易信号,设计动态止盈止损策略。
- 性能评估模块:使用均方误差(MSE)、平均绝对误差(MAE)、夏普比率等指标评估模型和策略性能。
三、关键技术实现
3.1 数据获取与预处理
3.1.1 数据获取
股票行情数据具有时间序列性、高噪声和非线性特征,需从多源获取:
- 股票行情数据:使用Tushare或AKShare接口获取A股历史行情数据,包括开盘价、收盘价、最高价、最低价、成交量等。
pythonimport tushare as ts# 设置Tushare token(需注册获取)ts.set_token('your_tushare_token')pro = ts.pro_api()# 获取沪深300指数成分股日线数据df = pro.daily(ts_code='000300.SH', start_date='20100101', end_date='20241231') - 新闻舆情数据:通过Scrapy框架爬取新浪财经、东方财富等平台的新闻标题和内容,使用jieba分词和TF-IDF算法提取情感特征。
- 宏观经济数据:从国家统计局、Wind等平台获取GDP增长率、CPI、利率等指标。
3.1.2 数据预处理
原始数据存在缺失值、异常值、量纲差异等问题,需进行以下处理:
- 缺失值处理:对少量缺失值采用均值/中位数填充;对缺失率超过30%的记录直接删除。
pythonimport pandas as pdimport numpy as np# 填充缺失值df.fillna(df.mean(), inplace=True)# 删除缺失率高的列df.dropna(thresh=len(df)*0.7, axis=1, inplace=True) - 异常值检测:利用3σ原则或箱线图法识别异常值,并根据业务逻辑修正。
python# 3σ原则检测异常值mean, std = df['close'].mean(), df['close'].std()lower_bound, upper_bound = mean - 3*std, mean + 3*stddf.loc[(df['close'] < lower_bound) | (df['close'] > upper_bound), 'close'] = np.nandf.fillna(mean, inplace=True) - 数据标准化/归一化:采用Z-score标准化或Min-Max归一化消除量纲影响。
pythonfrom sklearn.preprocessing import StandardScaler, MinMaxScaler# Z-score标准化scaler = StandardScaler()df[['open', 'close', 'high', 'low', 'volume']] = scaler.fit_transform(df[['open', 'close', 'high', 'low', 'volume']])# Min-Max归一化min_max_scaler = MinMaxScaler()df[['open', 'close']] = min_max_scaler.fit_transform(df[['open', 'close']])
3.2 特征工程
特征工程是提高模型预测能力的关键步骤。通过分析股票价格的变化规律,提取以下特征:
- 技术指标:计算移动平均线(MA)、相对强弱指数(RSI)、布林带(Bollinger Bands)等。
python# 计算5日和10日移动平均线df['MA5'] = df['close'].rolling(window=5).mean()df['MA10'] = df['close'].rolling(window=10).mean()# 计算RSIdelta = df['close'].diff()gain = delta.where(delta > 0, 0)loss = -delta.where(delta < 0, 0)avg_gain = gain.rolling(window=14).mean()avg_loss = loss.rolling(window=14).mean()rs = avg_gain / avg_lossdf['RSI'] = 100 - (100 / (1 + rs)) - 时间序列特征:计算价格变化率、波动率等短期波动特征。
python# 计算价格变化率df['return'] = df['close'].pct_change()# 计算波动率(滚动标准差)df['volatility'] = df['return'].rolling(window=5).std() - 多源数据融合:将宏观经济数据(如通货膨胀率)、行业数据(如新能源行业景气度指数)与股票行情数据融合,构建更全面的特征集。
python# 假设已获取宏观经济数据macro_df和行业数据industry_df# 合并数据merged_df = pd.merge(df, macro_df, on='date', how='left')merged_df = pd.merge(merged_df, industry_df, on='date', how='left')
3.3 模型构建与训练
3.3.1 模型选择
股票行情预测需捕捉时间序列的长期依赖关系与非线性模式,本文选择LSTM和Transformer作为主要模型进行对比研究。
- LSTM模型:通过输入门、遗忘门和输出门解决传统RNN的梯度消失问题,适用于长序列数据预测。
pythonimport tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Dense# 构建LSTM模型model = Sequential([LSTM(64, return_sequences=True, input_shape=(train_X.shape[1], train_X.shape[2])),LSTM(32),Dense(1)])model.compile(optimizer='adam', loss='mse') - Transformer模型:通过自注意力机制并行处理长序列数据,捕捉市场多因素关联。
pythonfrom tensorflow.keras.layers import MultiHeadAttention, LayerNormalization, Densefrom tensorflow.keras.models import Model# 构建Transformer编码器块def transformer_encoder(inputs, head_size, num_heads, ff_dim, dropout=0):# 自注意力层attn_output = MultiHeadAttention(key_dim=head_size, num_heads=num_heads)(inputs, inputs)attn_output = LayerNormalization(epsilon=1e-6)(attn_output + inputs)# 前馈网络ffn_output = Dense(ff_dim, activation='relu')(attn_output)ffn_output = Dense(inputs.shape[-1])(ffn_output)ffn_output = LayerNormalization(epsilon=1e-6)(ffn_output + attn_output)return ffn_output# 构建Transformer模型inputs = tf.keras.Input(shape=(train_X.shape[1], train_X.shape[2]))x = transformer_encoder(inputs, head_size=64, num_heads=4, ff_dim=128)outputs = Dense(1)(x[:, -1, :]) # 取最后一个时间步的输出model = Model(inputs=inputs, outputs=outputs)model.compile(optimizer='adam', loss='mse')
3.3.2 模型训练
将数据集划分为训练集、验证集和测试集,比例分别为70%、15%和15%。使用Adam优化器进行模型训练,学习率设置为0.001,批次大小为32,训练轮数为50轮。
python
from sklearn.model_selection import train_test_split | |
# 划分数据集 | |
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42) | |
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42) | |
# 训练模型 | |
history = model.fit( | |
X_train, y_train, | |
epochs=50, | |
batch_size=32, | |
validation_data=(X_val, y_val), | |
verbose=1 | |
) |
3.4 量化交易策略设计
基于深度学习模型的预测结果,设计量化交易策略。采用阈值法生成交易信号:当预测价格涨幅超过设定阈值(如2%)时触发买入信号;当预测价格跌幅超过设定阈值时触发卖出信号。同时,引入动态止损机制,基于平均真实波幅(ATR)指标设置自适应止盈止损线,控制交易风险。
python
def generate_signals(predictions, threshold=0.02): | |
signals = [] | |
position = 0 # 0表示空仓,1表示持仓 | |
for pred in predictions: | |
if pred > threshold and position == 0: | |
signals.append(1) # 买入信号 | |
position = 1 | |
elif pred < -threshold and position == 1: | |
signals.append(-1) # 卖出信号 | |
position = 0 | |
else: | |
signals.append(0) # 无操作 | |
return signals | |
# 计算ATR | |
def calculate_atr(df, window=14): | |
df['tr'] = np.max([df['high'] - df['low'], | |
np.abs(df['high'] - df['close'].shift()), | |
np.abs(df['low'] - df['close'].shift())], axis=0) | |
df['atr'] = df['tr'].rolling(window=window).mean() | |
return df['atr'].iloc[-1] # 取最新ATR值 |
3.5 性能评估
使用均方误差(MSE)、平均绝对误差(MAE)和决定系数(R²)等指标评估模型性能,使用夏普比率、最大回撤等指标评估交易策略性能。
python
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score | |
# 评估模型性能 | |
y_pred = model.predict(X_test) | |
mse = mean_squared_error(y_test, y_pred) | |
mae = mean_absolute_error(y_test, y_pred) | |
r2 = r2_score(y_test, y_pred) | |
print(f"MSE: {mse:.4f}, MAE: {mae:.4f}, R²: {r2:.4f}") | |
# 评估交易策略性能(假设已实现策略回测函数backtest) | |
initial_capital = 1000000 | |
returns, drawdowns = backtest(signals, df, initial_capital) | |
sharpe_ratio = np.mean(returns) / np.std(returns) * np.sqrt(252) # 年化夏普比率 | |
max_drawdown = np.max(drawdowns) | |
print(f"夏普比率: {sharpe_ratio:.2f}, 最大回撤: {max_drawdown:.2f}%") |
四、技术挑战与解决方案
4.1 数据质量问题
- 挑战:金融数据存在噪声、缺失值和非平稳性问题,影响模型训练效果。
- 解决方案:采用滑动窗口平均、卡尔曼滤波等方法平滑数据;使用生成对抗网络(GAN)生成合成数据补充缺失值;通过差分或对数变换使数据平稳。
4.2 过拟合问题
- 挑战:复杂模型在训练数据上表现优异,但在测试数据上性能下降。
- 解决方案:采用L1/L2正则化、Dropout层或早停法防止过拟合;使用交叉验证评估模型泛化能力。
4.3 可解释性问题
- 挑战:深度学习模型的黑箱特性限制了其在金融监管中的应用。
- 解决方案:结合SHAP值、LIME等方法解释特征贡献度;构建可解释的浅层模型(如决策树)辅助决策。
五、结论
Python深度学习在股票行情分析预测中展现出显著优势,通过LSTM、Transformer等模型捕捉市场非线性特征,结合多模态数据融合与量化策略优化,实现了预测精度与收益风险的平衡。本文详细阐述了数据获取与预处理、特征工程、模型构建与训练、量化交易策略设计及性能评估等关键技术,并针对数据质量、过拟合及可解释性等挑战提出了解决方案。未来,随着强化学习、联邦学习等技术的引入,深度学习在金融领域的应用将更加深入,为量化交易提供更科学的决策依据。
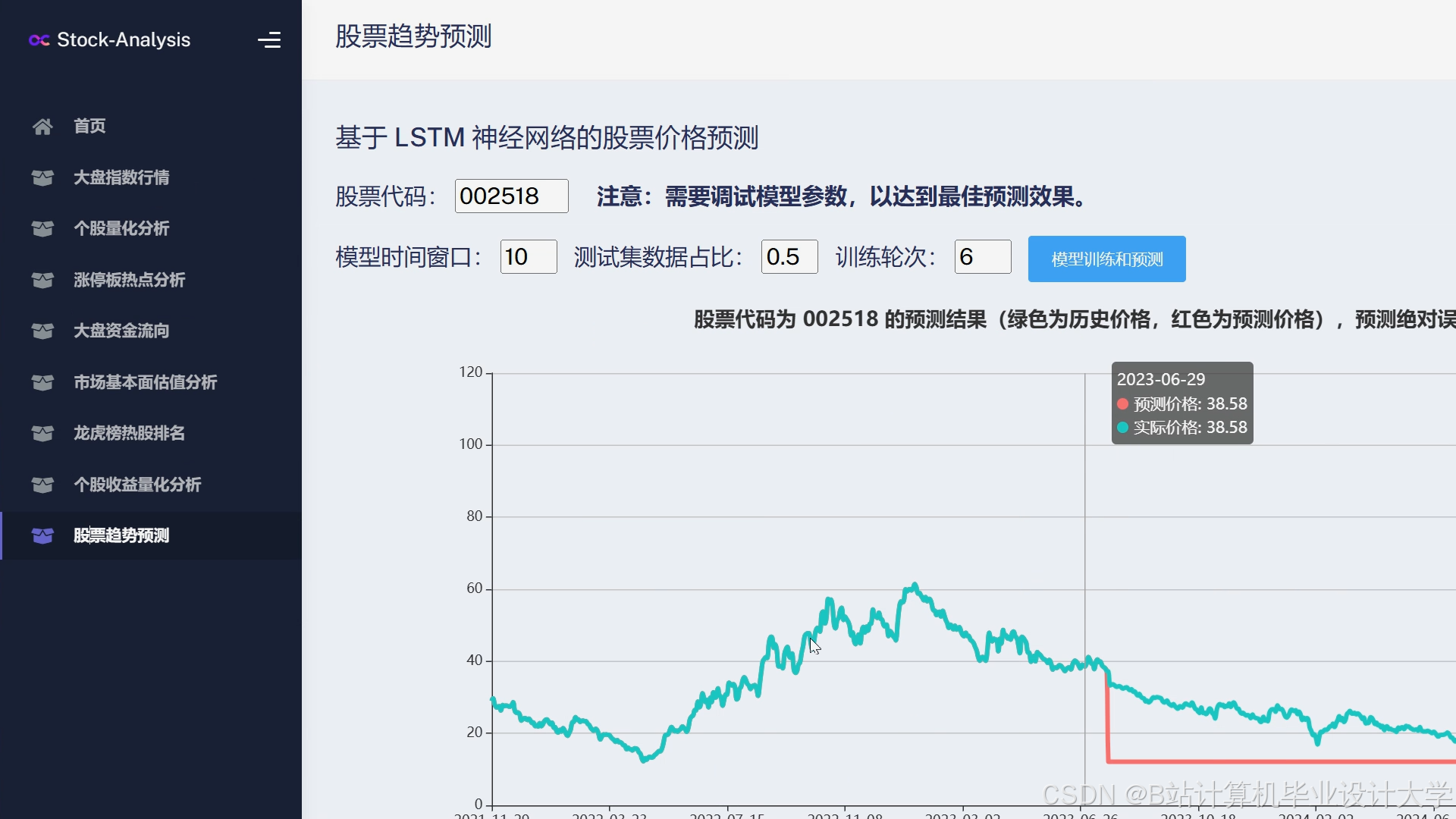
运行截图
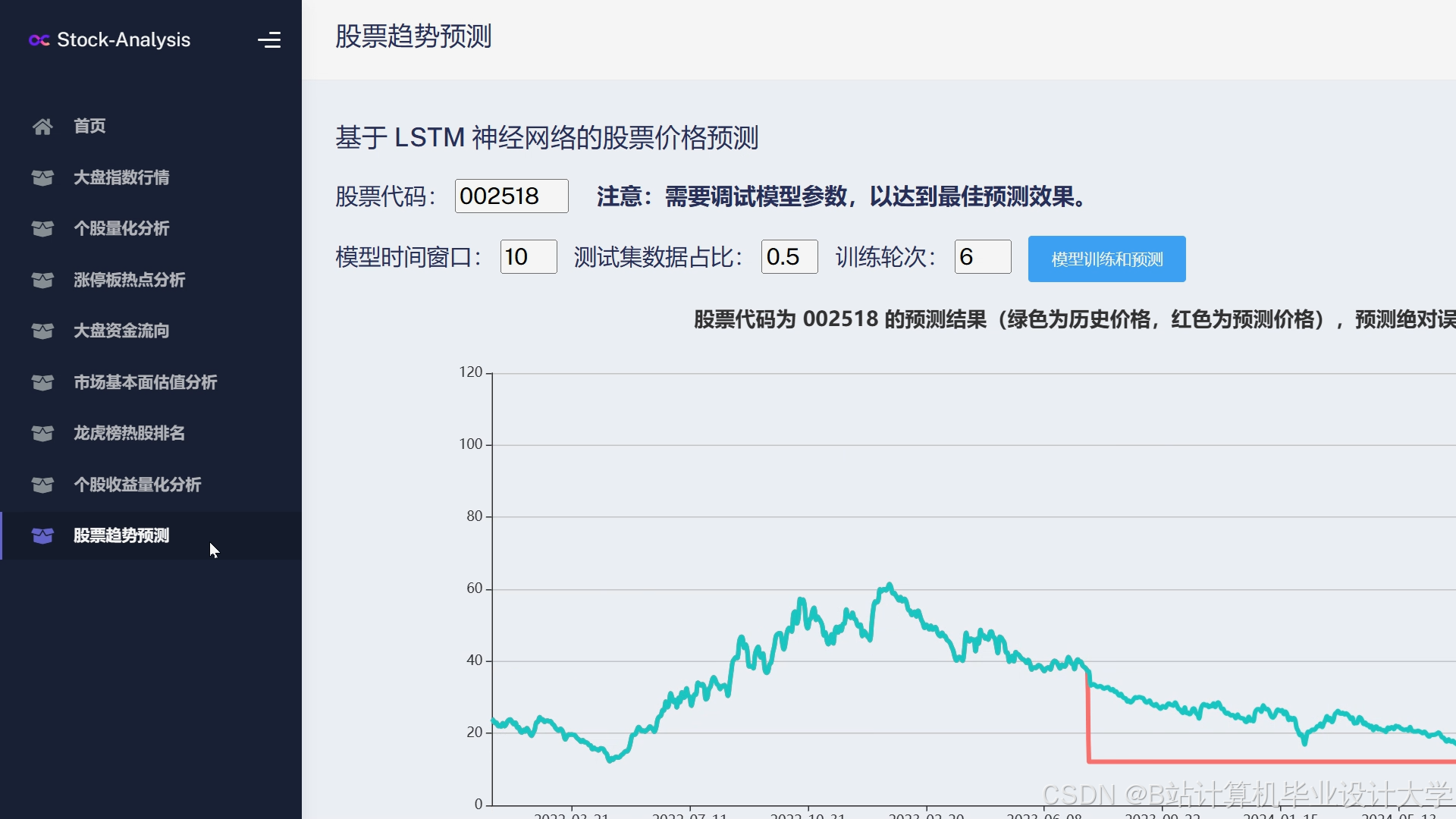

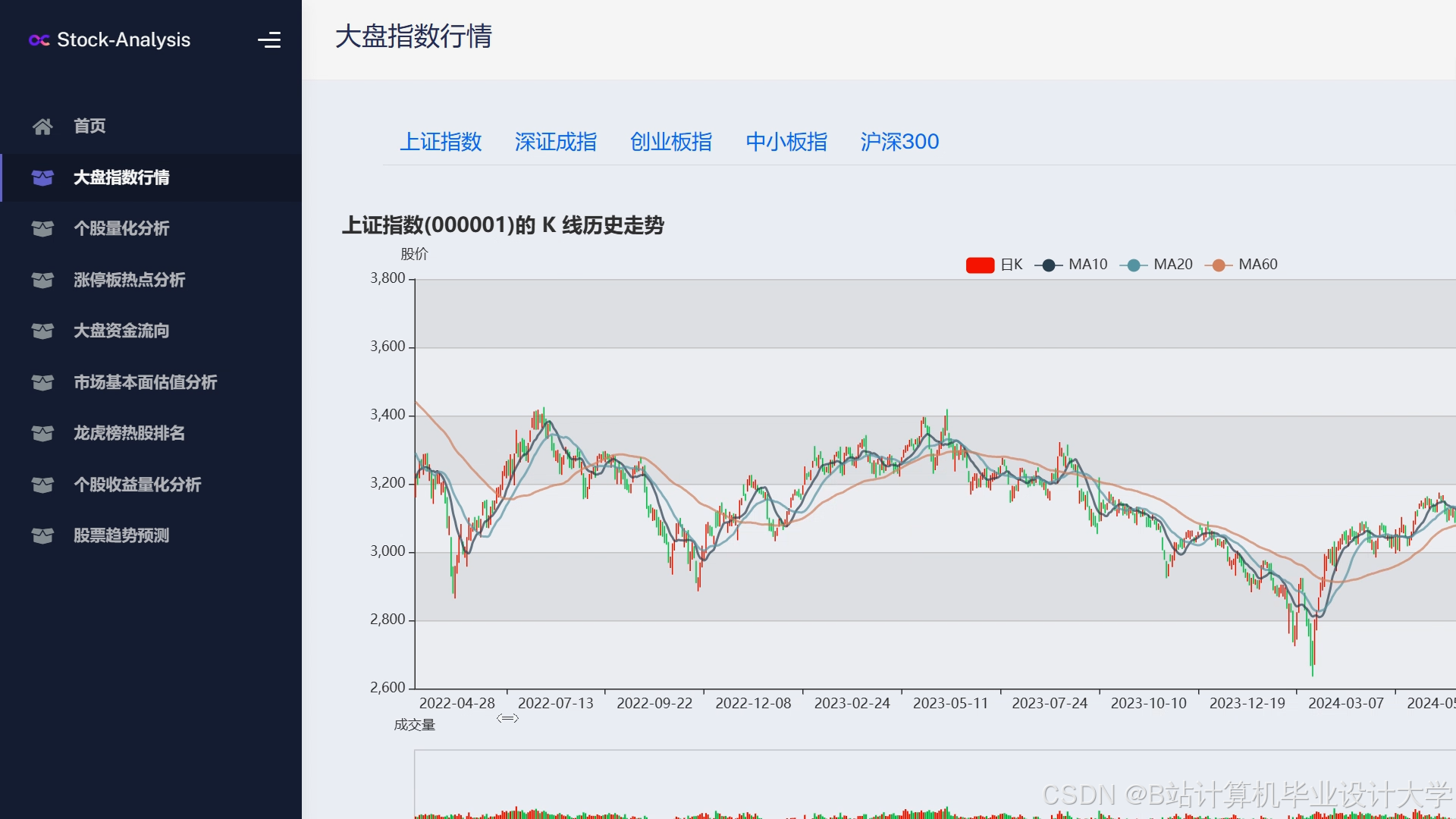
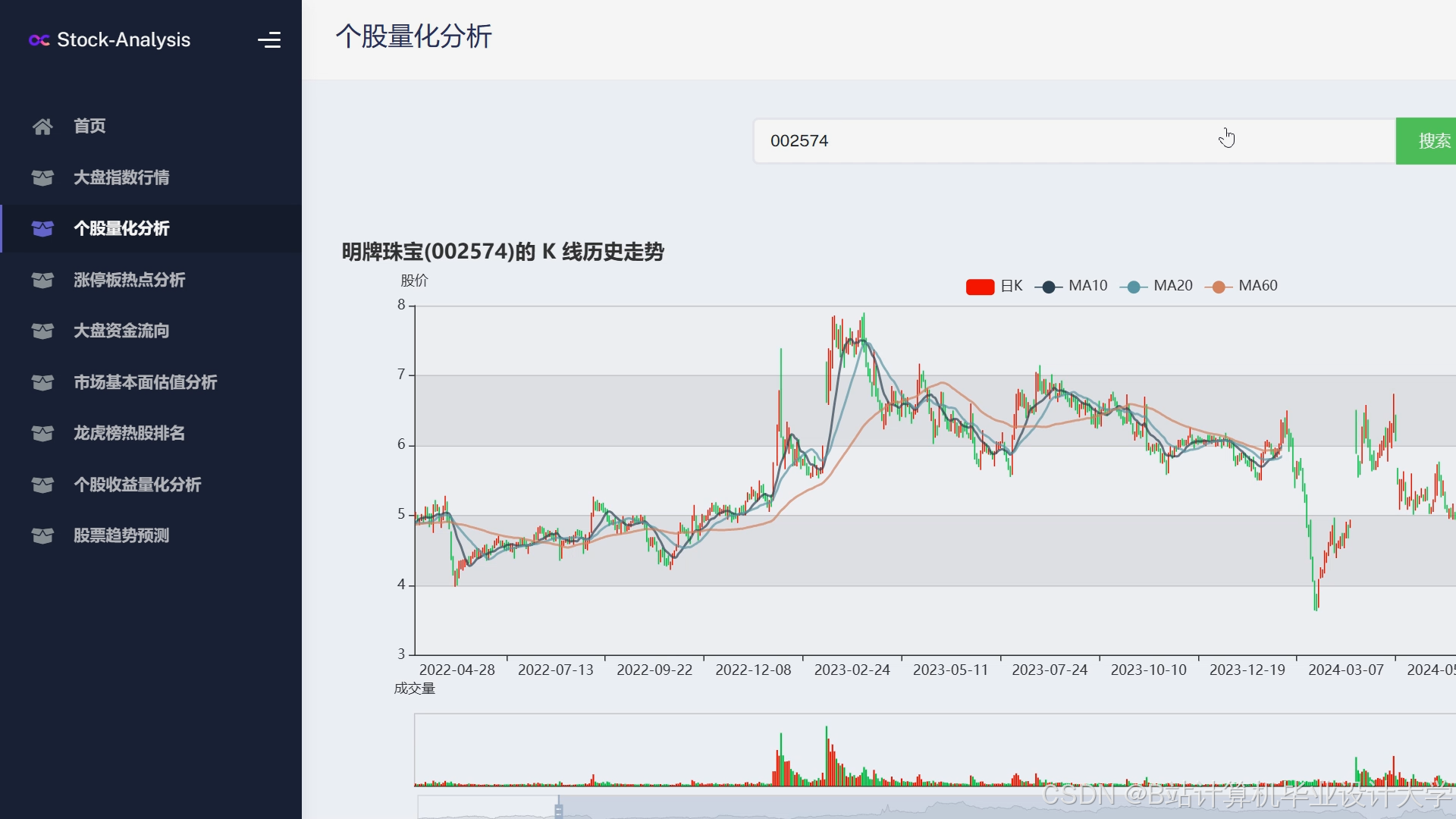
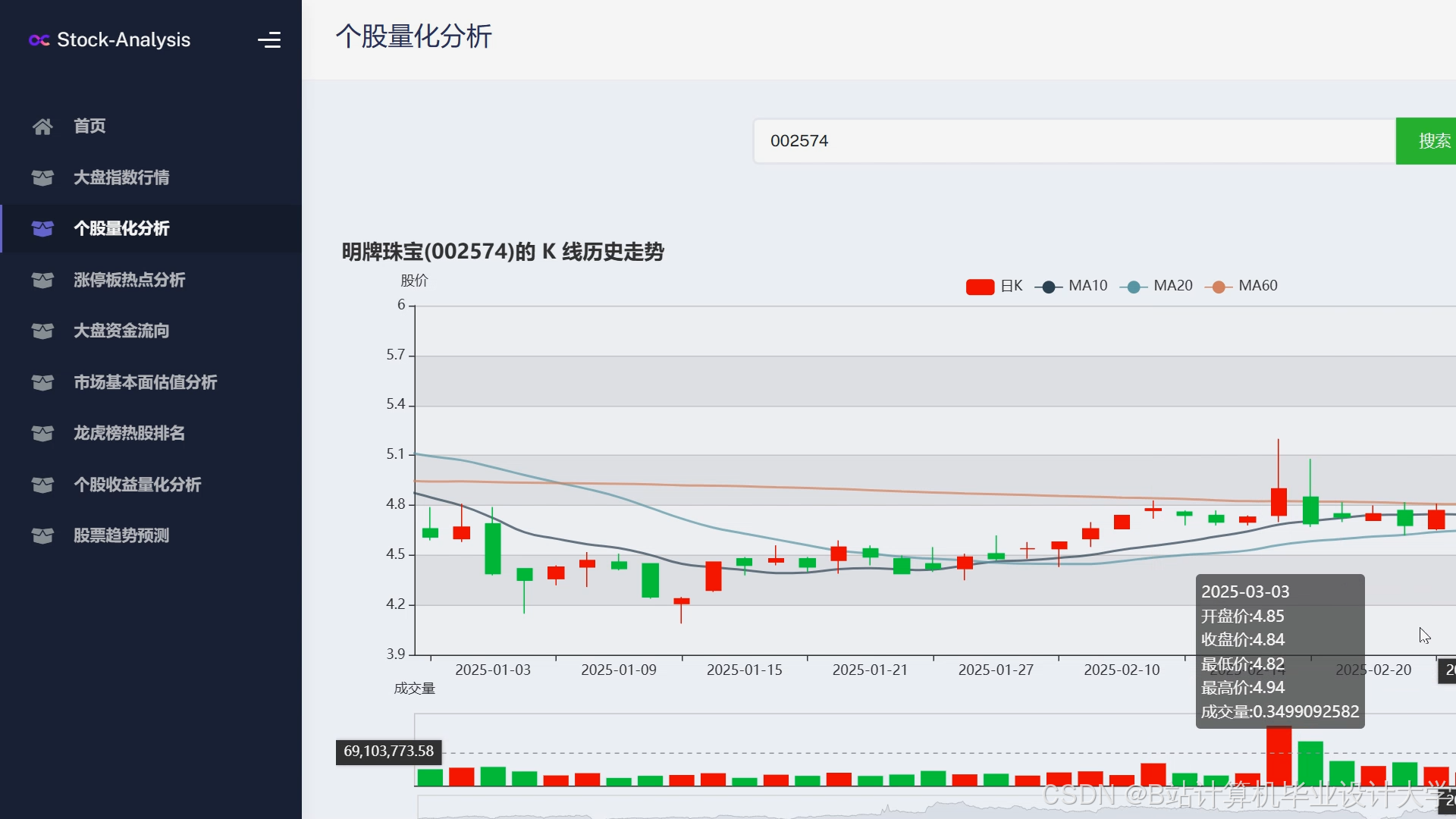
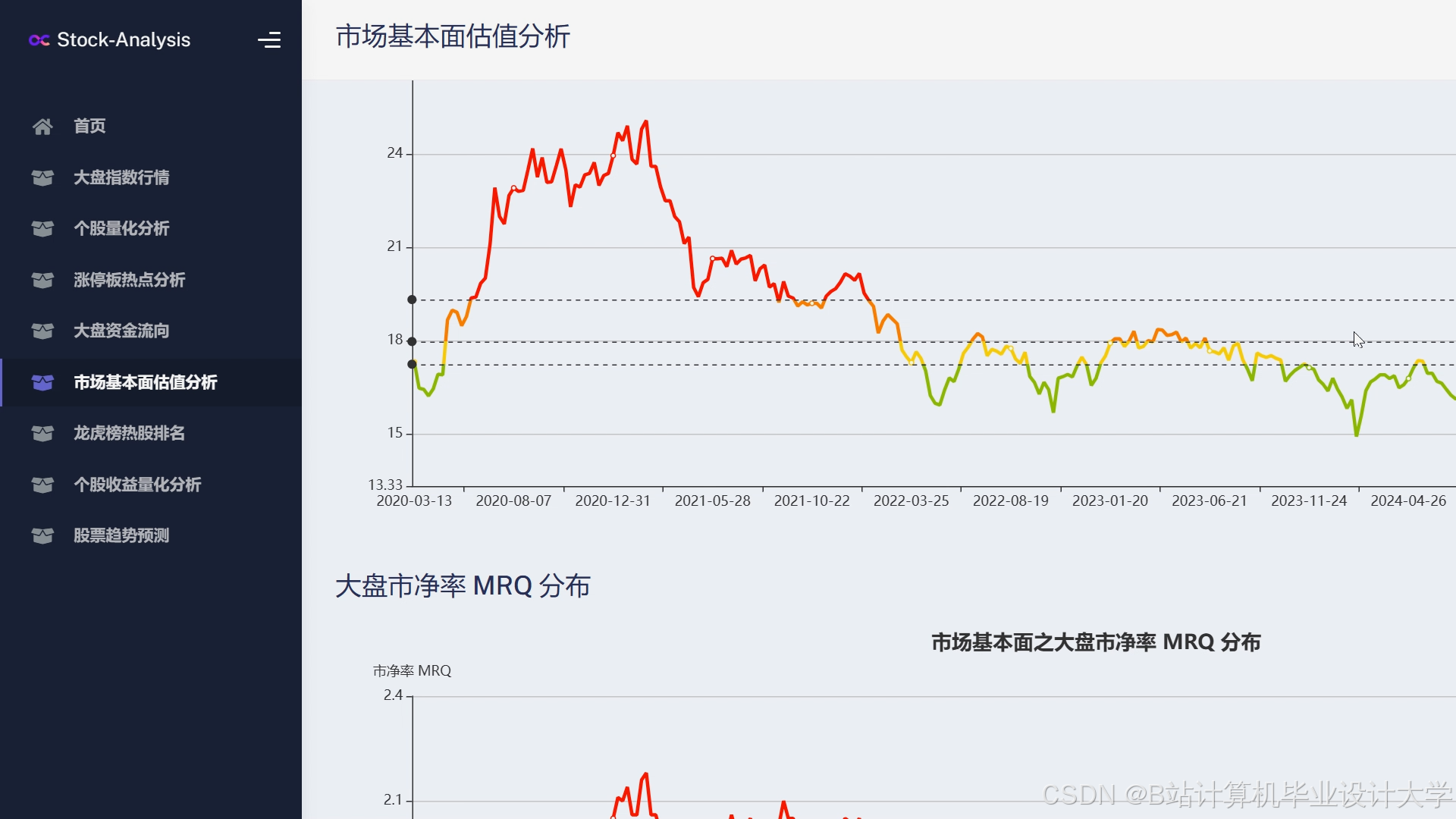
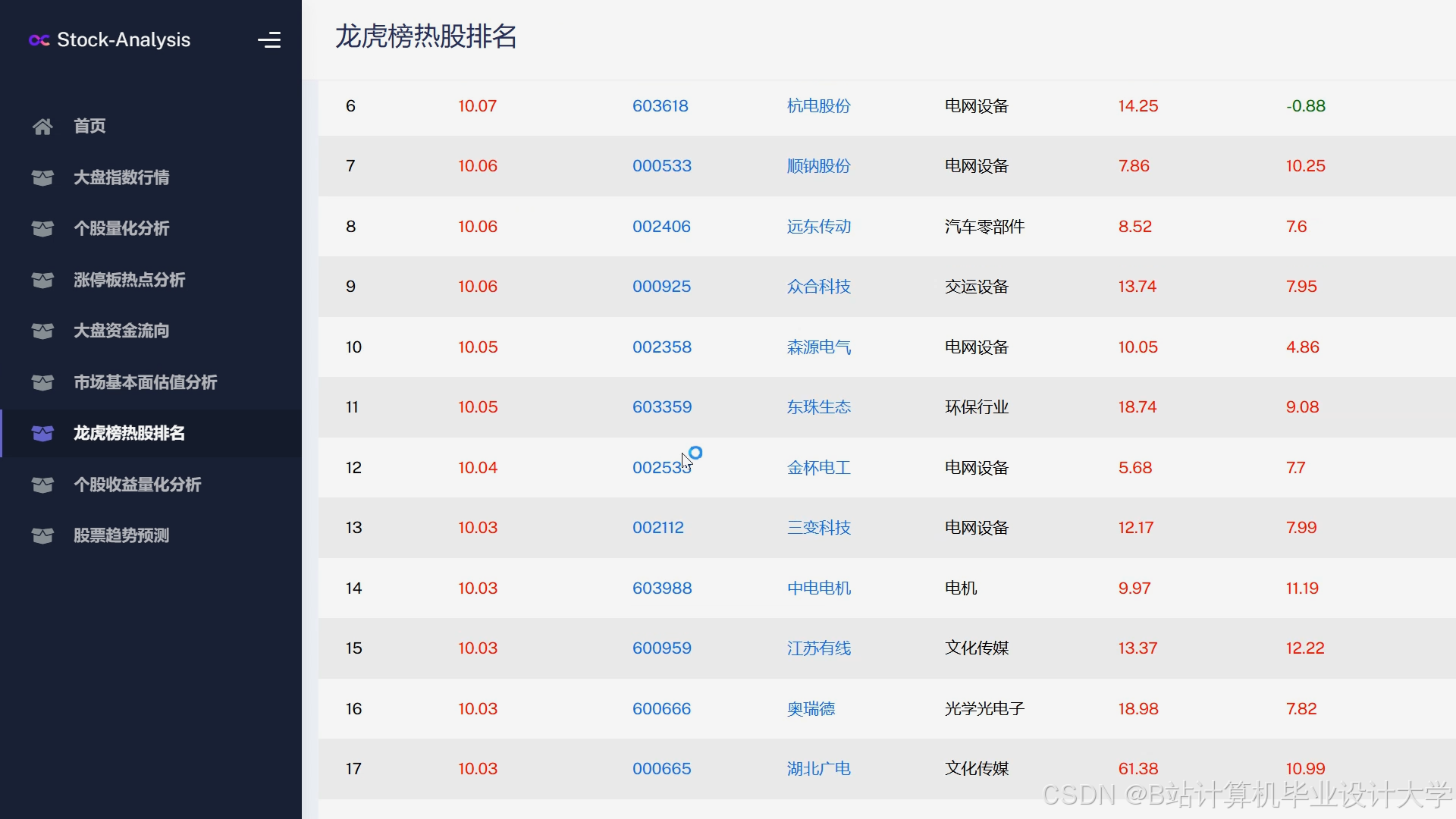
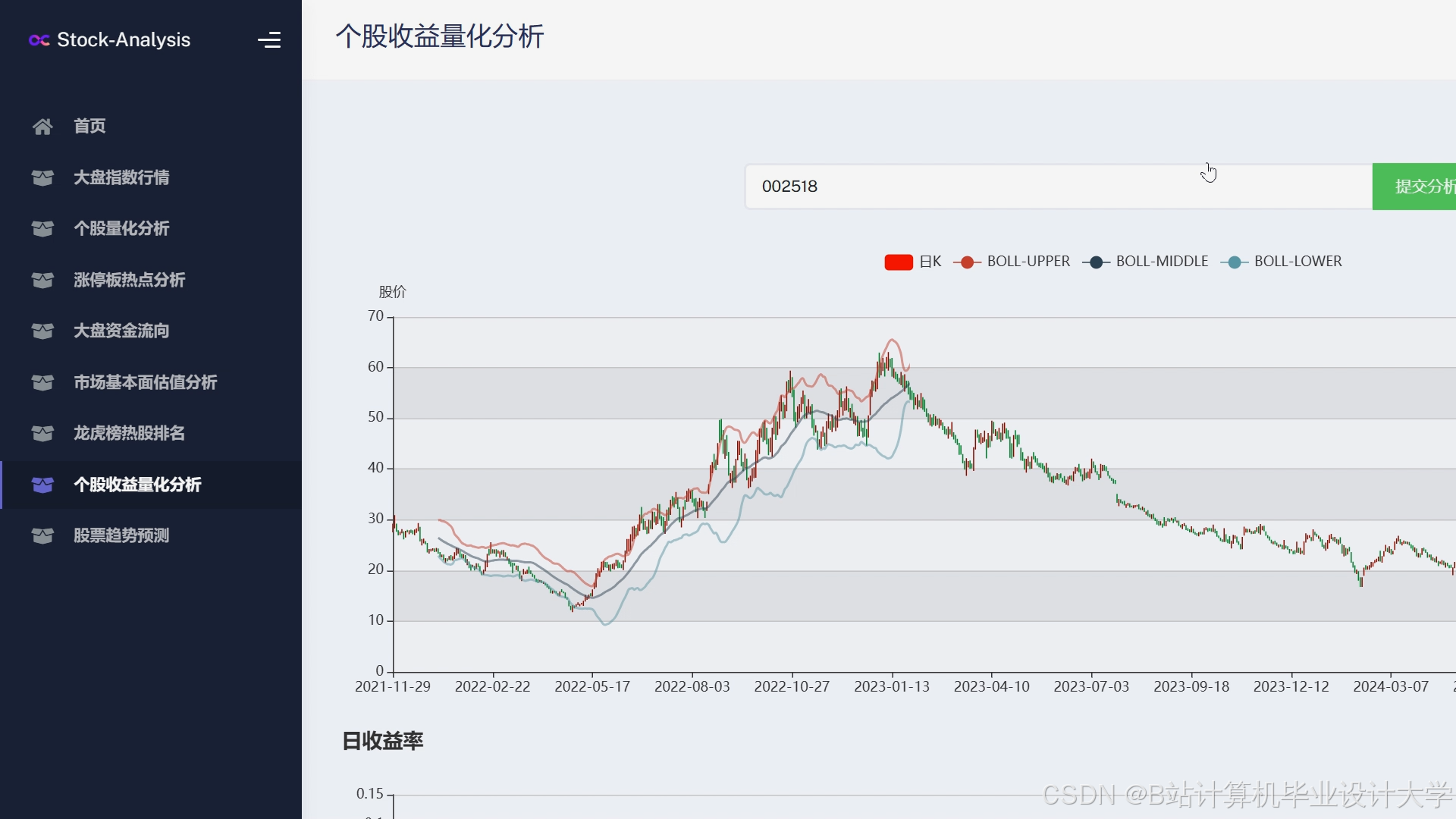
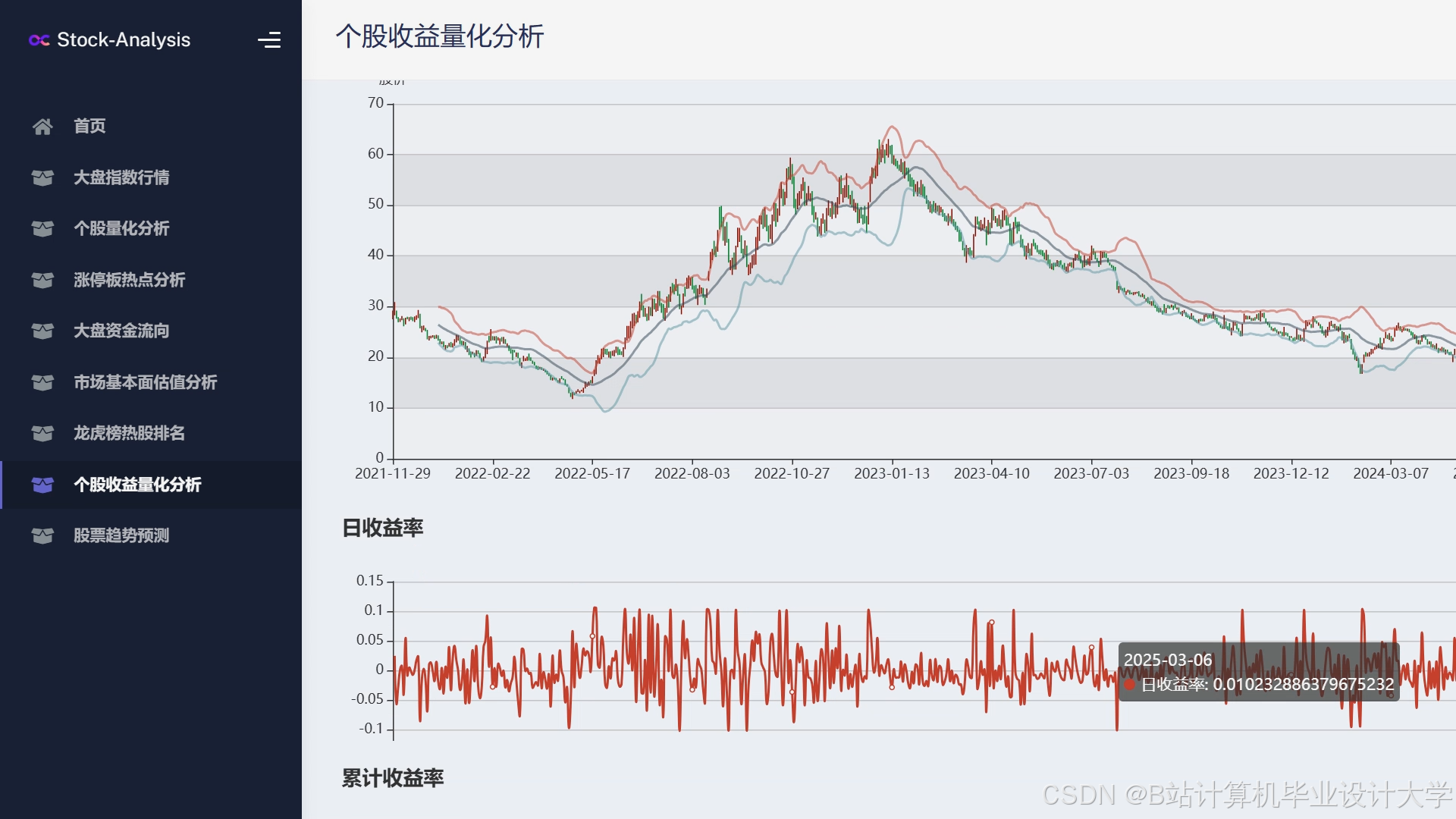
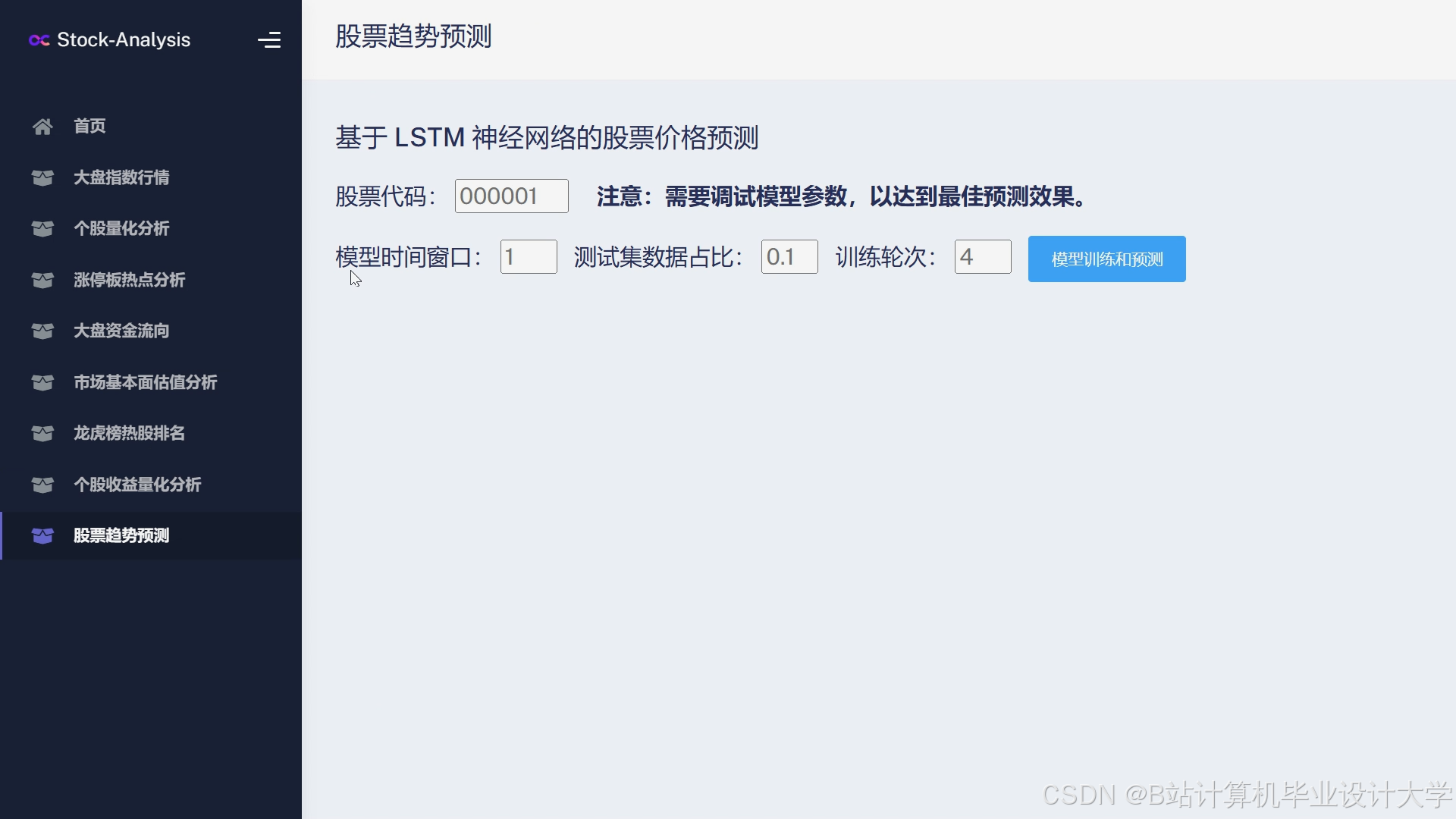
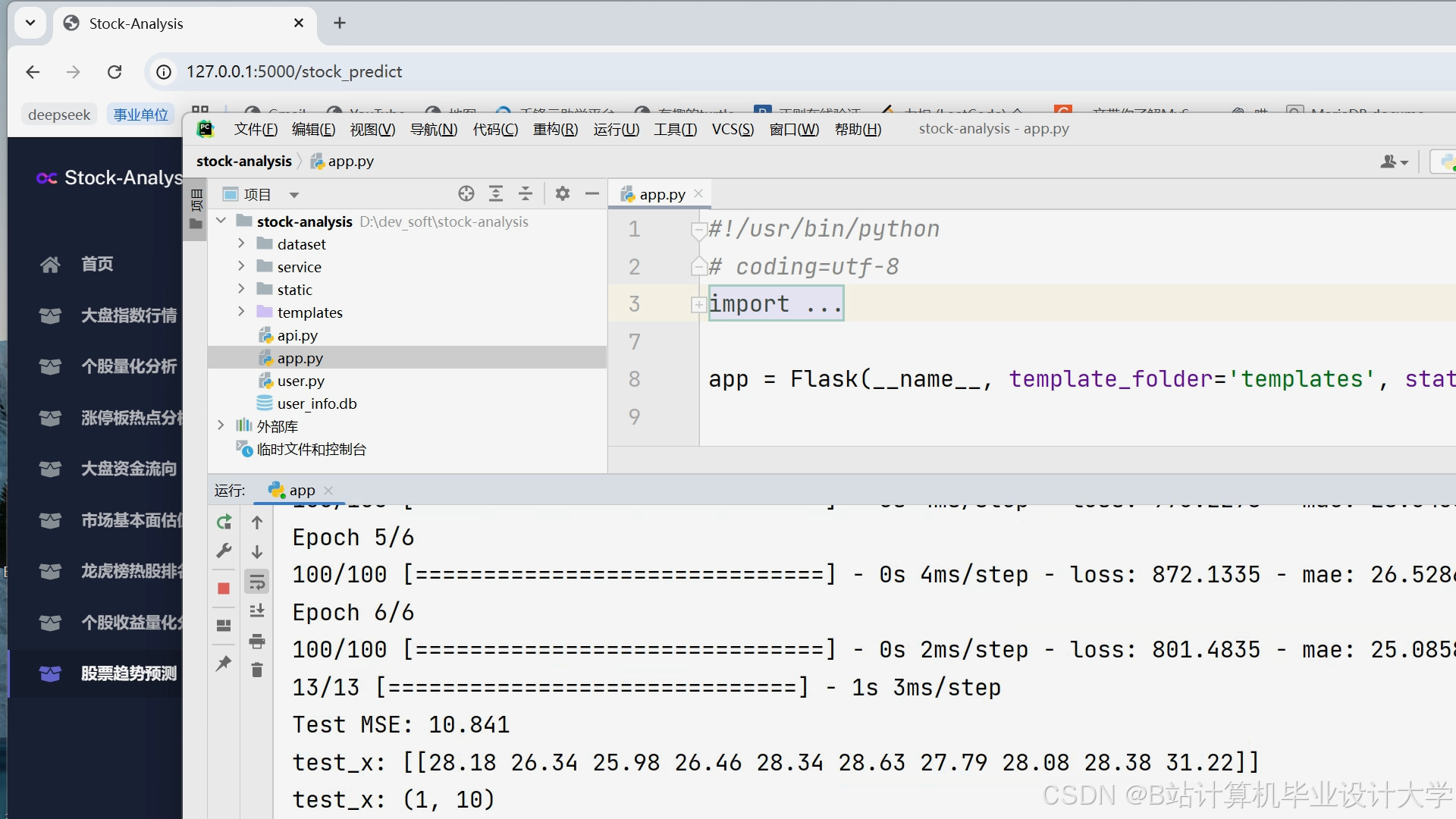
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1849
1849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











