




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+PySpark+Scrapy爬虫酒店推荐系统
摘要:随着互联网旅游行业的蓬勃发展,酒店预订市场规模持续扩大,用户对个性化、精准化酒店推荐的需求日益增长。本文提出了一种基于Hadoop、PySpark和Scrapy爬虫的酒店推荐系统,旨在利用大数据技术高效处理海量酒店数据,为用户提供个性化的酒店推荐服务。该系统通过Scrapy爬虫抓取各大在线旅游平台的酒店信息,利用Hadoop进行数据存储,借助PySpark进行数据处理和分析,结合协同过滤和基于内容的推荐算法实现酒店推荐。实验结果表明,该系统能够有效地提高酒店推荐的准确性和用户满意度。
关键词:Hadoop;PySpark;Scrapy;酒店推荐系统;协同过滤;基于内容的推荐
一、引言
在线旅游市场的快速发展使得酒店预订业务呈现出数据海量增长、用户需求多样化的特点。用户在选择酒店时,不仅关注价格、位置等基本信息,还越来越注重其他用户的评价、酒店的设施、服务质量等多维度因素。传统酒店推荐系统多依赖简单规则或统计方法,难以有效处理大规模数据和复杂用户行为,无法满足用户对个性化、精准化推荐的需求。Hadoop、PySpark和Scrapy等技术的出现,为解决这一问题提供了新的途径。Hadoop提供了分布式存储和计算能力,能够处理大规模的酒店数据;PySpark基于Spark的Python API,提供了高效的数据处理和分析能力;Scrapy是一个强大的Python爬虫框架,可用于高效地爬取网络上的酒店信息。通过这三者的结合,可以构建一个高效、智能的酒店推荐系统,为用户提供个性化的酒店推荐服务。
二、相关技术概述
(一)Hadoop
Hadoop是一个开源的分布式计算框架,其核心组件包括HDFS(分布式文件系统)和MapReduce(分布式计算模型)。HDFS具有高容错性、高吞吐量等特点,能够将大规模数据分布式存储在多个节点上,提供可靠的数据存储服务。MapReduce则是一种编程模型,用于处理和生成大数据集,它将计算任务分解为多个子任务,并在集群中的多个节点上并行执行,大大提高了数据处理的效率。在酒店推荐系统中,Hadoop主要用于存储从各大在线旅游平台抓取的海量酒店数据,为后续的数据处理和分析提供基础。
(二)PySpark
PySpark是Apache Spark的Python API,继承了Spark的内存计算和分布式处理能力。与Hadoop MapReduce相比,PySpark支持迭代计算和交互式查询,适用于机器学习和实时数据处理。在酒店推荐系统中,PySpark可用于对酒店数据进行快速的数据清洗、特征提取、模型训练等操作。例如,可以使用PySpark对酒店数据进行去重、缺失值填充、特征工程等处理,为推荐算法提供高质量的数据输入。同时,PySpark还支持与机器学习库(如MLlib)的集成,方便实现各种推荐算法。
(三)Scrapy
Scrapy是一个开源的Python爬虫框架,支持异步请求和数据解析,可高效抓取动态网页内容。它具有高效、灵活、可扩展等特点,可以根据不同的需求进行定制化开发。在酒店推荐系统中,Scrapy爬虫主要用于从各大在线旅游平台抓取酒店信息,如酒店名称、位置、价格、评分、用户评价等。通过设置代理IP、更换User-Agent等方式,可以绕过网站的反爬虫机制,提高数据抓取的效率和成功率。
三、系统架构设计
(一)总体架构
本系统采用分层架构设计,主要包括数据采集层、数据存储与处理层、推荐算法开发层和用户交互层,各层之间相互协作,共同完成酒店推荐任务。
(二)数据采集层
数据采集层利用Scrapy框架开发酒店数据爬虫,高效抓取各大在线旅游平台上的酒店信息。爬虫程序需要具备良好的反爬机制应对能力,如设置代理IP池、动态User-Agent、请求间隔随机化等,以确保数据的稳定性和可靠性。同时,为了提高数据采集的效率,可以采用分布式爬虫架构,将爬虫任务分配到多个节点上执行。
(三)数据存储与处理层
数据存储与处理层采用Hadoop HDFS存储海量酒店数据,利用PySpark进行数据清洗、整合与预处理。首先,将抓取到的酒店数据存储到HDFS中,然后使用PySpark对数据进行清洗,去除重复值、处理缺失值等。接着,进行特征工程,提取酒店的关键特征,如价格、评分、地理位置、设施等,构建酒店特征向量。此外,还可以利用Hive对数据进行进一步的分析和查询优化,提高数据处理的效率。
(四)推荐算法开发层
推荐算法开发层开发基于协同过滤、内容推荐等算法的酒店推荐系统,结合用户行为数据和酒店知识图谱,提供个性化推荐服务。协同过滤算法是根据用户的历史行为数据,找到与目标用户兴趣相似的其他用户,然后将这些用户喜欢的酒店推荐给目标用户。基于内容的推荐算法是根据酒店的特征信息,找到与目标用户历史喜欢的酒店特征相似的酒店进行推荐。为了提高推荐的准确性和多样性,可以将协同过滤算法和基于内容的推荐算法结合起来,形成混合推荐算法。同时,还可以考虑时间、地理位置等上下文信息,进一步优化推荐结果。
(五)用户交互层
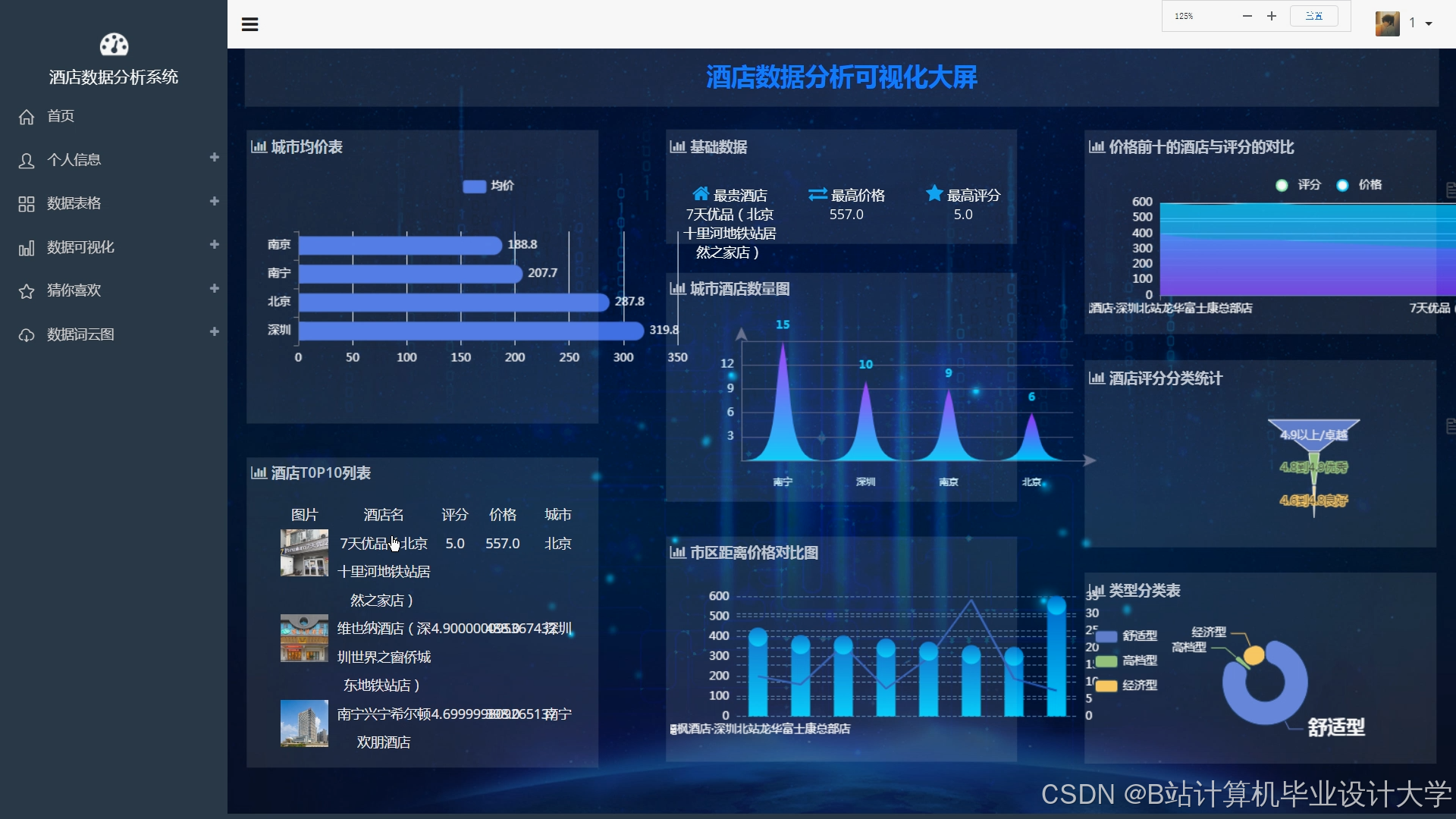
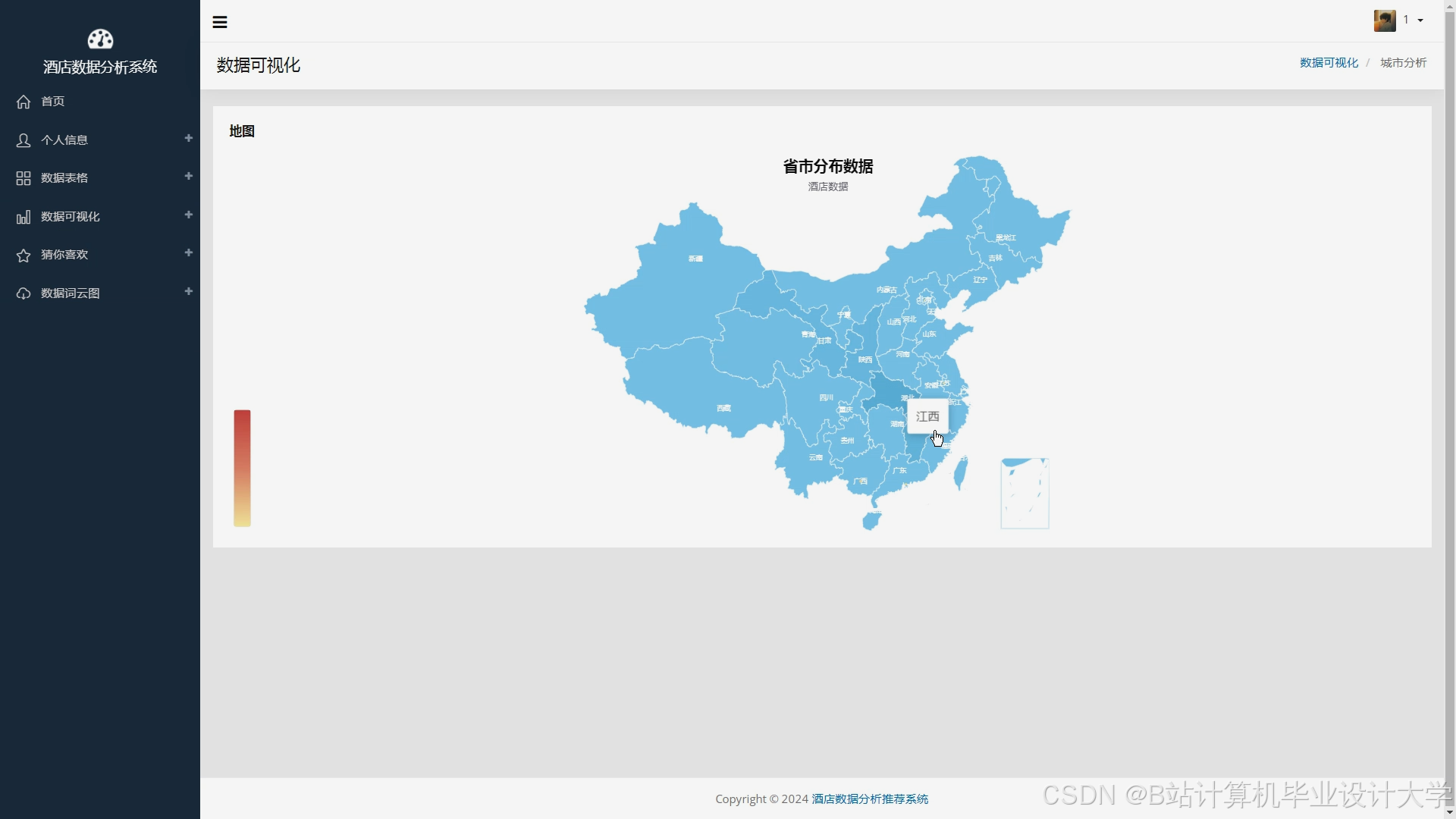
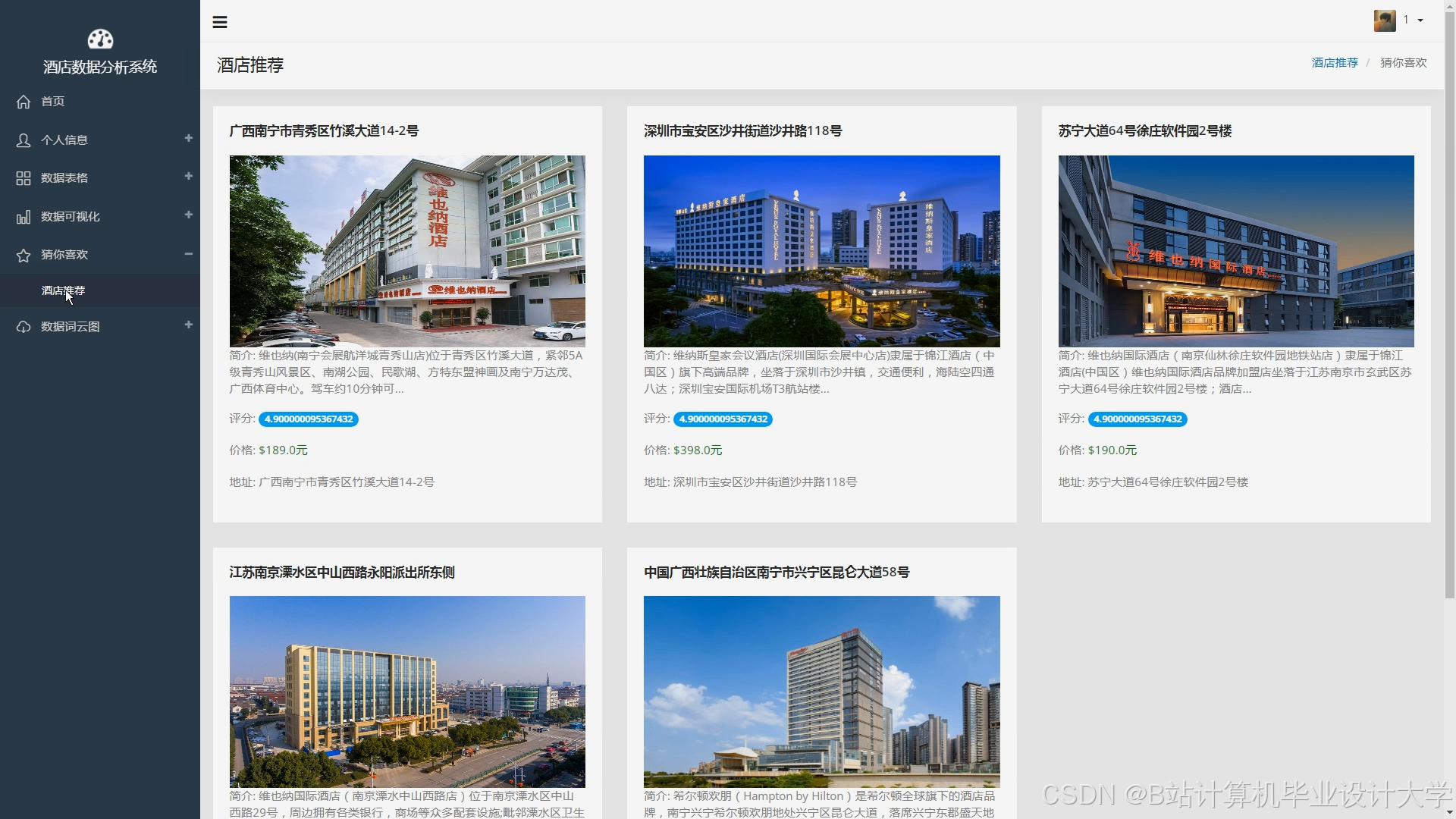
用户交互层使用Django或Flask等框架构建后端服务,提供API接口;使用React或Vue等前端框架构建用户界面,实现交互功能。用户可以通过前端界面进行注册、登录、搜索酒店、查看推荐结果等操作。系统将推荐结果以直观的方式展示给用户,如列表、地图等,方便用户进行选择。同时,用户还可以对推荐结果进行反馈,系统根据用户反馈不断优化推荐算法。
四、系统实现
(一)数据采集实现
使用Scrapy框架编写爬虫程序,针对不同的在线旅游平台进行定制化开发。例如,对于携程网,需要分析其网页结构,确定需要抓取的数据字段,如酒店名称、价格、评分、用户评价等。然后,编写相应的爬虫规则,使用XPath或CSS选择器提取数据。在爬虫运行过程中,设置合理的请求间隔,避免对目标网站造成过大压力。同时,将抓取到的数据存储到MongoDB或MySQL等数据库中,以便后续处理。
(二)数据存储与处理实现
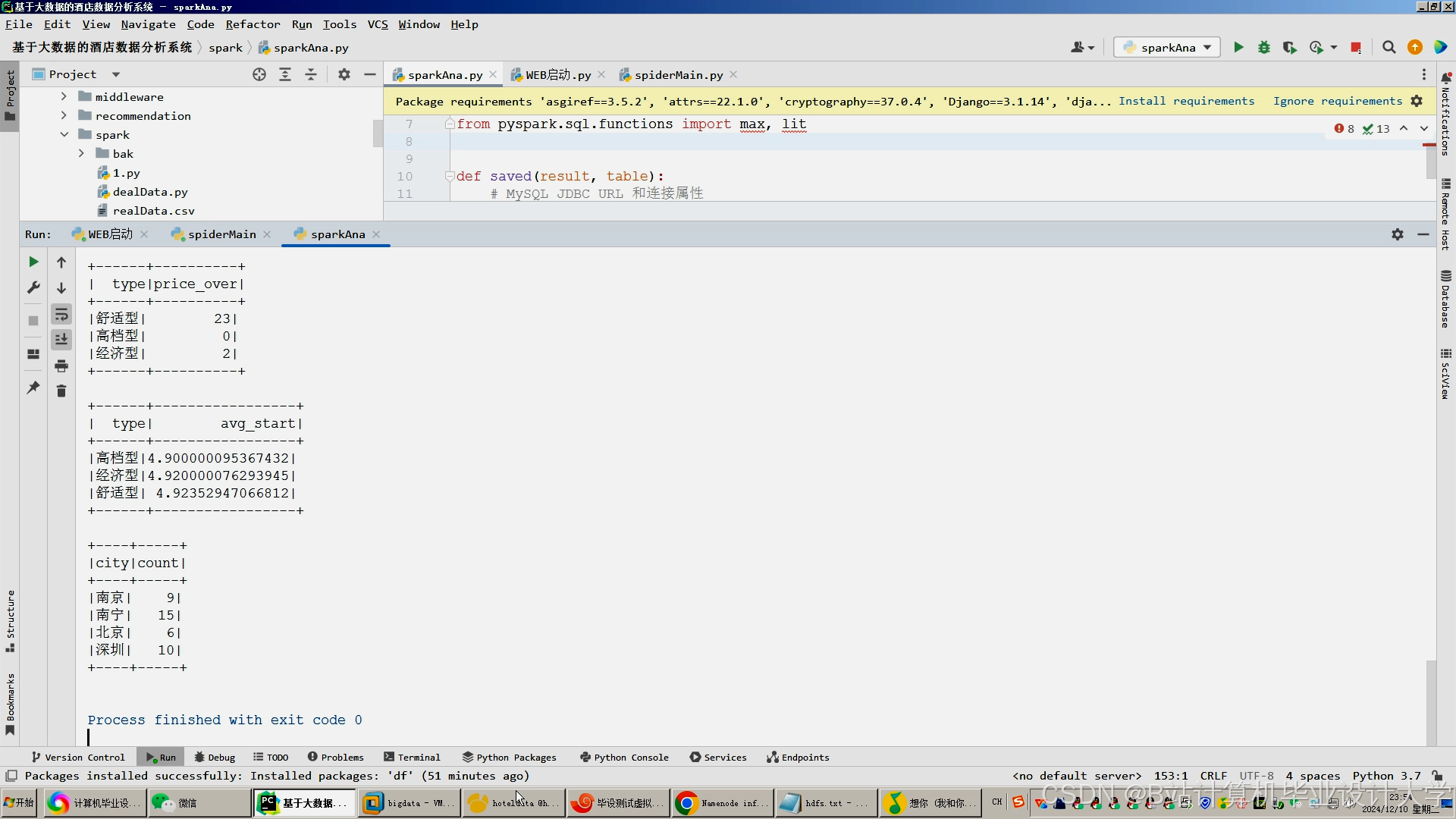
搭建Hadoop集群,配置HDFS和YARN等组件。将存储在数据库中的酒店数据导入到HDFS中,可以使用Sqoop等工具实现数据迁移。然后,使用PySpark进行数据处理。例如,编写PySpark程序对酒店数据进行去重操作,使用distinct()函数去除重复记录;对于缺失值,可以采用填充平均值或中位数的方法进行处理。在特征工程方面,使用PySpark的MLlib库中的特征提取工具,如TF-IDF、Word2Vec等,对用户评价等文本数据进行特征提取,构建用户和酒店的特征向量。
(三)推荐算法实现
基于协同过滤算法,计算用户-酒店相似度。可以使用余弦相似度或皮尔逊相关系数等方法衡量用户或酒店之间的相似度。根据相似度计算结果,生成推荐列表。同时,结合基于内容的推荐算法,根据酒店特征和用户偏好进行推荐。例如,对于喜欢高评分酒店且注重酒店设施的用户,推荐具有相应特征的酒店。考虑时间、地理位置等上下文信息,对推荐结果进行优化。例如,在旅游旺季,优先推荐地理位置优越、交通便利的酒店。
(四)用户交互实现
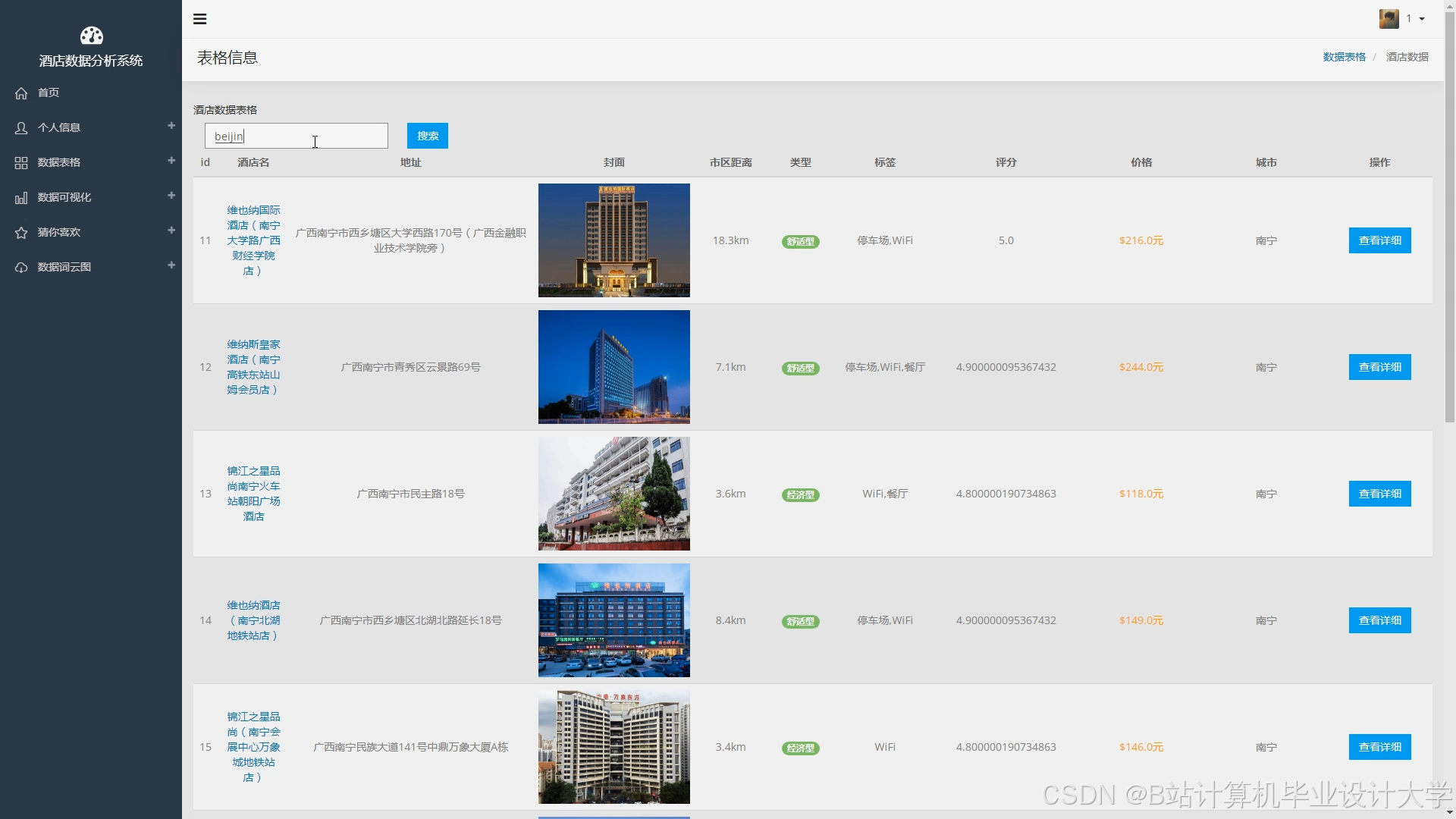
使用Django框架构建后端服务,定义API接口,处理用户请求和数据交互。例如,定义用户注册、登录接口,酒店搜索接口,推荐结果获取接口等。使用Vue框架构建前端界面,实现页面的布局和交互效果。前端界面包括酒店列表展示页面、酒店详情页面、用户个人中心页面等。在酒店列表展示页面,以列表或地图的形式展示推荐结果,用户可以点击酒店查看详细信息。
五、实验与结果分析
(一)实验环境
实验环境包括Hadoop集群、PySpark开发环境、Scrapy爬虫运行环境等。Hadoop集群由多台服务器组成,配置了适当的硬件资源,以确保数据存储和处理的效率。PySpark开发环境基于Python 3.x版本,安装了必要的依赖库。Scrapy爬虫运行在独立的服务器上,用于数据采集。
(二)实验数据
从携程、去哪儿等在线旅游平台抓取了大量的酒店数据,包括酒店基本信息、用户评价等。数据量达到了数百万条,涵盖了不同地区、不同价格区间、不同星级的酒店。
(三)评价指标
采用准确率、召回率、F1值等指标来评价推荐算法的性能。准确率是指推荐结果中用户真正感兴趣的酒店所占的比例;召回率是指用户真正感兴趣的酒店中被推荐出来的比例;F1值是准确率和召回率的调和平均数,综合反映了推荐算法的性能。
(四)实验结果与分析
通过实验对比了基于协同过滤算法、基于内容的推荐算法和混合推荐算法的性能。实验结果表明,混合推荐算法在准确率、召回率和F1值等指标上均优于单一算法。这是因为混合推荐算法结合了协同过滤算法和基于内容的推荐算法的优点,能够更全面地考虑用户的历史行为和酒店的特征信息,从而提高推荐的准确性。同时,考虑时间、地理位置等上下文信息后,推荐结果更加符合用户的实际需求,进一步提高了用户满意度。
六、系统优化与展望
(一)系统优化
针对数据抓取限制问题,可以进一步优化爬虫程序的反爬机制,如采用更智能的代理IP切换策略、模拟人类浏览行为等,以提高数据抓取的成功率。在数据处理性能方面,可以对PySpark作业进行优化,如调整并行度、合理使用缓存等,提高数据处理效率。对于推荐算法准确性问题,可以引入深度学习技术,如神经网络、卷积神经网络等,对用户行为数据和酒店特征数据进行深度挖掘和分析,提高推荐算法的泛化能力。
(二)未来展望
未来的研究可以进一步拓展系统的功能,如增加酒店价格预测功能,根据历史价格数据和市场趋势,为用户提供酒店价格走势预测,帮助用户选择合适的预订时间。同时,可以结合社交网络数据,分析用户的社交关系和兴趣偏好,为用户提供更加个性化的推荐服务。此外,还可以研究系统的跨平台应用,将酒店推荐系统应用到移动端设备上,方便用户随时随地获取酒店推荐信息。
七、结论
本文提出了一种基于Hadoop、PySpark和Scrapy爬虫的酒店推荐系统,通过Scrapy爬虫抓取酒店信息,利用Hadoop进行数据存储,借助PySpark进行数据处理和分析,结合协同过滤和基于内容的推荐算法实现酒店推荐。实验结果表明,该系统能够有效地提高酒店推荐的准确性和用户满意度。然而,该系统仍存在一些不足之处,如数据抓取限制、数据处理性能有待提高等。未来的研究可以针对这些问题进行优化和改进,进一步拓展系统的功能,为用户提供更加优质的酒店推荐服务。
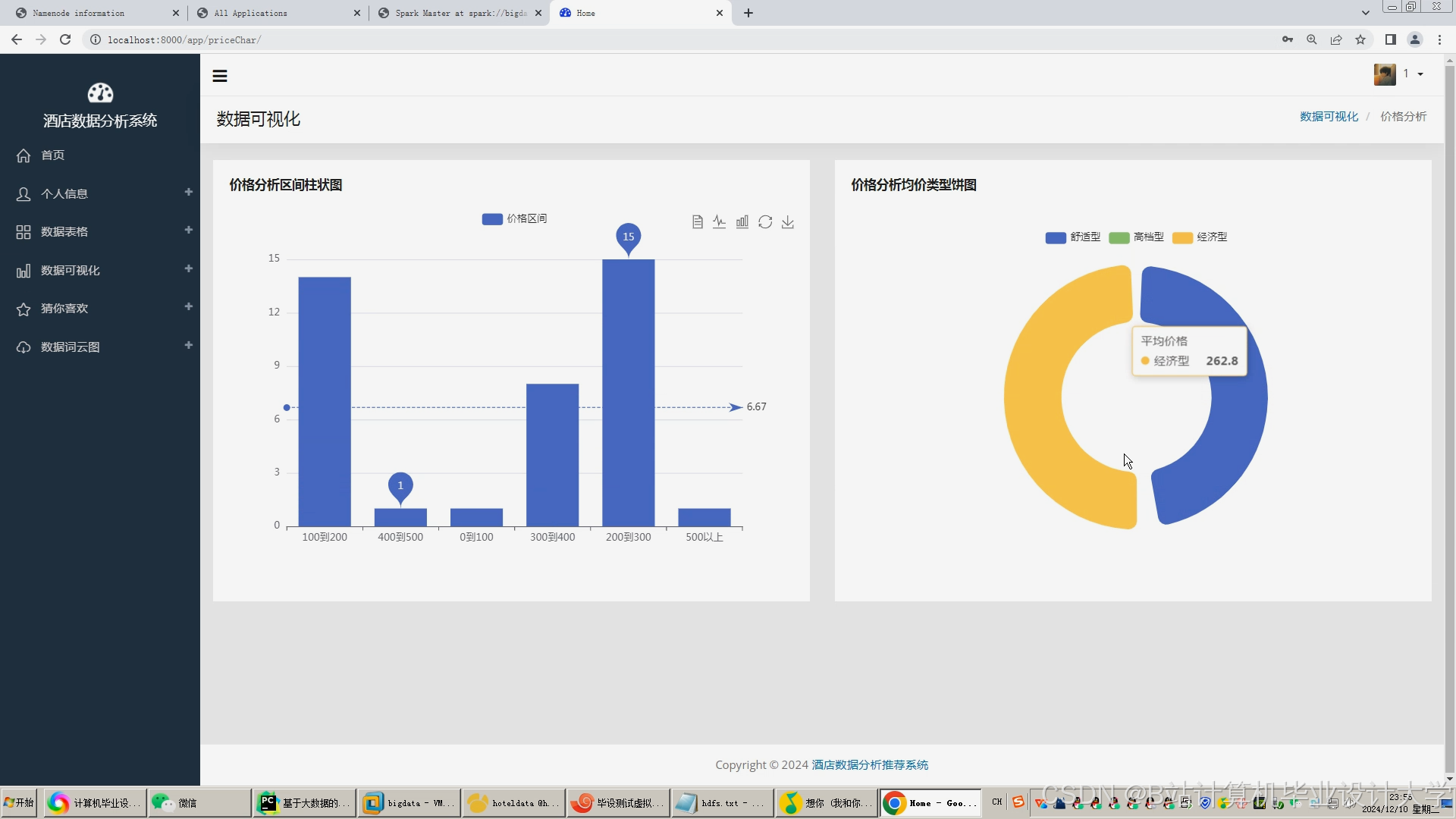
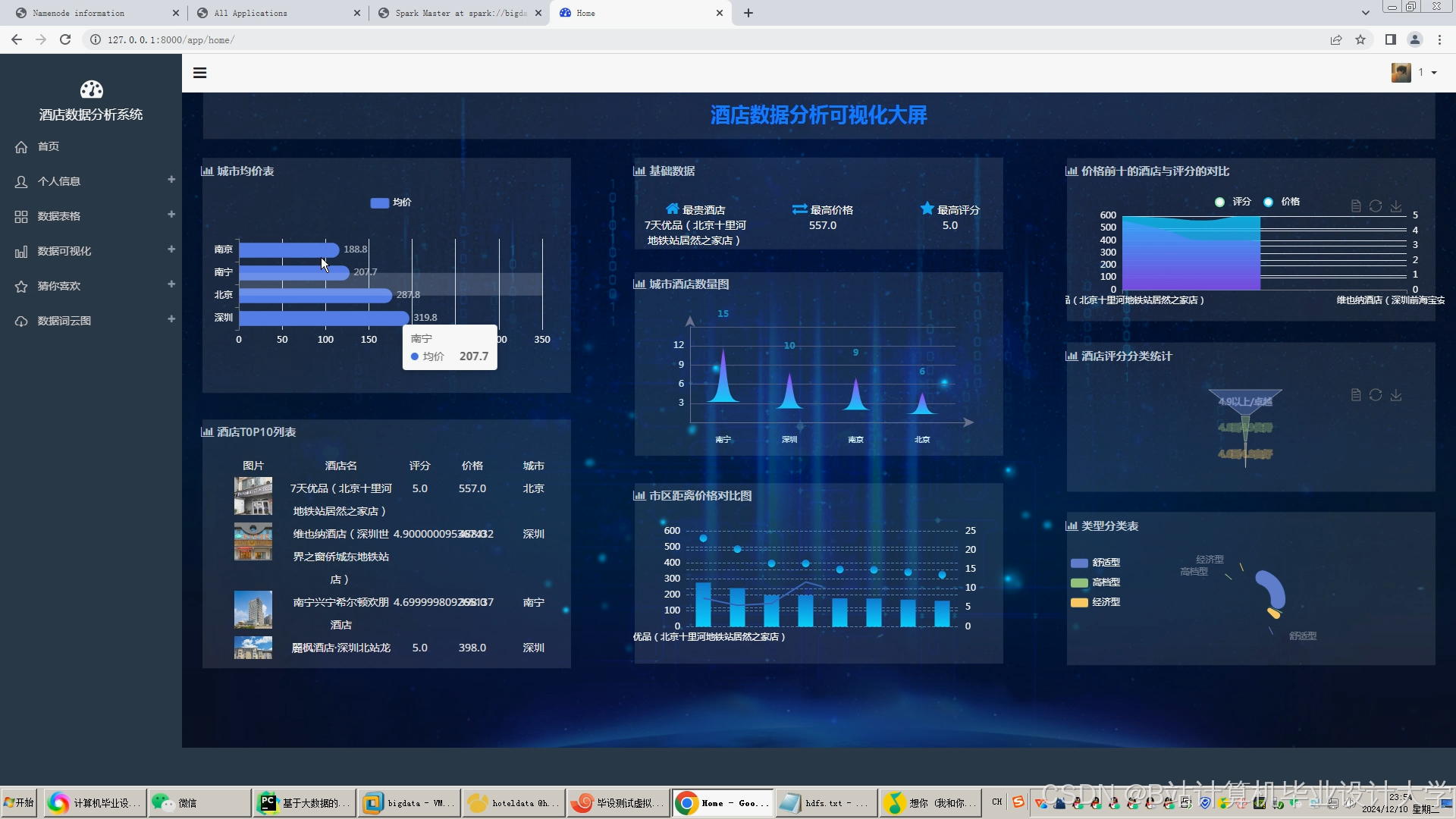
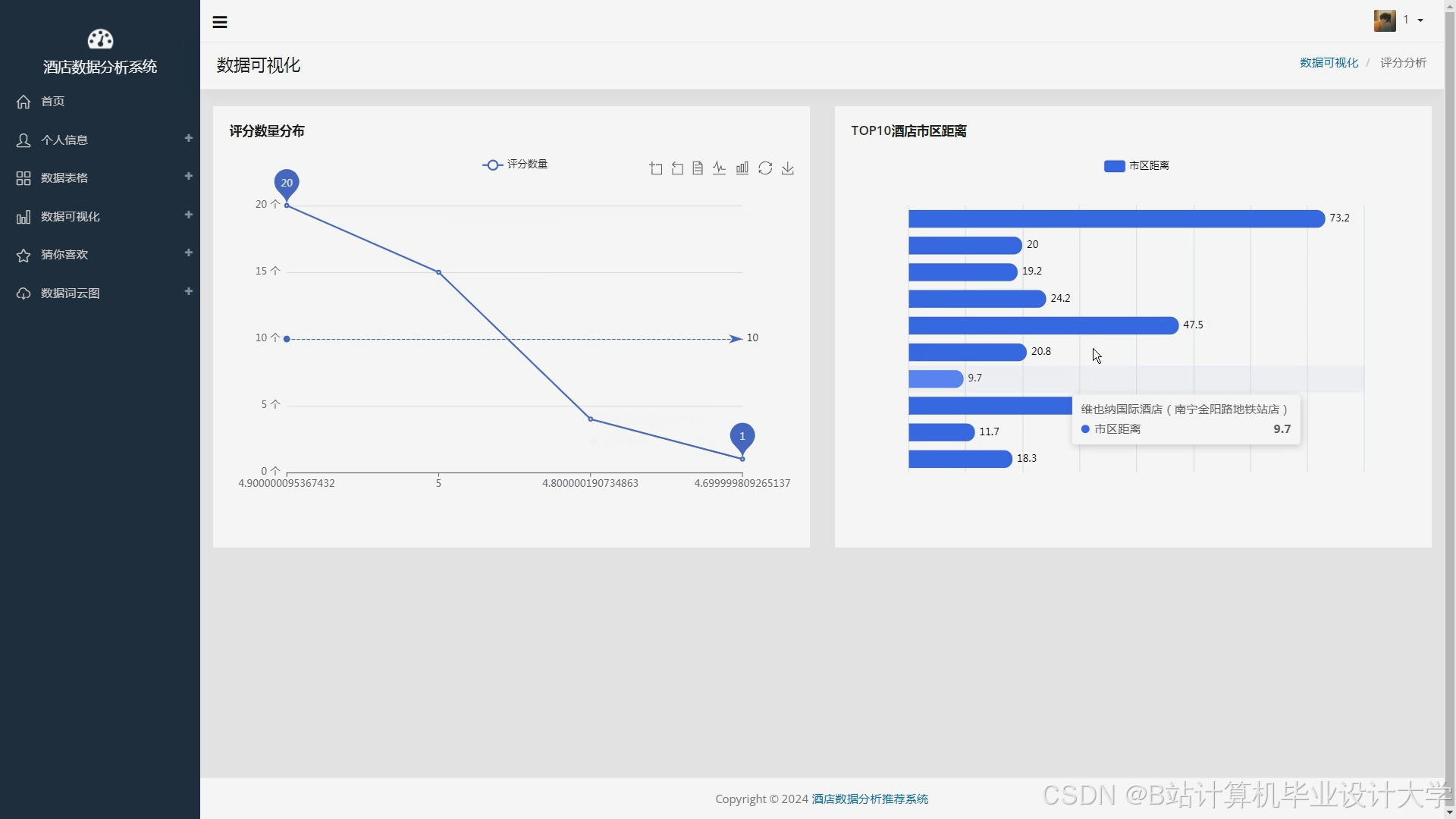
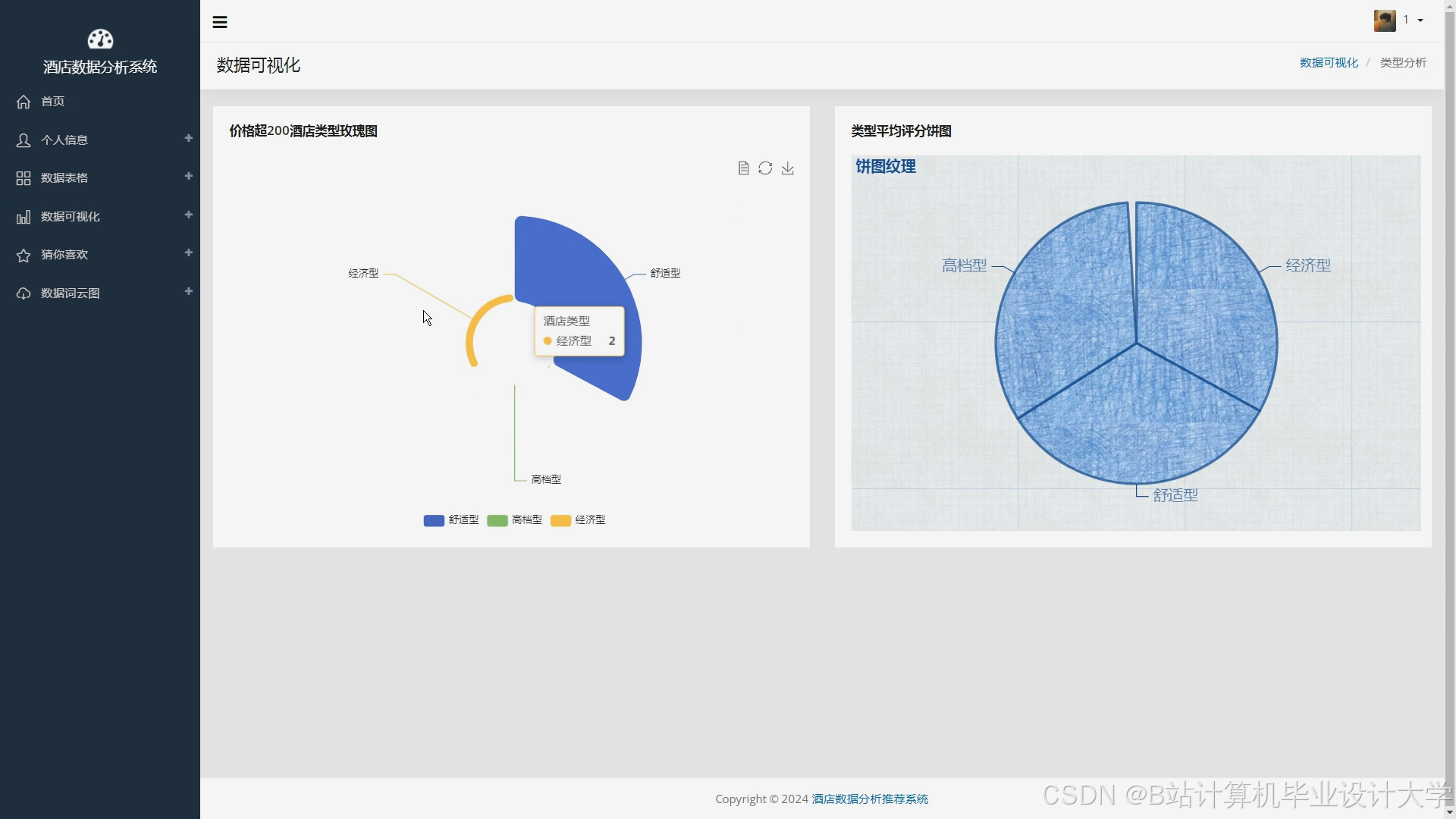
运行截图

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











