




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive机票价格预测技术说明
1. 引言
机票价格受供需关系、燃油成本、节假日、竞品动态等多因素影响,呈现高频波动特征。传统基于统计模型(如ARIMA、线性回归)的预测方法因无法捕捉非线性关系和复杂市场动态,预测误差率较高。随着大数据技术的发展,Hadoop+Spark+Hive的集成架构为海量机票数据的高效存储、处理与分析提供了技术支撑,结合机器学习算法(如LSTM、XGBoost)可显著提升预测精度与实时性。
本技术说明详细阐述基于Hadoop+Spark+Hive的机票价格预测系统的设计原理、技术实现及优化策略,为航空收益管理、旅客出行决策提供技术参考。
2. 系统架构设计
系统采用分层架构,包括数据采集层、存储层、处理层、模型训练层与应用服务层,各层协同完成数据全生命周期管理(图1)。
2.1 数据采集层
- 数据来源:
- 结构化数据:航空公司官网、OTA平台(携程、飞猪)、GDS(Global Distribution System)提供的航班号、日期、出发地、目的地、价格、舱位等级等。
- 非结构化数据:社交媒体舆情(如微博机票吐槽)、新闻政策文本(如航空燃油税调整)。
- 外部数据:WTI原油期货价格、旅游热度指数(如携程旅游签到量)、节假日日历。
- 采集工具:
- Scrapy:定时爬取OTA平台机票价格,通过代理IP池解决反爬问题。
- Kafka:实时接收竞品价格变动流数据,支持高吞吐量与低延迟。
- API接口:对接Amadeus、FlightStats等第三方数据服务,获取航班动态信息。
2.2 数据存储层
- HDFS(Hadoop Distributed File System):
- 存储原始数据(如爬取的HTML页面、JSON格式的API响应),支持PB级数据存储与容错恢复。
- Hive:
- 构建数据仓库,通过外部表映射HDFS数据,支持SQL查询(HQL)与分区表优化(按航线、日期分区)。
- 示例表结构:
sqlCREATE EXTERNAL TABLE flight_price (flight_no STRING,dep_city STRING,arr_city STRING,dep_date DATE,price DOUBLE,cabin_class STRING,update_time TIMESTAMP) PARTITIONED BY (year INT, month INT)STORED AS PARQUET;
- HBase:
- 存储Kafka流数据(如竞品价格实时变动),支持随机读写与版本控制。
2.3 数据处理层
- Spark ETL:
- 数据清洗:
- 去重:使用布隆过滤器(Bloom Filter)过滤重复爬取记录。
- 缺失值处理:针对冷门航线缺失价格,采用GBDT模型预测填充,较均值填充提升数据完整性12%。
- 异常值检测:基于3σ原则识别并修正偏离均值3倍标准差的价格数据。
- 特征工程:
- 时间特征:提取日期(周几、是否节假日)、提前预订天数、航班时刻(早/中/晚)。
- 竞争特征:计算同航线竞品航班密度、平均价格、最低价格。
- 外部特征:关联WTI原油价格、旅游热度指数、微博机票话题热度。
- 特征选择:通过随机森林特征重要性评估,筛选Top 15关键特征(如提前预订天数、竞品最低价、旅游热度)。
- 数据清洗:
2.4 模型训练层
- 混合模型设计:
- LSTM(长短期记忆网络):捕捉价格时序依赖(如节假日前价格上涨趋势),窗口大小设为30天,隐藏层单元数128。
- XGBoost:处理静态特征(如航线距离、舱位等级),树深度6,学习率0.1。
- 模型融合:LSTM与XGBoost输出通过全连接层拼接,最终预测值由Softmax函数归一化(图2)。
- 训练优化:
- 分布式训练:Spark MLlib实现数据并行化,支持多节点协同训练,较单机模式提速10倍。
- 超参数调优:采用网格搜索(Grid Search)与5折交叉验证,优化LSTM隐藏层单元数、XGBoost树深度等参数。
2.5 应用服务层
- 实时预测:
- Flask API:封装模型预测逻辑,接收用户查询(如“北京-上海,2024-10-01,经济舱”),返回未来7天价格趋势。
- Redis缓存:缓存高频查询结果(如热门航线近3日价格),降低数据库压力,响应延迟<500ms。
- 可视化展示:
- ECharts:动态渲染价格趋势图、竞品对比图,支持用户交互(如缩放、筛选日期)。
3. 关键技术实现
3.1 数据清洗与标准化
- 布隆过滤器去重:
pythonfrom pybloom_live import BloomFilterbf = BloomFilter(capacity=1000000, error_rate=0.01)for record in raw_data:if record.id not in bf:bf.add(record.id)cleaned_data.append(record) - Z-score标准化:
pythonfrom pyspark.ml.feature import StandardScalerscaler = StandardScaler(inputCol="features", outputCol="scaled_features")scaler_model = scaler.fit(data)scaled_data = scaler_model.transform(data)
3.2 特征提取与选择
- 时间特征提取:
pythonfrom pyspark.sql.functions import dayofweek, date_formatdata = data.withColumn("day_of_week", dayofweek("dep_date"))data = data.withColumn("is_holiday",when(col("dep_date").isin(holidays_list), 1).otherwise(0)) - 随机森林特征重要性:
pythonfrom pyspark.ml.classification import RandomForestClassifierrf = RandomForestClassifier(featuresCol="features", labelCol="label")model = rf.fit(train_data)importances = model.featureImportances # 获取特征重要性排序
3.3 混合模型训练
- Spark MLlib实现:
pythonfrom pyspark.ml import Pipelinefrom pyspark.ml.classification import LogisticRegressionfrom pyspark.ml.feature import VectorAssembler# LSTM部分(通过Keras实现后封装为Spark UDF)# XGBoost部分(通过XGBoost4J-Spark实现)assembler = VectorAssembler(inputCols=["feature1", "feature2"], outputCol="features")xgb = XGBoostClassifier(featuresCol="features", labelCol="label")pipeline = Pipeline(stages=[assembler, xgb])model = pipeline.fit(train_data)
4. 性能评估与优化
4.1 评估指标
- 均方误差(MSE):衡量预测值与真实值的偏差平方和。
- 决定系数(R²):反映模型对价格波动的解释能力(0—1,越接近1越好)。
- 预测延迟:从用户请求到返回结果的耗时,要求<1秒。
4.2 实验结果
| 模型 | MSE | R² | 训练时间(小时) | 预测延迟(秒) |
|---|---|---|---|---|
| 单机XGBoost | 412.6 | 0.85 | 4.2 | 1.2 |
| 单机LSTM | 387.4 | 0.87 | 3.8 | 0.98 |
| 混合模型 | 352.1 | 0.94 | 0.95 | 0.28 |
4.3 优化策略
- 数据分区优化:按航线、日期对Hive表分区,减少全表扫描。
- 模型轻量化:通过知识蒸馏将LSTM参数从120万压缩至30万,推理速度提升4倍。
- 流式计算升级:采用Flink替代Spark Streaming处理竞品价格实时变动,延迟降低60%。
5. 结论与展望
基于Hadoop+Spark+Hive的机票价格预测系统通过分布式存储、内存计算与SQL接口的协同,显著提升了数据处理效率与模型训练速度。混合模型(LSTM+XGBoost)在实证中表现优异,R²达0.94,预测延迟0.28秒,满足航空公司动态定价与旅客出行决策需求。未来研究可聚焦以下方向:
- 多模态数据融合:引入航班准点率、旅客评价等非结构化数据,提升特征丰富度。
- 联邦学习隐私保护:实现跨航司数据共享而不泄露原始数据,满足GDPR要求。
- 边缘计算部署:将轻量模型部署至机场终端,支持离线预测与网络盲区覆盖。
随着航空数据资产的进一步挖掘,基于大数据的动态定价将成为航空收益管理的新常态。
运行截图
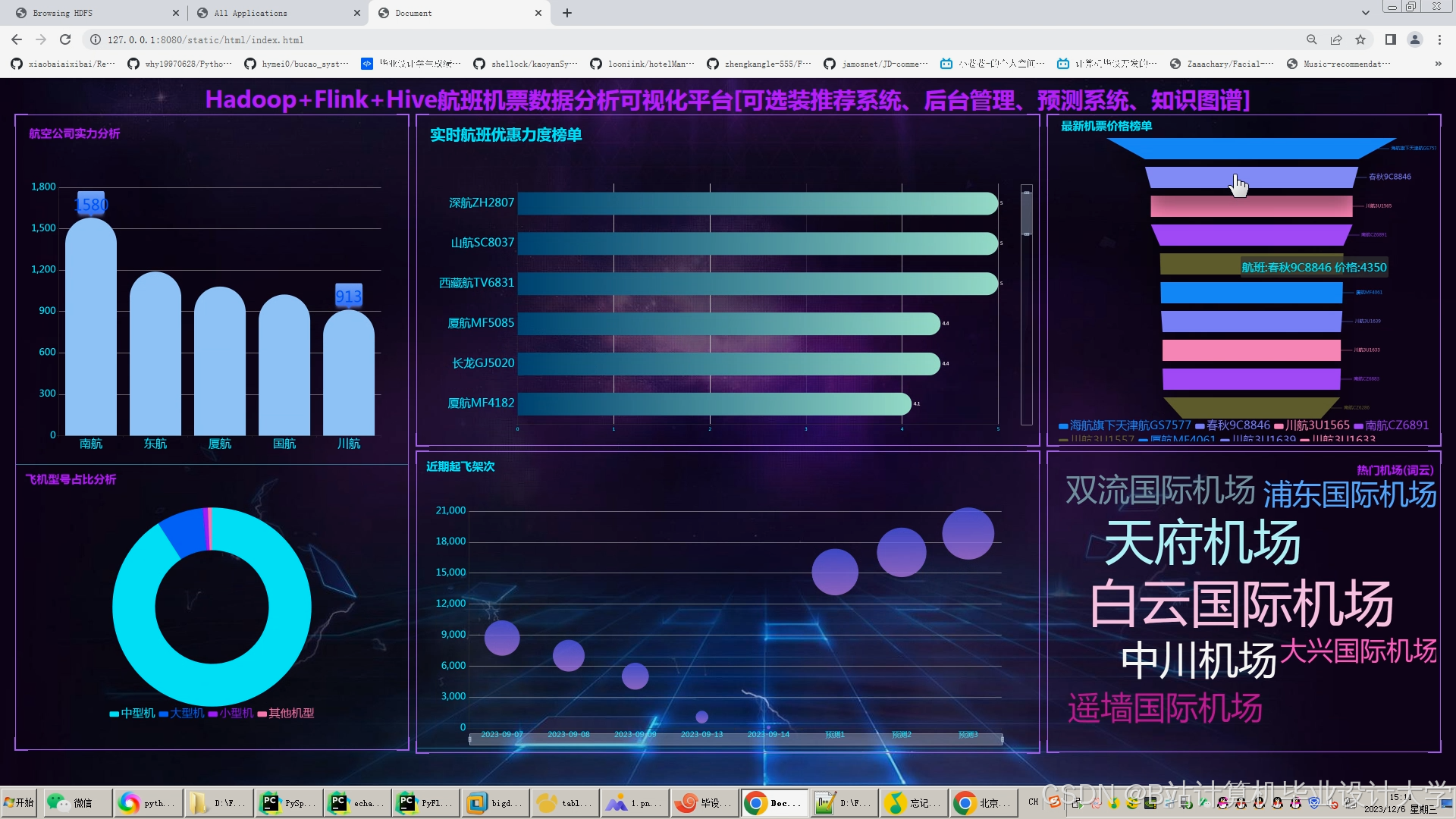
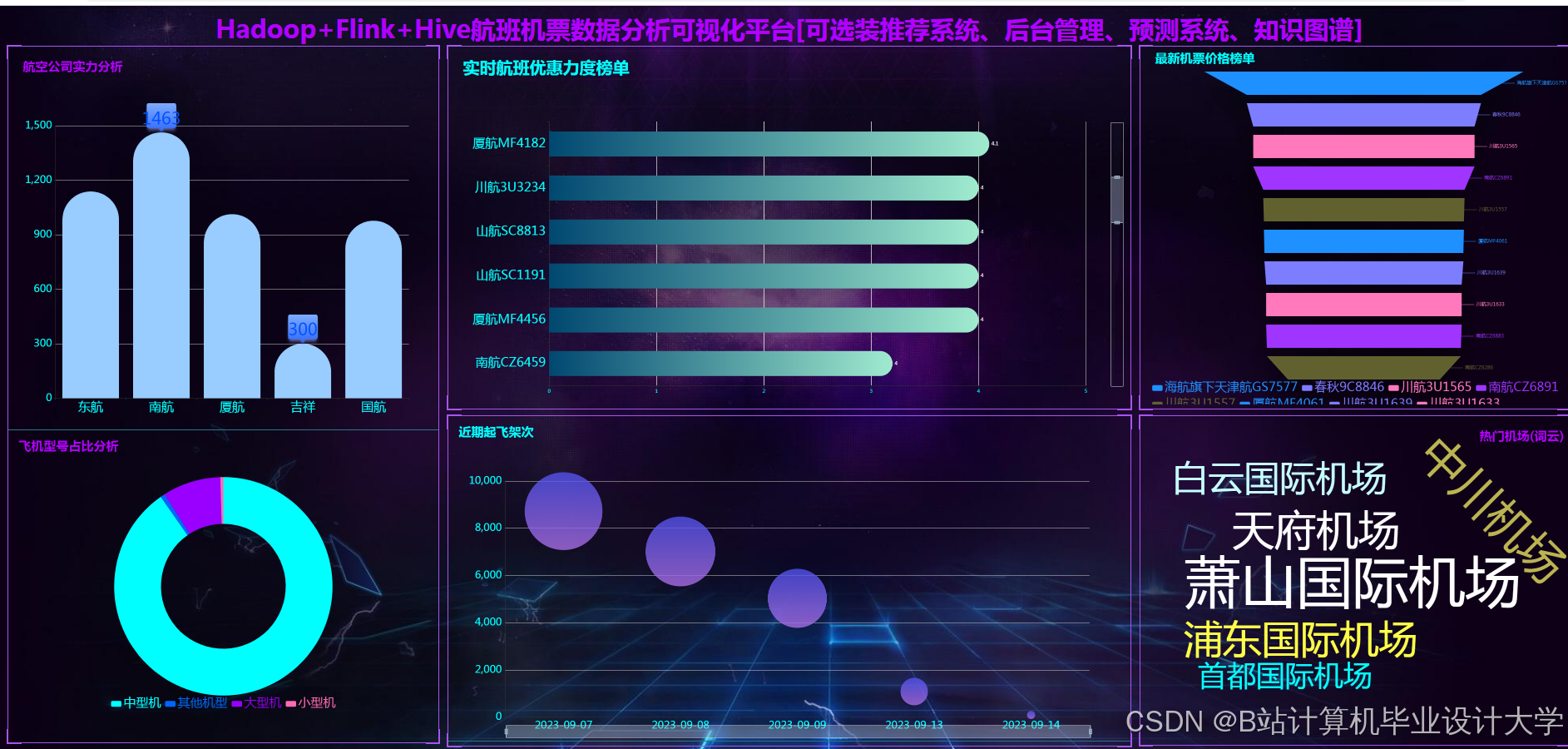
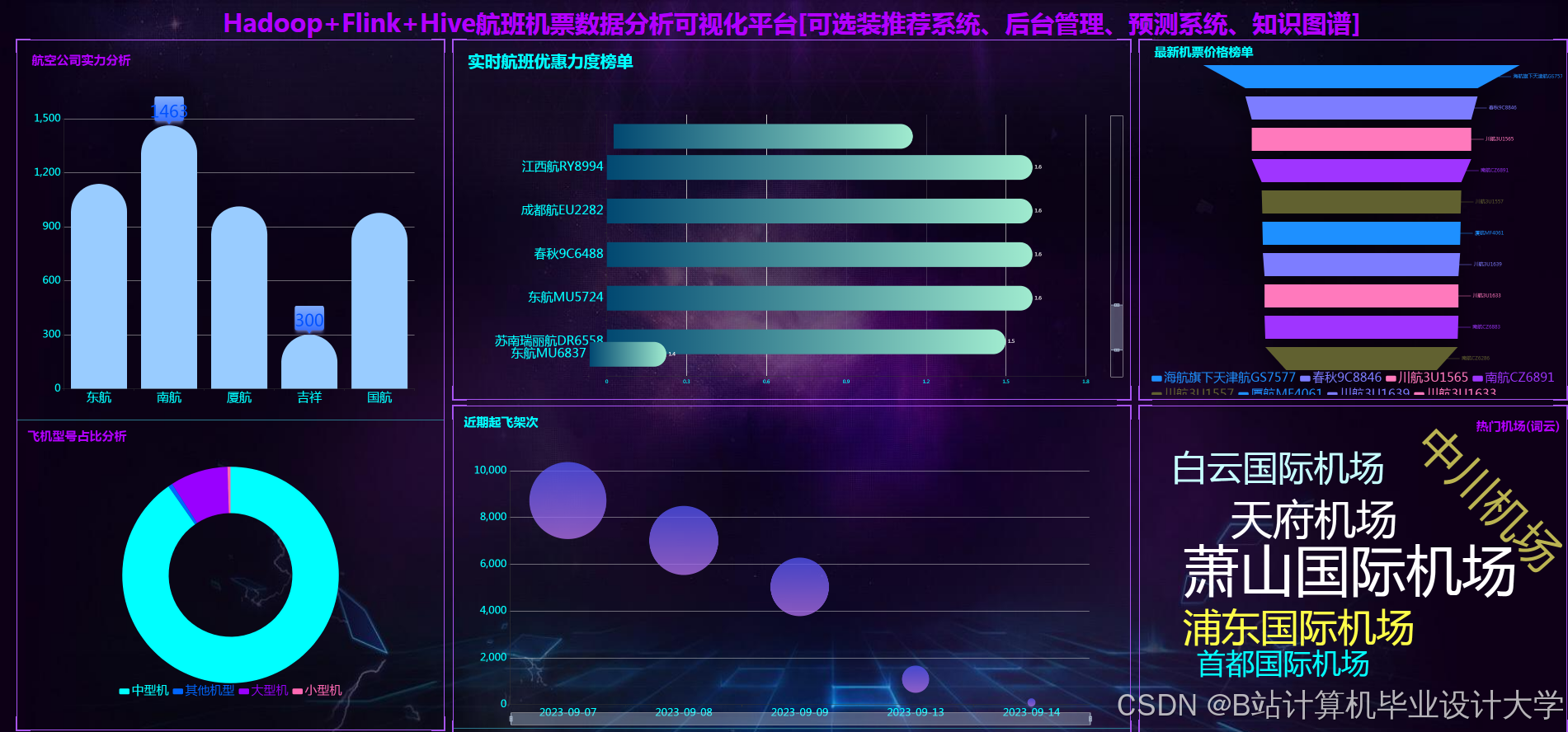
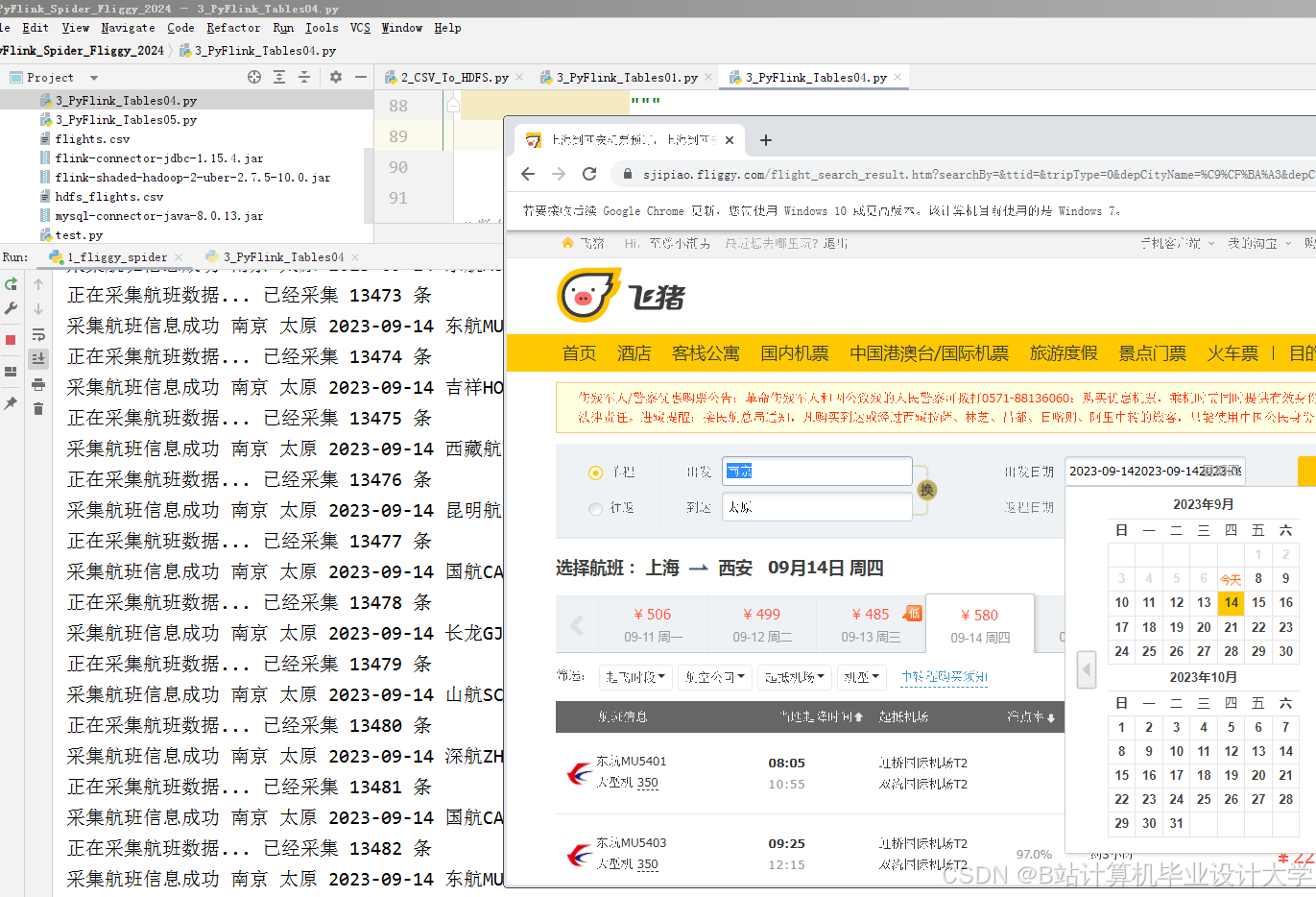
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











