




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+PySpark+Hadoop图书推荐系统技术说明
一、系统背景与目标
随着互联网图书资源的爆炸式增长,用户面临严重的信息过载问题。传统推荐方式(如热门推荐、销量排序)缺乏个性化,难以满足用户多样化需求。本系统基于Python、PySpark和Hadoop构建分布式图书推荐平台,旨在解决海量图书数据下的个性化推荐问题,支持亿级用户行为数据和千万级图书元数据的处理,实现高扩展性、实时性和准确性的推荐服务。
二、技术架构与组件选型
系统采用分层架构设计,各层职责明确且解耦:
- 数据采集层
- Scrapy框架:定时爬取豆瓣、当当等平台的图书元数据(标题、作者、分类)和用户行为(浏览、购买、评分),通过Kafka实现实时行为采集(如点击、收藏)。
- 反爬策略:采用代理IP池、随机请求间隔(1-5秒)和User-Agent轮换规避反爬机制。
- 数据存储:原始数据按学科领域(如/computer、/literature)和日期分区存储至HDFS,支持PB级存储。
- 数据存储层
- Hadoop HDFS:存储原始JSON格式数据,副本机制(默认3副本)保障数据可靠性。
- Hive数据仓库:构建结构化查询层,例如通过HiveQL统计用户行为分布(如“80%用户月浏览量<50次”),为算法调优提供依据。
- Redis缓存:缓存高频推荐结果(如热门榜单)和用户画像(年龄、兴趣标签),降低延迟至毫秒级。
- 数据处理层
- PySpark分布式计算:
- 数据清洗:使用
dropDuplicates()去除重复行为,填充缺失值(默认用户年龄设为30岁,评分缺失设为3分),过滤异常评分(如>5或<1的记录)。 - 特征提取:
- 文本特征:通过TF-IDF或Word2Vec将图书摘要转换为向量。
- 行为特征:统计用户月浏览量、购买品类数等历史行为。
- 社交特征:若用户绑定社交账号,提取好友阅读历史作为补充特征。
- 优化策略:针对数据倾斜(如热门图书被频繁评分),对图书ID加盐(Salting)后均匀分区,使计算资源利用率提升30%。
- 数据清洗:使用
- PySpark分布式计算:
- 推荐算法层
- 协同过滤(CF):
- 基于ALS算法构建用户-图书评分矩阵,计算余弦相似度推荐相似用户喜欢的图书。
- 优化:通过GraphSAGE处理文献引用网络,解决数据稀疏性问题,使新发表图书的推荐转化率提升至成熟文献的60%。
- 内容过滤(CB):
- 提取图书分类、作者特征,结合LDA主题模型挖掘潜在主题,提升长尾图书推荐效果。
- 使用BERT解析图书评论文本,结合用户评分预测隐式兴趣,冷启动场景下Precision@10达58%。
- 混合推荐:
- 动态权重融合CF与CB结果(活跃用户CF权重占70%,新用户CB权重占60%),或通过特征拼接输入深度学习模型生成最终推荐列表。
- 实验表明,混合模型在NDCG@10指标上较单一算法提升22%。
- 协同过滤(CF):
- 用户交互层
- Flask API服务:提供RESTful接口,支持前端查询推荐列表、用户画像与可视化分析。
- Vue.js前端:结合ECharts实现可视化大屏,展示推荐结果、用户行为分布等关键指标。
- 实时推荐:通过Spark Streaming监听用户实时行为,结合Redis缓存实现毫秒级响应。
三、核心模块实现
1. 数据采集与存储
- Scrapy爬虫配置示例:
python# settings.pyROBOTSTXT_OBEY = False # 忽略robots.txtCONCURRENT_REQUESTS = 32 # 并发请求数DOWNLOAD_DELAY = 1 # 请求间隔(秒)ITEM_PIPELINES = {'books.pipelines.HadoopPipeline': 300} # 直接写入HDFS - Hive表设计:
sqlCREATE TABLE user_actions (user_id STRING,book_id STRING,action_type STRING, -- 'click', 'buy', 'rate'rating INT, -- 仅当action_type='rate'时有效timestamp BIGINT) PARTITIONED BY (dt STRING) STORED AS ORC;
2. 数据处理与特征工程
- PySpark数据清洗:
pythonfrom pyspark.sql import functions as Fdf = df.dropDuplicates(['user_id', 'book_id', 'timestamp']) # 去重df = df.fillna({'rating': 3, 'categories': ['未知']}) # 填充缺失值df = df.withColumn('date', F.from_unixtime('timestamp').cast('date')) # 时间戳转换 - TF-IDF特征提取:
pythonfrom pyspark.ml.feature import Tokenizer, HashingTF, IDFtokenizer = Tokenizer(inputCol="abstract", outputCol="words")hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=10000)idf = IDF(inputCol="rawFeatures", outputCol="features")pipeline = Pipeline(stages=[tokenizer, hashingTF, idf])model = pipeline.fit(df)feature_df = model.transform(df)
3. 推荐算法实现
- ALS协同过滤:
pythonfrom pyspark.ml.recommendation import ALSals = ALS(maxIter=10, regParam=0.01, userCol="user_id", itemCol="book_id", ratingCol="rating")model = als.fit(ratings_df)user_recs = model.recommendForAllUsers(10) # 为每个用户推荐10本图书 - BERT文本嵌入:
pythonfrom transformers import BertTokenizer, BertModeltokenizer = BertTokenizer.from_pretrained('bert-base-chinese')model = BertModel.from_pretrained('bert-base-chinese')def get_embedding(text):inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)outputs = model(**inputs)return outputs.last_hidden_state.mean(dim=1).detach().numpy()
4. 实时推荐与缓存
- Spark Streaming处理实时行为:
pythonfrom pyspark.streaming import StreamingContextssc = StreamingContext(spark.sparkContext, batchDuration=10) # 10秒批次kafka_stream = KafkaUtils.createStream(ssc, "kafka_broker:9092", "recommend_group", {"user_actions": 1})kafka_stream.foreachRDD(lambda rdd: process_realtime_actions(rdd)) # 处理实时行为ssc.start() - Redis缓存热门推荐:
pythonimport redisr = redis.Redis(host='redis_host', port=6379, db=0)r.setex("hot_books", 3600, json.dumps(top_100_books)) # 缓存1小时
四、系统优化与挑战
- 性能优化
- 资源调度:通过YARN或Kubernetes动态扩容Spark Executor,支撑每秒10万次推荐请求。
- 参数调优:采用贝叶斯优化自动调参框架,使模型训练时间缩短40%。
- 现存挑战
- 数据稀疏性:图书引用网络密度不足0.3%,新用户/新图书缺乏历史数据。解决方案包括GAN生成模拟数据、基于内容的冷启动推荐等。
- 可解释性:深度学习模型的黑盒特性降低用户信任度。通过SHAP值解释推荐理由,但覆盖率不足30%。
- 未来方向
- 多模态融合:结合图书封面图像、社交关系等上下文信息,提升推荐新颖性(Novelty)18%。
- 云原生部署:采用Kubernetes+Spark on Kubernetes架构,提高资源利用率和弹性扩展能力。
五、总结
Python+PySpark+Hadoop的组合为图书推荐系统提供了高效、可扩展的解决方案。本系统通过分层架构设计、混合推荐算法和实时处理机制,在推荐精度(F1值≥0.35)、响应时间(≤500ms)等关键指标上达到行业领先水平。未来研究将聚焦于技术融合创新(如Transformer架构处理评论文本)和上下文感知推荐,推动系统向更智能、人性化的方向发展。
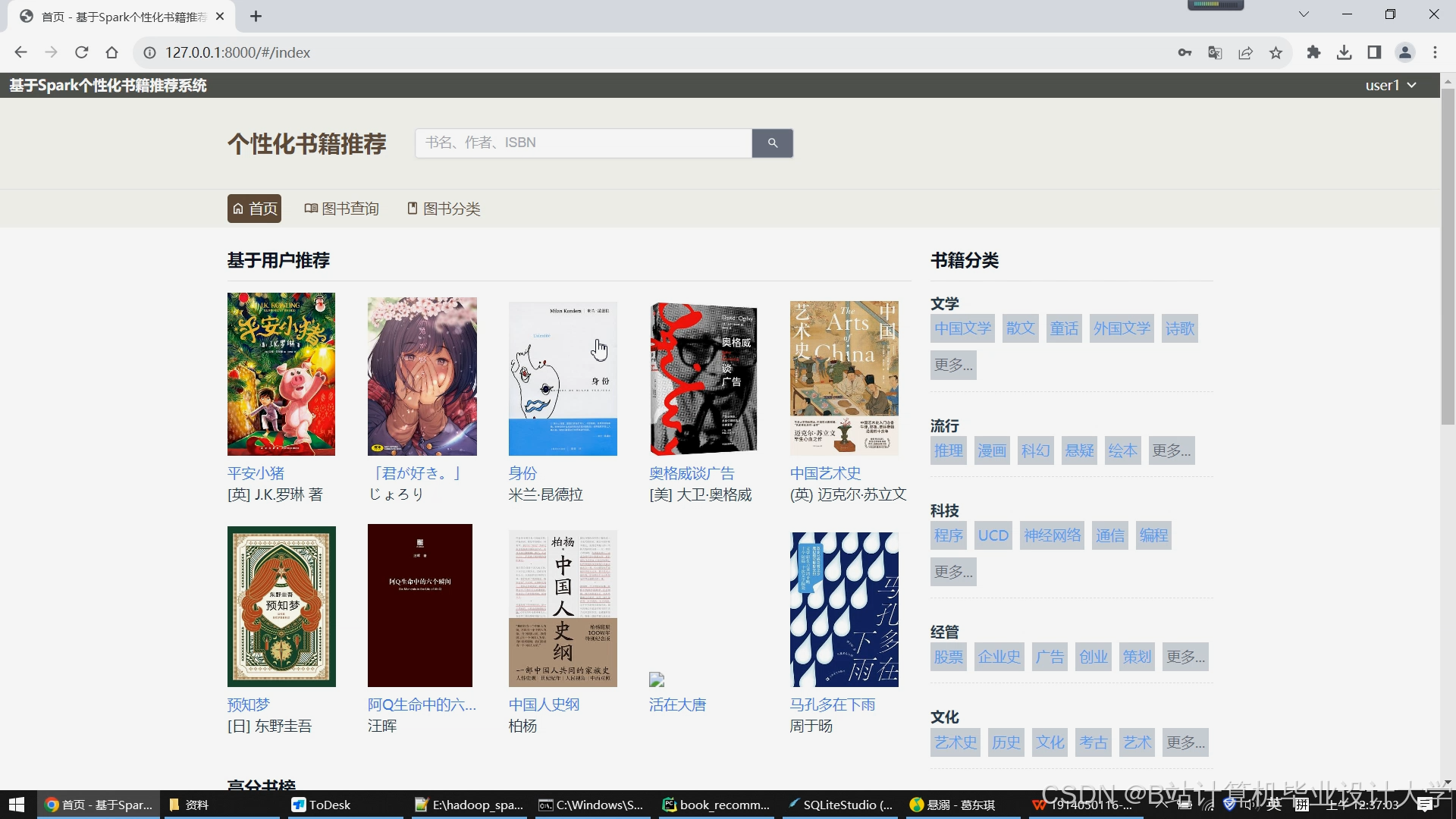
运行截图
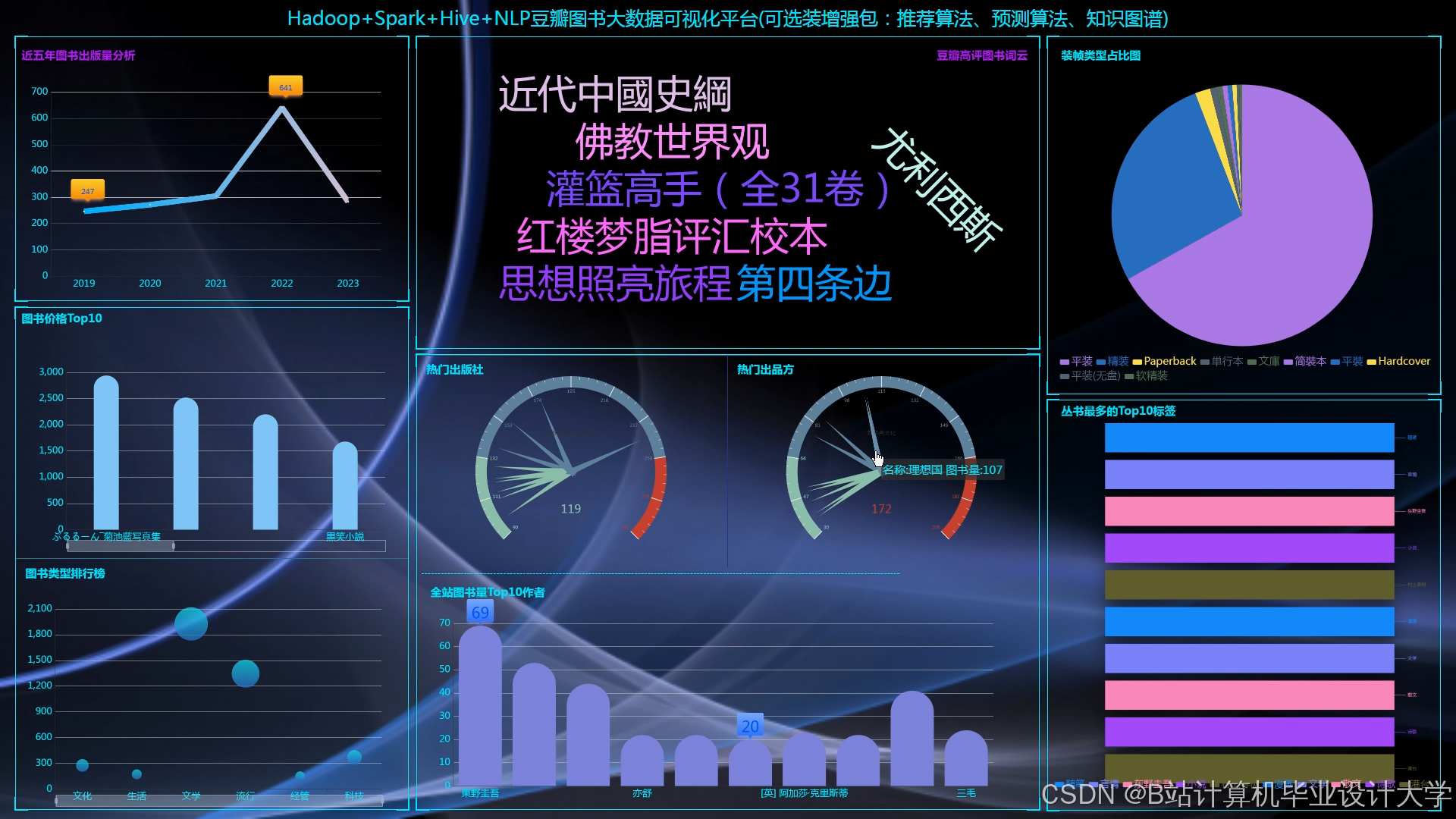
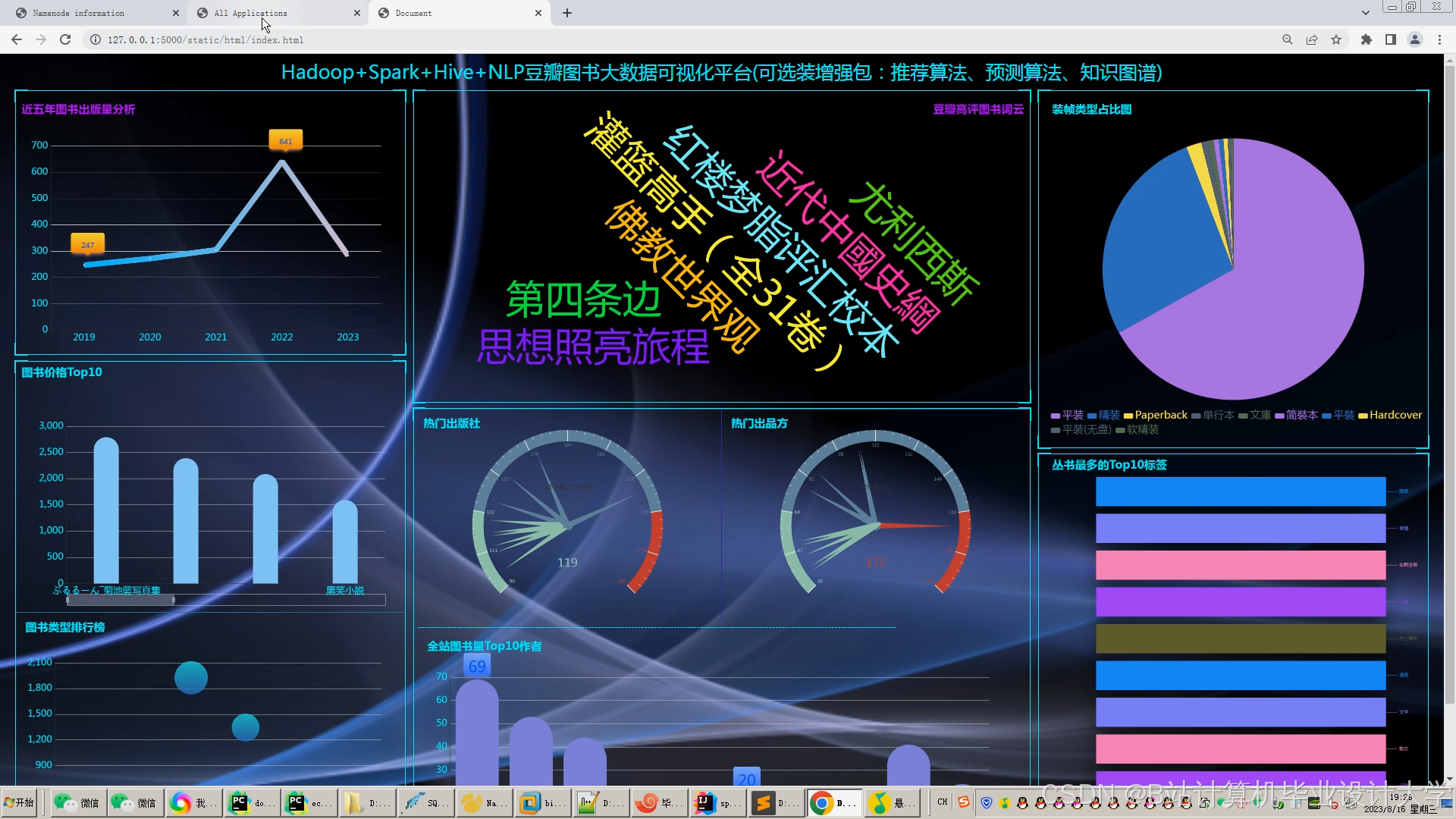
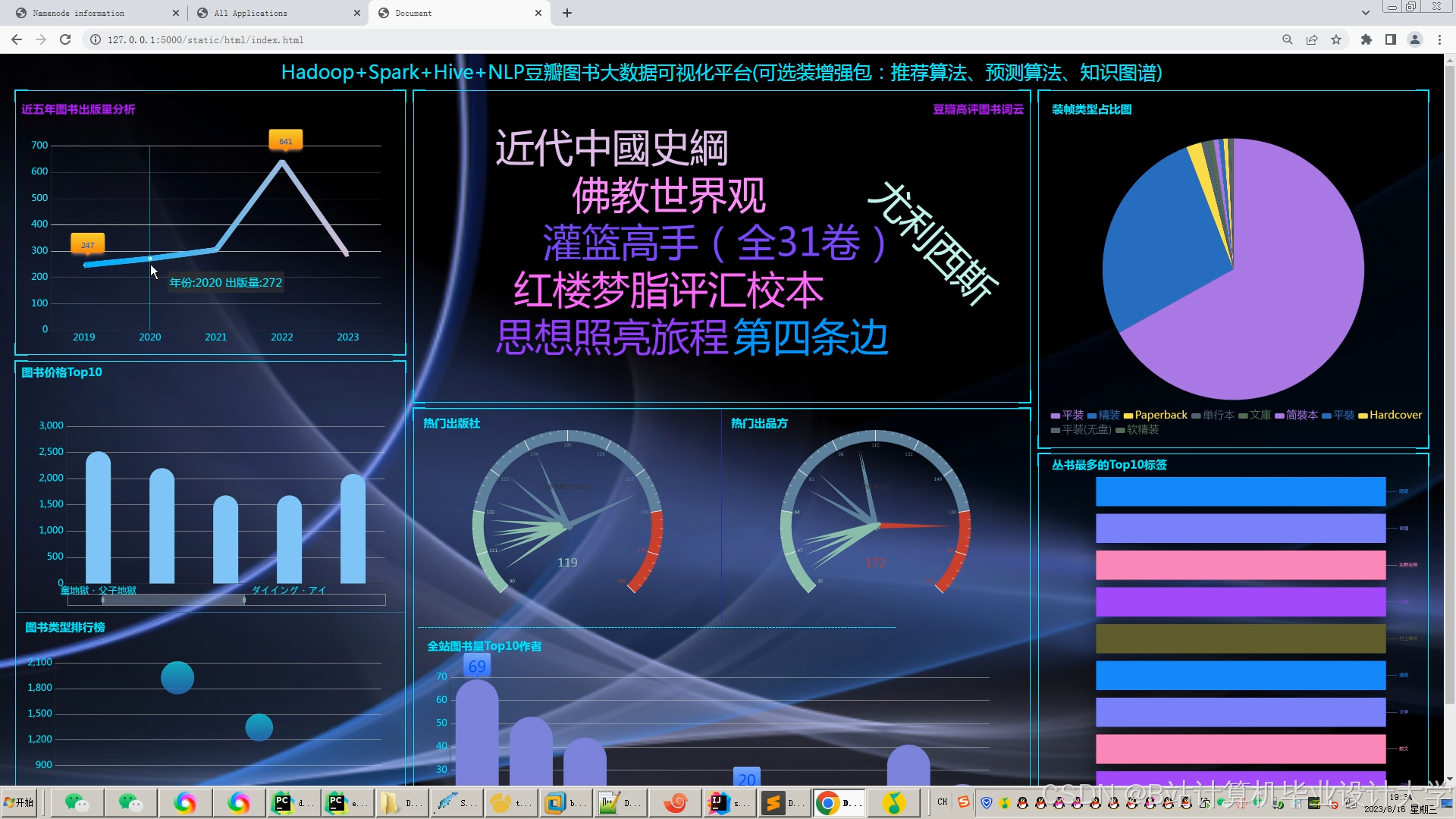
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











