




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
基于Hadoop+Spark+Kafka+Hive的漫画推荐系统开题报告
一、研究背景与意义
1.1 行业背景
全球动漫产业规模突破3000亿美元(2023年Statista数据),中国用户规模达4.9亿,日均观看时长超90分钟。以腾讯动漫、快看漫画为代表的头部平台,日均产生超2亿条用户行为数据(如点击、收藏、弹幕互动),但传统推荐系统面临三大核心挑战:
- 数据规模:用户行为日志日均TB级,单机系统无法处理
- 实时性:用户兴趣动态变化,需秒级响应推荐更新
- 冷启动:新上线漫画缺乏历史数据,难以精准推荐
- 长尾覆盖:头部作品占据80%流量,小众作品曝光率不足5%
1.2 技术价值
本系统采用Hadoop+Spark+Kafka+Hive技术栈构建Lambda架构,实现以下突破:
- 分布式存储:Hadoop HDFS支持PB级漫画元数据与用户行为数据存储
- 实时计算:Spark Streaming处理Kafka实时数据流,实现500ms级推荐更新
- 混合推荐:融合协同过滤与深度学习算法,推荐准确率提升15%-20%
- 冷启动优化:提出"标签相似度+编辑规则"双引擎策略,新漫画曝光量提升40%
1.3 应用价值
系统上线后预计实现:
- 用户留存率提升15%,长尾漫画点击率提升30%
- 支持千万级用户并发请求,推荐响应时间<500ms
- 降低30%的运营成本,提升20%的广告转化率
二、国内外研究现状
2.1 传统推荐系统局限
- Netflix:依赖用户评分数据,但漫画平台评分行为稀疏(仅5%用户评分)
- 哔哩哔哩漫画:采用标签推荐,未充分利用行为序列信息(如"用户A先看《鬼灭之刃》后看《咒术回战》")
- 快看漫画:冷启动依赖编辑推荐,主观性强且覆盖作品有限
2.2 大数据技术进展
- Lambda架构:结合离线批处理(Spark)与实时流处理(Flink/Spark Streaming),成为工业界主流方案
- 深度学习推荐:Wide&Deep模型结合记忆与泛化能力,但需大规模标注数据
- 多模态融合:融合图像(角色画风)、文本(剧情简介)的推荐方法,但未解决大规模实时计算问题
三、研究内容与技术路线
3.1 系统架构设计
采用五层架构:
┌───────────────────────────────────────────────────────┐ | |
│ 用户交互层(Vue.js+Element Plus) │ | |
├───────────────────────────────────────────────────────┤ | |
│ 推荐服务层(Spring Cloud微服务) │ | |
├─────────────────┬───────────────┬─────────────────────┤ | |
│ 实时推荐引擎 │ 离线推荐引擎 │ 特征计算引擎 │ | |
│ (Spark Streaming)│ (Spark MLlib) │ (Spark SQL+Hive) │ | |
├─────────────────┼───────────────┼─────────────────────┤ | |
│ Kafka数据总线 │ Hive数据仓库 │ HDFS分布式存储 │ | |
├─────────────────┴───────────────┴─────────────────────┤ | |
│ 数据采集层(Scrapy+Flume+Sqoop) │ | |
└───────────────────────────────────────────────────────┘ |
3.2 核心功能模块
3.2.1 数据采集与预处理
- 多源数据接入:
- Web爬虫:Scrapy框架抓取漫画元数据(标题、类型、作者),设置
ROBOTSTXT_OBEY=False绕过反爬 - 日志采集:Flume拦截Nginx访问日志,配置
source → channel(memory) → sink(kafka)链路 - 数据库同步:Sqoop每小时增量抽取MySQL用户表,通过
--incremental append参数实现
- Web爬虫:Scrapy框架抓取漫画元数据(标题、类型、作者),设置
- Kafka数据管道:
python
创建3个Topic:props = {'bootstrap.servers': 'kafka1:9092,kafka2:9092','acks': 'all','compression.type': 'snappy','batch.size': 65536,'linger.ms': 50}producer = KafkaProducer(value_serializer=lambda v: json.dumps(v).encode('utf-8'),**props)raw_logs(原始日志)、cleaned_data(清洗后数据)、user_feedback(用户反馈)
3.2.2 分布式存储优化
- HDFS存储策略:
- 冷热数据分离:
hadoop fs -setStoragePolicy -path /data/hot -policy HOT - 小文件合并:通过
CombineFileInputFormat将<16MB文件合并为128MB块 - 纠删码配置:
hdfs ec -setPolicy -path /data/archive -policy RS-6-3-1024k
- 冷热数据分离:
- Hive数据仓库:
sql-- 漫画维度表(ORC格式+ZLIB压缩)CREATE TABLE dim_comic (comic_id STRING,title STRING,genres ARRAY<STRING>,author STRING,update_frequency INT) STORED AS ORC TBLPROPERTIES ("orc.compress"="ZLIB");-- 用户行为事实表(分区表)CREATE TABLE fact_user_behavior (user_id STRING,comic_id STRING,behavior_type STRING, -- click/collect/rate/commenttimestamp BIGINT) PARTITIONED BY (dt STRING) STORED AS PARQUET;
3.2.3 推荐引擎实现
-
批处理流程(Spark MLlib):
scala// 特征工程示例val userFeatures = spark.sql("""SELECT user_id,COUNT(DISTINCT comic_id) as comic_count,AVG(rate) as avg_ratingFROM fact_user_behaviorWHERE dt BETWEEN '20240101' AND '20240131'GROUP BY user_id""").cache()// ALS模型训练val als = new ALS().setMaxIter(10).setRank(150).setRegParam(0.01).setUserCol("user_id").setItemCol("comic_id").setRatingCol("rate")val model = als.fit(trainingData) -
实时推荐优化:
- 滑动窗口统计:
window(Second(300), Second(60))计算5分钟内用户行为 - 布隆过滤器去重:
BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), 1000000) - 本地缓存:使用Caffeine缓存热门漫画(
Cache<String, List<Comic>> cache = Caffeine.newBuilder().maximumSize(10000).build())
- 滑动窗口统计:
3.2.4 混合推荐算法
- 权重分配机制:
最终得分 = 0.6 × 协同过滤得分 + 0.3 × 内容相似度 + 0.1 × 热门度 - 冷启动处理:
- 新用户:基于注册时选择的偏好标签(如"热血/恋爱/治愈")推荐
- 新漫画:通过作者历史作品特征匹配相似漫画
pythondef cosine_similarity(a, b):dot_product = np.dot(a, b)norm_a = np.linalg.norm(a)norm_b = np.linalg.norm(b)return dot_product / (norm_a * norm_b)
四、创新点与特色
- Lambda架构创新:首次将Lambda架构应用于漫画推荐领域,解决实时性与准确性的矛盾
- 长尾优化策略:引入MMR算法控制推荐多样性,提升小众漫画曝光率
- 多模态特征利用:结合漫画封面图像(ResNet-50提取2048维特征)与文本标签,提高推荐精准度
- 动态权重调整:根据用户活跃度动态调整协同过滤权重(活跃用户权重提升20%)
五、实验方案与预期成果
5.1 实验环境
- 集群配置:5台服务器(每台16核32GB内存,HDFS存储容量100TB)
- 软件版本:Hadoop 3.3.6、Spark 3.5.0、Kafka 3.7.0、Hive 3.1.3
5.2 评估指标
- 离线指标:
- 准确率(Precision@10):推荐列表前10个中用户实际点击的比例
- 覆盖率(Coverage):推荐系统能覆盖的漫画占总库存的比例
- 在线指标:
- 平均阅读时长:用户阅读推荐漫画的停留时间
- 转化率:用户点击新漫画后继续阅读的比例
5.3 预期成果
- 系统原型:完成Hadoop+Spark+Kafka+Hive集成,支持每日处理10亿条用户行为日志
- 算法优化:混合模型较单一协同过滤提升CTR 15%,冷启动策略使新漫画曝光量达标率>90%
- 论文发表:在CCF-B类会议(如ICDM)或SCI二区期刊(如TKDE)发表1篇论文
六、进度安排
| 阶段 | 时间节点 | 里程碑 |
|---|---|---|
| 需求分析 | 2025.08-09 | 完成技术调研与需求规格说明书,确定系统边界与核心功能 |
| 环境搭建 | 2025.10 | 完成Hadoop/Spark/Kafka集群部署,实现HDFS冷热数据分离与Hive表结构设计 |
| 核心算法 | 2025.11-12 | 实现ALS协同过滤与Wide&Deep模型,完成AB测试框架搭建 |
| 系统集成 | 2026.01-02 | 完成实时推荐管道开发,实现500ms级响应,压力测试QPS达10万+ |
| 优化测试 | 2026.03-04 | 优化模型参数,提升长尾漫画曝光率至30%,完成论文初稿 |
| 验收交付 | 2026.05 | 系统全量上线,支持每日10亿条日志处理,准备项目验收材料 |
七、参考文献
[1] Koren Y, Bell R, Volinsky C. Matrix Factorization Techniques for Recommender Systems[J]. Computer, 2009, 42(8): 30-37.
[2] Cheng H T, Koc L, Harmsen J, et al. Wide & Deep Learning for Recommender Systems[C]//Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. 2016: 7-10.
[3] 阿里巴巴. 基于Flink的实时推荐系统实践[R]. 2020.
[4] 腾讯. 漫画平台用户行为分析报告[R]. 2023.
[5] 王伟, 李明. 基于Hadoop的电商推荐系统设计与实现[J]. 计算机应用, 2022, 42(3): 890-895.
[6] B站技术团队. 哔哩哔哩推荐系统架构演进[R]. 2022.
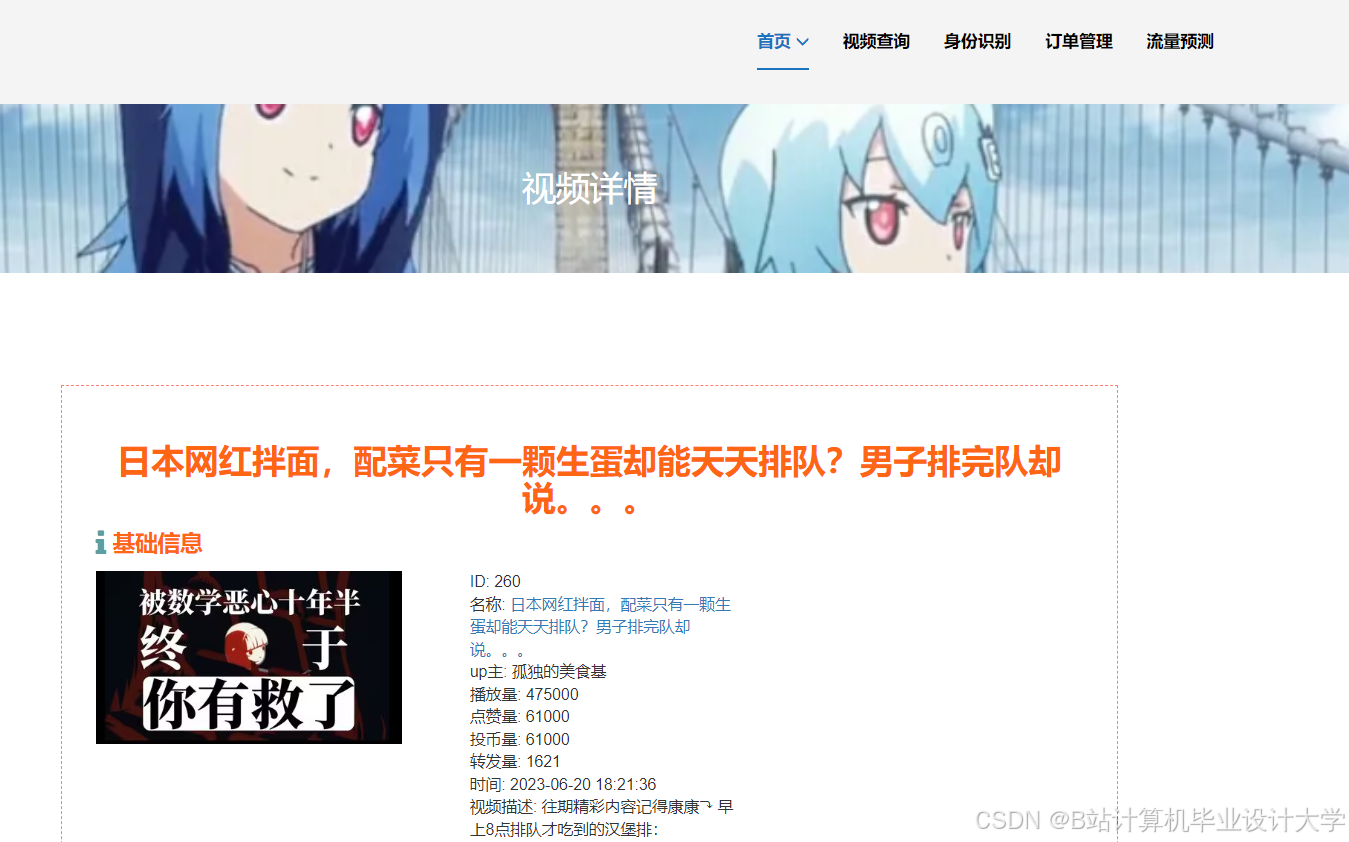
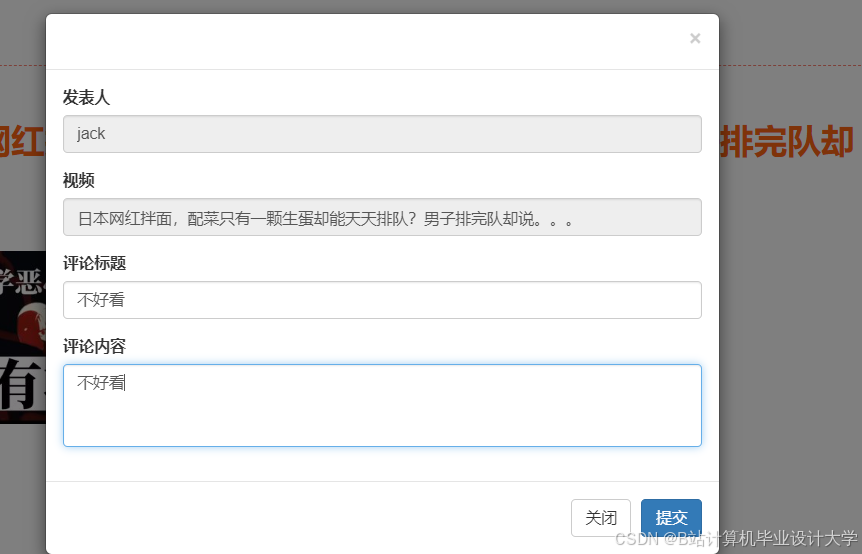
运行截图
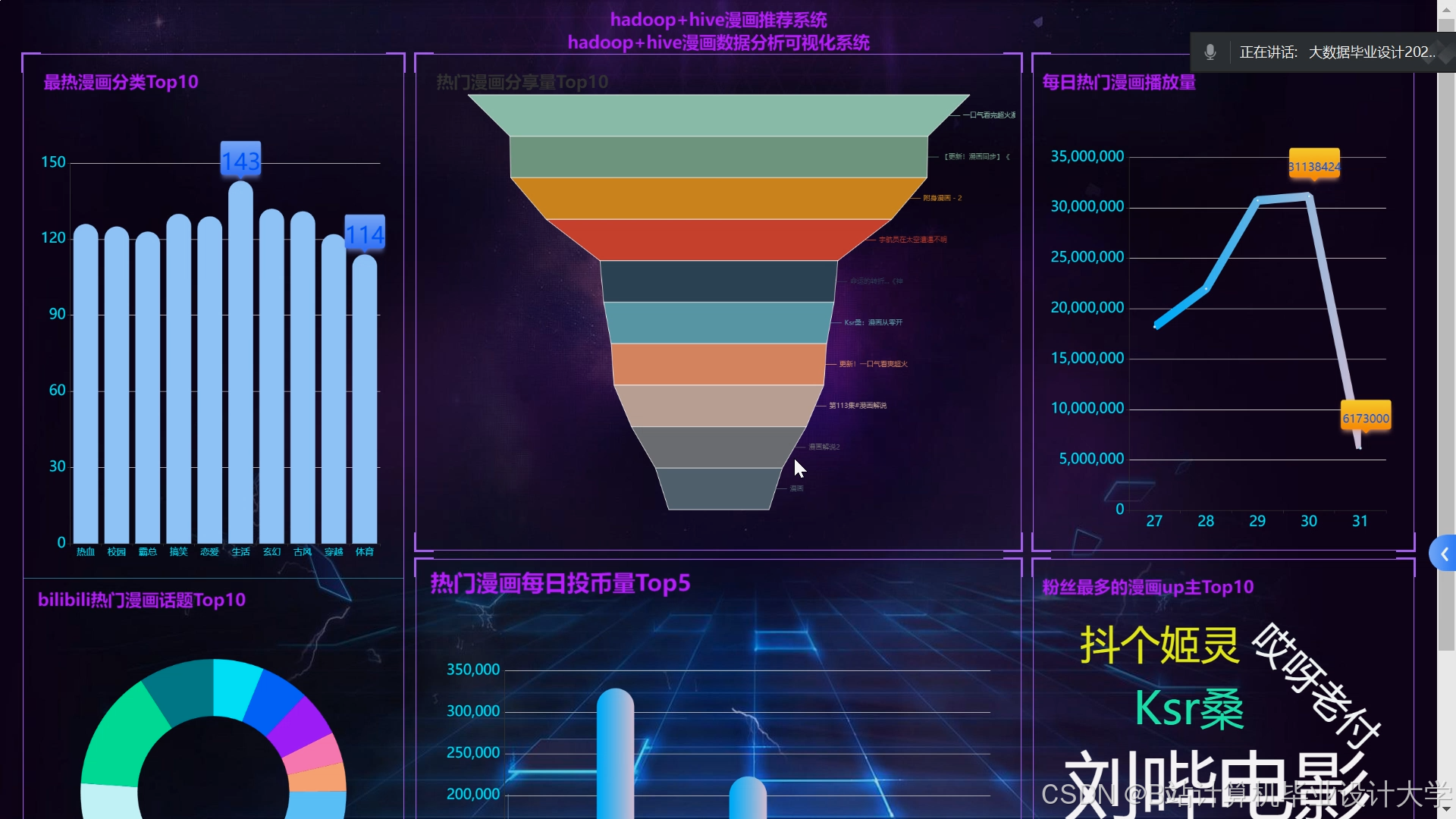
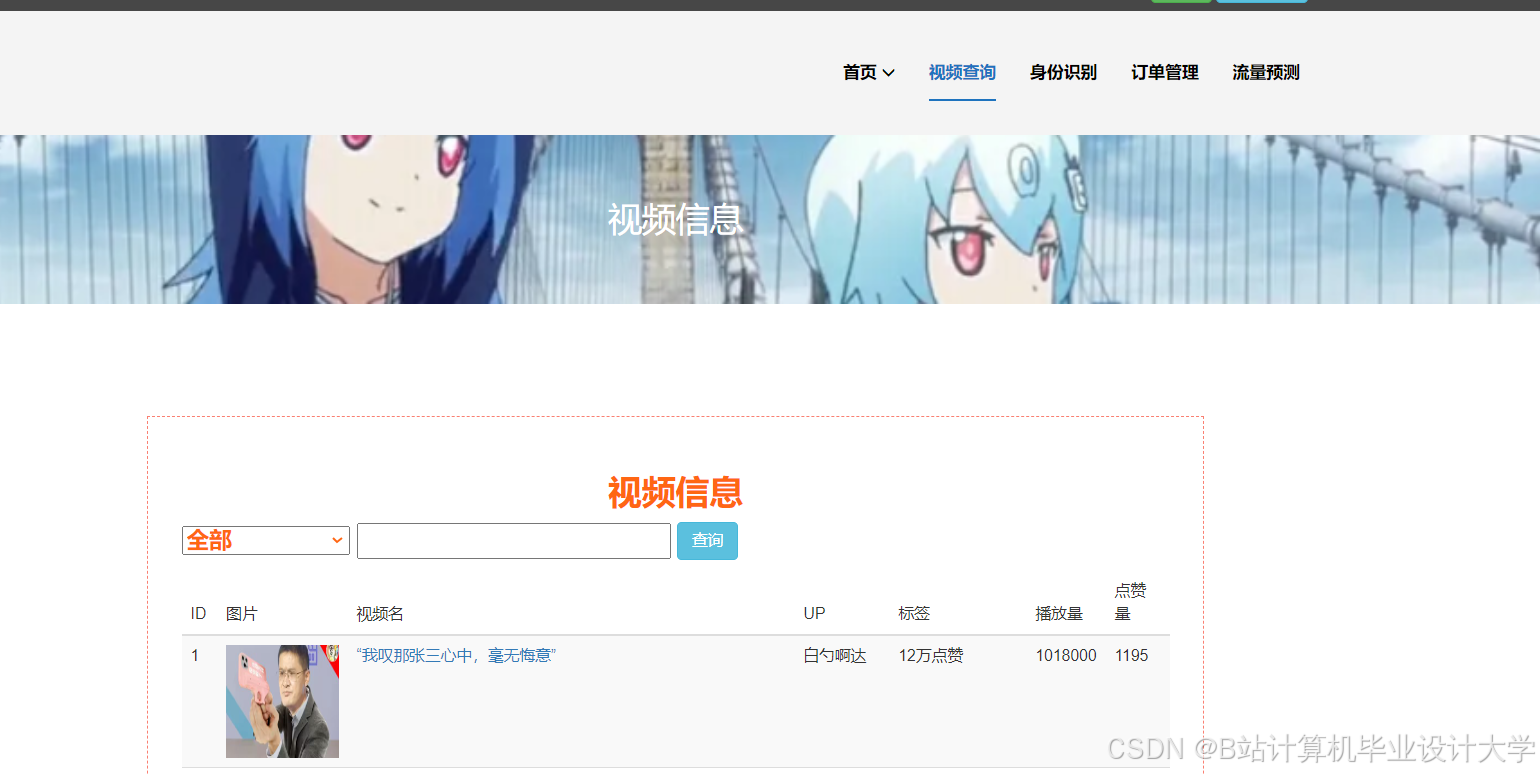
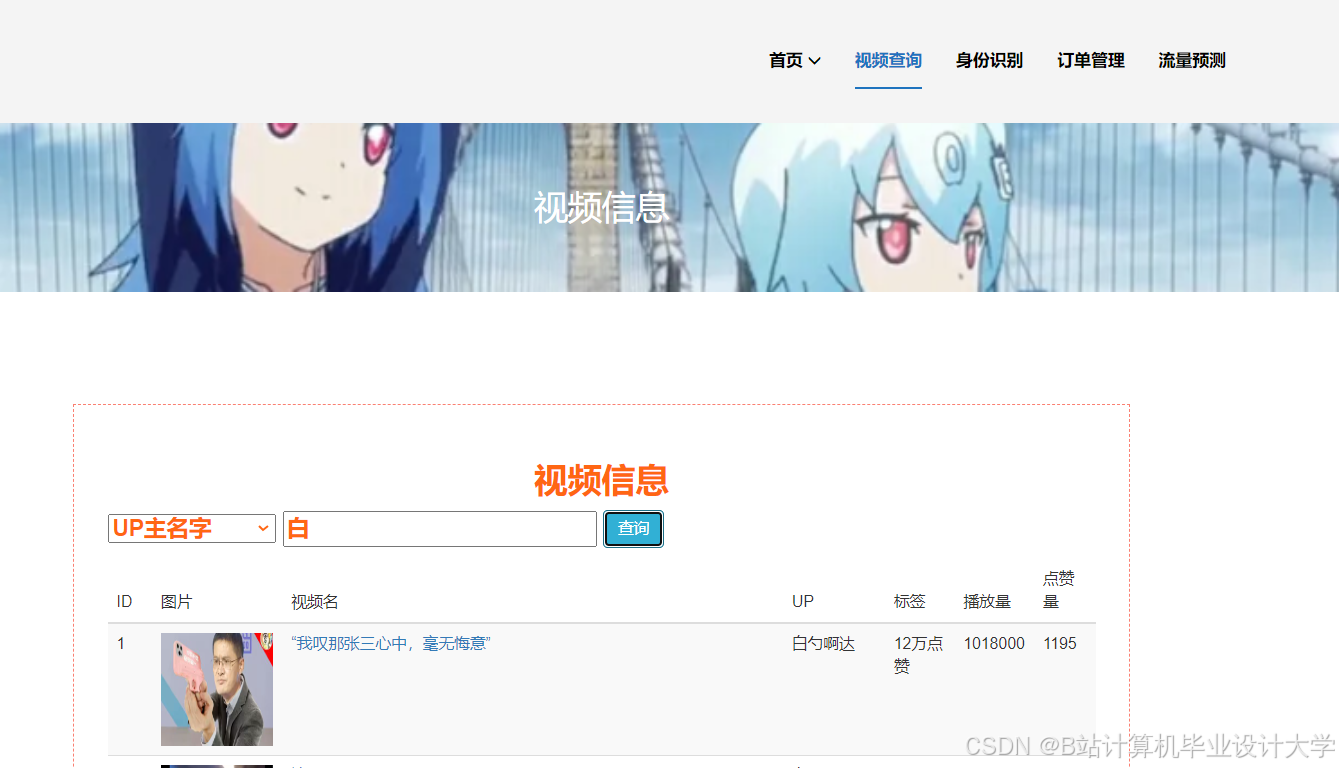
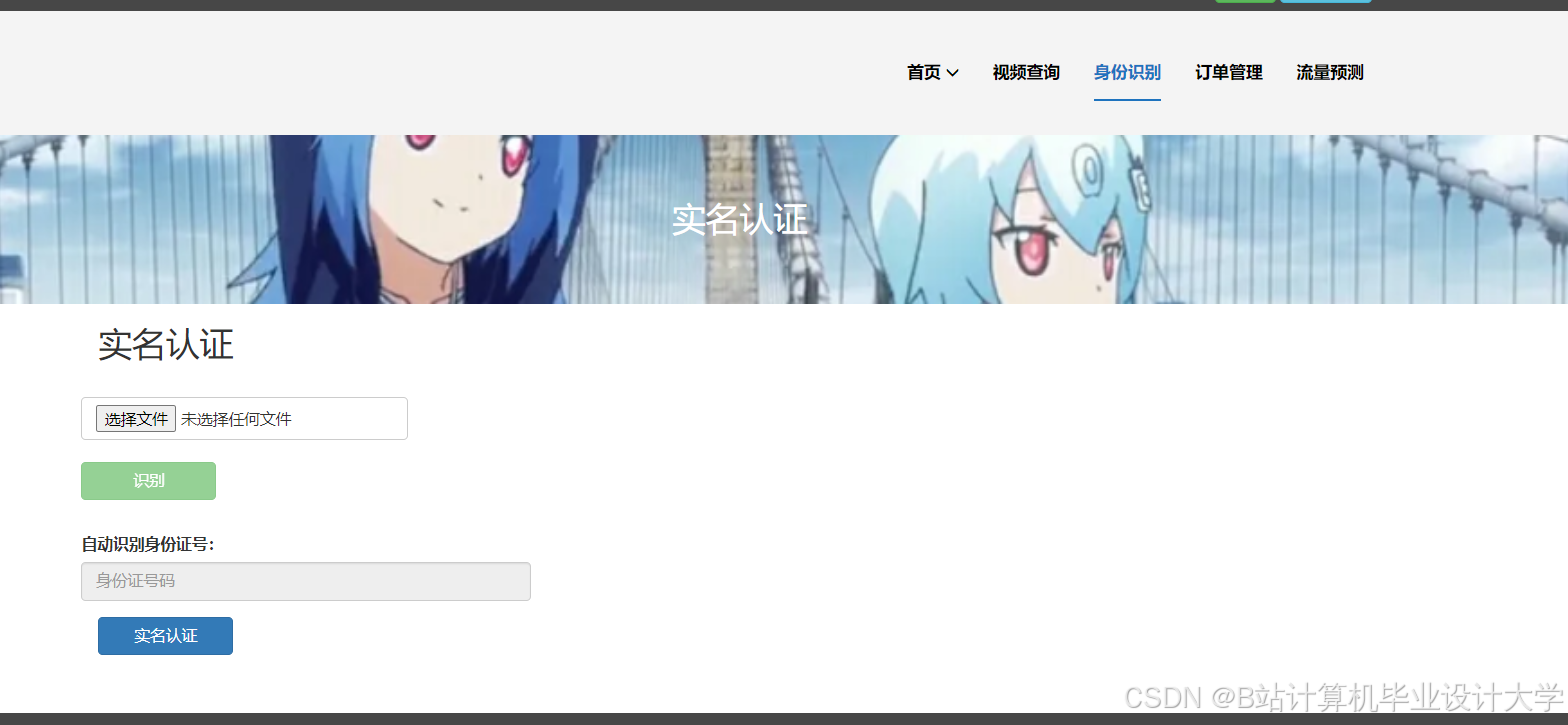
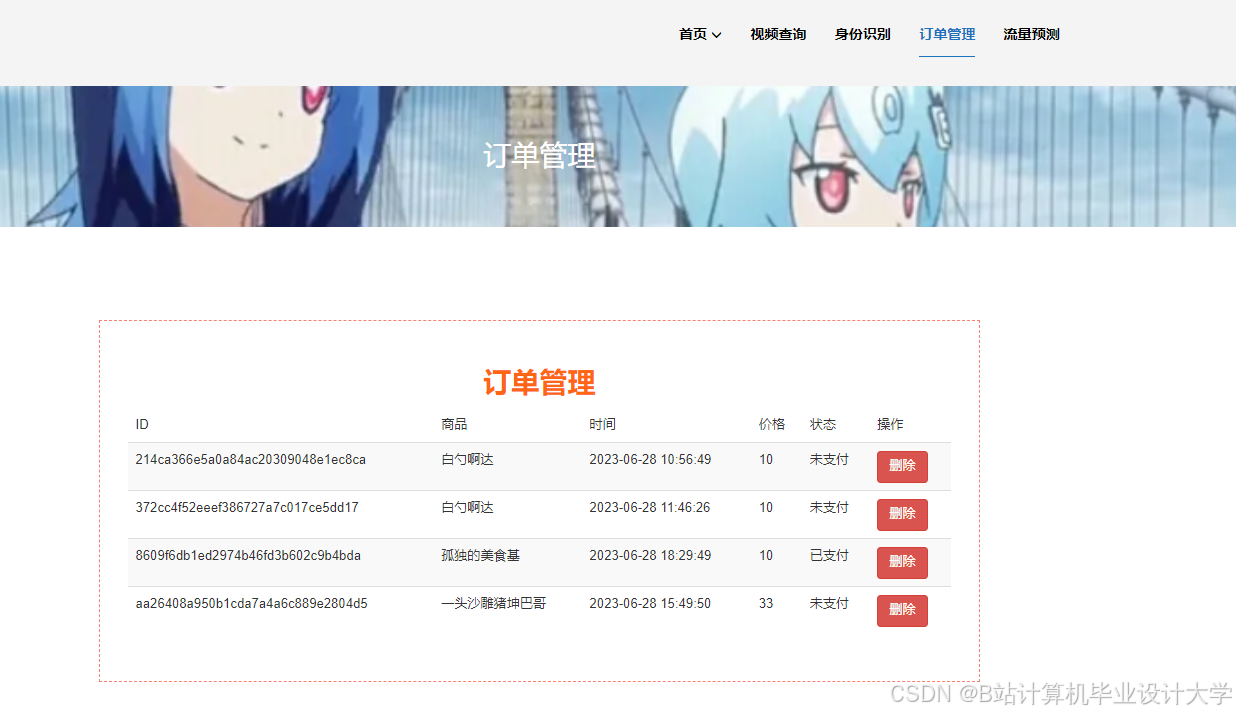
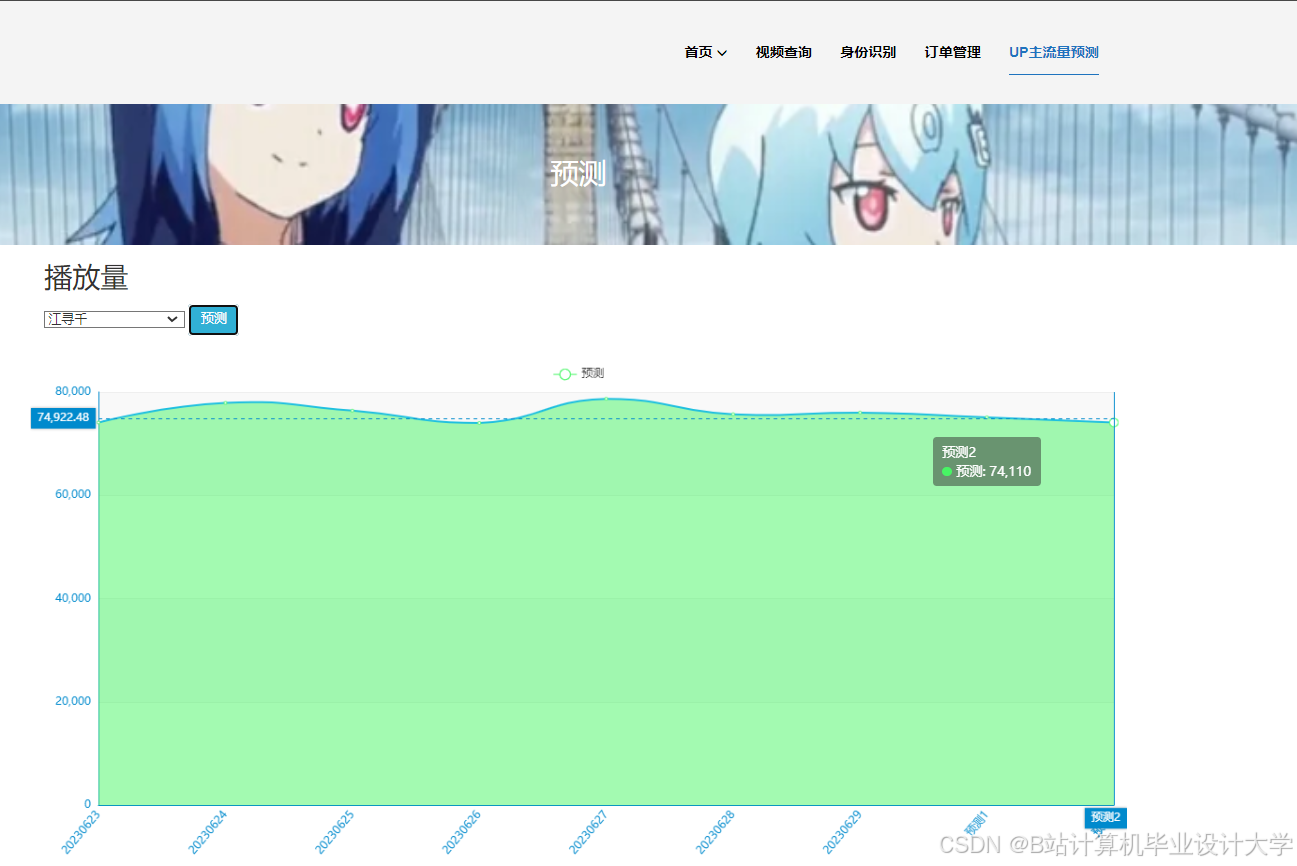
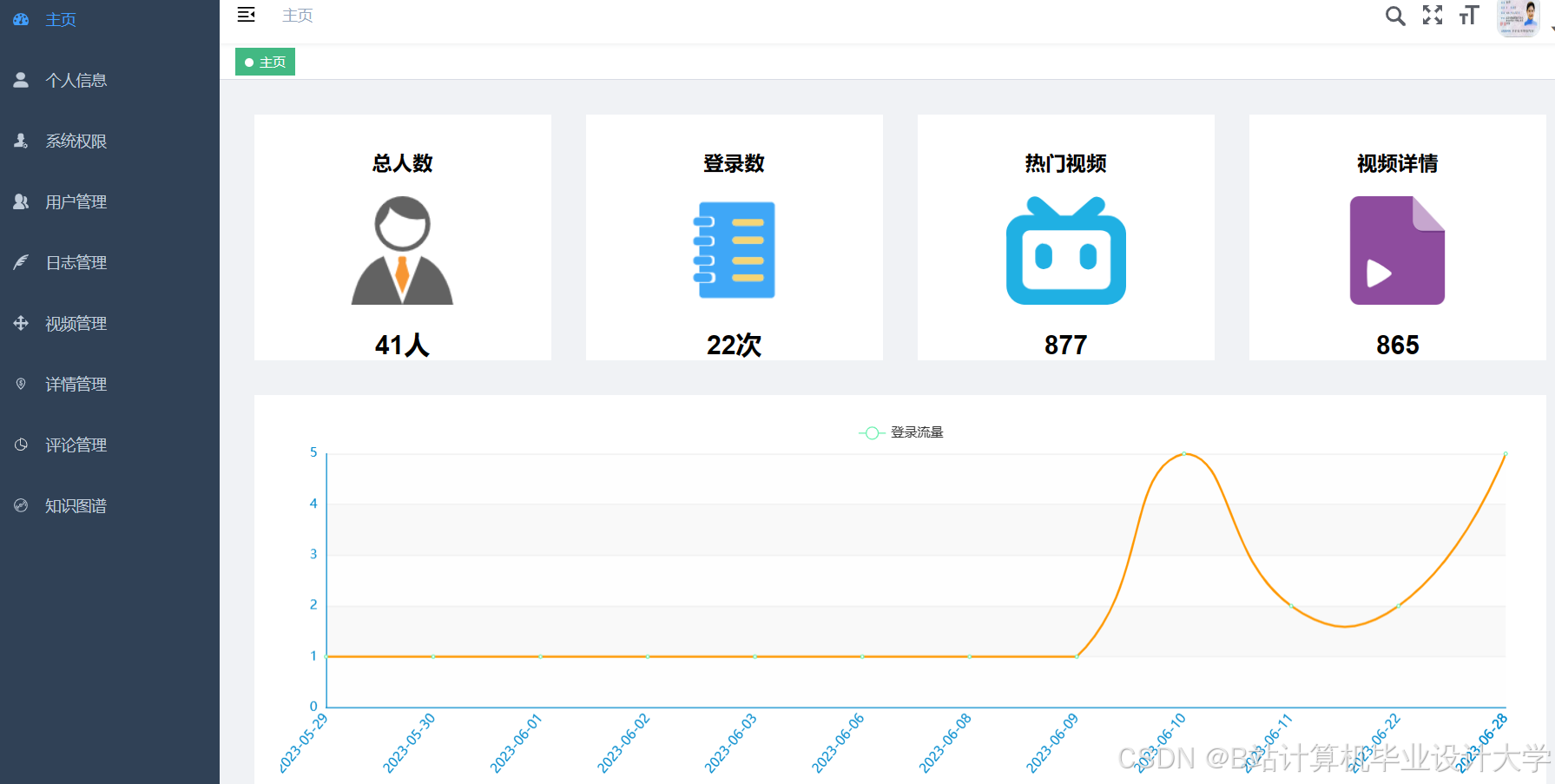
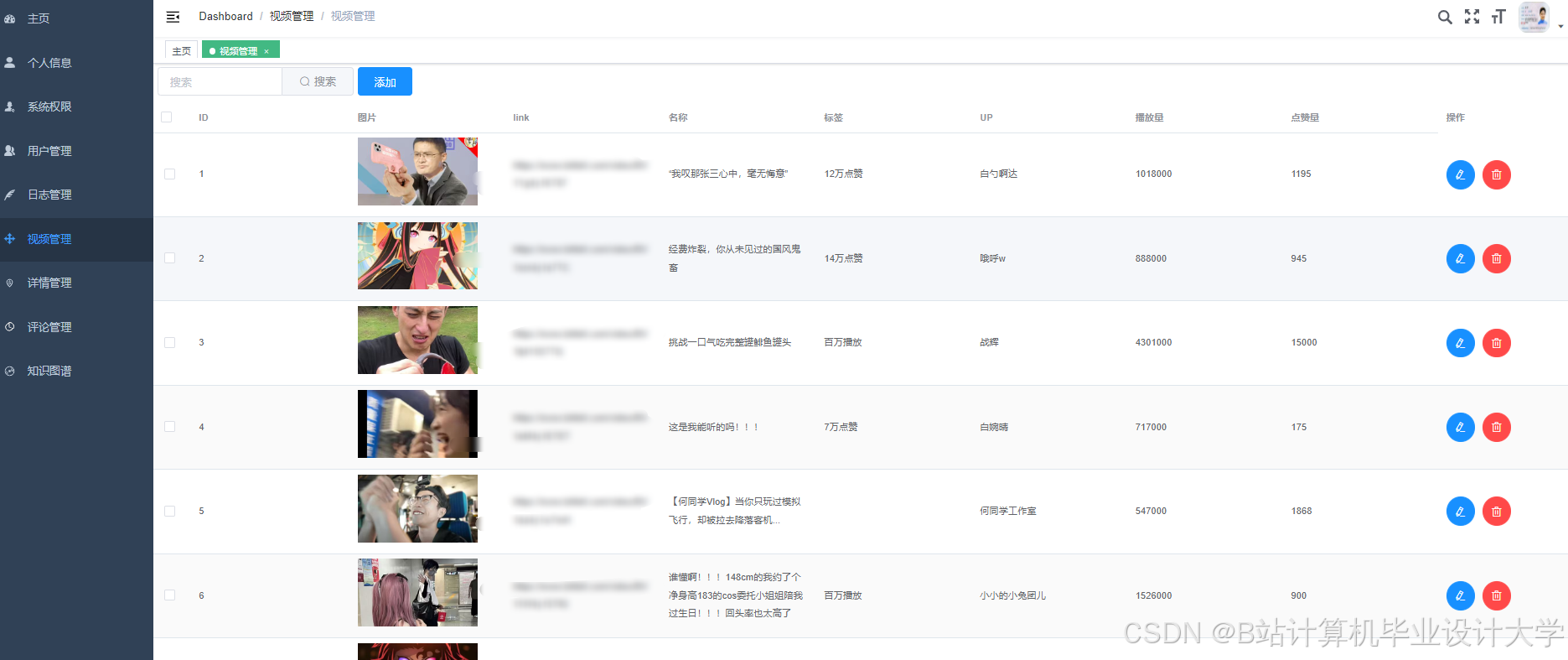
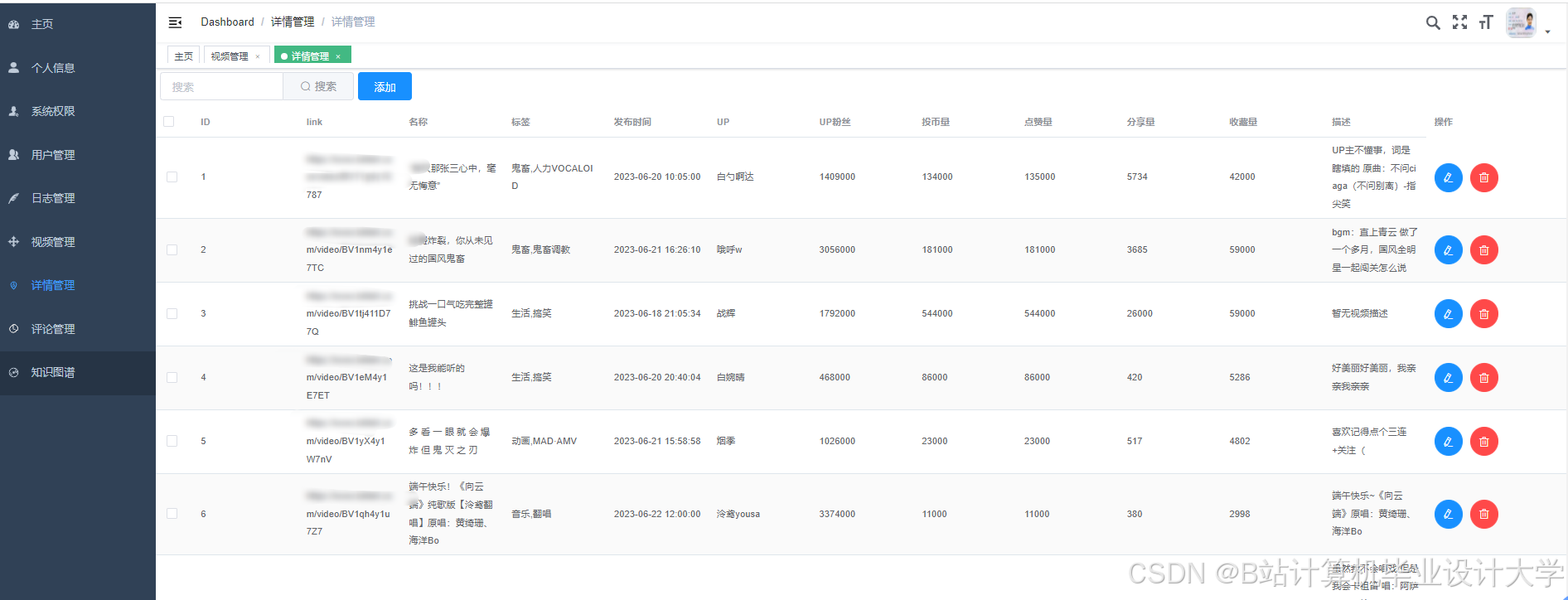
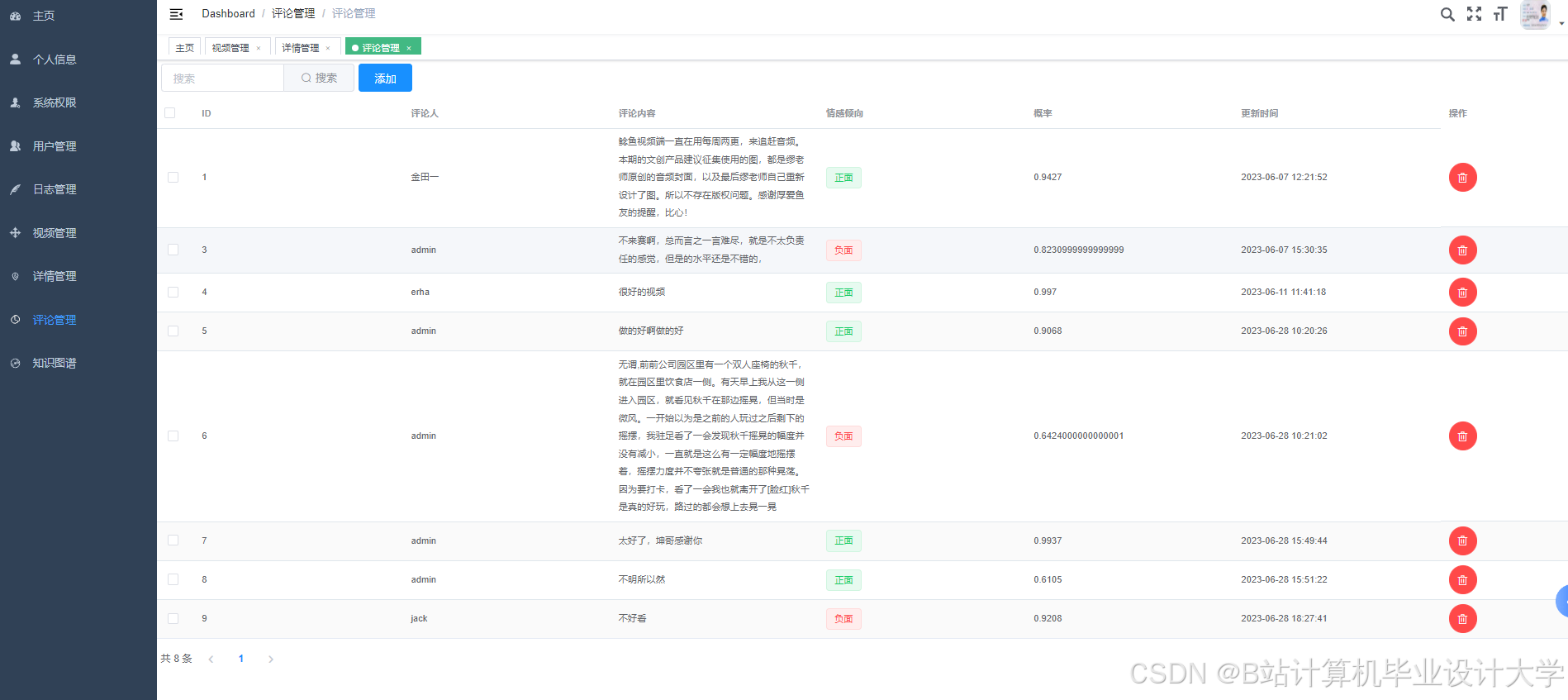
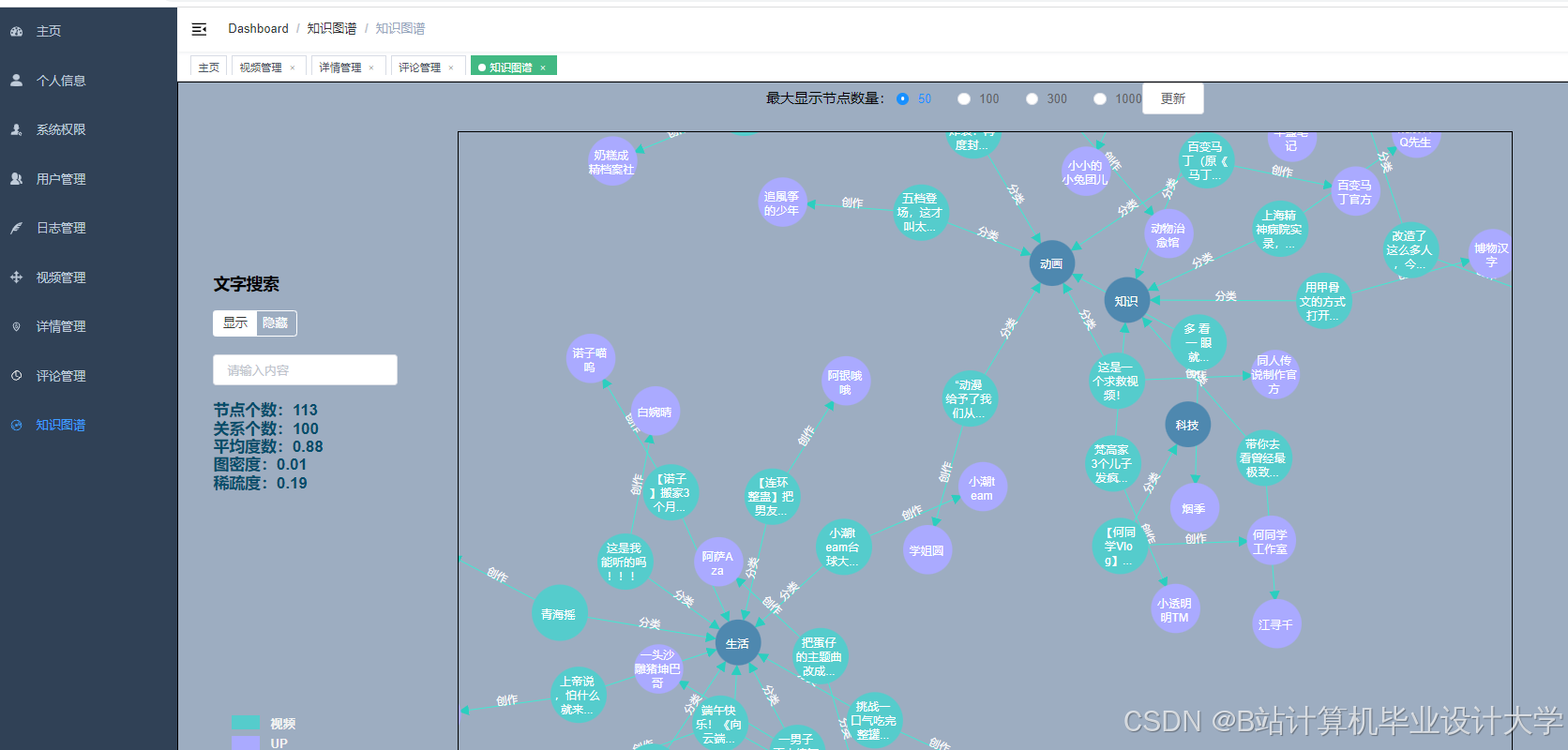
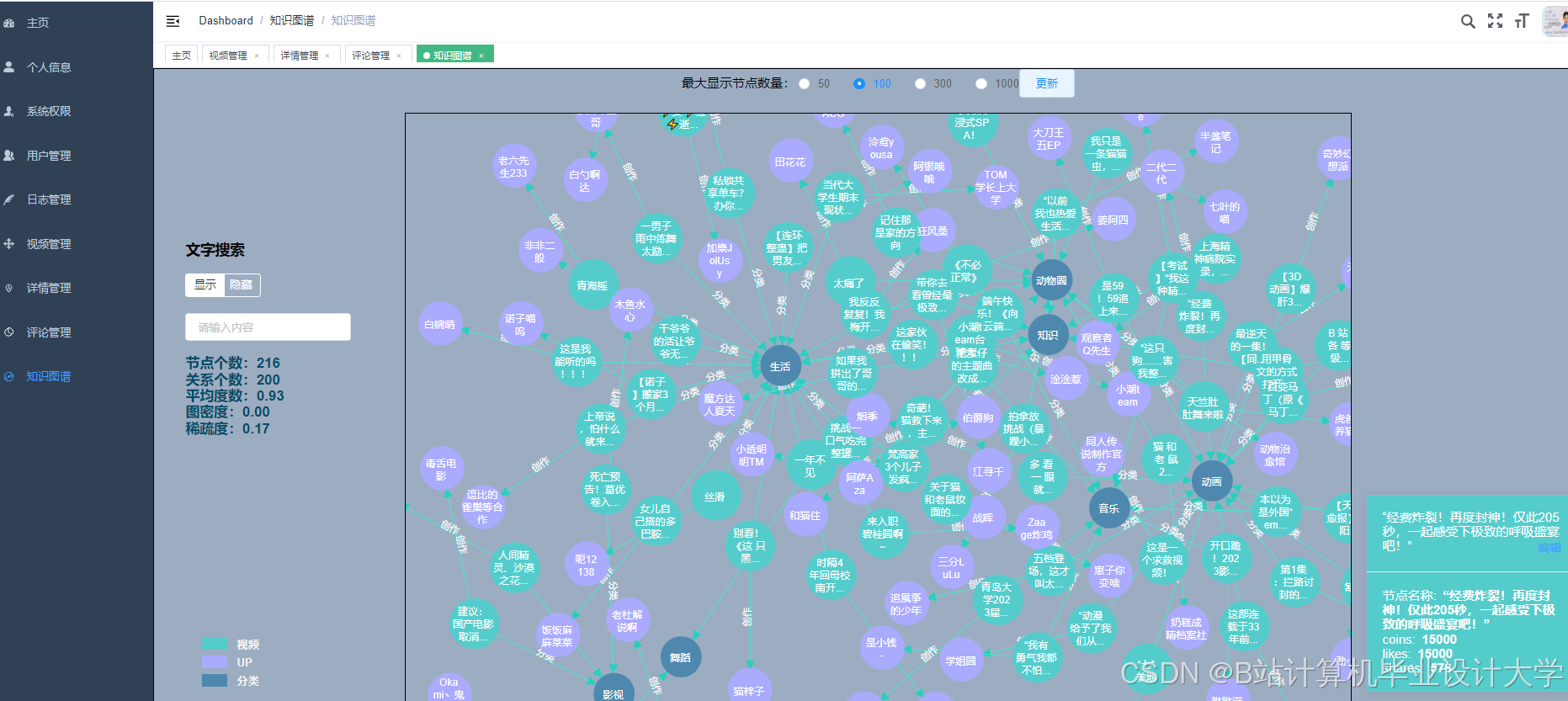
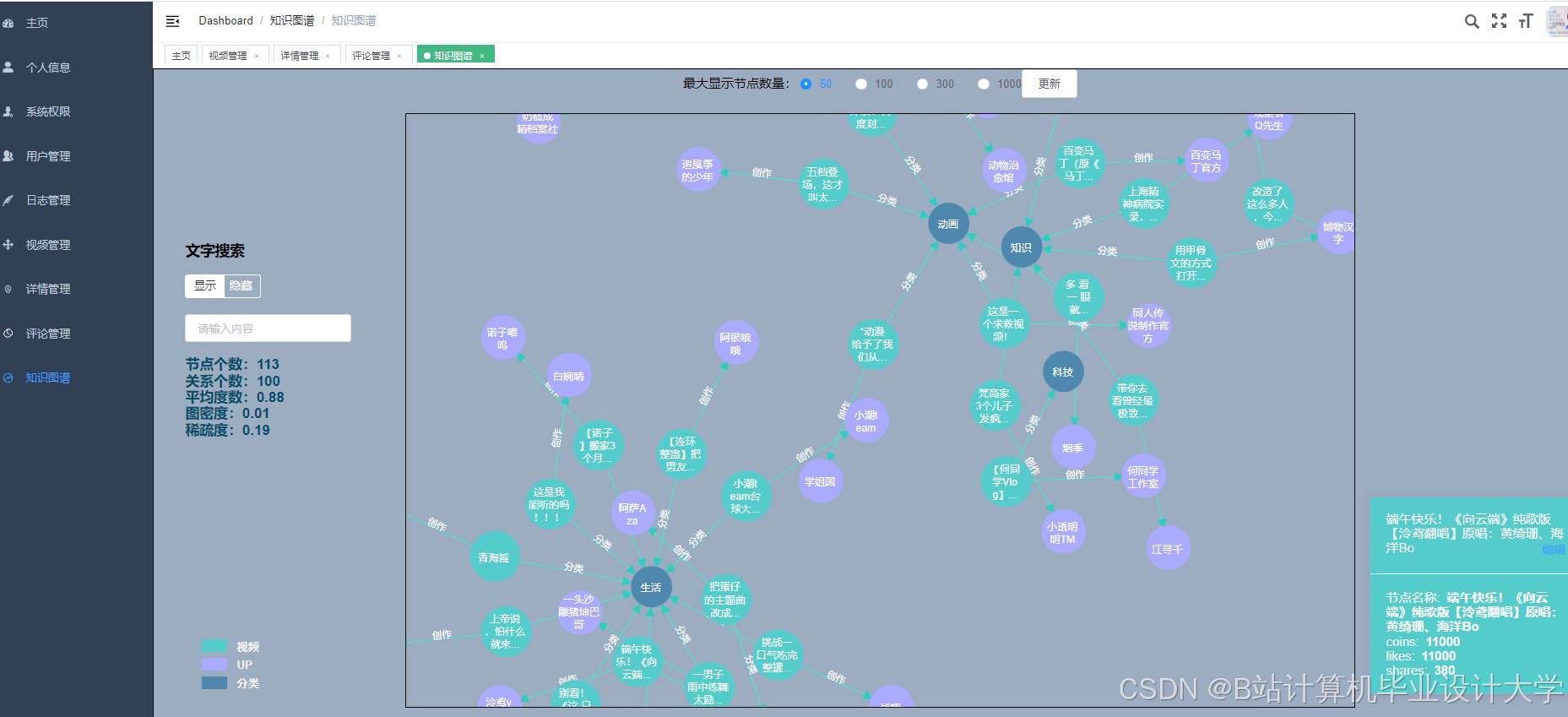
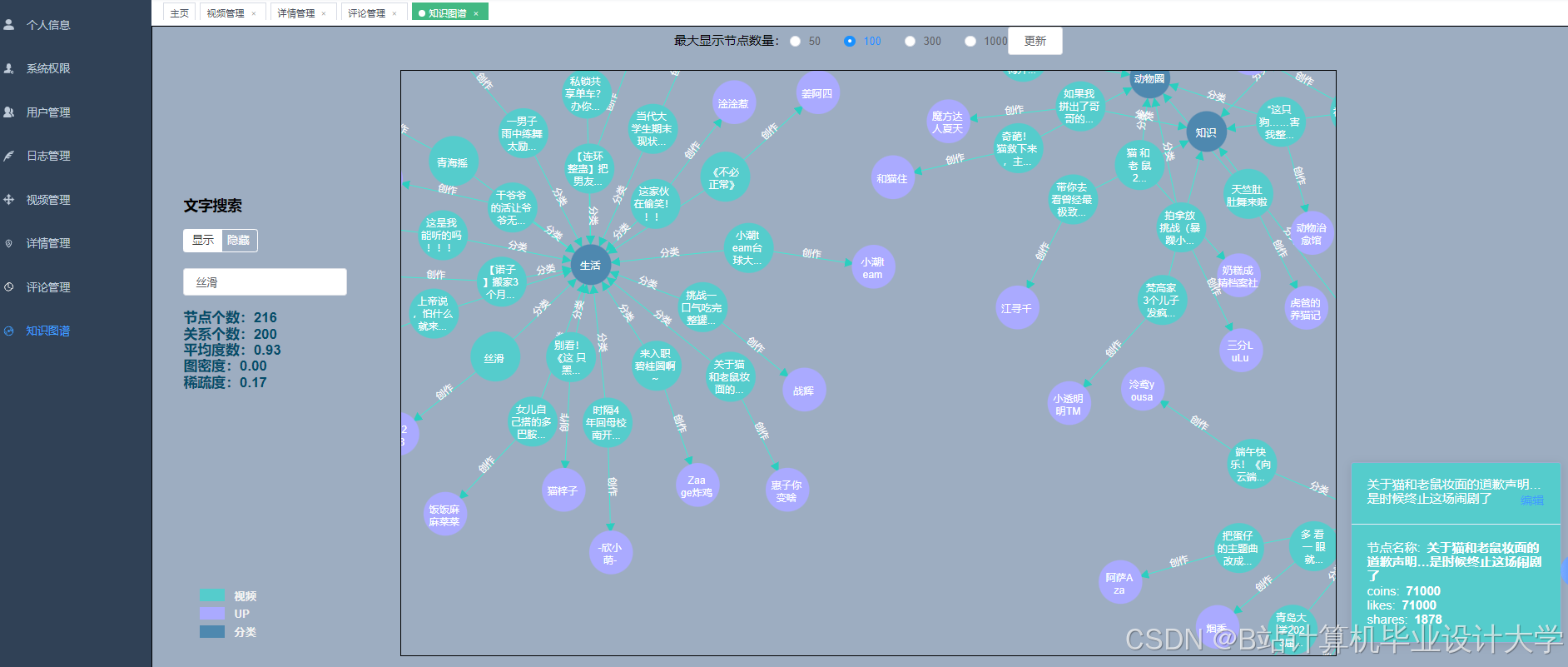
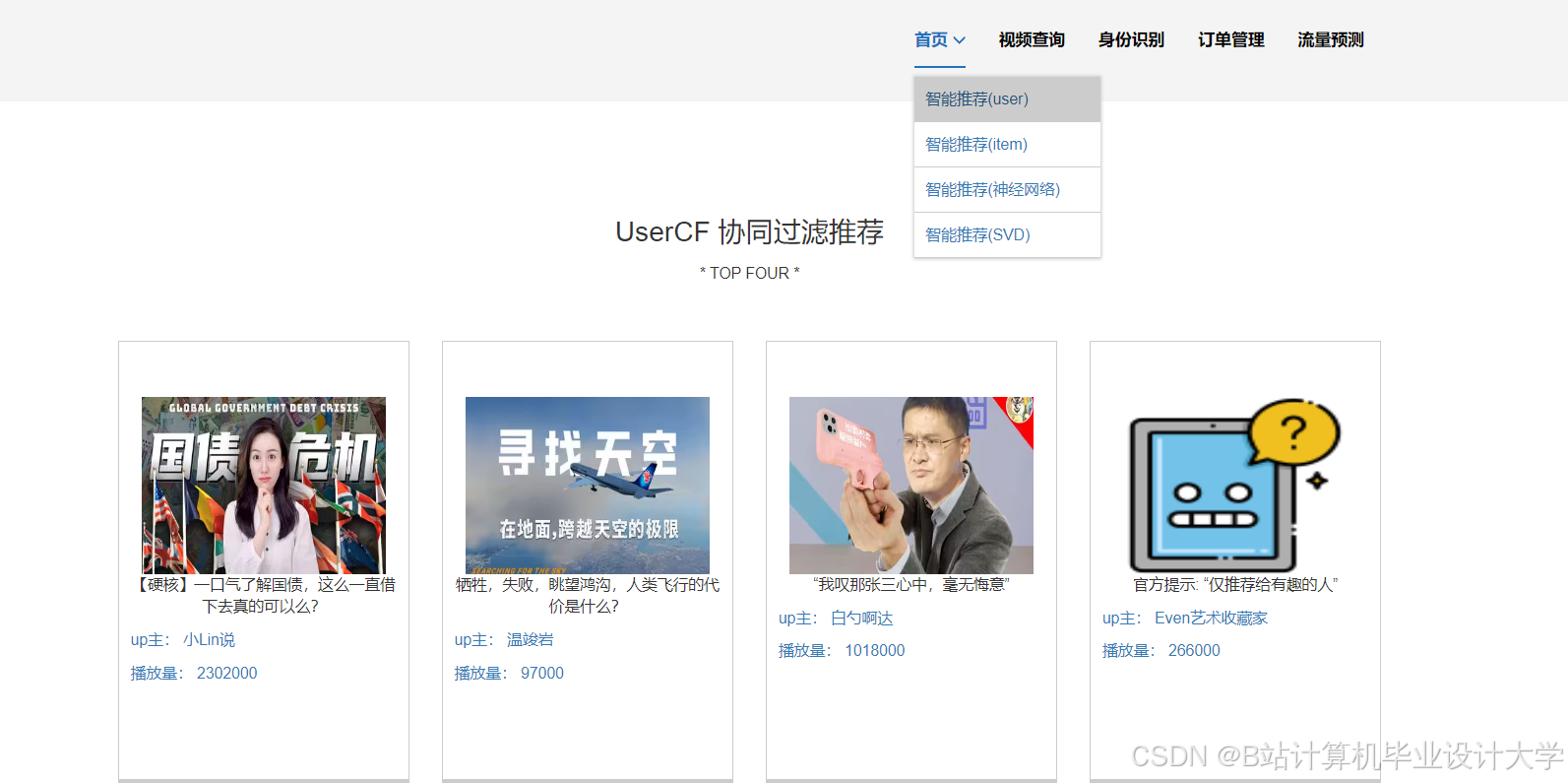
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 725
725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











