




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python深度学习股票行情分析预测与量化交易分析技术说明
一、引言
股票市场行情复杂多变,受宏观经济、公司运营、市场情绪等多重因素影响,传统分析方法在精准预测和有效交易方面存在局限。深度学习凭借强大的非线性拟合与特征学习能力,能挖掘数据潜在规律,为股票行情分析和量化交易提供新途径。Python作为高效编程语言,拥有丰富深度学习库,便于实现相关模型与策略。本技术说明旨在阐述利用Python深度学习进行股票行情分析预测及量化交易的技术流程与方法。
二、技术架构与工具
(一)技术架构
整体技术架构涵盖数据获取、预处理、模型构建与训练、量化交易策略设计及回测等环节。各环节紧密相连,数据是基础,模型是核心,策略是应用,回测是验证。
(二)关键工具
- 数据获取:使用Tushare、AKShare等金融数据接口,可获取股票历史行情、宏观经济、公司财务等多维度数据。
- 深度学习框架:TensorFlow功能强大且灵活,支持分布式训练;PyTorch动态计算图便于快速实验;Keras作为高级API,可简化模型构建流程。
- 量化交易框架:Backtrader提供丰富的策略开发工具和回测功能;Zipline具有简洁的API和良好的可扩展性。
三、数据收集与预处理
(一)数据收集
- 股票行情数据:获取开盘价、收盘价、最高价、最低价、成交量等,时间粒度可根据需求选择,如15分钟、日线等。
- 辅助数据:收集宏观经济数据(GDP增长率、通货膨胀率等)、公司财务数据(市盈率、市净率、净利润等)以及舆情数据(新闻情感分析、社交媒体热度等)。
(二)数据预处理
- 缺失值处理:对于少量缺失值,可采用均值、中位数填充;若缺失值较多,可考虑删除该记录或使用插值法。例如,某股票某日成交量缺失,可用该股票过去一周成交量的平均值填充。
- 异常值检测与修正:利用3σ原则、箱线图法识别异常值,根据业务逻辑修正或删除。如某股票某日收盘价远超正常波动范围,可视为异常值,用相邻几天收盘价的平均值修正。
- 数据标准化/归一化:采用Z-score标准化将数据转换为均值为0、标准差为1的分布;或使用Min-Max归一化将数据缩放到[0, 1]区间,以消除不同特征量纲影响。
(三)特征工程
- 技术指标计算:计算移动平均线(MA)、相对强弱指标(RSI)、随机指标(KDJ)等,反映股票价格趋势和超买超卖情况。例如,5日均线反映短期趋势,20日均线反映中期趋势。
- 时间序列特征提取:计算价格变化率、波动率等,捕捉股票价格短期波动特征。如计算某股票过去一周的日变化率,了解其短期涨跌情况。
- 特征融合:将股票行情数据、宏观经济数据、公司财务数据等进行融合,构建更全面的特征集。例如,当宏观经济处于扩张期时,某些行业股票可能受益,将宏观经济指标与行业股票数据融合,提高模型预测准确性。
四、深度学习模型构建与训练
(一)模型选择
- LSTM(长短期记忆网络):通过门控机制解决传统RNN的梯度消失问题,能处理长序列数据并捕捉长期依赖关系,适用于股票行情这种具有时间序列特性的数据。
- GRU(门控循环单元):结构简化,参数数量减少,计算效率更高,同时能有效捕捉时间序列长期依赖,在股票行情预测中也有良好表现。
- CNN(卷积神经网络):通过一维卷积操作提取时间序列特征,在处理多变量股票行情数据时能发现局部模式。
- Transformer:通过自注意力机制捕捉数据长程依赖关系,在处理大规模多变量股票行情数据时具有优势。
(二)模型构建
以PyTorch为例,构建LSTM模型代码如下:
python
import torch | |
import torch.nn as nn | |
class LSTMModel(nn.Module): | |
def __init__(self, input_size, hidden_size, num_layers, output_size): | |
super(LSTMModel, self).__init__() | |
self.hidden_size = hidden_size | |
self.num_layers = num_layers | |
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True) | |
self.fc = nn.Linear(hidden_size, output_size) | |
def forward(self, x): | |
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device) | |
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device) | |
out, _ = self.lstm(x, (h0, c0)) | |
out = self.fc(out[:, -1, :]) | |
return out |
(三)模型训练
- 数据划分:将数据划分为训练集、验证集和测试集,比例通常为7:1.5:1.5。
- 损失函数与优化器:选择均方误差(MSE)作为损失函数,衡量预测值与实际值差异;使用Adam优化器调整模型参数。
- 训练过程:设置训练轮数(epochs)和批量大小(batch_size),在训练过程中使用验证集监控模型性能,采用早停法防止过拟合。
python
import torch.optim as optim | |
# 假设数据已准备好 | |
input_size = 10 # 特征维度 | |
hidden_size = 64 | |
num_layers = 2 | |
output_size = 1 | |
model = LSTMModel(input_size, hidden_size, num_layers, output_size) | |
criterion = nn.MSELoss() | |
optimizer = optim.Adam(model.parameters(), lr=0.001) | |
num_epochs = 100 | |
batch_size = 32 | |
for epoch in range(num_epochs): | |
for i in range(0, len(train_X), batch_size): | |
inputs = torch.tensor(train_X[i:i + batch_size], dtype=torch.float32) | |
labels = torch.tensor(train_y[i:i + batch_size], dtype=torch.float32) | |
optimizer.zero_grad() | |
outputs = model(inputs) | |
loss = criterion(outputs, labels) | |
loss.backward() | |
optimizer.step() | |
# 验证集评估 | |
model.eval() | |
with torch.no_grad(): | |
val_outputs = model(torch.tensor(val_X, dtype=torch.float32)) | |
val_loss = criterion(val_outputs, torch.tensor(val_y, dtype=torch.float32)) | |
print(f'Epoch [{epoch + 1}/{num_epochs}], Validation Loss: {val_loss.item():.4f}') |
五、量化交易策略设计与回测
(一)交易信号生成
- 阈值法:设定价格涨幅和跌幅阈值,当预测价格涨幅超过阈值时生成买入信号,跌幅超过阈值时生成卖出信号。例如,设定涨幅阈值为2%,跌幅阈值为1.5%。
- 动量策略:结合价格趋势与技术指标生成买卖信号。如当价格趋势向上且RSI指标超过70时,生成卖出信号;当价格趋势向下且RSI指标低于30时,生成买入信号。
(二)策略回测
- 回测框架使用:以Backtrader为例,加载数据、策略,设置初始资金、手续费等参数进行回测。
python
import backtrader as bt | |
class StrategyWithDL(bt.Strategy): | |
params = (('threshold', 0.02),) | |
def __init__(self): | |
self.model = load_pretrained_model() # 加载预训练模型 | |
self.data_buffer = [] | |
def next(self): | |
self.data_buffer.append(self.datas[0].close[0]) | |
if len(self.data_buffer) > 200: # 假设使用200个数据点进行预测 | |
input_data = torch.tensor([self.data_buffer[-200:]], dtype=torch.float32) | |
pred = self.model(input_data).item() | |
if pred > self.params.threshold: | |
self.buy() | |
elif pred < -self.params.threshold: | |
self.close() | |
cerebro = bt.Cerebro() | |
data = bt.feeds.YahooFinanceData(dataname='AAPL', fromdate=datetime(2020, 1, 1), todate=datetime(2024, 1, 1)) | |
cerebro.adddata(data) | |
cerebro.addstrategy(StrategyWithDL) | |
cerebro.run() | |
cerebro.plot() |
- 参数优化:通过网格搜索或贝叶斯优化调整策略参数,如阈值、持仓周期等,提升策略性能。
(三)风险管理
- 动态止损:基于ATR指标设置自适应止盈止损线,根据市场波动自动调整止盈止损价位。
- 仓位管理:采用凯利准则优化仓位比例,控制风险并最大化收益。
- 流动性控制:使用VWAP算法拆分大额订单,减少对市场价格的冲击。
六、系统部署与监控
(一)系统部署
将训练好的模型和量化交易策略部署到服务器或云平台上,确保系统稳定运行。可采用Docker容器化技术,方便部署和管理。
(二)实时监控
建立监控系统,实时监测模型预测结果、交易执行情况和市场动态。设置预警机制,当出现异常情况时及时通知相关人员。
七、总结
本技术说明详细阐述了利用Python深度学习进行股票行情分析预测与量化交易的技术流程。通过合理的数据收集与预处理、模型构建与训练、策略设计与回测,以及有效的风险管理和系统部署,可构建一个基于数据驱动的股票量化交易系统。然而,股票市场具有不确定性,模型和策略需不断优化和调整,以适应市场变化。
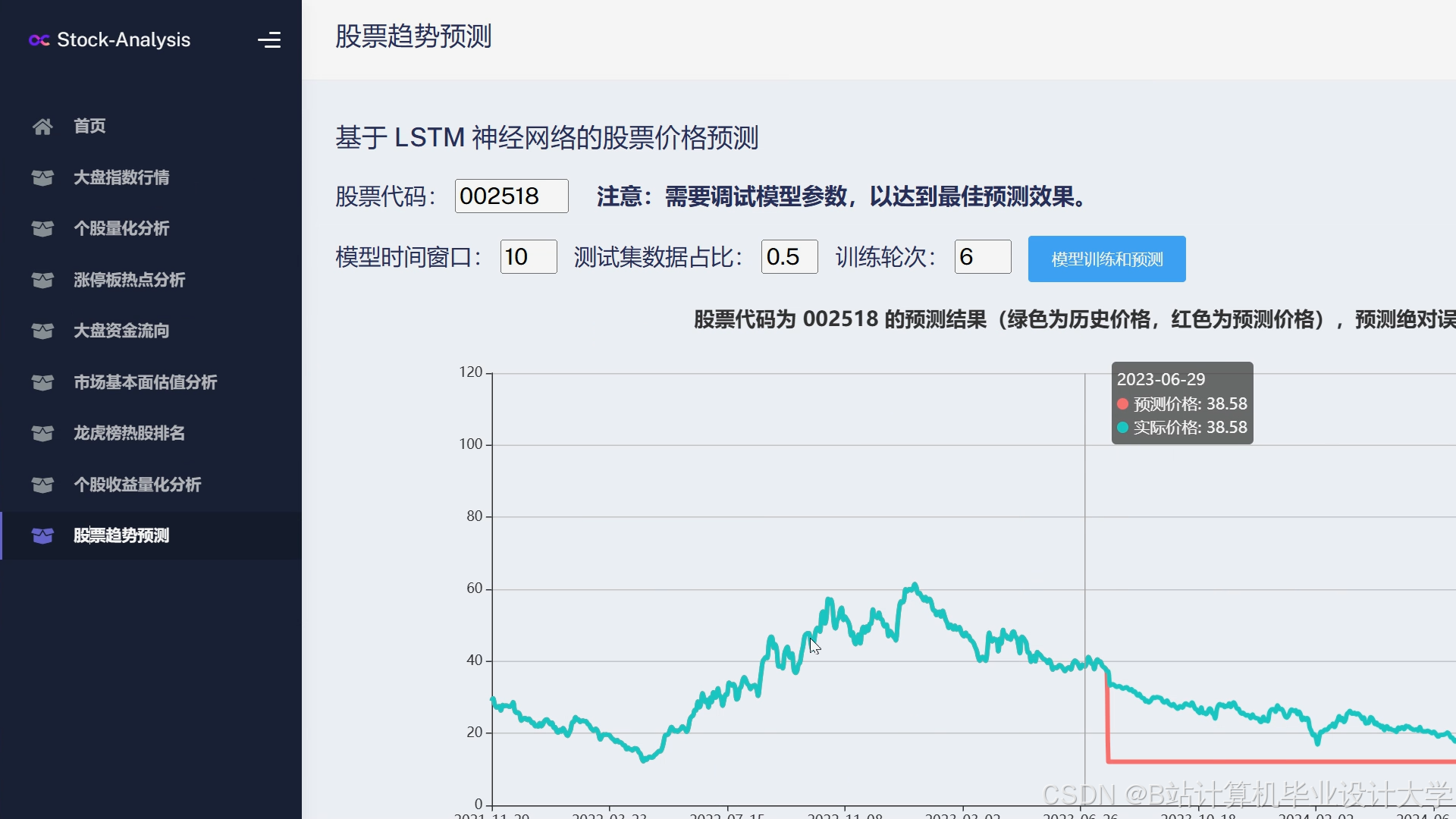
运行截图
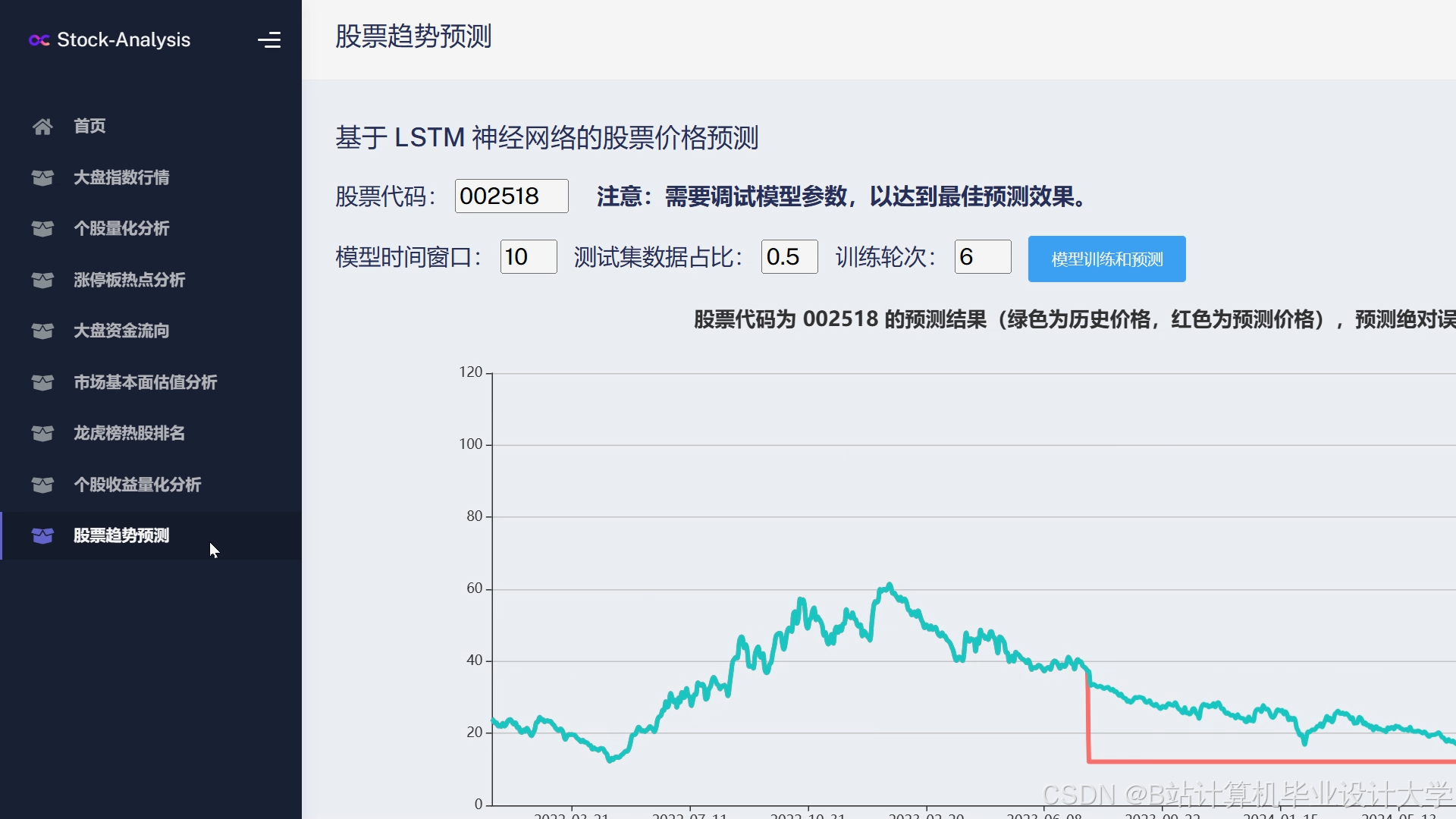

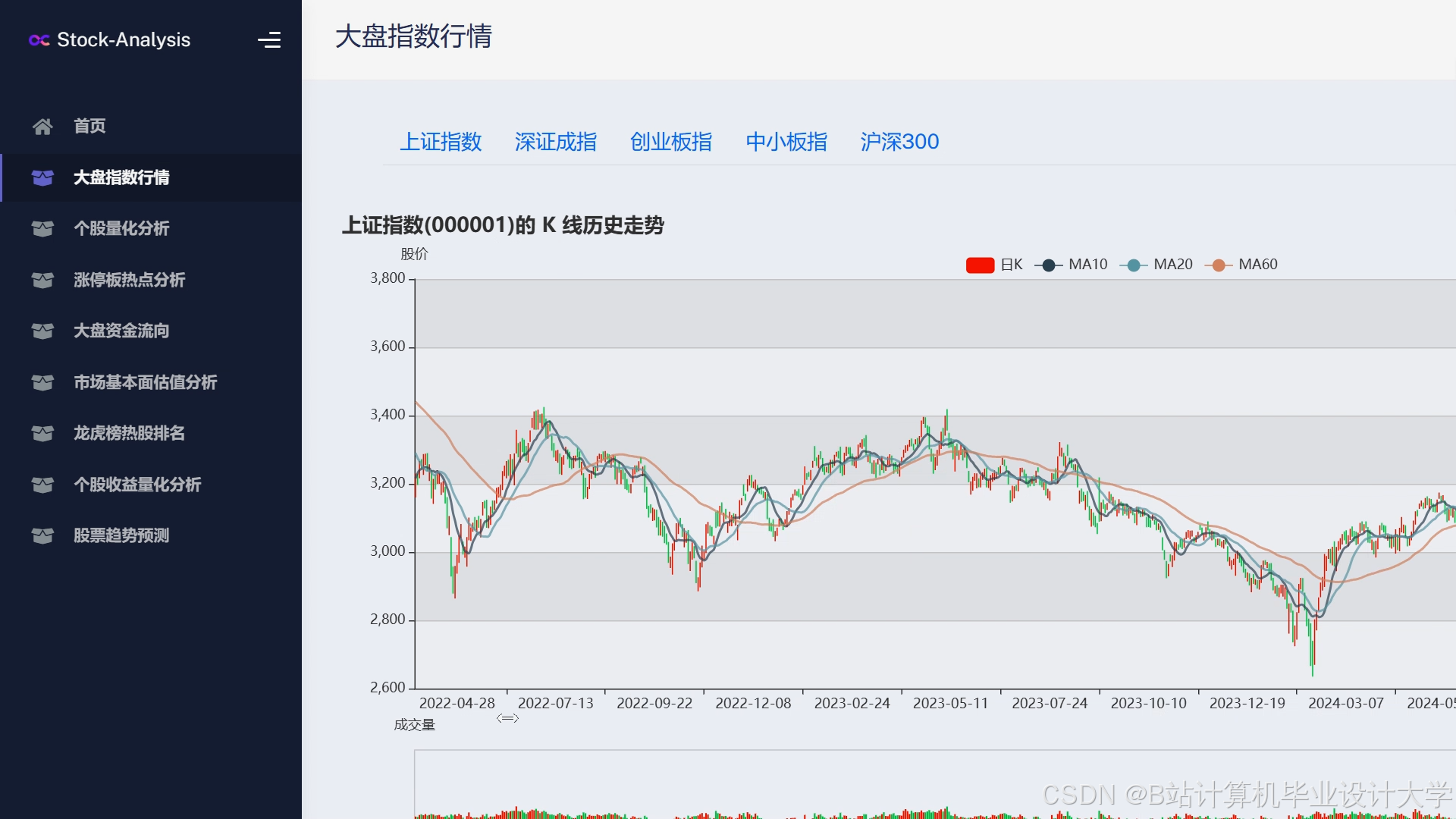
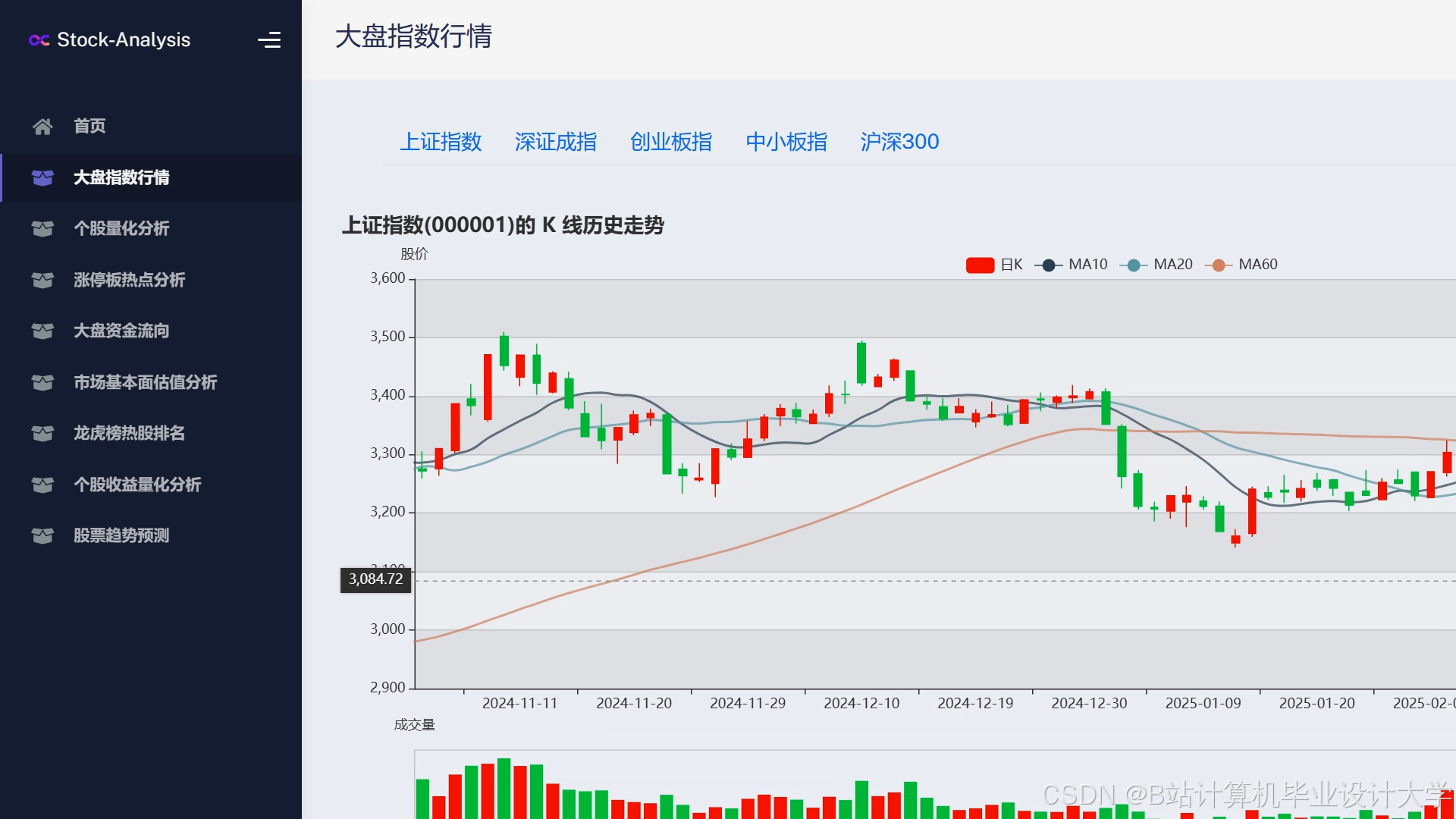
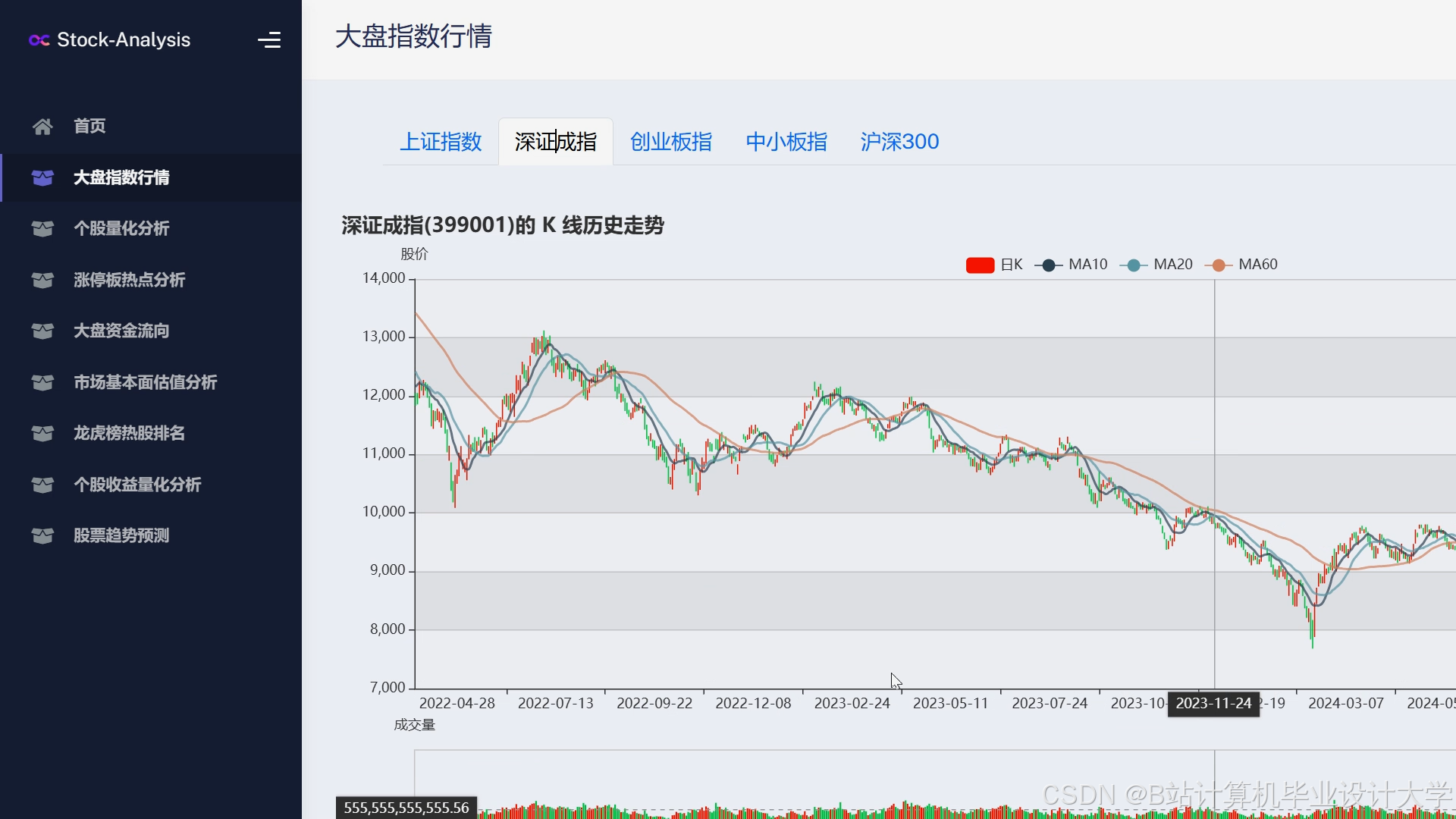
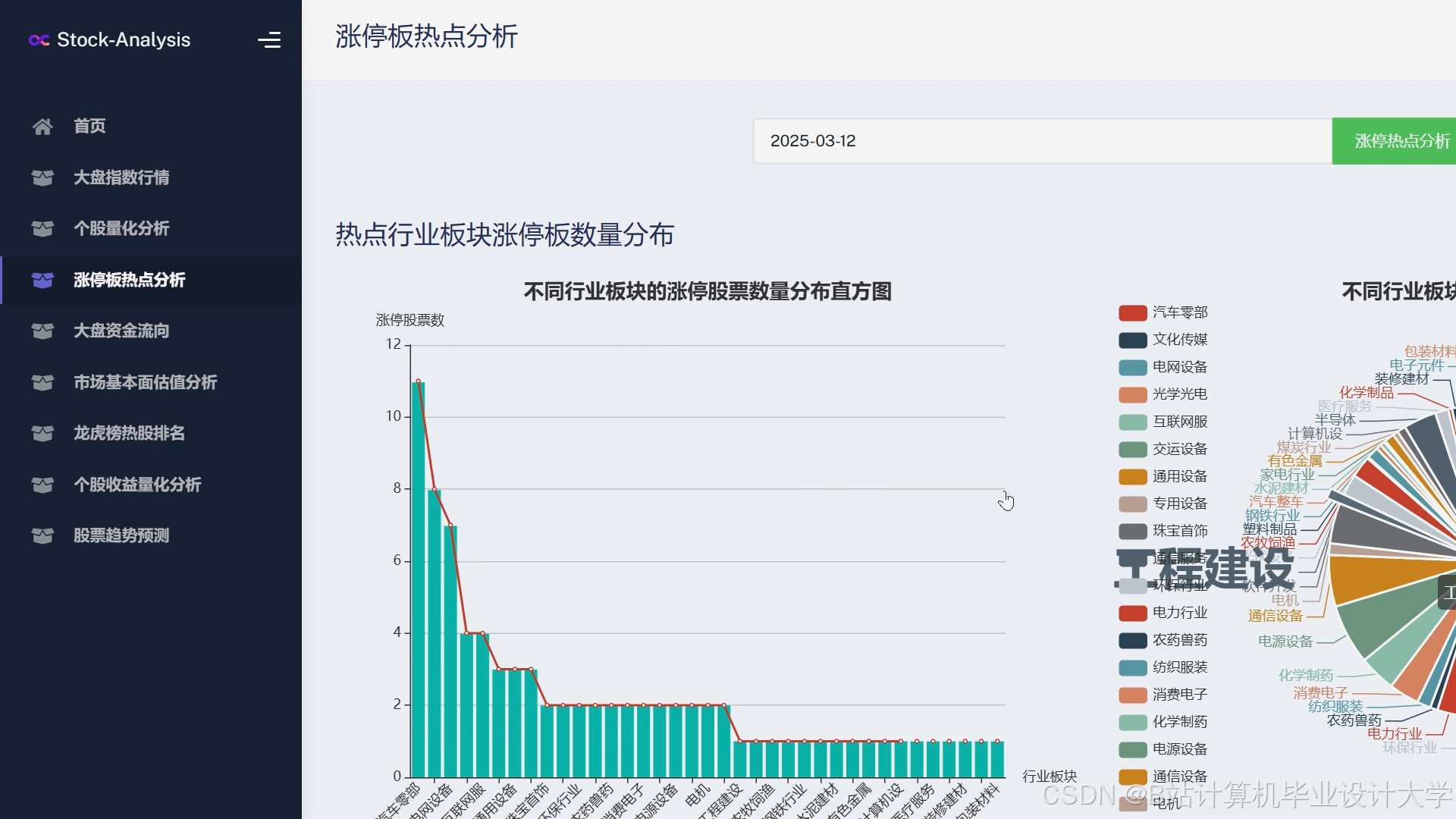
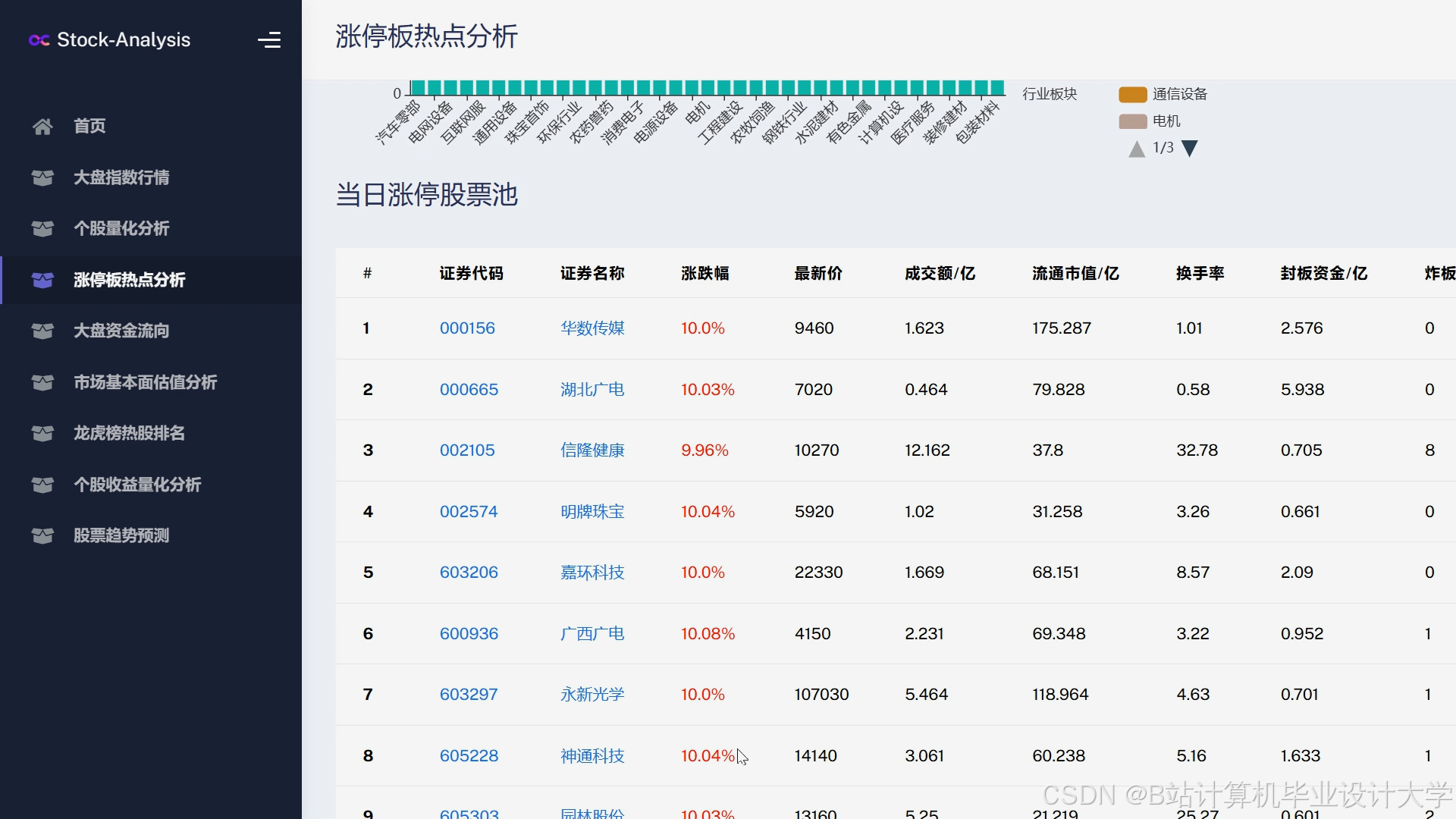
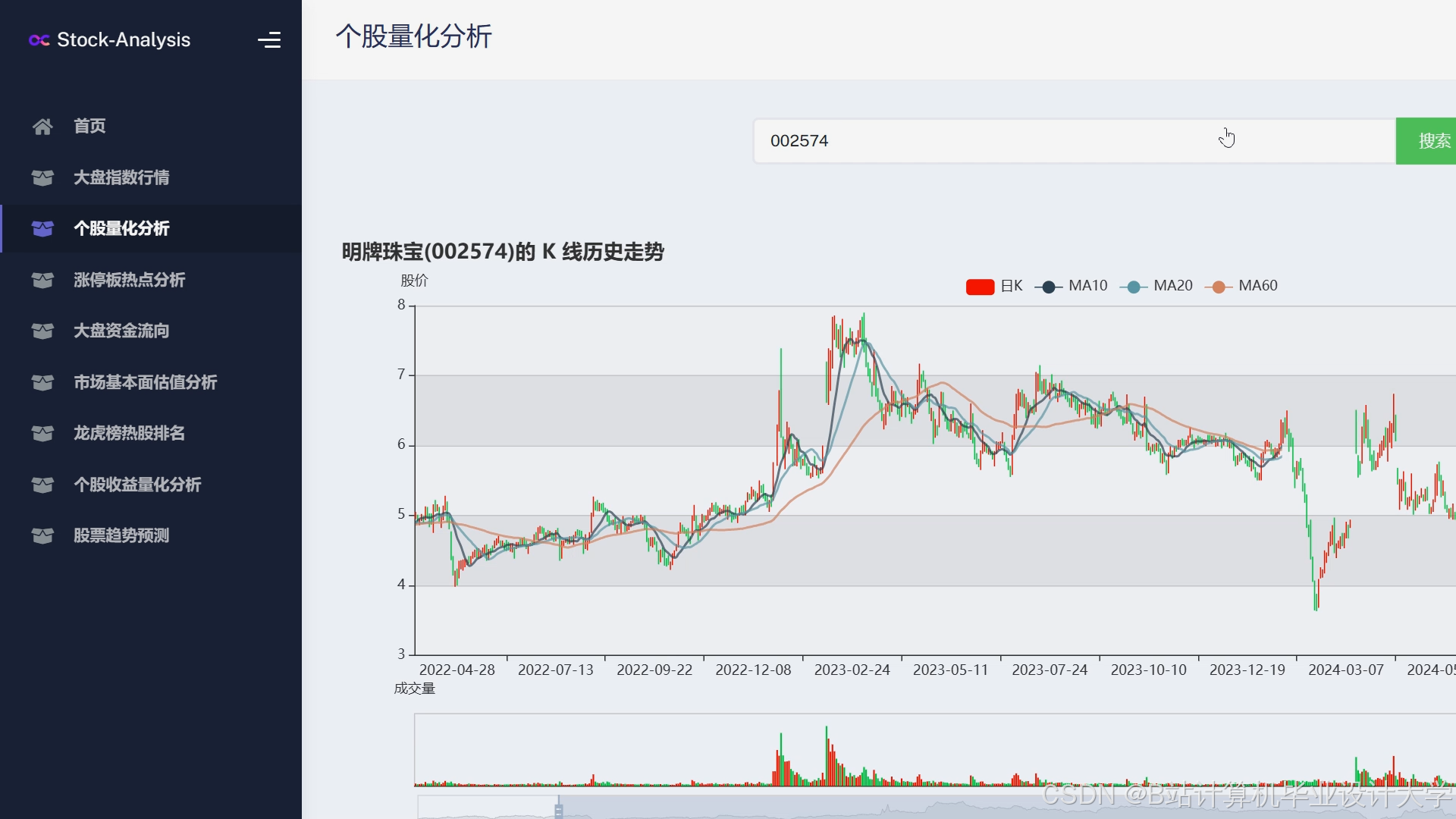
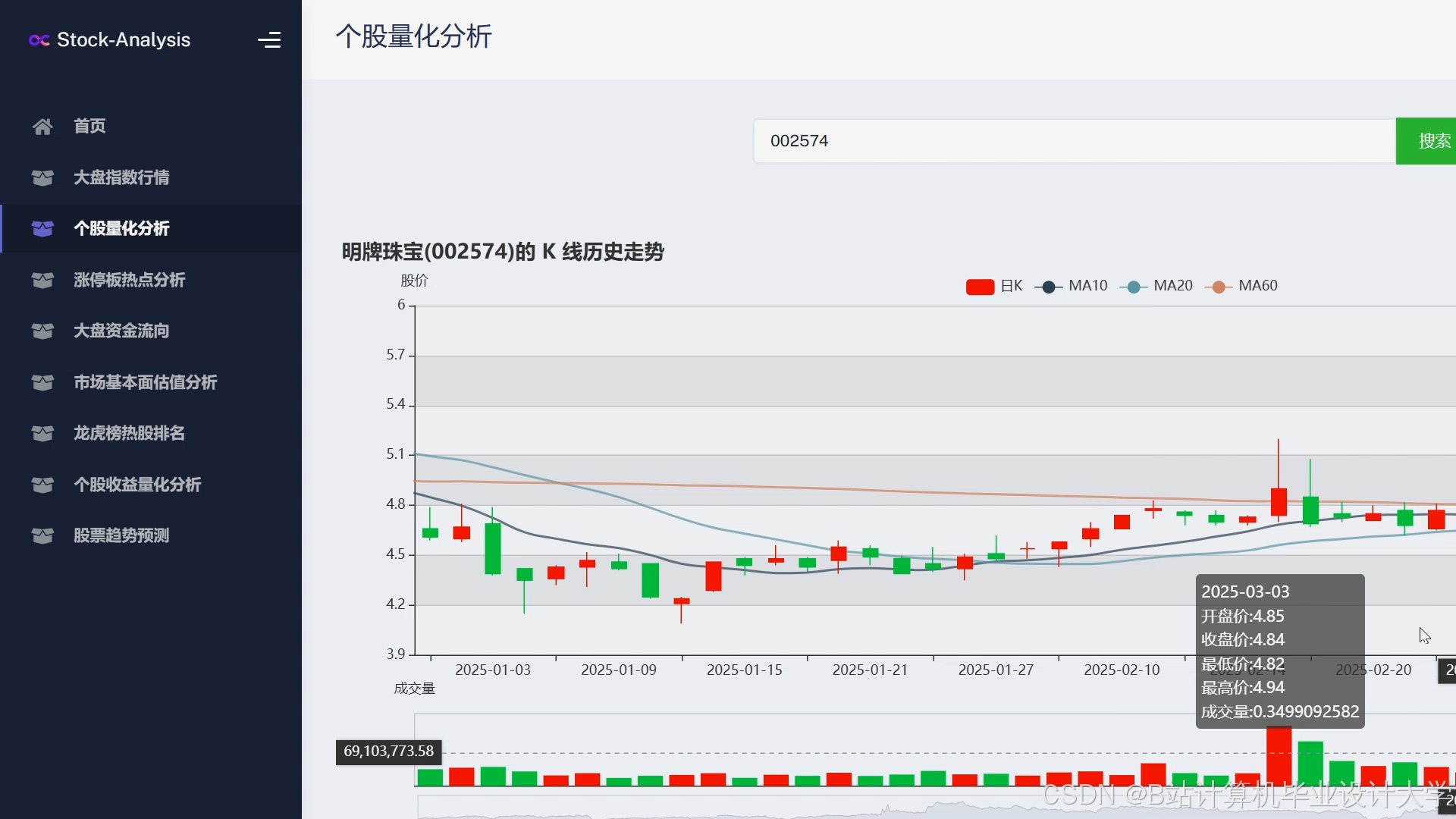
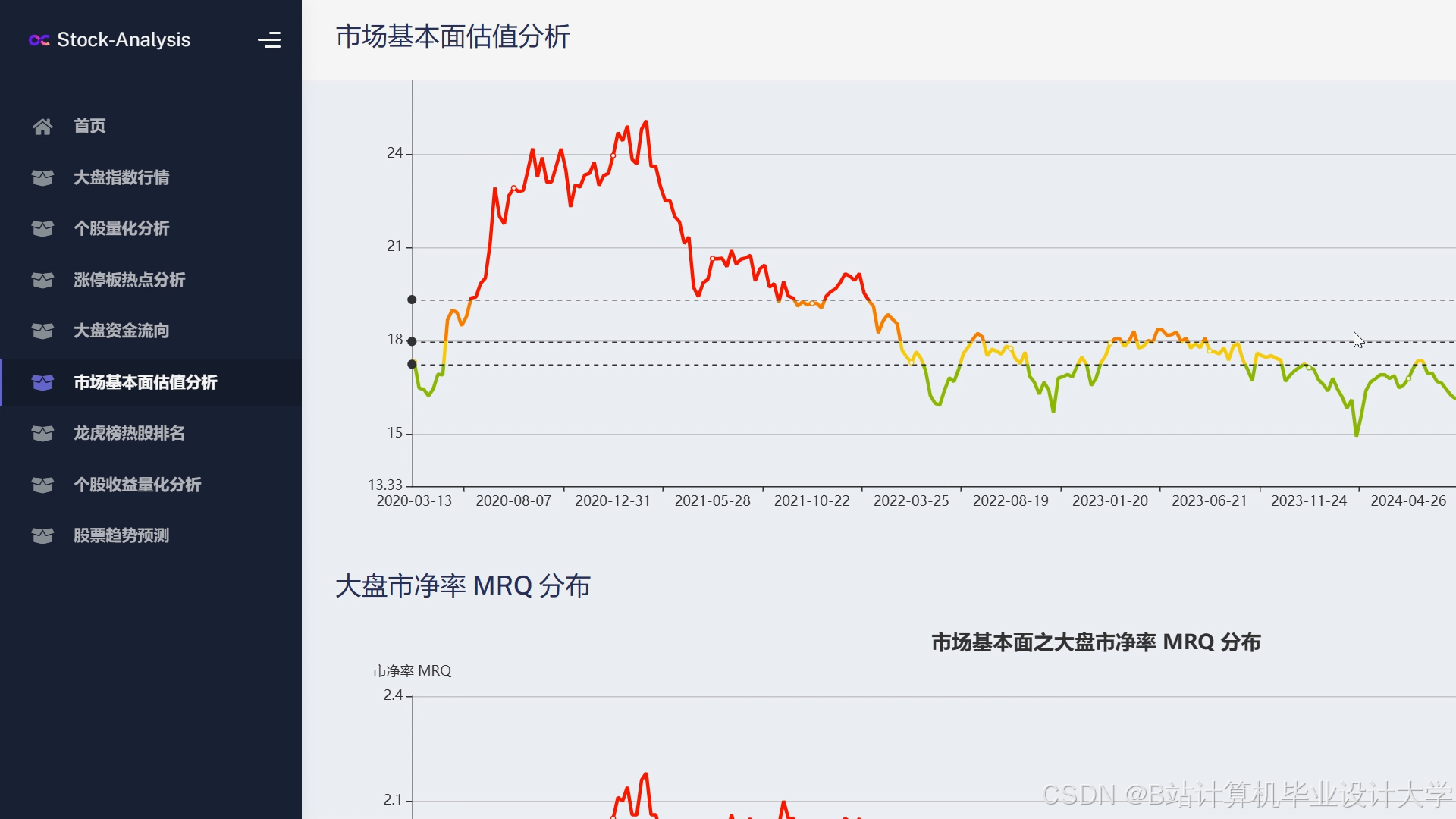
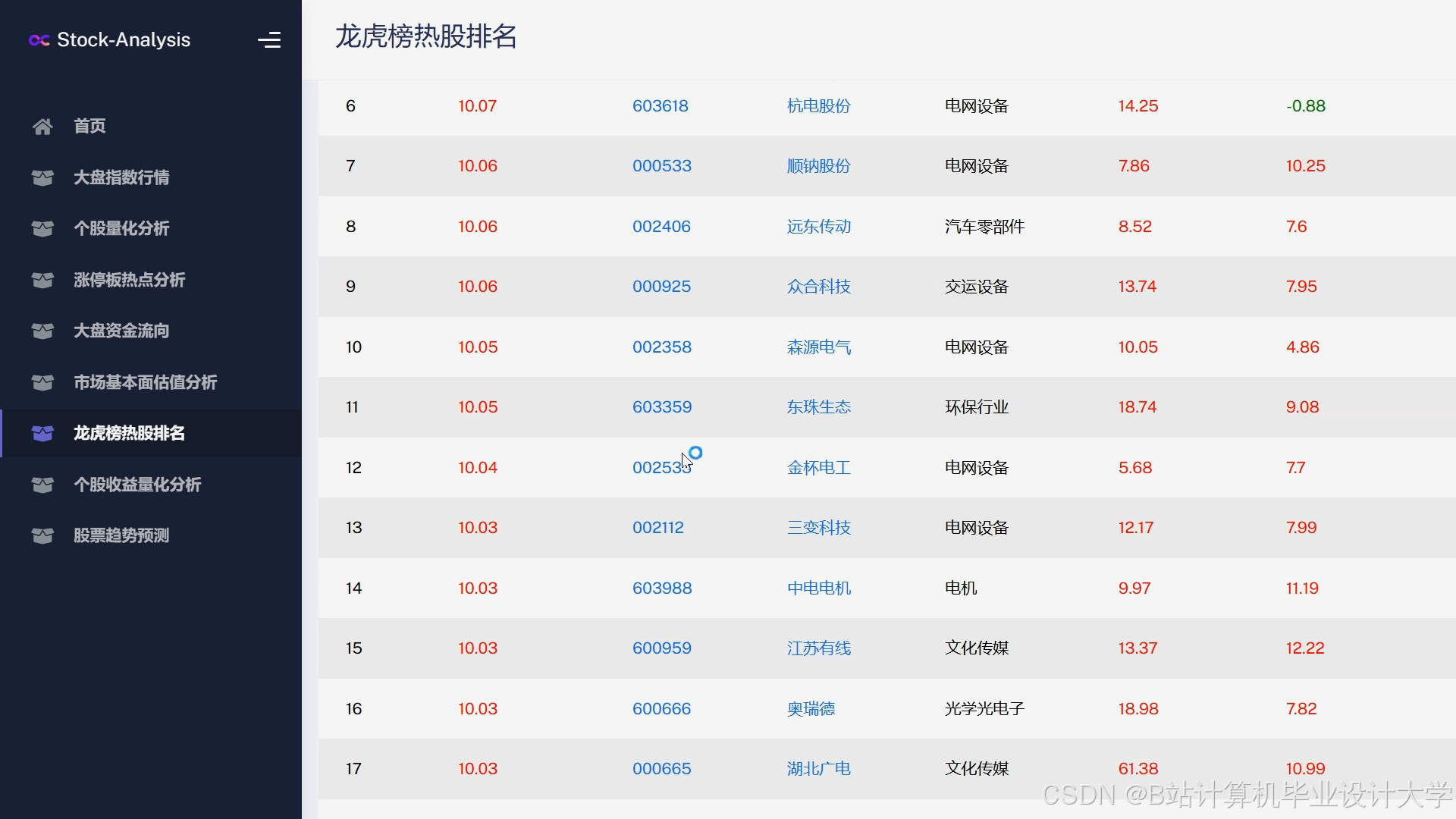
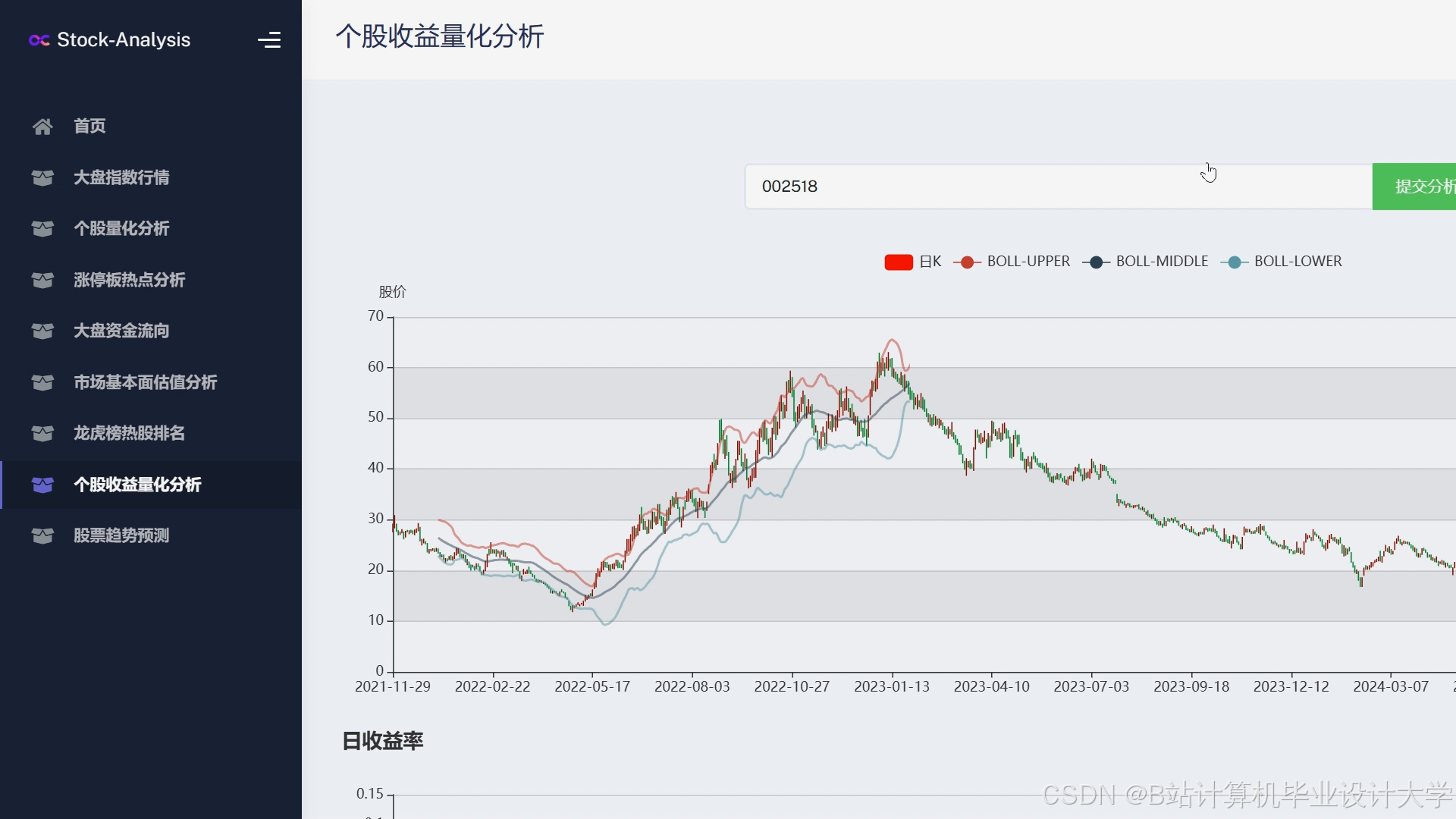
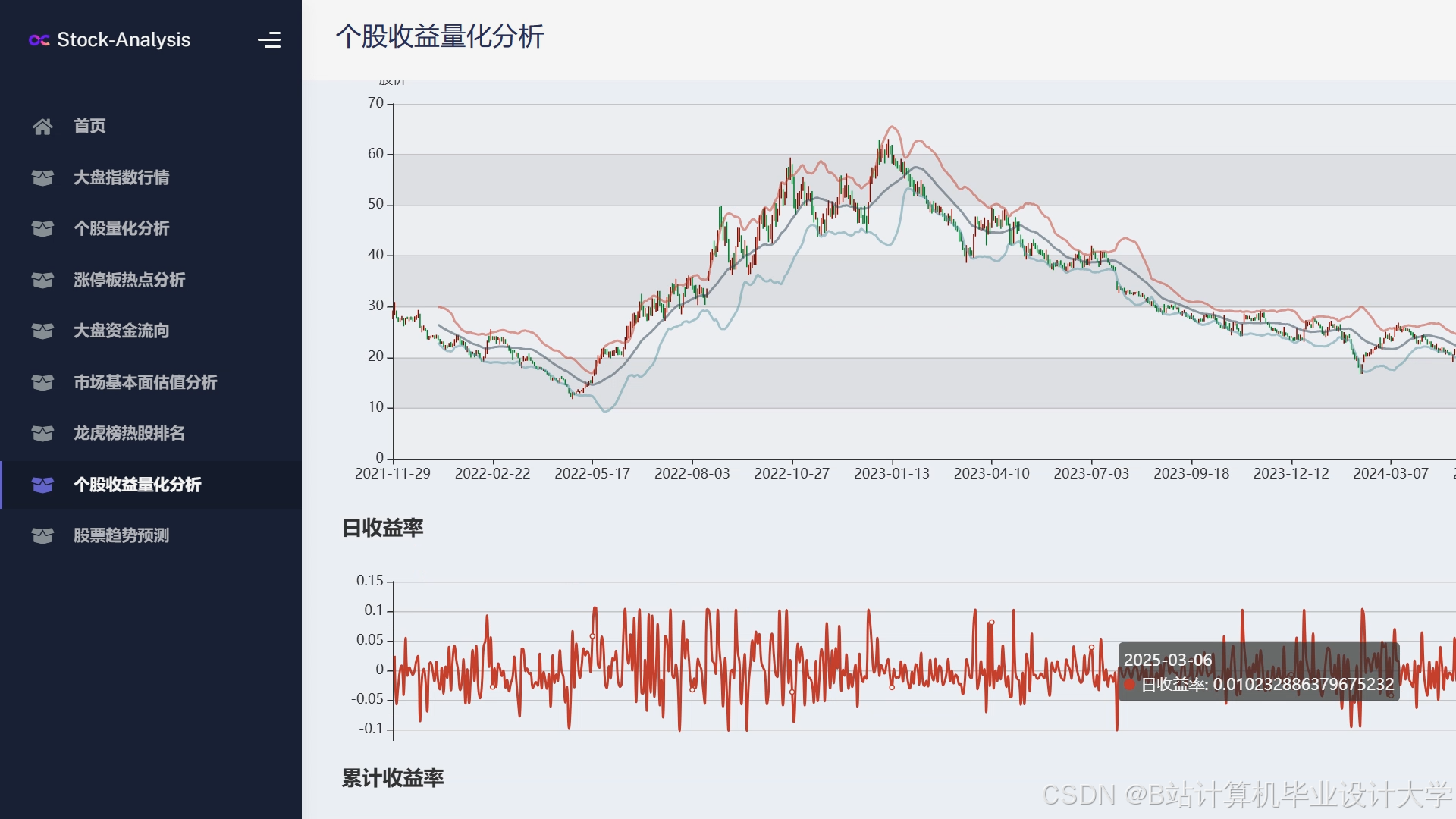
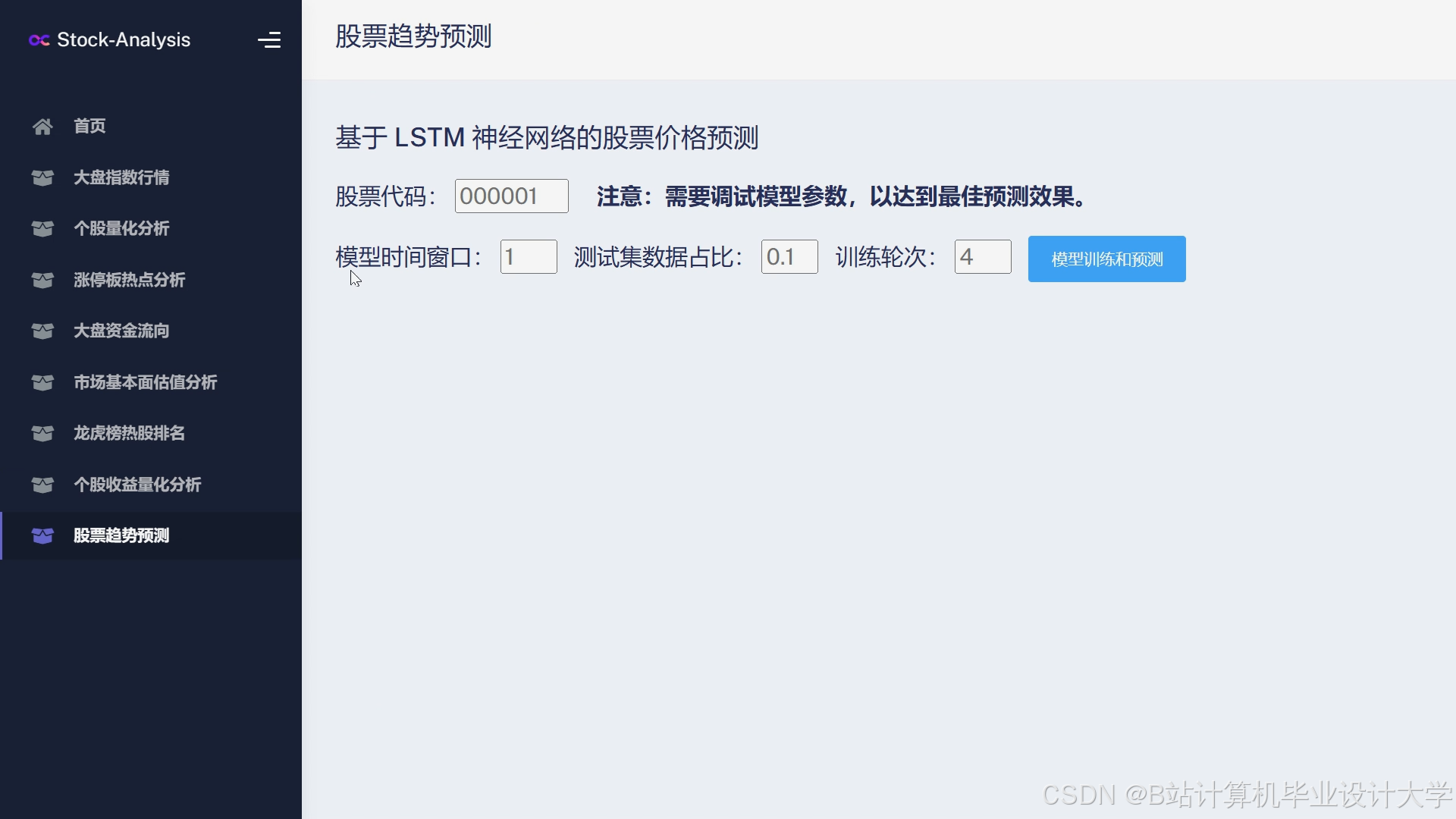
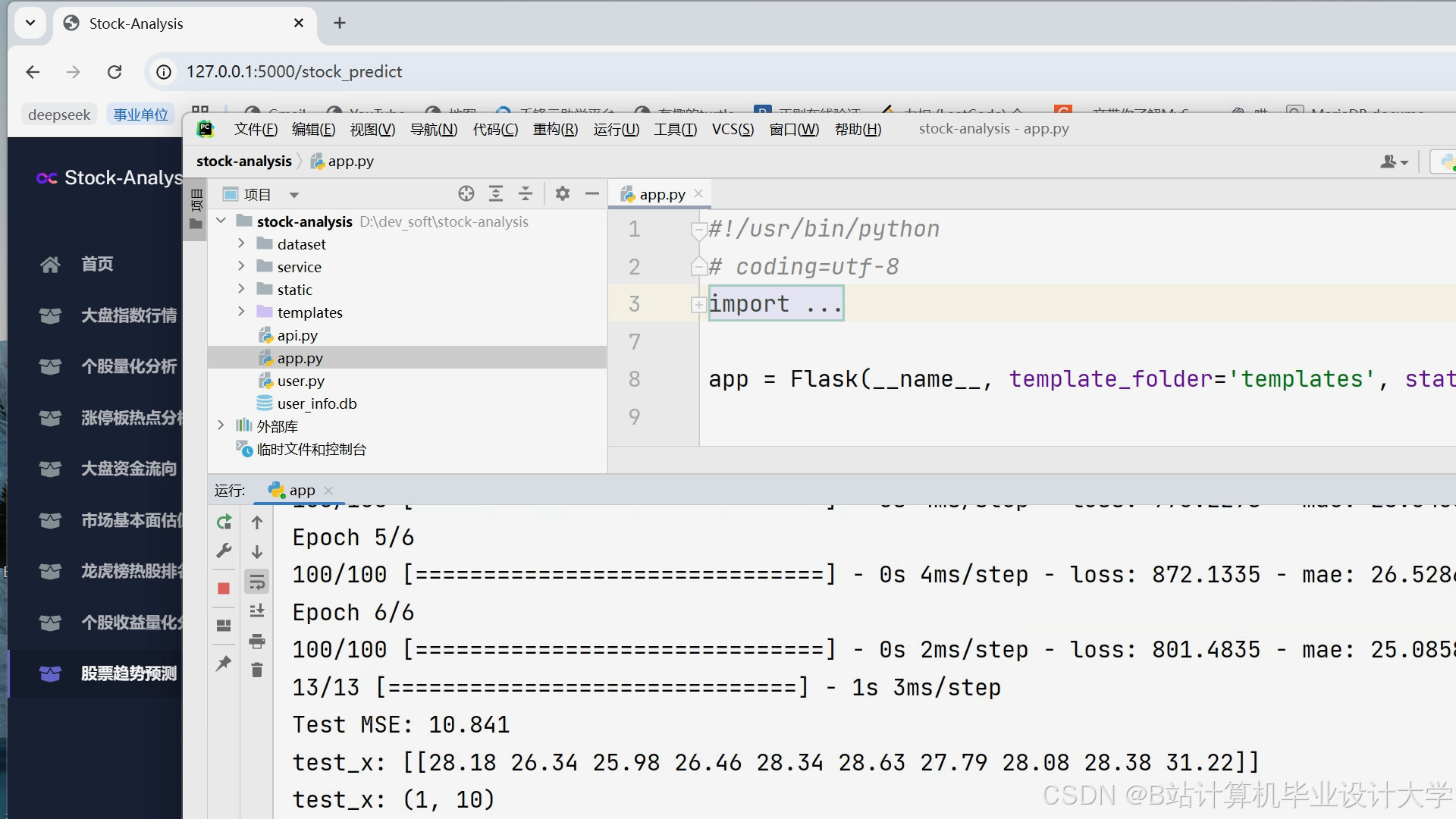
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1867
1867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











