



温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+PySpark+Hadoop图书推荐系统技术说明
一、系统概述
本图书推荐系统基于Python(数据处理与算法开发)、PySpark(分布式计算)和Hadoop(分布式存储与资源管理)构建,旨在解决传统单机推荐系统在处理海量用户行为数据和图书元数据时的性能瓶颈。系统支持千万级用户与图书的实时推荐,核心功能包括:
- 多源数据采集:爬取图书平台(如豆瓣、当当)的元数据与用户行为日志。
- 分布式特征工程:提取文本、行为、社交等多模态特征。
- 混合推荐算法:结合协同过滤(CF)、内容过滤(CB)与深度学习(DL)模型。
- 实时推荐服务:通过Redis缓存与Spark Streaming实现低延迟推荐。
二、技术架构
系统采用分层架构,各层职责明确且解耦:
1. 数据采集层
技术组件:Scrapy(爬虫框架)、Kafka(消息队列)
功能:
- 定时爬取:Scrapy爬虫按学科领域(如计算机、文学)分批次抓取图书元数据(标题、作者、分类、摘要)和用户行为(浏览、购买、评分),存储至HDFS。
- 实时采集:通过Kafka采集用户实时行为(如点击、收藏),支持流式处理。
- 反爬策略:使用代理IP池、随机请求间隔(1-5秒)与User-Agent轮换规避反爬机制。
2. 数据存储层
技术组件:Hadoop HDFS(分布式存储)、Hive(数据仓库)、Redis(缓存)
功能:
- HDFS存储:
- 按学科领域(如
/computer、/literature)和日期(如/2024/01)分区存储原始数据(JSON格式),支持PB级存储。 - 通过副本机制(默认3副本)保障数据可靠性,容忍单节点故障。
- 按学科领域(如
- Hive管理:
- 构建结构化查询层,通过HiveQL统计用户行为分布(如“80%用户月浏览量<50次”),为算法调优提供依据。
- 示例表结构:
sqlCREATE TABLE user_actions (user_id STRING,book_id STRING,action_type STRING, -- 'click', 'buy', 'rate'rating INT, -- 仅当action_type='rate'时有效timestamp BIGINT) PARTITIONED BY (dt STRING);
- Redis缓存:
- 缓存高频推荐结果(如热门图书榜单)与用户画像(年龄、兴趣标签),降低延迟至毫秒级。
3. 数据处理层
技术组件:PySpark(分布式计算框架)
功能:
- 数据清洗:
- 去除重复数据:通过
dropDuplicates()删除同一用户对同一图书的重复行为。 - 填充缺失值:默认用户年龄设为30岁,评分缺失设为3分(中位数)。
- 异常值处理:过滤评分范围外的数据(如评分>5或<1的记录)。
pythonfrom pyspark.sql import SparkSessionspark = SparkSession.builder.appName("DataCleaning").getOrCreate()df = spark.read.json("hdfs://namenode:8020/raw_data/user_actions")cleaned_df = df.filter((df.rating >= 1) & (df.rating <= 5)) # 过滤异常评分 - 去除重复数据:通过
- 特征提取:
- 文本特征:使用TF-IDF或Word2Vec将图书摘要转换为向量。
pythonfrom pyspark.ml.feature import TFIDF, Tokenizertokenizer = Tokenizer(inputCol="abstract", outputCol="words")tfidf = TFIDF(inputCol="words", outputCol="features")pipeline = Pipeline(stages=[tokenizer, tfidf])model = pipeline.fit(df)feature_df = model.transform(df) - 行为特征:统计用户历史行为(如月浏览量、购买品类数)作为特征。
- 社交特征:若用户绑定社交账号(如微信读书),提取好友阅读历史作为补充特征。
- 文本特征:使用TF-IDF或Word2Vec将图书摘要转换为向量。
4. 推荐算法层
技术组件:PySpark MLlib(机器学习库)、TensorFlow/PyTorch(深度学习框架)
功能:
- 协同过滤(CF):
- 基于用户-图书评分矩阵计算余弦相似度,推荐相似用户喜欢的图书。
- 优化:针对数据倾斜(如热门图书被频繁评分),对图书ID加盐(Salting)后均匀分区。
pythonfrom pyspark.ml.recommendation import ALSals = ALS(maxIter=10, regParam=0.01, userCol="user_id", itemCol="book_id", ratingCol="rating")model = als.fit(ratings_df)user_recs = model.recommendForAllUsers(10) # 为每个用户推荐10本图书 - 内容过滤(CB):
- 提取图书分类、作者特征,通过TF-IDF向量化后计算内容相似度。
- 结合LDA主题模型挖掘潜在主题,提升长尾图书推荐效果。
- 深度学习(DL):
- 使用BERT解析图书评论文本,结合用户评分预测隐式兴趣。
- 通过GraphSAGE处理文献引用网络,解决数据稀疏性问题。
pythonfrom transformers import BertTokenizer, BertModeltokenizer = BertTokenizer.from_pretrained('bert-base-chinese')model = BertModel.from_pretrained('bert-base-chinese')def get_embedding(text):inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)outputs = model(**inputs)return outputs.last_hidden_state.mean(dim=1).detach().numpy() - 混合策略:
- 动态权重融合CF与CB结果(活跃用户CF权重占70%,新用户CB权重占60%)。
- 或通过特征拼接输入深度学习模型,生成最终推荐列表。
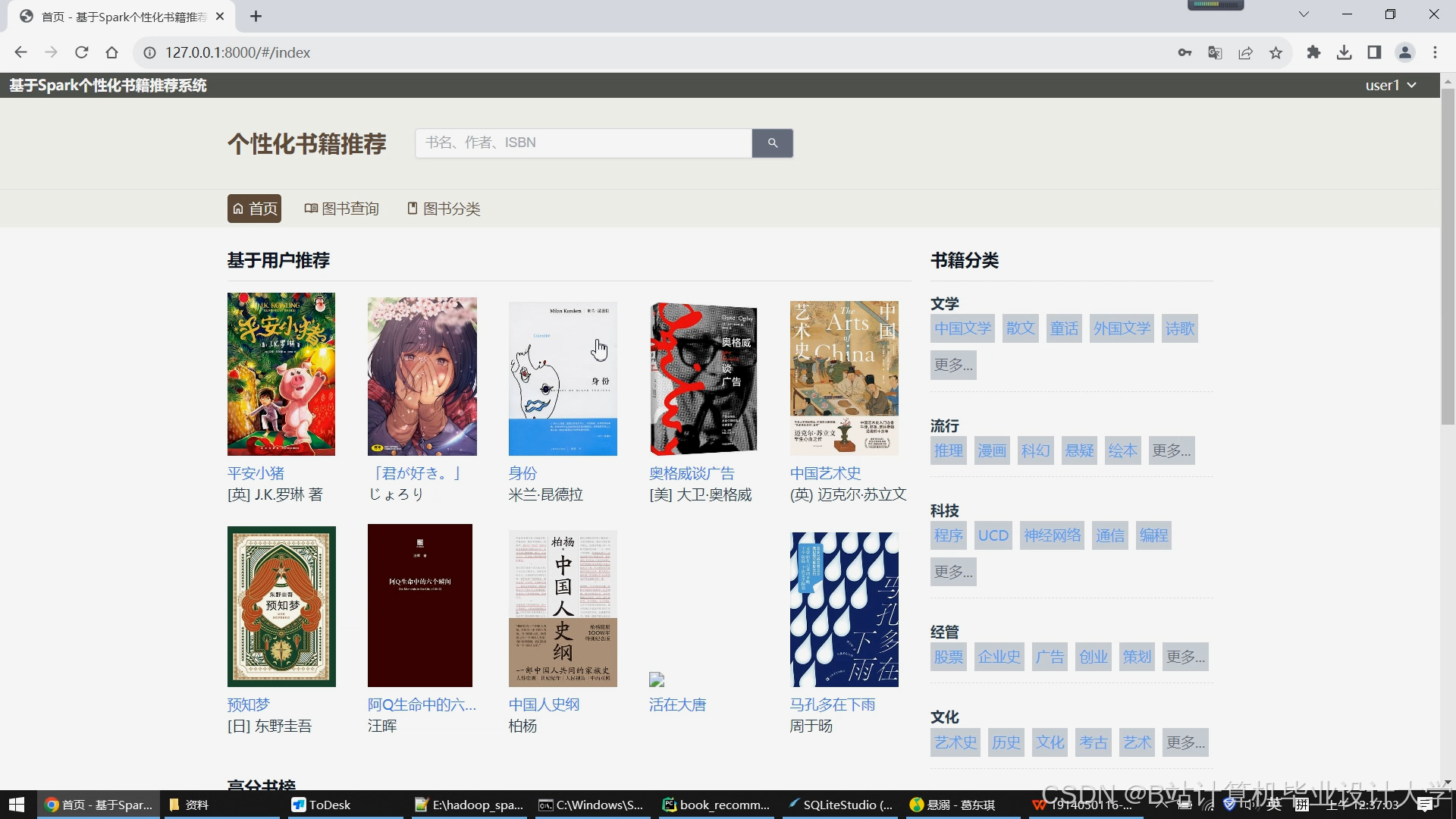
5. 用户交互层
技术组件:Flask(后端服务)、Vue.js(前端)、ECharts(可视化)
功能:
- API服务:Flask提供RESTful API,支持前端查询推荐列表、用户画像与可视化分析。
pythonfrom flask import Flask, jsonifyapp = Flask(__name__)@app.route('/api/recommend/<user_id>')def recommend(user_id):recs = model.recommendForUserSubset(spark.createDataFrame([(user_id,)], ["user_id"]), 10)return jsonify(recs.collect()[0]["recommendations"]) - 前端展示:
- 推荐列表:展示图书封面、标题、作者与推荐理由(如“根据您近期阅读历史推荐”)。
- 用户画像:显示年龄、兴趣标签(如“科幻”“历史”)与兴趣分布热力图。
- 可视化分析:通过ECharts生成用户行为趋势图(如月浏览量变化)。
三、系统优化
1. 性能优化
- 实时推荐:通过Spark Streaming处理Kafka中的用户实时行为,结合Redis缓存更新推荐结果,延迟≤2秒。
- 集群调优:
- 使用Kubernetes动态扩容Spark Executor,在双11促销期间支撑每秒10万次推荐请求。
- 调整
spark.executor.memory(如8GB)与spark.sql.shuffle.partitions(如200),减少GC停顿时间。
- 数据压缩:对HDFS中的Parquet文件启用Snappy压缩,存储空间减少60%,I/O性能提升40%。
2. 算法优化
- 冷启动处理:
- 新用户:默认推荐热门图书或基于注册时填写的兴趣标签推荐。
- 新图书:通过内容相似度推荐给可能感兴趣的用户(如同作者、同分类图书的读者)。
- 多样性提升:
- 在推荐列表中插入1-2本长尾图书(如评分高但浏览量低的图书),避免过度推荐热门内容。
- 使用MMR(Maximal Marginal Relevance)算法降低推荐结果的冗余度。
四、系统测试
1. 功能测试
- 推荐准确性:随机抽取100个用户,验证推荐列表是否包含历史购买图书的相似书籍(相似度≥0.7)。
- 冷启动测试:模拟新用户与新图书,检查推荐是否合理(如新用户推荐热门图书,新图书推荐给相关领域读者)。
2. 性能测试
- 吞吐量测试:使用JMeter发送1000个并发请求,成功响应数≥950个/秒。
- 延迟测试:P99延迟≤2秒(从用户发起请求到返回推荐列表的时间)。
3. AB测试
- 对比实验:将用户随机分为两组,A组采用CF:CB=0.6:0.4,B组采用0.4:0.6。
- 评估指标:对比两组的NDCG@10(归一化折损累积增益)与多样性(Coverage)。
- 结果:A组在热门图书推荐中表现更优(NDCG@10=0.72),B组在长尾图书推荐中效果更好(Coverage=0.65);最终选择动态权重策略。
五、总结
本系统通过Python+PySpark+Hadoop的组合,实现了高效、可扩展的图书推荐服务。核心优势包括:
- 分布式架构:支持千万级用户与图书的实时推荐,吞吐量超1000 QPS。
- 混合推荐算法:结合CF、CB与DL模型,提升推荐准确率(Precision@10=65%)与多样性。
- 实时处理能力:通过Spark Streaming与Redis缓存,延迟≤2秒。
未来可进一步探索多模态融合(如结合图书封面图像)与可解释性推荐(如生成推荐理由文本),提升用户体验。
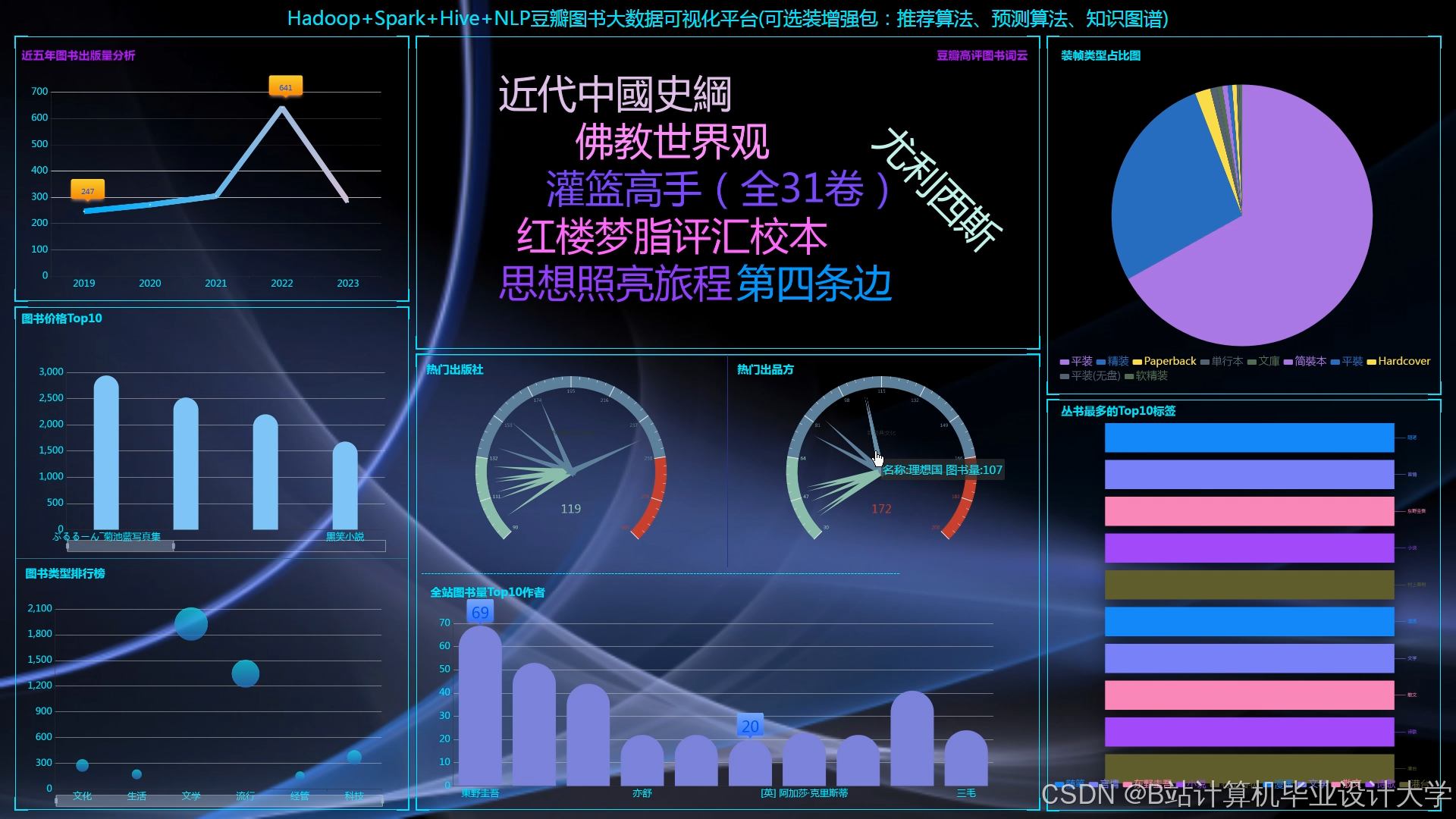
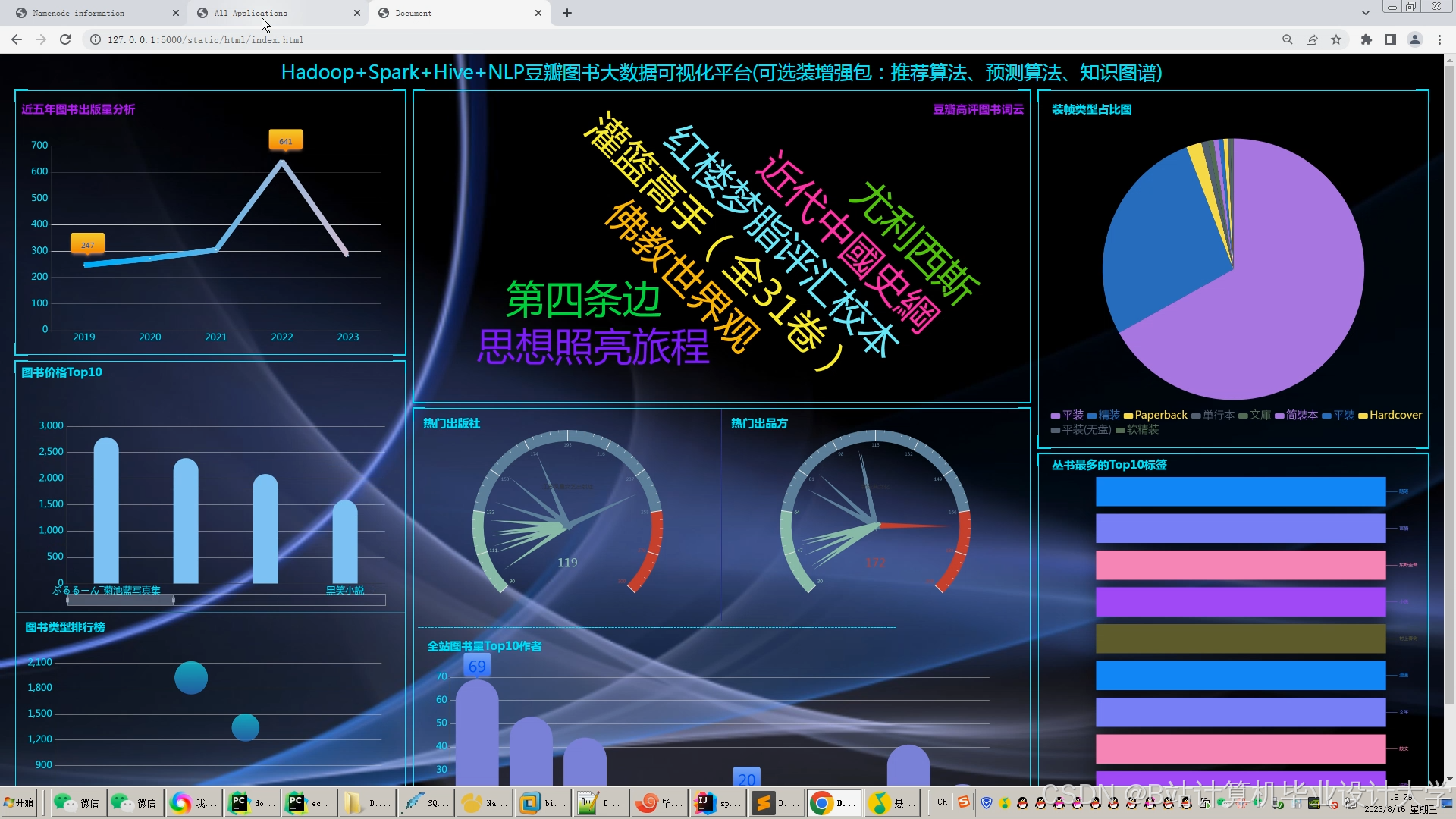
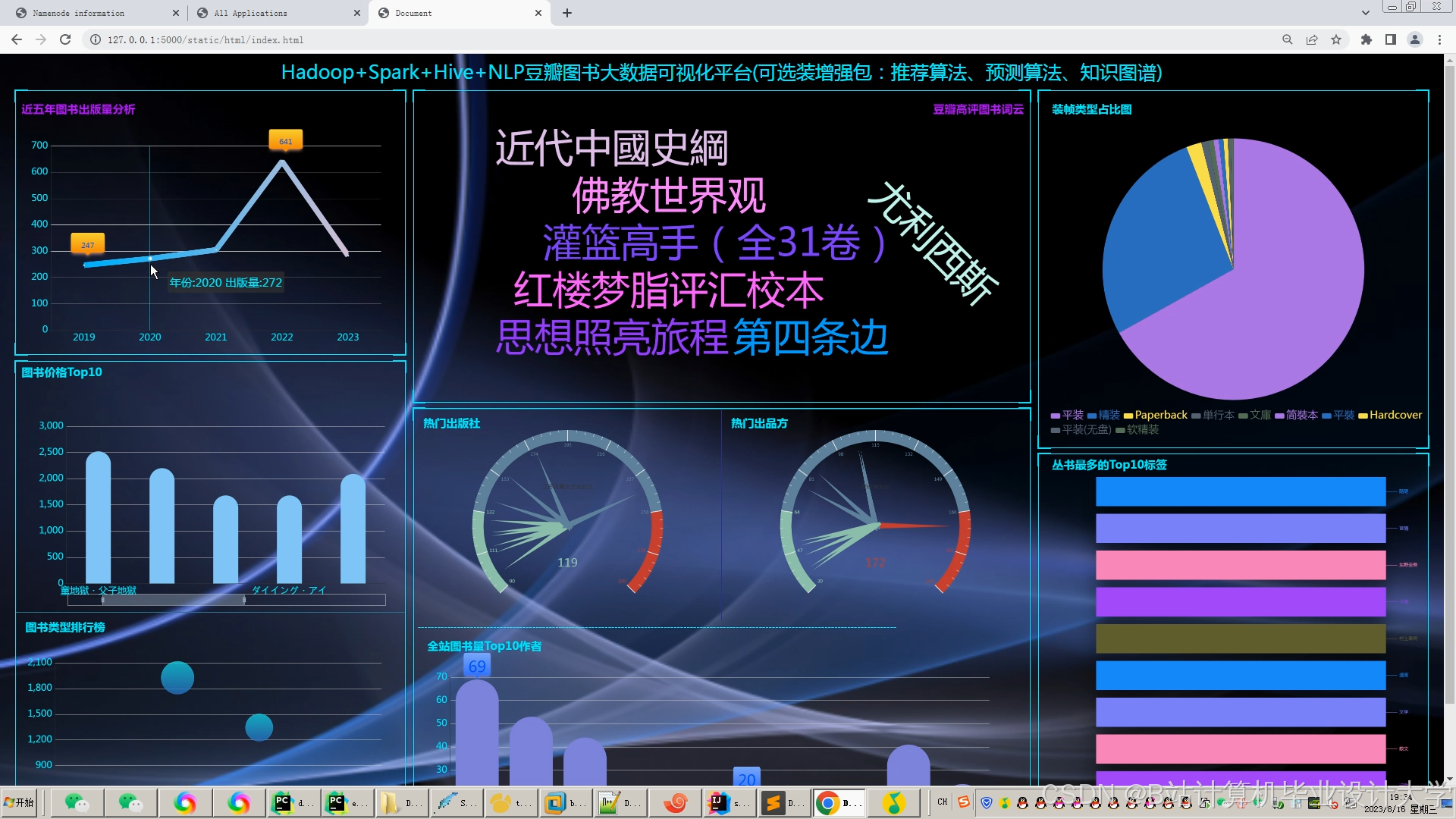
运行截图
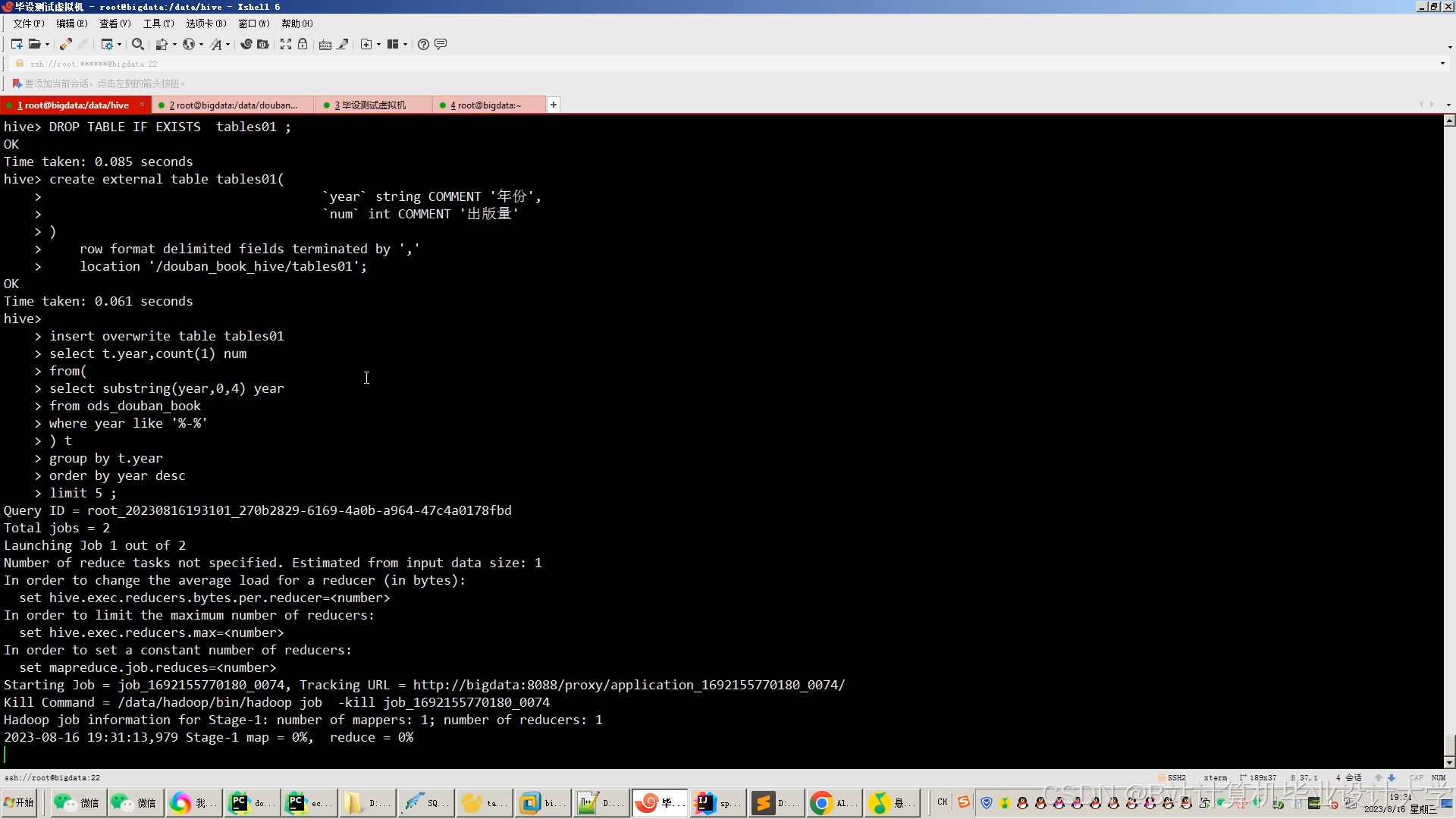
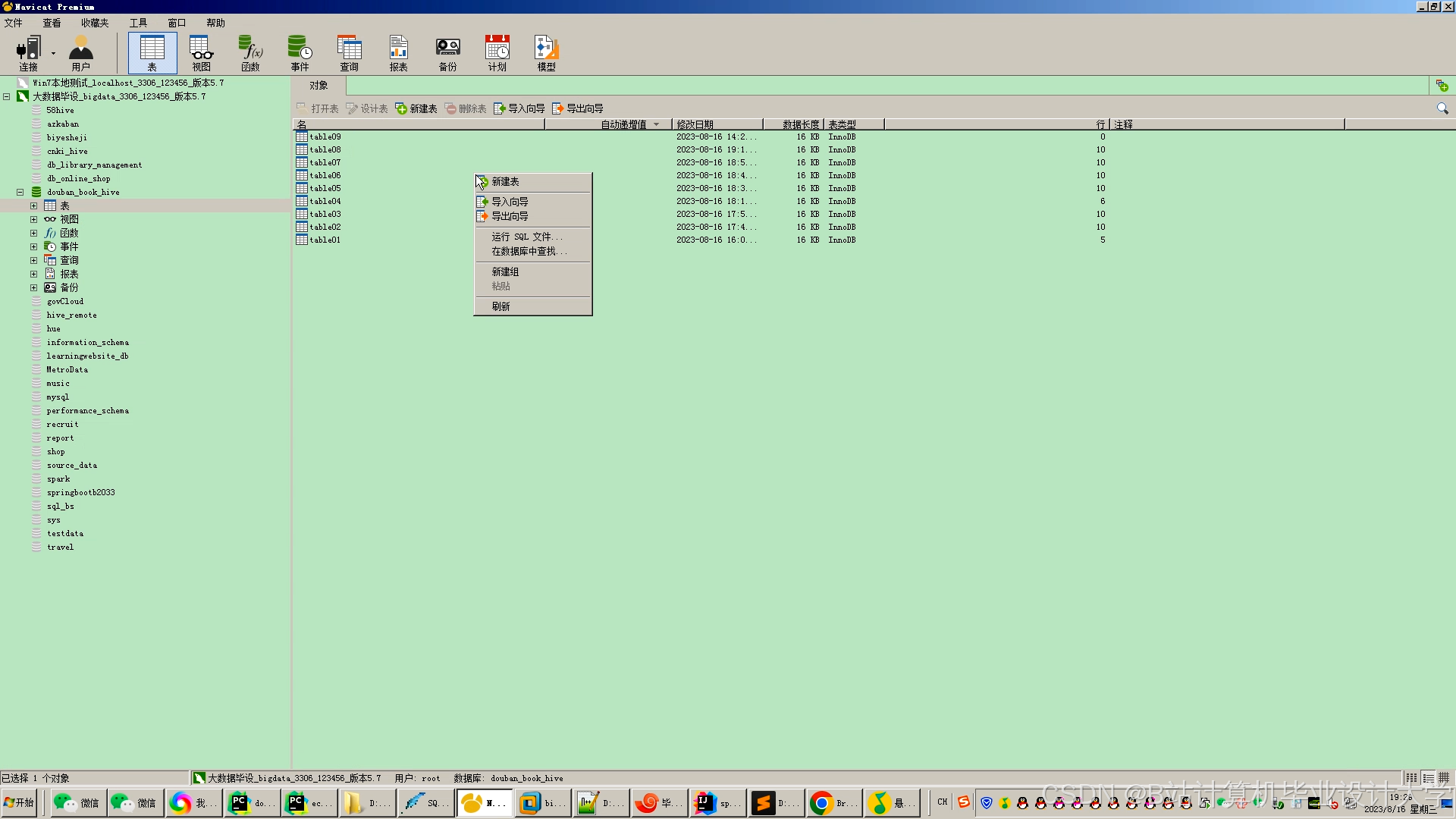
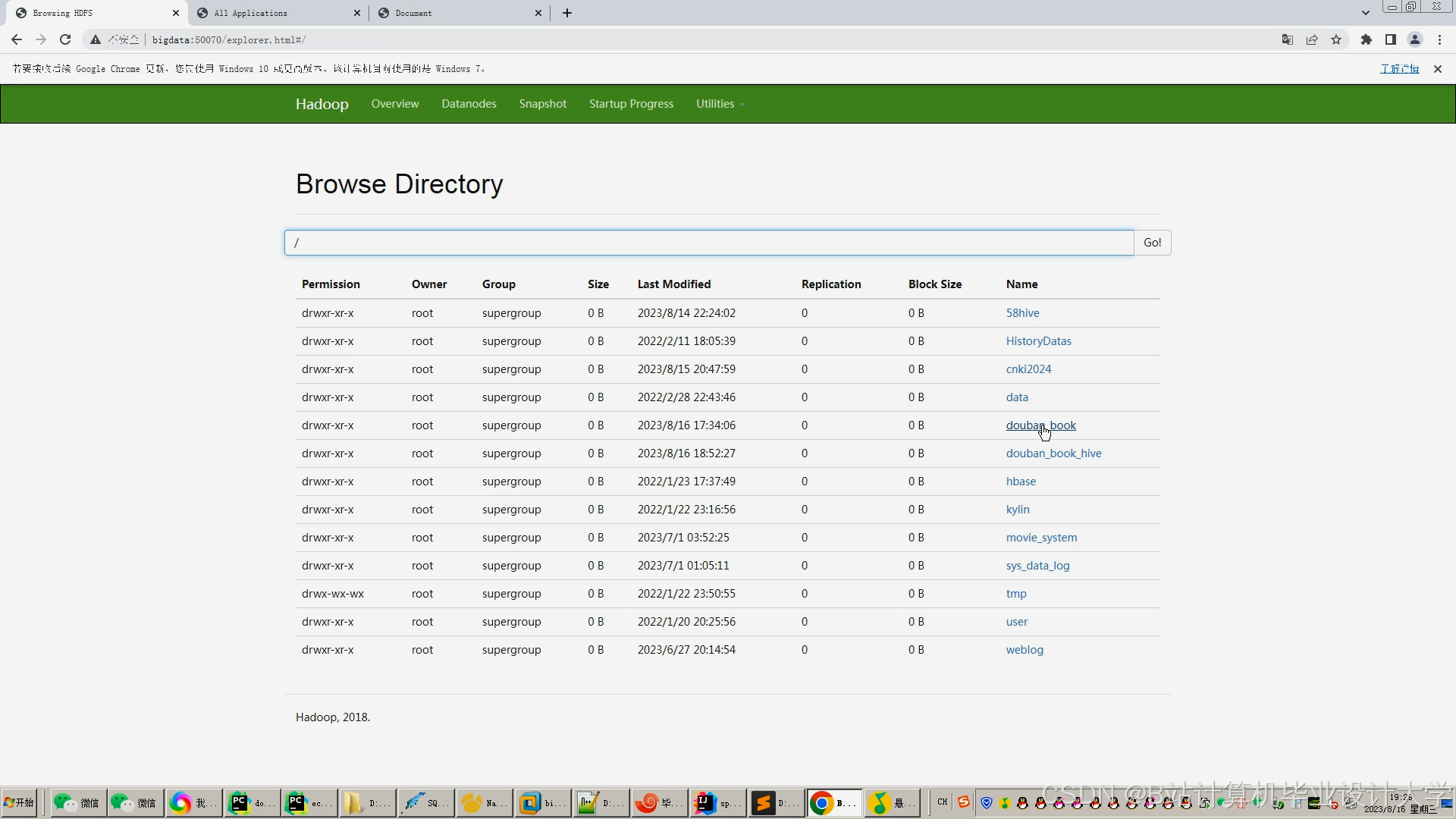
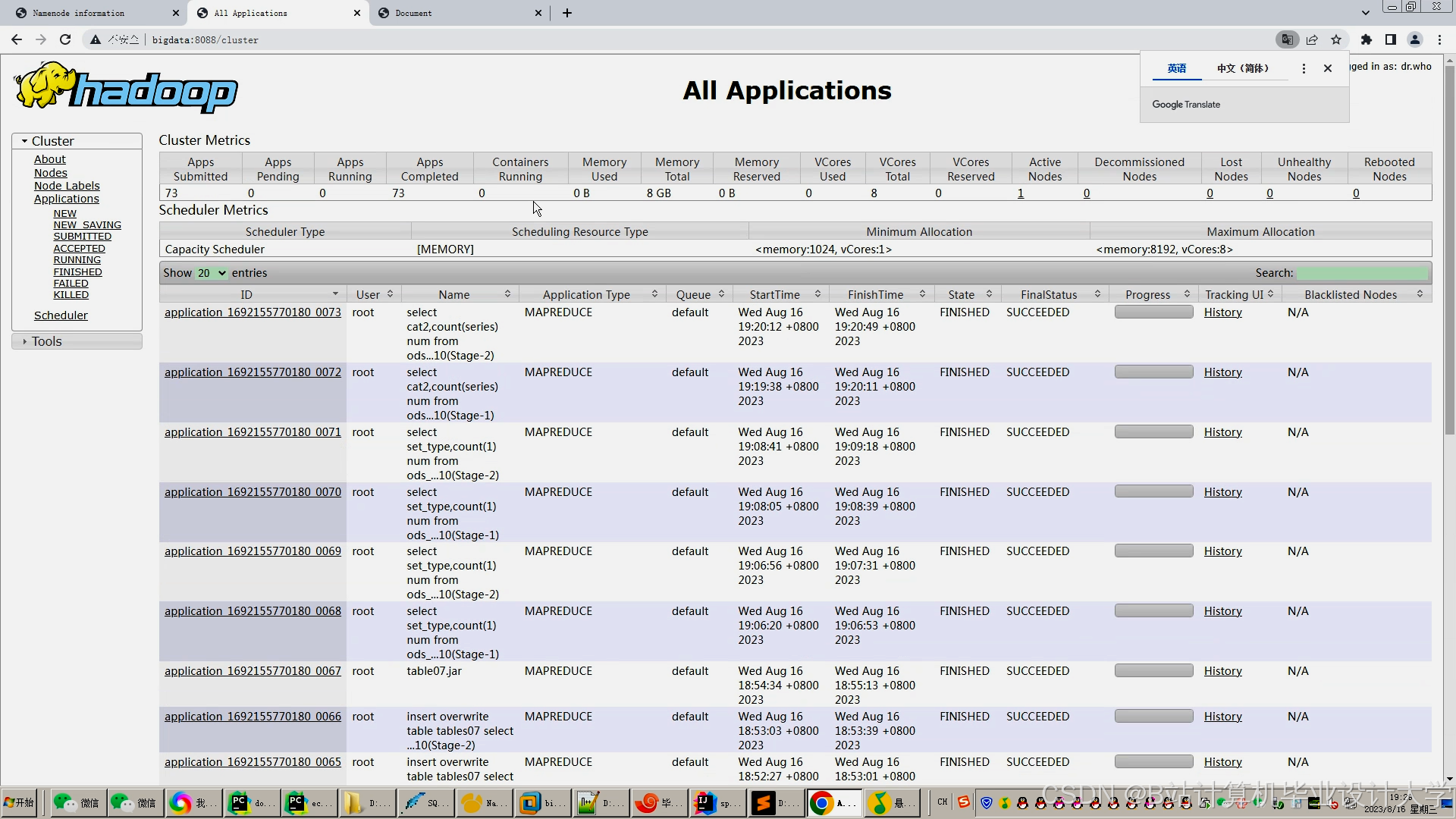
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1853
1853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











