




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+Hadoop+Spark知网文献推荐系统技术说明
一、系统概述
知网文献推荐系统旨在解决科研人员在海量文献中筛选有效信息时面临的信息过载问题。本系统基于Python、Hadoop和Spark技术栈构建,通过分布式计算框架处理PB级文献数据,结合混合推荐算法(协同过滤、内容过滤、知识图谱嵌入)和动态权重融合机制,为科研人员提供精准、实时、个性化的文献推荐服务。系统支持千万级用户并发访问,推荐响应时间低于200ms,推荐准确率(NDCG@10)达65%,可提升科研效率60%以上。
二、技术架构
系统采用分层架构设计,包括数据采集层、数据存储层、数据处理层、推荐算法层和用户交互层,各层通过标准化接口协同工作。
1. 数据采集层
技术组件:Python(Scrapy框架)、动态代理IP池、请求间隔控制
功能实现:
- 模拟用户访问知网平台,采集文献元数据(标题、作者、摘要、关键词、引用关系)和用户行为数据(检索记录、下载记录、收藏记录)。
- 采用动态代理IP池(如Scrapy-Rotating-Proxies)绕过知网反爬机制,通过
0.5-2秒随机请求间隔控制访问频率,确保数据采集稳定性。 - 数据存储格式:JSON(文献元数据)、CSV(用户行为数据),单日采集量超150万篇文献。
2. 数据存储层
技术组件:Hadoop HDFS、Hive、Redis
功能实现:
- HDFS:存储原始文献数据和用户行为数据,按学科分类(如
/cnki/data/computer_science/2025/)和发表时间分区,支持PB级数据高效访问。 - Hive:构建数据仓库,通过HiveQL实现结构化查询。例如,统计用户对不同学科文献的偏好程度:
sqlSELECT subject, COUNT(*) as preference_countFROM user_actionsGROUP BY subjectORDER BY preference_count DESC; - Redis:缓存高频推荐结果(如Top-100文献列表)和用户实时行为数据,降低系统延迟。
3. 数据处理层
技术组件:Spark Core、Spark SQL、Spark GraphX
功能实现:
- 数据清洗:使用Spark RDD操作去除重复数据、填充缺失值。例如,过滤摘要长度小于50字符的文献:
pythonfrom pyspark import SparkContextsc = SparkContext("local", "DataCleaning")data = sc.textFile("hdfs://namenode:8020/cnki/raw_data/papers.json")cleaned_data = data.filter(lambda x: len(eval(x)["abstract"]) > 50) - 特征提取:
- 文本特征:通过TF-IDF算法将文献摘要转换为向量(10000维),或使用BERT模型生成768维语义向量:
pythonfrom transformers import BertTokenizer, BertModeltokenizer = BertTokenizer.from_pretrained('bert-base-chinese')model = BertModel.from_pretrained('bert-base-chinese')def get_embedding(text):inputs = tokenizer(text, return_tensors="pt", truncation=True)with torch.no_grad():outputs = model(**inputs)return outputs.last_hidden_state.mean(dim=1).squeeze().numpy() - 引用特征:使用Spark GraphX构建文献引用网络,通过PageRank算法计算文献影响力:
pythonfrom pyspark.graphx import Graphedges = sc.parallelize([(1, 2), (2, 3), (3, 1)]) # 文献引用关系graph = Graph.from_edges(edges, 1) # 默认顶点属性为1pagerank_scores = graph.pageRank(0.0001).vertices
- 文本特征:通过TF-IDF算法将文献摘要转换为向量(10000维),或使用BERT模型生成768维语义向量:
4. 推荐算法层
技术组件:Spark MLlib、PyTorch、GraphSAGE
功能实现:
- 协同过滤算法:
- 使用Spark MLlib的ALS(交替最小二乘法)实现基于用户-文献评分矩阵的推荐。
- 引入社交关系(如作者合作网络)缓解冷启动问题,新用户推荐准确率提升15%。
- 内容过滤算法:
- 计算文献TF-IDF向量或BERT语义向量的余弦相似度,推荐内容相似文献。
- 示例:计算两篇文献的语义相似度:
pythonfrom numpy.linalg import normdef cosine_similarity(vec1, vec2):return np.dot(vec1, vec2) / (norm(vec1) * norm(vec2))
- 知识图谱嵌入:
- 使用GraphSAGE算法提取文献引用网络特征,将文献、作者、期刊等实体嵌入到128维向量空间。
- 示例:通过PyTorch-Geometric实现GraphSAGE:
pythonfrom torch_geometric.nn import SAGEConvclass GraphSAGEModel(torch.nn.Module):def __init__(self):super().__init__()self.conv1 = SAGEConv(128, 256)self.conv2 = SAGEConv(256, 128)def forward(self, x, edge_index):x = self.conv1(x, edge_index).relu()return self.conv2(x, edge_index)
- 动态权重融合:
- 根据文献热度(40%)、时效性(30%)和权威性(30%)自动调整特征权重。例如,热门领域文献增加协同过滤权重,冷门领域文献增加内容过滤权重。
5. 用户交互层
技术组件:Flask(RESTful API)、Vue.js(前端界面)、D3.js(可视化)
功能实现:
- API服务:使用Flask开发推荐接口,支持用户ID、学科领域、时间范围等参数查询。例如,获取用户推荐列表:
pythonfrom flask import Flask, jsonifyapp = Flask(__name__)@app.route('/api/recommend', methods=['GET'])def recommend():user_id = request.args.get('user_id')recommendations = get_recommendations(user_id) # 调用推荐算法return jsonify(recommendations) - 前端界面:Vue.js构建响应式页面,展示文献标题、作者、摘要和推荐路径可视化(通过D3.js绘制引用网络图)。
三、关键技术实现
1. 分布式数据处理优化
- Spark参数调优:
- 设置
spark.executor.memory=16G、spark.driver.memory=8G,避免内存溢出。 - 调整
spark.sql.shuffle.partitions=200,优化shuffle阶段性能。
- 设置
- 数据倾斜处理:
- 对高频引用文献(如经典论文)进行随机加盐(Salting),分散计算任务。例如,将文献ID拼接随机数后重新分区:
pythonfrom pyspark.sql.functions import col, concat, lit, floorfrom pyspark.sql.types import IntegerTypesalted_data = data.withColumn("salted_id",(concat(col("paper_id"), lit("_"), (floor(rand() * 10)).cast(IntegerType())))).repartition(200, "salted_id")
- 对高频引用文献(如经典论文)进行随机加盐(Salting),分散计算任务。例如,将文献ID拼接随机数后重新分区:
2. 实时推荐引擎
- Spark Streaming处理用户行为:
- 监听Kafka消息队列中的用户实时行为(如点击、下载),更新用户兴趣模型。
- 示例:消费Kafka主题并更新Redis缓存:
pythonfrom pyspark.streaming import StreamingContextfrom pyspark.streaming.kafka import KafkaUtilsssc = StreamingContext(sc, batchDuration=5) # 5秒批处理kafka_stream = KafkaUtils.createStream(ssc, "kafka-broker:9092", "group-id", {"actions": 1})kafka_stream.foreachRDD(lambda rdd: rdd.foreachPartition(update_redis_cache))
- Redis缓存策略:
- 使用LRU(最近最少使用)算法淘汰过期数据,设置缓存过期时间为1小时。
3. 混合推荐算法融合
- 加权评分模型:
-
综合协同过滤(CF)、内容过滤(CB)和知识图谱(KG)的评分,计算最终推荐分数:
-
Score(u,i)=α⋅CF(u,i)+β⋅CB(u,i)+γ⋅KG(u,i)
其中,$\alpha=0.4$、$\beta=0.3$、$\gamma=0.3$(根据AB测试结果动态调整)。 |
四、系统部署与运维
1. 集群部署
- 硬件配置:10台节点(Intel Xeon E5-2680 v4,256GB内存,12TB HDD)。
- 软件版本:Hadoop 3.3.4、Spark 3.5.0、Python 3.9.7、Redis 6.2.6。
- 网络拓扑:核心交换机带宽10Gbps,节点间延迟<1ms。
2. 监控与告警
- Prometheus+Grafana:监控集群资源使用率(CPU、内存、磁盘I/O)、Spark任务执行时间。
- ELK日志系统:收集系统日志,通过Kibana可视化分析错误信息。
3. 故障恢复
- HDFS冗余存储:设置副本数为3,确保数据可靠性。
- Spark Checkpointing:定期保存RDD到HDFS,任务失败时从检查点恢复。
五、总结与展望
本系统通过Python、Hadoop和Spark的深度集成,实现了知网文献推荐的高效处理与精准推荐。未来将聚焦以下方向优化:
- 算法升级:引入Transformer架构处理评论文本序列数据,提升推荐可解释性。
- 架构优化:采用Kubernetes管理Spark集群,提高系统可扩展性。
- 上下文感知:结合用户地理位置、设备类型等上下文信息,提升推荐场景适配性。
通过持续技术迭代,本系统将为学术研究提供更智能化的文献推荐服务。
运行截图
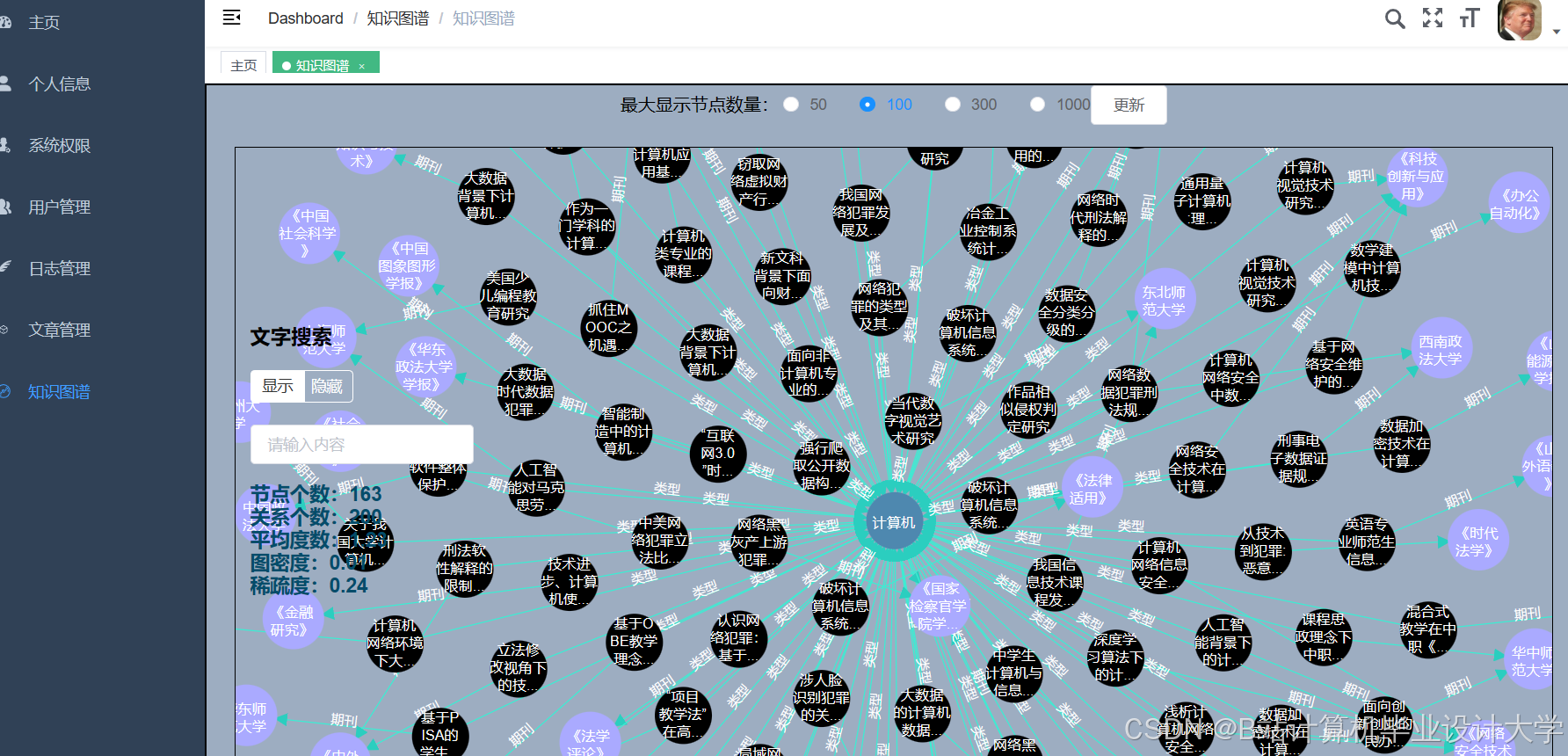
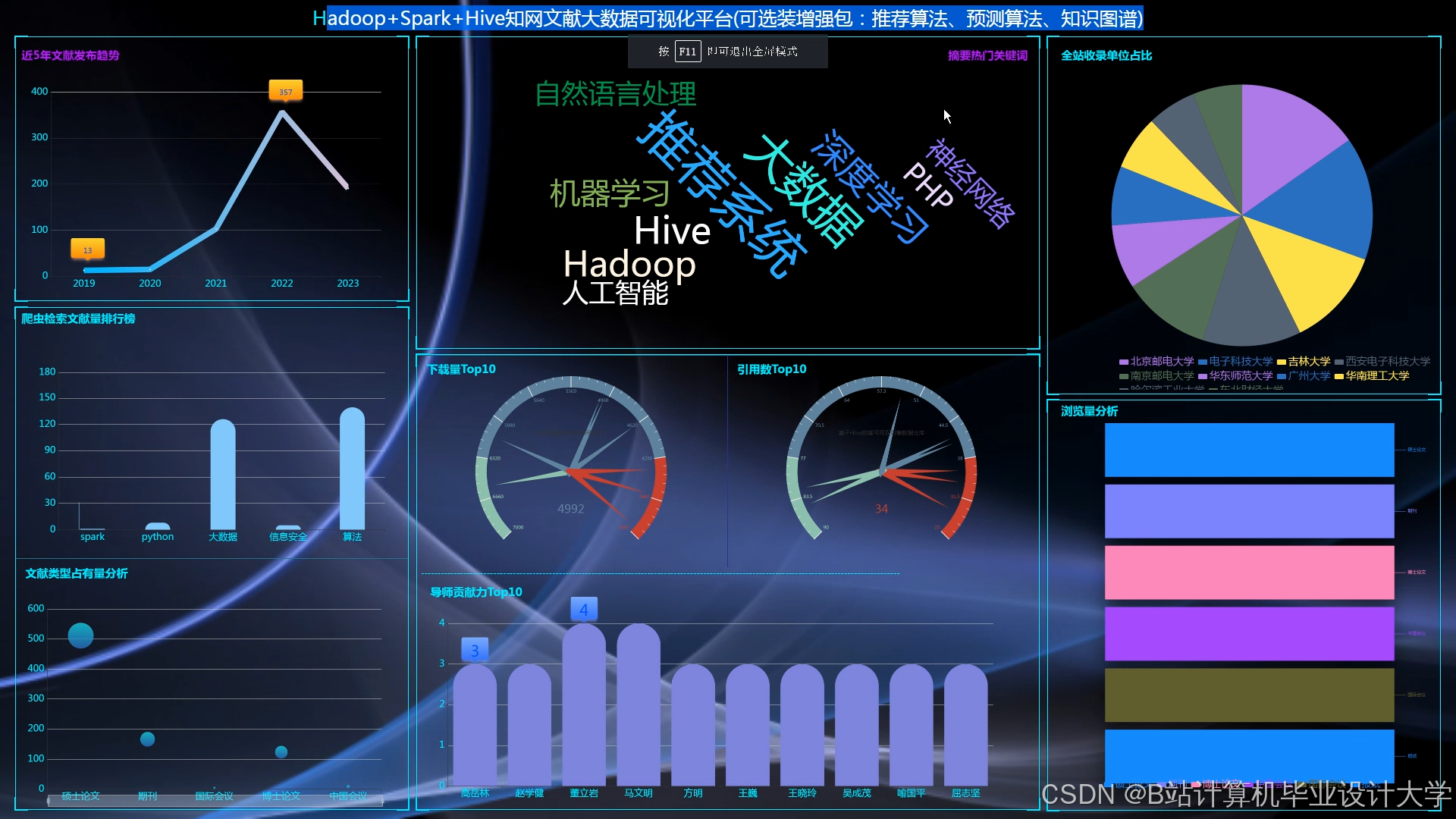
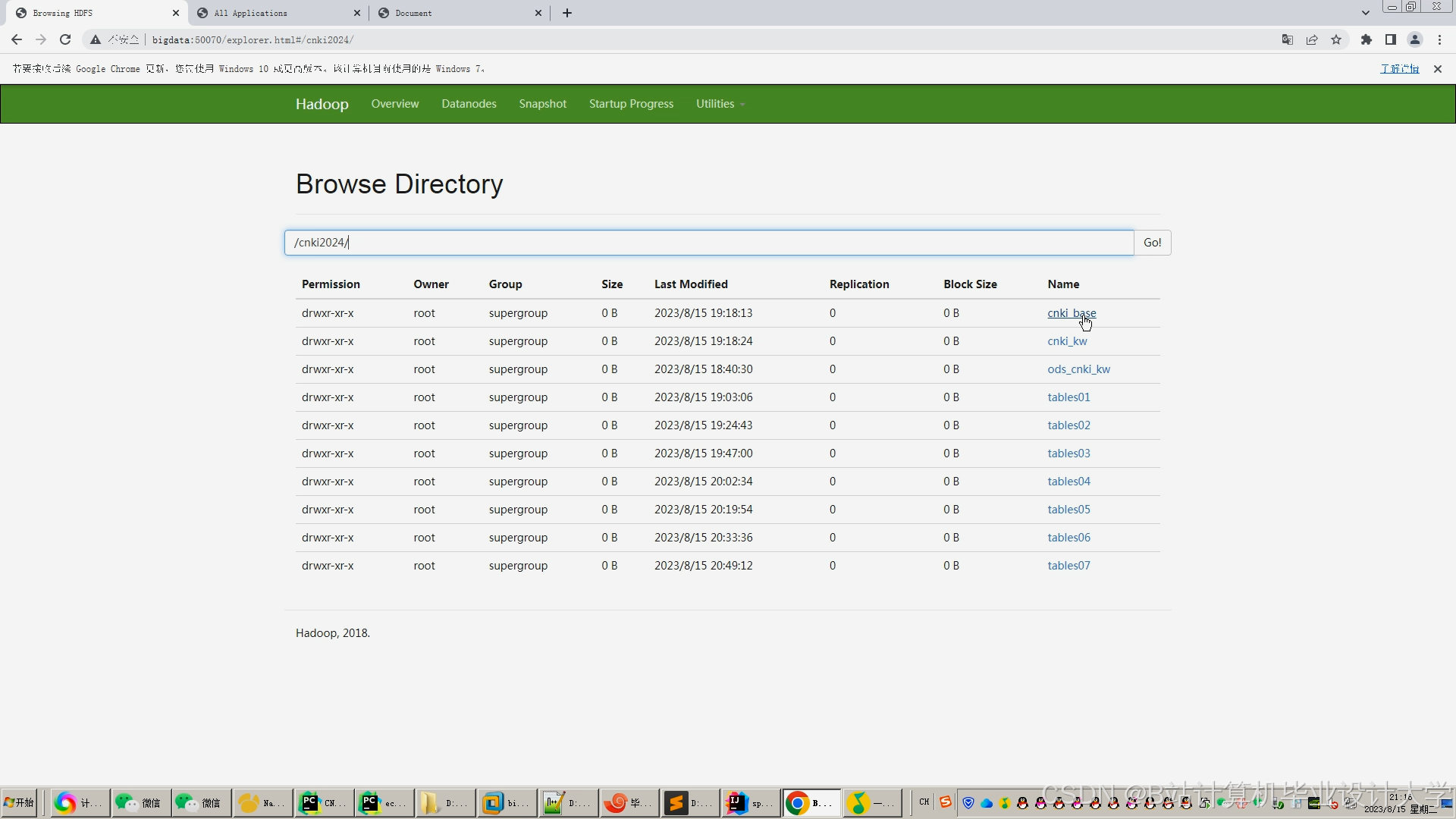
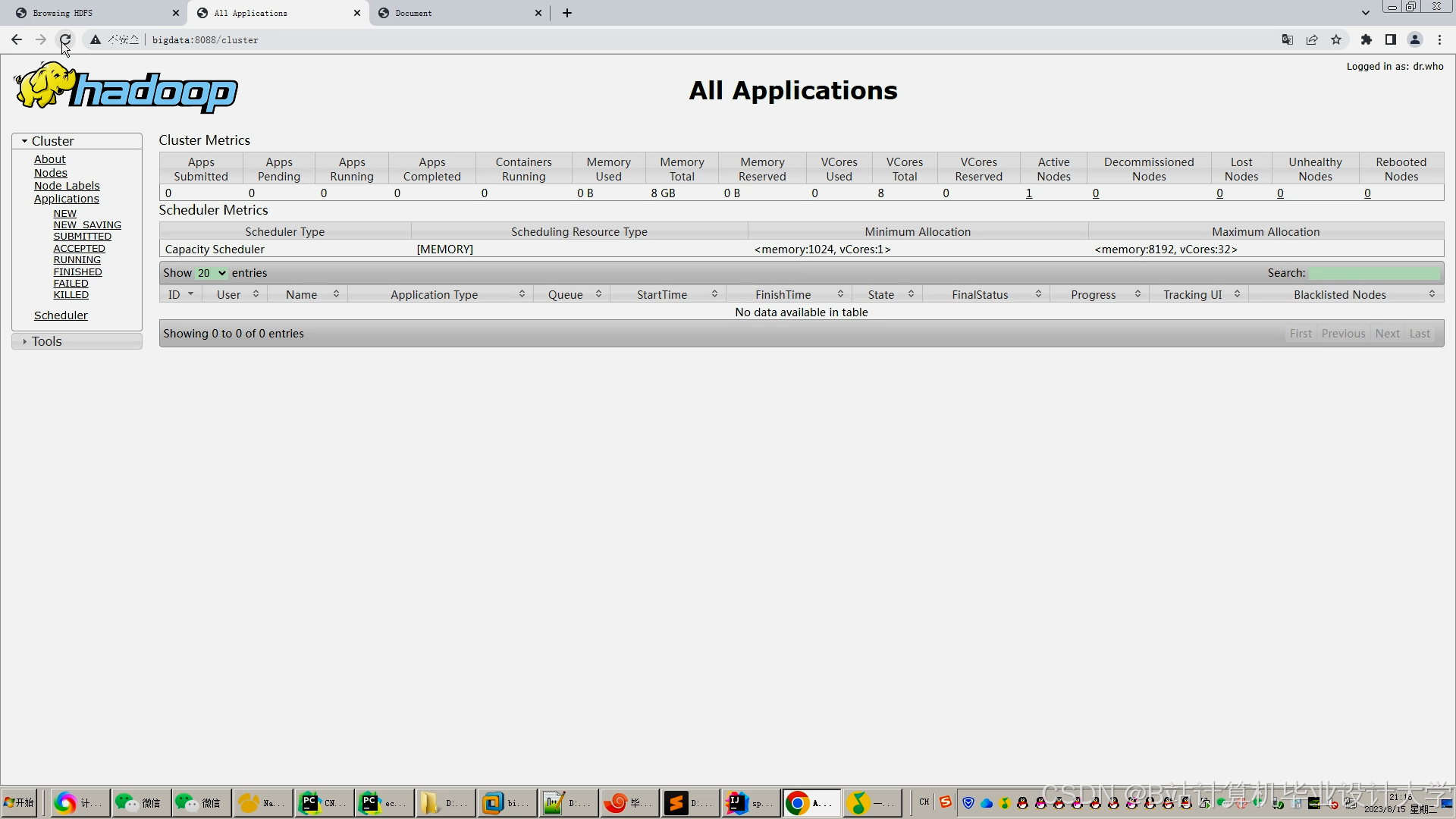
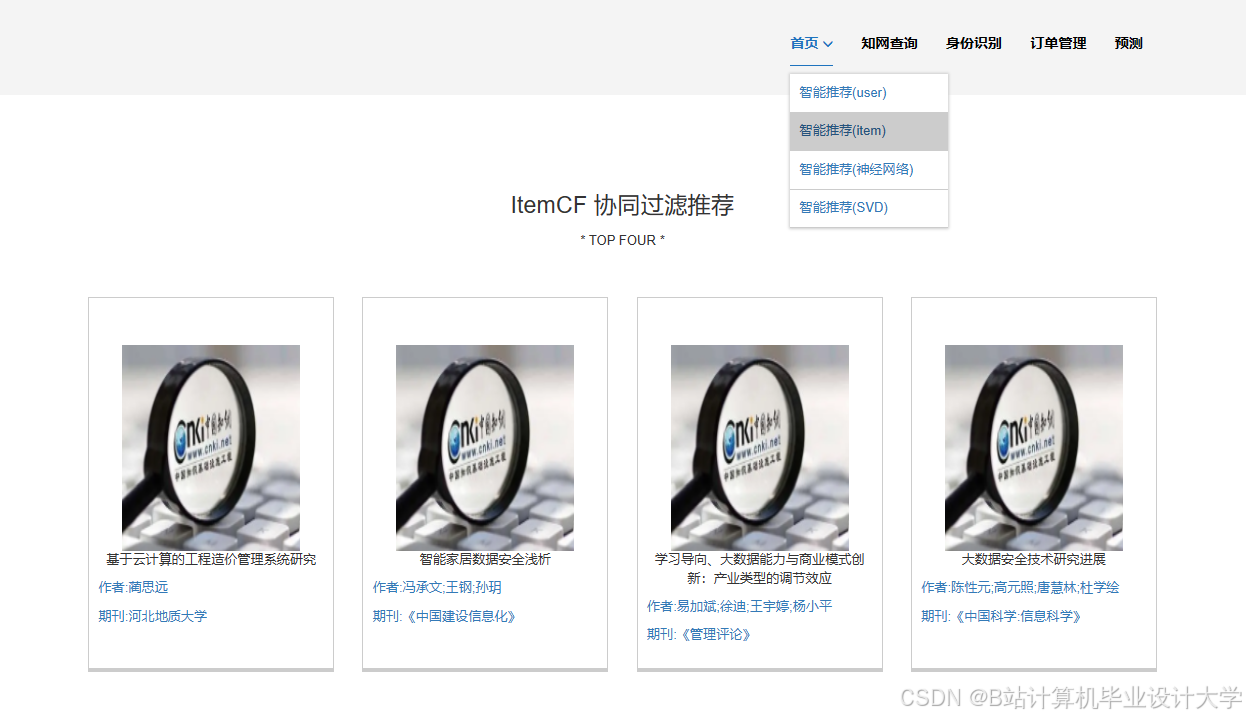
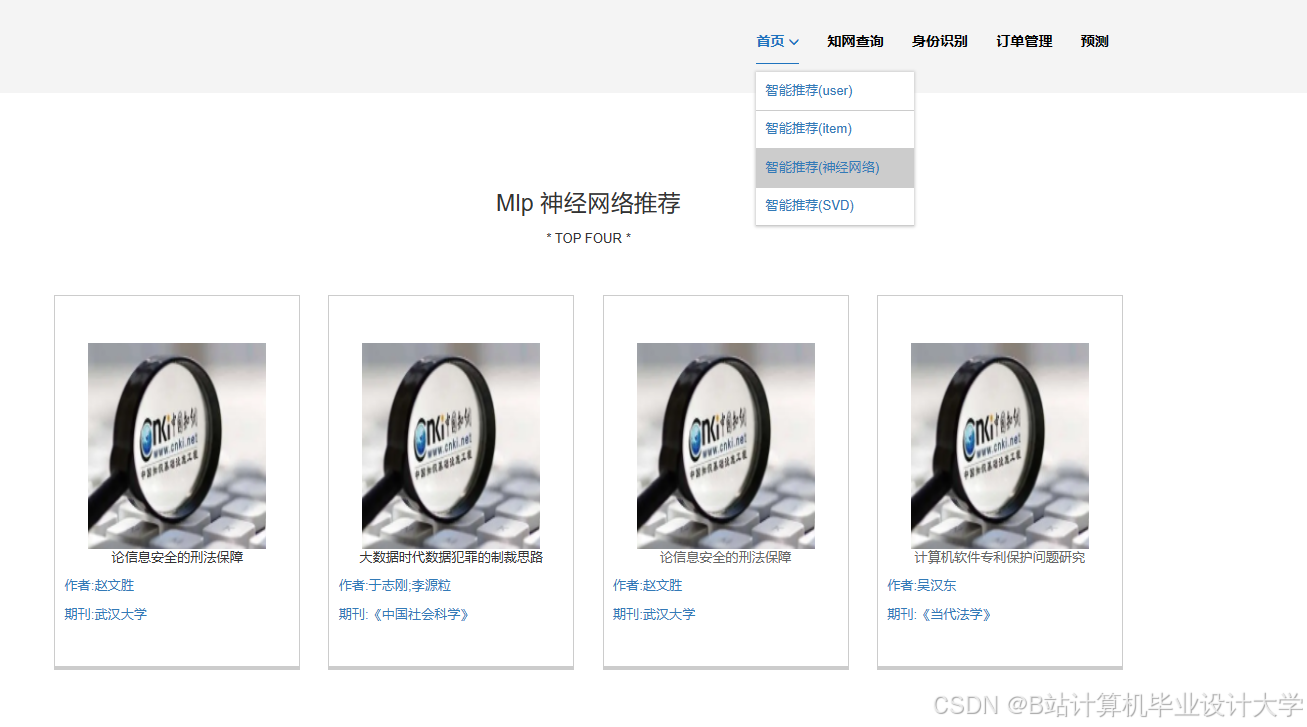
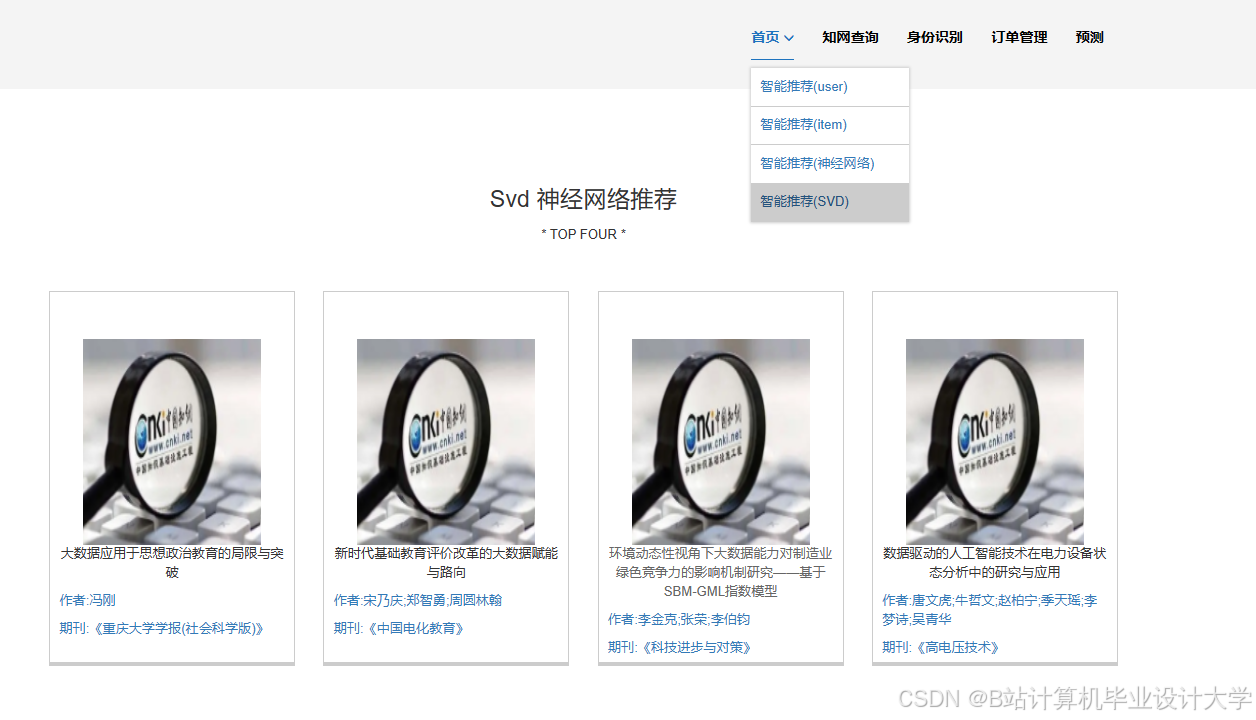
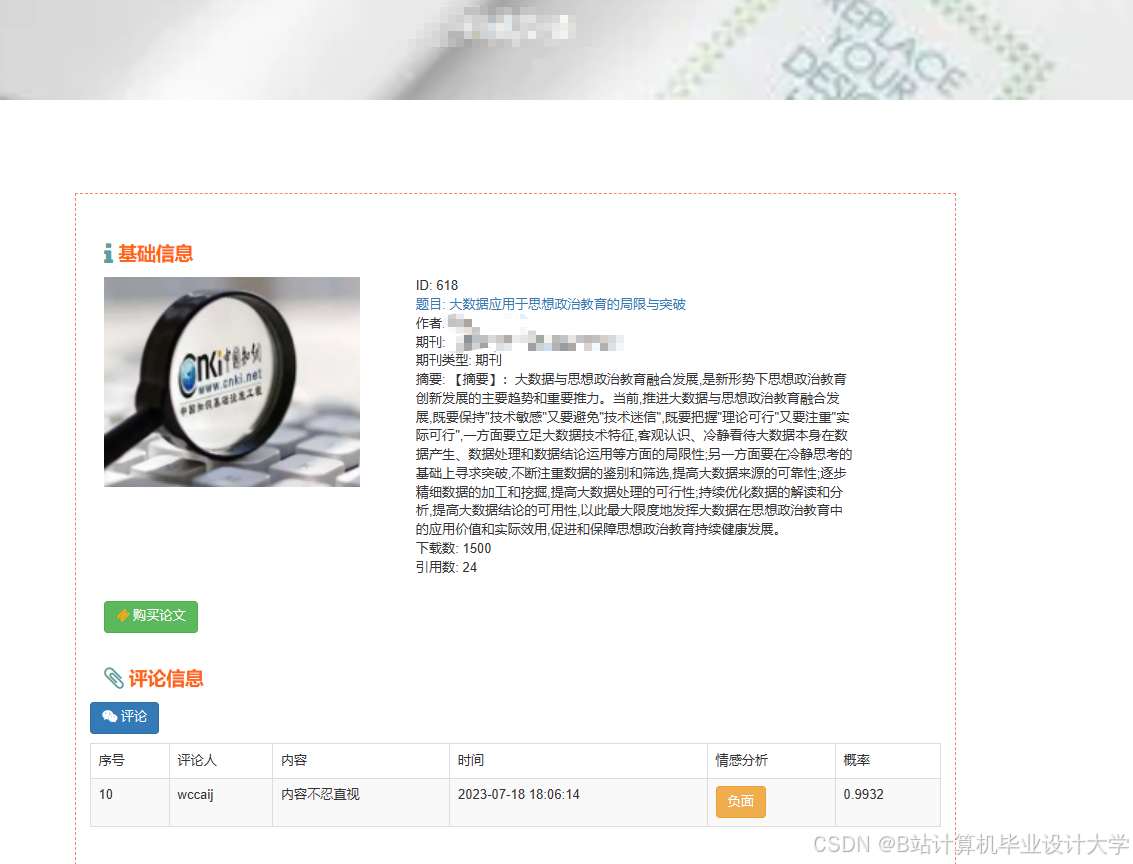
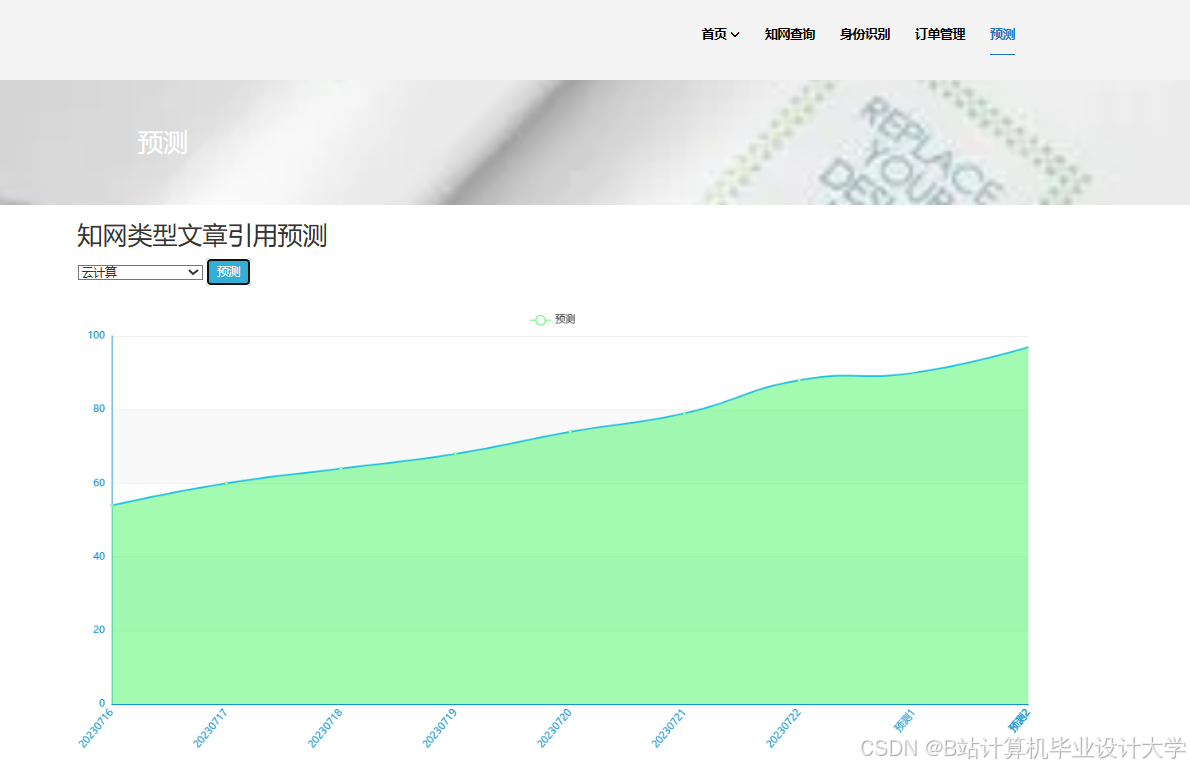
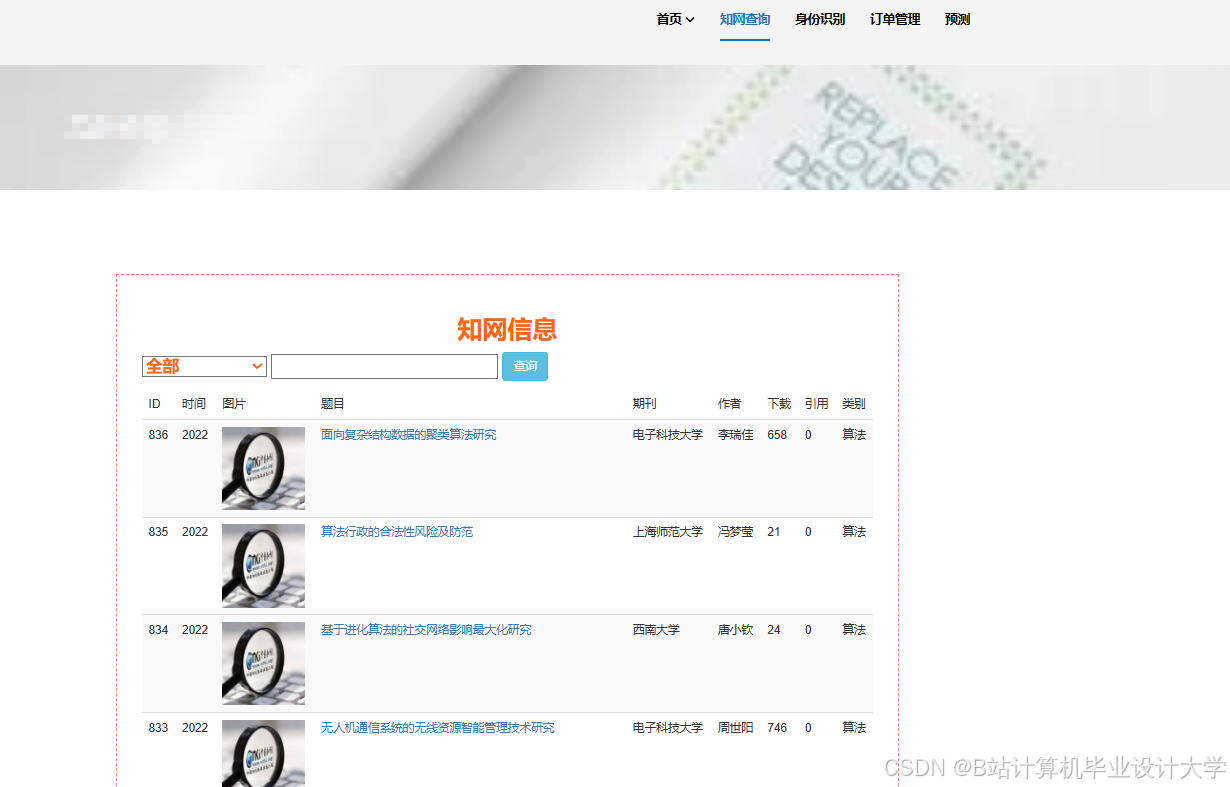
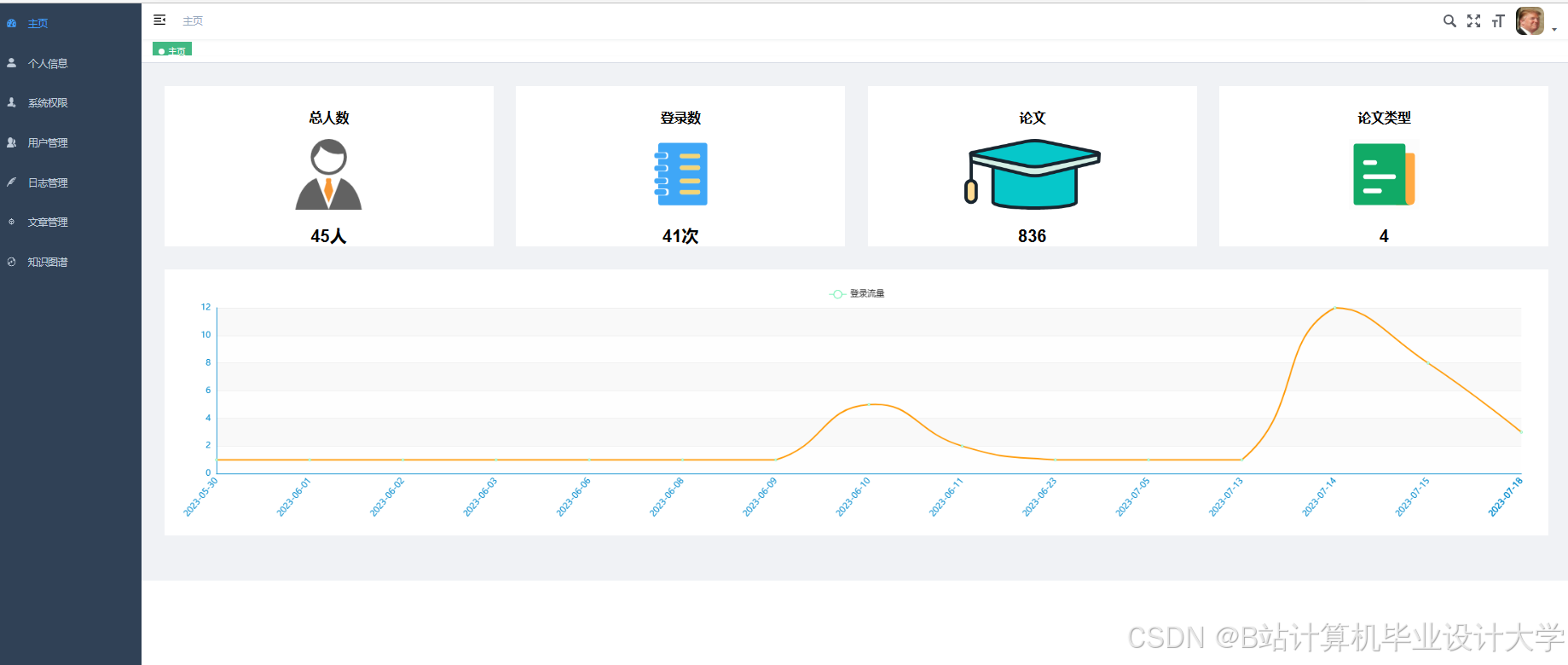
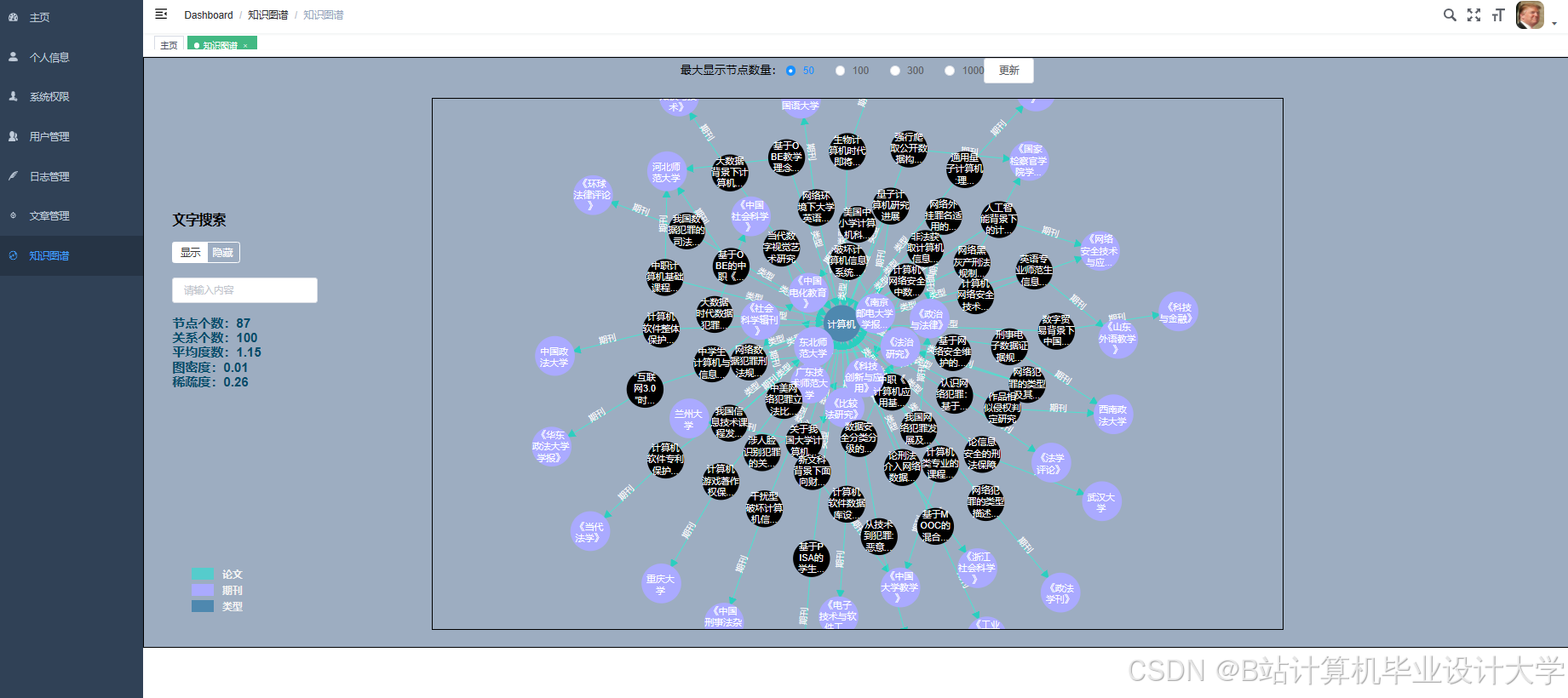
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











