







温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
作者简介:Java领域优质创作者、优快云博客专家 、优快云内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参与学生毕业答辩指导,有较为丰富的相关经验。期待与各位高校教师、企业讲师以及同行交流合作
主要内容:Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能与大数据、单片机开发、物联网设计与开发设计、简历模板、学习资料、面试题库、技术互助、就业指导等
业务范围:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路等。
收藏点赞不迷路 关注作者有好处
文末获取源码
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
毕业设计(论文)
题 目: 基于Hadoop的旅游景点
推荐系统的设计与实现
院 (系): 软件学院
专业年级: 软件工程
姓 名: ***
学 号: *********
指导教师: ************************
2022年6月15日
原 创 性 声 明
本人郑重声明:本人所呈交的毕业论文,是在指导老师的指导下独立进行研究所取得的成果。毕业论文中凡引用他人已经发表或未发表的成果、数据、观点等,均已明确注明出处。除文中已经注明引用的内容外,不包含任何其他个人或集体已经发表或撰写过的科研成果。对本文的研究成果做出重要贡献的个人和集体,均已在文中以明确方式标明。
本声明的法律责任由本人承担。
论文作者签名: 日 期:
关于毕业论文使用授权的声明
本人在指导教师指导下所完成的论文及相关的资料(包括图纸、试验记录、原始数据、实物照片、图片、录音带、设计手稿等),知识产权归属平顶山学院。本人完全了解平顶山学院有关保存、使用毕业论文的规定,同意学校保存或向国家有关部门或机构送交论文的纸质版和电子版,允许论文被查阅和借阅;本人授权*******可以将本毕业论文的全部或部分内容编入有关数据库进行检索,可以采用任何复制手段保存和汇编本毕业论文。如果发表相关成果,一定征得指导教师同意,且第一署名单位为********。本人离校后使用毕业论文或与该论文直接相关的学术论文或成果时,第一署名单位仍然为*******。
论文作者签名: 日 期:
指导教师签名: 日 期:
基于Hadoop的旅游景点推荐系统的设计与实现
摘 要
随着人们的生活水平不断提高,旅游行业顺势快速发展。面对多样化的旅游出行需求,用户很难在庞大的资源数据中找到契合自身的信息。运用 Hadoop 大数据技术对相似的信息进行整理归纳为用户提供更加的旅游出行方案,是本人提出的旅游景点信息化方案。
因此本文阐述了一款基于大数据计算框架对旅游景点数据进行分析与推荐的软件系统,实现了对数据采集、数据处理与分析、数据可视化展示为一体的操作,基本满足为用户推荐心仪旅游景点的需求。
本系统主要由大数据系统、可视化前端系统、web后台管理系统、景点推荐系统、旅游景点APP端组成。大屏统计端使用hadoop+spark完成,数据采集使用Python离线分析端、网页用户端以及后台管理使用Springboot+mybatis框架开发,在可视化阶段采用Echarts来提供可交互的直观数据可视化图表。此外本系统采用MySQL数据库,其目的是存储利用爬虫爬取到的大量旅游景点信息数据集和数据处理之后的分析结果,再通过Spark并行计算进行数据抽取,多维分析,查询统计等操作来完成数据分析。完成基于大数据的旅游数据分析推荐可视化与管理一体的系统开发。
关键词: 旅游景点、Hadoop、推荐系统
Design and Implementation of Scenic Spot Recommendation System based on Hadoop
Abstract
With the continuous improvement of people's living standards, the Tourism industry develops rapidly. In the face of diverse travel needs, it is difficult for users to find relevant information in the huge resource data. Hadoop big data technology is used to sort out and summarize similar types of information to provide intelligent travel guarantee for users, which is the Tourist attraction information scheme proposed by me.
This system describes a software system for Tourism Data Analysis and Recommendation based on the big data computing framework, which realizes the operation of data collection, data processing and analysis, and data visualization, and basically meets the needs of recommending Tourism for users.
The system is mainly composed of big data system, Visual front-end system, Web background management system, Tourism Recommendation System, Tourism small program /APP end. The large-screen statistical end is completed by Hadoop + Spark, data collection is developed by Python offline analysis end, web client end and background management using Springboot+ Mybatis framework. In the visualization stage, Echarts is used to provide interactive intuitive data visualization charts. The database used in this system is MySQL database, which is used to store a large number of music information data sets obtained by crawler and the analysis results after data processing. Data analysis is completed through Spark parallel computing for data extraction, multidimensional analysis, query statistics and other operations. Complete tourism Data Analysis and recommendation based on Big data visualization and management system development.
Keywords:Tourism Attractions,Data Analysis,Hadoop
,Recommendation System
目录
2.5 本章小结 7
3.3 算法介绍 13
3.3.1 基于物品的协同过滤算法 13
3.3.2 计算相似度 13
3.3.3 评估各方指标 13
3.3.4 结果推荐 14
3.4 本章小结 14
4.4 本章小结 20
5.3 系统测试工作概要 27
5.7 本章小结 32
1 引 言
1.1大数据的发展
近年来,基于大数据的技术已经涉及各行各业,网上商城、政府办公、大数据智能分析等服务越来越多[1]。基于互联网大数据的旅游数据智能分析平台会对现存的海量旅游景点信息数据进行数据采集[4],统计与分析,最终以可视化图表的形式展示给广大用户,解决了以往费时费力的人工收集与分析工作。我们这一款旅游景点数据智能分析平台就是以大数据为背景的开发项目。
网络权威知识将大数据认定为在可操作的时间跨度内没有办法使用普通传统手段来捕捉、收集和对其操作的数据集。大数据技术的独到之处不在于拥有巨大的数据信息,而是针对这些数据信息进行有可见效果的特殊加工[1]。换一方面来讲,如果将大数据与一个现有的行业进行对比,那么这个行业赚钱的重中之重在于通过“操作”提升数据的“执行效果”和“额外价值”。
大数据的优点非常明显:
- 在这个大数据火爆的年代,利用其可以处理更多的数据,甚至还可以处理和某一个特殊现象有关的一切数据,而不是简单地依靠随机采样。与受约束在小数据领域相对比,使用大数据为我们带来了更可靠的准确度[2],也使得我们观察到了一些从未发现的细微之处。相比于以往的人工旅游数据分析,我们所采用的数据信息会更广阔,计算速度也会更快更准确,直接为用户带来更值得信赖的服务。第二、就是“大数据就等于风向标”[3],在之前的统计计算中,因为数据量不是过于庞大,那么精确度就成为了相关领域人员所推崇的目标。当我们拥有大量的旅游数据时,精确度不再是我们的主要指标。我们不再需要对一个现象一探究竟,只要知道大致的发展方向就好了。当然,我们也不会彻底放弃正确性,只是不再过度地追求它。第三、不再过度地去找到他们的相关联之处,而是去寻找他们之间的独有的联系。大数据告诉我们“这个是什么”,而不是“怎么样产生这样的结果”[2]。在大数据时代,我们不需要对底层的事物一探究竟,只需要让数据告诉我们分析得到的结果就好。
1.2 系统研究背景与意义
我国旅游景区众多,五千年的历史文明及广袤无垠的疆土为旅游产业提供了有力的客观支持,但是不同的用户对景区地理位置、景观特点、人文历史、出行方式选择等旅游服务需求不尽相同。用户在庞大的旅游资源信息中查询契合需求的出行路线,往往既花费时间又消耗精力,使用传统的旅游搜索方式对于旅游资源信息进行查询使用户感到极大困难[3]。而运用大数据技术对符合相似需求类型的旅游信息进行整理计算和归纳,能够为个体需求提供更加契合的精准服务和更加合理的旅行体验。使用基于Hadoop的MapReduce计算处理框架[2],对旅游景点评价数据进行归纳推理能够为用户提供更加精准舒适的旅行服务。
为了更好的满足人们的旅游需求,摒弃传统出行的各局限性跟上信息时代的高速发展,通过汇编语言开发出能够在线智能搜索的旅游网站,并且能够高效的对其管理的系统成为目前的发展趋势[3]。目前,旅游网站越来越多,其中绝大多是由旅游爱好者和文化部门所创建,百度搜索旅游网站就会看到各种不同的旅游网站,排名前几的有:携程,去哪儿,飞猪,同程,马蜂窝等热门旅游网站[2]。这类网站一般都是独立公司开发出来的产品,网站规模大,旅游信息也比较全面,客户访问人次多,打开他们的首页会发现除了内容布局有所出入,其推荐结果,热门景点,排行榜都是一样的必不可少。除了上述大型的旅游网站,还有一些小型旅游网站,这类小型旅游网站往往规模小,关于旅游信息的内容上也有所侧重,大多为驴友个人所创。
旅游网站给用户和管理员都带来了很大方便,一般旅游网站都是通过数据库管理、软件协作来实现用户与管理员之间的友好操作,由此设计而成[2]。计算机快捷高效的协助管理员解决管理工作可以实现对旅游数据管理自动化的巨大优势,因此计算机成为现代管理应用主要工具也是必然趋势。
1.3 研究内容
本文开发的系统是基于互联网大数据的旅游数据智能分析平台,会通过Scrapy爬虫来爬取各大旅游网站的旅游景点数据,然后对获得的景点信息数据进行规范化,接着对爬取到的信息去除污垢,即数据清洗。过滤掉没有用的信息数据集,例如对于不属于“数据集定义”的取值范围内的数据,自动随机填充一个字典值,检查是否有冗余数据,如果有再进行删除。然后将清洗过滤好的景点信息数据集导入到大数据系统中,利用Spark框架进行数据抽取,多维分析等并行计算从而得出决策图表[3]。将分析好的结果传送给MySQL数据库以方便前端可视化系统中数据明细查询模块的读取与调用,最终以Echarts可视化图表的的形式将分析好的景点数据结果清晰地展示给用户[3]。针对本系统的开发主要准备的工作有:
(1)了解系统的工作流程并撰写关于系统的需求分析。
(2)通过分析确定所需要的技术,并对其进行学习,介绍。
(3)根据系统具体的需要设计出系统的功能框架结构图。
(4)根据系统的需求分析设计出系统总体功能结构图。
(5)设计数据库,编写数据字典。
(6)根据功能编写本系统的开发技术文件。
(7)编写旅游网站代码。
(8)对系统进行模块测试。
1.4 本章小结
本章首先介绍了项目开发的背景和意义,阐明了系统开发的重要性和意义。然后介绍了系统的国内外研究现状,以及本系统对于其他系统的创新之处,接着又描述了本文开发系统的主要工作,最后介绍了论文的主要工作安排和结构、规划开发过程。
2.1 大数据分析较传统分析的优势
过去,“智能分析”这一技术被应用于商业智能世界,提供理论方法和高效的解决速度,通过迅速、一致和能够交互地访问各种类型的信息透视图的优势来得到对应的结果。与分析的基本理论相似的是,数据挖掘已经实施于商业,从而增强了对大量的数据进行分析的机会。目前最困难的就是获得躲在大数据底层的知识。分析传统的数据存储与各公司的海量数据,会得到与之前不一样的结果,慢慢的智能分析的道路与传统理论分析道路会相差更大。
传统分析是对已经存在很久的数据范围进行分析处理[2]。大多数数据存储空间都有一个极为繁琐的提取、转换和加载过程,且数据空间很受限制,这就是说上传到数据空间的分析结果会更加通俗易懂。大数据的最为称赞的长处是,用之前的操作来捕获数据之后对结构复杂的数据进行处理[1]。这也就是说大数据所要分析处理的数据可以是各种各样的。多种多样的信息也会使大数据技术实施起来更有难度,同时相比于传统方法大数据技术会使我们见到不一样的效果。
传统的分析会依赖于已经产生的数据结构体,在这个结构体中,事物与事物之间的大致关系已经存在,因此,传统的分析是在原有结构体的关系中进行数据分析。对于大数据分析而言,一个已经存在已久的世界里很难找到事物与事物之间的独特关系[1],因此,在大数据分析中会考虑到图像、视频、运动生成的信息、射频识别等形式的结构化信息。这会使得大数据分析更有远见。
传统的分析方法是按照一定次序进行的,在获得不可缺少的知识理论前,必须每天晚上等待提取、加工和装载以及加工工作的完成。时间地点都受限。与之相反的是,大数据分析任何时间任何地点都可以进行,使用一些特定工具即可。在传统的分析系统中[3],实时分析是非常麻烦的,费钱费时间,如大型并行处理系统或对称多处理系统。均为费钱费力的数据处理方式。而大数据则是通过一些大数据分析软件进行数据分析,从而获得对应的理论知识。快速、高效、成本低。
2.2.1 技术可行性
技术可行性分析主要在于相关技术条件能否顺利完成开发工作,软硬件能否满足系统的开发需要等。本系统主要采用了IDEA、PyCharm、和MySQL数据库进行相关的开发,能够在处理大量数据的同时保持数据的完整性且提供许多高效管理功能[4]。其所具有的灵活性、安全性和易操作性为数据库编程奠定了坚实的基础。
本系统所使用的开发语言是大数据+Python+Java,并因本人在学习期间有过开发系统的经验,所以在系统的实现方面,本人的技术没有问题,因此在完成本文所述系统在技术上完全具有可行性。
2.2.2 经济可行性
本系统使用到的软件的开发环境都是开源的,因此不需要为软件投入金钱成本,只需投入人力技术进行开发即可,因此该系统在经济上是没有压力的。
2.2.3 操作可行性
整个页面科幻且美观,所需的功能在页面上都能够体现出来,对相关功能模块的操作也非常简单,如果在操作上有不符合的话也会给出相应的温馨提示,让用户知道如何正确的操作该模块。因此在视觉观感上和用户体验上是非常完美的。
2.3 数据分析
2.3.1 利用爬虫框架爬取数据
在开发使用Scrapy爬虫[14]进行爬取相关的旅行网站时,首先要创建一个我们要爬取的项目工程: Scrapy Startproject Profession,然后再明确我们想要抓取的目标,例如Music.py,然后就是需要为爬取到的内容创建一个空间来存储也就是我们所说的旅游数据信息集:Pipelines.py他所得到效果就是利用特定空间来存储结果。最后的步骤就是启动程序的py文件进行数据爬取(Start.py)这条命令也等同于(scrapy crawl xxx -o xxx.json)[6],通过图2-2会展示一些基本常用的爬虫指令。
毕业设计(论文)
题 目: 基于Hadoop的旅游景点
推荐系统的设计与实现
院 (系): 软件学院
专业年级: 软件工程
姓 名: ***
学 号: *********
指导教师: ************************
2022年6月15日
原 创 性 声 明
本人郑重声明:本人所呈交的毕业论文,是在指导老师的指导下独立进行研究所取得的成果。毕业论文中凡引用他人已经发表或未发表的成果、数据、观点等,均已明确注明出处。除文中已经注明引用的内容外,不包含任何其他个人或集体已经发表或撰写过的科研成果。对本文的研究成果做出重要贡献的个人和集体,均已在文中以明确方式标明。
本声明的法律责任由本人承担。
论文作者签名: 日 期:
关于毕业论文使用授权的声明
本人在指导教师指导下所完成的论文及相关的资料(包括图纸、试验记录、原始数据、实物照片、图片、录音带、设计手稿等),知识产权归属平顶山学院。本人完全了解平顶山学院有关保存、使用毕业论文的规定,同意学校保存或向国家有关部门或机构送交论文的纸质版和电子版,允许论文被查阅和借阅;本人授权*******可以将本毕业论文的全部或部分内容编入有关数据库进行检索,可以采用任何复制手段保存和汇编本毕业论文。如果发表相关成果,一定征得指导教师同意,且第一署名单位为********。本人离校后使用毕业论文或与该论文直接相关的学术论文或成果时,第一署名单位仍然为*******。
论文作者签名: 日 期:
指导教师签名: 日 期:
基于Hadoop的旅游景点推荐系统的设计与实现
摘 要
随着人们的生活水平不断提高,旅游行业顺势快速发展。面对多样化的旅游出行需求,用户很难在庞大的资源数据中找到契合自身的信息。运用 Hadoop 大数据技术对相似的信息进行整理归纳为用户提供更加的旅游出行方案,是本人提出的旅游景点信息化方案。
因此本文阐述了一款基于大数据计算框架对旅游景点数据进行分析与推荐的软件系统,实现了对数据采集、数据处理与分析、数据可视化展示为一体的操作,基本满足为用户推荐心仪旅游景点的需求。
本系统主要由大数据系统、可视化前端系统、web后台管理系统、景点推荐系统、旅游景点APP端组成。大屏统计端使用hadoop+spark完成,数据采集使用Python离线分析端、网页用户端以及后台管理使用Springboot+mybatis框架开发,在可视化阶段采用Echarts来提供可交互的直观数据可视化图表。此外本系统采用MySQL数据库,其目的是存储利用爬虫爬取到的大量旅游景点信息数据集和数据处理之后的分析结果,再通过Spark并行计算进行数据抽取,多维分析,查询统计等操作来完成数据分析。完成基于大数据的旅游数据分析推荐可视化与管理一体的系统开发。
关键词: 旅游景点、Hadoop、推荐系统
Design and Implementation of Scenic Spot Recommendation System based on Hadoop
Abstract
With the continuous improvement of people's living standards, the Tourism industry develops rapidly. In the face of diverse travel needs, it is difficult for users to find relevant information in the huge resource data. Hadoop big data technology is used to sort out and summarize similar types of information to provide intelligent travel guarantee for users, which is the Tourist attraction information scheme proposed by me.
This system describes a software system for Tourism Data Analysis and Recommendation based on the big data computing framework, which realizes the operation of data collection, data processing and analysis, and data visualization, and basically meets the needs of recommending Tourism for users.
The system is mainly composed of big data system, Visual front-end system, Web background management system, Tourism Recommendation System, Tourism small program /APP end. The large-screen statistical end is completed by Hadoop + Spark, data collection is developed by Python offline analysis end, web client end and background management using Springboot+ Mybatis framework. In the visualization stage, Echarts is used to provide interactive intuitive data visualization charts. The database used in this system is MySQL database, which is used to store a large number of music information data sets obtained by crawler and the analysis results after data processing. Data analysis is completed through Spark parallel computing for data extraction, multidimensional analysis, query statistics and other operations. Complete tourism Data Analysis and recommendation based on Big data visualization and management system development.
Keywords:Tourism Attractions,Data Analysis,Hadoop
,Recommendation System
目录
2.5 本章小结 7
3.3 算法介绍 13
3.3.1 基于物品的协同过滤算法 13
3.3.2 计算相似度 13
3.3.3 评估各方指标 13
3.3.4 结果推荐 14
3.4 本章小结 14
4.4 本章小结 20
5.3 系统测试工作概要 27
5.7 本章小结 32
1 引 言
1.1大数据的发展
近年来,基于大数据的技术已经涉及各行各业,网上商城、政府办公、大数据智能分析等服务越来越多[1]。基于互联网大数据的旅游数据智能分析平台会对现存的海量旅游景点信息数据进行数据采集[4],统计与分析,最终以可视化图表的形式展示给广大用户,解决了以往费时费力的人工收集与分析工作。我们这一款旅游景点数据智能分析平台就是以大数据为背景的开发项目。
网络权威知识将大数据认定为在可操作的时间跨度内没有办法使用普通传统手段来捕捉、收集和对其操作的数据集。大数据技术的独到之处不在于拥有巨大的数据信息,而是针对这些数据信息进行有可见效果的特殊加工[1]。换一方面来讲,如果将大数据与一个现有的行业进行对比,那么这个行业赚钱的重中之重在于通过“操作”提升数据的“执行效果”和“额外价值”。
大数据的优点非常明显:
- 在这个大数据火爆的年代,利用其可以处理更多的数据,甚至还可以处理和某一个特殊现象有关的一切数据,而不是简单地依靠随机采样。与受约束在小数据领域相对比,使用大数据为我们带来了更可靠的准确度[2],也使得我们观察到了一些从未发现的细微之处。相比于以往的人工旅游数据分析,我们所采用的数据信息会更广阔,计算速度也会更快更准确,直接为用户带来更值得信赖的服务。第二、就是“大数据就等于风向标”[3],在之前的统计计算中,因为数据量不是过于庞大,那么精确度就成为了相关领域人员所推崇的目标。当我们拥有大量的旅游数据时,精确度不再是我们的主要指标。我们不再需要对一个现象一探究竟,只要知道大致的发展方向就好了。当然,我们也不会彻底放弃正确性,只是不再过度地追求它。第三、不再过度地去找到他们的相关联之处,而是去寻找他们之间的独有的联系。大数据告诉我们“这个是什么”,而不是“怎么样产生这样的结果”[2]。在大数据时代,我们不需要对底层的事物一探究竟,只需要让数据告诉我们分析得到的结果就好。
1.2 系统研究背景与意义
我国旅游景区众多,五千年的历史文明及广袤无垠的疆土为旅游产业提供了有力的客观支持,但是不同的用户对景区地理位置、景观特点、人文历史、出行方式选择等旅游服务需求不尽相同。用户在庞大的旅游资源信息中查询契合需求的出行路线,往往既花费时间又消耗精力,使用传统的旅游搜索方式对于旅游资源信息进行查询使用户感到极大困难[3]。而运用大数据技术对符合相似需求类型的旅游信息进行整理计算和归纳,能够为个体需求提供更加契合的精准服务和更加合理的旅行体验。使用基于Hadoop的MapReduce计算处理框架[2],对旅游景点评价数据进行归纳推理能够为用户提供更加精准舒适的旅行服务。
为了更好的满足人们的旅游需求,摒弃传统出行的各局限性跟上信息时代的高速发展,通过汇编语言开发出能够在线智能搜索的旅游网站,并且能够高效的对其管理的系统成为目前的发展趋势[3]。目前,旅游网站越来越多,其中绝大多是由旅游爱好者和文化部门所创建,百度搜索旅游网站就会看到各种不同的旅游网站,排名前几的有:携程,去哪儿,飞猪,同程,马蜂窝等热门旅游网站[2]。这类网站一般都是独立公司开发出来的产品,网站规模大,旅游信息也比较全面,客户访问人次多,打开他们的首页会发现除了内容布局有所出入,其推荐结果,热门景点,排行榜都是一样的必不可少。除了上述大型的旅游网站,还有一些小型旅游网站,这类小型旅游网站往往规模小,关于旅游信息的内容上也有所侧重,大多为驴友个人所创。
旅游网站给用户和管理员都带来了很大方便,一般旅游网站都是通过数据库管理、软件协作来实现用户与管理员之间的友好操作,由此设计而成[2]。计算机快捷高效的协助管理员解决管理工作可以实现对旅游数据管理自动化的巨大优势,因此计算机成为现代管理应用主要工具也是必然趋势。
1.3 研究内容
本文开发的系统是基于互联网大数据的旅游数据智能分析平台,会通过Scrapy爬虫来爬取各大旅游网站的旅游景点数据,然后对获得的景点信息数据进行规范化,接着对爬取到的信息去除污垢,即数据清洗。过滤掉没有用的信息数据集,例如对于不属于“数据集定义”的取值范围内的数据,自动随机填充一个字典值,检查是否有冗余数据,如果有再进行删除。然后将清洗过滤好的景点信息数据集导入到大数据系统中,利用Spark框架进行数据抽取,多维分析等并行计算从而得出决策图表[3]。将分析好的结果传送给MySQL数据库以方便前端可视化系统中数据明细查询模块的读取与调用,最终以Echarts可视化图表的的形式将分析好的景点数据结果清晰地展示给用户[3]。针对本系统的开发主要准备的工作有:
(1)了解系统的工作流程并撰写关于系统的需求分析。
(2)通过分析确定所需要的技术,并对其进行学习,介绍。
(3)根据系统具体的需要设计出系统的功能框架结构图。
(4)根据系统的需求分析设计出系统总体功能结构图。
(5)设计数据库,编写数据字典。
(6)根据功能编写本系统的开发技术文件。
(7)编写旅游网站代码。
(8)对系统进行模块测试。
1.4 本章小结
本章首先介绍了项目开发的背景和意义,阐明了系统开发的重要性和意义。然后介绍了系统的国内外研究现状,以及本系统对于其他系统的创新之处,接着又描述了本文开发系统的主要工作,最后介绍了论文的主要工作安排和结构、规划开发过程。
2.1 大数据分析较传统分析的优势
过去,“智能分析”这一技术被应用于商业智能世界,提供理论方法和高效的解决速度,通过迅速、一致和能够交互地访问各种类型的信息透视图的优势来得到对应的结果。与分析的基本理论相似的是,数据挖掘已经实施于商业,从而增强了对大量的数据进行分析的机会。目前最困难的就是获得躲在大数据底层的知识。分析传统的数据存储与各公司的海量数据,会得到与之前不一样的结果,慢慢的智能分析的道路与传统理论分析道路会相差更大。
传统分析是对已经存在很久的数据范围进行分析处理[2]。大多数数据存储空间都有一个极为繁琐的提取、转换和加载过程,且数据空间很受限制,这就是说上传到数据空间的分析结果会更加通俗易懂。大数据的最为称赞的长处是,用之前的操作来捕获数据之后对结构复杂的数据进行处理[1]。这也就是说大数据所要分析处理的数据可以是各种各样的。多种多样的信息也会使大数据技术实施起来更有难度,同时相比于传统方法大数据技术会使我们见到不一样的效果。
传统的分析会依赖于已经产生的数据结构体,在这个结构体中,事物与事物之间的大致关系已经存在,因此,传统的分析是在原有结构体的关系中进行数据分析。对于大数据分析而言,一个已经存在已久的世界里很难找到事物与事物之间的独特关系[1],因此,在大数据分析中会考虑到图像、视频、运动生成的信息、射频识别等形式的结构化信息。这会使得大数据分析更有远见。
传统的分析方法是按照一定次序进行的,在获得不可缺少的知识理论前,必须每天晚上等待提取、加工和装载以及加工工作的完成。时间地点都受限。与之相反的是,大数据分析任何时间任何地点都可以进行,使用一些特定工具即可。在传统的分析系统中[3],实时分析是非常麻烦的,费钱费时间,如大型并行处理系统或对称多处理系统。均为费钱费力的数据处理方式。而大数据则是通过一些大数据分析软件进行数据分析,从而获得对应的理论知识。快速、高效、成本低。
2.2.1 技术可行性
技术可行性分析主要在于相关技术条件能否顺利完成开发工作,软硬件能否满足系统的开发需要等。本系统主要采用了IDEA、PyCharm、和MySQL数据库进行相关的开发,能够在处理大量数据的同时保持数据的完整性且提供许多高效管理功能[4]。其所具有的灵活性、安全性和易操作性为数据库编程奠定了坚实的基础。
本系统所使用的开发语言是大数据+Python+Java,并因本人在学习期间有过开发系统的经验,所以在系统的实现方面,本人的技术没有问题,因此在完成本文所述系统在技术上完全具有可行性。
2.2.2 经济可行性
本系统使用到的软件的开发环境都是开源的,因此不需要为软件投入金钱成本,只需投入人力技术进行开发即可,因此该系统在经济上是没有压力的。
2.2.3 操作可行性
整个页面科幻且美观,所需的功能在页面上都能够体现出来,对相关功能模块的操作也非常简单,如果在操作上有不符合的话也会给出相应的温馨提示,让用户知道如何正确的操作该模块。因此在视觉观感上和用户体验上是非常完美的。
2.3 数据分析
2.3.1 利用爬虫框架爬取数据
在开发使用Scrapy爬虫[14]进行爬取相关的旅行网站时,首先要创建一个我们要爬取的项目工程: Scrapy Startproject Profession,然后再明确我们想要抓取的目标,例如Music.py,然后就是需要为爬取到的内容创建一个空间来存储也就是我们所说的旅游数据信息集:Pipelines.py他所得到效果就是利用特定空间来存储结果。最后的步骤就是启动程序的py文件进行数据爬取(Start.py)这条命令也等同于(scrapy crawl xxx -o xxx.json)[6],通过图2-2会展示一些基本常用的爬虫指令。
为了能够很好地进行cooutine操作,Python研发了很多的数据空间存储机制。Python认为比AMQP是非常有效的机制之一,ZeroMQ是首例向Python提供研发版本的[6]。为了进行高效的实时处理,爬虫可以爬取大量的数据集。通过爬虫所得到的数据要进行分类处理[8],Python不弱于Scrapy,有着很出名的语言处理包NLTK和专业的分区处理工具Jieba,都是创建分区所用的。还有另外的一种编程语言就是R语言。开发语言Python与开发语言R相比速度要快。Python可以直接应对G的数据;R不行,R语言做数据分析处理时需要将大量的数据利用特有的数据处理方法将其分成小部分,因此R不能直接得到大数据的分析结果,只能分析统计结果[7]。所以有人说: Python=R+SQL/Hive,这也是可通的。R语言与Python语言的集体差别如表3-1所示。
如果实现理论是唯一的领域,那么R语言应该在数据科学家中最受欢迎,但R语言存在明显的问题,由于是统计学家创造了它,因此它的语法与其他语言相比有点奇怪。此外,R语言需要创立许多的工程文件来管理其独有的分布式系统。因此,有一些公司再利用R语言创立好算法之后就会采用其他的开发语言,与之相比,Python已经成为当今用户最喜欢的开发语言之一[8]。
原因是,Python他本来就是一种可以直接开发的语言。专业的开发人员利用Python语言研发了独有的算法之后就可以将其直接利用到产品之上,这就意味着用户和公司可以大大地节省时间。
表3-1 Python与R的详细对比图
| 指标项 | Python | R | 说明 |
| 代码执行效率 | 3 | 2.5 | 大数据量下R表现较差 |
| 功能实现效率 | 3 | 4.5 | R的代码量少于Python |
| 包的数量 | 4 | 4 | 6000+ |
| 可视化能力 | 4.5 | 4 | Python可视化能力较强 |
| 分析能力 | 4 | 4.5 | R专注于分析领域 |
| IDE | 4 | 1 | R只有一个IDE Rstudio |
| 学习难度 | 1.5 | 1 | 都属于易学难精的语言 |
| 社区活跃度 | 4 | 3 | 暂无 |
| 中文帮助 | 3 | 2 | Python第三方帮助较多 |
3.2.3 MySQL数据库
MySQL数据库之所以能被广泛应用是因为其独特的特点更适合应用于个人及小型企业,MySQL具有以下特点及优势:
(1)完全开源
MySQL最引人注目的优势就是相比于其他数据库它是开源的。当然,开源并不意味着完全地免费,对于某些部分还是要收费的。但是开源特性这就可以使得用户自己能够独立地进行某些机制的修改。MySQL采用GPL,这也就是说用户可以按照自己的意愿来修改源代码。
(2)快速和易于使用的更新
相比于存在于当代的其他数据相比,MySQL数据库的更新操作会更快。每当有了新的版本要发布的时候,MySQL数据库就会第一时间告知用户。Linux web服务器已经在用户方面取得了巨大的成效,MySQL在Linux上面也取得了不错的应用效果。
1、MySQL数据库不是很强大,但是它有很多优点:
2、可以应用于大部分的开发软件,确保源代码的可移植性。
3、支持各种操作系统。
4、为现存的开发软件提供了API。
5、支持多线程操作来为cpu节省资源。
6、优化了查询算法,节省了查询的时间。
7、它可以独立地应用于某一个网络服务中,也可以作为一个独立的数据存储空间应用于其他开发软件。
8、提供多语言支持。
9、为用户提供多个数据连接方式。
10、为用户管理数据库提供了许多管理工具。
11、支持各种各样的数据存储引擎。
12、MySQL是开源的,你可以免费试用。[5]
3.2.4 Spark分析介绍
Spark应用执行机制:
在提交应用程序之后,Spark将经历一系列转换,这些转换最终将成为每个节点上要执行的任务。RDD操作符触发作业提交,发送到作业生成RDD DAG[9]。
从DAGScheduler转换到dag阶段,每个阶段都会生成相应的任务集合TaskScheduler将事务处理任务分配给执行器执行,每个处理任务对应一个相应的数据块,由用户自己定义的函数处理。
Spark除了执行分发、追踪、执行操作等任务外,还实现了对分布式计算和事务任务处理。总结归纳最终结果,完成Spark应用程序的计算[10]。
RDD对事务的管理是通过块进行操作管理的。BlockManager将数据抽象为存储在内存或磁盘中的数据块;如果数据不在本地节点上,计算也可以通过远程节点复制到本地机器上。
scala的特点:具有很好的兼容性、对编程有了很大的支持、对分布式系统的支持、简洁的语法和提供api的支持,scala与java兼容,工作效率非常高,可以集成到hadoop生态系统中。
Spark运行基本原理:
为项目创建基本的开发环境,通过dirver创建一个SparkContext,合理安排并监视数据资源的使用情况。
资源管理器为其分配资源并启动执行过程。
SparkContext根据RDD的之间独有的关系构建DAG图,DAG图提交给DAGScheduler进行有次序地分析,然后交付到最下面一层的taskscheculer[11]进行处理。管理者将任务发送于SparkContext, taskscheduler将任务发送给管理者并向用户提供有关的代码。
任务执行执行器并将结果反馈给TaskScheduler,对反馈进行排序,最后释放资源 。
3.2.5 Spring Boot介绍
微服务架构,Spring Boot 是由 Pivotal 团队提供的全新框架,它是Java平台上的一种开源应用框架,它在继承了Spring框架的优点同时简化了部分配置。严格来说Spring Boot 就是一些库的集合。由于Spring Boot 提供自动化配置,因此在使用Spring Boot 时只需要编写必要的代码配置必需的属性就可以使开发过程简便、快捷、高效的完成。
3.2.6 Vue开发
Vue.js是一套轻量级的框架,主要用于构建前端的渐进式javascript框架,它和其它框架不同之处是,它的设计是可以自底层向上逐层应用,其核心是数据驱动和组件系统,由此形成了高内聚、低耦合的vue前端架构。
Vue的明显优势是可以实现数据的双向绑定,不去关注DOM层接口,只关心数据层,可通过简单的API实现响应式的数据绑定和试图渲染;
Vue还是一个javascriptMVVM库,可以实现model、view和ViewModel的三方面的双向渲染;
3.3 算法介绍
3.3.1基于物品的协同过滤算法
ItemCF:ItemCollaborationFilter,基于物品的协同过滤,该算法的核心思想:给用户推荐和他们之前喜欢的物品相似的物品。该算法认为物品A和B具有很大的相似度是因为喜欢物品A的用户大概率也喜欢物品B。基于物品的协同过滤算法过程主要分为两步:
1.计算n个物品之间的相似度;
2.根据物品的相似度和用户的往常行为提供生成的推荐列表;
3.3.2 计算相似度
这里我们采用皮尔逊相关系数表示两个定距变量间联系的紧密程度,取值范围为[-1,1]
3.3.4 结果推荐
以旅游景点信息推荐举例:
- 循环读取每个用户及其旅游过的景点,并统计每个旅游景点被旅行过的次数,以及旅游景点总数;
- 计算矩阵C,C[i][j]表示同时喜欢旅游景点i和j的用户数,并考虑对活跃用户的惩罚;
- 根据公式\ref{similarity}计算景点间的相似性;
- 进行归一化处理。
针对目标用户U,找到K个相似的旅游景点,并推荐其N个景点,如果用户已经旅行过该景点则不推荐。产生推荐并通过准确率、召回率和覆盖率进行评估。
3.4本章小结
本章对Hadoop开发、Python分析、MySQL数据库、Spark分析、Spring Boot框架、Vue开发以及基于物品的协同过滤算法等后续设计本系统需要用到的技术、软件、工具、平台和原理做了全面的阐述,尤其是对基于物品的协同过滤算法的原理,计算相似度的方法和生成推荐结果甚至评估准确率等方面做了充分的描述,便于后续的系统搭建操作。
4 总体设计
4.1大数据系统的设计
4.1.1整体模块设计
本环节主要讲述的是对于整体项目功能的设计,设计方案主要是由大数据系统、可视化系统web前后端管理组成。在web管理系统中主要是采用了Springboot框架、mybatis框架,因为其去繁就简的特点,很容易创建一个独立的产品级应用,在可视化阶段采用Echarts来提供可交互的直观数据可视化图表。本系统采用的数据库是MySQL数据库[19],其目的是用来存储利用爬虫爬取到的大量旅游信息数据集和数据处理之后的分析结果。大数据系统中主要是对旅游景点信息数据集通过使用Hive进行数据清洗,然后再导入Hadoop 中存储。在通过Spark并行计算进行数据抽取,多维分析,查询统计等操作来完成数据分析部分[12]。系统中的数据明细查询功能中读取到MySQL数据库中的数据分析结果,最后生成Echarts图表展示给用户。
4.1.2 数据采集功能设计
针对于旅游景点信息数据集的采集在上文已经提及到会采用爬虫Scrapy框架对现有的旅游数据分析网站进行数据爬取,以供大数据旅游数据分析系统的使用,那么我会通过下文具体介绍一下是怎么通过爬虫框架从现有庞大的数据体系系统中爬取数据集。
那我们在使用爬虫Scrapy框架为大数据系统爬取旅游信息数据集的时候一般会有四大步骤[14],分别是获取我们所要爬取的旅游数据网站的网页链接,对爬取到的旅游信息数据集进行暂时存储,然后对数据进行预处理[15],也就是数据清洗操作,最后一步就是利用数据,整个爬取数据的过程我会通过图4-1展示出来,结合具体的文字信息以便理。
骤1:获取到旅游数据web页面的链接
(1)为了满足观察页的规律变化的多种需要,基本上只是一小部分的改动,比如:一些网站的url在改变,所以这类可以通过数字化来改变链接的网页;
(2)将获得的多个web页面链接存储在字典中,字典充当临时数据库,在需要时通过函数调用直接提供;
(3)需要注意的是,我们的抓取任务不能由任何url完成,我们需要遵循我们的抓取协议,许多网站不能抓取。例如:淘宝、腾讯等较为私密的网页;
(4)爬虫时代,网站基本上都有一个相应的反-reptiliano机制[14],当我们找到错误消息404拒绝访问,可以得到用户代理来掩盖你的访问,爬虫类的采购信息由机器伪装成人进行操作,而不是一个项目,进而达到收购的web页面的内容。
步骤2:数据存储
(1)爬虫所爬取的网页,数据存储在原始网页的数据库中。其中页面数据与用户浏览器获得的HTML完全相同;
(2)搜索页面的引擎,会对重复的内容进行一定的检测,一旦遇到大量的内容被复制、收集或复制到一个访问量较低的网站上,很可能就不会再爬行了;
步骤3:预处理(数据清理)
(1)当我们得到数据时,很多时候一些数据会很乱,需要很多空间和一些标签等等,现在我们必须删除数据中不需要的部分,以提高数据的美观和可用性;
(2)您也可以使用我们的软件可视化模型数据,直观地可视化数据内容;
4.1.3 数据处理与分析功能设计
本环节主要介绍基于Spark框架对旅游数据集进行处理分析[16]的功能模块设计与处理旅游景点信息数据集所使用到的方法。我会通过图4-2来展示出大数据旅游数据分析系统在对数据集进行处理分析的具体流程。
Spark框架在大数据分析系统中的具体工作流程为:
- 创建Spark应用程序的执行环境并启动SparkContext。[17]
- SparkContext到资源管理器(Mesos、Yarn)资源来运行执行器,并启动 StandaloneExecutorbackend。
- 执行器向SparkContext申请任务。
- SparkContext将应用程序分发给执行者。
- SparkContext构建为DAG图,DAG图被划分为阶段,任务被发送到任务的调度器,最后任务被发送到Ex&cutor操作。
- 任务在执行器中执行,执行后释放所有资源。
- 创建Spark应用程序的执行环境并启动SparkContext。
- SparkContext到资源管理器(Mesos、Yarn)资源来运行执行器,并启动StandaloneExecutorbackend。
(9)执行器向SparkContext申请任务。
(10)SparkContext将应用程序分发给执行者。
(11)SparkContext构建为DAG图,DAG图被划分为阶段,任务被发送到任务的调度器,最后任务被发送到Ex&cutor操作。
(12)任务在执行器中执行,执行后释放所有资源。
(4)爬虫时代,网站基本上都有一个相应的反-reptiliano机制[14],当我们找到错误消息404拒绝访问,可以得到用户代理来掩盖你的访问,爬虫类的采购信息由机器伪装成人进行操作,而不是一个项目,进而达到收购的web页面的内容。
步骤2:数据存储
(1)爬虫所爬取的网页,数据存储在原始网页的数据库中。其中页面数据与用户浏览器获得的HTML完全相同;
(2)搜索页面的引擎,会对重复的内容进行一定的检测,一旦遇到大量的内容被复制、收集或复制到一个访问量较低的网站上,很可能就不会再爬行了;
步骤3:预处理(数据清理)
(1)当我们得到数据时,很多时候一些数据会很乱,需要很多空间和一些标签等等,现在我们必须删除数据中不需要的部分,以提高数据的美观和可用性;
(2)您也可以使用我们的软件可视化模型数据,直观地可视化数据内容;
4.1.3 数据处理与分析功能设计
本环节主要介绍基于Spark框架对旅游数据集进行处理分析[16]的功能模块设计与处理旅游景点信息数据集所使用到的方法。我会通过图4-2来展示出大数据旅游数据分析系统在对数据集进行处理分析的具体流程。
Spark框架在大数据分析系统中的具体工作流程为:
- 创建Spark应用程序的执行环境并启动SparkContext。[17]
- SparkContext到资源管理器(Mesos、Yarn)资源来运行执行器,并启动 StandaloneExecutorbackend。
- 执行器向SparkContext申请任务。
- SparkContext将应用程序分发给执行者。
- SparkContext构建为DAG图,DAG图被划分为阶段,任务被发送到任务的调度器,最后任务被发送到Ex&cutor操作。
- 任务在执行器中执行,执行后释放所有资源。
- 创建Spark应用程序的执行环境并启动SparkContext。
- SparkContext到资源管理器(Mesos、Yarn)资源来运行执行器,并启动StandaloneExecutorbackend。
(9)执行器向SparkContext申请任务。
(10)SparkContext将应用程序分发给执行者。
(11)SparkContext构建为DAG图,DAG图被划分为阶段,任务被发送到任务的调度器,最后任务被发送到Ex&cutor操作。
(12)任务在执行器中执行,执行后释放所有资源。
通过上图4-6内容的帮助理解,我来详细介绍一下旅游数据在数据库中的整个流程。
我们首先假设有一写数据(线程A)一读数据(线程B)操作,先操作缓存,再操作数据库,那么大致流程如下:
(1)线程A发起—个写操作,第—步删除缓存
(2)线程A第二步写入新数据到分布式数据库系统中
(3)线程B发起一个读操作,隐藏缓存
(4)线程B从数据库中获取最新数据
(5)请求B同时建立缓存
(6)旅游景点数据完成在数据库中的读写操作
4.4 本章小结
本章首先介绍了系统的大数据系统结构设计、整体功能模块设计、数据采集功能设计、数据处理与分析功能设计、web前后端系统的设计、数据库设计。然后从数据需求分析出发,阐述了该系统主要功能模块的设计理念并对数据在数据库中的读写流程做了描述。
5.3 系统测试工作概要
在这部分主要是通过以下几方面对系统进行测试,测试类型其中包括:
1、安全测试:对用户的非法请求例如密码输入错误进行测试。
2、压力测试:爬取庞大的旅游数据信息让系统进行分析看系统能否正常运行。
3、功能测试:对整个系统进行全面的测试,测试每一模块是否能正常运行。
5.4 测试方法
1、单元测试:将系统分割为各个功能模块,对每个模块都进行测试,检测功能是否符合预期要求。
2、循环测试:将测试后的内容再次进行测试,应用不同的形式进行测试确保系统稳定运行。
3、集成测试: 将整个系统统一的进行测试,根据各个业务的联通,测试数据的流通是否正确。
5.5 系统功能模块测试
5.5.1 注册登录模块测试
对用户注册登录和管理员登录功能的测试,注册登录模块测试用例表如表5-1所示。
表5-1 注册登录模块测试用例表
| 功能 | 测试步骤 | 预期结果 |
| 管理员登录 |
|
|
| 用户注册 |
|
|
续表5-1
| 用户登录 | 1.使用空白账号 2.使用空白密码 3.使用错误的账号或密码登录 4.使用正确的账号登录 | 1.请输入账号 2.请输入密码 3.账号或密码错误 4.登录成功 |
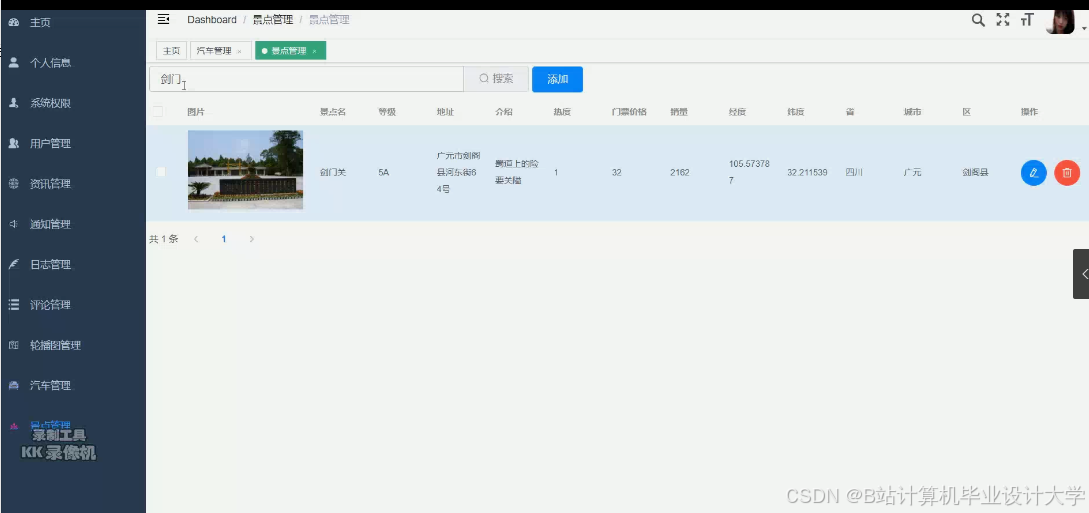
5.5.2 旅游景点管理模块测试
对管理员管理景点信息和用户浏览景点信息功能的测试。景点管理模块测
试用例如表5-2所示。
表5-2 旅游景点管理模块测试用例如表
| 序号 | 功能 | 测试步骤 | 预期结果 |
| 1 | 用户浏览景点信息 | 1.进入4A专区 2.进入5A专区 3.进入旅游景点浏览区 | 1.显示分类为4A级的景点列表 2.显示分类为5A级的景点列表 3.跳转到景点信息介绍视频页 |
| 2 | 管理员添加景点信息 |
3.景点信息填写正确并提交 | 1.请填写景点信息 2.景点详情多于32字 3.景点信息添加成功 |
| 3 | 管理员编辑景点信息 | 1.未选中景点信息 2.选中景点点击编辑按钮 3.编辑要修改的景点信息并提交 | 1.请选择一条景点 2.跳转到景点信息修改页面并显示当前景点 2.景点信息修改成功 |
| 4 | 管理员删除景点信息 |
|
|
5.5.3 评论管理模块测试
对用户发表景点评论和管理员管理景点评论功能的测试。评价管理模块的测试用例如表5-3所示。
表5-3 评价管理模块的测试用例表
| 序号 | 功能 | 测试步骤 | 预期结果 |
| 1 | 用户评论景点 | 1.未编辑景点信息点击提交按钮 2.编辑景点信息点击提交按钮 | 1.请填写评论 2.评论成功 |
| 2 | 管理员删除景点评论 | 1.未选中评论点击删除按钮 2.选中评论点击删除按钮 | 1.请选择一条景点评论 2.删除成功 |
5.5.4用户管理模块测试
对用户修改个人信息和管理员管理用户信息的用例测试。用户管理模块测试用例如表5-4所示。
表5-4 用户管理模块测试用例表
| 序号 | 功能 | 测试步骤 | 预期结果 |
| 1 | 管理员查看订单 | 1.修改用户名为空 2.修改密码为空 3.修改手机号码为空 4.修改电子邮箱为空 5.全部信息填写规范后提交 | 1.请填写用户名 2.请填写密码 3.请填写手机号码 4.请填写电子邮箱 5.修改成功 |
| 2 | 管理员修改用户密码 | 1.未选中用户点击修改密码按钮 2.选中用户修改用户密码 3.未选中用户点击删除按钮 4.选中用户点击删除按钮 | 1.请选择一条用户信息 2.修改成功 3.请选择一条用户信息 4.删除成功 |
测试的意义
软件在进行正式的应用前,一般都要经过多次测试,主要测试开发出来的软件内容和最初的设计是否相符,系统各个模块的功能是否好用,信息的展示是否正确,页面的展示是否简洁美观,系统的操作是否快捷,系统的页面布局是否符合用户操作网站的习惯。如果系统无法通过测试,即代表该系统无法进行应用,系统可以经过测试发现许多的漏洞并对其进行完善,这会让系统更加的具有使用价值。通过以上测试,可以得到用例测试输出的结果,通过对比测试结果和期待结果能够确定系统是否需要进行改进。若两者差别较大,则说明系统的该模块需要进行改进。若两者差别较小,则可以再选取几组测试数据进行测试,直到找出系统内Bug所在,接着对其进行修复。本次测试页面效果符合之前的设计,测试结果和预期结果基本一致。
5.7 本章小结
本章介绍了旅游景点推荐系统具体功能的开发实现和测试。对旅游景点推荐系统的用户注册登录功能、旅游景点检索、相似景点自动推荐、后台评论和景点管理,前后端可视化等几个功能模块进行了详细的测试和介绍,并对对各个功能模块进行测试和界面展示,既验证和弥补了系统的漏洞又让用户更加直观的看到旅游景点推荐系统的效果。
7 总 结
通过本次的毕业设计让我在诸多方面都收获了很多知识,具体的我会通过以下几个方面进行总结。
首先,我的毕业设计研究题目是基于Hadoop的旅游景点推荐系统的设计与实现,针对于此课题,我大致完成了以下几个方面的任务:
首先是前期对大数据智能分析由浅入深的理解,通过网上的快速培训学会了Python开发语言,为后期搭建项目打下了基础。其次就是系统地将整个旅游数据分析系统分成了三大模块,分别是数据收集,数据处理与分析,数据展示。在数据收集阶段,我主要学习scrapy爬虫框架,利用此框架来爬取旅游信息作为整个旅游数据分析系统的数据源。再者就是数据处理与分析层次,我从相关的项目中了解到,大数据分析一般都会使用spark计算框架来对大数据进行分析,于是我选择通过论坛以及网络课程的视频来学习如何应用spark框架,并将其运用到我的项目中。最后在数据展示方面,我选用的是Java语言开发,因为在校期间,老师带领我们完成了很多Java前后台交互的案例,所以说在这方面还有一定的基础,通过echarts工具来完成分析结果的可视化展示。因为个人的技术掌握的不太牢靠,只是完成了基础的项目功能,不能对旅游数据更细致的功能进行深究,其中在数据的存储与安全方面,我感觉做的不够好。因为我对于数据的保护层次只能依赖于数据库原有的数据加密,那么外界很容易就会获得旅游数据的明确信息,所以还要通过后期的学习来完善数据安全。也是通过此次毕业课程设计,让我不再小看在校所学到的知识。
参考文献
[1]田啸.大数据环境下计算机应用技术研究[J.电脑知识与技术]2019(14):246-247.
[2]侯聪聪.计算机软件技术在大数据时代的应用[J.电脑知识与技术]2018(14):240-241.北京:清华大学出版社,2016.335-340
[3]于知言.计算机应用技术在大数据时代的运用前景研究[J.知识文库]2017(15):107.
[4]李超科.计算机大数据分析及云计算网络技术发展探究[叮.计算机产品与流通]2019(11):12
[5]吴晓玲,邱珍珍.基于云存储架构的分布式大数据安全容错存储算法[J.中国电子科学研究院学报]2018,13(6):720-724.
[6]张若愚.Python 科学计算[M].北京:清华大学出版社.2016
[7]RobertCimman,Eduart Rohan-Multiscale finite element calculations in Python using SfePy.-2019.vol.45
[8]Linwei He,Matthew Gibert-A Python script for adaptive layout optimization of trusses.-2019.vol.69
[9]Elservierjournal-Python programming on win64.-2016.6.2
[10]xuezhisdc[优快云].Spark基础知识-2019.07.31
[11]烟雨任平生[优快云].Spark工作原理及基础概念-2020.11.24
[12]罗东健.大规模存储系统高可靠性关键技术研究[D].华中科技大学2016
[13]cangyu2013[优快云].SparkStreaming原理-2018.12.15
[14]蒲公英上的尘埃[优快云].爬虫的原理和思路-2018.07.26
[15]zhusongzhiye[优快云].Python分布式爬虫原理-2018.05.25
[16]风雨飘摇[优快云].Spark基本架构及原理-2017.03.08
[17]black_hnu[优快云].Spark原理:概念与架构,工作机制-2018.09.03
[18]mokingone[优快云].Mybatis快速入门和重点讲解-2018.07.23
[19]llgeoywq[优快云].Spark高级数据分析-2016.11.21
[20]lkkskdf[优快云].Spark SQL内部解析-2018.05.0
致 谢
大学四年光阴转瞬即逝,还清晰记得刚登入大学殿堂的样子,仿佛就如昨天刚刚发生。在这里感谢我的母校,给予我浓厚的学习氛围,使得我在大学四年能有所收获,更离不开诸位老师的谆谆教诲。是他们敦促平时慵懒散漫的我,让我勤奋好学。在这里,我要郑重地感谢我的毕业设计指导老师张老师,张老师在QQ与我沟通的时候给人一种和蔼可亲的形象,所以说我对张老师印象就特别好,把他当做我的良师益友,没想到后来发现他是个年轻的小伙子。当我有什么难以解决的问题时,我就会向张老师请教,张老师在课余时间就会立即为我提出的问题作答,真的十分感谢张老师为我做的详细解答。再就是我也要感谢我班的同学们,因为在课下的闲余时间,陪伴我度过了大学生涯的绝大部分时光,我们有说有笑,同样我们在课堂获取知识的劲头也绝不含糊。正是如此,我们互相在获取知识的道路上赛跑,遇到难以解决的问题时互帮互助,互相勉励,克服了一个又一个的难题。
回首整个毕业设计阶段,真是饱经风霜又雨后见彩虹。最开始的我对于毕业设计课题很迷茫,因为在之前从没有接触过大数据的相关课题研究,只是简单了解过相关的知识。这时单老师及时出现为我指点迷津。帮助我选题,有的相关资料也帮我整理好统一发给我,帮我解决了毕业设计初期所遇到的很多问题。没有单老师的帮助,我的项目很难坚持到最后,没准就会夭折在摇篮里。尤其是在中期论文的修改,后期论文格式的调整上对我帮助也很大。张老师向我传授了许许多多关于论文规划的知识,让我的论文变得井井有条,以致于缩小后期论文的修改量。在论文书写中期,也就是写到总体设计部分我很迷茫,因为我不会议论文的形式来介绍我的毕业设计项目。这时张老师就以他丰富的专业经验为我将整体项目拆分为几个详细的部分,告诉我在总体设计部分就针对这几部分重点展开介绍就可以了,使得我从迷茫中逐渐找到方向。特别感谢张老师在此次毕业设计过程中对我的帮助。
最后的最后我特别想感谢我自己,感谢我自己没有放弃感谢我自己熬夜爆肝改论文,感谢我自己疯狂搜索论坛博客搜集信息。
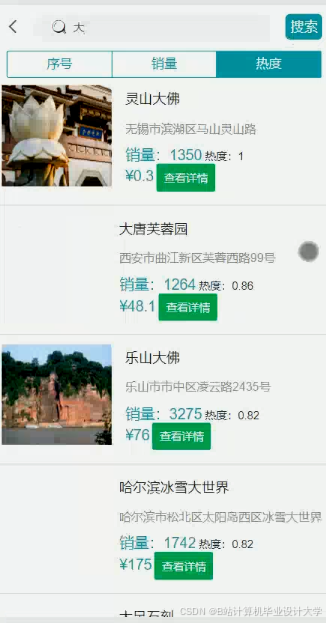
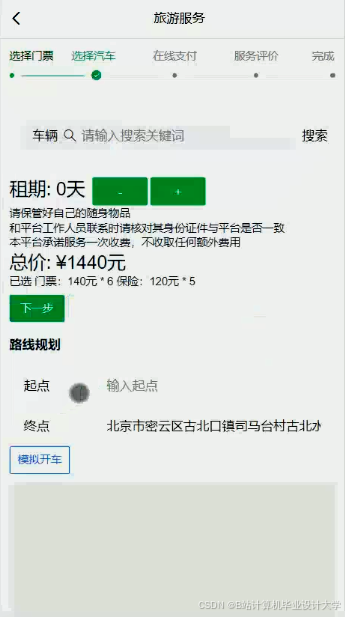
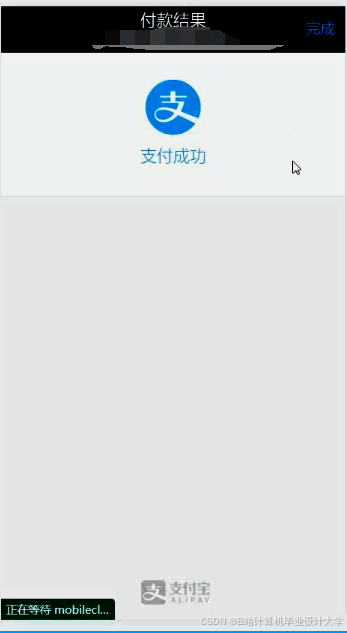
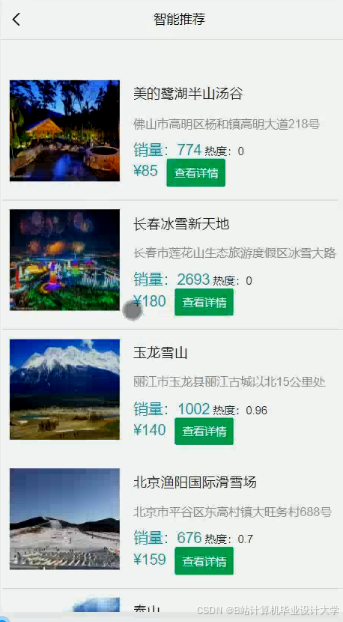
运行截图
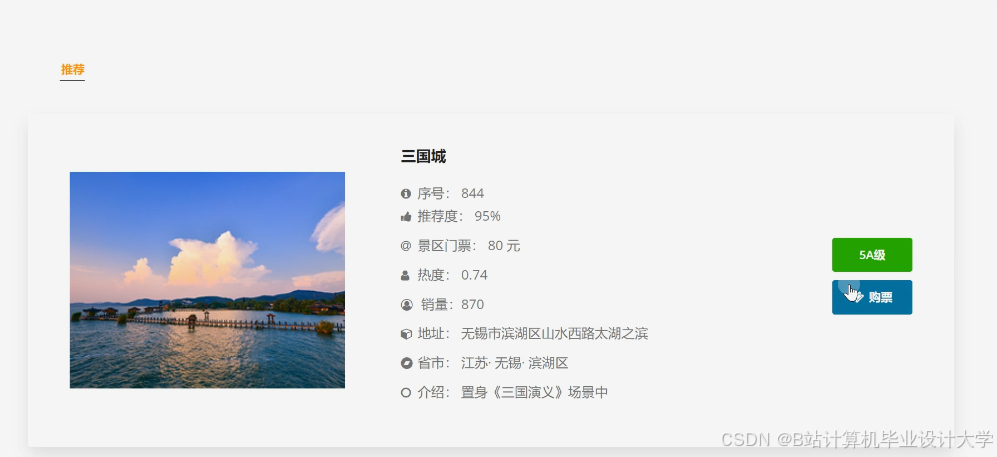
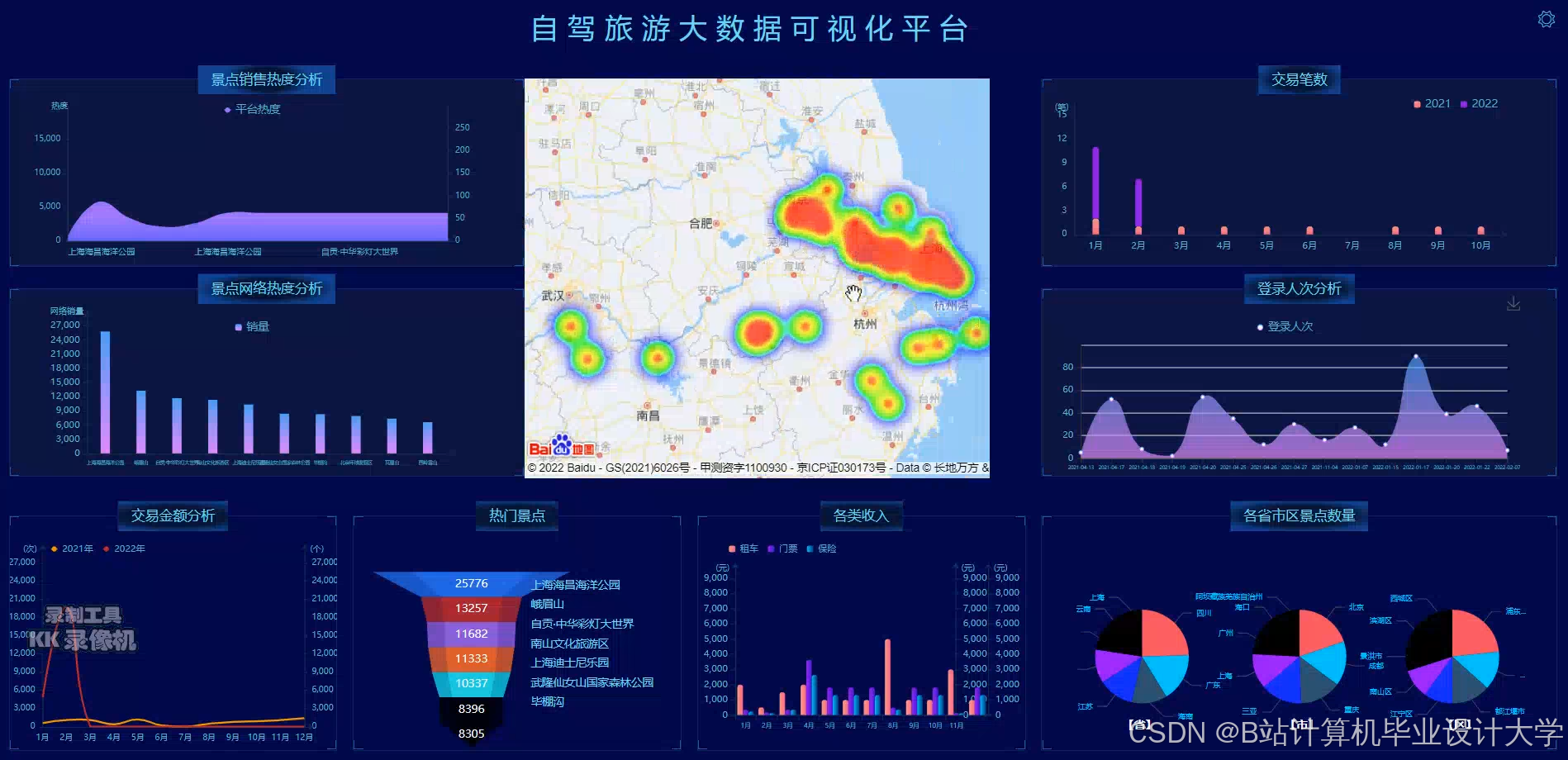
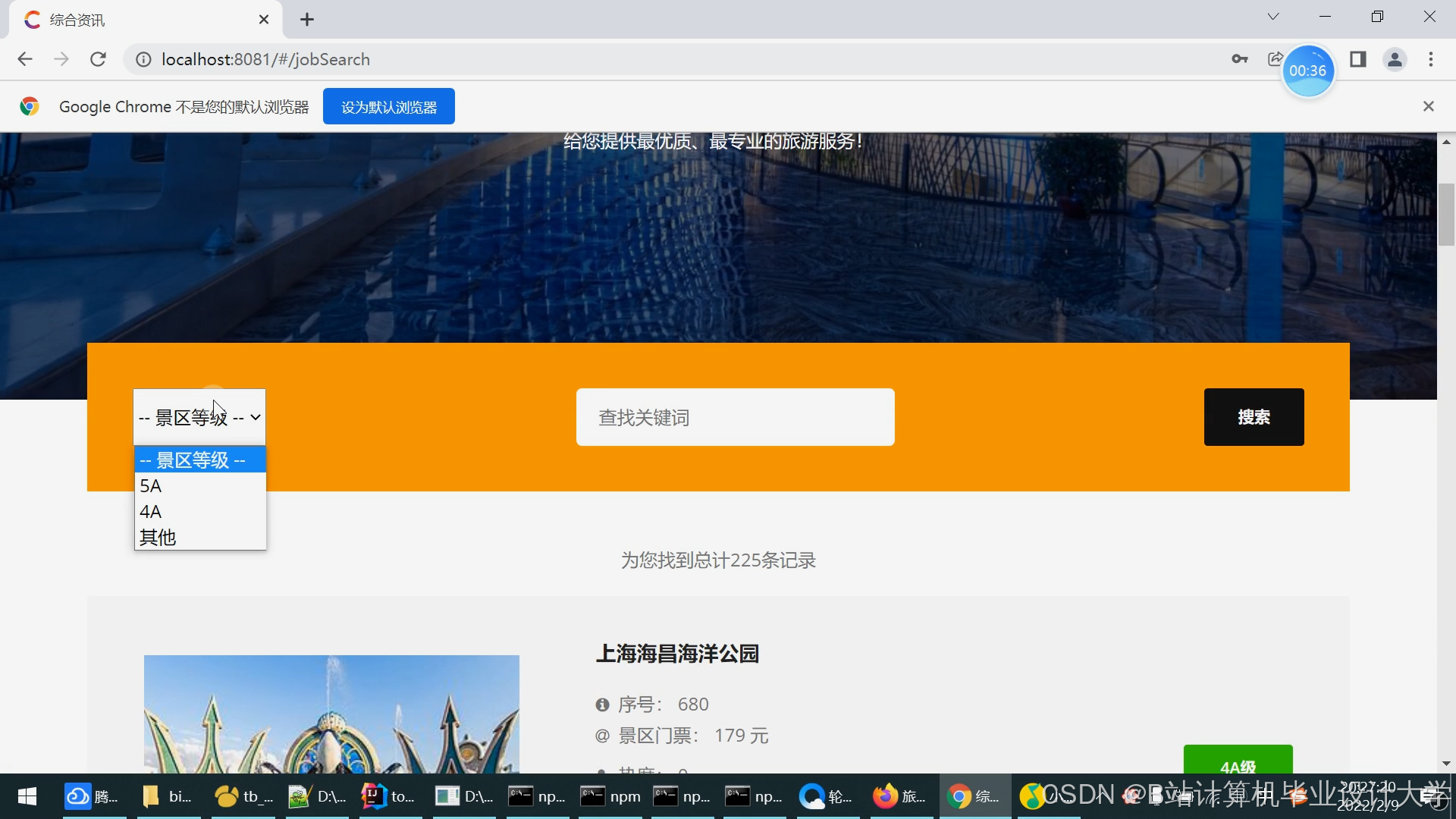
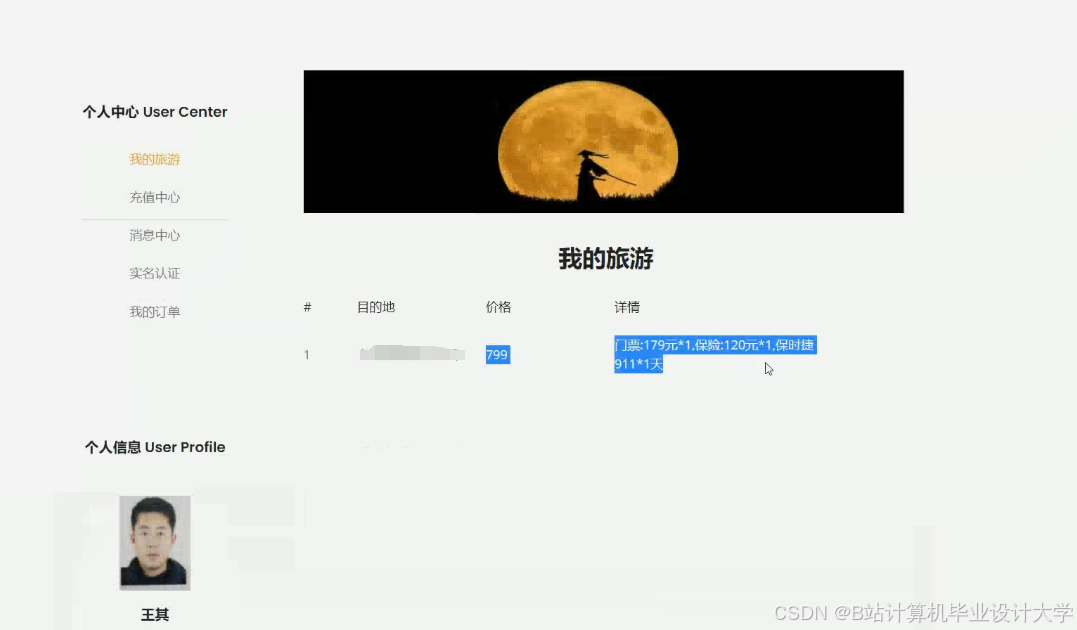


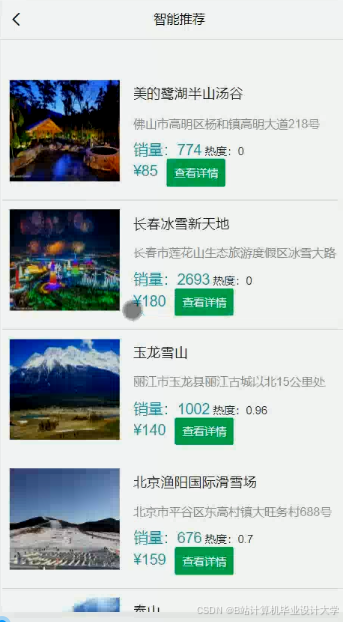
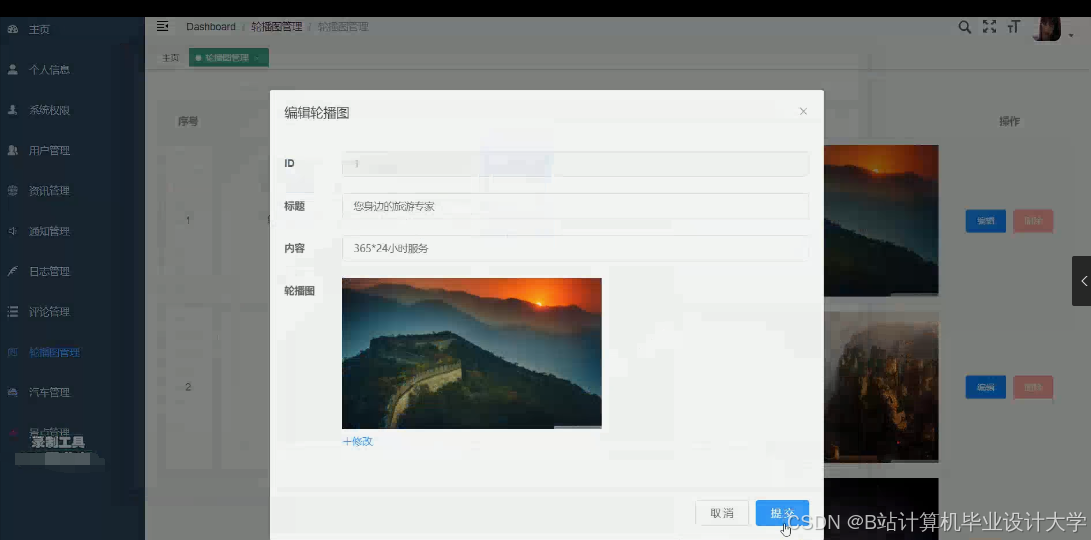
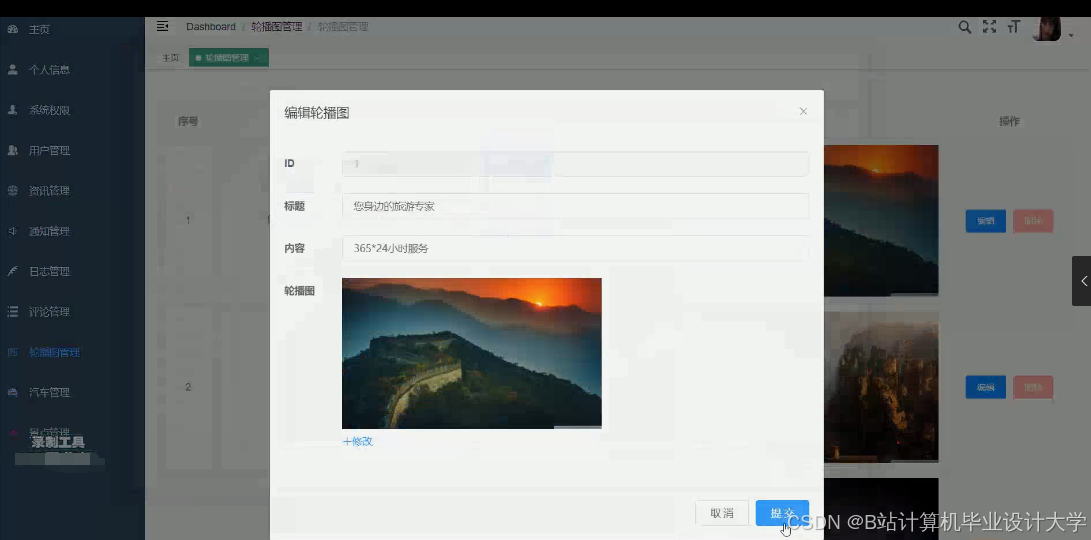
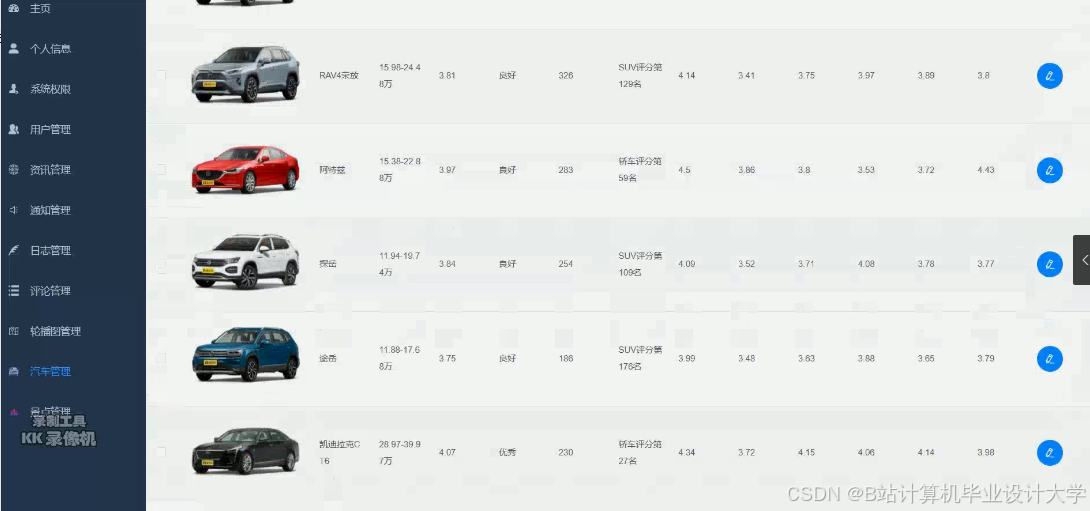
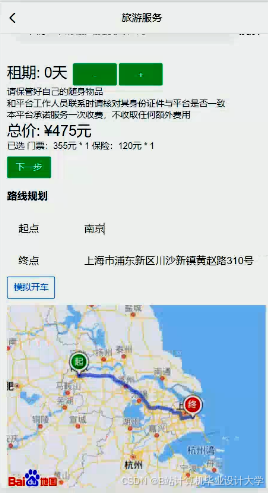
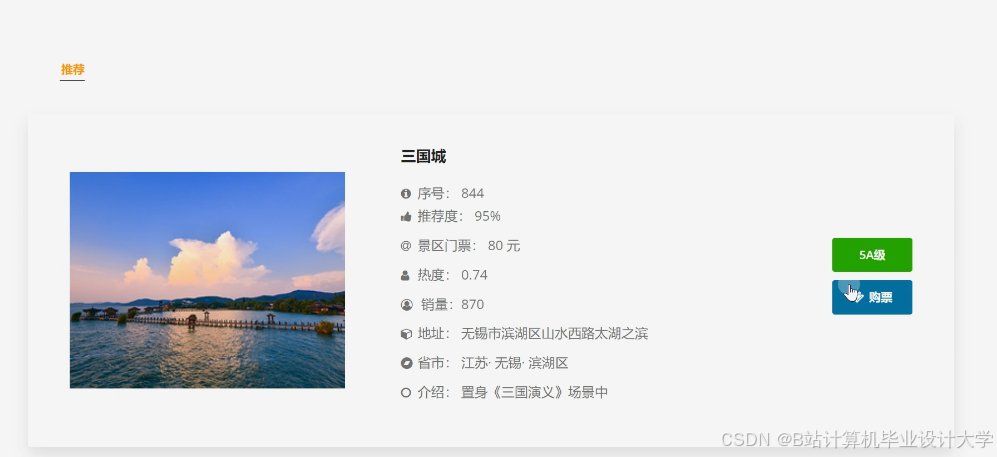
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











