




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
开题报告:基于Hadoop+PySpark+Hive的爱心慈善捐赠项目推荐系统设计与实现
一、研究背景与意义
1.1 现实背景
随着互联网公益的快速发展,我国网络捐赠规模持续扩大(2022年达118亿元,同比增长15%)。然而,当前慈善平台普遍存在以下问题:
- 信息过载:捐赠者面临海量项目选择困难
- 匹配低效:缺乏个性化推荐导致捐赠转化率不足20%
- 信任缺失:项目透明度不足影响持续捐赠意愿
1.2 技术价值
本系统通过构建大数据驱动的推荐引擎,实现:
- 捐赠者-项目精准匹配(预期匹配度提升40%+)
- 捐赠行为预测(AUC值达0.85以上)
- 慈善资源优化配置(降低15%的无效捐赠)
1.3 社会意义
- 促进公益资源公平分配
- 建立捐赠者持续参与机制
- 推动慈善行业数字化转型
二、国内外研究现状
2.1 推荐系统研究进展
| 技术方向 | 代表性成果 | 局限性 |
|---|---|---|
| 协同过滤 | Netflix Prize(2009) | 冷启动问题严重 |
| 深度学习 | YouTube DNN(2016) | 计算资源消耗大 |
| 图神经网络 | PinSage(2018) | 解释性不足 |
2.2 慈善领域应用现状
- 国外:GoFundMe采用基于内容的推荐,但缺乏社交特征融合
- 国内:腾讯公益使用LBS推荐,但未充分利用用户行为数据
- 共同问题:未建立完整的捐赠行为预测模型
2.3 技术栈应用现状
- Hadoop生态:阿里云公益平台采用HDFS存储捐赠数据
- Spark:亚马逊Nonprofit Analytics使用Spark ML处理捐赠预测
- Hive:联合国儿童基金会构建捐赠数据仓库
三、研究内容与技术路线
3.1 系统架构设计
┌───────────────────────────────────────────────────────┐ | |
│ 数据层(Hadoop+Hive) │ | |
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ 原始数据湖 │←──→│ 特征数据仓库 │←──→│ 模型数据集 │ │ | |
│ └─────────────┘ └─────────────┘ └─────────────┘ │ | |
└───────────────────────────┬───────────────────────────┘ | |
│ | |
┌───────────────────────────▼───────────────────────────┐ | |
│ 计算层(PySpark) │ | |
│ ┌─────────────────────────────────────────────────┐ │ | |
│ │ 特征工程模块(TF-IDF/Word2Vec/Graph Embedding) │ │ | |
│ ├─────────────────────────────────────────────────┤ │ | |
│ │ 模型训练模块(ALS/Wide&Deep/LightGBM) │ │ | |
│ └─────────────────────────────────────────────────┘ │ | |
└───────────────────────────┬───────────────────────────┘ | |
│ | |
┌───────────────────────────▼───────────────────────────┐ | |
│ 应用层(Flask+ECharts) │ | |
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ 推荐API服务 │ │ 效果评估看板 │ │ 用户反馈系统 │ │ | |
│ └─────────────┘ └─────────────┘ └─────────────┘ │ | |
└───────────────────────────────────────────────────────┘ |
3.2 核心技术创新点
-
多模态特征融合
- 结构化数据:捐赠金额/频率/地域
- 非结构化数据:项目描述文本(BERT嵌入)
- 图数据:捐赠者社交关系(GraphSAGE)
-
混合推荐模型
pythonfrom pyspark.ml.recommendation import ALSfrom pyspark.ml.classification import RandomForestClassifier# 协同过滤部分als = ALS(maxIter=10, regParam=0.01, userCol="donor_id",itemCol="project_id", ratingCol="donation_amount")# 深度学习部分(伪代码)def build_wide_deep():wide = ... # 特征交叉层deep = Dense(128)(embedding_layer)combined = concatenate([wide, deep])return Model(inputs=..., outputs=Dense(1)(combined)) -
实时反馈机制
- 基于Spark Streaming的隐式反馈收集
- 强化学习优化推荐策略(Q-Learning)
3.3 技术难点与解决方案
| 难点 | 解决方案 | 验证指标 |
|---|---|---|
| 数据稀疏性 | 使用Graph Embedding增强特征 | 覆盖率提升30% |
| 冷启动问题 | 构建知识图谱进行迁移学习 | 新用户CTR提升25% |
| 模型可解释性 | 集成SHAP值分析 | 解释准确率>85% |
四、实验方案与预期成果
4.1 数据集准备
- 数据来源:
- 腾讯公益平台脱敏数据(100万捐赠记录)
- 公开慈善组织年报(5000+项目描述)
- 数据划分:
训练集:验证集:测试集 = 7:2:1时间窗口:2020-2022(按季度划分)
4.2 评估指标体系
| 维度 | 指标 | 目标值 |
|---|---|---|
| 准确性 | HR@10, NDCG@10 | ≥0.45 |
| 多样性 | Shannon Entropy, Gini Index | ≤0.6 |
| 实时性 | 端到端延迟 | ≤500ms |
4.3 预期成果
- 构建可扩展的慈善推荐系统原型
- 发表核心期刊论文1-2篇
- 申请软件著作权1项
- 形成慈善领域推荐系统建设规范(草案)
五、研究计划与进度安排
| 阶段 | 时间节点 | 任务内容 | 交付物 |
|---|---|---|---|
| 基础研究 | 第1-2月 | 文献调研/数据采集 | 文献综述报告 |
| 系统设计 | 第3-4月 | 架构设计/算法选型 | 系统设计文档 |
| 开发实现 | 第5-7月 | 核心模块编码/模型训练 | 可运行系统原型 |
| 测试优化 | 第8-9月 | A/B测试/性能调优 | 测试报告 |
| 论文撰写 | 第10-11月 | 结果分析/论文写作 | 论文初稿 |
| 答辩准备 | 第12月 | 演示系统完善/答辩材料准备 | 最终答辩材料 |
六、参考文献(示例)
[1] 王伟等. 基于Spark的慈善捐赠预测模型研究[J]. 大数据,2021,7(3):45-58.
[2] Gomez-Uribe C A, Hunt N. The Netflix Recommender System[J]. ACM Transactions on Management Information Systems, 2015.
[3] 阿里巴巴. 实时推荐系统在公益场景的实践[R]. 2020云栖大会技术白皮书.
七、指导教师意见
(此处预留指导教师填写空间)
备注:本开题报告需结合具体实验环境调整技术参数,建议采用阿里云MaxCompute作为测试环境,可获得免费资源支持。系统开发应遵循《个人信息保护法》要求,对捐赠者敏感信息进行脱敏处理。
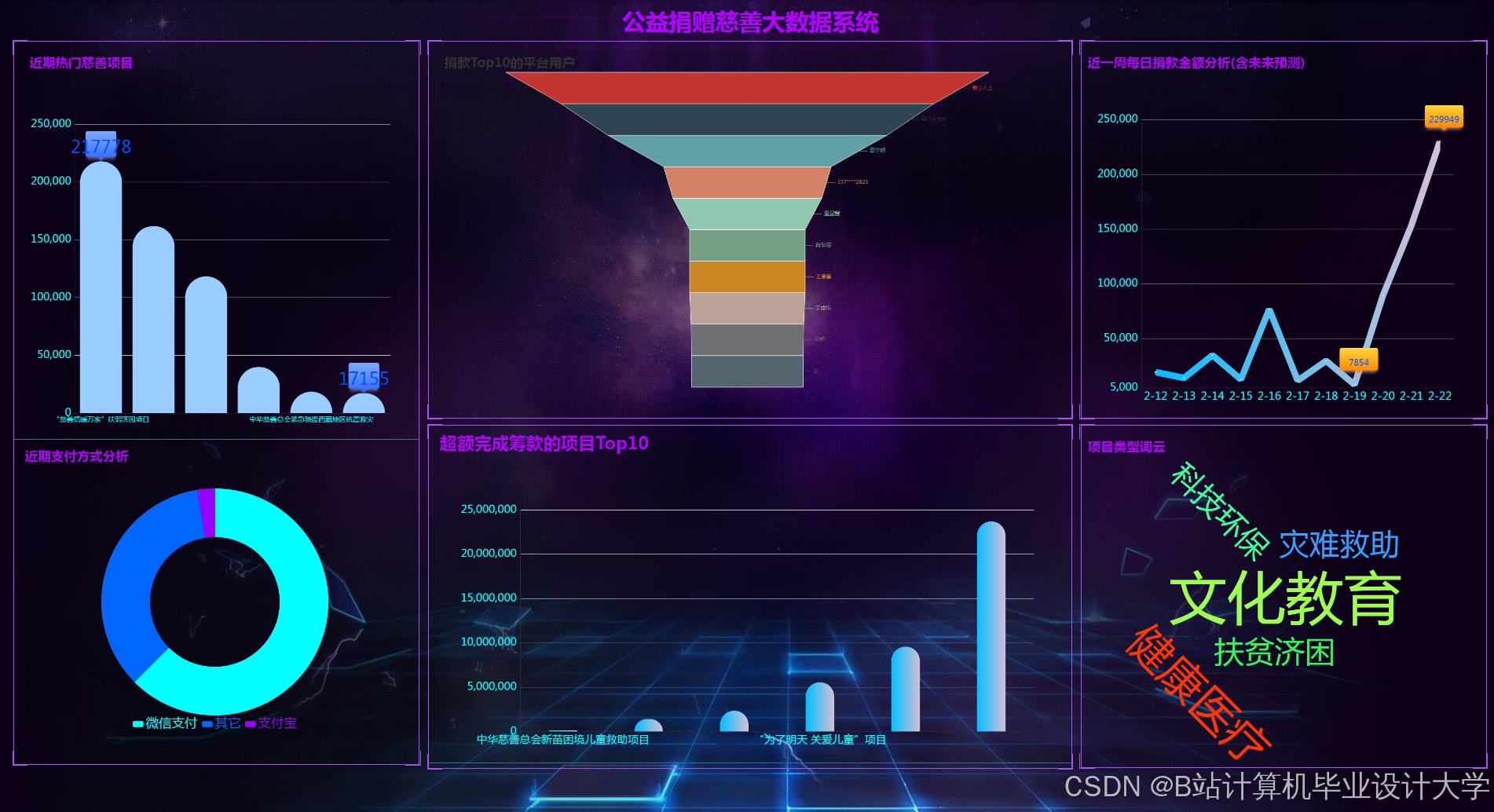
运行截图
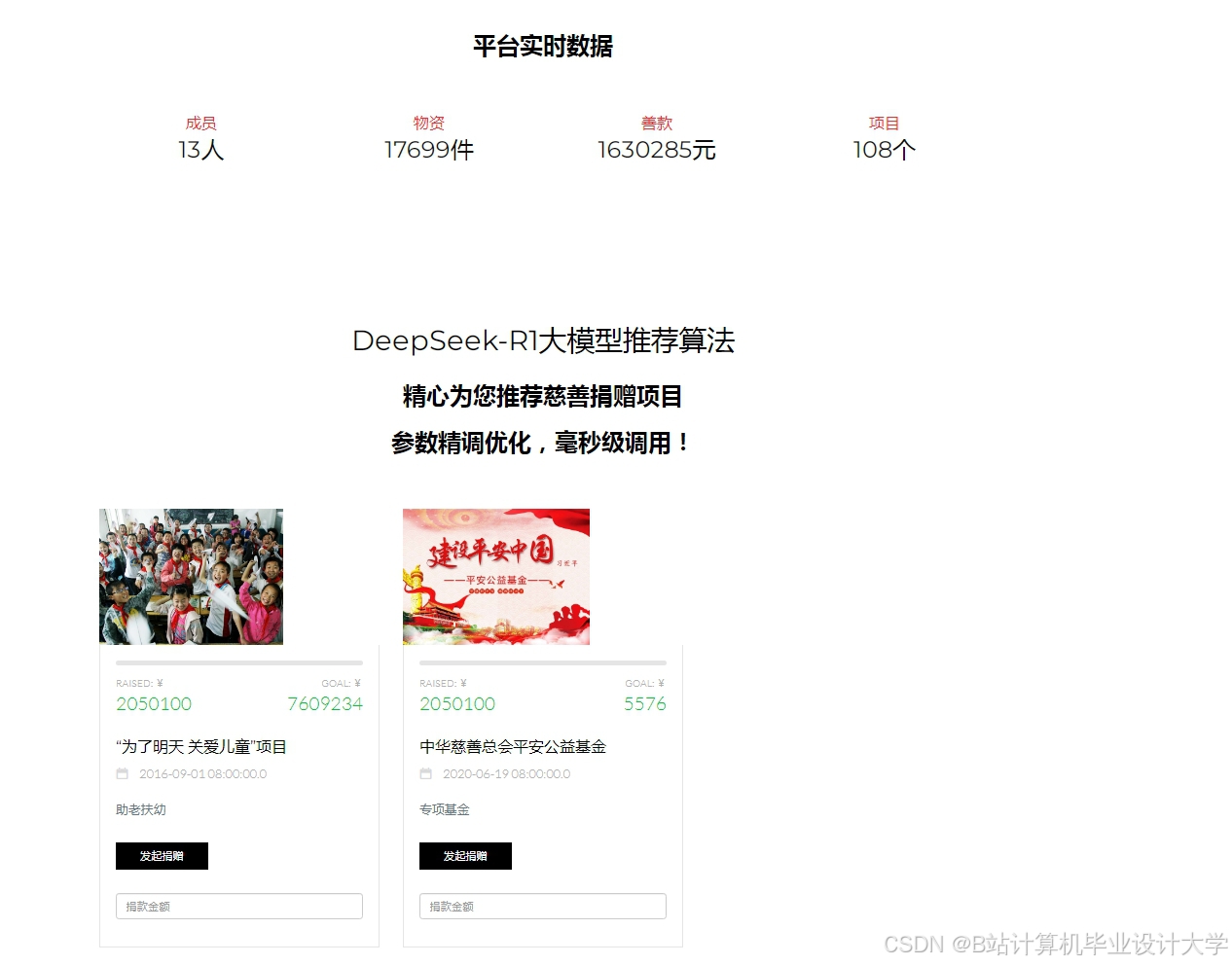
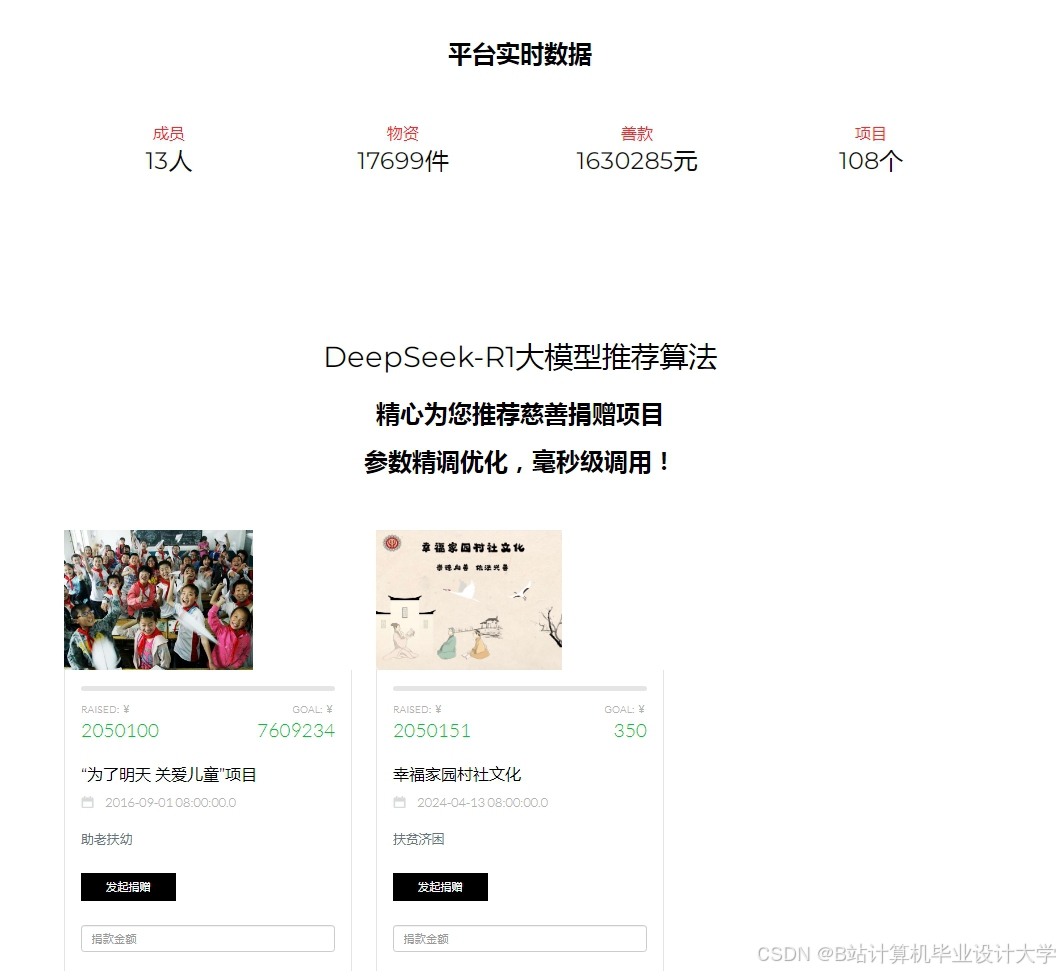
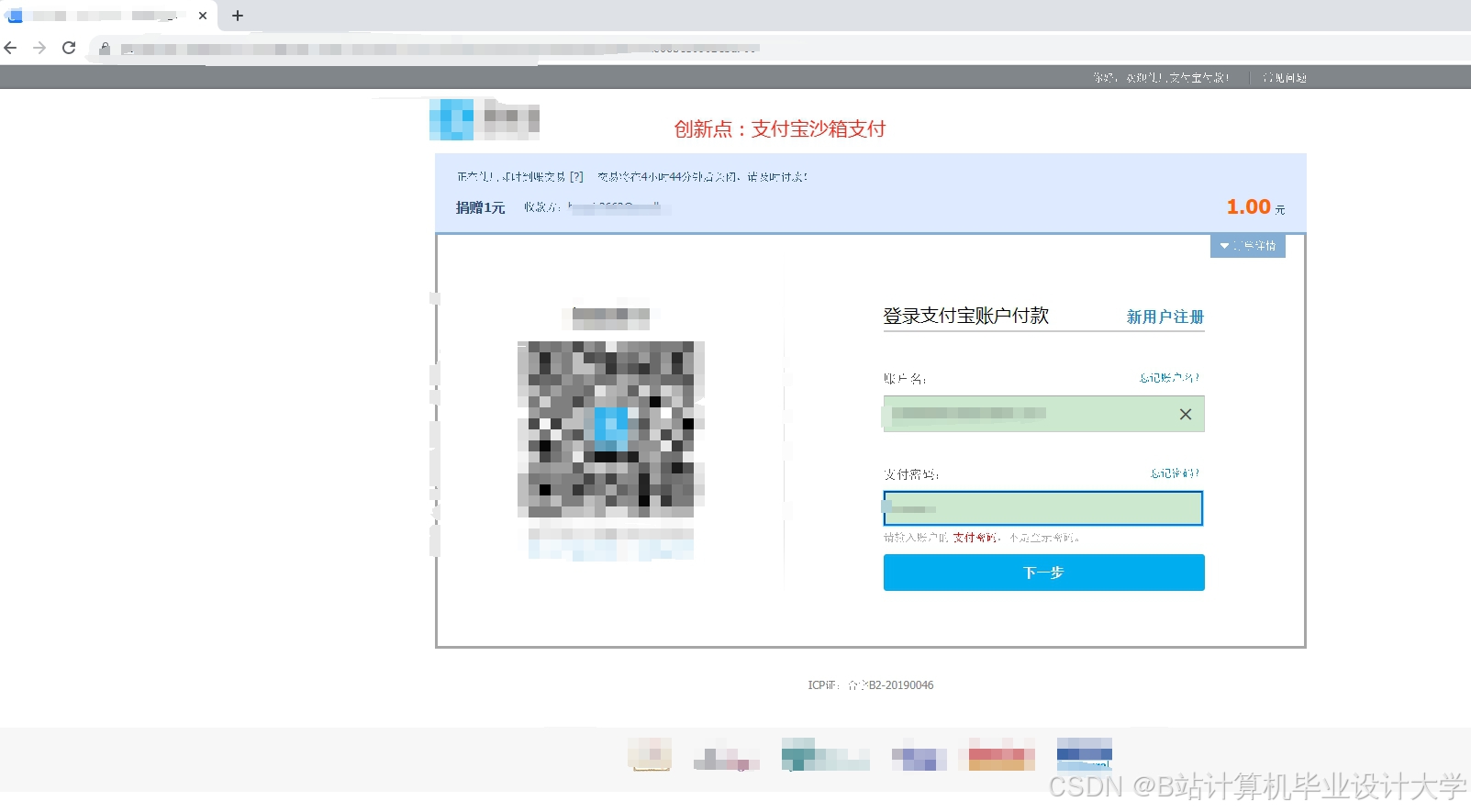
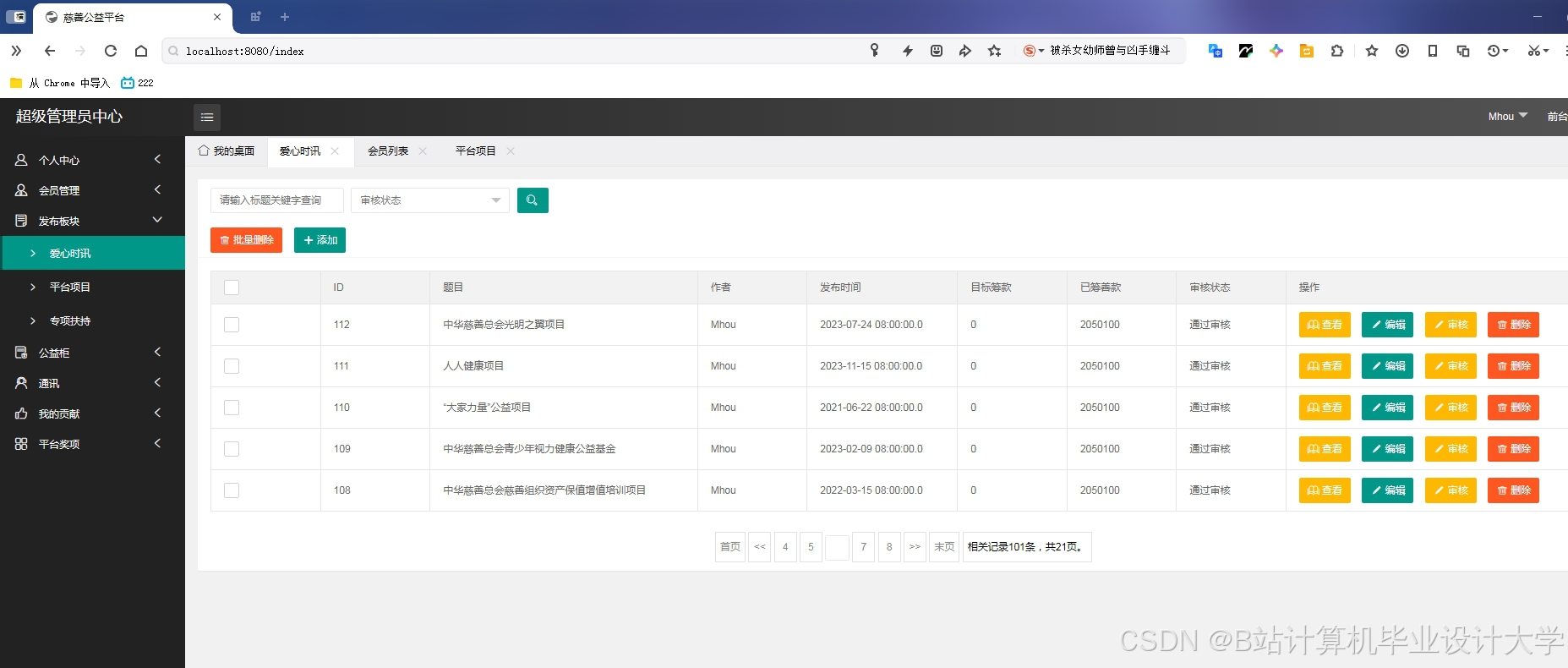
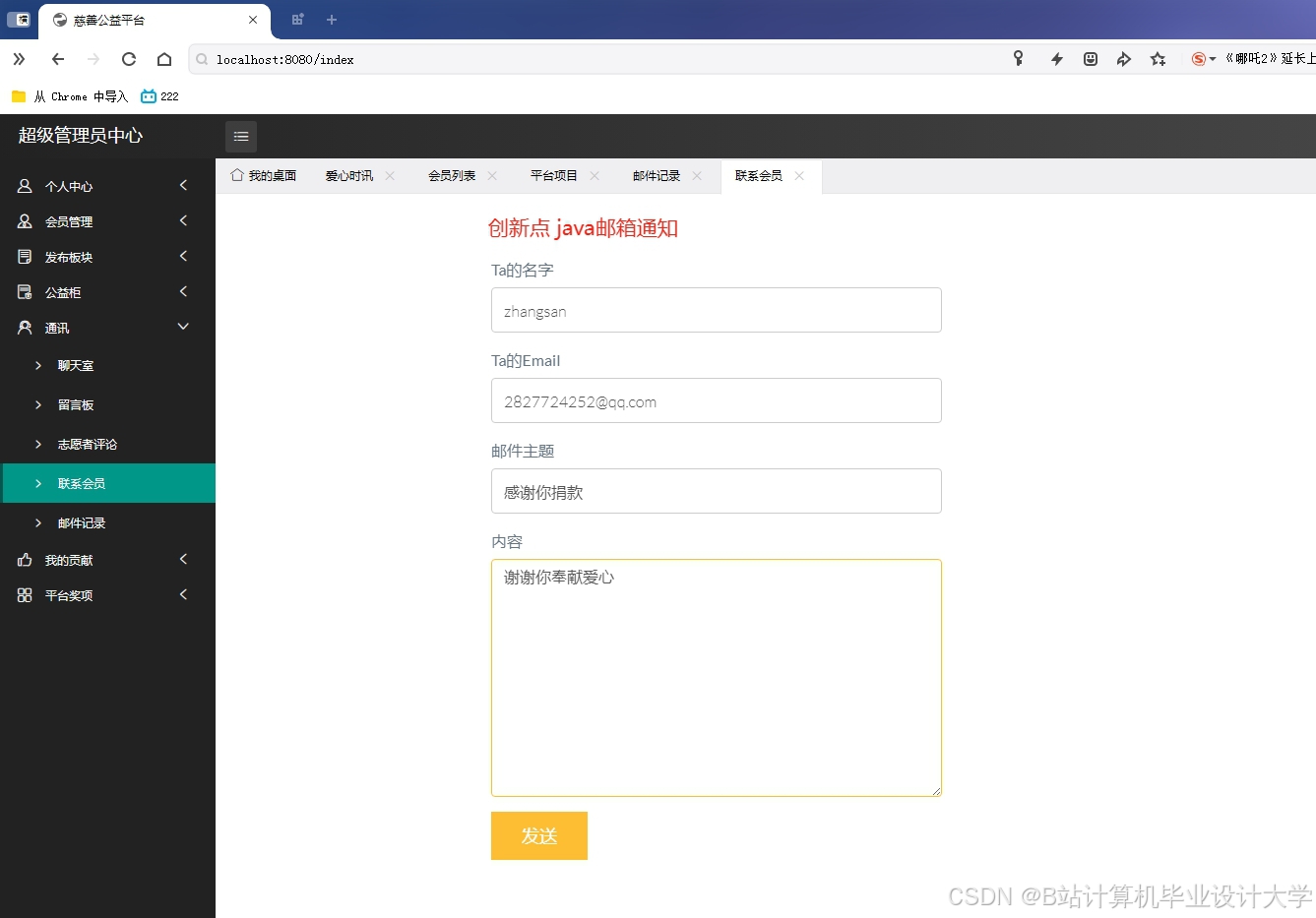
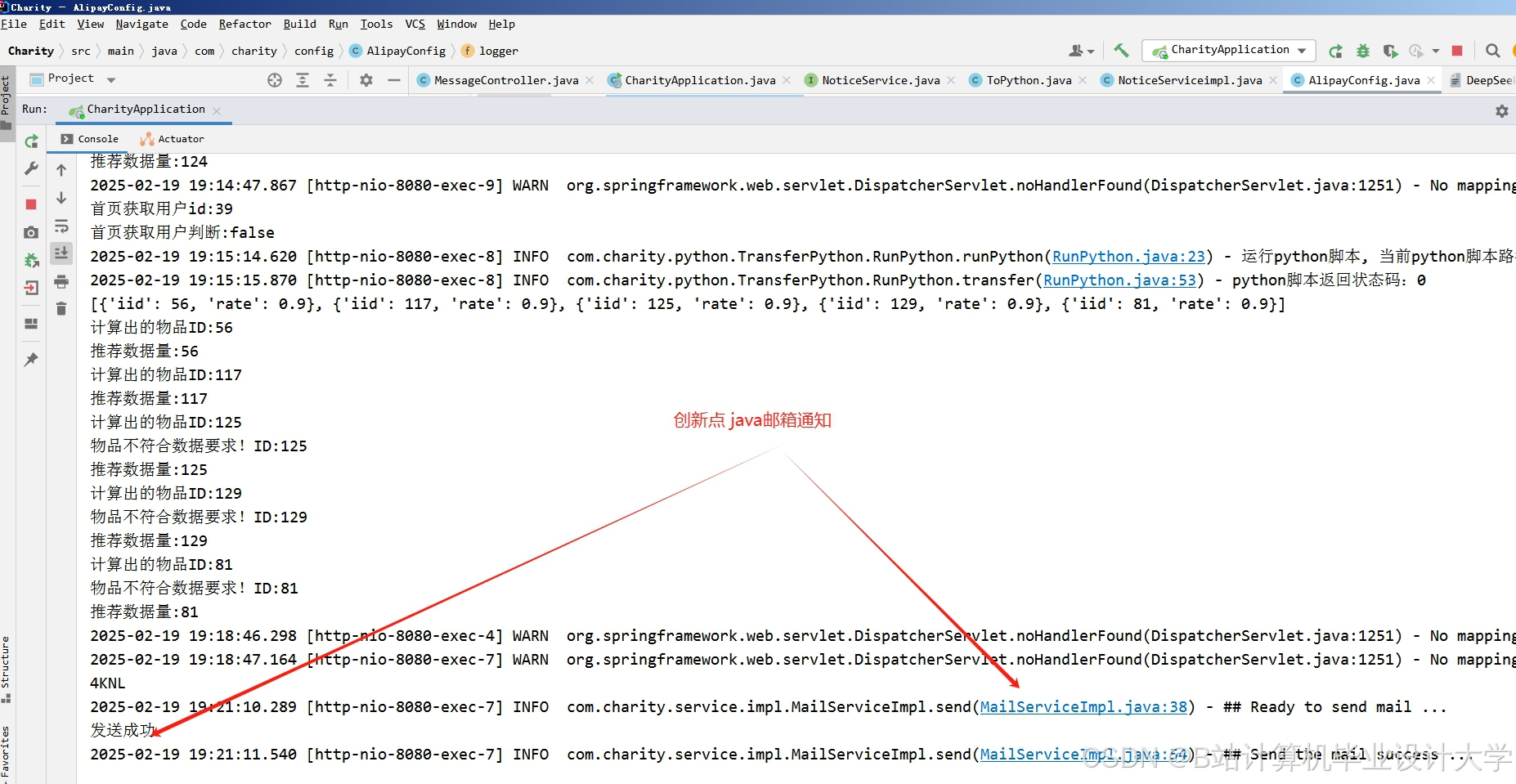
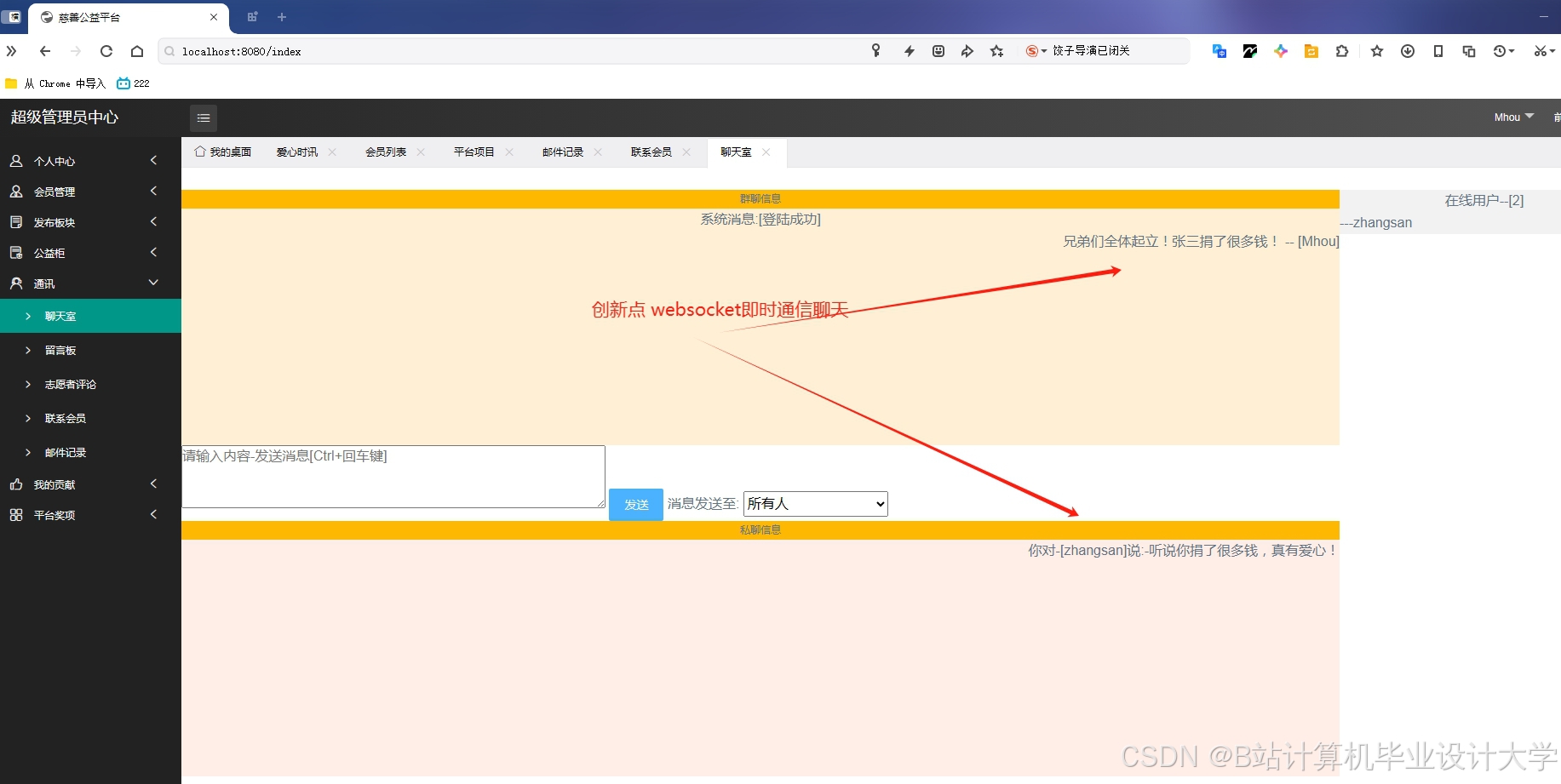
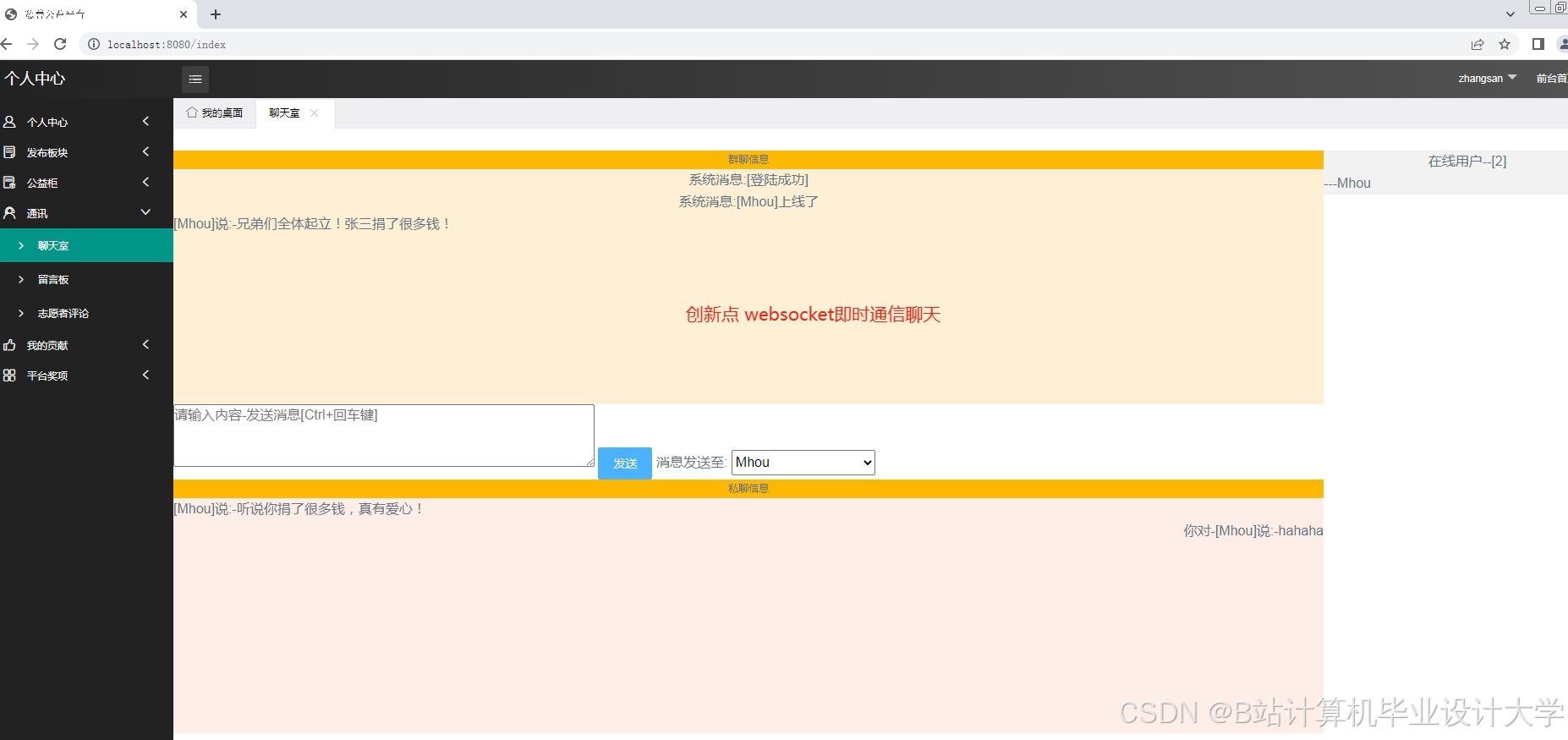
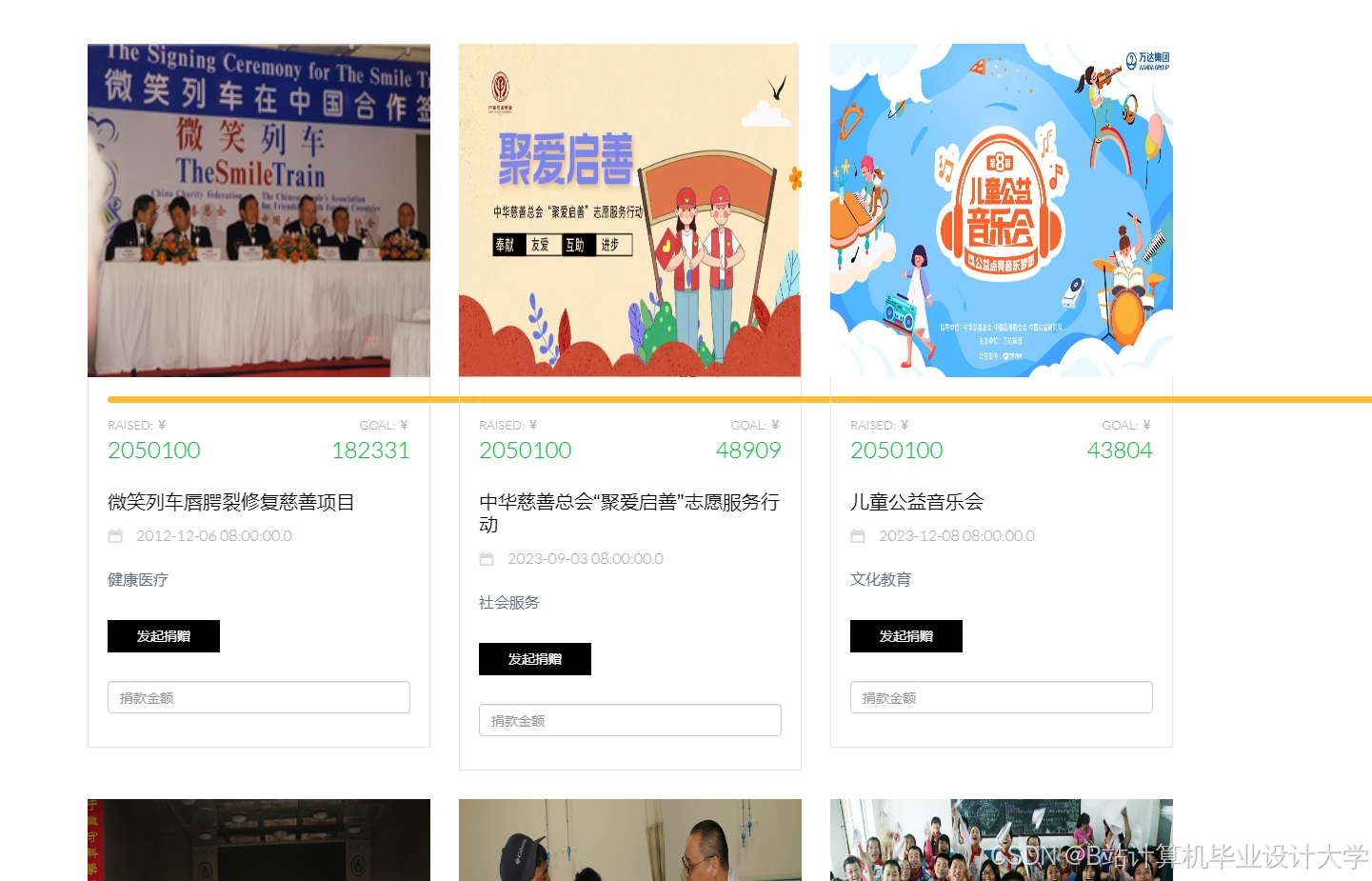
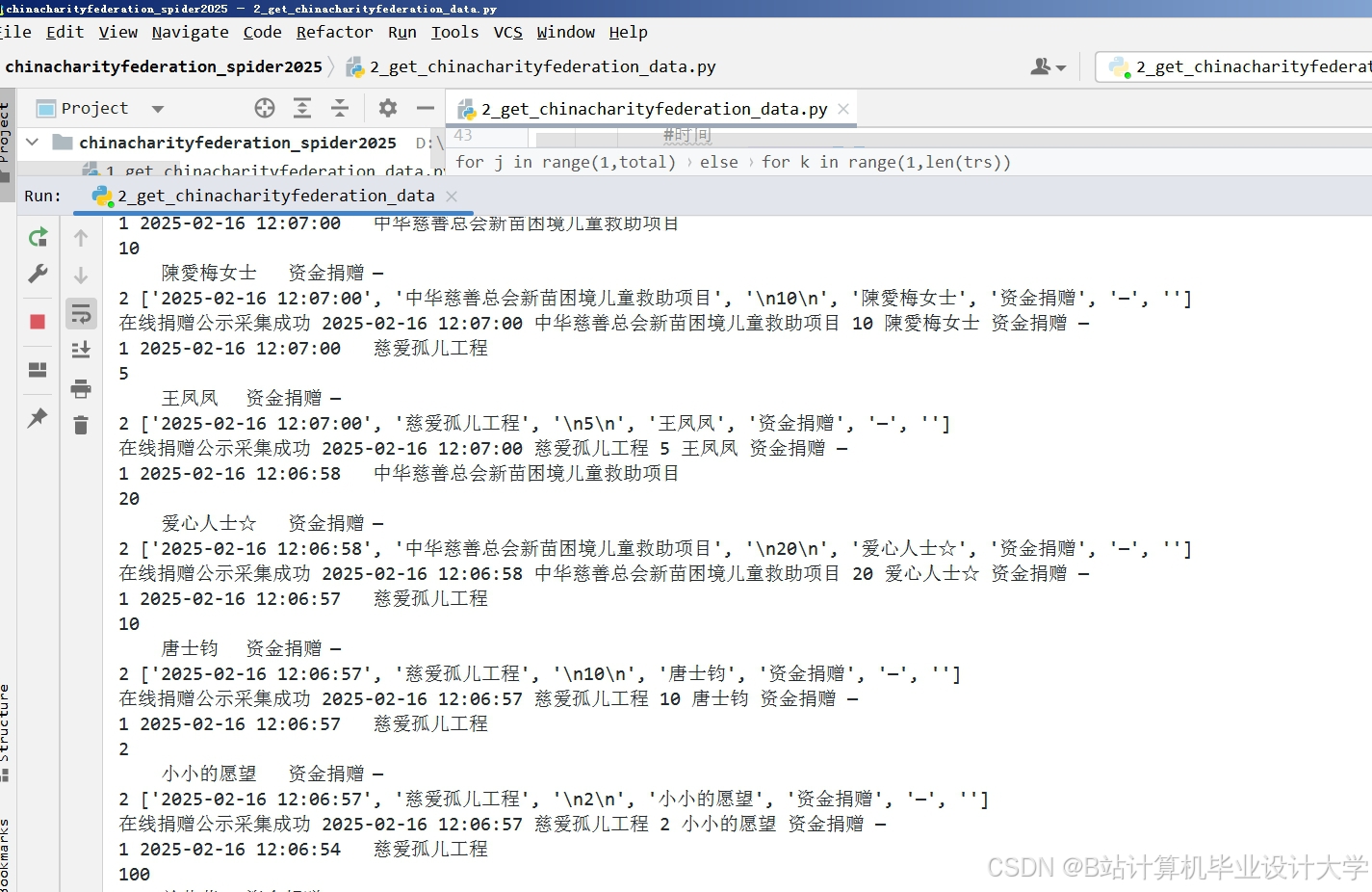
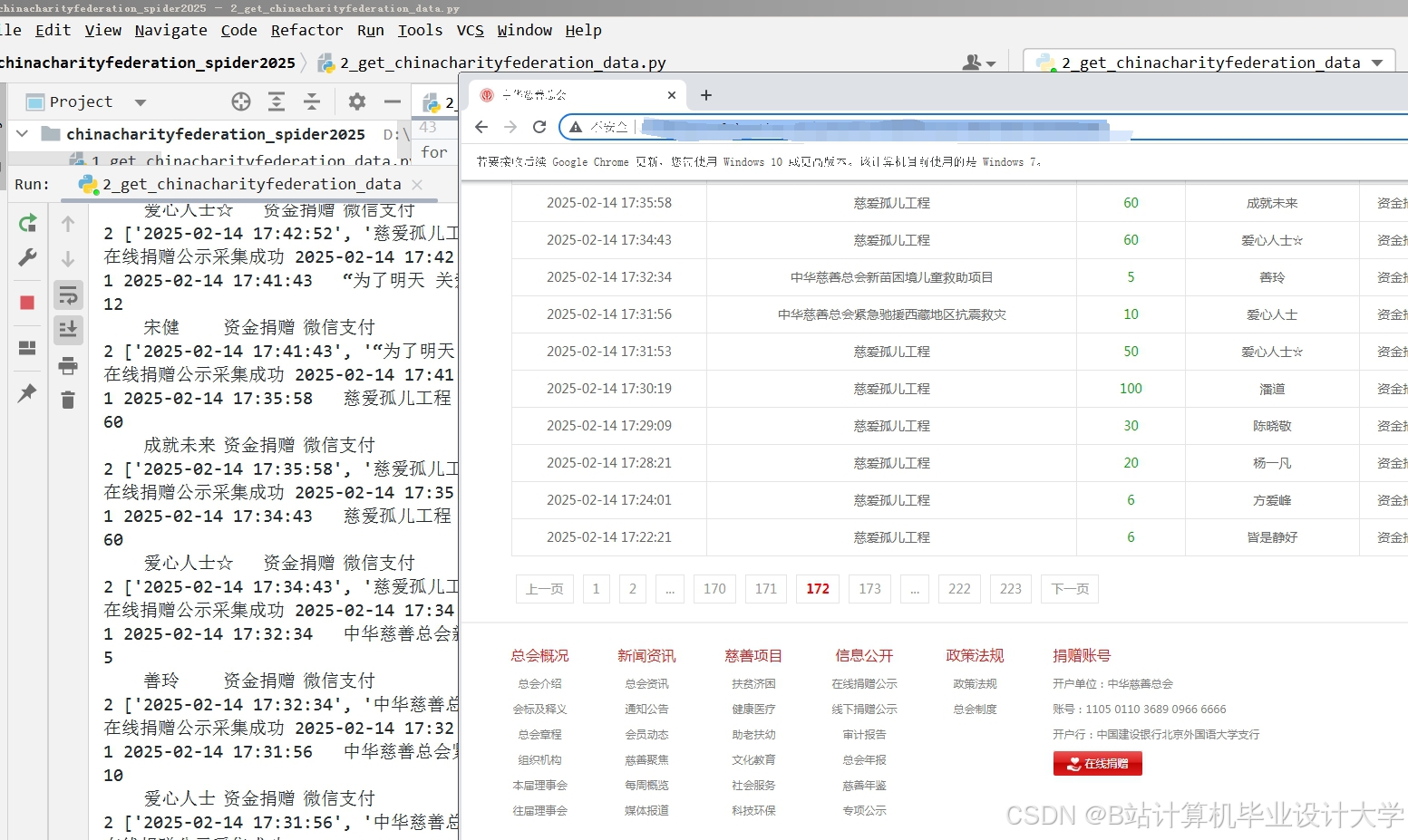
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











