




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python知识图谱中华古诗词可视化与古诗词情感分析技术说明
一、引言
中华古诗词作为中华民族传统文化的璀璨明珠,承载着丰富的历史、文化和情感信息。随着信息技术的迅猛发展,利用Python技术对中华古诗词进行知识图谱构建、可视化展示以及情感分析,能够为古诗词的研究、教学和传承提供全新的视角和有力的工具。本技术说明将详细介绍如何运用Python实现中华古诗词知识图谱的构建、可视化以及情感分析的关键技术和步骤。
二、技术环境搭建
2.1 Python版本选择
推荐使用Python 3.x版本,它具有丰富的库支持和良好的性能,能够满足数据处理、自然语言处理、可视化等多种需求。
2.2 所需库安装
- 数据处理与分析:
pandas用于数据的读取、清洗和转换;numpy提供高效的数值计算功能。 - 自然语言处理:
jieba用于中文分词;snownlp可用于简单的情感分析(作为基础参考,后续会结合更复杂模型)。 - 知识图谱构建:
py2neo用于与Neo4j图数据库进行交互,实现知识图谱的存储和查询。 - 可视化:
pyecharts用于绘制各种类型的图表,如词云图、柱状图等;networkx和matplotlib结合可用于绘制网络图。 - 深度学习(情感分析):
tensorflow或pytorch用于构建和训练深度学习模型。
可以通过pip命令安装这些库,例如:
bash
pip install pandas numpy jieba snownlp py2neo pyecharts networkx matplotlib tensorflow |
三、中华古诗词知识图谱构建
3.1 数据收集
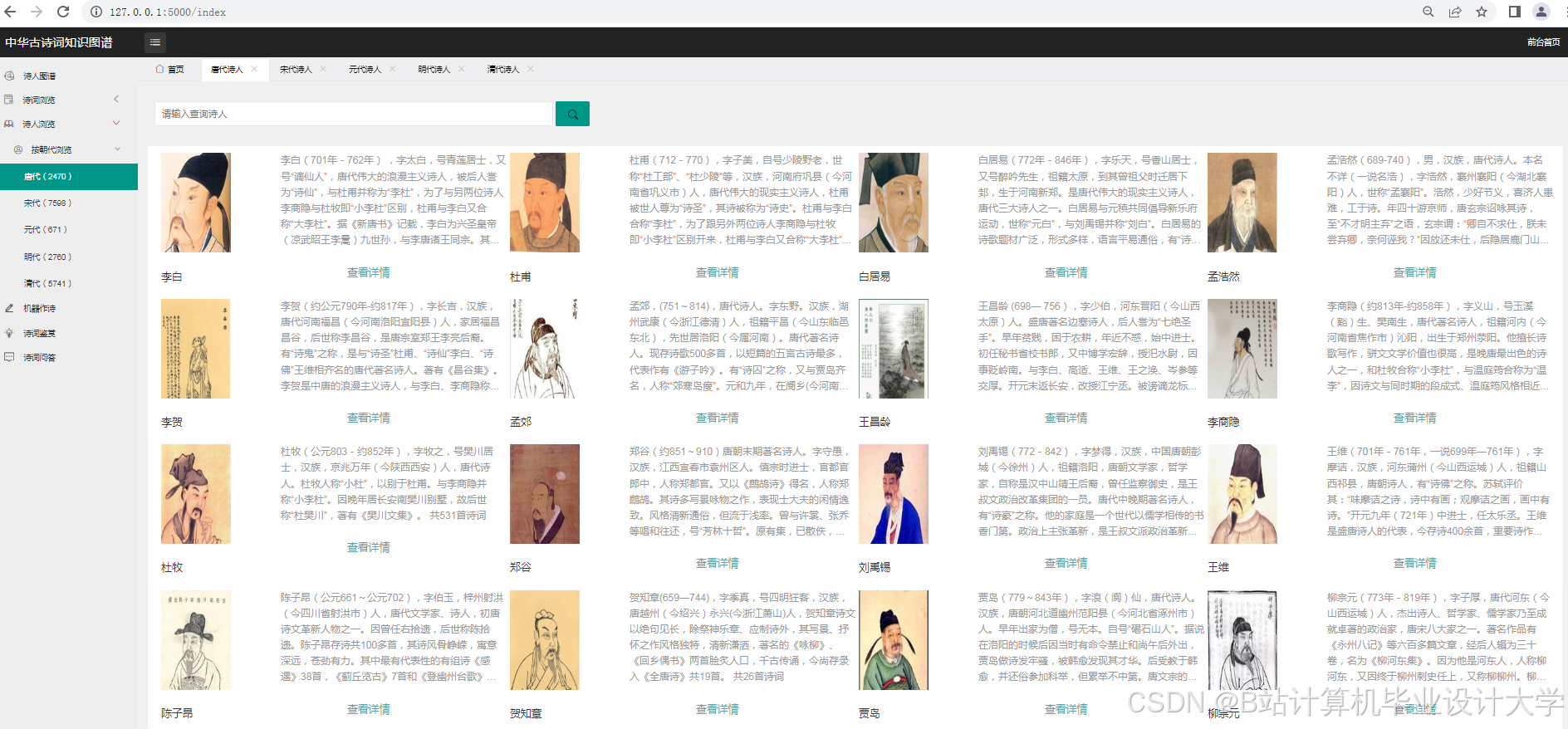
从多个渠道收集中华古诗词数据,如经典的诗词集(电子版)、专业的诗词网站(如古诗文网、中华诗词库)等。数据应包含诗词原文、作者、朝代、标题、注释等信息。
3.2 数据预处理
- 数据清洗:去除数据中的噪声,如HTML标签、特殊字符、重复数据等。
- 分词处理:使用
jieba库对诗词原文进行分词,例如:
python
import jieba | |
text = "床前明月光,疑是地上霜。" | |
seg_list = jieba.cut(text, cut_all=False) | |
print(" ".join(seg_list)) |
- 标注处理:对诗词中的实体(如诗人、诗作、意象等)进行标注,为后续的知识抽取做准备。
3.3 实体识别与关系抽取
- 实体识别:通过定义规则或使用命名实体识别模型,识别出诗词中的诗人、诗作、朝代、意象等实体。例如,利用正则表达式识别朝代信息。
- 关系抽取:分析诗词文本,抽取实体之间的关系,如“诗人 - 创作 - 诗作”“诗作 - 包含 - 意象”等。可以使用依存句法分析工具(如
LTP)辅助关系抽取。
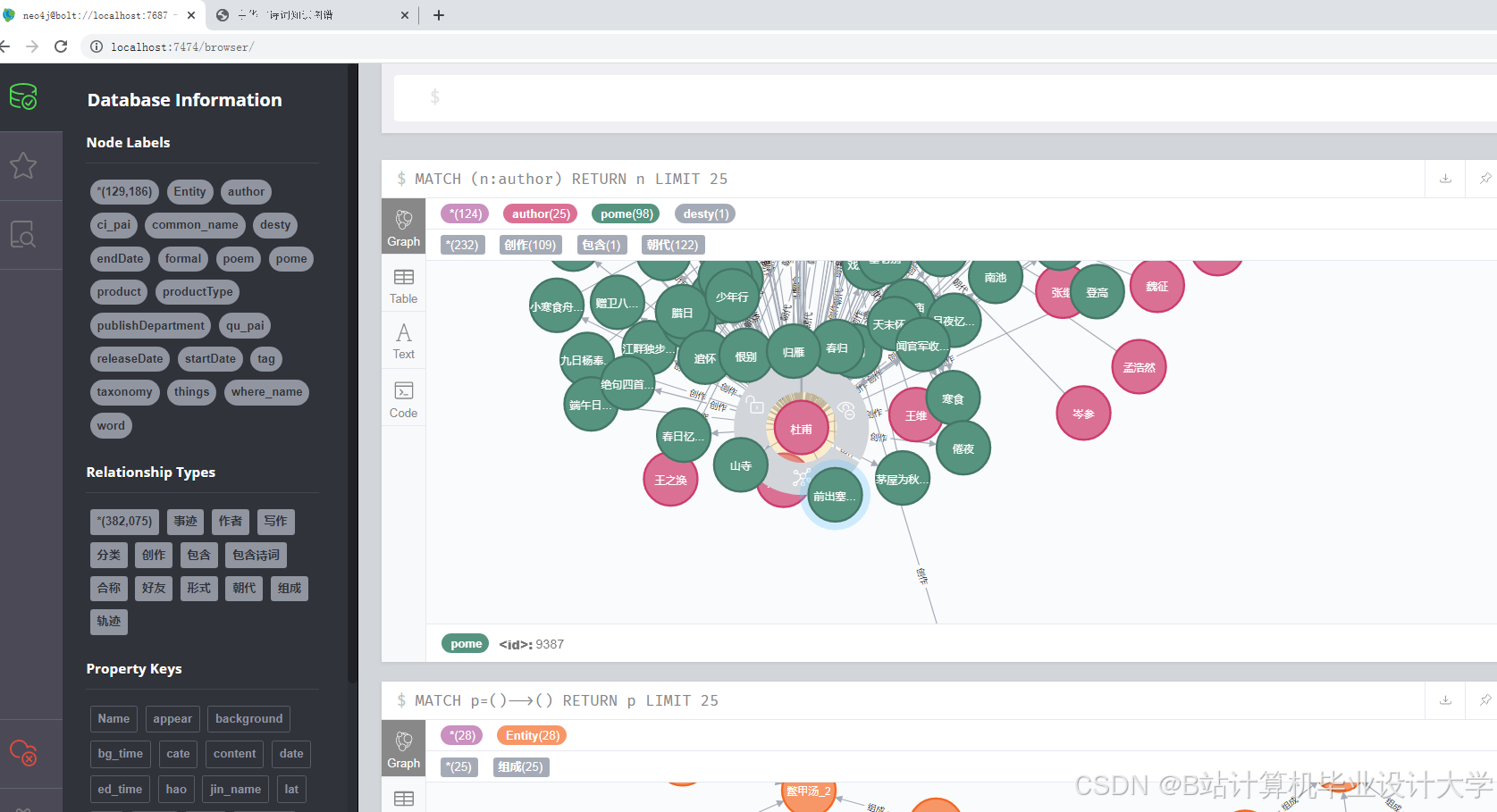
3.4 知识图谱存储
使用py2neo库将识别出的实体和抽取的关系存储到Neo4j图数据库中。以下是一个简单的示例代码:
python
from py2neo import Graph, Node, Relationship | |
# 连接到Neo4j数据库 | |
graph = Graph("bolt://localhost:7687", auth=("username", "password")) | |
# 创建诗人节点 | |
poet = Node("Poet", name="李白") | |
graph.create(poet) | |
# 创建诗作节点 | |
poem = Node("Poem", title="静夜思") | |
graph.create(poem) | |
# 创建关系 | |
relation = Relationship(poet, "WROTE", poem) | |
graph.create(relation) |
四、中华古诗词可视化
4.1 词云图绘制
使用pyecharts库绘制古诗词意象词云图,直观展示古诗词中常用的意象。示例代码如下:
python
from pyecharts.charts import WordCloud | |
from pyecharts import options as opts | |
# 假设已经统计好意象及其频率 | |
words = [("明月", 100), ("清风", 80), ("流水", 60)] | |
wordcloud = ( | |
WordCloud() | |
.add(series_name="意象", data_pair=words, word_size_range=[20, 100]) | |
.set_global_opts(title_opts=opts.TitleOpts(title="古诗词意象词云图")) | |
) | |
wordcloud.render("wordcloud.html") |
4.2 网络图绘制
使用networkx和matplotlib绘制诗人关系网络图,展示诗人之间的创作关联。示例代码如下:
python
import networkx as nx | |
import matplotlib.pyplot as plt | |
# 创建有向图 | |
G = nx.DiGraph() | |
# 添加节点和边 | |
G.add_node("李白") | |
G.add_node("杜甫") | |
G.add_edge("李白", "杜甫", relation="朋友") | |
# 绘制图形 | |
pos = nx.spring_layout(G) | |
nx.draw(G, pos, with_labels=True, node_size=2000, node_color="skyblue", font_size=10, font_weight="bold") | |
plt.show() |
4.3 基于Web的可视化系统(可选)
使用Flask或Django框架搭建一个基于Web的古诗词可视化系统,将上述可视化结果集成到网页中,方便用户通过浏览器访问和查看。
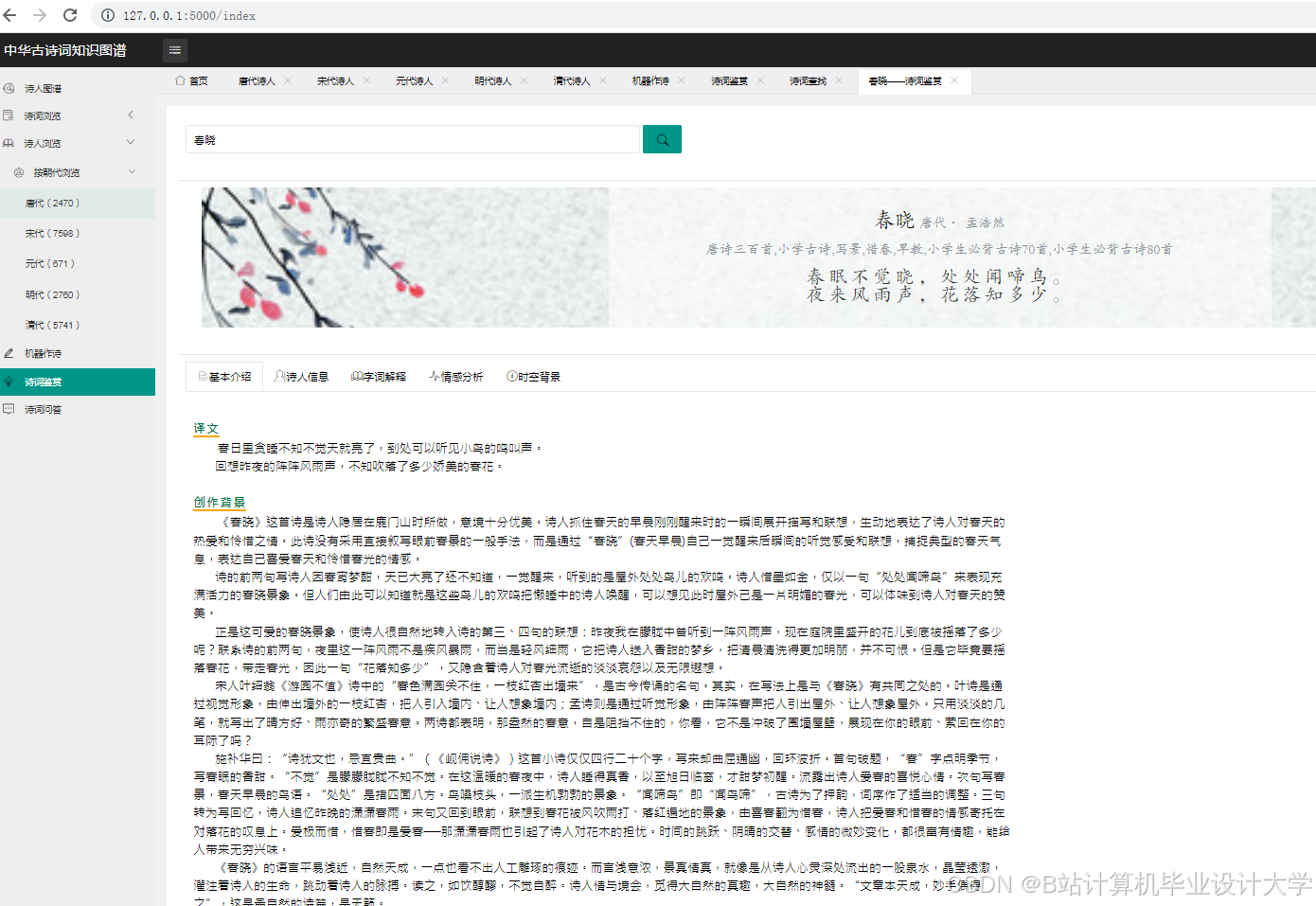
五、古诗词情感分析
5.1 基于词典的情感分析(简单方法)
构建一个古诗词情感词典,对诗词中的情感词汇进行标注和计分,然后根据词汇的情感得分计算整首诗词的情感倾向。示例代码如下:
python
# 简单的情感词典示例 | |
sentiment_dict = { | |
"喜": 1, "乐": 1, "爱": 1, | |
"悲": -1, "愁": -1, "恨": -1 | |
} | |
def simple_sentiment_analysis(text): | |
words = jieba.cut(text) | |
score = 0 | |
for word in words: | |
if word in sentiment_dict: | |
score += sentiment_dict[word] | |
if score > 0: | |
return "积极" | |
elif score < 0: | |
return "消极" | |
else: | |
return "中性" | |
text = "春风得意马蹄疾,一日看尽长安花。" | |
print(simple_sentiment_analysis(text)) |
5.2 基于机器学习的情感分析
- 数据标注:邀请诗词学专家对古诗词进行情感标注,构建标注数据集。
- 特征提取:将古诗词文本转换为数值特征向量,常用的方法有词袋模型、TF - IDF等。例如,使用
sklearn库的TfidfVectorizer:
python
from sklearn.feature_extraction.text import TfidfVectorizer | |
corpus = [ | |
"床前明月光,疑是地上霜。", | |
"春风又绿江南岸,明月何时照我还。" | |
] | |
vectorizer = TfidfVectorizer() | |
X = vectorizer.fit_transform(corpus) | |
print(X.toarray()) |
- 模型训练与评估:选择合适的机器学习算法,如支持向量机(SVM)、朴素贝叶斯(Naive Bayes)等,使用标注数据集进行训练和评估。示例代码如下:
python
from sklearn.model_selection import train_test_split | |
from sklearn.svm import SVC | |
from sklearn.metrics import accuracy_score | |
# 假设已经有了特征矩阵X和标签y | |
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) | |
model = SVC() | |
model.fit(X_train, y_train) | |
y_pred = model.predict(X_test) | |
print("准确率:", accuracy_score(y_test, y_pred)) |
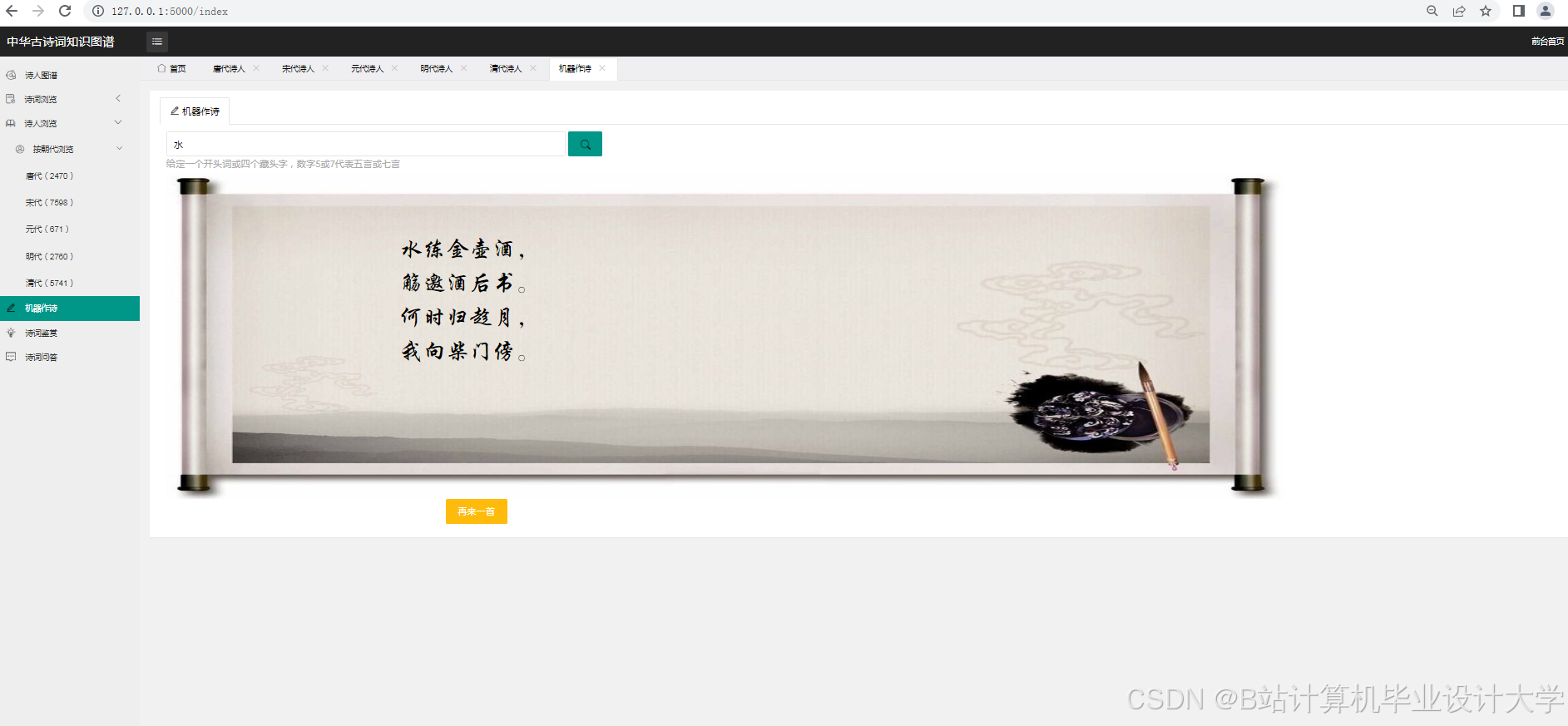
5.3 基于深度学习的情感分析
使用深度学习模型,如长短期记忆网络(LSTM)、双向编码器表示(BERT)等,能够更好地捕捉古诗词中的上下文信息和语义关系。以下是一个使用tensorflow构建LSTM模型进行情感分析的简单示例:
python
import tensorflow as tf | |
from tensorflow.keras.models import Sequential | |
from tensorflow.keras.layers import Embedding, LSTM, Dense | |
# 假设已经对文本进行了预处理和序列化 | |
max_len = 100 # 序列最大长度 | |
vocab_size = 10000 # 词汇表大小 | |
embedding_dim = 64 # 嵌入维度 | |
model = Sequential([ | |
Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=max_len), | |
LSTM(64), | |
Dense(1, activation='sigmoid') | |
]) | |
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) | |
# 假设已经有了训练数据X_train和标签y_train | |
# model.fit(X_train, y_train, epochs=10, batch_size=32) |
六、总结与展望
6.1 总结
本技术说明详细介绍了利用Python实现中华古诗词知识图谱构建、可视化和情感分析的关键技术和步骤。通过知识图谱的构建,能够整合古诗词中的多维度信息;可视化技术可以将抽象的知识以直观的方式呈现出来;情感分析方法能够挖掘古诗词中蕴含的情感信息。这些技术和方法为古诗词的研究、教学和传承提供了有力的支持。
6.2 展望
未来的研究可以进一步拓展以下几个方面:一是加强多模态数据融合,将古诗词的文本、图像、音频等多模态数据进行融合,构建更丰富的知识表示;二是探索更先进的深度学习模型,提高情感分析的准确性和泛化能力;三是开发更多的应用场景,如古诗词智能创作、古诗词推荐系统等,促进古诗词的广泛传播和深入传承。
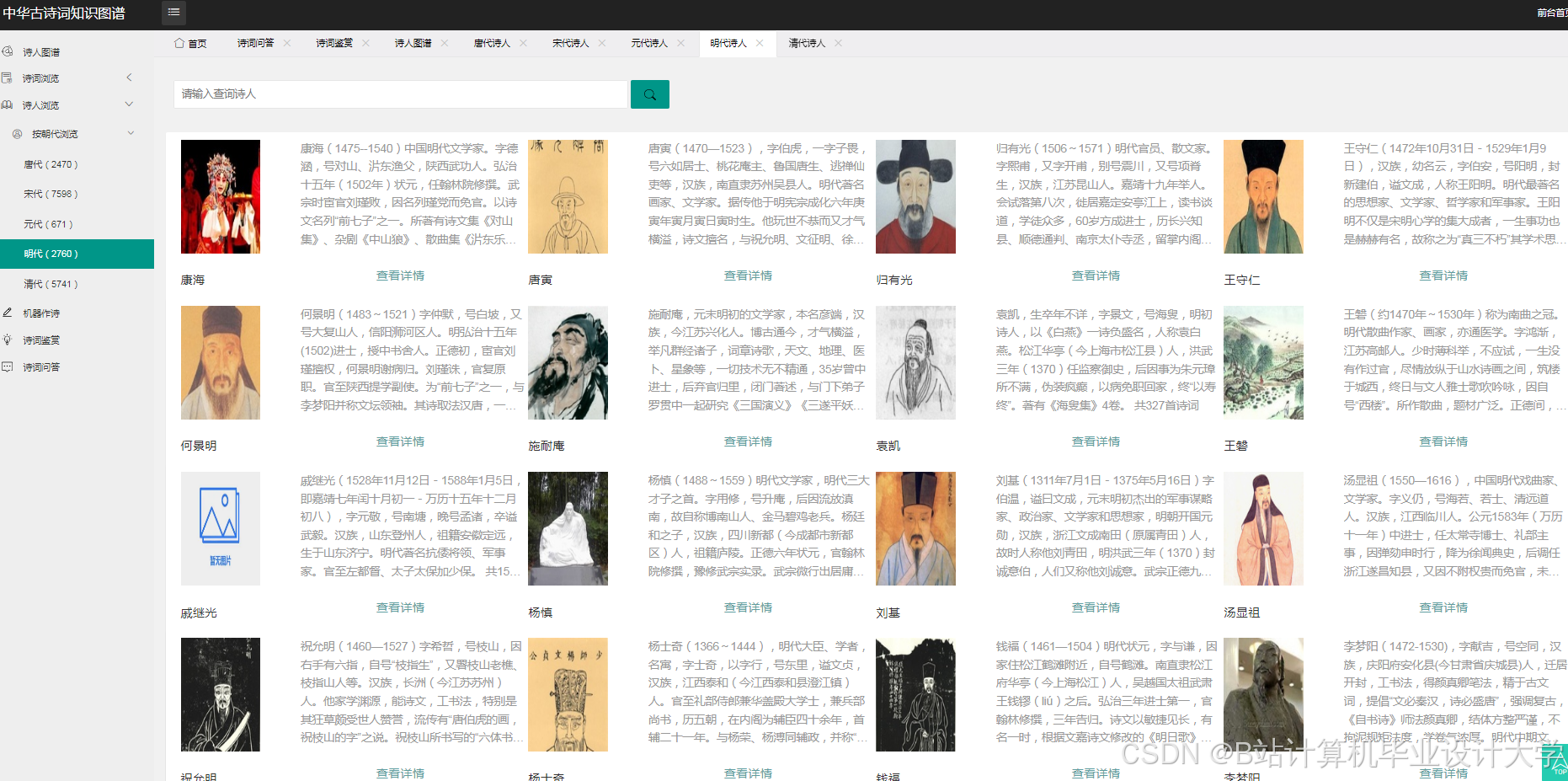
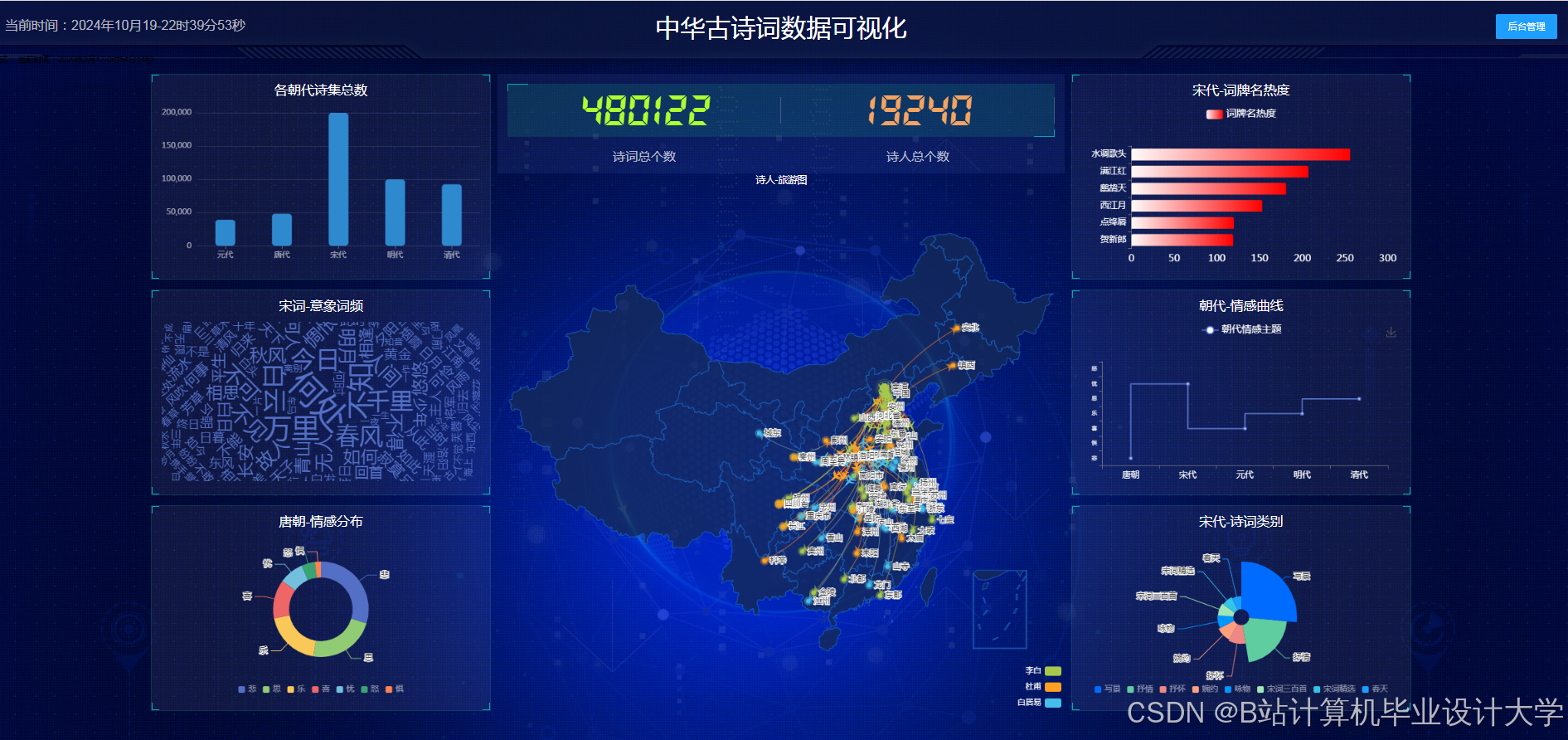
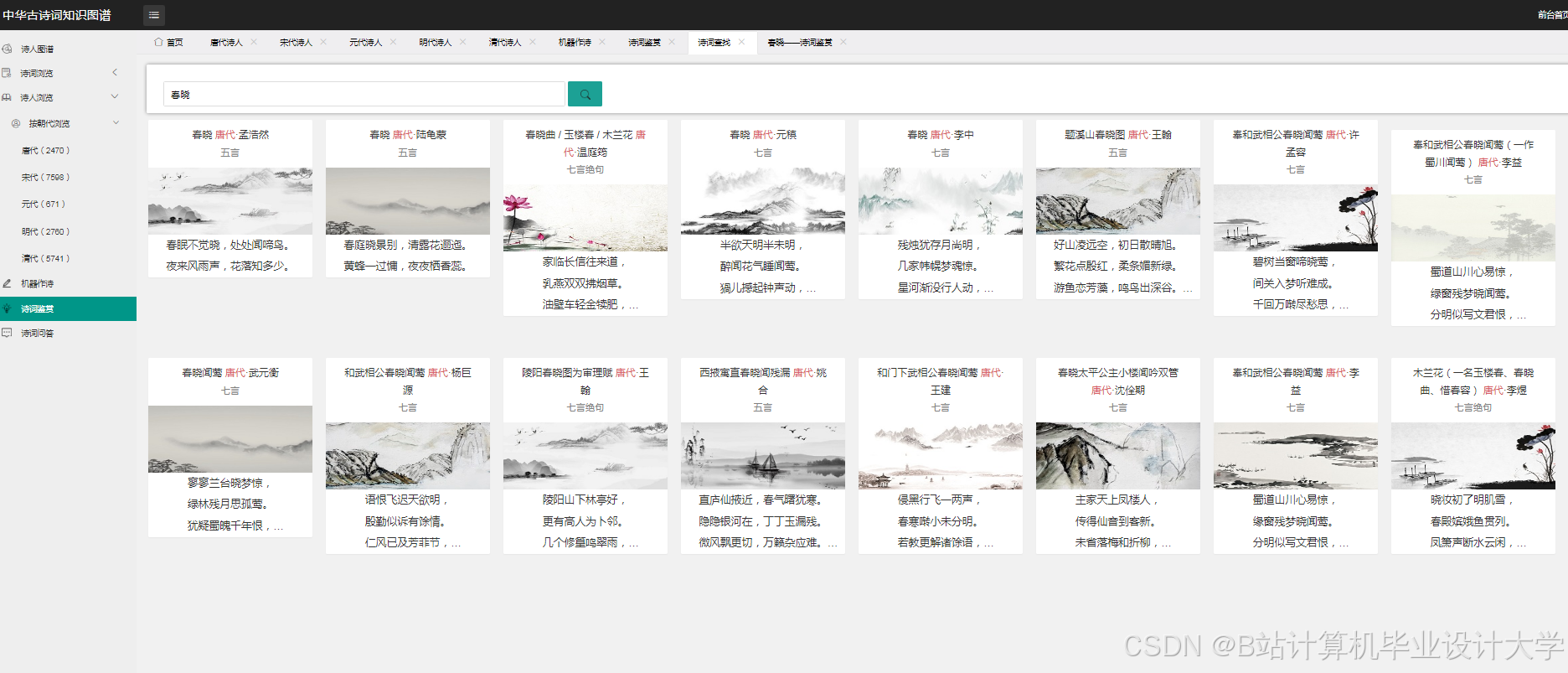
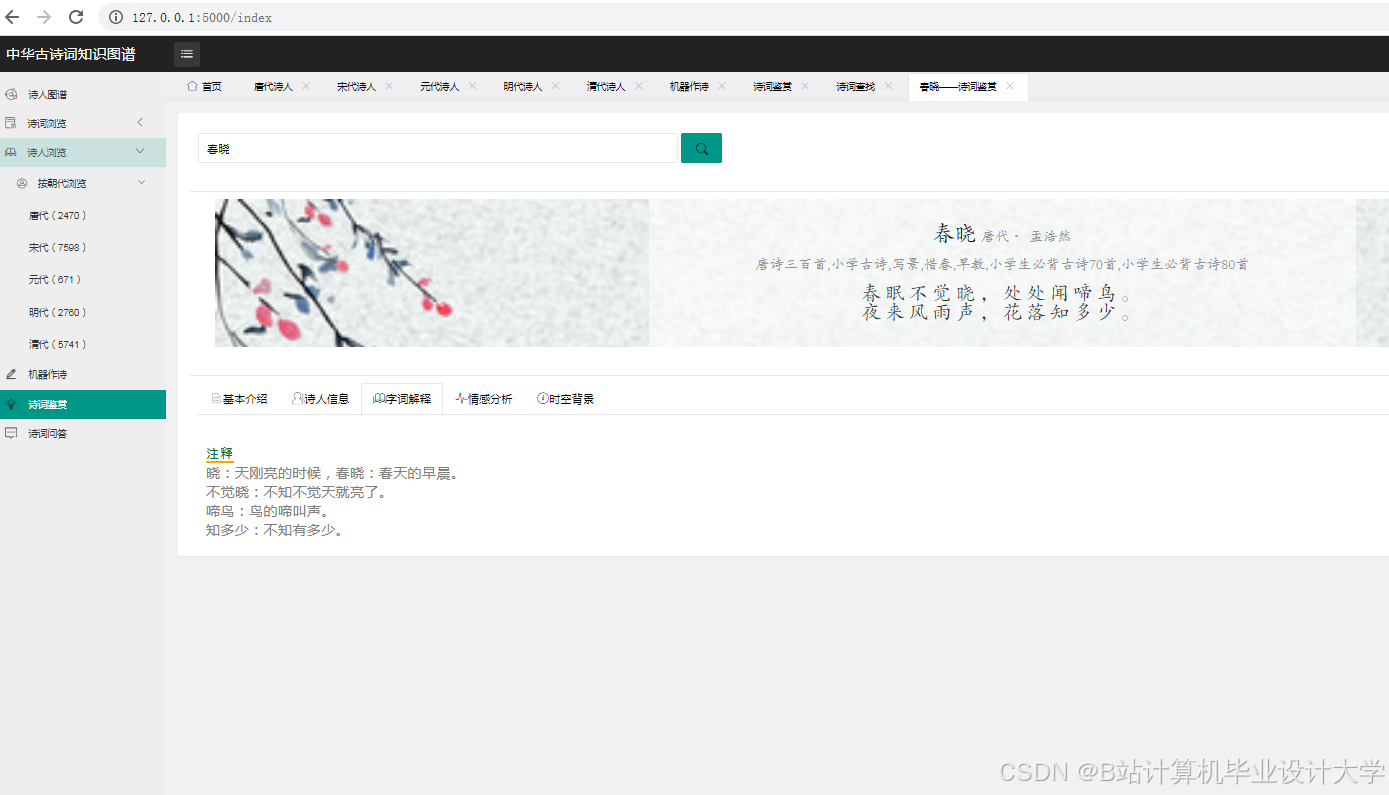
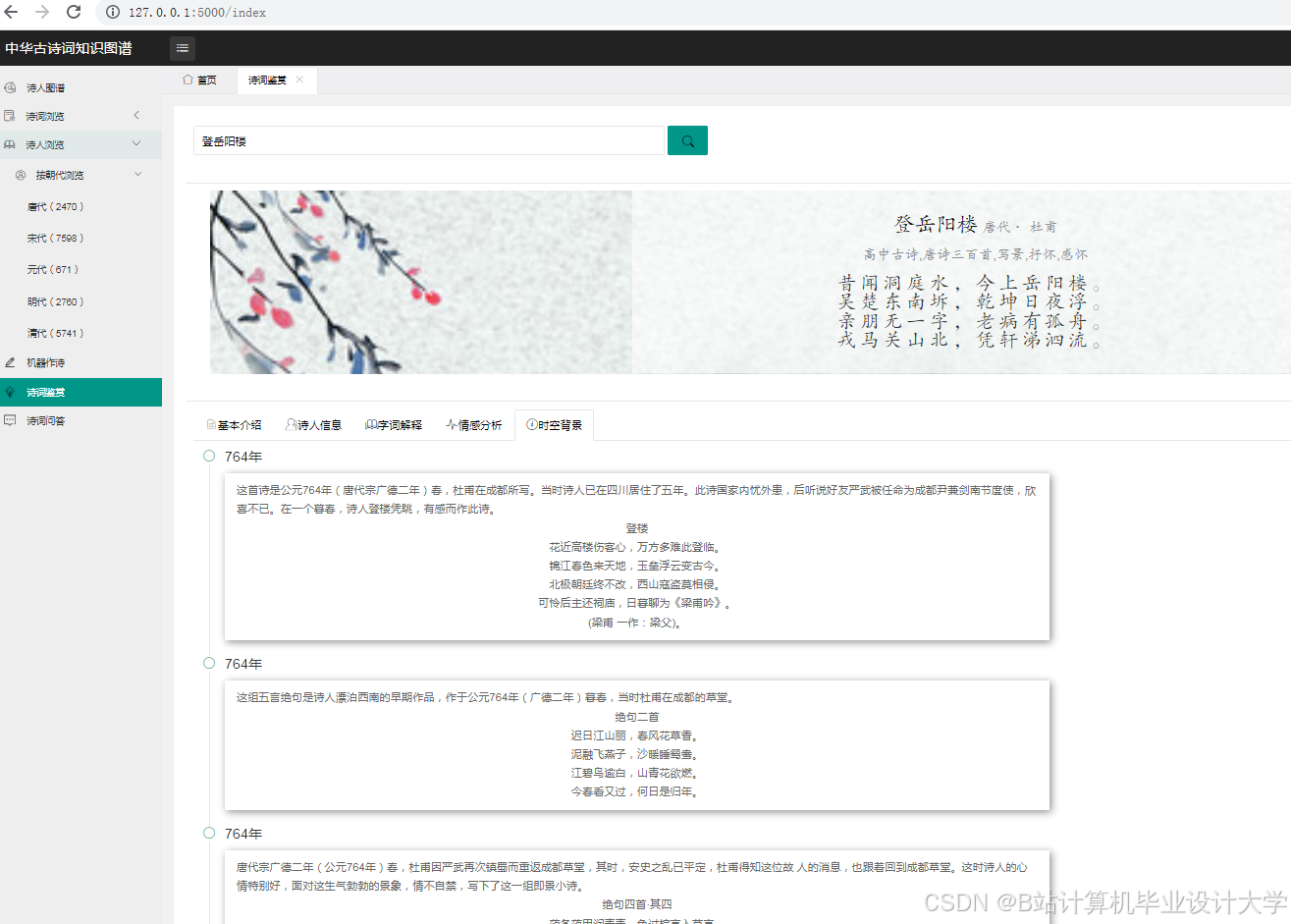
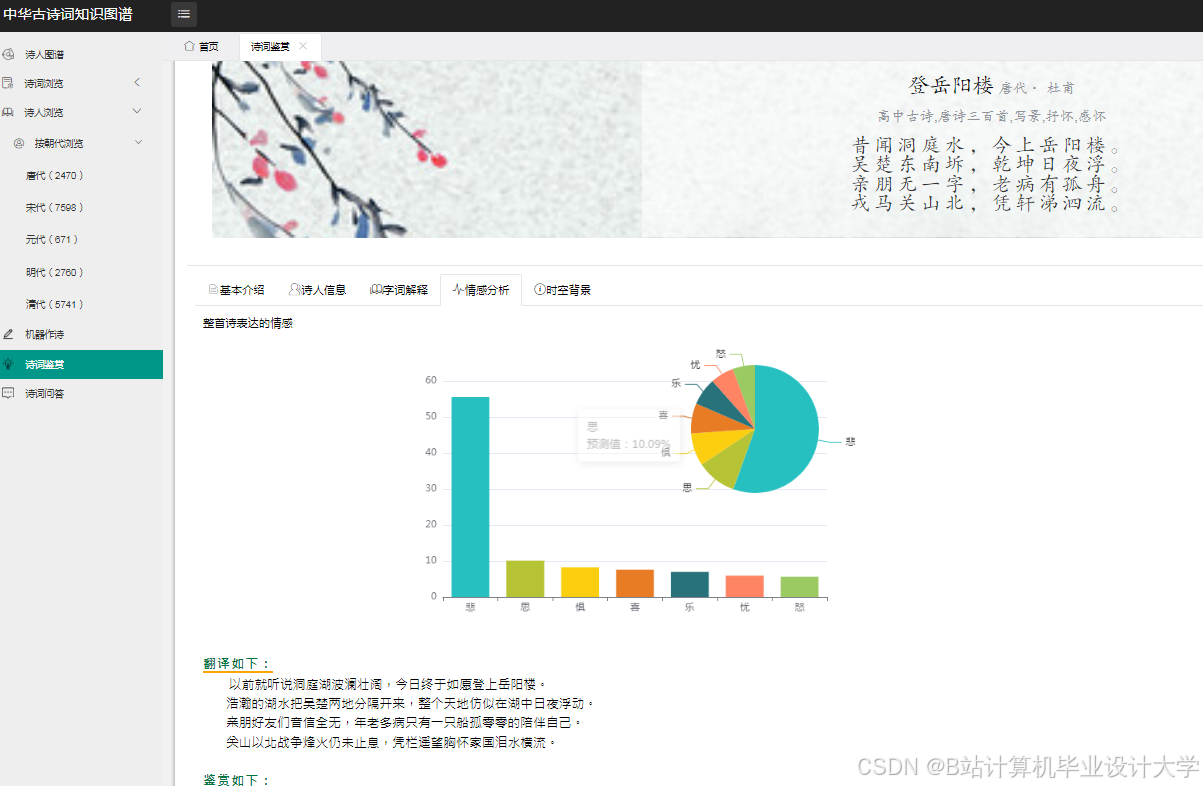
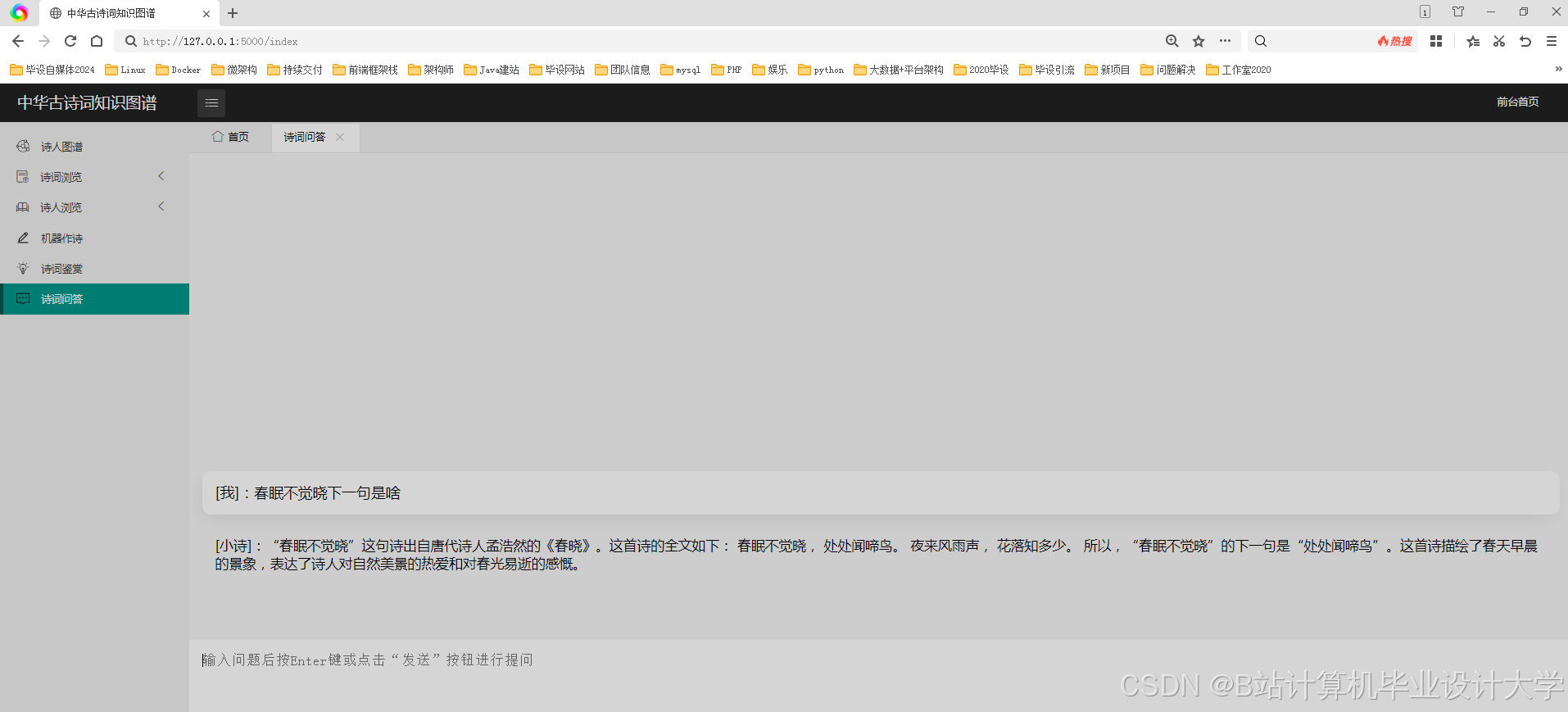
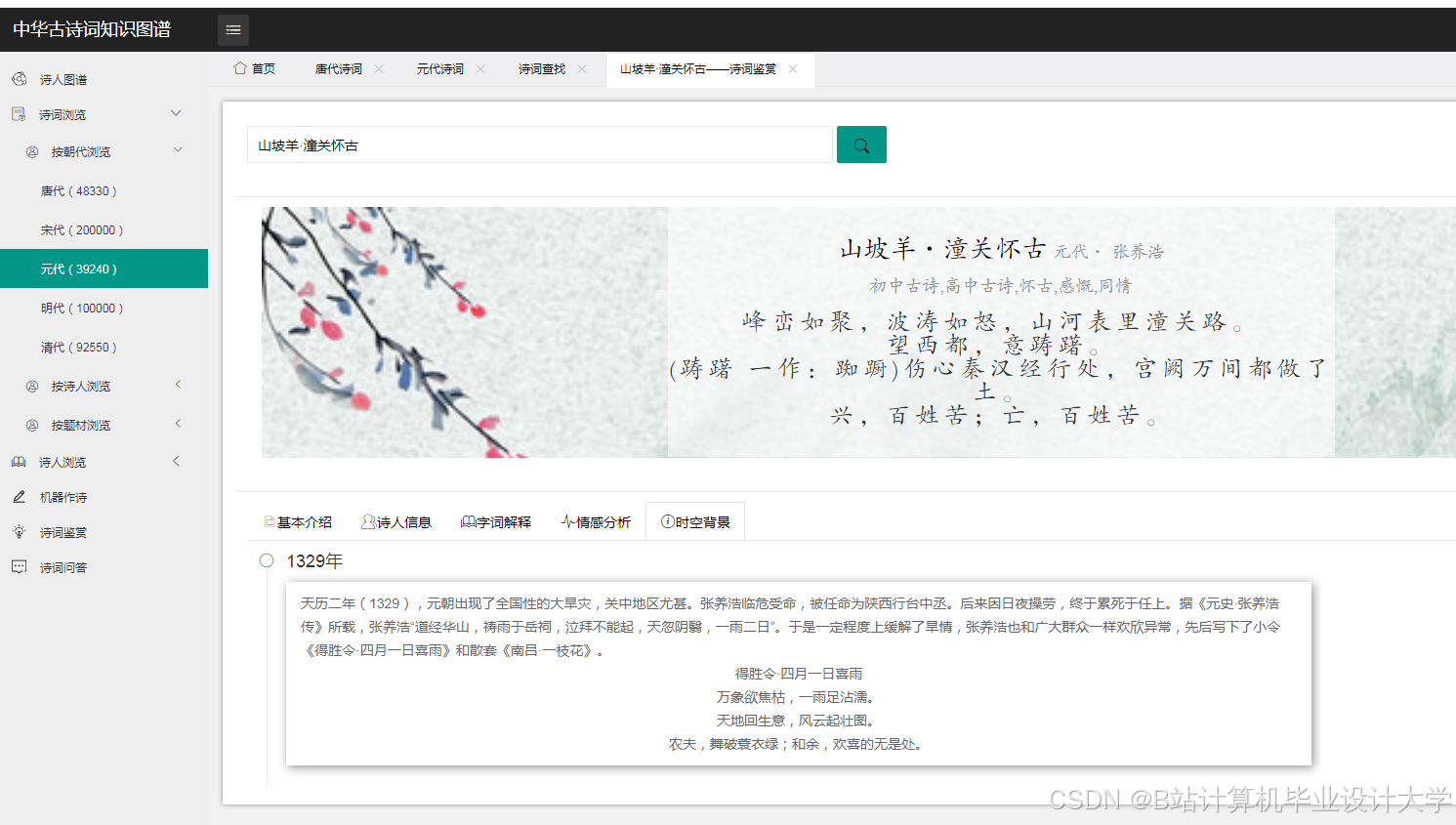
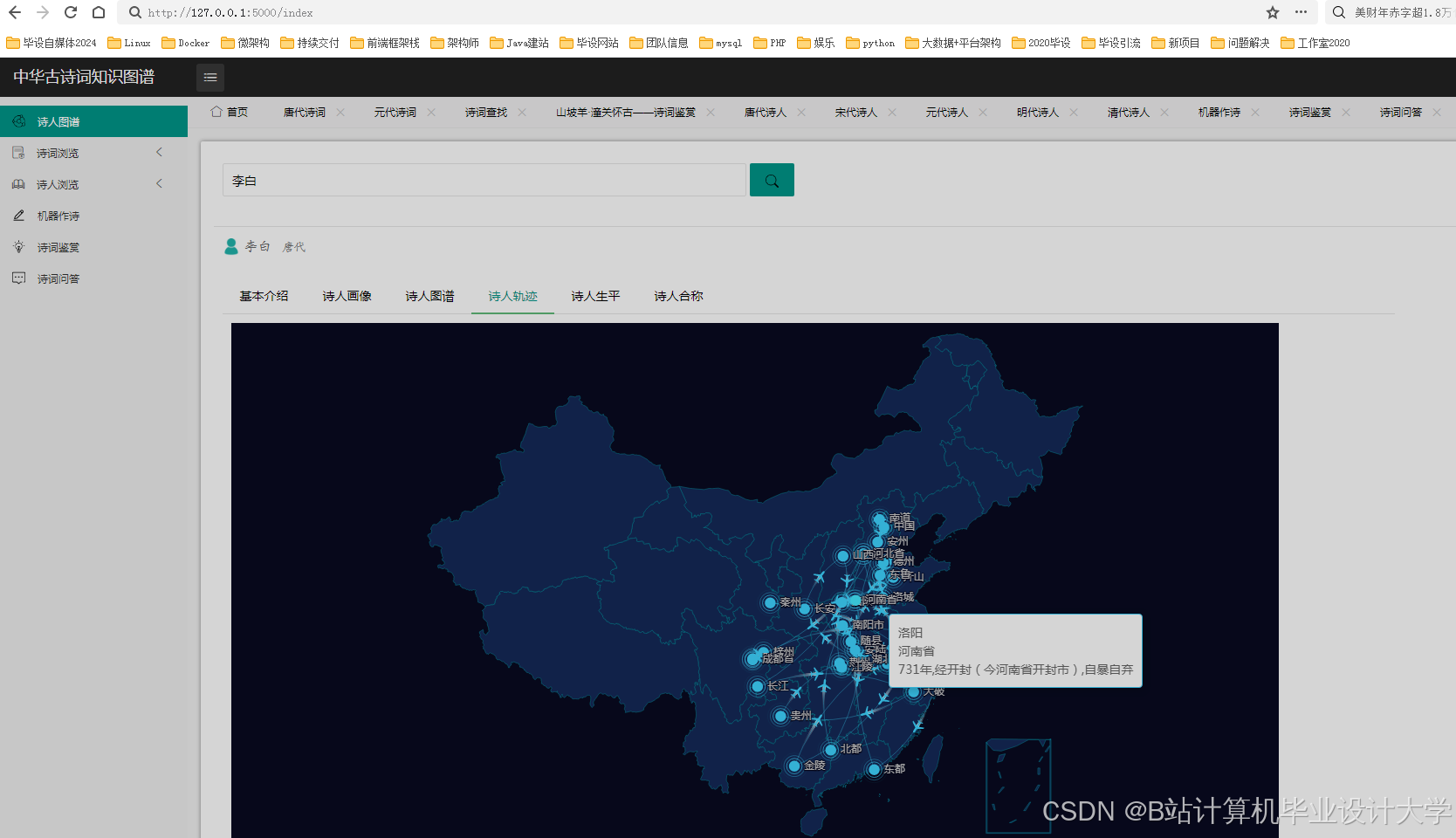
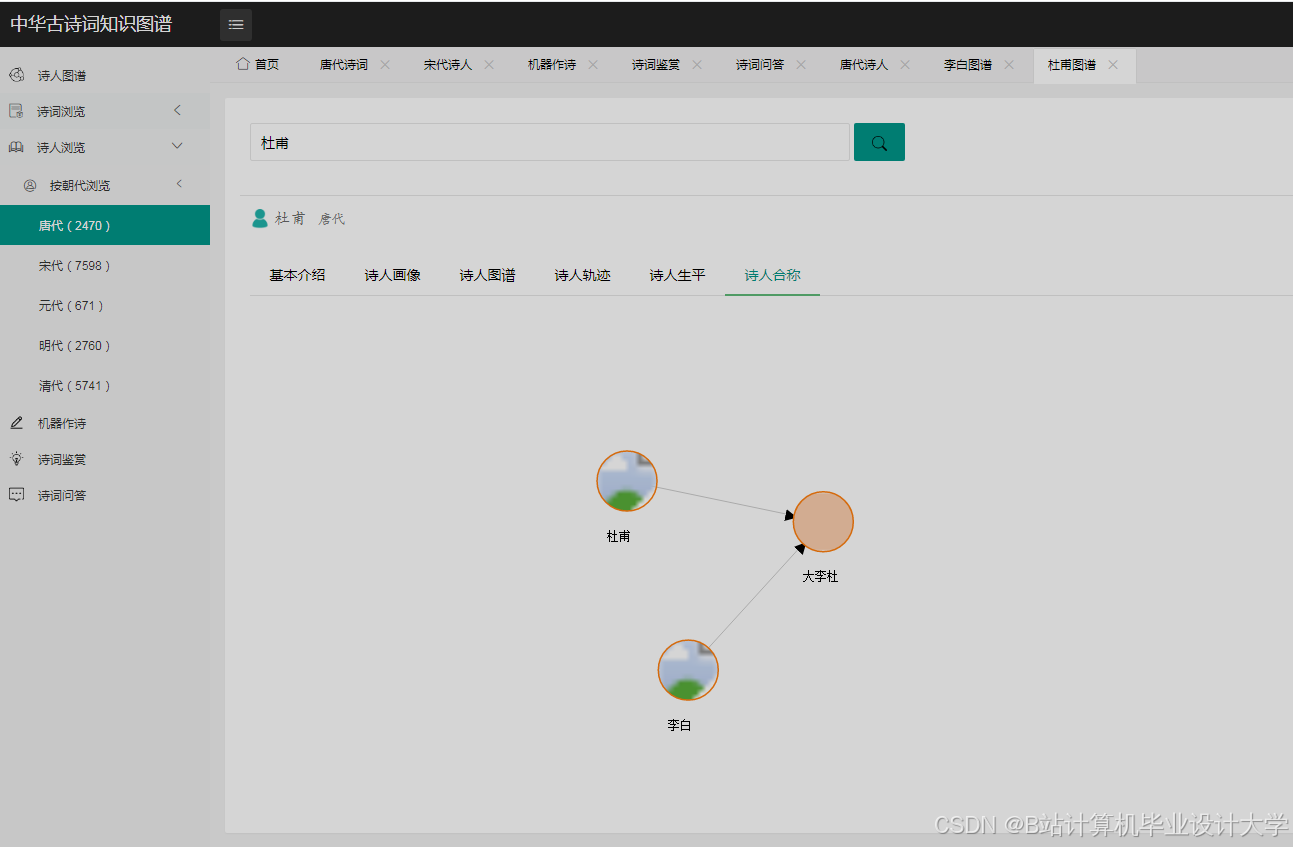
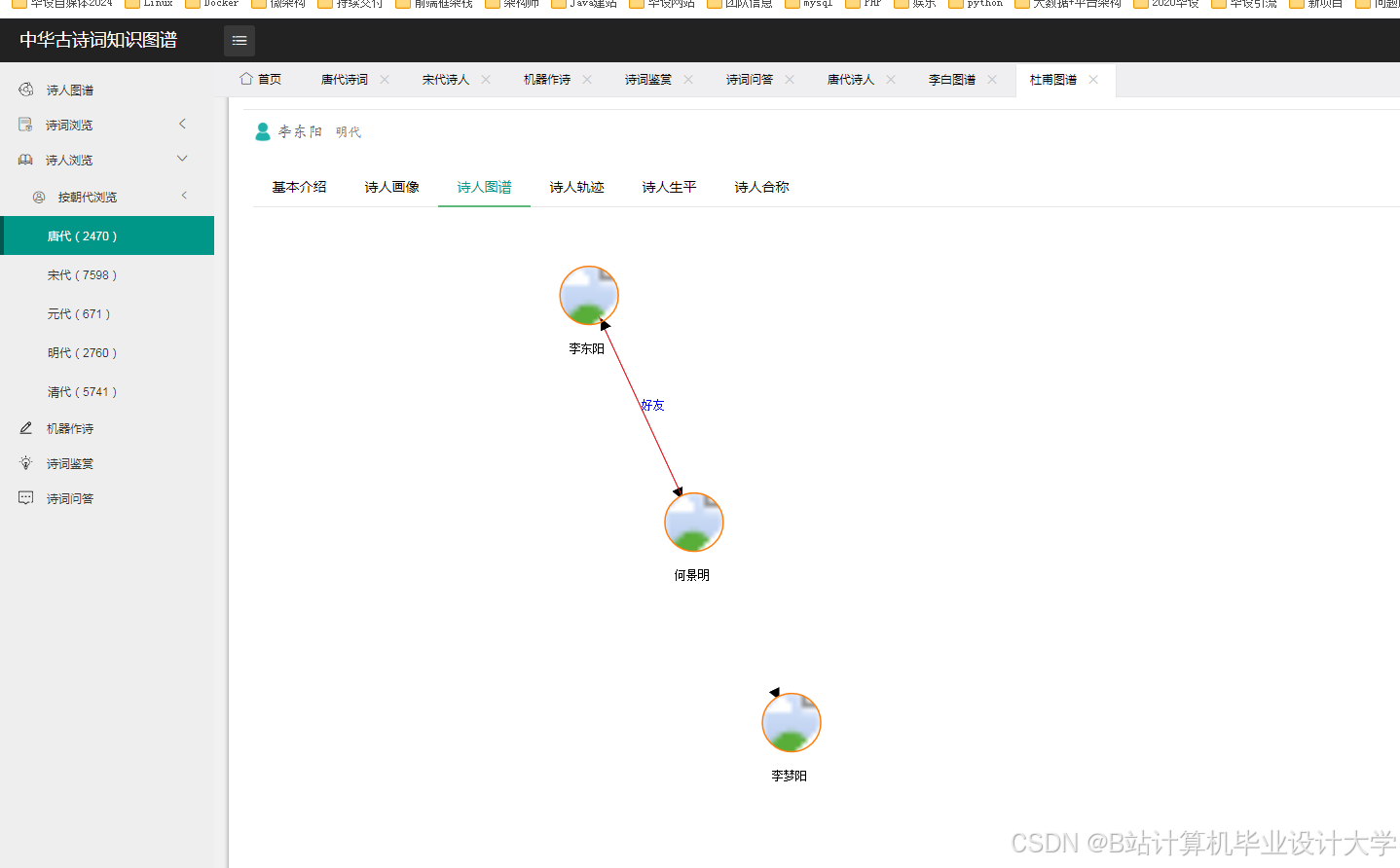
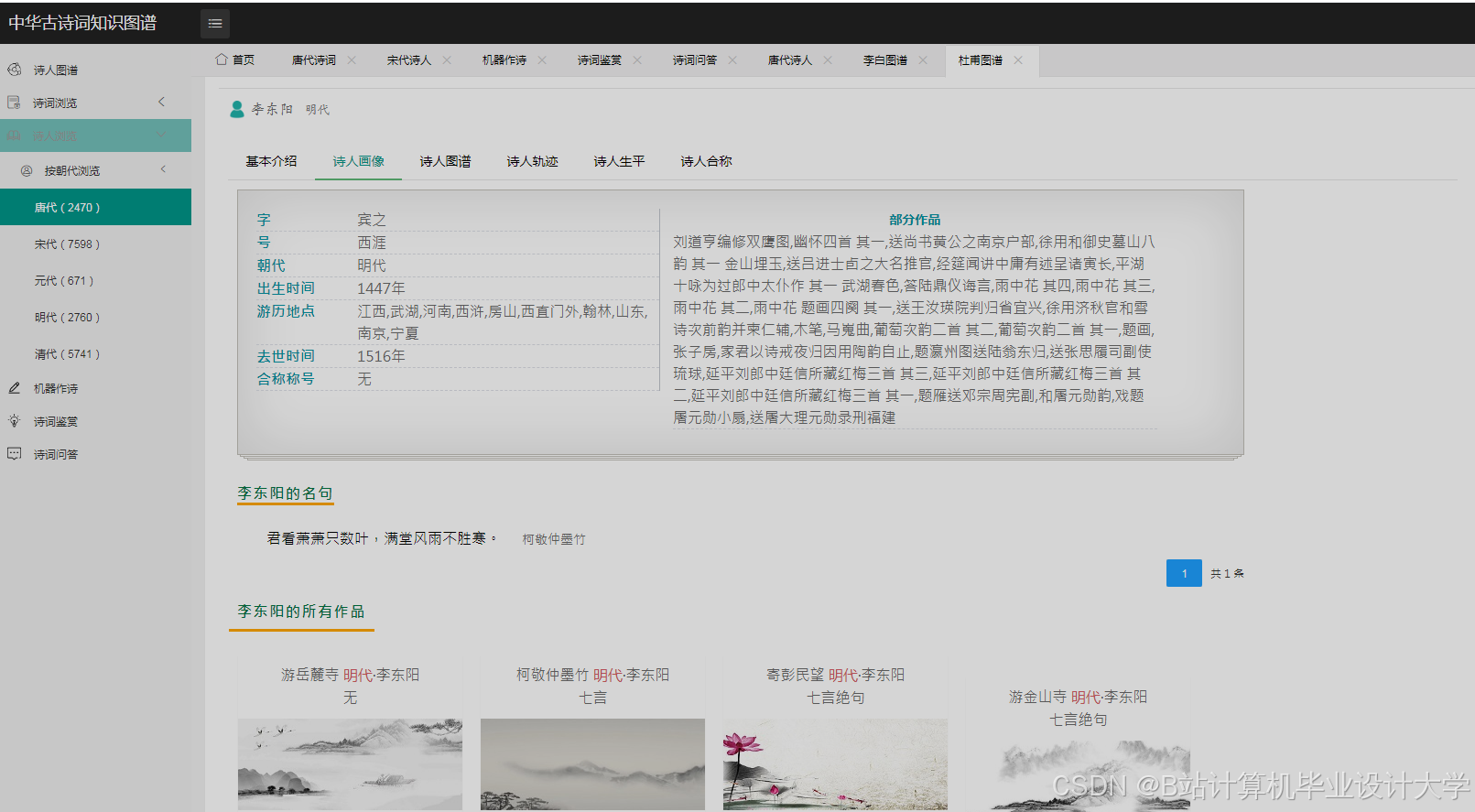
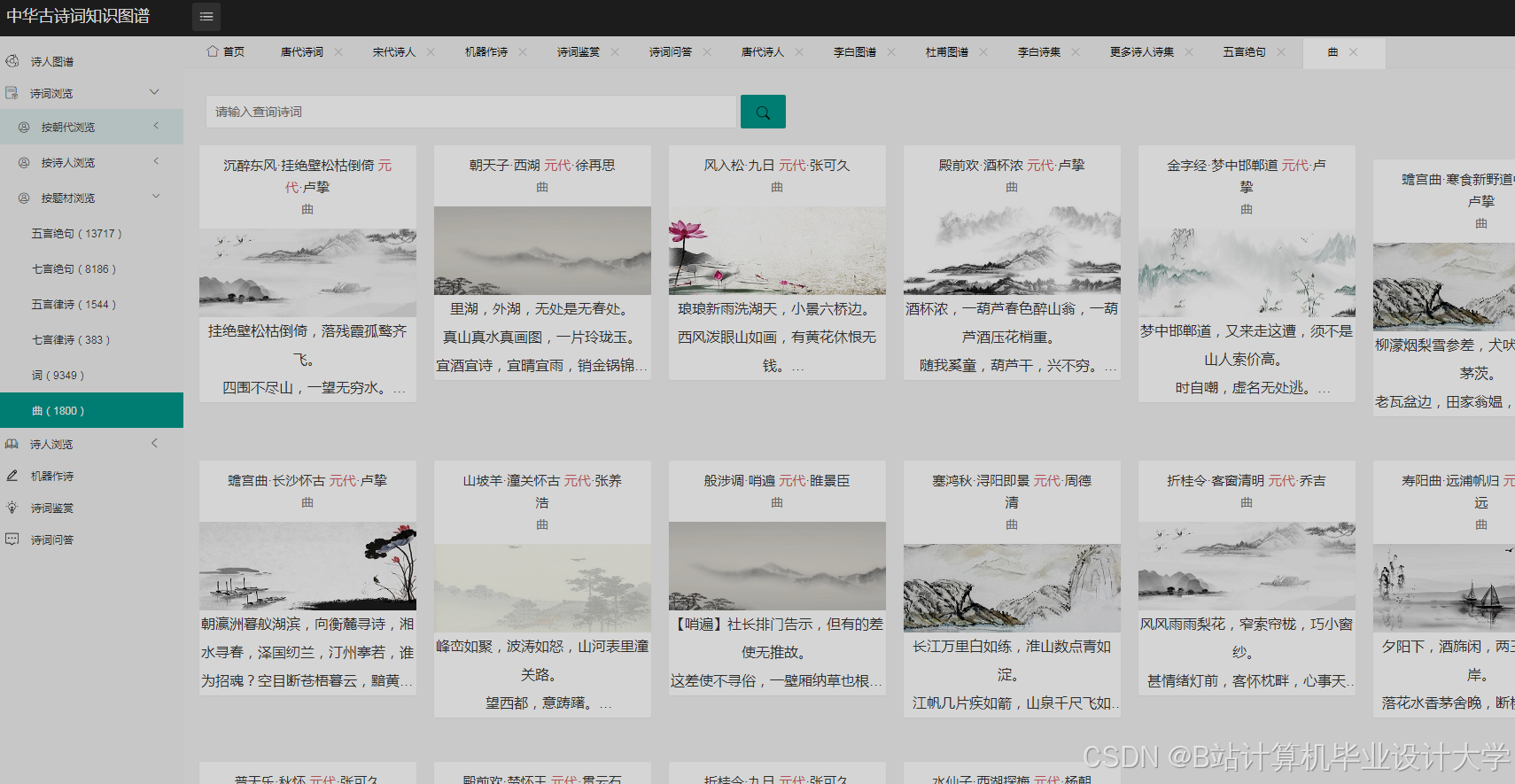
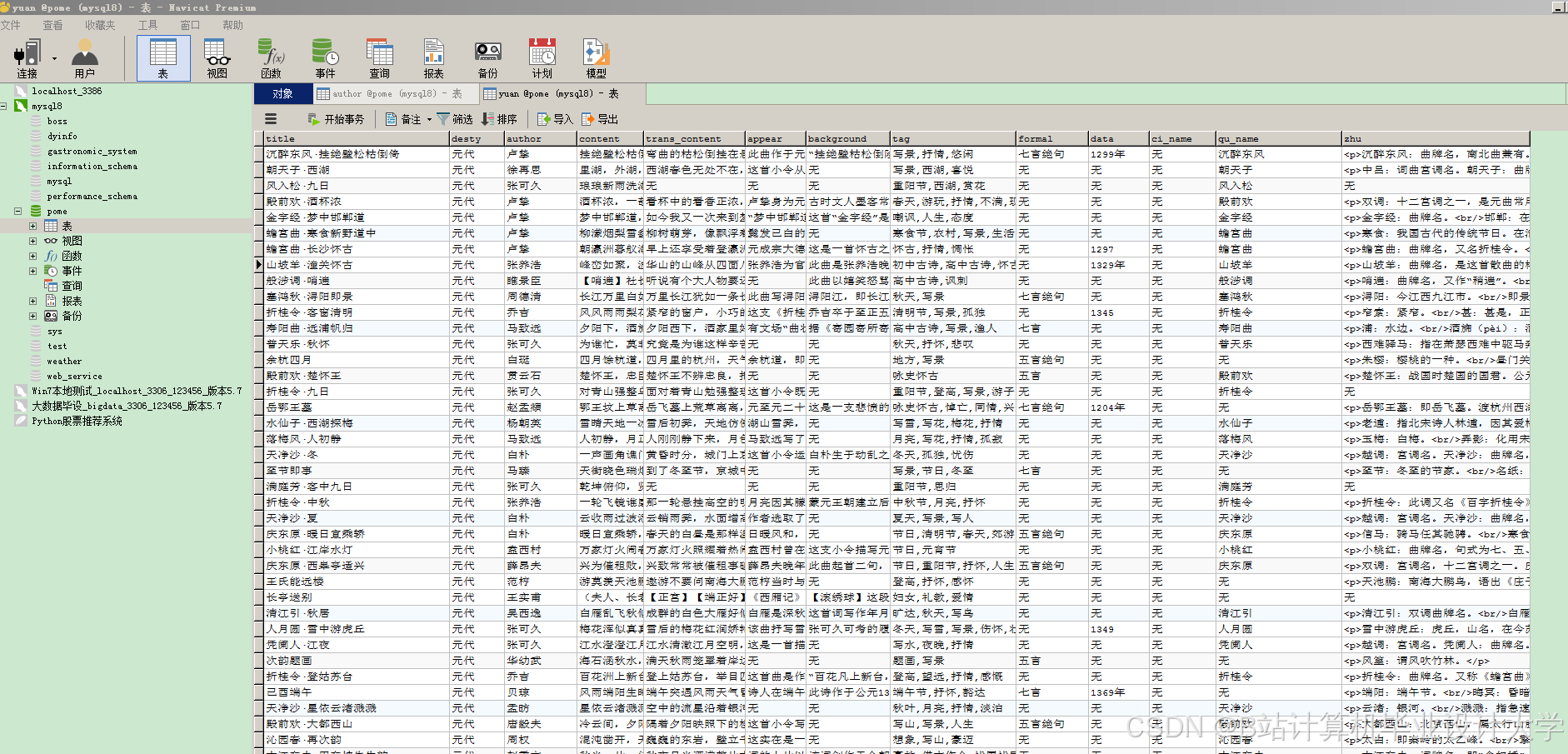
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











