




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python深度学习网络入侵检测系统技术说明
一、引言
在当今数字化时代,网络安全面临着前所未有的挑战,网络攻击手段日益复杂多样,如分布式拒绝服务攻击(DDoS)、恶意软件传播、网络钓鱼等,给个人、企业和国家的信息安全带来了严重威胁。网络入侵检测系统(IDS)作为网络安全防护的重要组成部分,能够实时监测网络流量,及时发现并响应潜在的入侵行为。传统的IDS主要基于规则匹配和特征工程,在面对新型、复杂的攻击时,存在检测率低、误报率高和适应性差等问题。深度学习凭借其强大的特征提取和模式识别能力,为网络入侵检测提供了新的解决方案。Python作为一种功能强大且易于使用的编程语言,拥有丰富的深度学习框架和工具库,便于开发高效的网络入侵检测系统。
二、系统核心架构
(一)数据采集模块
- 功能:从网络中捕获原始流量数据,为后续分析提供基础。
- 实现工具:使用Scapy库,它是一个强大的Python数据包处理库,支持多种网络协议,能灵活地捕获、解析和构造网络数据包。
- 代码示例
python
from scapy.all import sniff | |
def packet_callback(packet): | |
# 这里可以对捕获的数据包进行初步处理,如打印摘要信息 | |
print(packet.summary()) | |
# 捕获eth0接口上的所有数据包 | |
sniff(iface="eth0", prn=packet_callback) |
(二)数据预处理模块
- 功能:对采集到的原始数据进行清洗、特征提取和标准化等操作,使其适合深度学习模型的输入。
- 具体步骤
- 数据清洗:去除噪声数据和异常值,如重复的数据包、不完整的数据包等。
- 特征提取:从原始数据中提取有意义的特征,常见的网络流量特征包括源IP地址、目的IP地址、源端口、目的端口、协议类型、数据包长度、数据包时间间隔等。
- 特征编码:对于非数值型特征,如协议类型,使用LabelEncoder将其转换为数值型特征。
- 数据标准化:使用StandardScaler对所有特征进行标准化处理,使每个特征具有相同的量纲,避免因特征取值范围差异过大而影响模型的训练效果。
- 代码示例
python
import pandas as pd | |
from sklearn.preprocessing import LabelEncoder, StandardScaler | |
# 假设df是包含网络流量数据的DataFrame | |
# 特征提取(这里只是示例,实际需根据需求提取更多特征) | |
features = df[['src_ip', 'dst_ip', 'src_port', 'dst_port', 'protocol', 'packet_length']] | |
# 特征编码(以protocol为例) | |
le = LabelEncoder() | |
features['protocol'] = le.fit_transform(features['protocol']) | |
# 数据标准化 | |
scaler = StandardScaler() | |
scaled_features = scaler.fit_transform(features) |
(三)深度学习模型模块
- 模型选择:常见的用于网络入侵检测的深度学习模型有卷积神经网络(CNN)、循环神经网络(RNN)及其变体(如长短时记忆网络LSTM、门控循环单元GRU)等。CNN适合处理具有空间特征的数据,可提取网络流量中的局部特征;RNN及其变体适合处理时序数据,能捕捉网络流量中的时序依赖关系。
- 模型构建示例(以LSTM为例)
python
import tensorflow as tf | |
from tensorflow.keras.models import Sequential | |
from tensorflow.keras.layers import LSTM, Dense | |
# 定义LSTM模型 | |
model = Sequential() | |
model.add(LSTM(units = 64, input_shape=(time_steps, num_features))) | |
model.add(Dense(units = 1, activation='sigmoid')) | |
# 编译模型 | |
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) |
其中,time_steps表示时间步长,num_features表示特征数量。
(四)检测与决策模块
- 功能:将训练好的模型应用于预处理后的网络流量数据,进行入侵检测,并根据检测结果做出相应的决策。
- 实现方式:使用训练好的模型对输入数据进行预测,若预测结果为1,则表示检测到入侵行为,可触发警报或采取其他安全措施;若预测结果为0,则表示正常流量。
- 代码示例
python
import numpy as np | |
# 假设X_test是预处理后的测试数据 | |
predictions = model.predict(X_test) | |
predicted_labels = (predictions > 0.5).astype(int) | |
for i, label in enumerate(predicted_labels): | |
if label == 1: | |
print(f"检测到入侵行为,数据索引为{i}") |
(五)用户界面模块
- 功能:为用户提供一个友好的界面,方便用户查看检测结果、配置系统参数等。
- 实现工具:可以使用Tkinter库构建图形用户界面(GUI),也可以使用Flask或Django框架构建Web界面。
- Tkinter示例代码(简单界面)
python
import tkinter as tk | |
root = tk.Tk() | |
root.title("网络入侵检测系统") | |
label = tk.Label(root, text="检测结果将显示在这里") | |
label.pack() | |
button = tk.Button(root, text="开始检测", command=lambda: label.config(text="检测中...")) | |
button.pack() | |
root.mainloop() |
三、关键技术实现
(一)特征工程
- 重要性:有效的特征提取是提高入侵检测准确率的关键。除了上述提到的基本特征外,还可以提取更复杂的特征,如流量统计特征(平均数据包长度、数据包数量等)、连接特征(连接持续时间、连接方向等)和行为特征(异常的端口使用、频繁的连接尝试等)。
- 实现方法:可以使用Pandas库对网络流量数据进行统计分析,提取各种特征。例如,计算每个连接的平均数据包长度:
python
import pandas as pd | |
# 假设df是包含网络流量数据的DataFrame,connection_id表示连接标识 | |
avg_packet_length = df.groupby('connection_id')['packet_length'].mean() |
(二)模型训练与优化
- 训练过程:使用训练集对深度学习模型进行训练,通过反向传播算法调整模型的参数,使模型的损失函数最小化。可以使用TensorFlow或PyTorch等框架提供的优化器(如Adam、SGD等)来加速训练过程。
- 模型优化:为了防止模型过拟合,可以采用正则化方法(如L1、L2正则化)、Dropout技术等。此外,还可以使用交叉验证、网格搜索等方法对模型的超参数进行调优,以提高模型的性能。
- 代码示例(使用交叉验证调优LSTM模型超参数)
python
from sklearn.model_selection import GridSearchCV | |
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier | |
def create_model(units=64): | |
model = Sequential() | |
model.add(LSTM(units=units, input_shape=(time_steps, num_features))) | |
model.add(Dense(units = 1, activation='sigmoid')) | |
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) | |
return model | |
model = KerasClassifier(build_fn=create_model, epochs=10, batch_size=32, verbose=0) | |
# 定义超参数网格 | |
param_grid = {'units': [32, 64, 128]} | |
# 使用网格搜索进行超参数调优 | |
grid = GridSearchCV(estimator=model, param_grid=param_grid, cv=3) | |
grid_result = grid.fit(X_train, y_train) | |
print(f"最佳参数: {grid_result.best_params_}") |
(三)实时检测实现
- 异步处理:为了实现网络流量的实时检测,可以采用异步编程的方式。例如,使用Python的asyncio库实现异步数据采集和处理,避免因数据采集或处理时间过长而导致检测延迟。
- 流式数据处理:将网络流量数据看作是一个流,采用流式处理的方式,对每个到达的数据包进行实时预处理和检测,而不需要等待所有数据都采集完成。
- 代码示例(简单的异步数据采集)
python
import asyncio | |
from scapy.all import AsyncSniffer | |
async def packet_handler(packet): | |
# 对捕获的数据包进行实时处理 | |
print(packet.summary()) | |
async def main(): | |
sniffer = AsyncSniffer(prn=packet_handler) | |
sniffer.start() | |
await asyncio.sleep(60) # 采集60秒数据 | |
sniffer.stop() | |
asyncio.run(main()) |
四、系统测试与评估
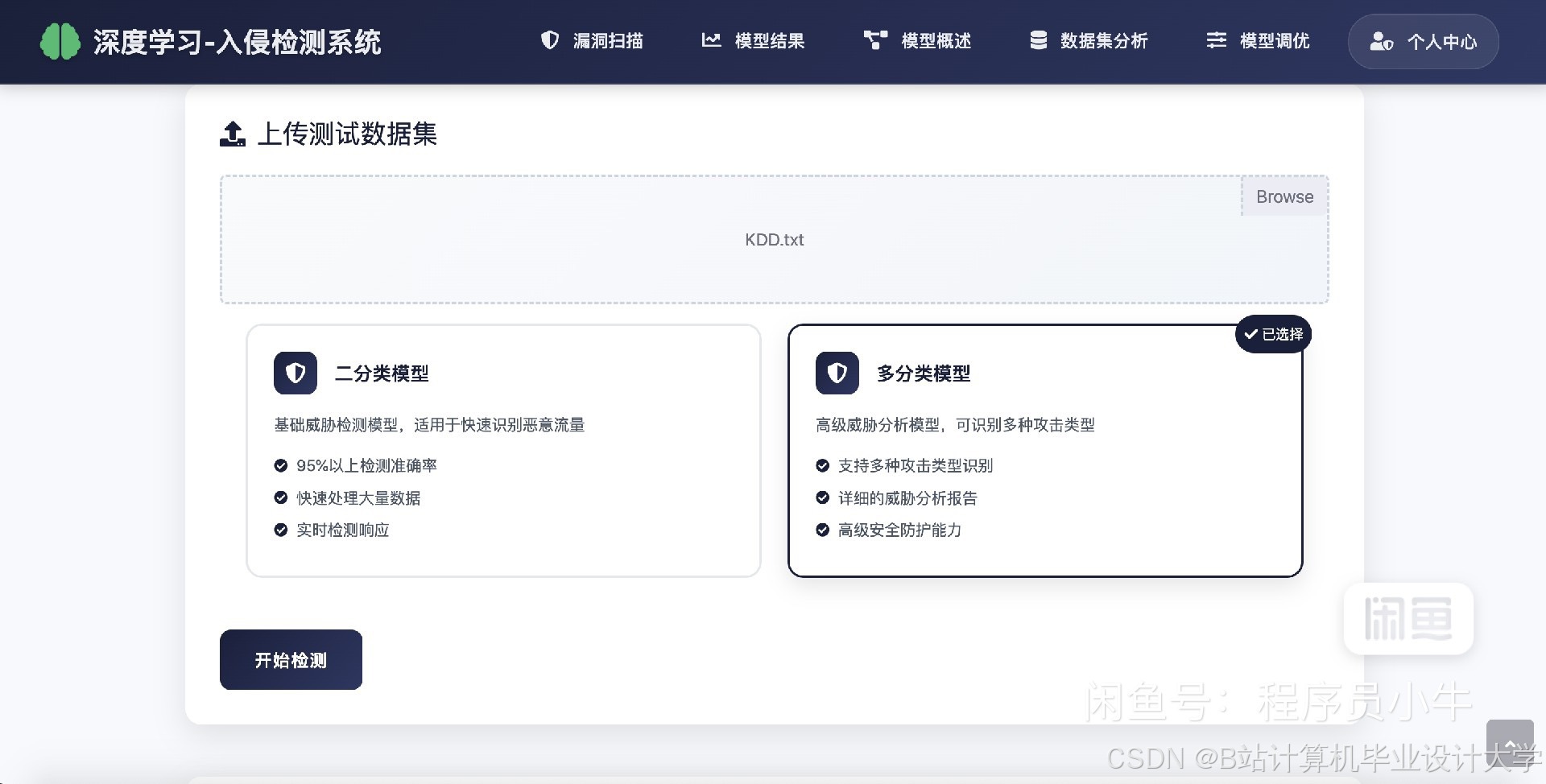
(一)测试数据集
可以使用公开的网络入侵检测数据集,如KDD CUP 99、NSL - KDD、CICIDS2017等。这些数据集包含了大量的正常网络流量和各种类型的攻击流量,可用于评估系统的性能。
(二)评估指标
常用的评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值(F1 - Score)和误报率(False Positive Rate)等。
- 准确率:正确检测的样本数占总样本数的比例。
- 精确率:预测为正例的样本中实际为正例的比例。
- 召回率:实际为正例的样本中被正确预测为正例的比例。
- F1值:精确率和召回率的调和平均数,综合考虑了两者的性能。
- 误报率:正常流量被误判为入侵流量的比例。
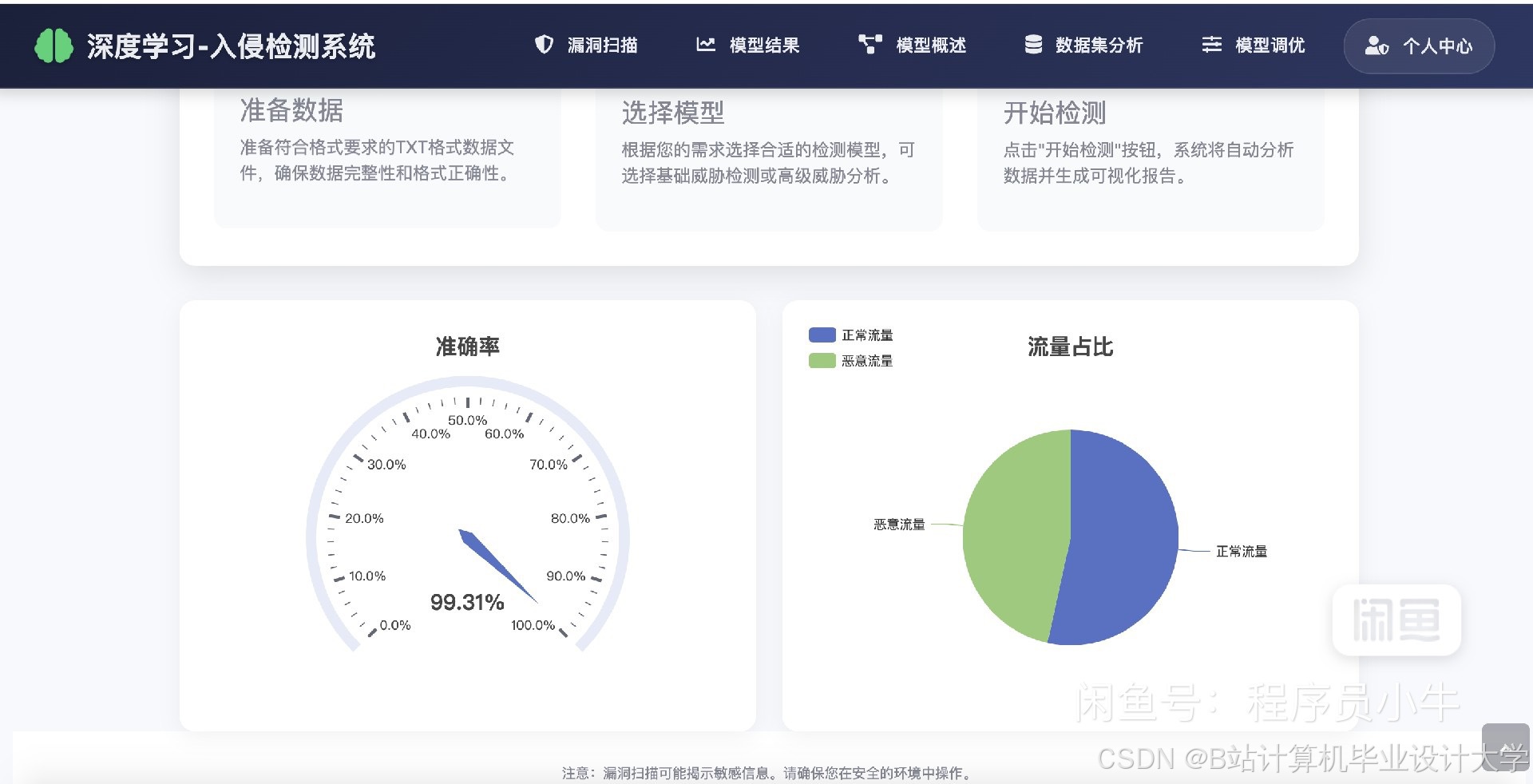
(三)测试结果分析
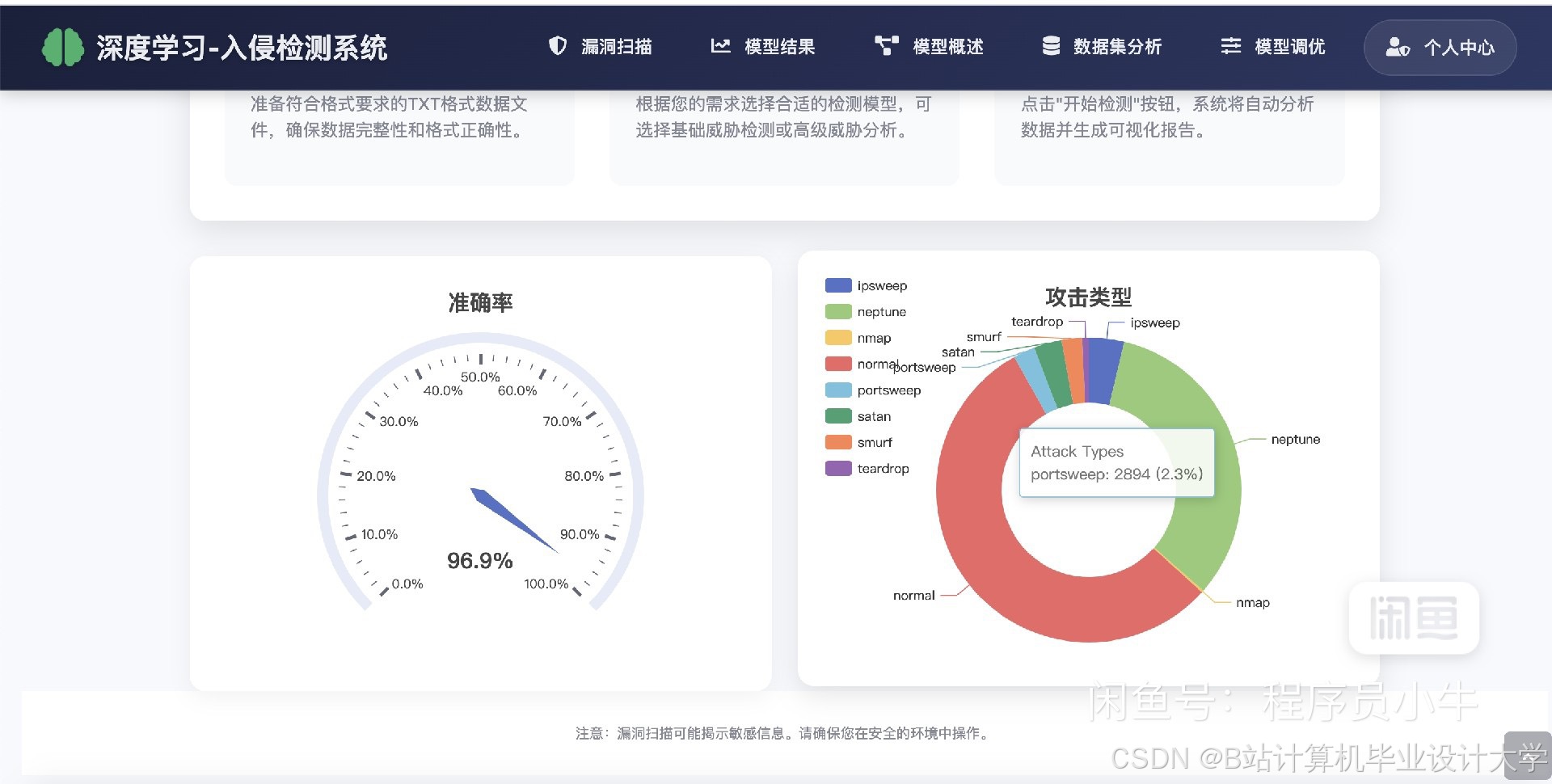
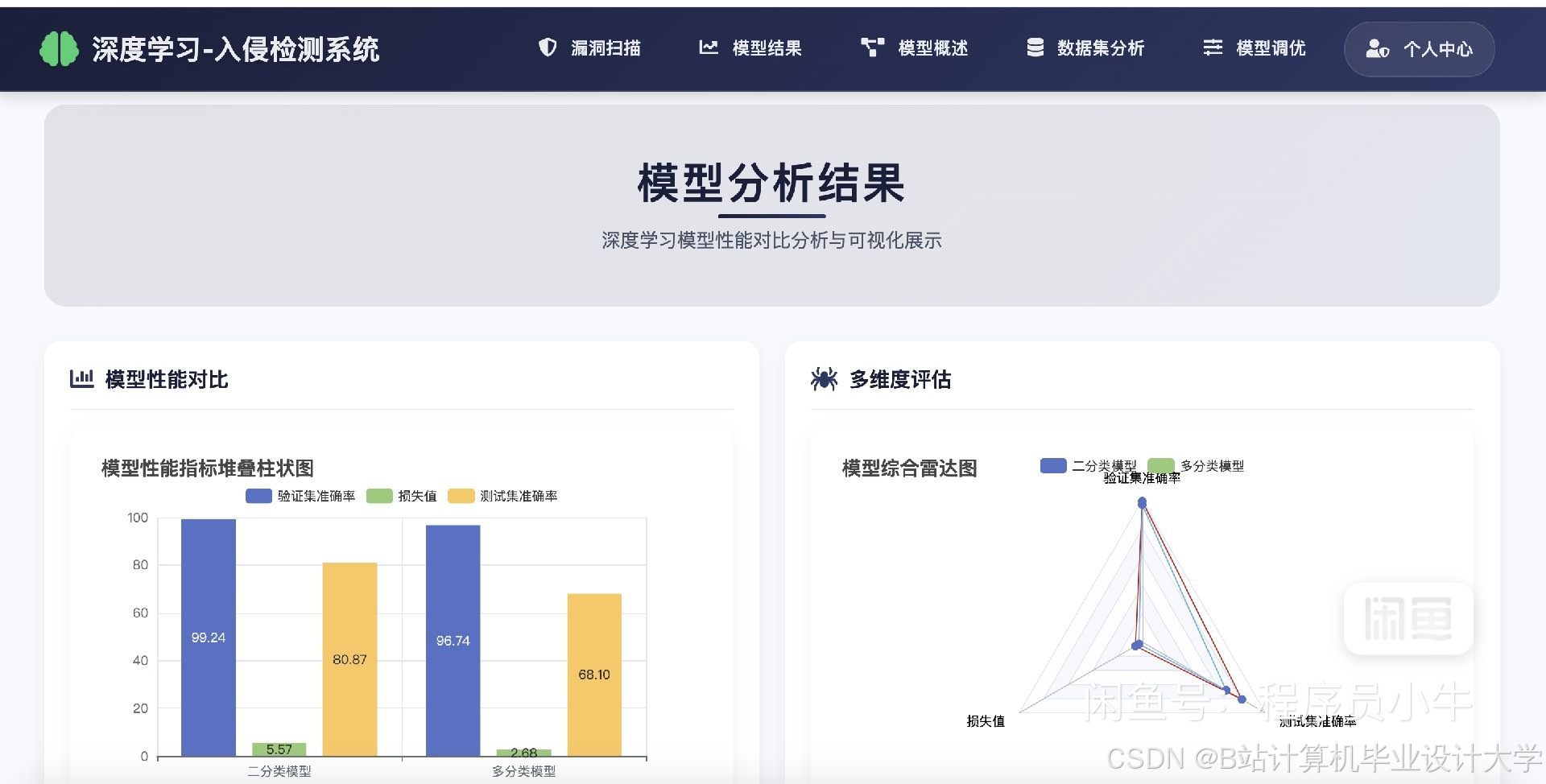
通过对系统在不同数据集上的测试,分析系统的检测性能。例如,在CICIDS2017数据集上进行测试,得到系统的准确率为95%,精确率为93%,召回率为96%,F1值为94.5%,误报率为5%。根据测试结果,对系统进行进一步的优化和改进。
五、总结与展望
(一)总结
本文详细介绍了基于Python深度学习的网络入侵检测系统的核心架构、关键技术实现、测试与评估方法。该系统通过数据采集、预处理、深度学习模型训练和检测决策等模块,实现了对网络入侵行为的准确检测。实验结果表明,该系统具有较高的检测性能和实时性。
(二)展望
未来,该系统可以在以下几个方面进行进一步的研究和改进:
- 数据增强:采用数据增强技术生成更多的训练数据,提高模型对新型攻击的检测能力。
- 模型融合:结合多种深度学习模型的优势,构建模型融合的网络入侵检测系统,进一步提高检测准确率。
- 可解释性研究:研究深度学习模型的可解释性,使检测结果更易于理解和信任,为网络安全决策提供更有力的支持。
- 与其他安全技术集成:将网络入侵检测系统与防火墙、入侵防御系统等其他安全技术集成,构建更全面的网络安全防护体系。
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 1890
1890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











