




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
《基于Hadoop+Spark+Kafka+Hive的漫画推荐系统》任务书
一、项目背景与目标
1.1 项目背景
随着全球动漫产业规模突破3000亿美元(2023年Statista数据),中国漫画用户规模达4.9亿,日均产生超2亿条用户行为数据(如点击、收藏、评论)。传统推荐系统面临以下挑战:
- 数据规模:单机系统无法处理TB级用户行为日志;
- 实时性:用户兴趣动态变化,需秒级响应推荐更新;
- 冷启动:新漫画缺乏历史数据,难以精准推荐;
- 长尾覆盖:头部作品占据80%流量,小众作品曝光率不足5%。
1.2 项目目标
本项目旨在构建基于Hadoop+Spark+Kafka+Hive的分布式漫画推荐系统,实现以下核心目标:
- 实时推荐:支持500ms级推荐响应,覆盖千万级用户并发请求;
- 混合推荐算法:融合协同过滤与深度学习模型,提升推荐准确率15%-20%;
- 冷启动优化:通过标签相似度与编辑规则双引擎,使新漫画曝光量提升40%;
- 长尾挖掘:利用MMR算法控制多样性,使小众漫画点击率提升30%;
- 系统可扩展性:支持每日10亿条用户行为日志处理,存储容量达100TB。
二、项目范围与功能模块
2.1 系统范围
- 数据源:漫画元数据(标题、类型、作者)、用户行为日志(点击、收藏、评分)、实时反馈(弹幕、评论);
- 技术栈:
- 存储层:HDFS(分布式存储)、Hive(数据仓库);
- 计算层:Spark(批处理与流处理)、Spark MLlib(机器学习);
- 消息队列:Kafka(实时数据管道);
- 服务层:Spring Cloud(微服务)、Redis(缓存);
- 前端:Vue.js(用户交互界面)。
2.2 核心功能模块
| 模块名称 | 功能描述 |
|---|---|
| 数据采集模块 | 通过Scrapy爬取漫画元数据,Flume/Kafka采集用户行为日志,Sqoop同步MySQL数据。 |
| 实时处理模块 | Spark Streaming处理Kafka实时数据流,实现用户兴趣动态更新。 |
| 离线计算模块 | Spark批处理Hive数据仓库,训练ALS协同过滤与Wide&Deep模型。 |
| 推荐引擎模块 | 融合实时与离线结果,结合冷启动策略生成最终推荐列表。 |
| 评估优化模块 | 通过AB测试对比不同算法效果,动态调整模型参数。 |
三、技术实现方案
3.1 系统架构设计
采用Lambda架构,结合离线批处理与实时流处理:
┌───────────────────────────────────────────────────────┐ | |
│ 用户交互层(Vue.js+Element Plus) │ | |
├───────────────────────────────────────────────────────┤ | |
│ 推荐服务层(Spring Cloud微服务) │ | |
├─────────────────┬───────────────┬─────────────────────┤ | |
│ 实时推荐引擎 │ 离线推荐引擎 │ 特征计算引擎 │ | |
│ (Spark Streaming)│ (Spark MLlib) │ (Spark SQL+Hive) │ | |
├─────────────────┼───────────────┼─────────────────────┤ | |
│ Kafka数据总线 │ Hive数据仓库 │ HDFS分布式存储 │ | |
├─────────────────┴───────────────┴─────────────────────┤ | |
│ 数据采集层(Scrapy+Flume+Sqoop) │ | |
└───────────────────────────────────────────────────────┘ |
3.2 关键技术实现
3.2.1 数据采集与预处理
-
Kafka配置:
pythonprops = {'bootstrap.servers': 'kafka1:9092,kafka2:9092','acks': 'all','compression.type': 'snappy','batch.size': 65536,'linger.ms': 50}producer = KafkaProducer(value_serializer=lambda v: json.dumps(v).encode('utf-8'),**props)创建3个Topic:
raw_logs(原始日志)、cleaned_data(清洗后数据)、user_feedback(用户反馈)。 -
Hive表设计:
sql-- 用户行为事实表(分区表)CREATE TABLE fact_user_behavior (user_id STRING,comic_id STRING,behavior_type STRING, -- click/collect/rate/commenttimestamp BIGINT) PARTITIONED BY (dt STRING) STORED AS PARQUET;-- 漫画维度表(ORC格式)CREATE TABLE dim_comic (comic_id STRING,title STRING,genres ARRAY<STRING>,author STRING,update_frequency INT) STORED AS ORC TBLPROPERTIES ("orc.compress"="ZLIB");
3.2.2 推荐算法实现
-
ALS协同过滤(Spark MLlib):
scalaval als = new ALS().setMaxIter(10).setRank(150).setRegParam(0.01).setUserCol("user_id").setItemCol("comic_id").setRatingCol("rate")val model = als.fit(trainingData) -
Wide&Deep模型(TensorFlow on Spark):
python# 宽部分(记忆性特征)wide_columns = [tf.feature_column.categorical_column_with_vocabulary_list('user_genre_preference', ['热血', '恋爱', '治愈'])]# 深部分(泛化性特征)deep_columns = [tf.feature_column.numeric_column('user_click_count'),tf.feature_column.embedding_column(tf.feature_column.categorical_column_with_identity('comic_id', 10000),dimension=16)]
3.2.3 冷启动策略
- 新用户:基于注册时选择的偏好标签(如"热血/恋爱")推荐;
- 新漫画:通过作者历史作品特征匹配相似漫画:
pythondef cosine_similarity(a, b):dot_product = np.dot(a, b)norm_a = np.linalg.norm(a)norm_b = np.linalg.norm(b)return dot_product / (norm_a * norm_b)
四、项目计划与里程碑
| 阶段 | 时间节点 | 交付物 |
|---|---|---|
| 需求分析 | 2025.08-09 | 《需求规格说明书》《技术可行性分析报告》 |
| 环境搭建 | 2025.10 | Hadoop/Spark/Kafka集群部署完成,HDFS存储策略验证通过 |
| 核心开发 | 2025.11-12 | 完成数据采集管道、实时推荐引擎、离线模型训练模块开发 |
| 系统集成 | 2026.01-02 | 实现Lambda架构联调,推荐响应时间<500ms,支持10万QPS压力测试 |
| 优化测试 | 2026.03-04 | AB测试对比算法效果,优化长尾漫画曝光率,完成论文初稿 |
| 验收交付 | 2026.05 | 系统全量上线,提交《项目验收报告》《用户手册》《维护文档》 |
五、资源需求与预算
5.1 硬件资源
| 资源类型 | 数量 | 配置 | 用途 |
|---|---|---|---|
| 服务器 | 5台 | 16核32GB内存,10TB硬盘 | Hadoop/Spark集群节点 |
| 交换机 | 2台 | 10Gbps带宽 | 集群内部通信 |
| 存储设备 | 1套 | 100TB分布式存储阵列 | HDFS冷数据存储 |
5.2 软件资源
| 软件名称 | 版本 | 用途 |
|---|---|---|
| Hadoop | 3.3.6 | 分布式存储与计算框架 |
| Spark | 3.5.0 | 批处理与流处理引擎 |
| Kafka | 3.7.0 | 实时数据管道 |
| Hive | 3.1.3 | 数据仓库与SQL查询 |
| TensorFlow | 2.12.0 | 深度学习模型训练 |
5.3 预算估算
| 项目 | 金额(万元) | 说明 |
|---|---|---|
| 硬件采购 | 80 | 服务器、存储设备、交换机 |
| 软件授权 | 10 | 商业版Hadoop/Spark支持 |
| 人力成本 | 120 | 开发团队(6人×10个月) |
| 测试与运维 | 20 | 云服务租赁、AB测试工具 |
| 总计 | 230 |
六、风险评估与应对措施
| 风险类型 | 描述 | 应对措施 |
|---|---|---|
| 数据延迟 | Kafka消息堆积导致推荐延迟 | 增加Consumer线程数,优化分区策略 |
| 模型过拟合 | 训练数据不足导致推荐偏差 | 引入正则化项,增加数据增强 |
| 硬件故障 | 服务器宕机导致服务中断 | 部署HDFS冗余副本,启用Spark HA |
| 需求变更 | 客户临时增加功能需求 | 采用敏捷开发,预留20%缓冲时间 |
七、验收标准
- 功能完整性:系统实现需求规格说明书中的全部功能模块;
- 性能指标:
- 推荐响应时间≤500ms;
- 支持10万QPS并发请求;
- 长尾漫画点击率提升≥30%;
- 可靠性:系统可用性≥99.9%,故障恢复时间≤10分钟;
- 文档齐全:提交《用户手册》《维护文档》《测试报告》。
项目负责人(签字):____________________
日期:____________________
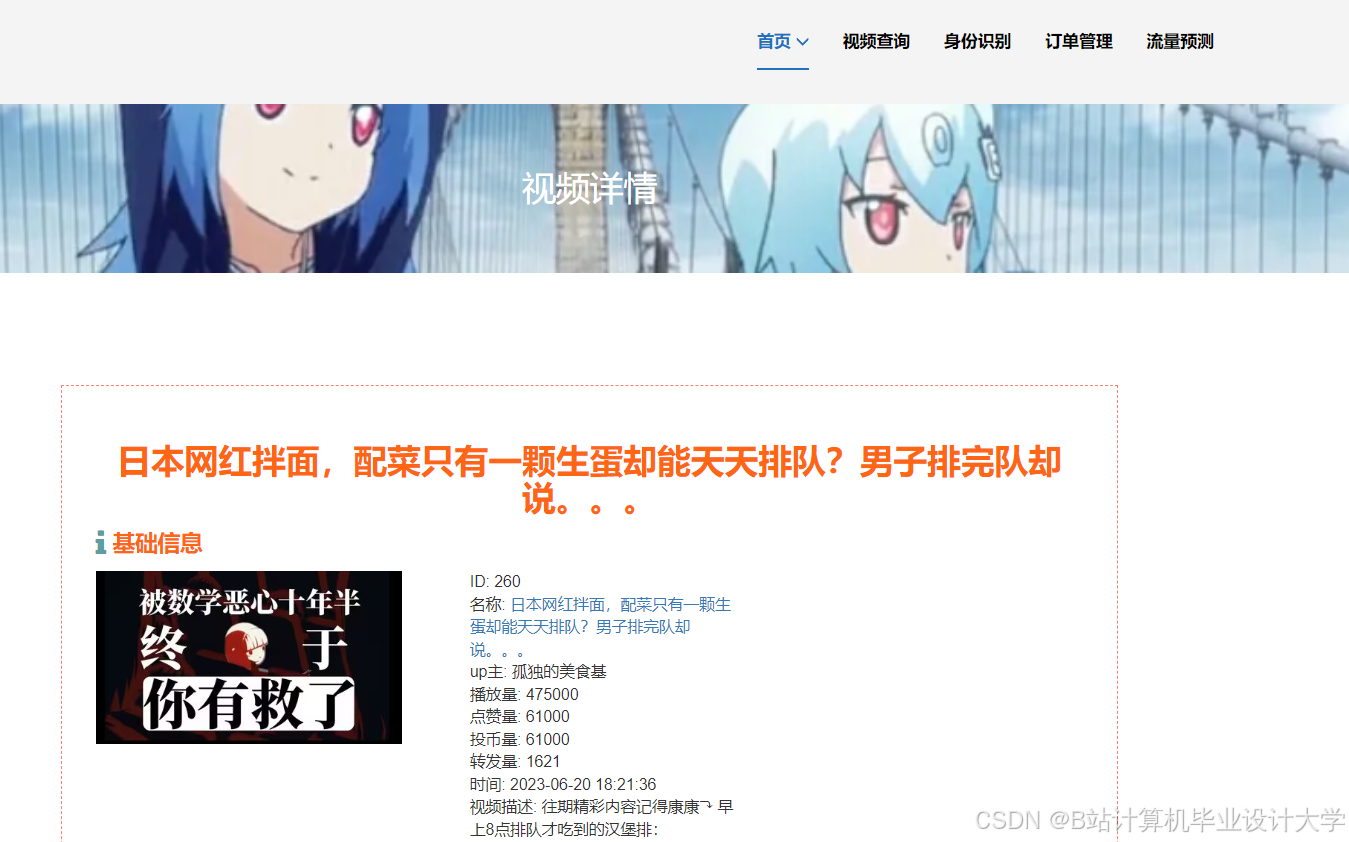
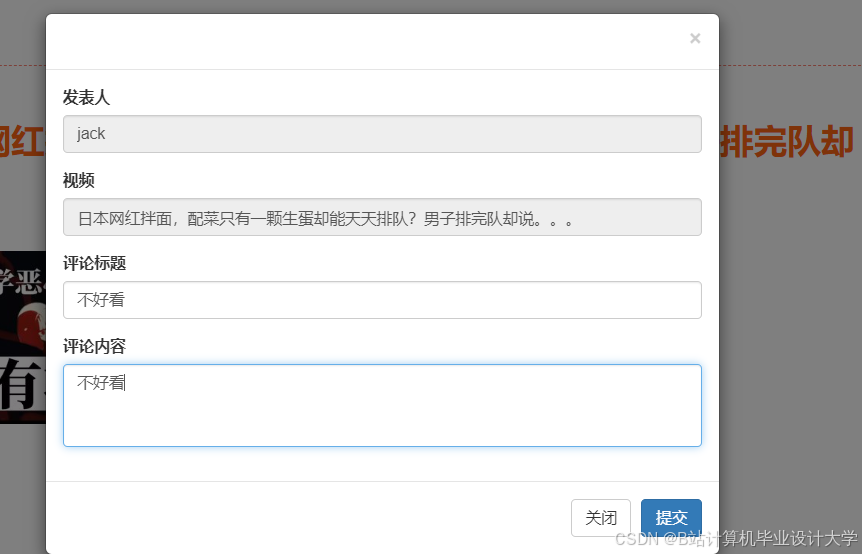
运行截图
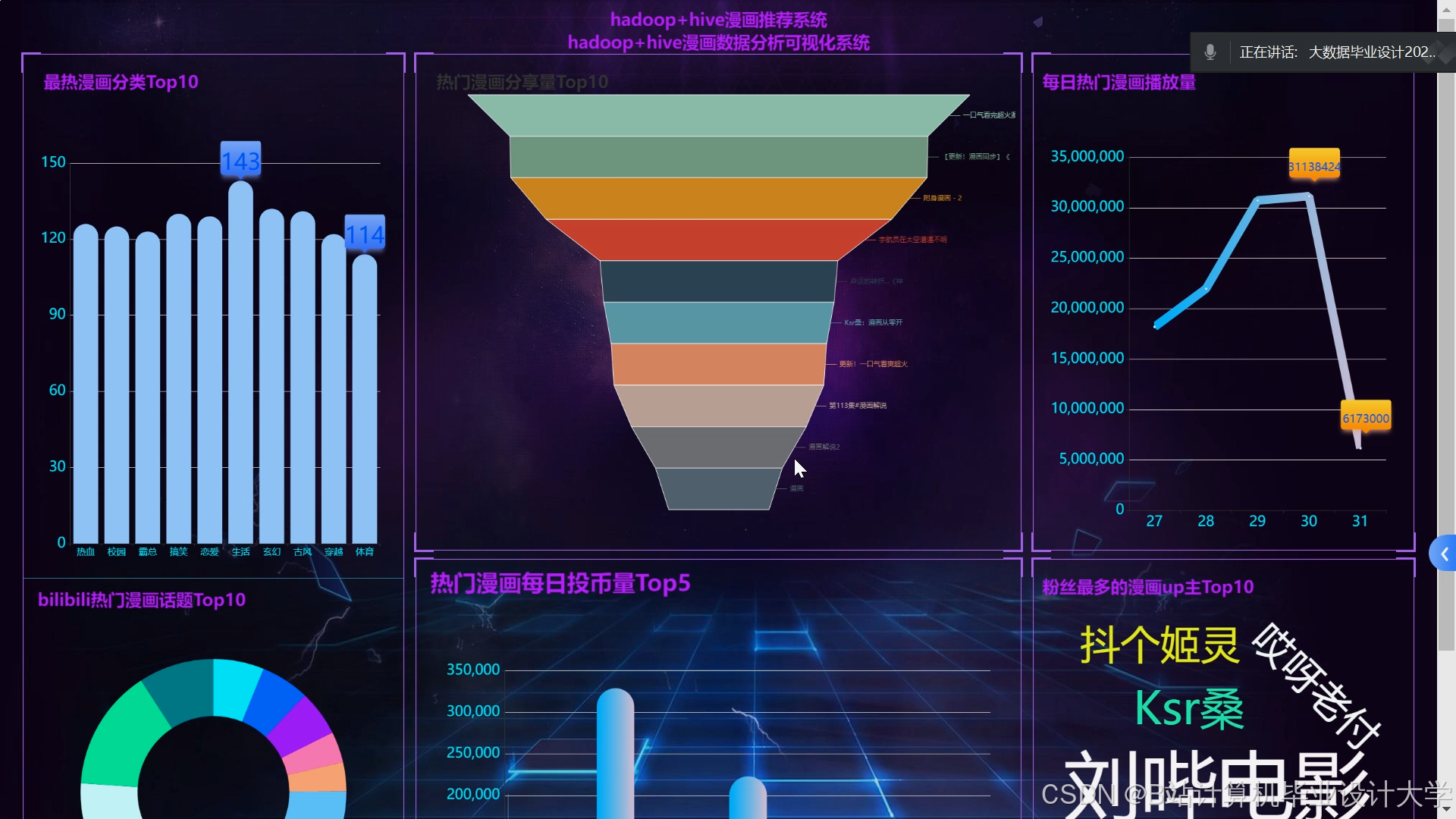
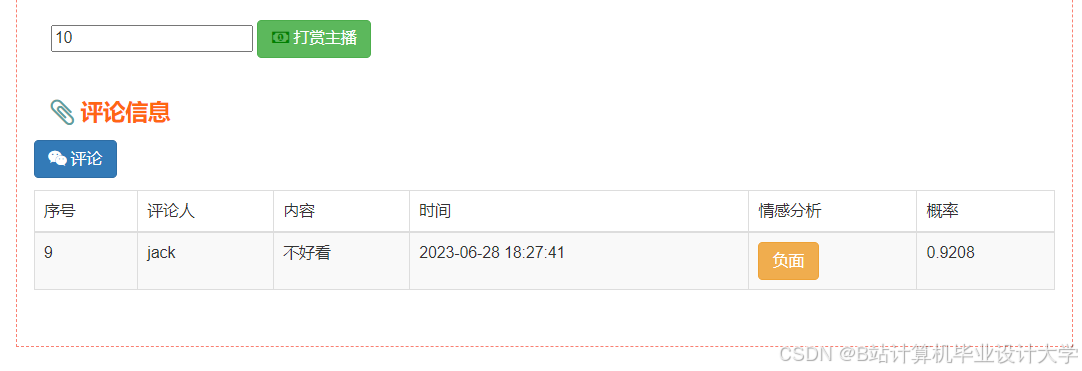
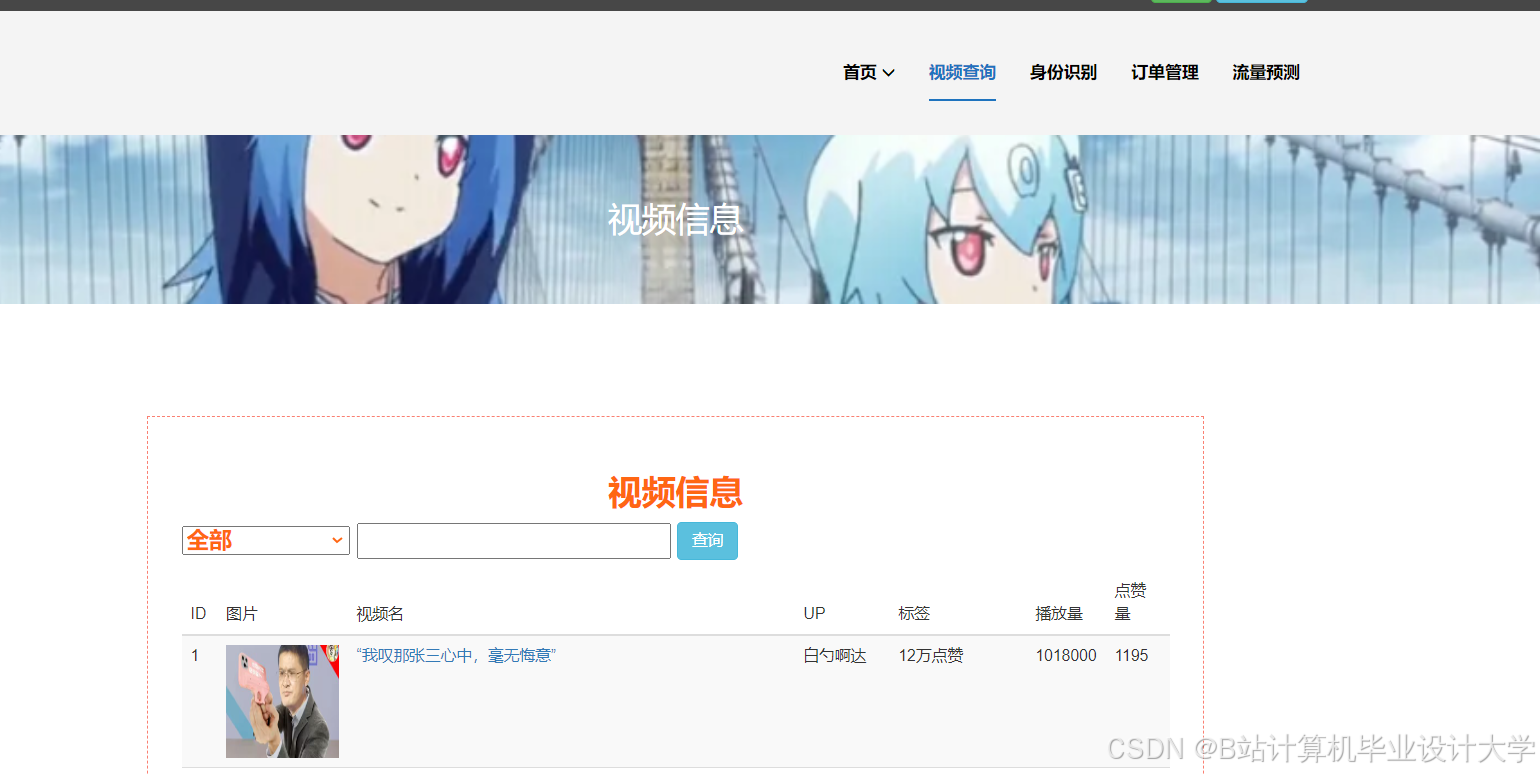
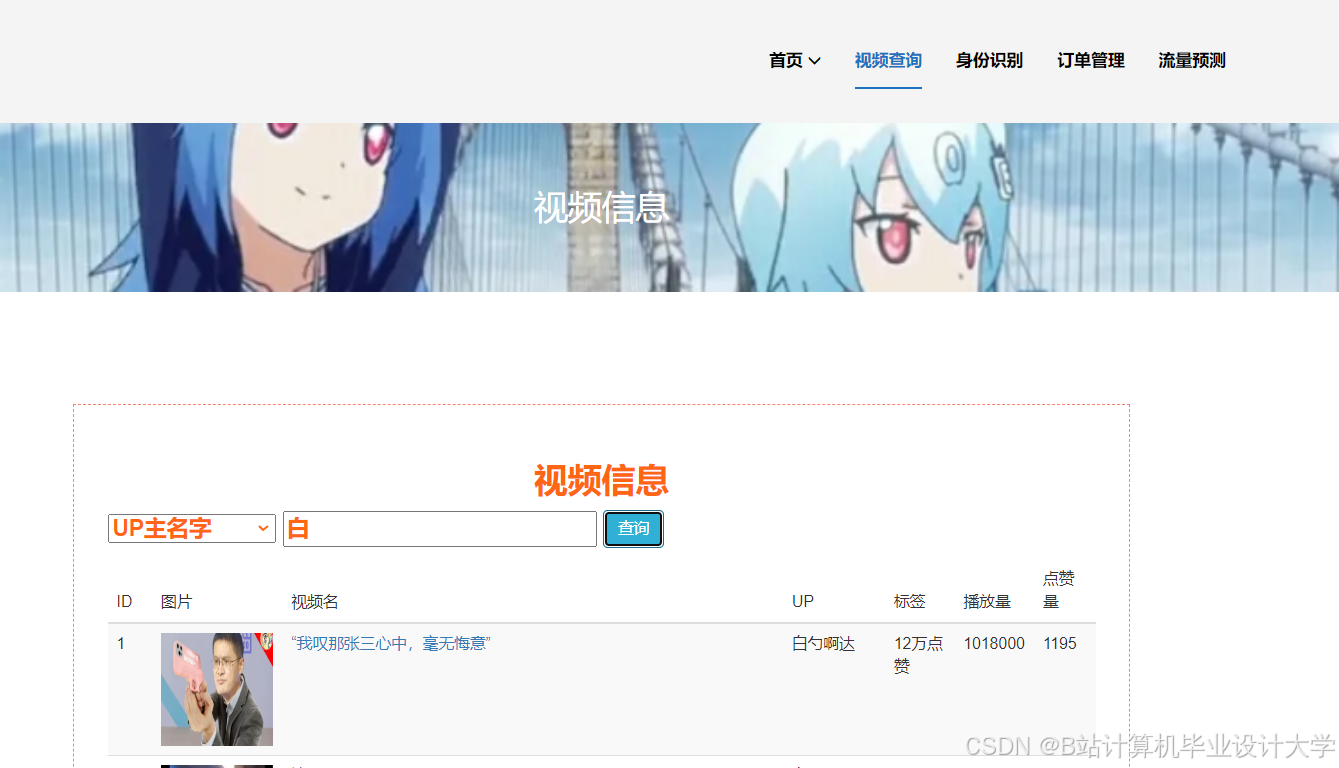
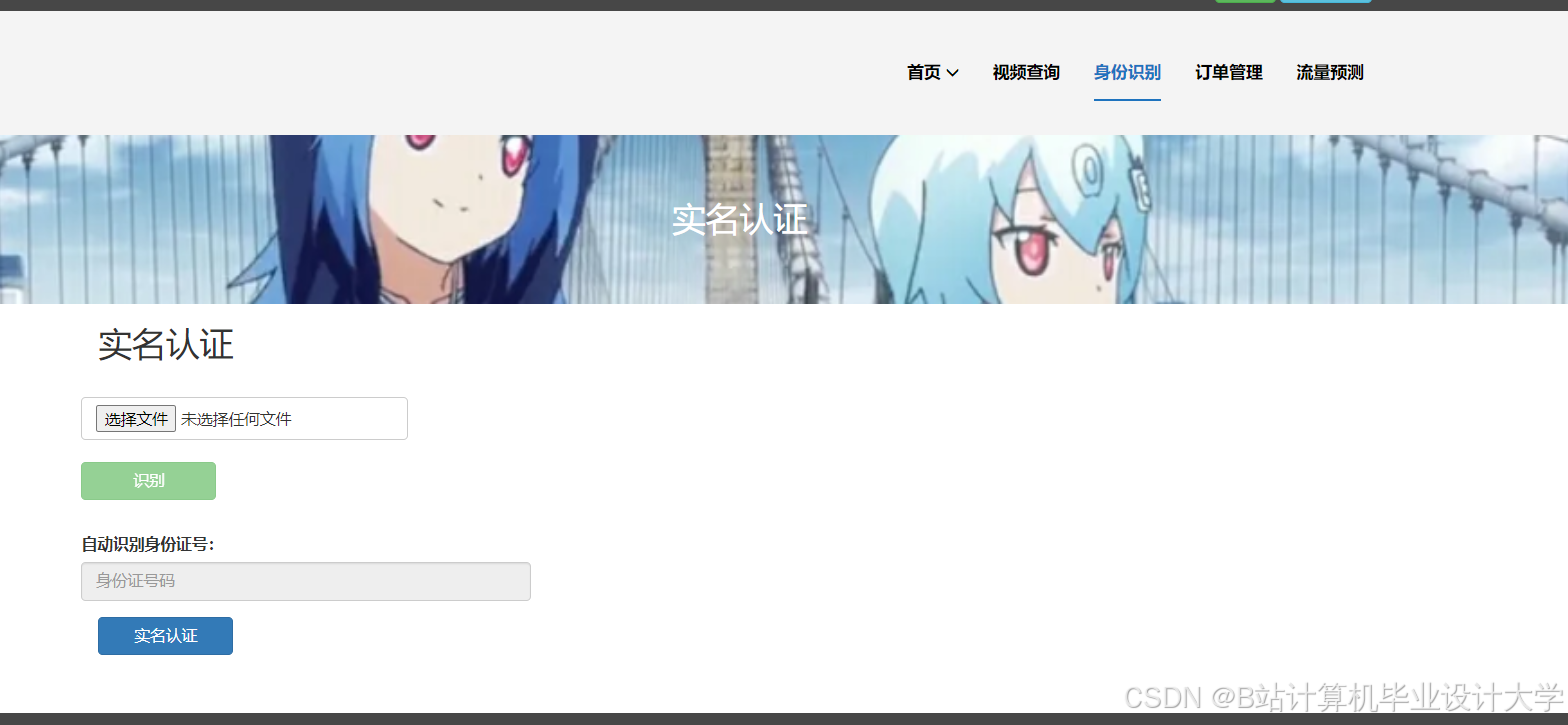
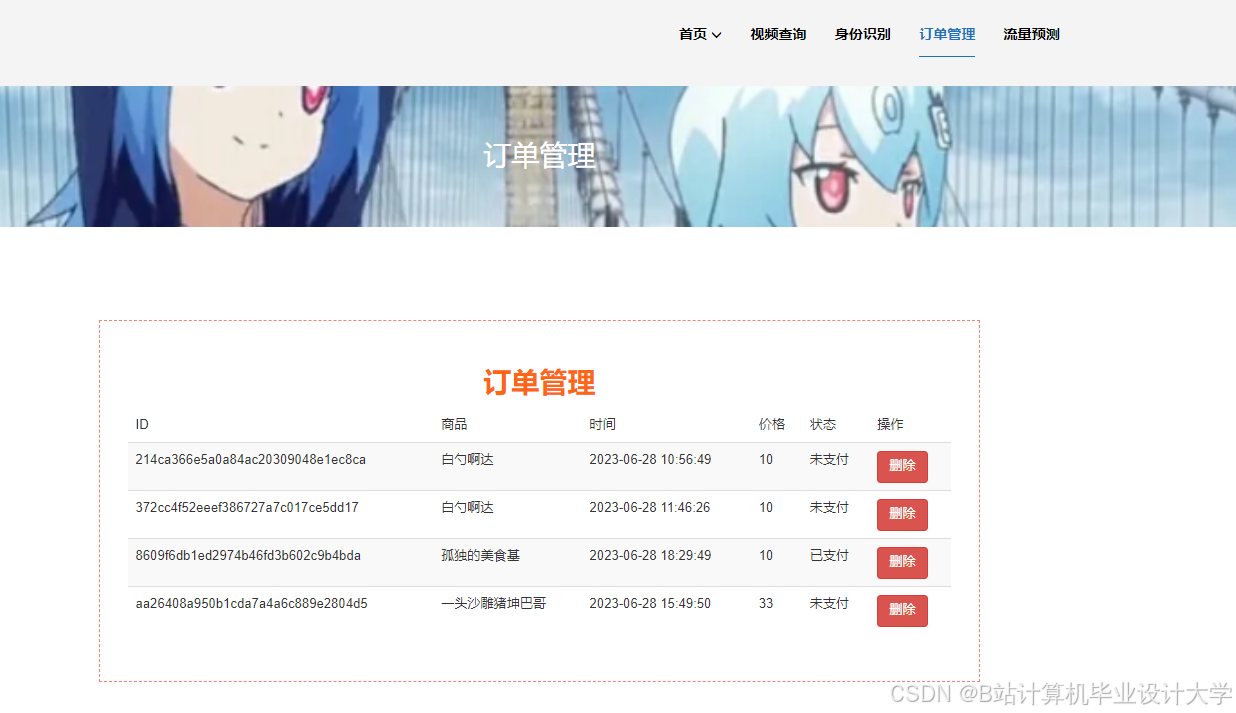
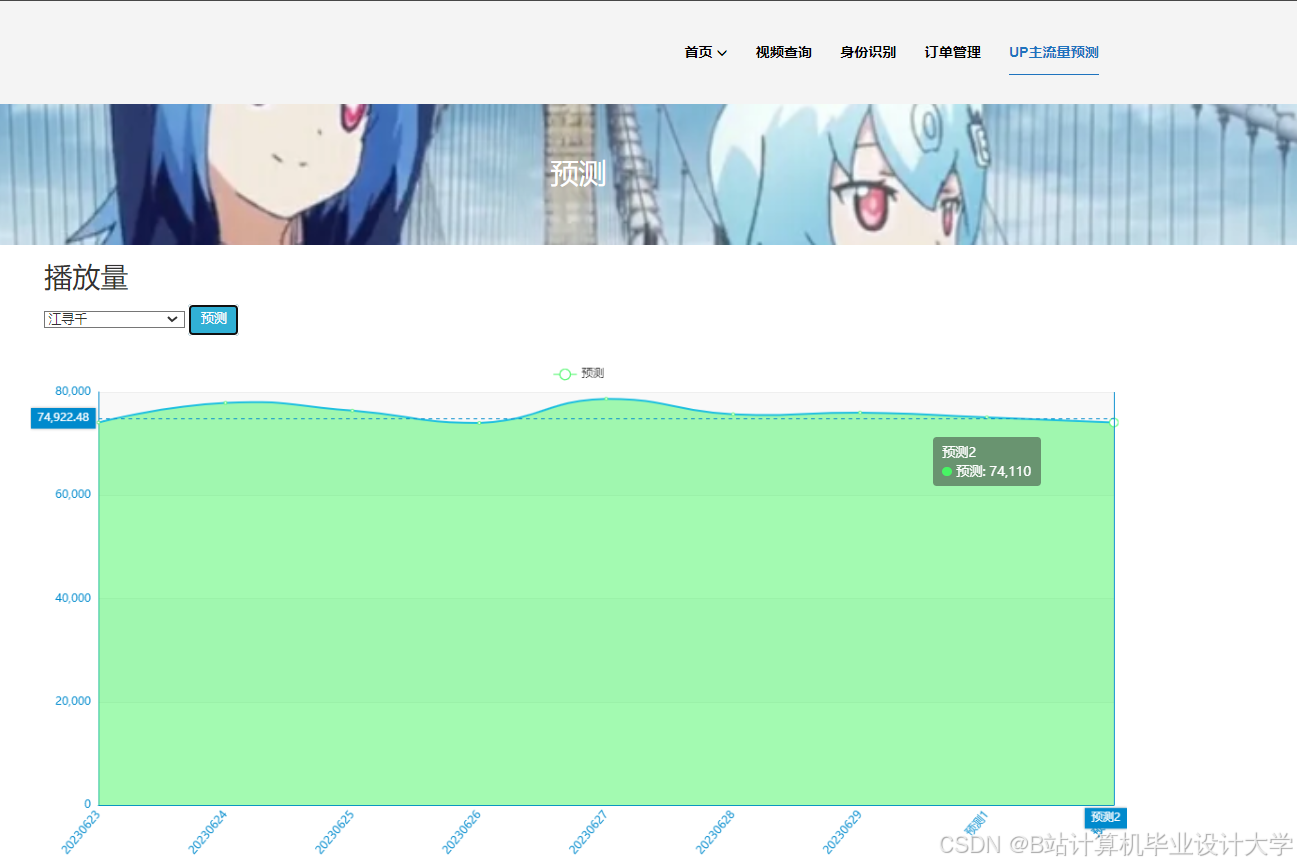
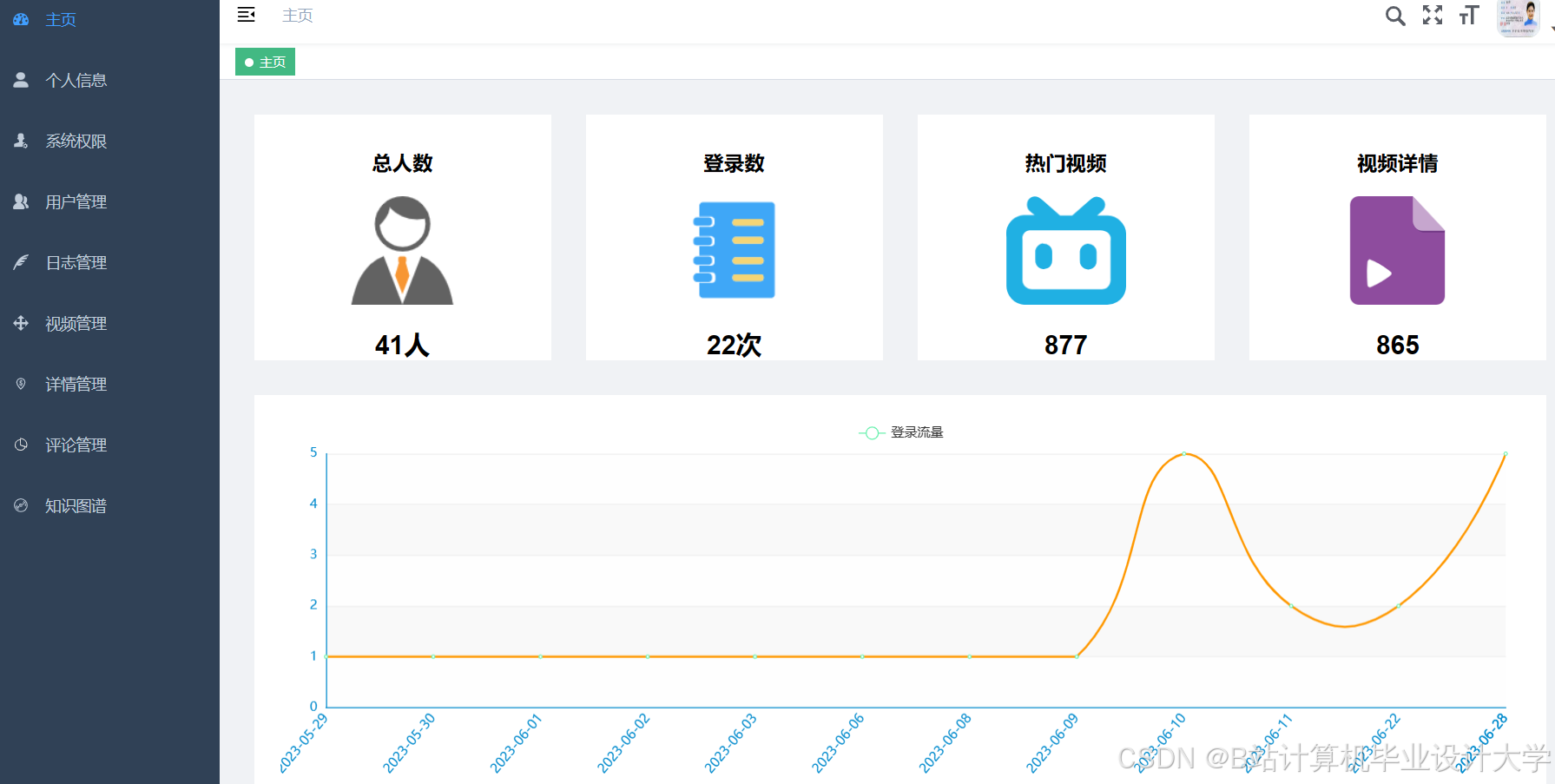
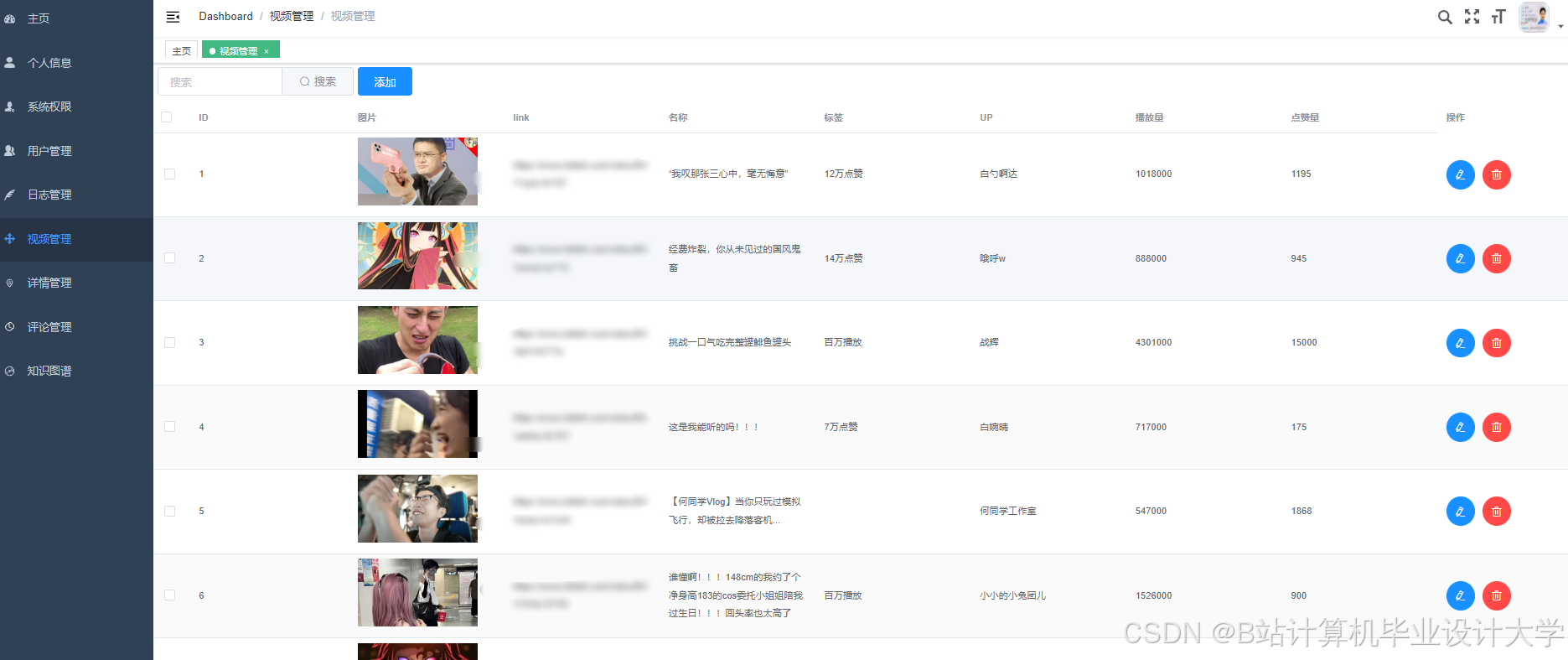
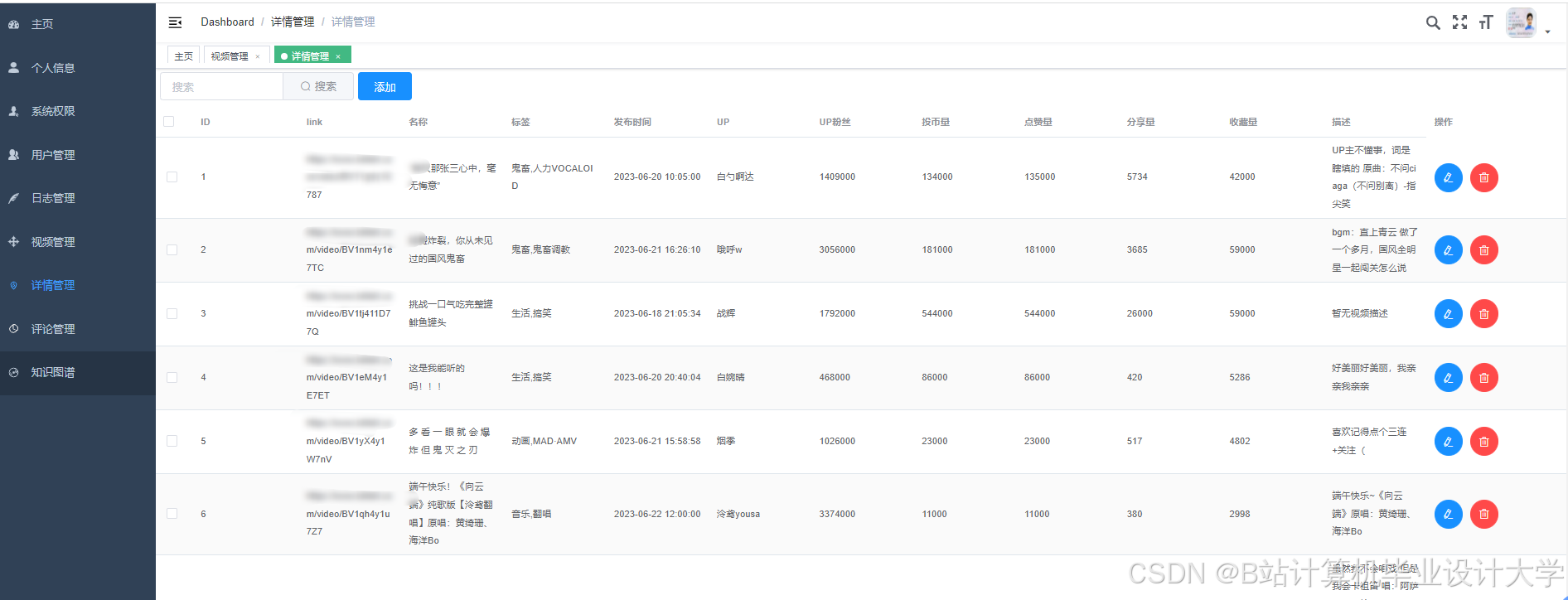
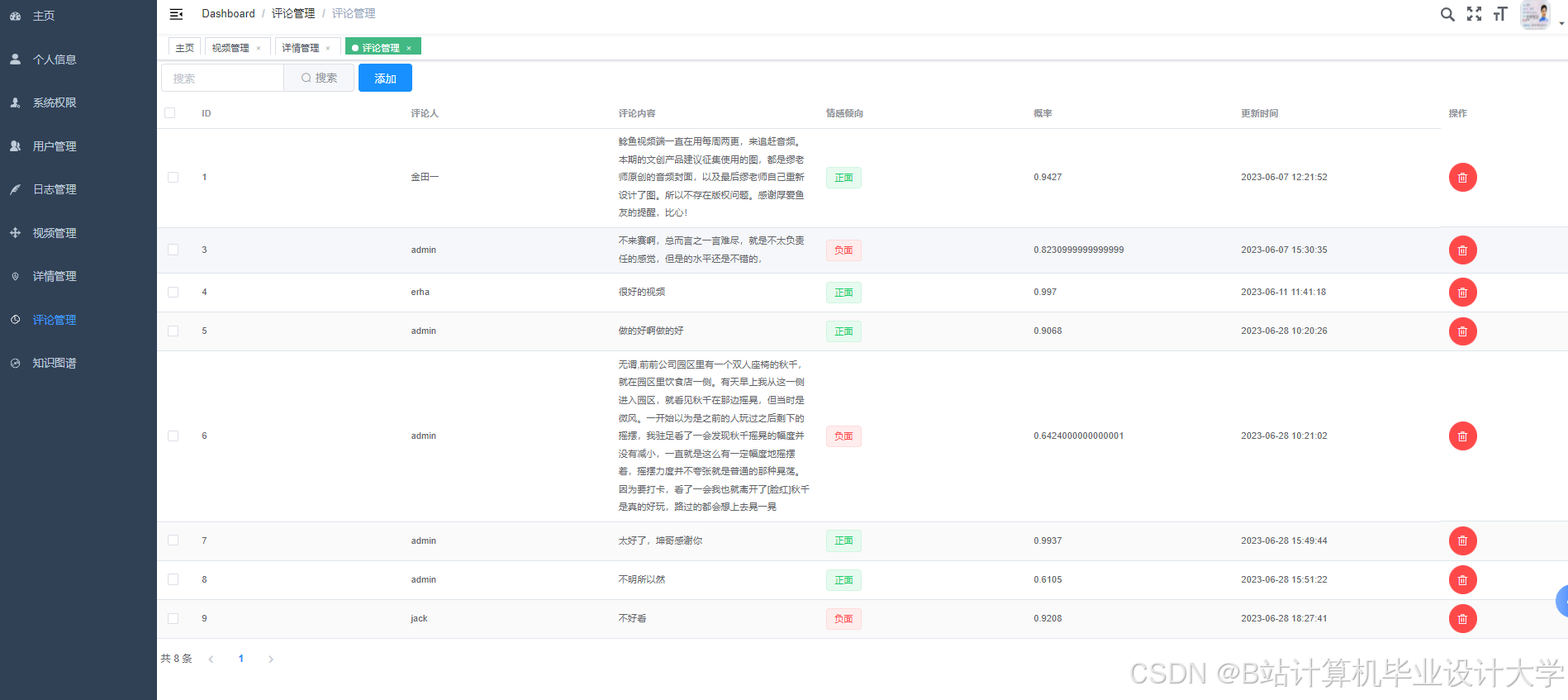
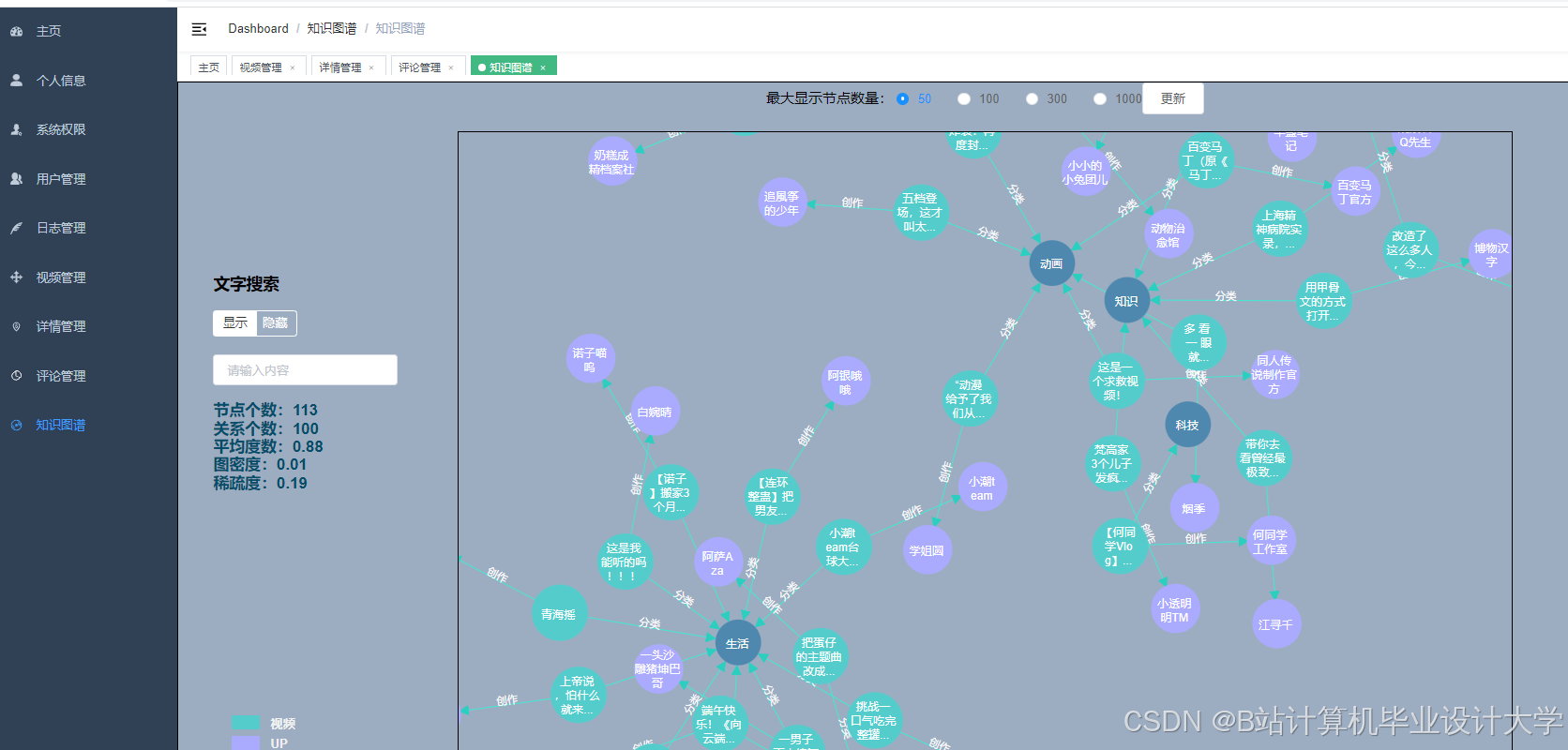
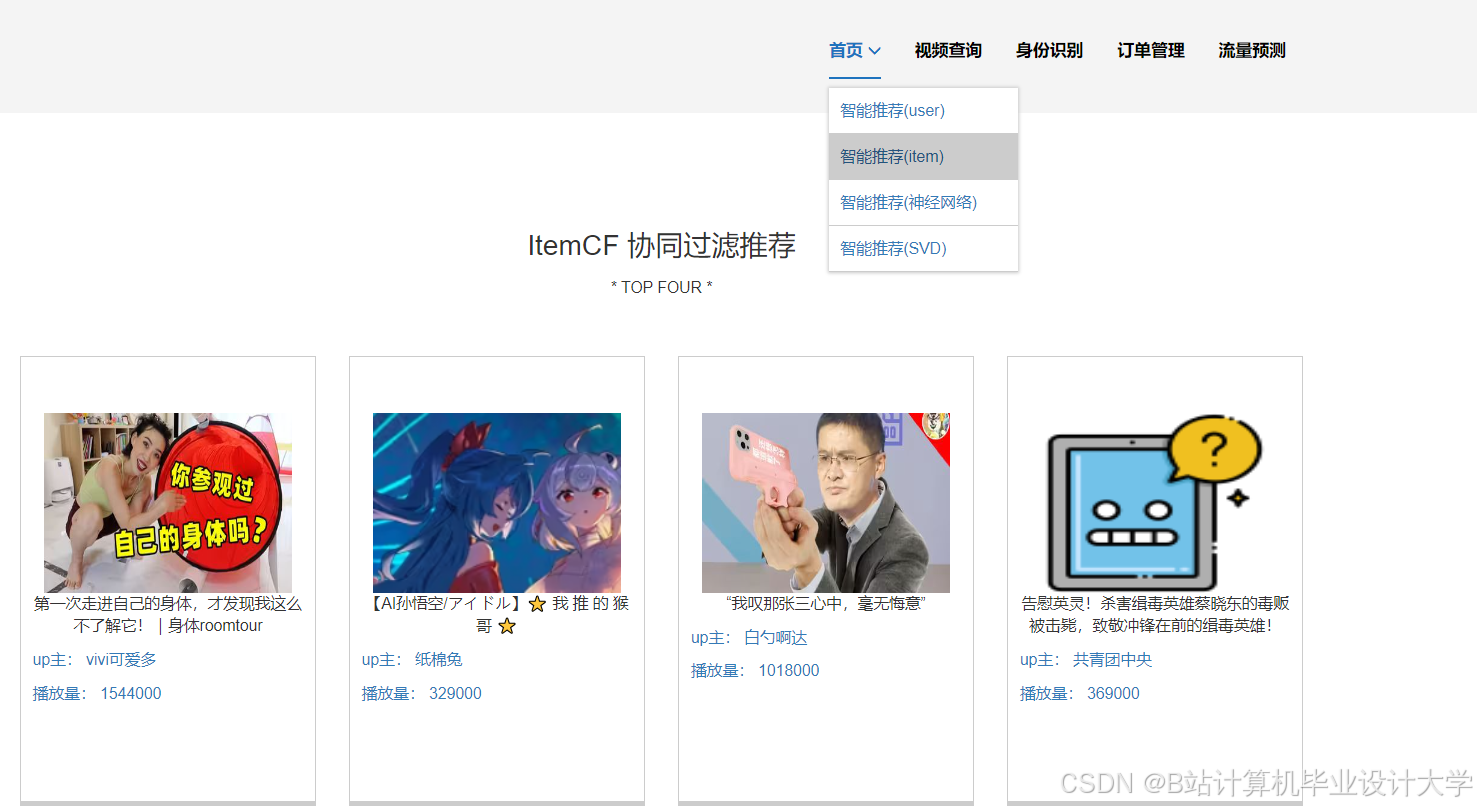
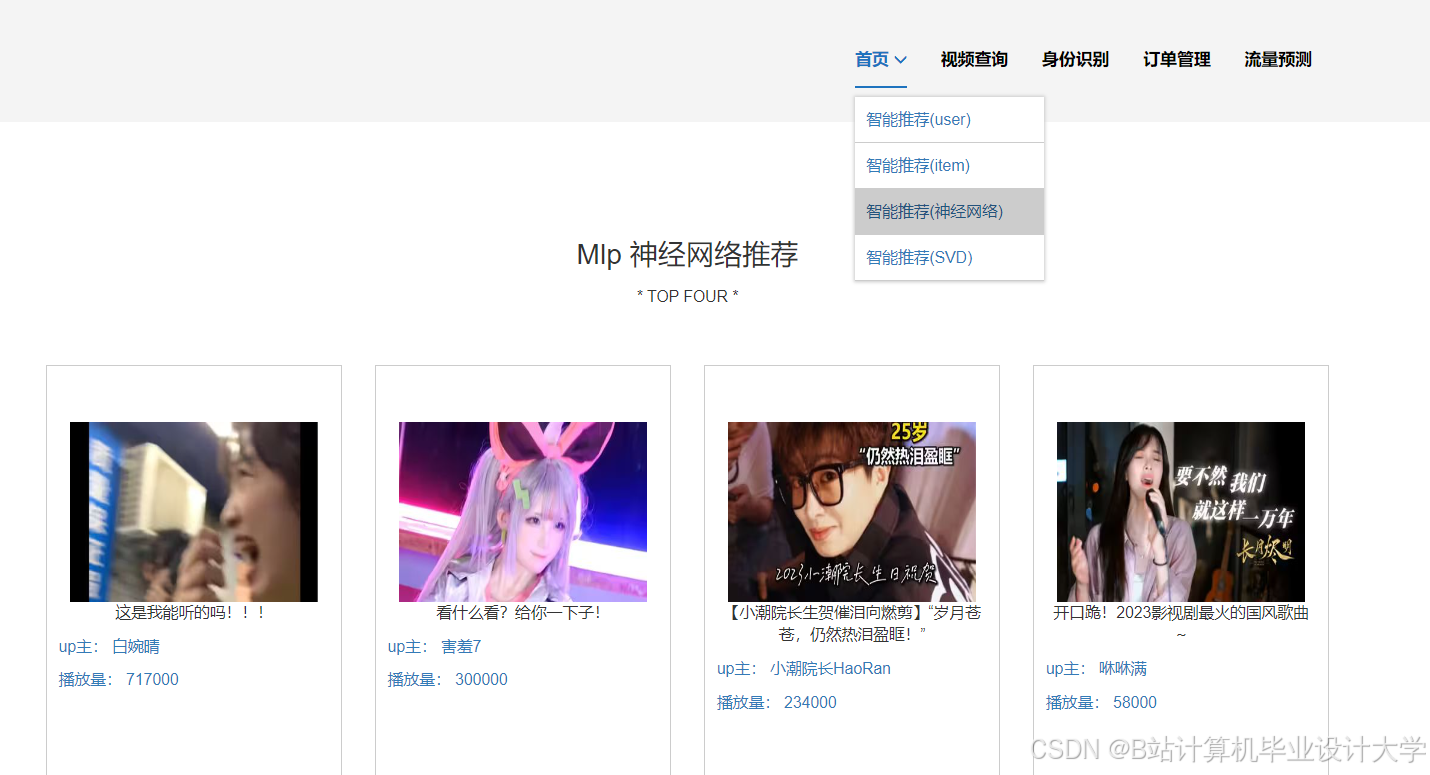
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











