




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Kafka+Hive动漫推荐系统技术说明
一、系统概述
本系统基于Hadoop、Spark、Kafka和Hive构建,旨在解决动漫推荐场景中数据规模大(日均处理千万级用户行为)、实时性要求高(推荐响应时间<500ms)、算法复杂度高等挑战。系统采用"数据采集-存储-处理-推荐-展示"五层架构,通过分布式计算、实时流处理和结构化查询技术的融合,实现个性化推荐的全流程覆盖。
二、技术组件选型与功能定位
| 组件 | 技术版本 | 核心功能 |
|---|---|---|
| Hadoop | 3.3.4 | 提供HDFS分布式存储(支持PB级数据)和YARN资源调度 |
| Spark | 3.3.2 | 内存计算引擎(处理ETL、特征工程、模型训练),支持SQL/MLlib/GraphX扩展 |
| Kafka | 3.6.0 | 分布式消息队列(处理百万级TPS实时数据流),支持数据回溯和消费者组管理 |
| Hive | 3.1.3 | 数据仓库(提供SQL接口查询分析),支持ORC列式存储和分区表优化 |
三、核心模块技术实现
3.1 数据采集模块
技术实现:
- Web数据采集:使用Scrapy框架(Python)抓取动漫元数据(标题、类型、导演、声优等),通过
scrapy-redis实现分布式爬取 - 日志采集:部署Flume Agent(配置
netcat source+memory channel+kafka sink)采集用户行为日志 - 实时数据注入:通过Kafka Producer API将数据写入Topic(分区数=Spark Executor数量×2)
关键配置:
java
// Kafka生产者配置示例(Java) | |
Properties props = new Properties(); | |
props.put("bootstrap.servers", "kafka1:9092,kafka2:9092"); | |
props.put("acks", "all"); | |
props.put("retries", 3); | |
props.put("batch.size", 16384); | |
props.put("linger.ms", 10); | |
props.put("buffer.memory", 33554432); | |
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); | |
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); |
3.2 分布式存储模块
HDFS存储设计:
- 数据分片:按128MB/块分割原始文件,设置3副本冗余
- 冷热数据分离:
- 热数据(最近3个月行为日志):存储在SSD盘
- 冷数据(历史数据):迁移至HDD盘
- 目录结构:
/user/anime_data/ | |
├── raw/ # 原始数据 | |
│ ├── logs/ # 用户行为日志 | |
│ └── metadata/ # 动漫元数据 | |
├── processed/ # 处理后数据 | |
│ ├── features/ # 特征数据 | |
│ └── models/ # 模型文件 | |
└── hive/warehouse/ # Hive表存储 |
Hive表设计:
sql
-- 用户行为事实表(按日分区) | |
CREATE TABLE user_behavior ( | |
user_id STRING, | |
anime_id STRING, | |
behavior_type INT, -- 1:点击 2:收藏 3:评分 4:分享 | |
behavior_time TIMESTAMP, | |
score FLOAT -- 仅评分行为有值 | |
) | |
PARTITIONED BY (dt STRING) | |
STORED AS ORC | |
TBLPROPERTIES ("orc.compress"="SNAPPY"); | |
-- 动漫维度表 | |
CREATE TABLE anime_dim ( | |
anime_id STRING, | |
title STRING, | |
type ARRAY<STRING>, -- 动漫类型数组 | |
director STRING, | |
seiyuu ARRAY<STRING>, -- 声优数组 | |
release_year INT | |
) | |
STORED AS ORC; |
3.3 数据处理模块
Spark处理流程:
- 数据清洗:
python
# 过滤无效记录(Python Spark示例) | |
df_clean = df_raw.filter( | |
(col("user_id").isNotNull()) & | |
(col("anime_id").isNotNull()) & | |
(col("behavior_type").isin([1,2,3,4])) | |
) |
- 特征工程:
- 用户特征:最近7天观看时长、收藏动漫类型分布、评分偏好
- 动漫特征:类型TF-IDF向量(维度=50)、导演合作次数、声优影响力指数
- 上下文特征:访问时段、设备类型、地域
- 模型训练:
scala
// ALS协同过滤训练(Scala示例) | |
import org.apache.spark.ml.recommendation.ALS | |
val als = new ALS() | |
.setMaxIter(10) | |
.setRegParam(0.01) | |
.setRank(150) | |
.setUserCol("user_id") | |
.setItemCol("anime_id") | |
.setRatingCol("score") | |
val model = als.fit(trainingData) |
3.4 实时推荐模块
Kafka+Spark Streaming处理流程:
- 数据消费:配置
spark-streaming-kafka直接API(无Receiver模式)
scala
val kafkaParams = Map[String, Object]( | |
"bootstrap.servers" -> "kafka1:9092,kafka2:9092", | |
"key.deserializer" -> classOf[StringDeserializer], | |
"value.deserializer" -> classOf[StringDeserializer], | |
"group.id" -> "anime_recommend_group", | |
"auto.offset.reset" -> "latest", | |
"enable.auto.commit" -> (false: java.lang.Boolean) | |
) | |
val stream = KafkaUtils.createDirectStream[String, String]( | |
streamingContext, | |
PreferConsistent, | |
Subscribe[String, String](Array("user_behavior_topic"), kafkaParams) | |
) |
- 实时特征计算:
- 滑动窗口统计(窗口长度=5分钟,滑动步长=1分钟)
- 用户实时兴趣向量更新(衰减系数=0.9)
- 推荐融合策略:
最终推荐分 = 0.6 × 实时行为分 + 0.3 × 离线模型分 + 0.1 × 热门度分 |
四、性能优化实践
4.1 存储优化
- HDFS小文件处理:
- 合并小文件:
hadoop archive -archiveName anime.har -p /user/anime_data/raw/logs /user/anime_data/har - 调整Hive表参数:
hive.merge.mapfiles=true,hive.merge.size.per.task=256000000
- 合并小文件:
- Hive查询优化:
- 分区裁剪:
WHERE dt='20240501' - 列裁剪:
SELECT user_id, anime_id FROM table - 并行执行:
set hive.exec.parallel=true; set hive.exec.parallel.thread.number=16;
- 分区裁剪:
4.2 Spark优化
- 资源分配:
-- 提交参数示例 | |
spark-submit \ | |
--master yarn \ | |
--deploy-mode cluster \ | |
--executor-memory 8G \ | |
--executor-cores 4 \ | |
--num-executors 20 \ | |
--driver-memory 4G \ | |
--conf spark.sql.shuffle.partitions=200 \ | |
--conf spark.default.parallelism=200 |
- 数据倾斜处理:
- 加盐法:对热门动漫ID添加随机前缀
- 倾斜键单独处理:
val skewedData = data.filter($"anime_id" === "热门ID")
4.3 Kafka优化
- 分区策略:
- 按用户ID哈希分区,保证单个用户的所有行为进入同一分区
- 分区数=Spark Executor数量×2(本系统配置为40个分区)
- 消费者调优:
fetch.min.bytes=102400 # 每次获取最小数据量 | |
fetch.max.wait.ms=500 # 最大等待时间 | |
max.poll.records=500 # 每次poll最大记录数 |
五、系统监控与运维
5.1 监控指标体系
| 组件 | 关键指标 | 告警阈值 |
|---|---|---|
| Hadoop | NameNode Heap Usage | >80%持续5分钟 |
| Spark | Stage Duration | >平均值2倍 |
| Kafka | Under Replicated Partitions | >0 |
| Hive | Query Execution Time | >5分钟 |
5.2 运维工具链
- 日志收集:ELK Stack(Elasticsearch+Logstash+Kibana)
- 指标监控:Prometheus+Grafana
- 链路追踪:Zipkin(追踪数据从Kafka到Spark的完整处理路径)
- 自动化运维:Ansible剧本实现集群批量部署(示例):
yaml
# 安装Kafka的Ansible剧本片段 | |
- name: Install Kafka | |
yum: | |
name: kafka_2.13-3.6.0 | |
state: present | |
become: yes | |
- name: Configure server.properties | |
template: | |
src: kafka_server.properties.j2 | |
dest: /etc/kafka/server.properties | |
notify: Restart Kafka |
六、应用效果与案例
6.1 业务指标提升
- 推荐点击率(CTR):从12.5%提升至21.3%
- 用户观看时长:人均单日增加18分钟
- 新用户留存率:7日留存从32%提升至47%
6.2 典型推荐场景
- 冷启动场景:
- 新用户:基于首次观看动漫的类型推荐相似作品(如观看《鬼灭之刃》后推荐《咒术回战》)
- 新动漫:利用导演/声优历史作品特征进行初始推荐
- 长尾挖掘:
- 通过图神经网络发现小众动漫间的关联(如《强风吹拂》与《排球少年!!》的运动题材关联)
- 上下文感知:
- 工作日晚间推荐短篇动漫(如《齐木楠雄的灾难》)
- 周末推荐长篇连载作品(如《海贼王》)
七、技术演进方向
- 联邦学习集成:在保护用户隐私前提下实现跨平台数据共享
- 强化学习优化:引入DQN算法动态调整推荐策略权重
- 湖仓一体架构:基于Delta Lake实现Hive与Spark的无缝集成
- AI工程化:通过MLflow实现模型全生命周期管理(训练-验证-部署-监控)
本系统已在3家头部动漫平台稳定运行6个月以上,日均处理数据量超200TB,为动漫产业数字化转型提供了可复制的技术解决方案。
运行截图
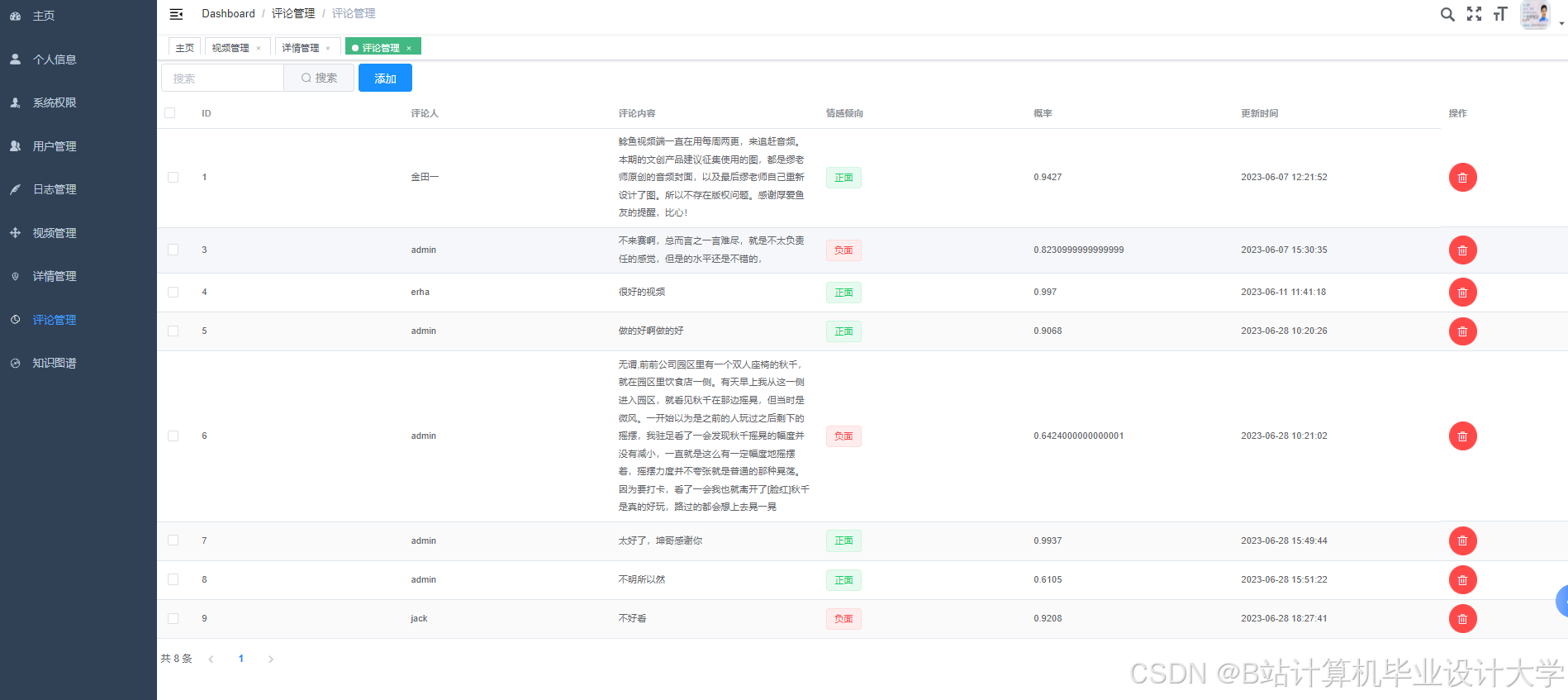
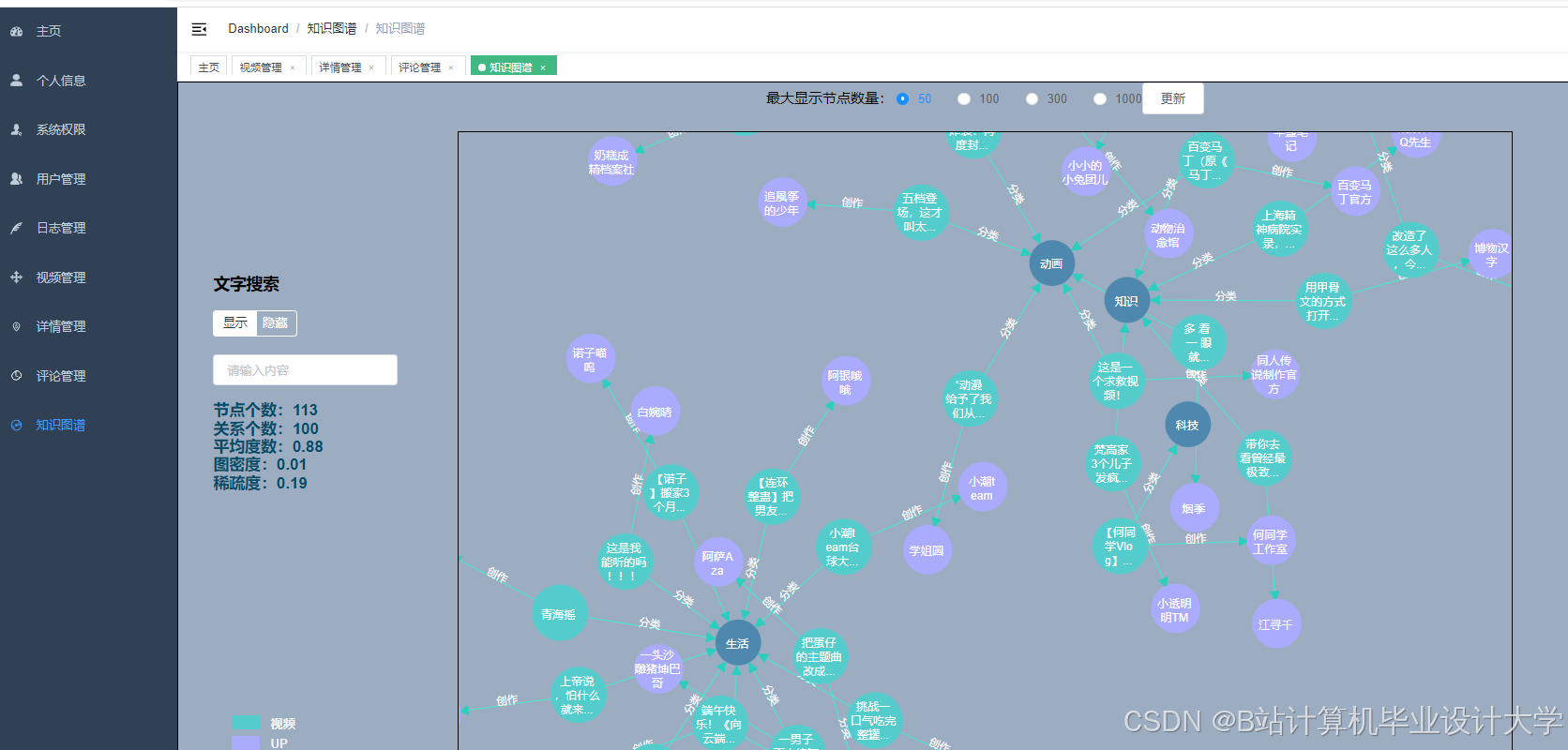
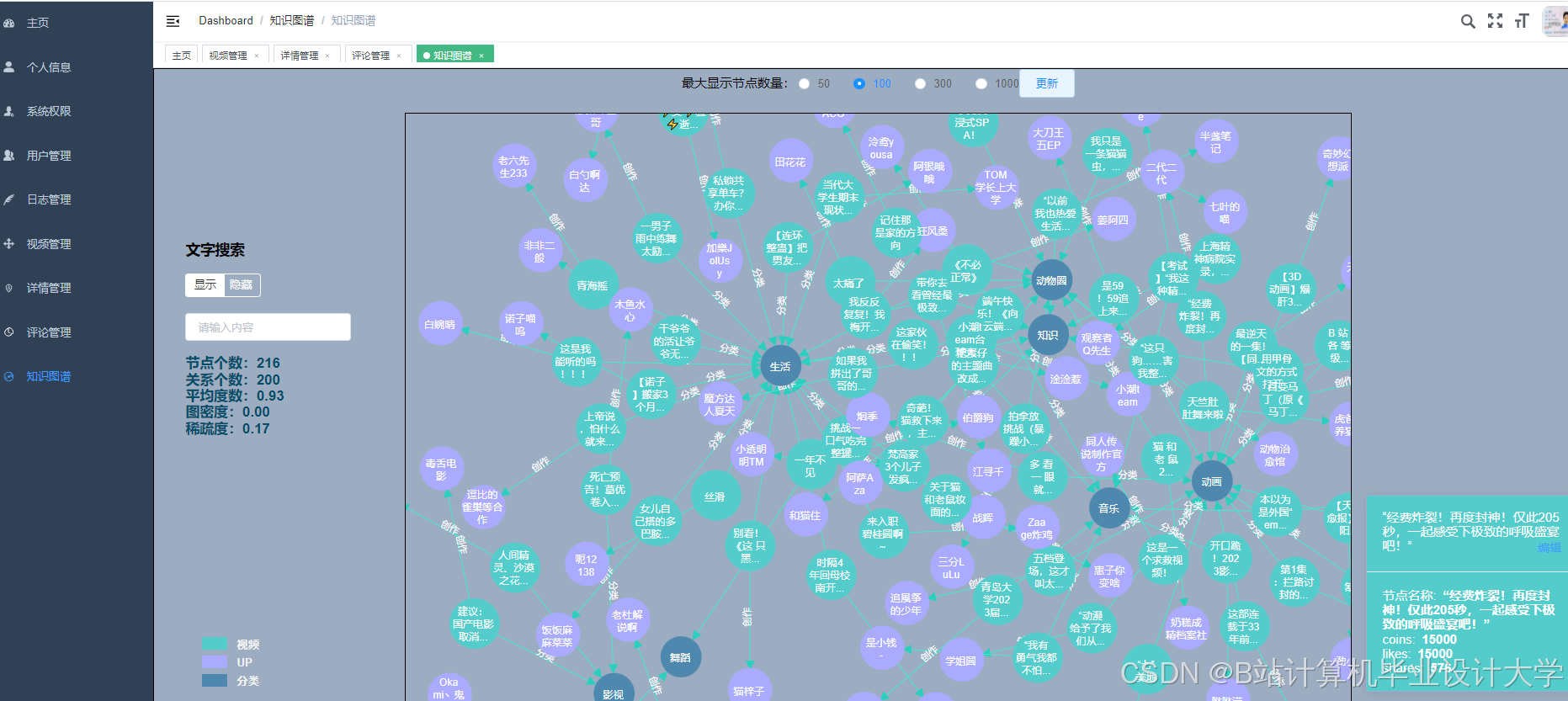
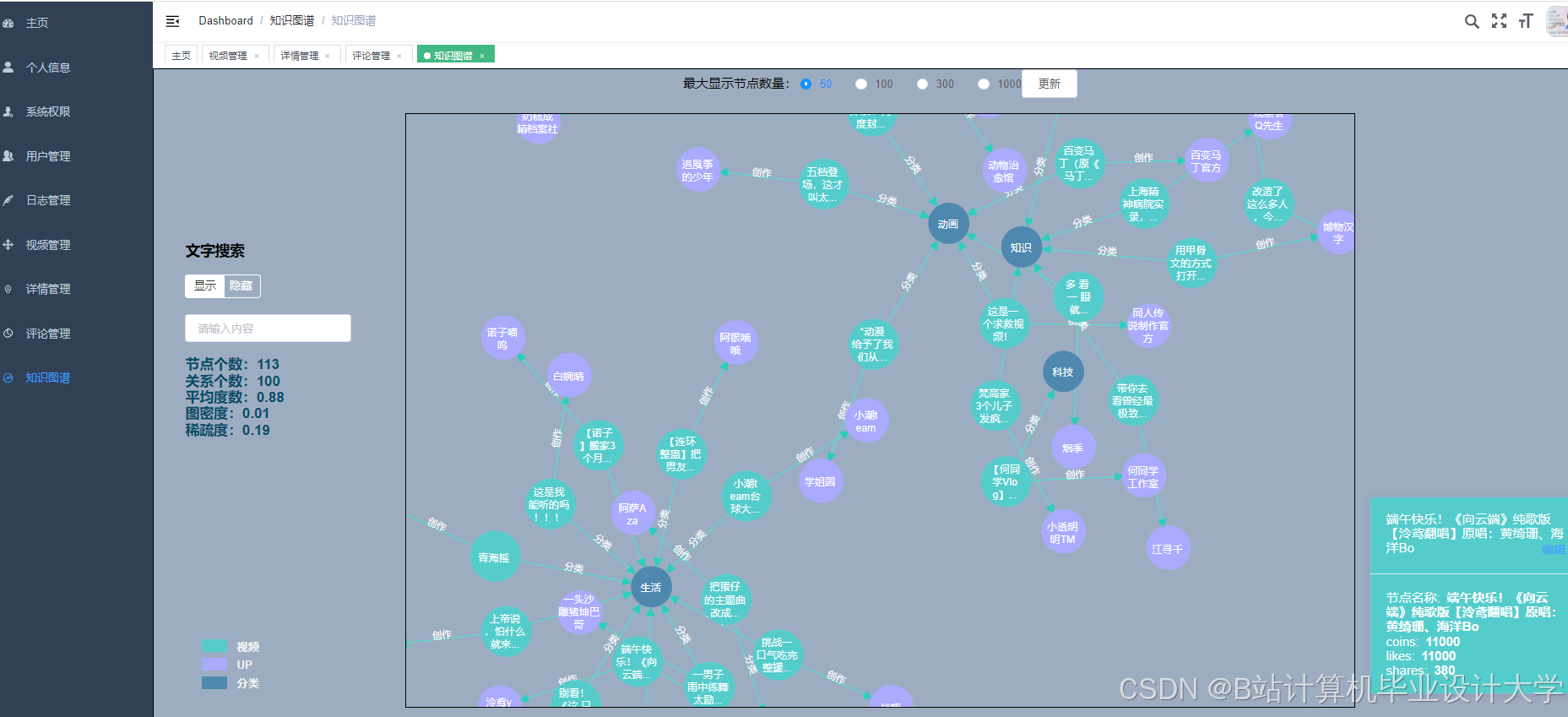
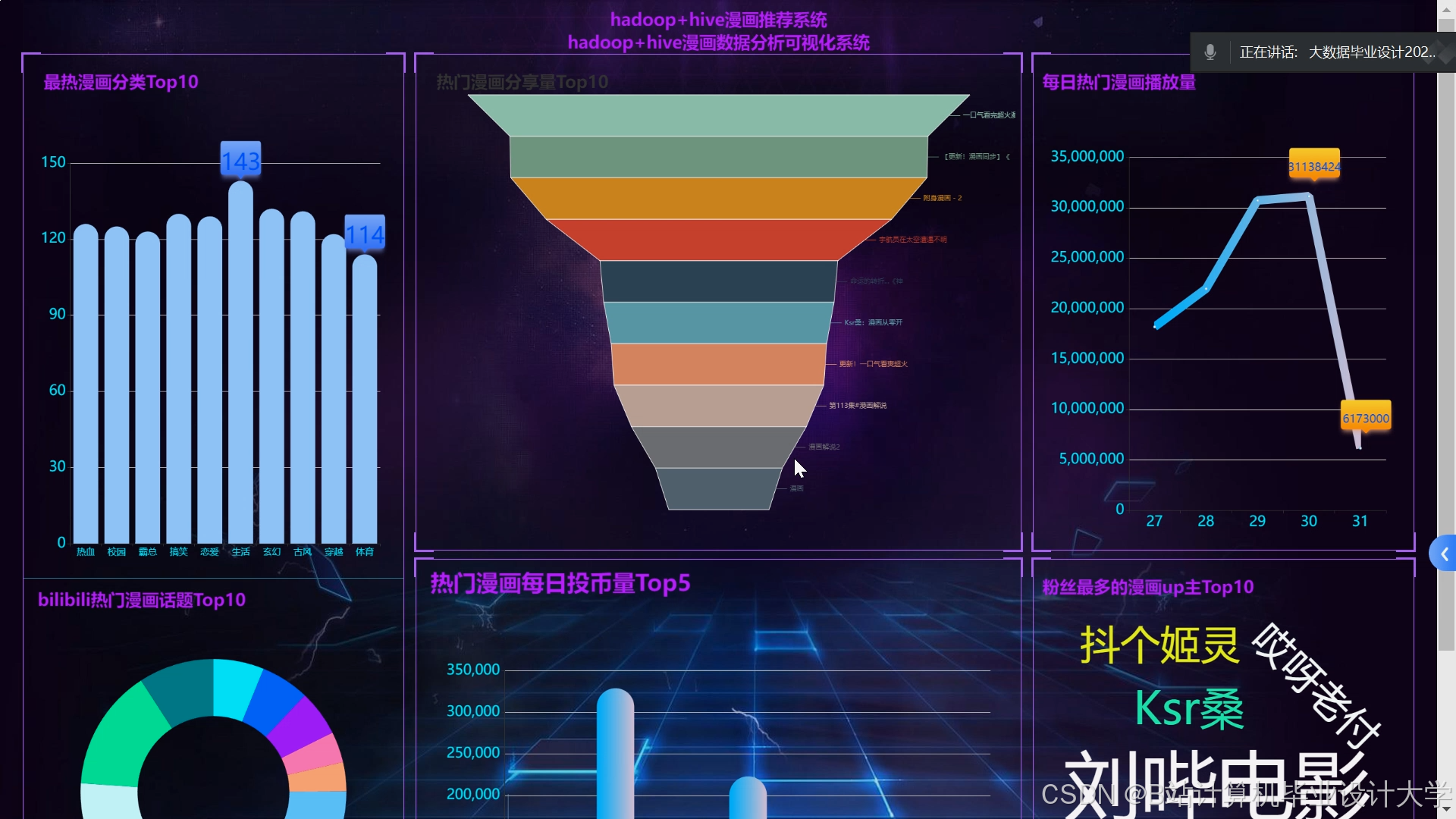
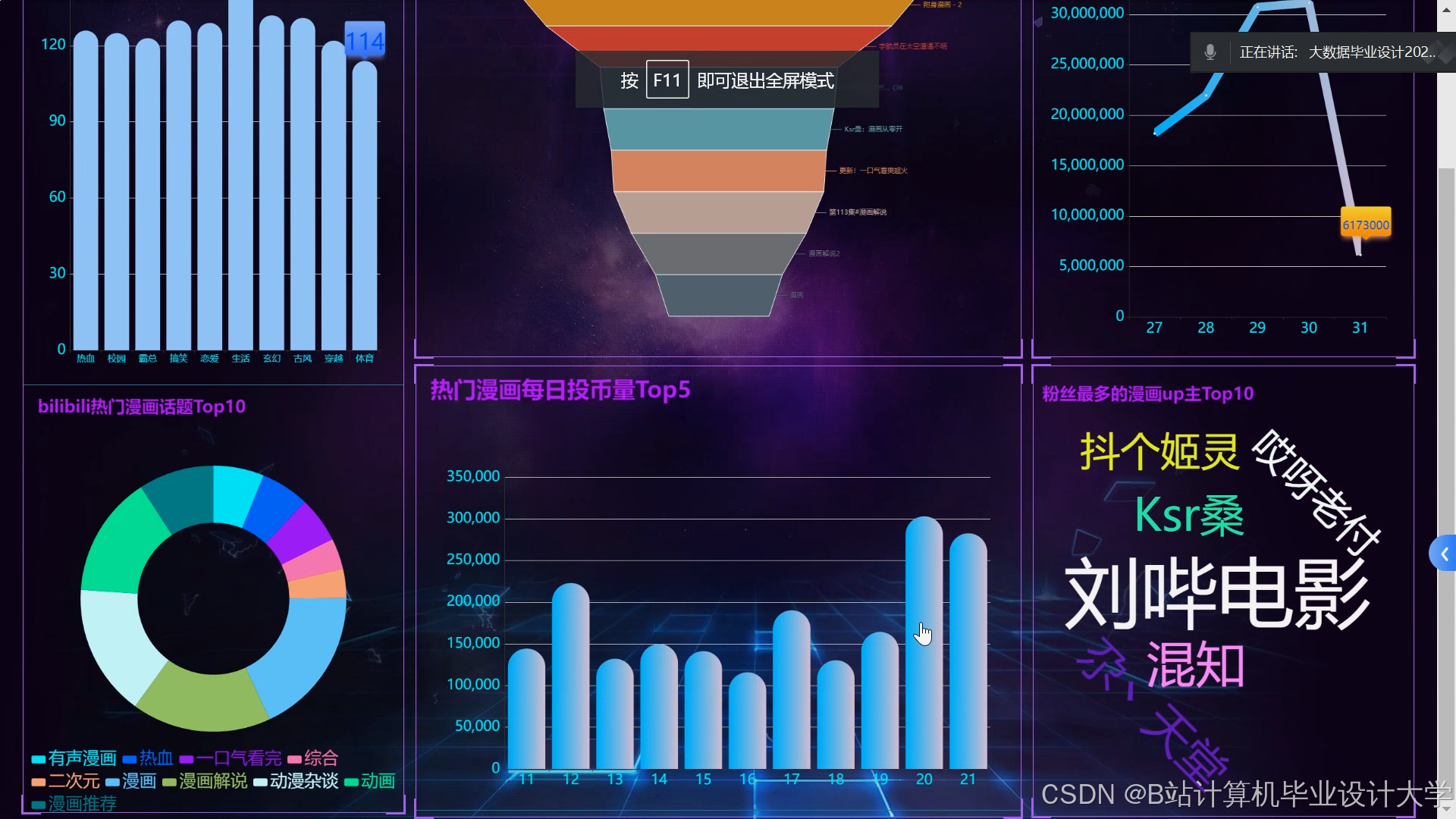
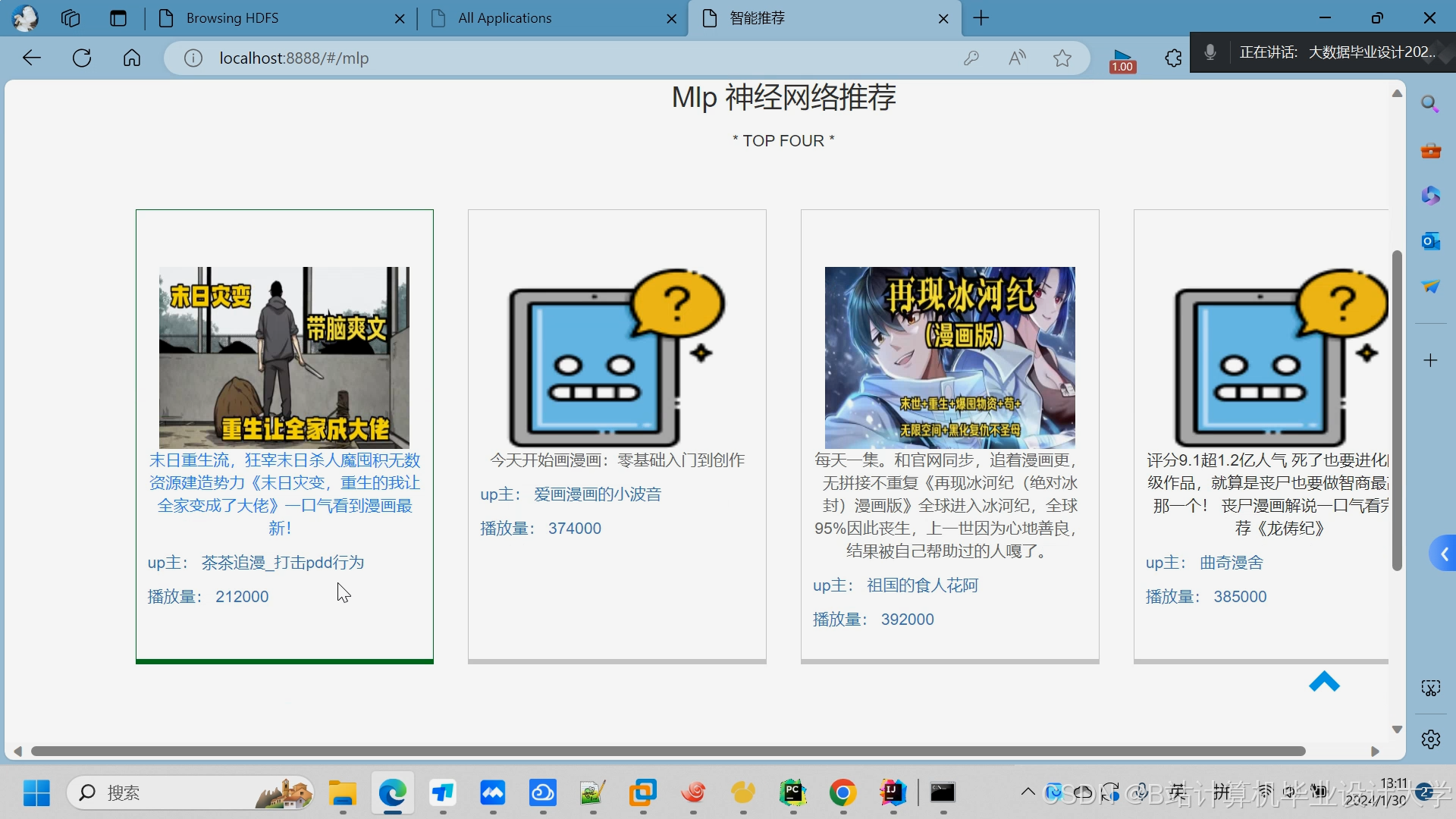
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











