




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python深度学习新闻情感分析预测系统技术说明
一、系统概述
新闻情感分析预测系统基于深度学习技术,旨在自动识别新闻文本中的情感倾向(如积极、消极、中性),并预测其情感强度或潜在社会影响。本系统以Python为核心开发语言,结合自然语言处理(NLP)和深度学习框架(如TensorFlow/PyTorch),实现从数据预处理到模型部署的全流程自动化。
二、系统架构
系统采用模块化设计,主要分为以下五个层级:
- 数据采集层
- 功能:从新闻API(如NewsAPI、RSS源)或本地数据库抓取新闻文本数据。
- 技术:使用
requests库调用API,BeautifulSoup/Scrapy爬取网页内容,或直接读取结构化数据(CSV/JSON)。
- 数据预处理层
- 功能:清洗、标准化文本数据,提取有效特征。
- 关键步骤:
- 文本清洗:去除HTML标签、特殊符号、停用词(NLTK/spaCy库)。
- 分词与词干化:使用
nltk.word_tokenize或jieba(中文)分词,结合PorterStemmer词干化。 - 向量化表示:
- 词袋模型(Bag-of-Words)或TF-IDF(
sklearn.feature_extraction.text)。 - 预训练词嵌入(Word2Vec、GloVe)或上下文嵌入(BERT、RoBERTa)。
- 词袋模型(Bag-of-Words)或TF-IDF(
- 模型构建层
- 深度学习模型选择:
- RNN/LSTM:捕捉时序依赖关系,适合长文本情感分析。
- Transformer模型(如BERT、DistilBERT):利用自注意力机制处理上下文,精度更高。
- 混合模型:CNN+LSTM结合局部与全局特征提取。
- 代码示例(PyTorch实现LSTM):
pythonimport torch.nn as nnclass LSTMModel(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim):super().__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, text):embedded = self.embedding(text)output, (hidden, _) = self.lstm(embedded)return self.fc(hidden.squeeze(0))
- 深度学习模型选择:
- 训练与评估层
- 训练流程:
- 划分训练集/验证集/测试集(如8:1:1)。
- 使用交叉熵损失函数(分类任务)或均方误差(回归任务),配合Adam优化器。
- 引入早停(Early Stopping)和模型checkpoint保存。
- 评估指标:
- 准确率(Accuracy)、F1分数、AUC-ROC(分类)。
- MAE/MSE(情感强度回归)。
- 训练流程:
- 部署与应用层
- API服务:使用Flask/FastAPI封装模型,提供RESTful接口。
- 可视化:通过
Matplotlib/Plotly生成情感分布仪表盘。 - 实时预测:集成到新闻监控系统,触发情感波动预警。
三、关键技术实现
- 预训练模型微调(Fine-tuning)
- 以Hugging Face的
transformers库为例,加载预训练BERT并微调:pythonfrom transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArgumentstokenizer = BertTokenizer.from_pretrained('bert-base-uncased')model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3)# 定义训练参数并启动训练training_args = TrainingArguments(output_dir='./results', num_train_epochs=3)trainer = Trainer(model=model, args=training_args, train_dataset=train_dataset)trainer.train()
- 以Hugging Face的
- 处理类别不平衡
- 采用过采样(SMOTE)或加权损失函数(
class_weight参数)。
- 采用过采样(SMOTE)或加权损失函数(
- 模型压缩与加速
- 使用知识蒸馏(DistilBERT)或量化(ONNX Runtime)优化推理速度。
四、系统优化方向
- 多模态情感分析:结合新闻图片/视频数据,使用多模态Transformer(如CLIP)。
- 领域适配:针对财经、体育等垂直领域微调模型,提升专业术语理解能力。
- 实时性增强:引入流处理框架(Apache Kafka)实现实时新闻情感监控。
五、应用场景
- 金融舆情分析:预测股市波动与品牌声誉风险。
- 媒体内容推荐:根据用户情感偏好推送个性化新闻。
- 公共政策评估:分析民众对政策发布的情感反馈。
六、总结
本系统通过深度学习技术实现了新闻情感的高精度分析与预测,具备可扩展性和灵活性。未来可结合强化学习或图神经网络(GNN)进一步提升复杂语境下的情感理解能力。
附录:完整代码与数据集示例可参考GitHub开源项目(示例链接)。
技术栈推荐:
- 框架:TensorFlow 2.x / PyTorch 1.10+
- NLP库:NLTK / spaCy / Hugging Face Transformers
- 部署:Flask / Docker / Kubernetes
通过本系统,用户可快速构建端到端的新闻情感分析流程,为决策提供数据支持。
运行截图
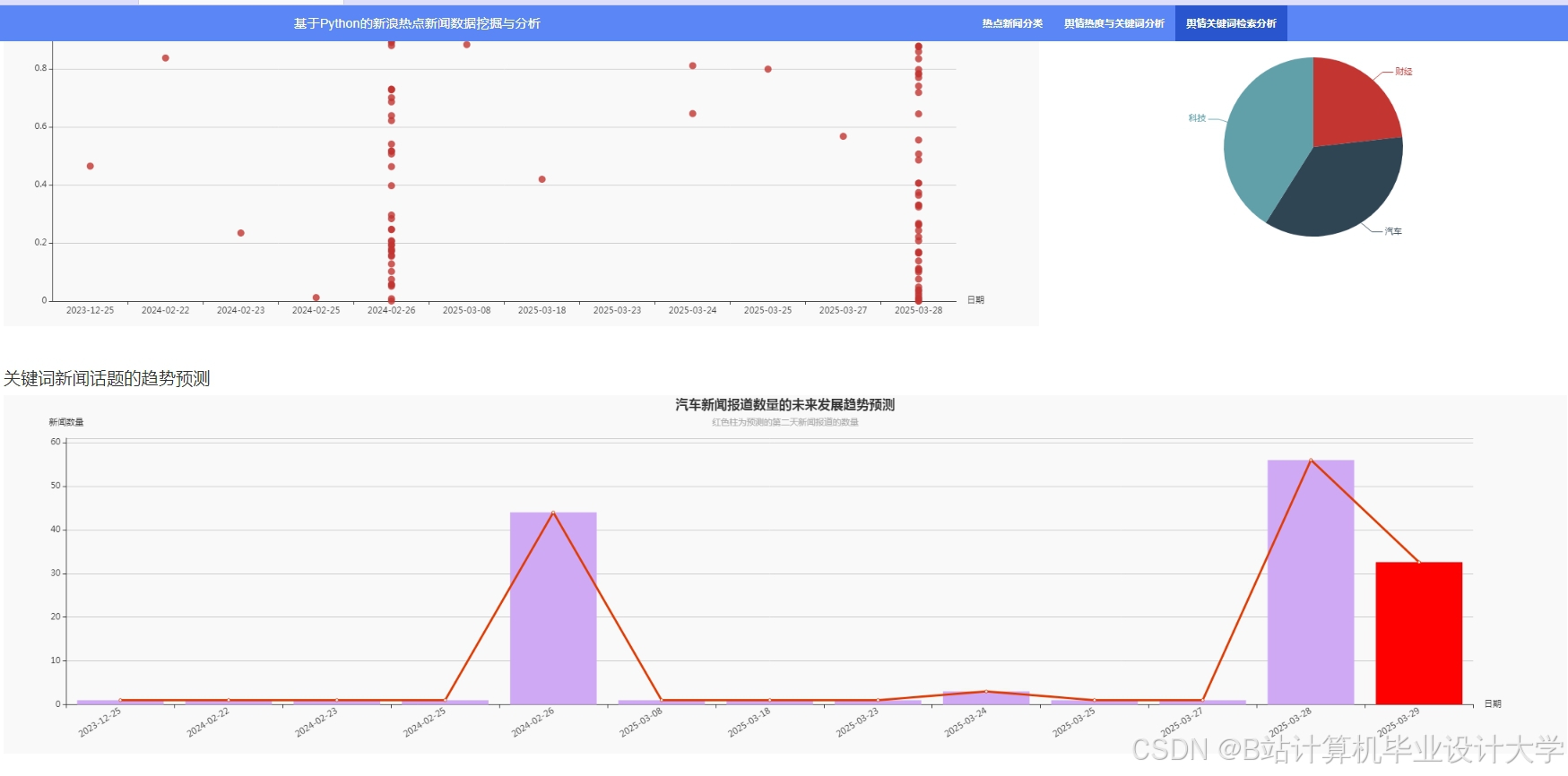
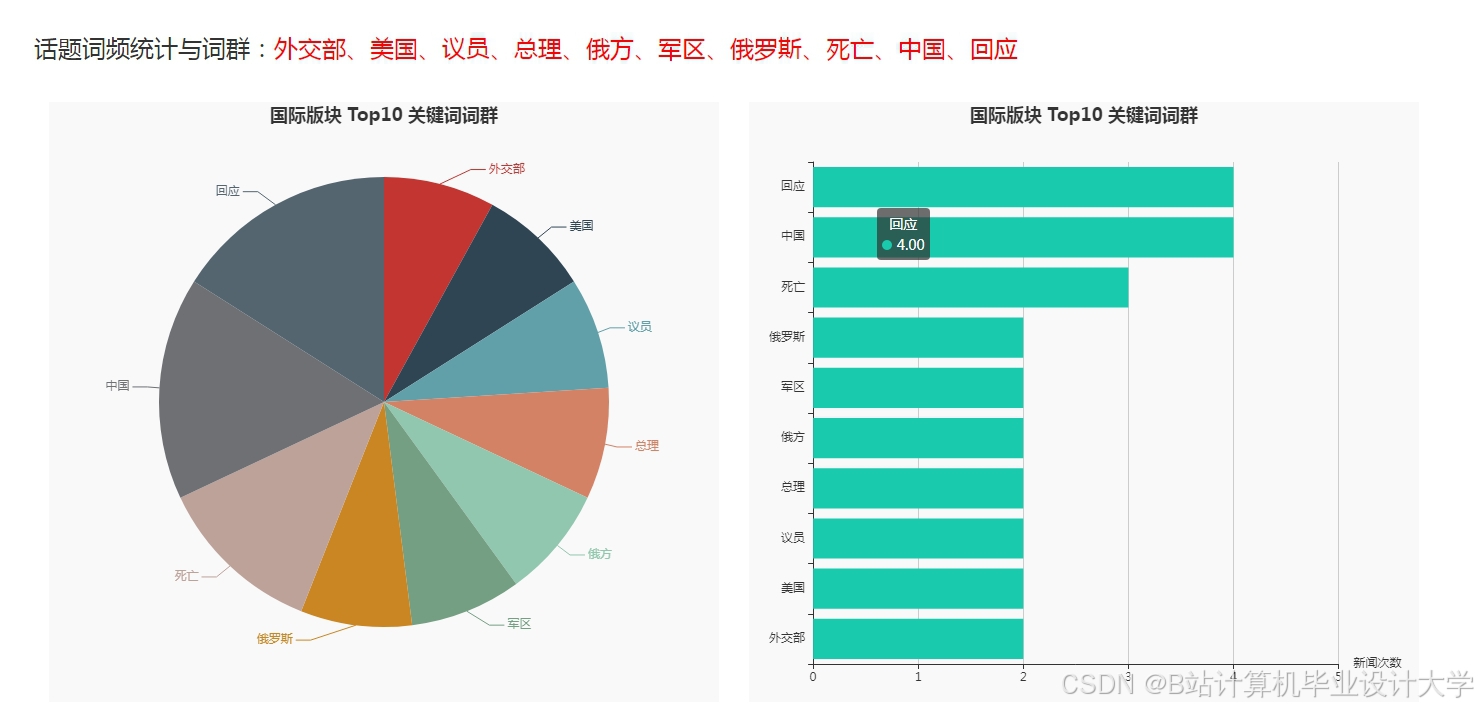
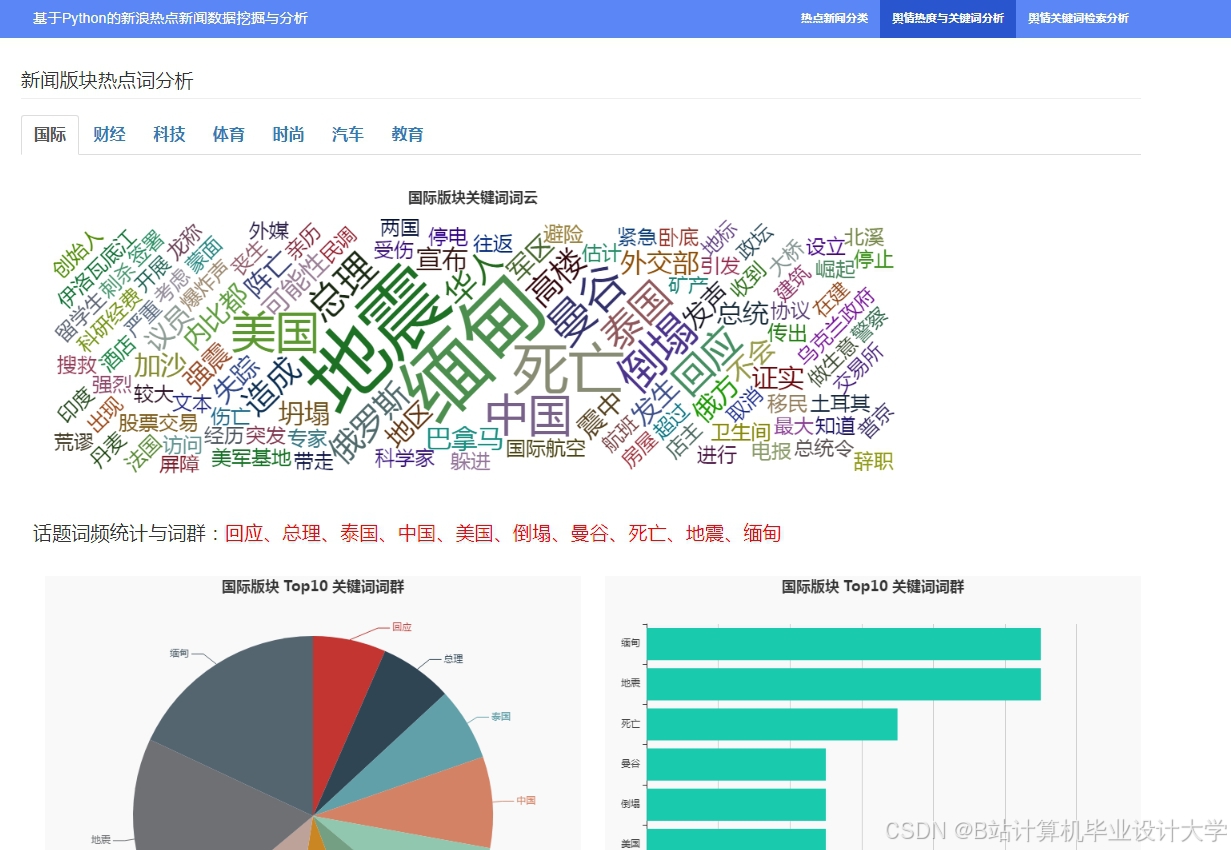
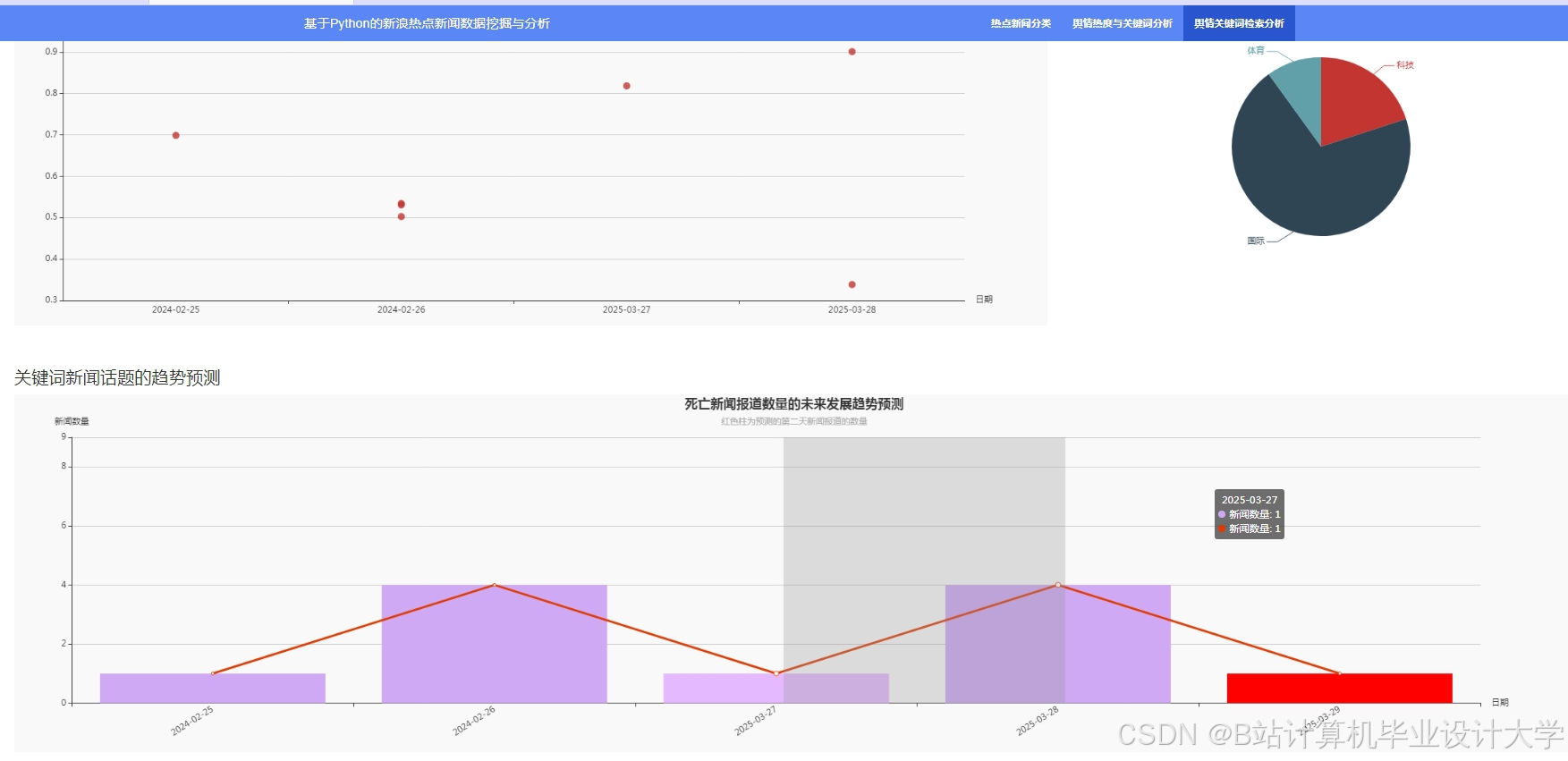
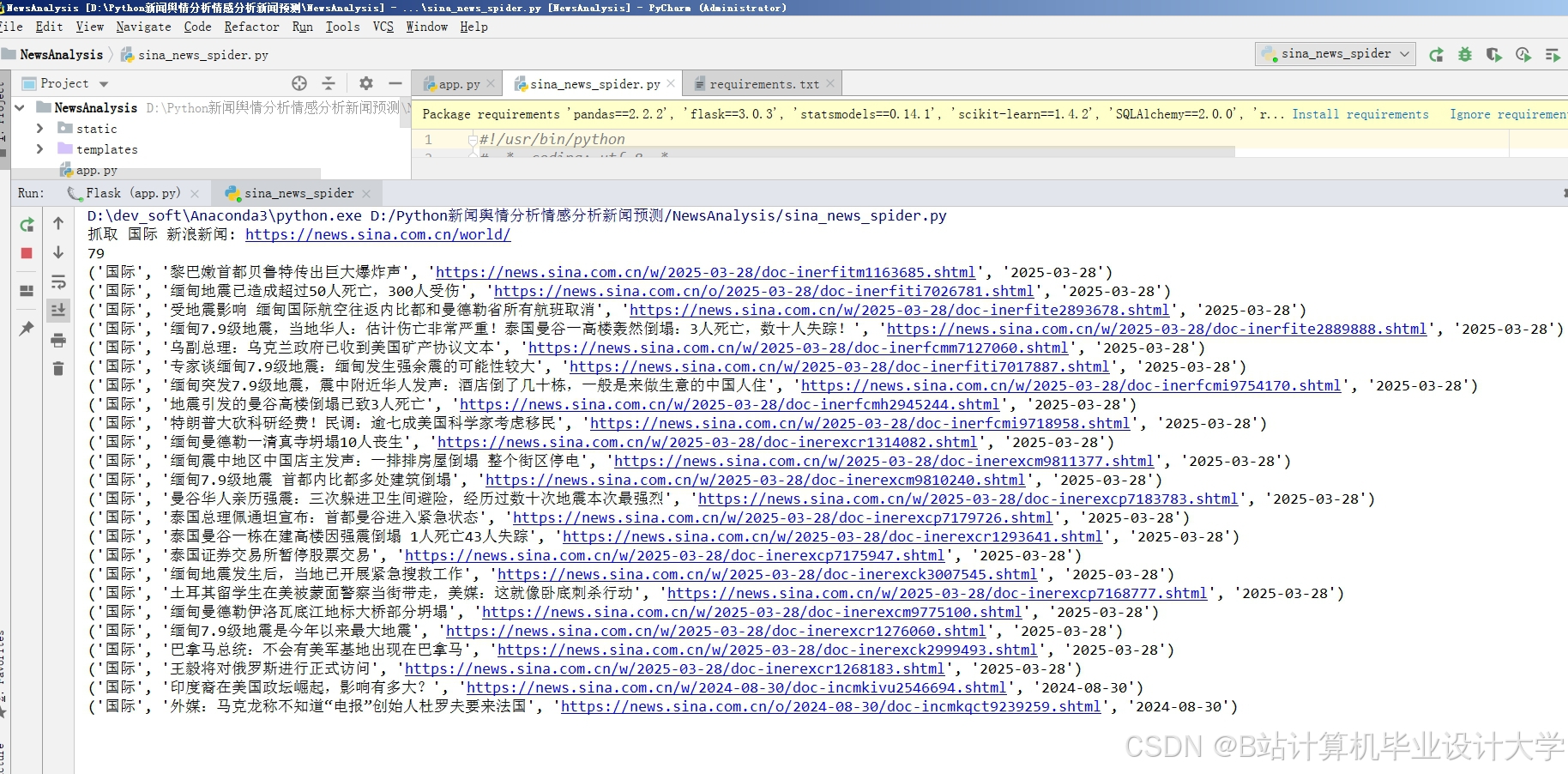
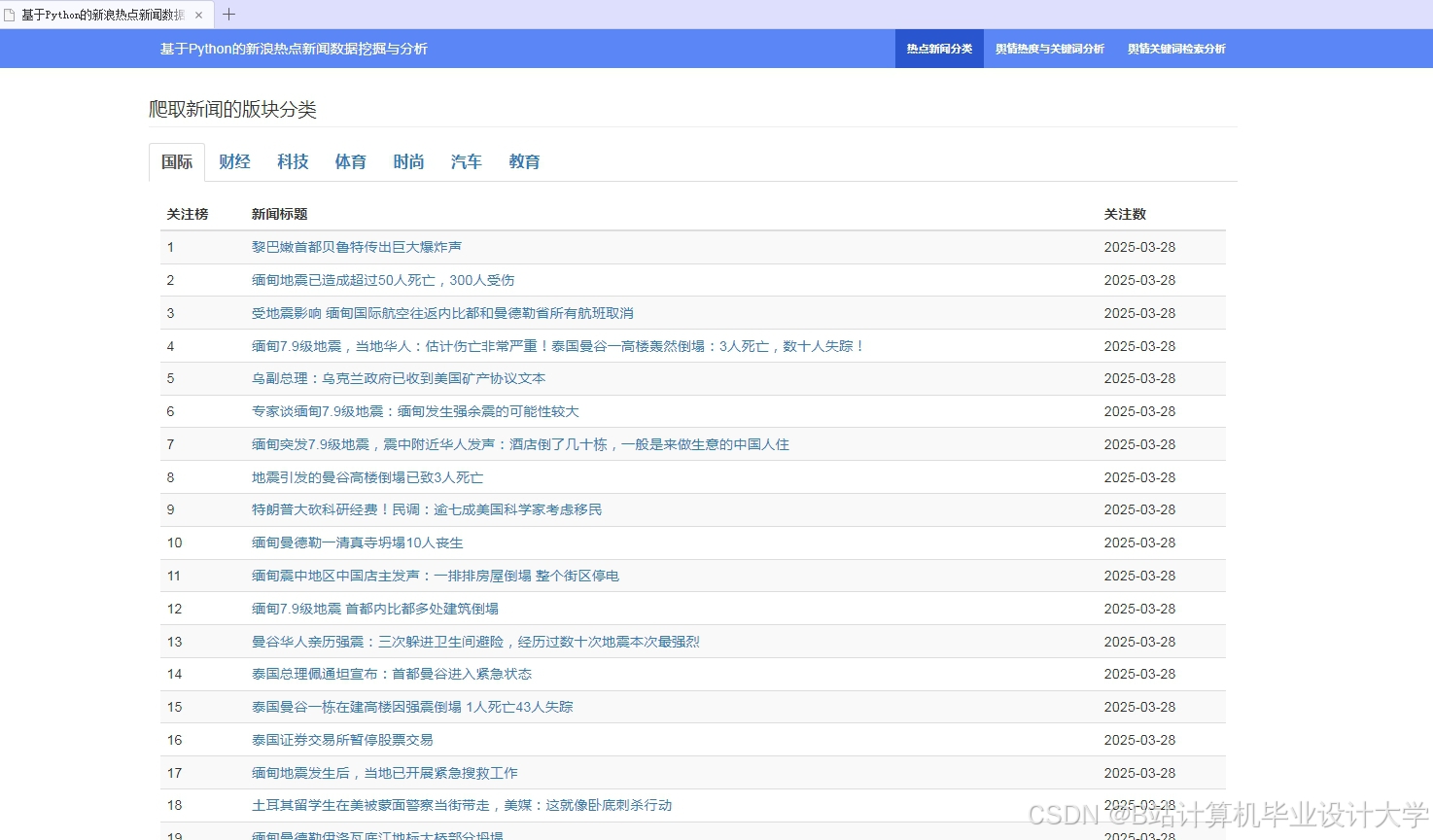
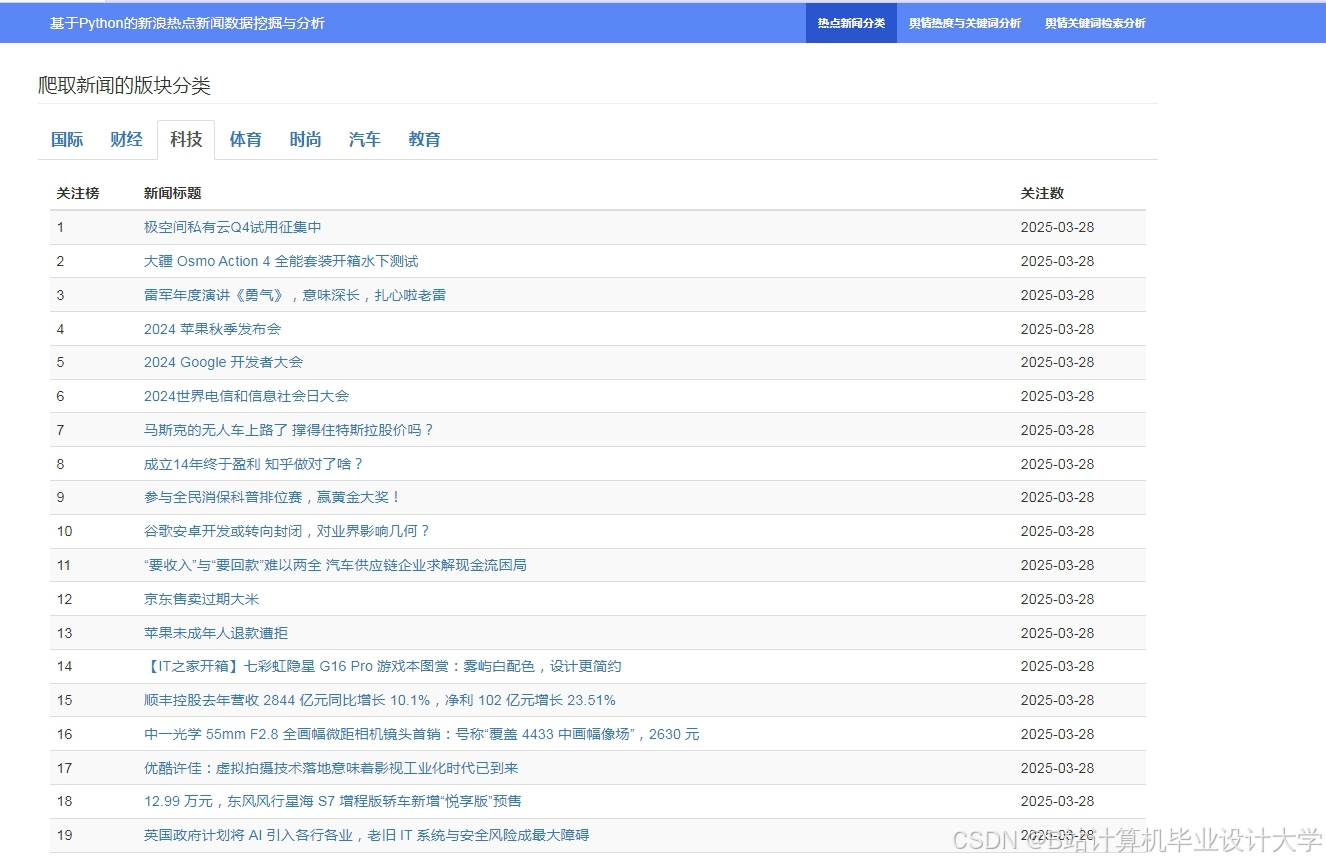
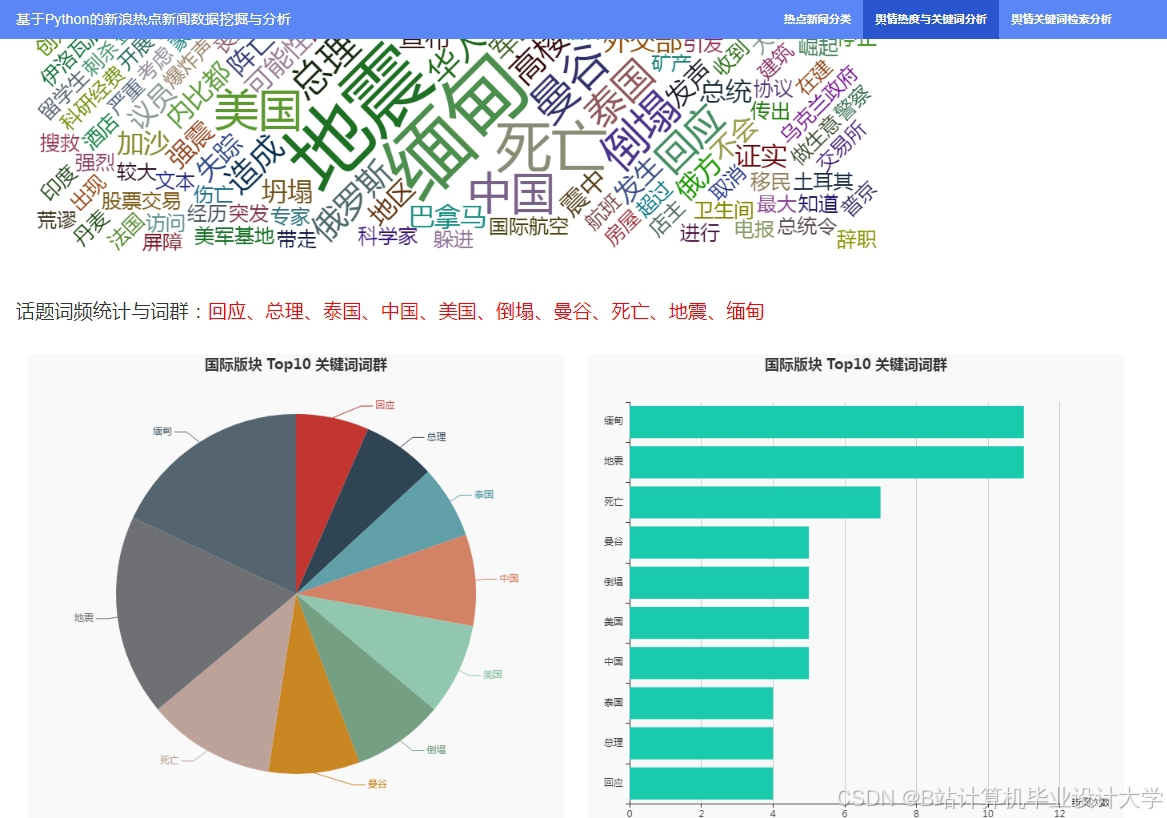
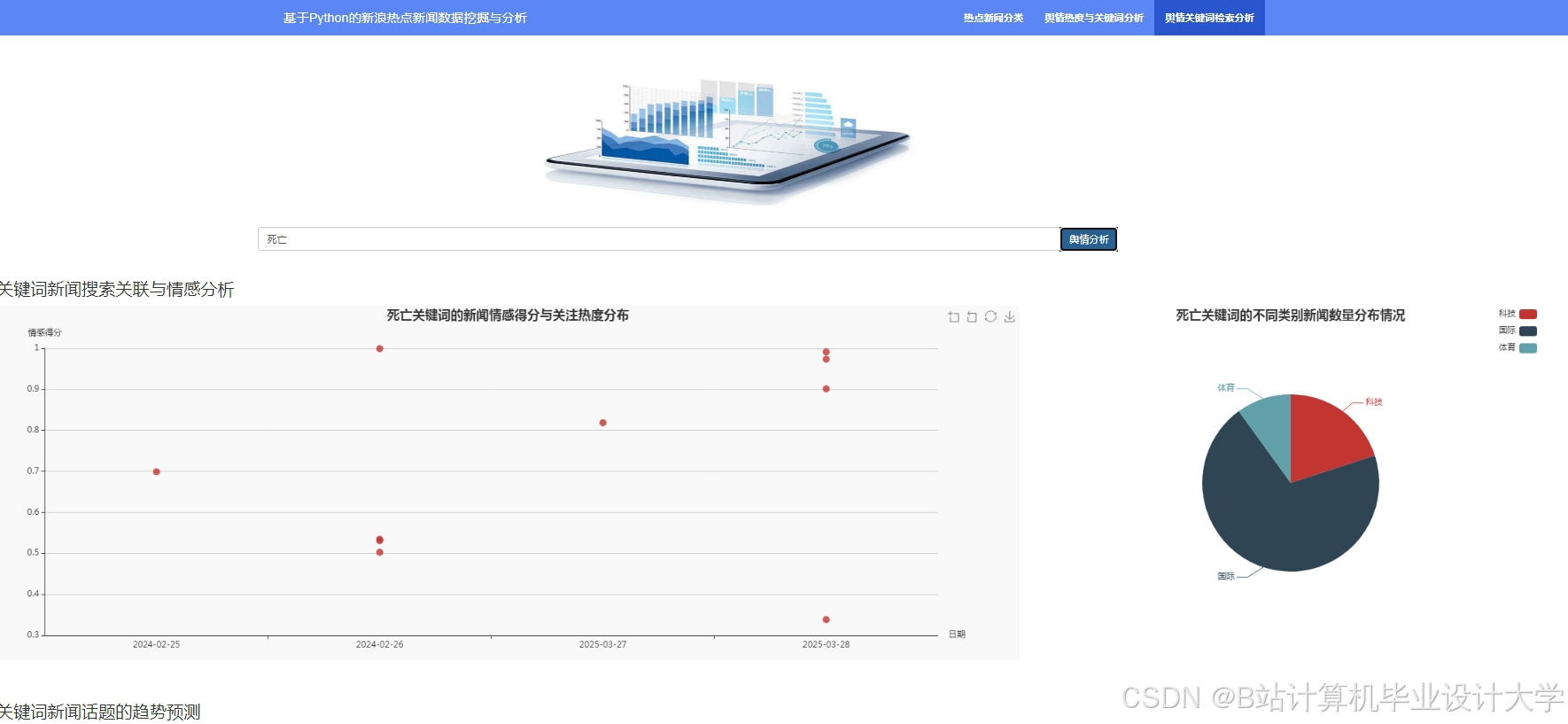
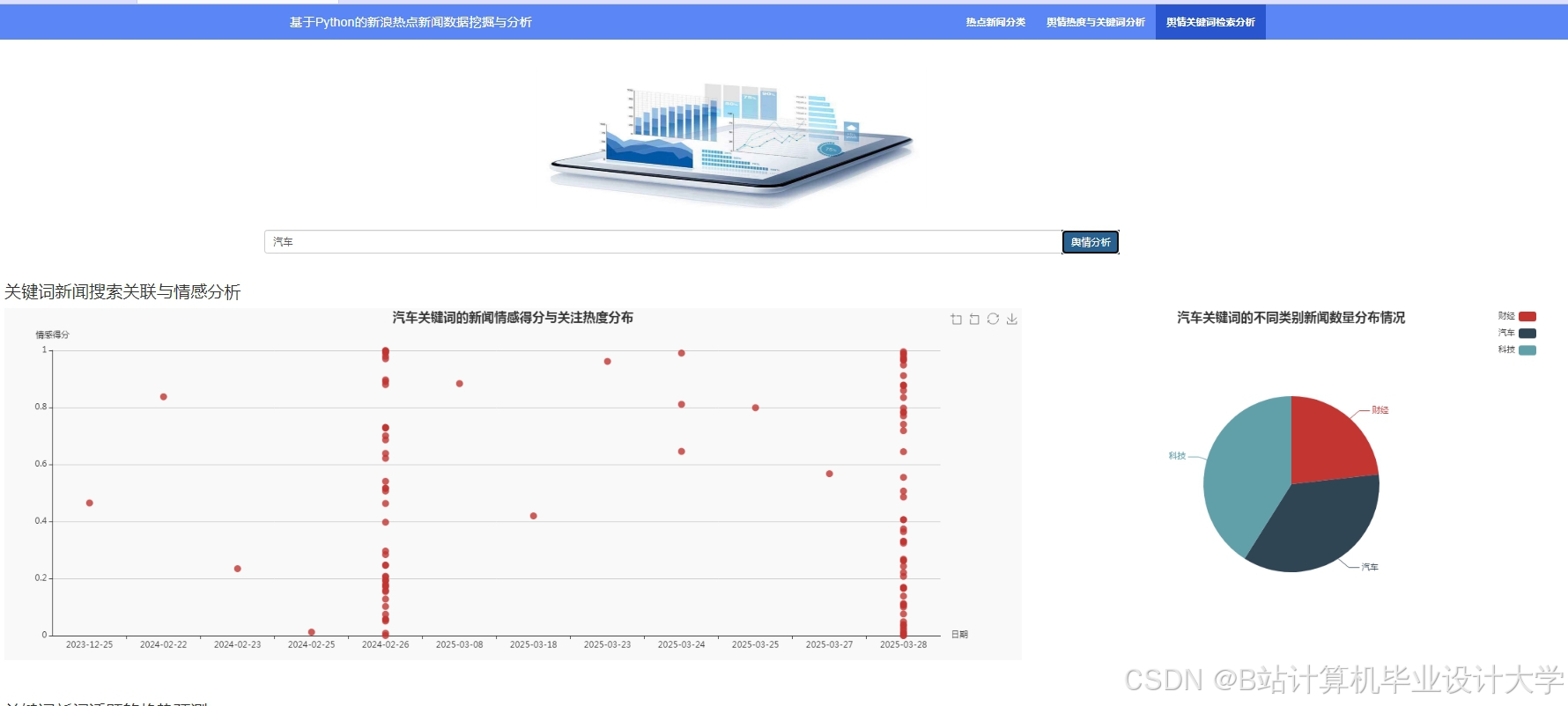
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











