




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive 酒店推荐系统技术说明
一、系统概述
在当今数字化旅游时代,用户面临着海量的酒店信息,难以快速找到符合自身需求的酒店。传统酒店推荐系统受限于数据规模和处理能力,难以提供精准、个性化的推荐。基于 Hadoop+Spark+Hive 的酒店推荐系统应运而生,它整合了 Hadoop 的分布式存储、Spark 的高效计算以及 Hive 的数据仓库功能,能够处理大规模的酒店数据,为用户提供更精准、个性化的酒店推荐服务,提升用户体验和酒店预订转化率。
二、核心技术组件
(一)Hadoop
- HDFS(Hadoop Distributed File System):作为 Hadoop 的分布式文件系统,HDFS 为酒店推荐系统提供了高可靠、高吞吐量的数据存储解决方案。它将酒店相关的各类数据,如用户行为日志(包含用户的浏览、点击、预订等操作记录)、酒店基本信息(酒店名称、地址、价格、评分、设施等)、评论数据等分散存储在多个节点上,避免了单点故障,保障了数据的安全性和可用性。同时,HDFS 的高吞吐量特性使得系统能够快速读取和处理大规模数据。
- YARN(Yet Another Resource Negotiator):YARN 是 Hadoop 的资源管理和调度框架,负责为酒店推荐系统中的各个计算任务分配集群资源。它能够根据任务的优先级、资源需求等因素,动态地分配 CPU、内存等资源,确保各个任务高效执行,提高集群的整体利用率。
(二)Spark
- Spark Core:Spark Core 是 Spark 的核心组件,提供了分布式任务调度、内存计算和容错机制等基础功能。在酒店推荐系统中,Spark Core 可以对存储在 HDFS 上的数据进行快速处理,例如进行数据的清洗、转换和聚合操作。它支持 RDD(弹性分布式数据集)编程模型,使得开发者能够以简洁的方式编写分布式计算程序,提高开发效率。
- Spark SQL:Spark SQL 允许开发者使用 SQL 语句来查询和处理结构化数据。在酒店推荐系统中,Spark SQL 可以与 Hive 集成,方便地对存储在 Hive 中的酒店数据进行查询和分析。它支持多种数据源的访问,如 HDFS、Hive 表等,并且提供了丰富的优化技术,能够提高查询性能。
- Spark Streaming:Spark Streaming 用于处理实时数据流,在酒店推荐系统中可以实时处理用户的最新行为数据,如用户的实时搜索、点击等操作。它支持多种数据源的接入,如 Kafka、Flume 等,能够将实时数据流划分为一系列小的批处理作业进行处理,实现低延迟的实时推荐。
- Spark MLlib:Spark MLlib 是 Spark 的机器学习库,提供了丰富的机器学习算法,如协同过滤算法、分类算法、聚类算法等。在酒店推荐系统中,可以利用 Spark MLlib 中的算法实现酒店推荐功能,例如使用 ALS(交替最小二乘法)协同过滤算法根据用户的历史行为数据为用户推荐酒店。
(三)Hive
Hive 是一个基于 Hadoop 的数据仓库工具,它提供了类似 SQL 的查询语言 HiveQL,使得开发者能够方便地对存储在 HDFS 上的数据进行管理和查询。在酒店推荐系统中,Hive 可以将半结构化或非结构化的酒店数据转换为结构化数据,存储在 Hive 表中,方便后续的数据分析和处理。同时,Hive 支持分区表和分桶表,可以提高查询效率,特别是在处理大规模数据时。
三、系统架构与数据流程
(一)系统架构
- 数据采集层:负责从多个数据源采集酒店相关的数据,如用户行为数据可以通过埋点技术收集用户的浏览、点击、预订等操作记录,并将其发送到 Kafka 或 Flume 等消息队列中;酒店基本信息和评论数据可以从酒店管理系统或第三方数据平台获取,并存储到 HDFS 中。
- 数据存储层:使用 HDFS 存储原始数据,包括用户行为日志、酒店基本信息、评论数据等。同时,利用 Hive 构建数据仓库,对数据进行结构化存储和管理,方便后续的数据分析和查询。
- 数据处理层:采用 Spark 对数据进行清洗、转换、特征提取和模型训练等操作。首先,使用 Spark SQL 对 Hive 中的数据进行清洗和预处理,去除重复数据、填充缺失值、处理异常数据等;然后,提取用户和酒店的特征,构建用户画像和酒店特征模型;最后,利用 Spark MLlib 中的算法进行模型训练,如训练协同过滤模型、深度学习模型等。
- 推荐引擎层:根据训练好的模型和实时用户行为数据,为用户生成个性化的酒店推荐列表。推荐引擎可以结合多种推荐算法,如协同过滤、内容推荐、基于模型的推荐等,以提高推荐的准确性和多样性。
- 应用层:将推荐结果展示给用户,用户可以通过 Web 界面或移动应用查看推荐的酒店信息,并进行预订操作。同时,应用层还可以提供酒店管理功能,如酒店信息维护、用户反馈处理等。
(二)数据流程
- 数据采集:通过各种数据采集工具和技术,将酒店相关的数据采集到系统中,并存储到 Kafka 或 Flume 等消息队列中,等待后续处理。
- 数据存储:将消息队列中的数据写入 HDFS,同时使用 Hive 创建相应的表结构,将数据导入到 Hive 表中,进行结构化存储。
- 数据清洗与预处理:使用 Spark SQL 对 Hive 表中的数据进行清洗和预处理,去除噪声数据和无效数据,对数据进行标准化和归一化处理,为后续的特征提取和模型训练做好准备。
- 特征工程:从清洗后的数据中提取用户和酒店的特征,如用户的历史行为特征(点击频次、停留时间、预订记录等)、偏好特征(酒店类型、价格区间、地理位置等),酒店的特征(评分、价格、设施、服务质量等),并将这些特征进行组合和转换,构建用户画像和酒店特征模型。
- 模型训练:利用 Spark MLlib 中的算法,如 ALS 协同过滤算法、LSTM 深度学习模型等,对用户和酒店的特征数据进行训练,生成推荐模型。在训练过程中,可以使用交叉验证等方法评估模型的性能,并进行参数调优,以提高模型的准确性和泛化能力。
- 实时推荐:当用户产生新的行为数据时,Spark Streaming 实时捕获这些数据,并结合训练好的推荐模型,为用户生成实时的酒店推荐列表。推荐结果可以存储到 Redis 等缓存系统中,以便快速响应用户的请求。
- 推荐结果展示:将推荐结果展示给用户,用户可以根据推荐结果选择合适的酒店进行预订。同时,收集用户的反馈信息,如对推荐结果的满意度、是否预订等,用于后续的模型优化和推荐策略调整。
四、关键技术实现
(一)数据清洗与预处理
- 去除重复数据:使用 Spark 的去重操作,如
distinct()方法,去除用户行为日志和酒店信息中的重复记录。 - 填充缺失值:对于缺失的数据,可以根据数据的分布和业务逻辑,采用均值填充、中位数填充、众数填充或基于模型的填充方法进行处理。例如,对于酒店价格字段的缺失值,可以根据同类型酒店的平均价格进行填充。
- 处理异常数据:识别并处理数据中的异常值,如价格超出合理范围、评分过高或过低等。可以使用统计方法(如箱线图)或基于规则的方法来检测异常值,并进行相应的处理,如删除或修正。
- 数据标准化和归一化:对数值型特征进行标准化和归一化处理,使其具有相同的尺度,避免某些特征对模型的影响过大。常用的标准化方法有 Z-score 标准化,归一化方法有 Min-Max 归一化。
(二)特征提取与构建
- 用户特征提取:从用户行为日志中提取用户的历史行为特征,如用户的点击次数、停留时间、预订次数等;根据用户的预订记录和偏好设置,提取用户的偏好特征,如偏好的酒店类型、价格区间、地理位置等。
- 酒店特征提取:从酒店基本信息中提取酒店的特征,如酒店的评分、价格、设施数量、服务质量评分等;结合酒店的地理位置信息,提取酒店的周边设施特征,如距离景点、交通枢纽的距离等。
- 特征组合与转换:将提取的用户和酒店特征进行组合和转换,构建更有意义的特征。例如,可以计算用户对某类酒店的偏好程度,将用户的偏好特征和酒店的特征进行交叉组合,生成新的特征。
(三)推荐算法实现
- 协同过滤算法:使用 Spark MLlib 中的 ALS 算法实现协同过滤推荐。ALS 算法通过将用户—酒店交互矩阵分解为用户潜在因子矩阵和酒店潜在因子矩阵,然后根据潜在因子的相似性进行推荐。在实现过程中,需要设置合适的潜在因子维度、正则化参数和迭代次数等超参数,并通过交叉验证等方法进行参数调优。
- 深度学习算法:采用 LSTM 深度学习模型处理用户的历史行为序列,捕捉用户行为的长期依赖关系。将用户的历史行为序列作为输入,使用 Spark 的深度学习库(如 TensorFlowOnSpark)进行模型训练。在训练过程中,需要调整网络结构、学习率、批次大小等超参数,以提高模型的性能。
- 混合推荐算法:结合协同过滤算法和深度学习算法的优点,采用加权融合或级联融合的方式实现混合推荐。根据两种算法在不同场景下的表现,为它们分配不同的权重,或者先使用一种算法生成初步的推荐列表,再使用另一种算法对推荐列表进行优化。
五、系统优化策略
(一)性能优化
- 数据分区与分桶:在 Hive 中对数据进行合理的分区和分桶,根据查询需求选择合适的分区字段和分桶策略,提高查询效率。例如,按照时间、地理位置等字段对酒店数据进行分区,按照酒店类型等字段进行分桶。
- 缓存机制:使用 Redis 等缓存系统缓存热门推荐结果和常用数据,减少对 HDFS 和 Hive 的查询次数,降低系统响应时间。在系统启动时,可以将常用的推荐结果加载到缓存中,实现缓存预热。
- 并行计算优化:合理设置 Spark 的并行度,根据集群资源和数据规模调整 Executor 的数量和内存分配,提高并行计算效率。同时,优化 Spark 作业的调度和执行计划,减少数据 shuffle 和序列化开销。
(二)算法优化
- 模型压缩与量化:对于深度学习模型,采用模型压缩和量化技术,减少模型的存储空间和计算量,提高模型的推理速度。例如,使用剪枝、量化等方法对模型进行优化。
- 增量学习:采用增量学习的方式更新推荐模型,当有新的数据产生时,只对模型进行局部更新,而不是重新训练整个模型,提高模型的更新效率。
(三)容错与恢复
- 数据备份与恢复:定期对 HDFS 上的数据进行备份,防止数据丢失。当数据出现损坏或丢失时,能够及时从备份中恢复数据。
- 任务容错:利用 Spark 和 Hadoop 的容错机制,当计算任务出现故障时,能够自动重新调度任务,确保任务的顺利完成。
六、总结
基于 Hadoop+Spark+Hive 的酒店推荐系统通过整合分布式存储、高效计算和数据仓库技术,能够处理大规模的酒店数据,实现精准、个性化的酒店推荐。在系统实现过程中,需要关注数据清洗与预处理、特征提取与构建、推荐算法实现等关键技术环节,并采取性能优化、算法优化和容错与恢复等策略,提高系统的性能和可靠性。未来,随着技术的不断发展,酒店推荐系统可以进一步融合多模态数据、强化学习等技术,为用户提供更加智能、个性化的推荐服务。
运行截图
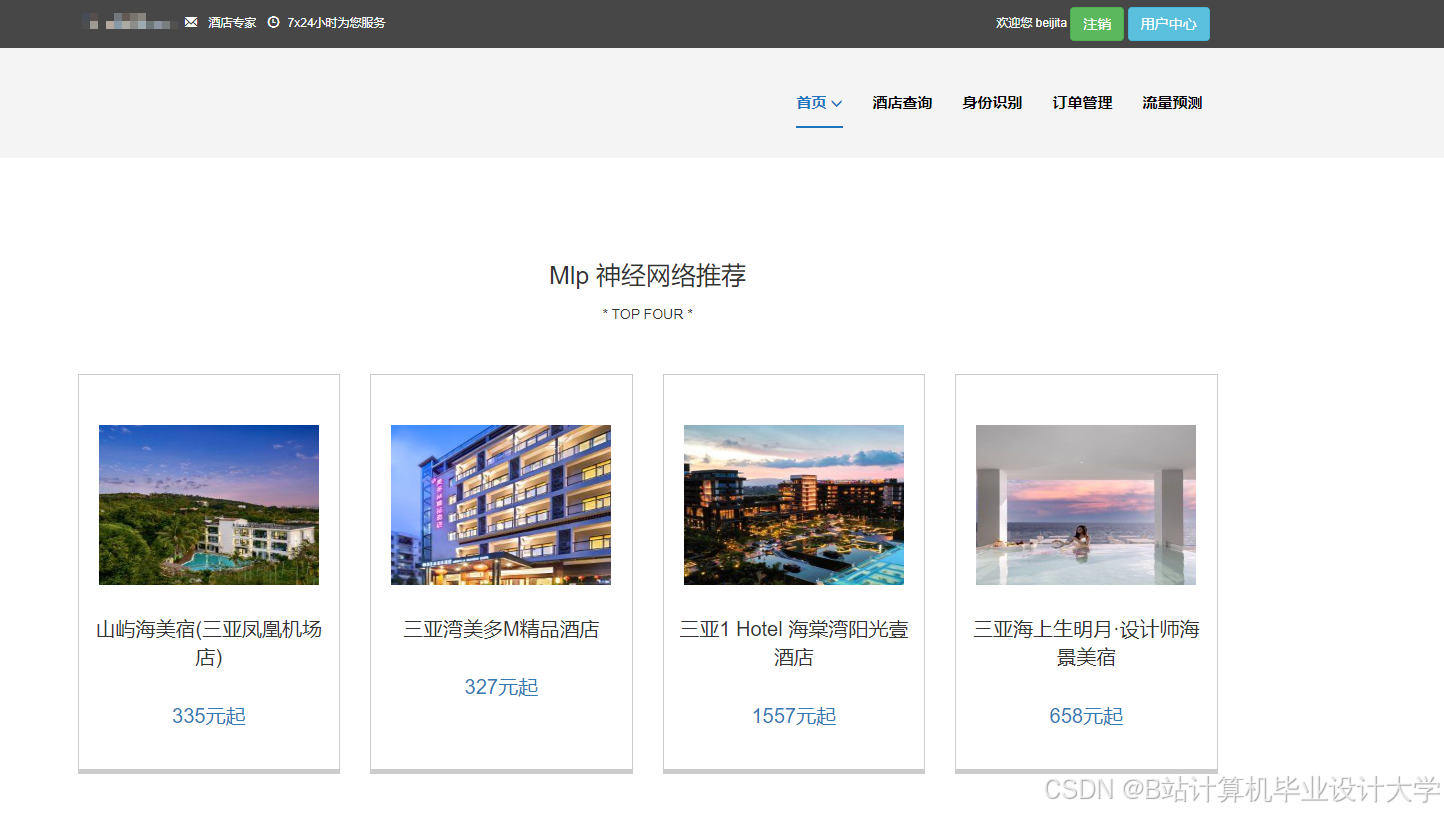
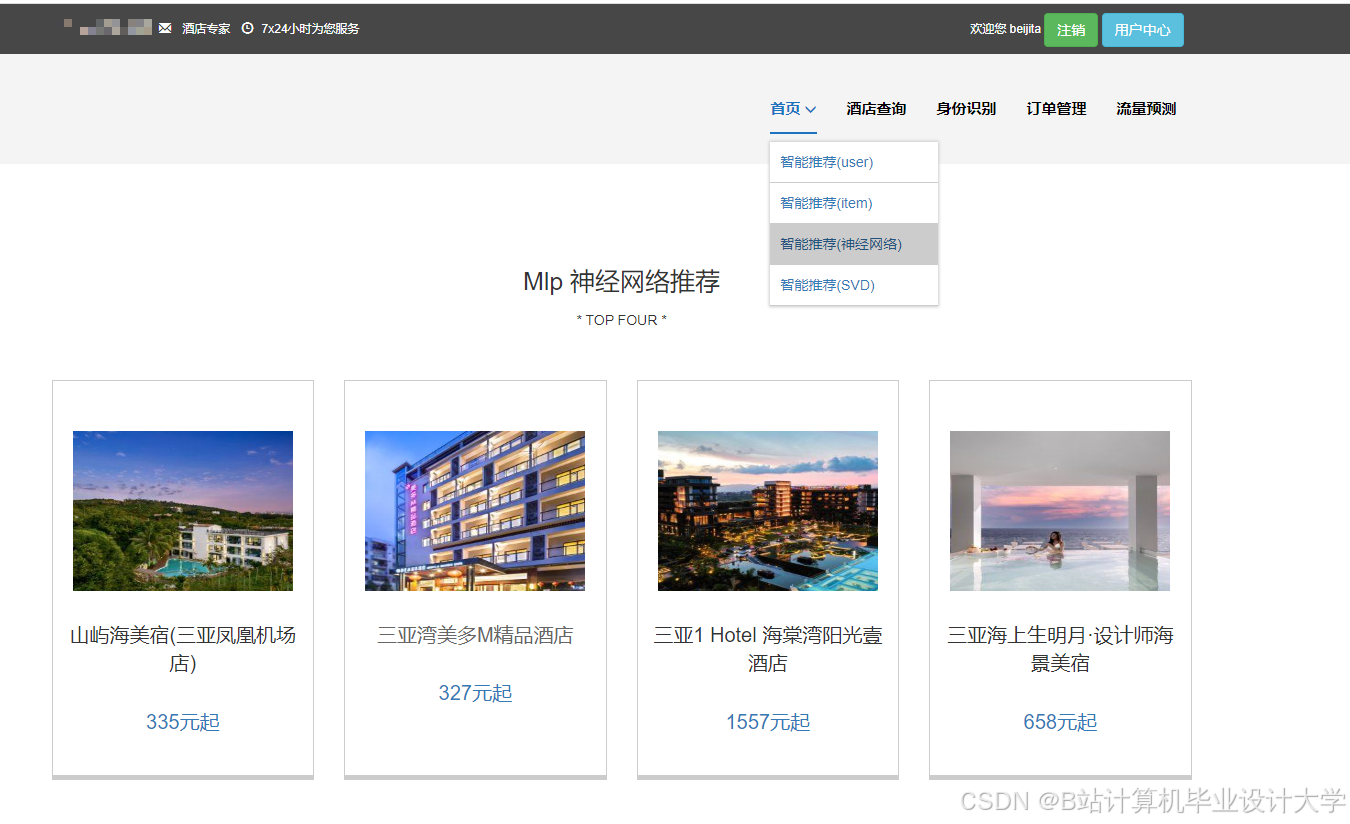
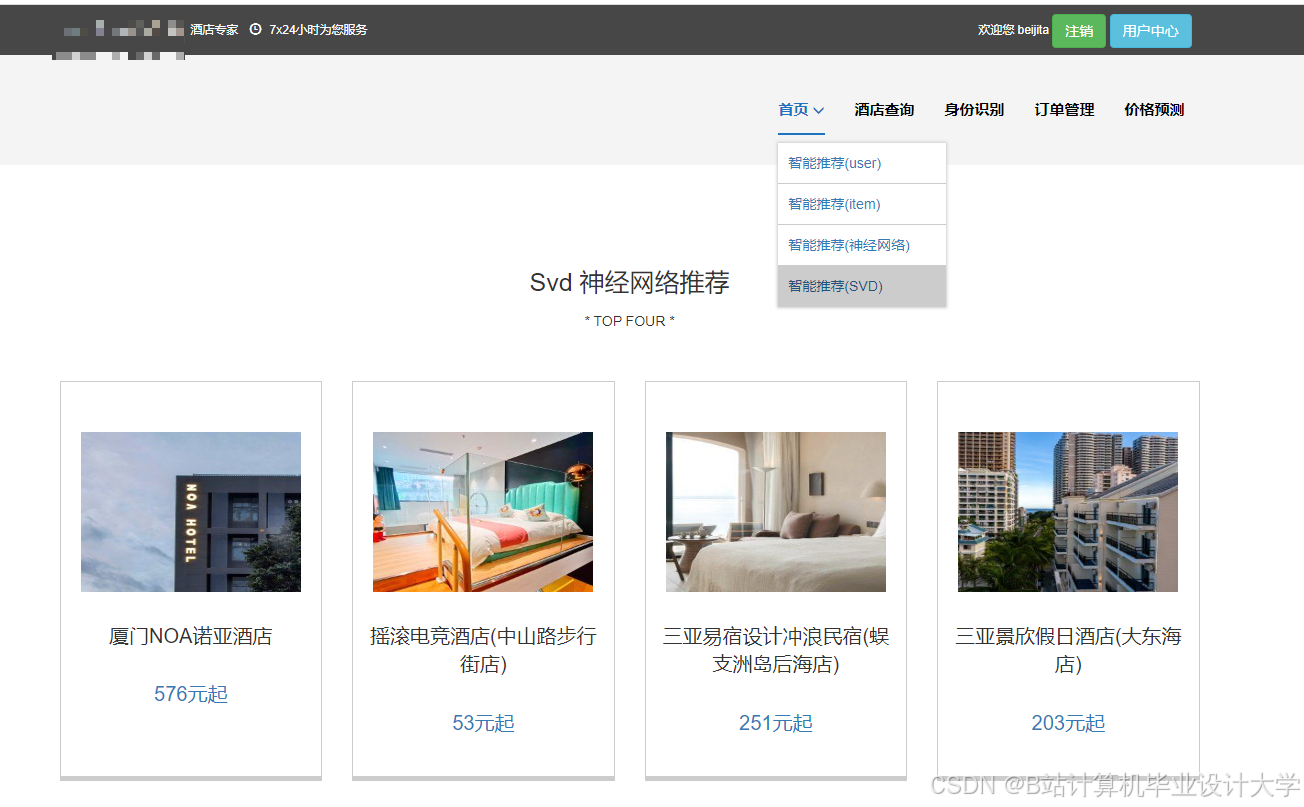
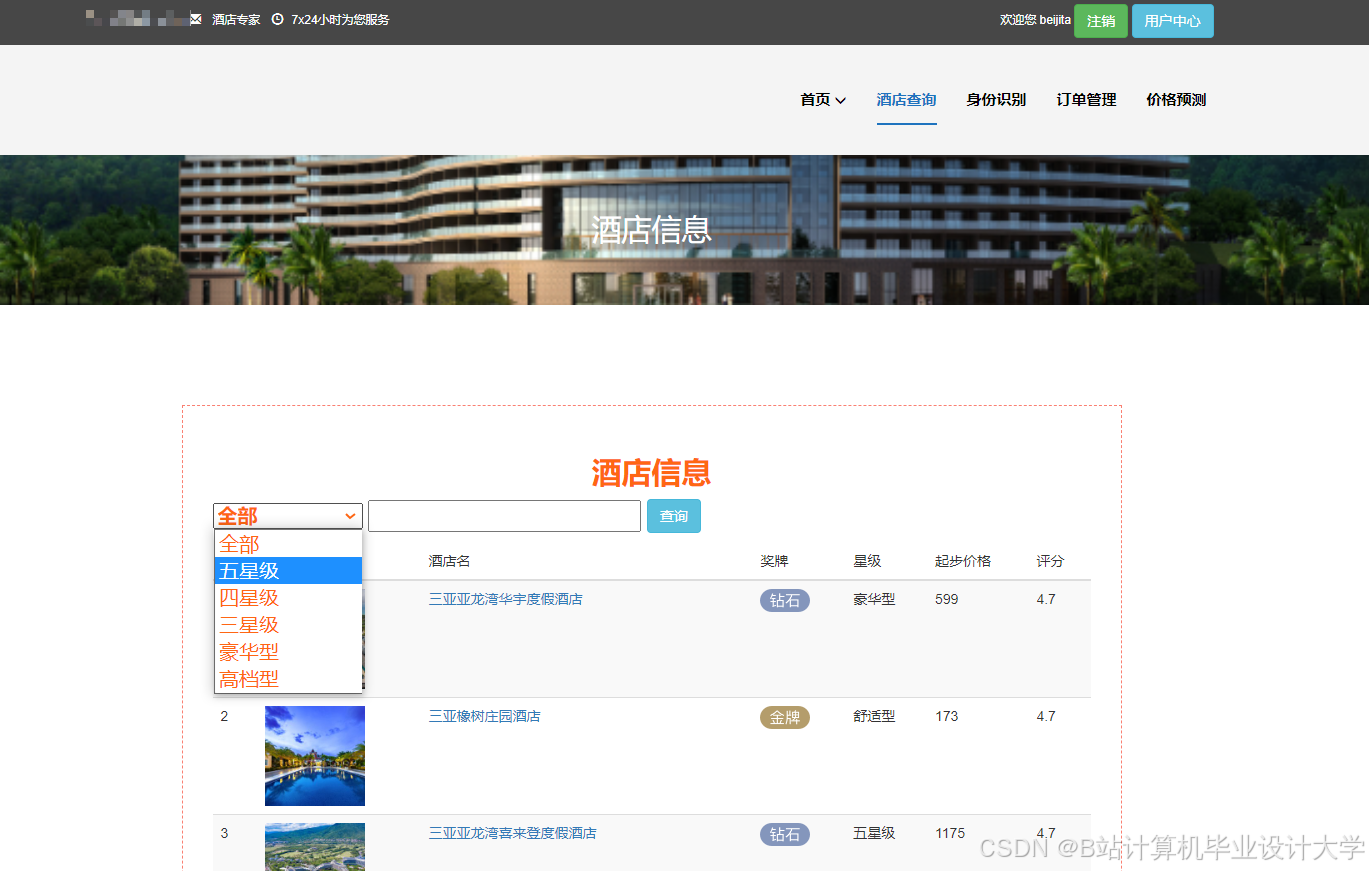
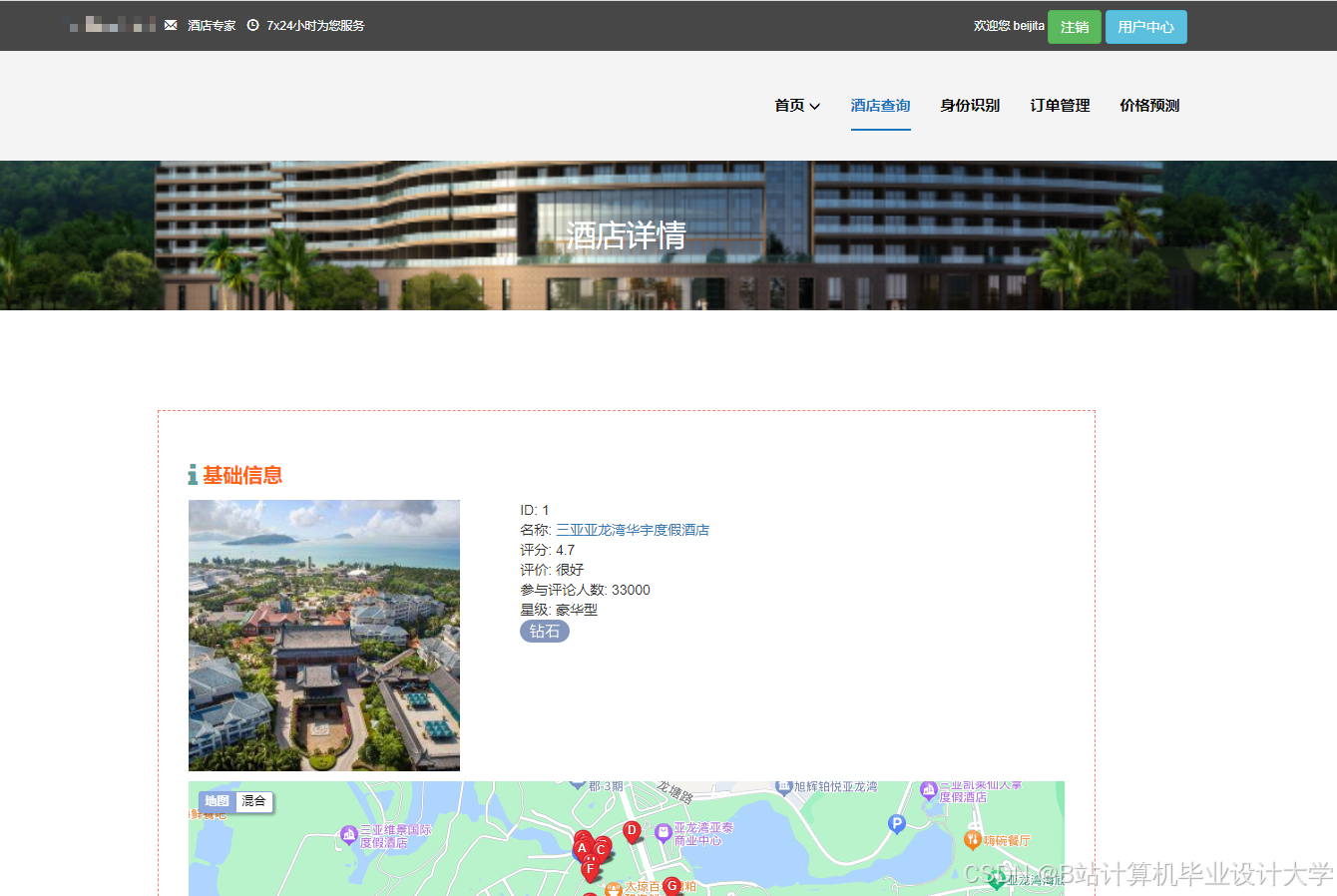
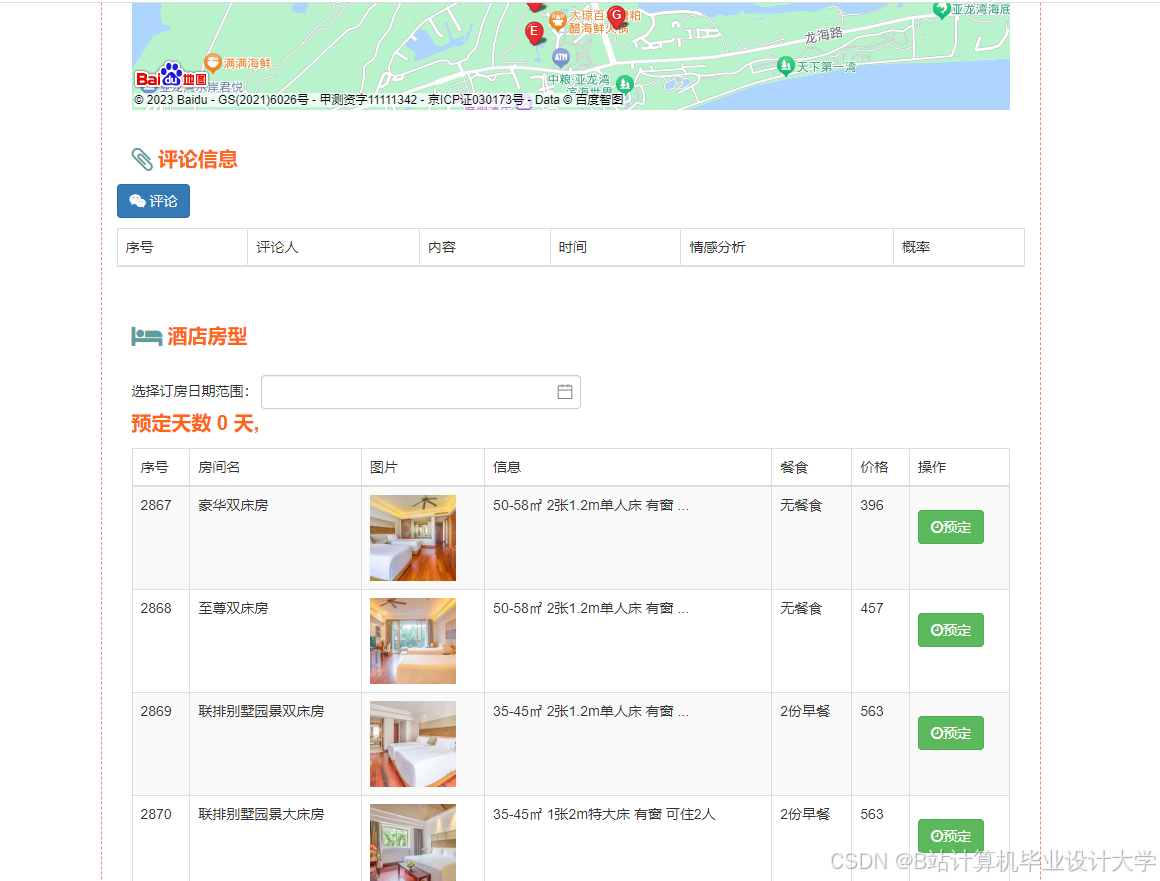
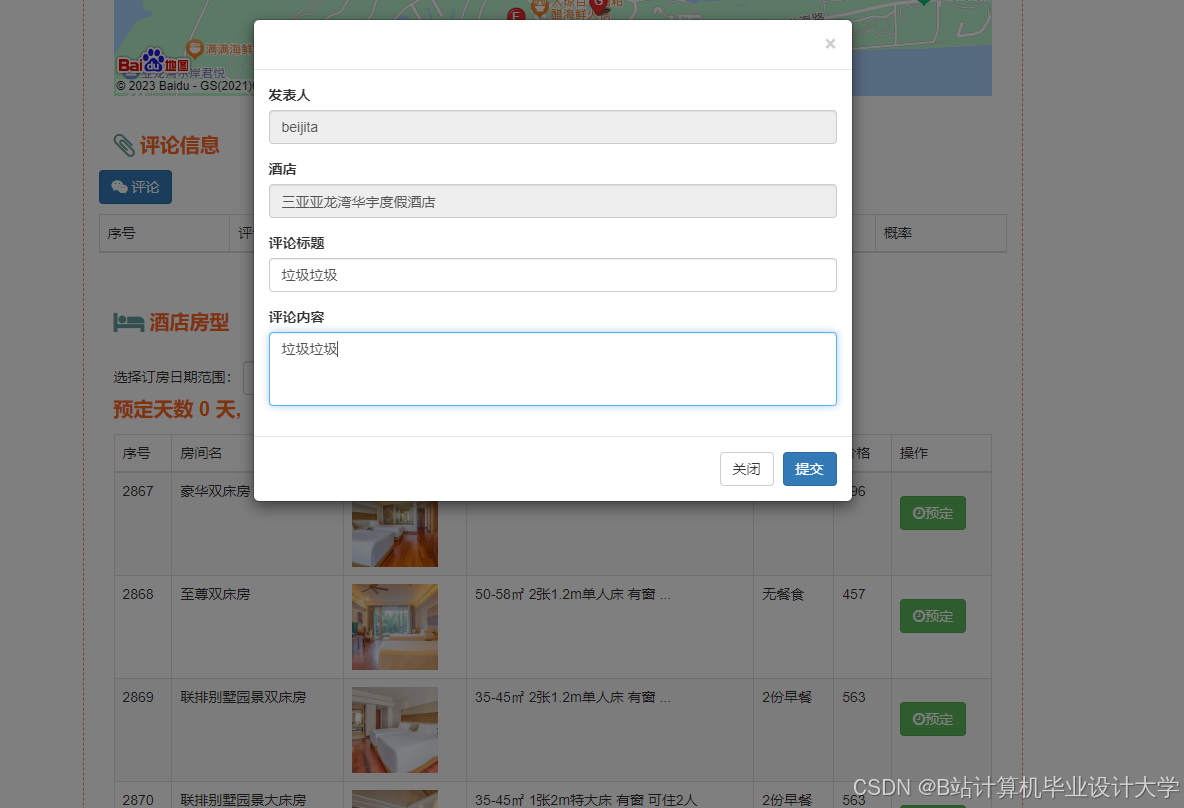
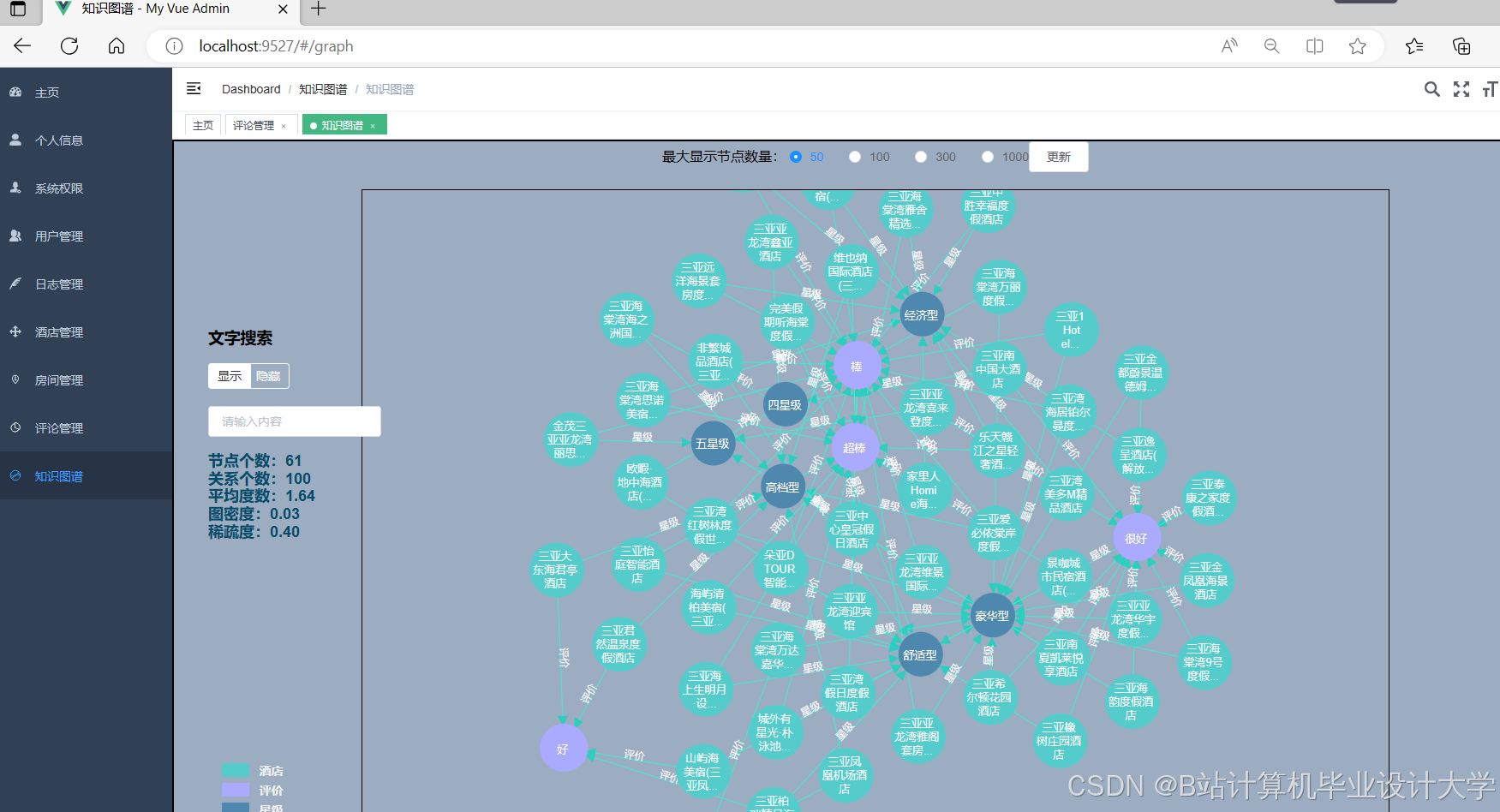
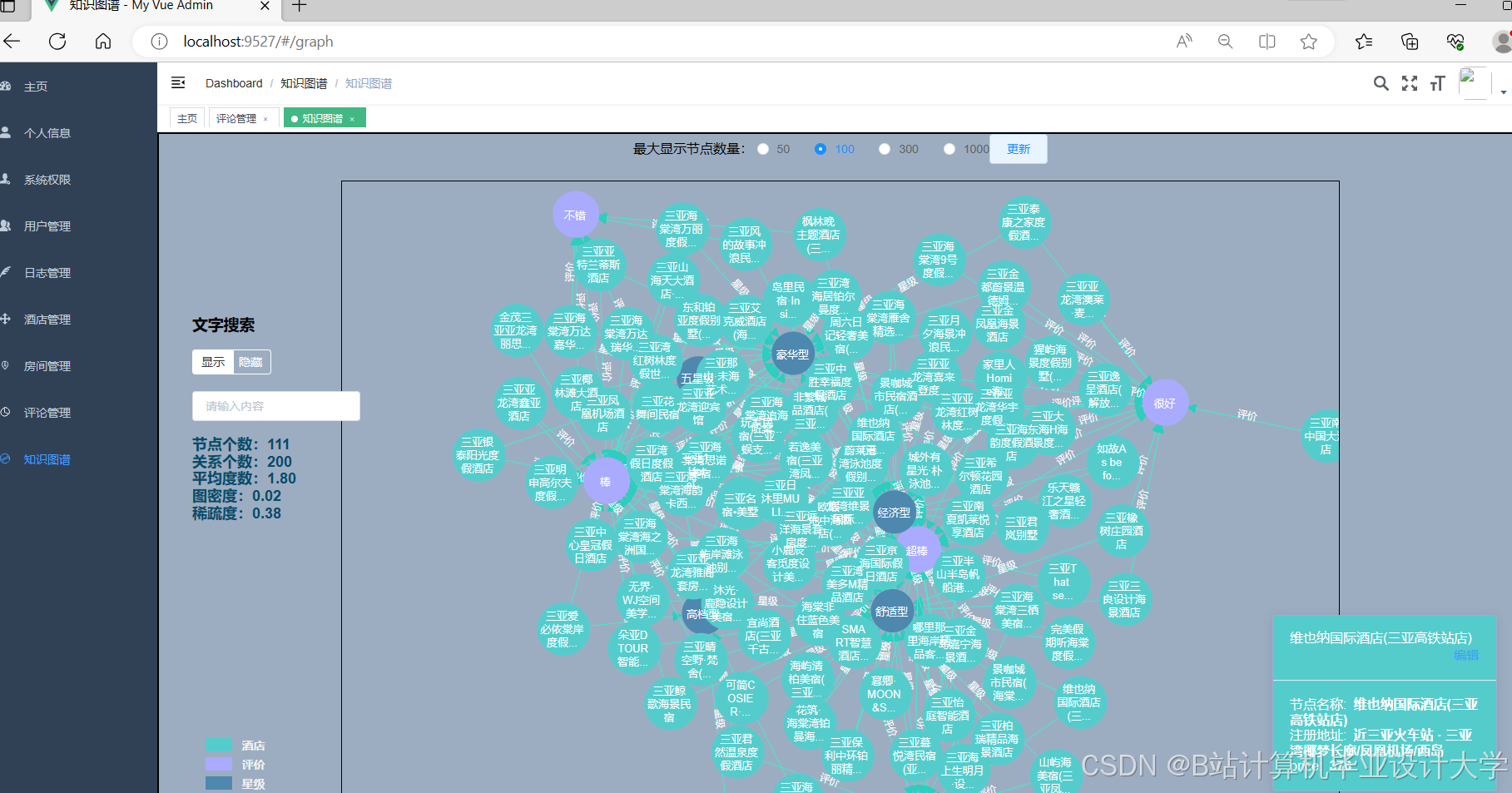
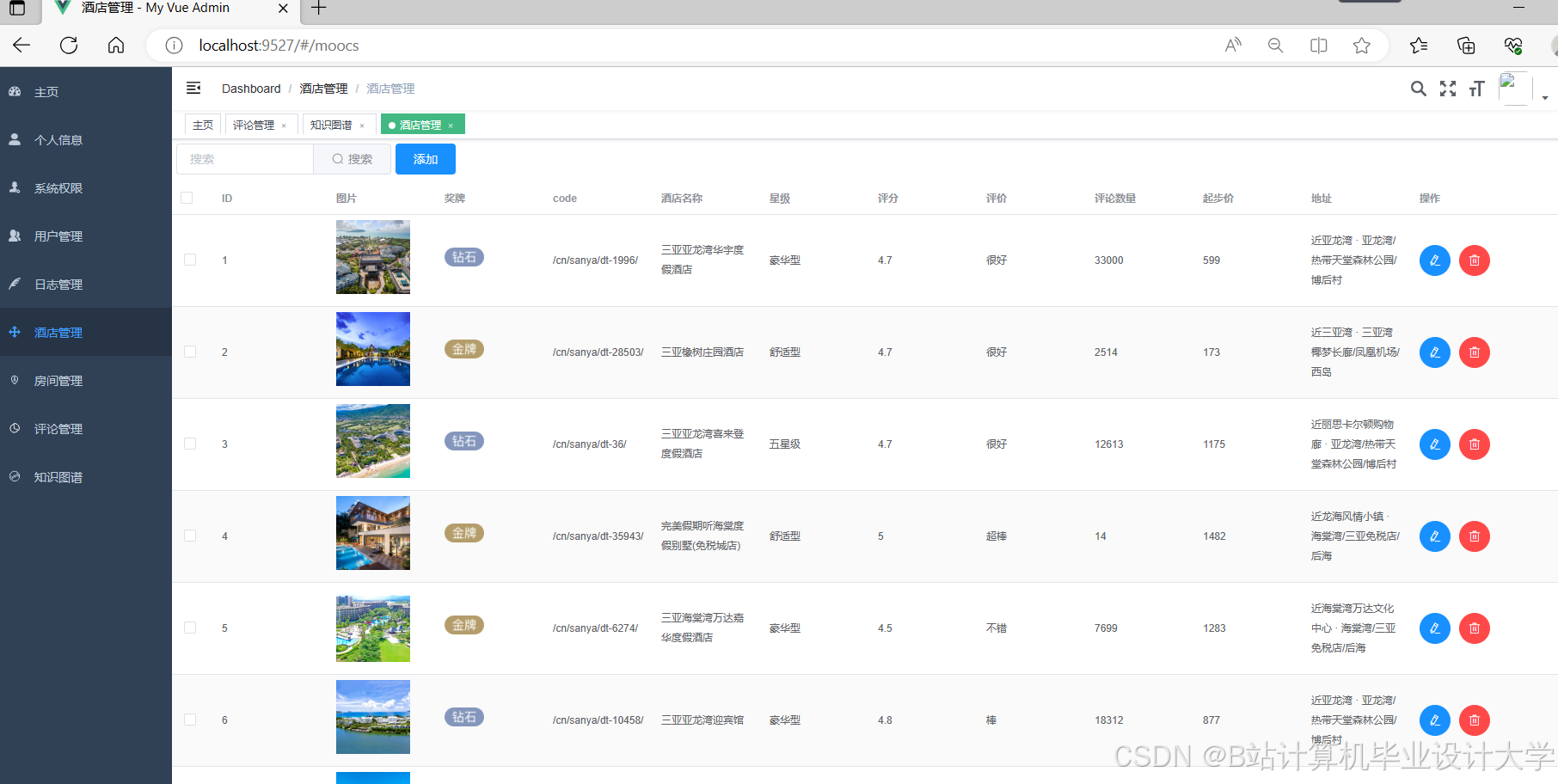

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











