




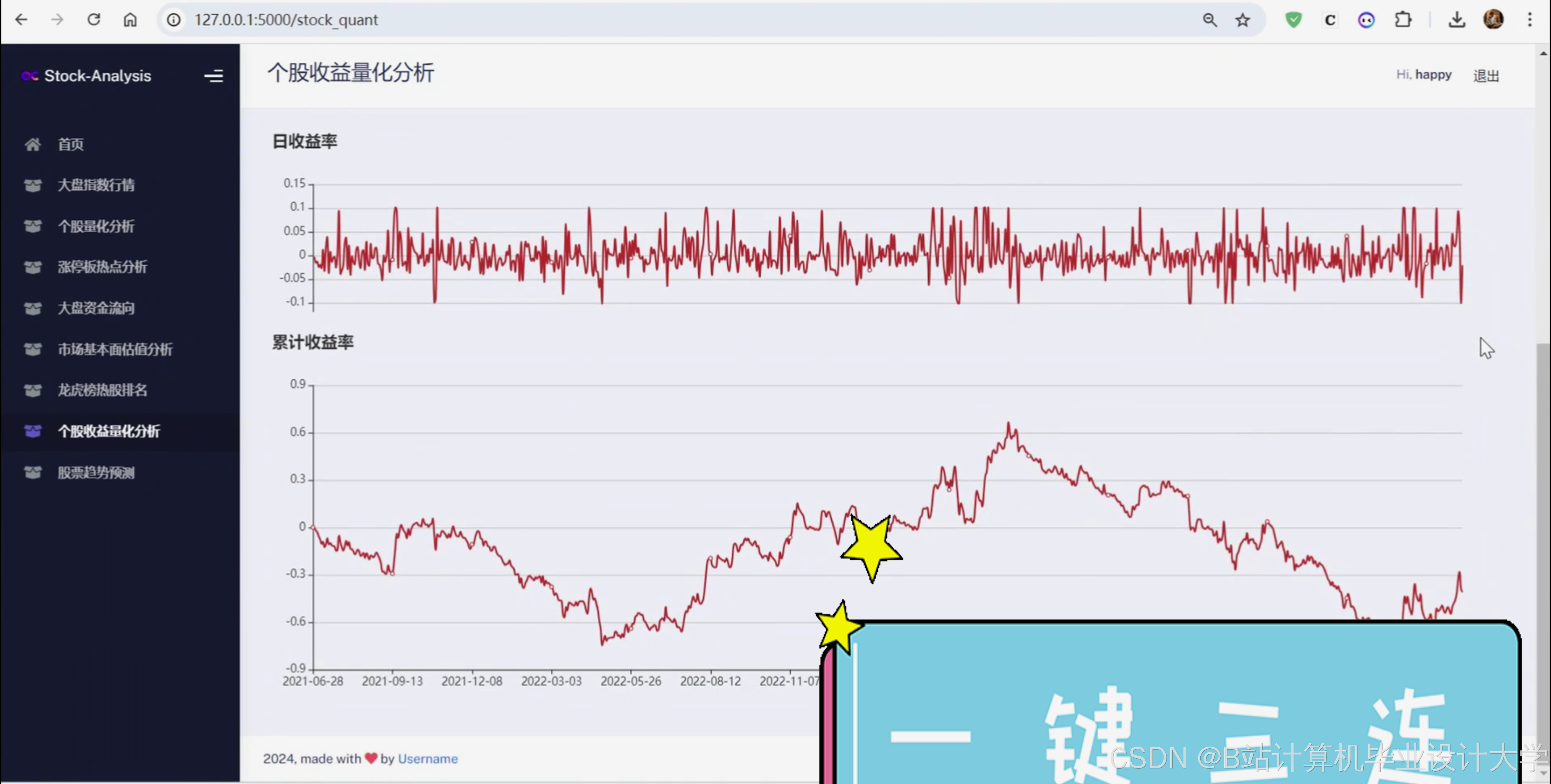
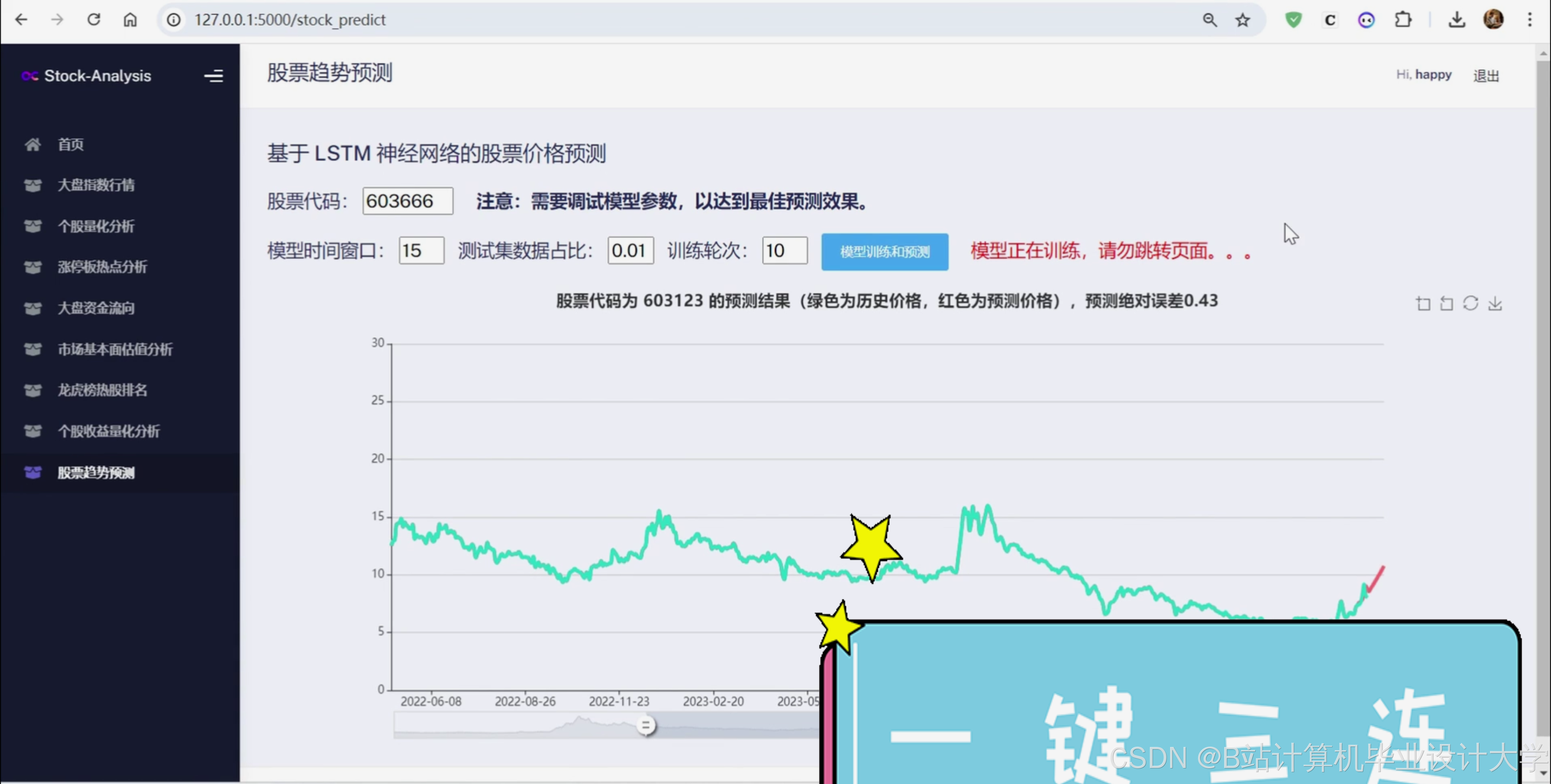
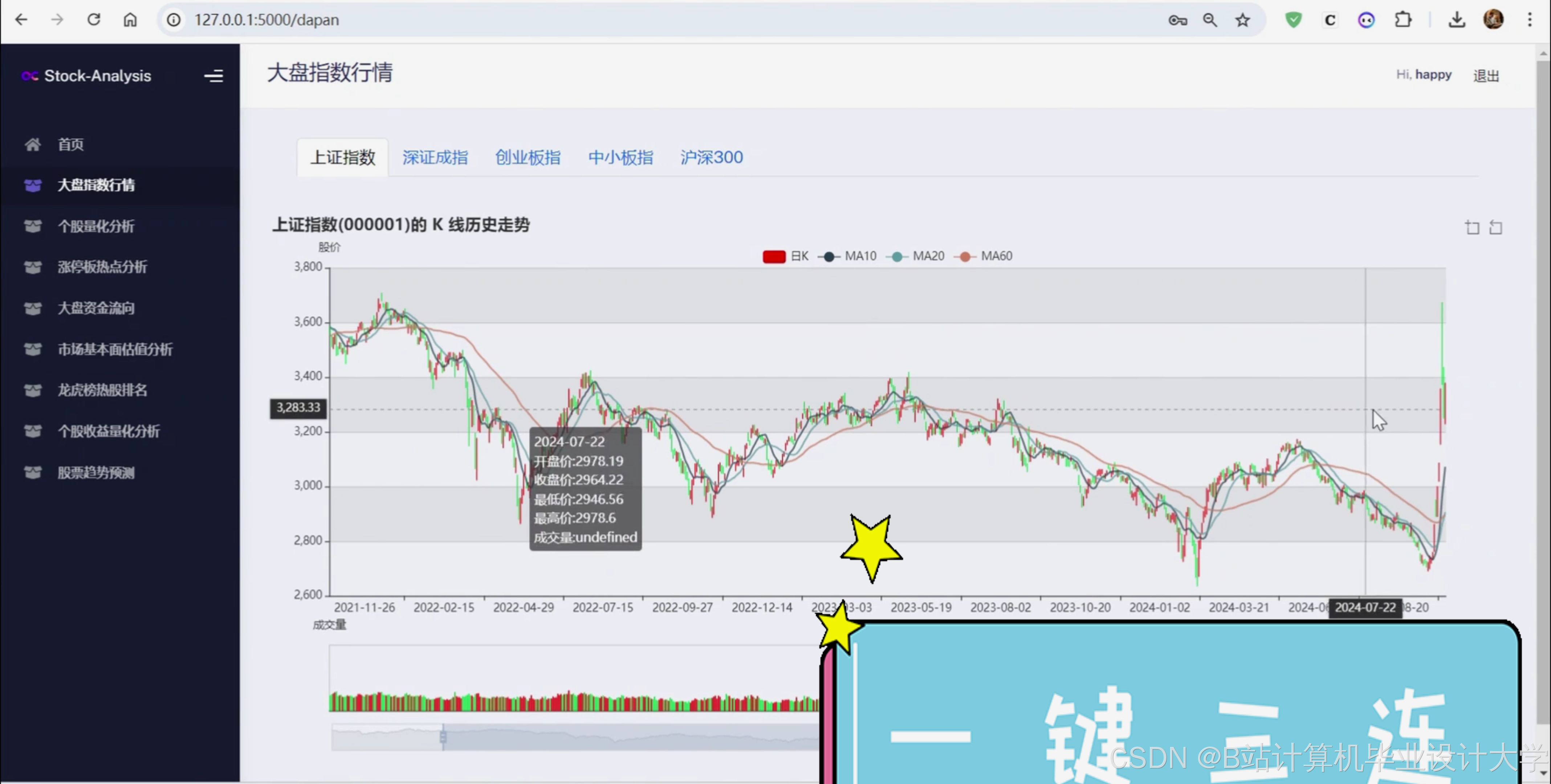
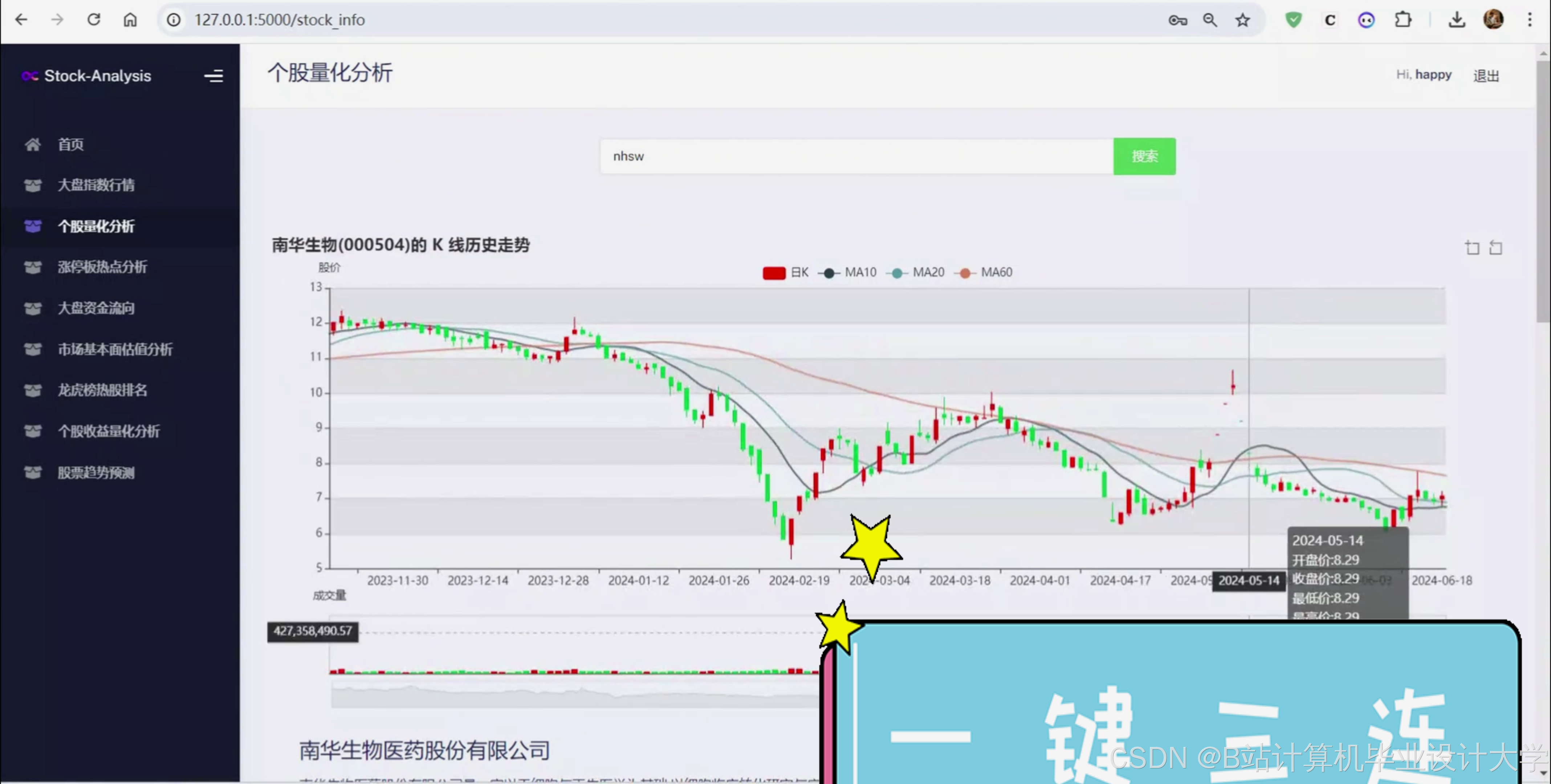
本项目利用 Python 网络爬虫技术从某财经网站实时采集A股各大指数、个股的 K线数据、公司简介、财务指标、机构预测、资金流向、龙虎榜等数据,并进行 KDJ、BOLL等技术指标的计算和收益率的量化计算,构建股票数据分析与预测系统,深入挖掘板块热点、资金流向、市场估值等,并利用 Tensorflow 深度学习框架构建 LSTM 神经网络,预测个股的未来走势。
1、指数或个股的模糊搜索;
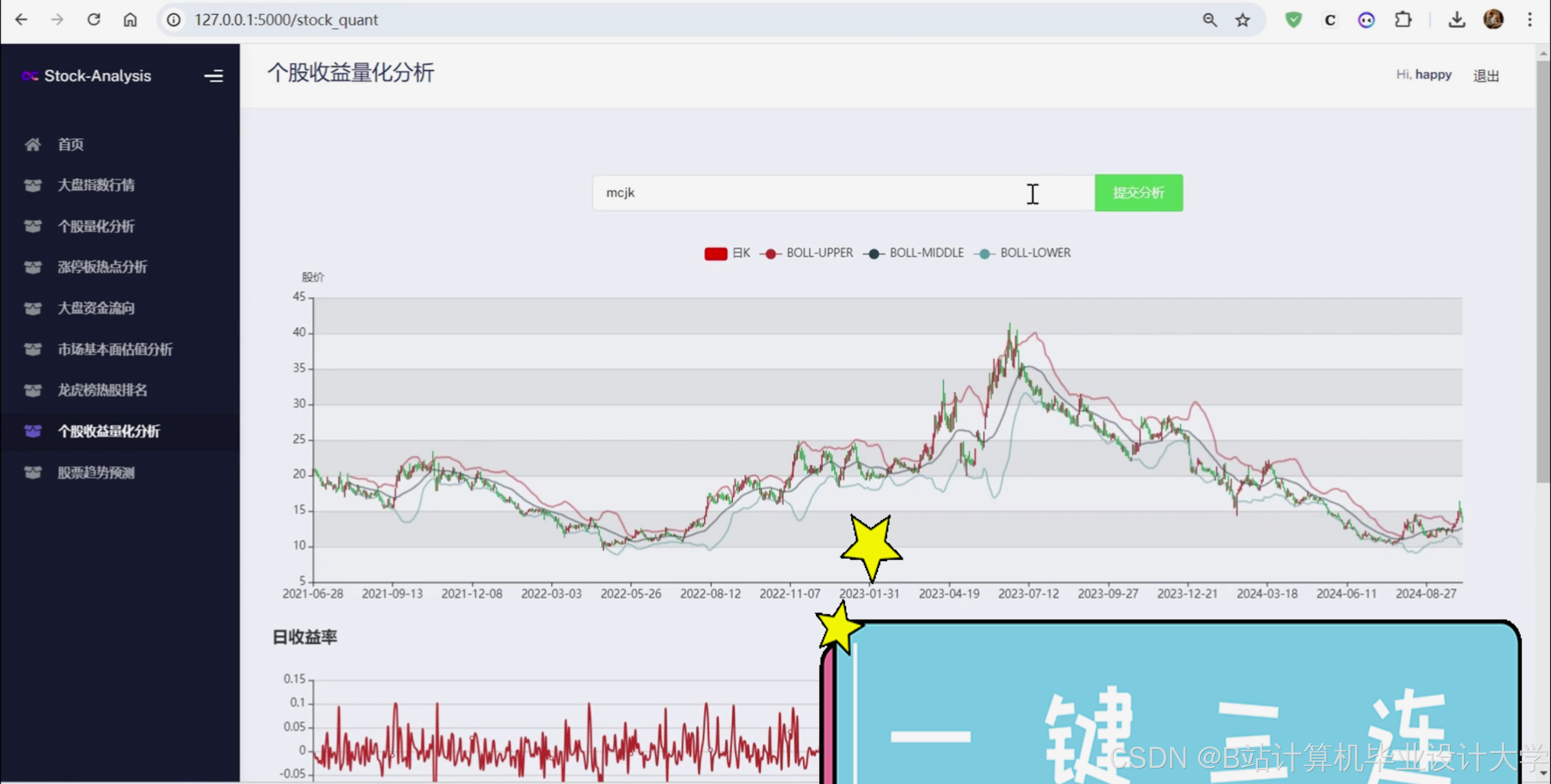
2、获取个股的 K 线和基本指标数据;
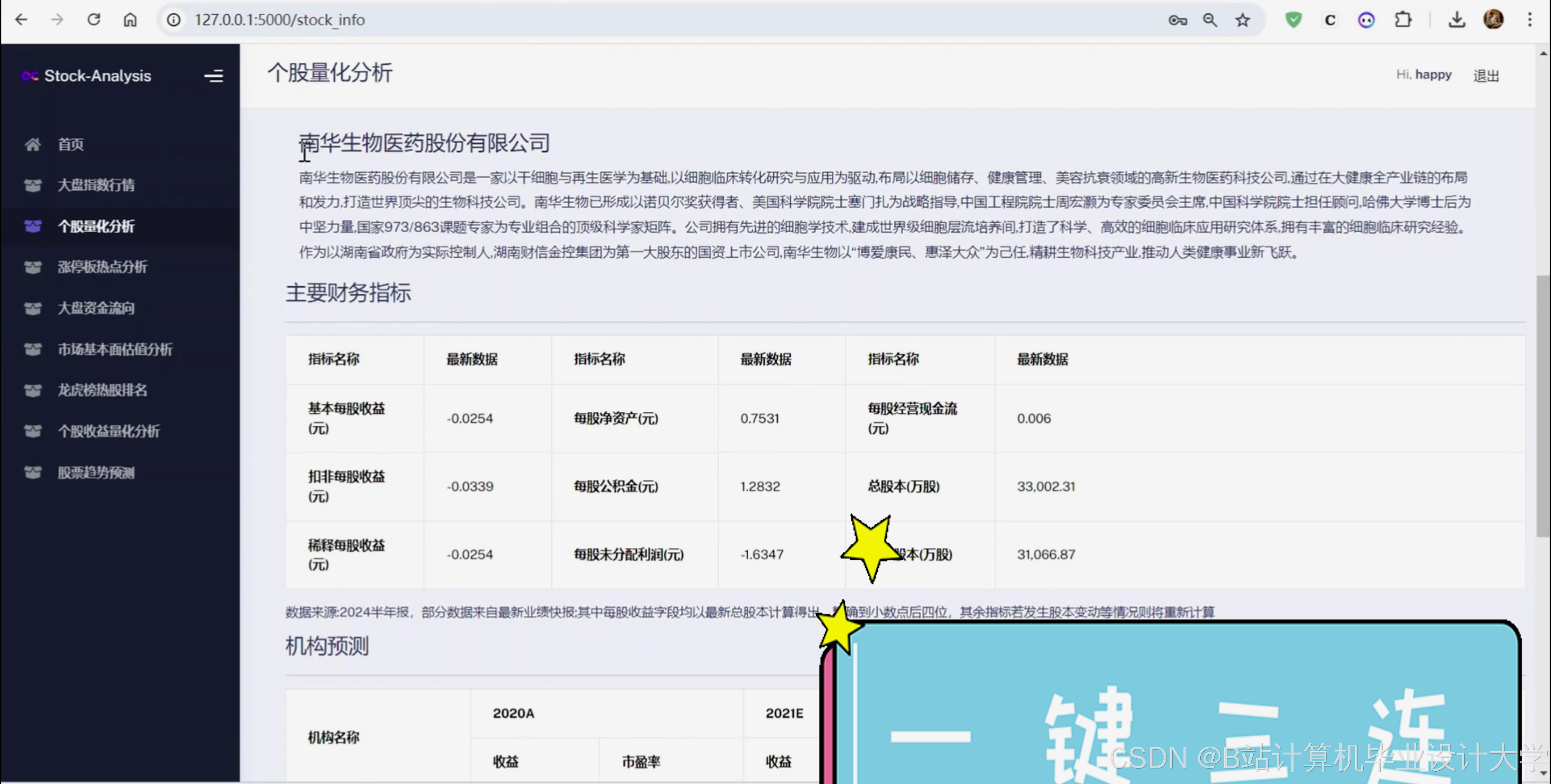
3、个股基本面信息获取;
4、个股的最新核心题材;
5、A股的资金流的最新排名;
6、个股主力资金占比排名;
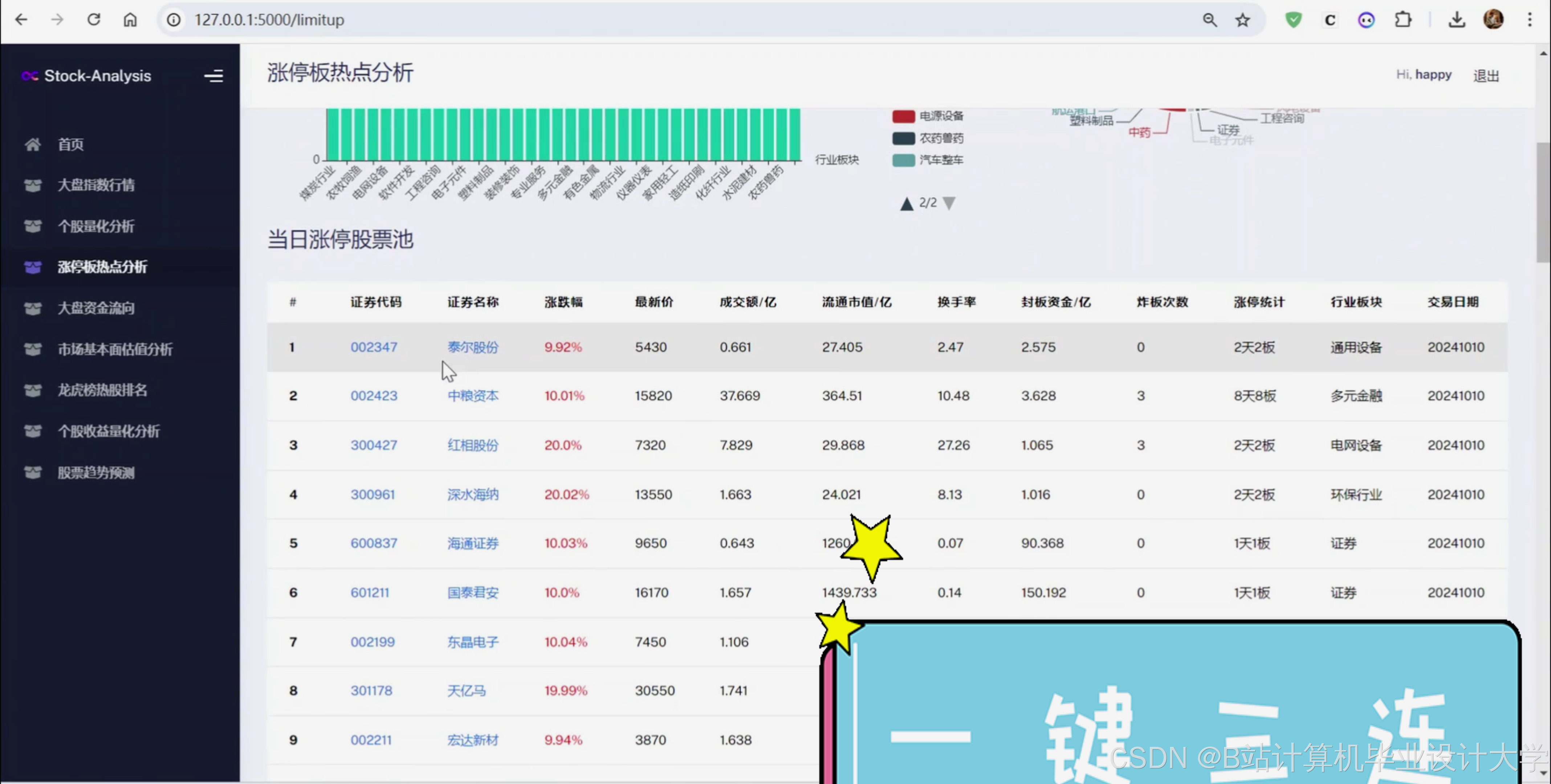
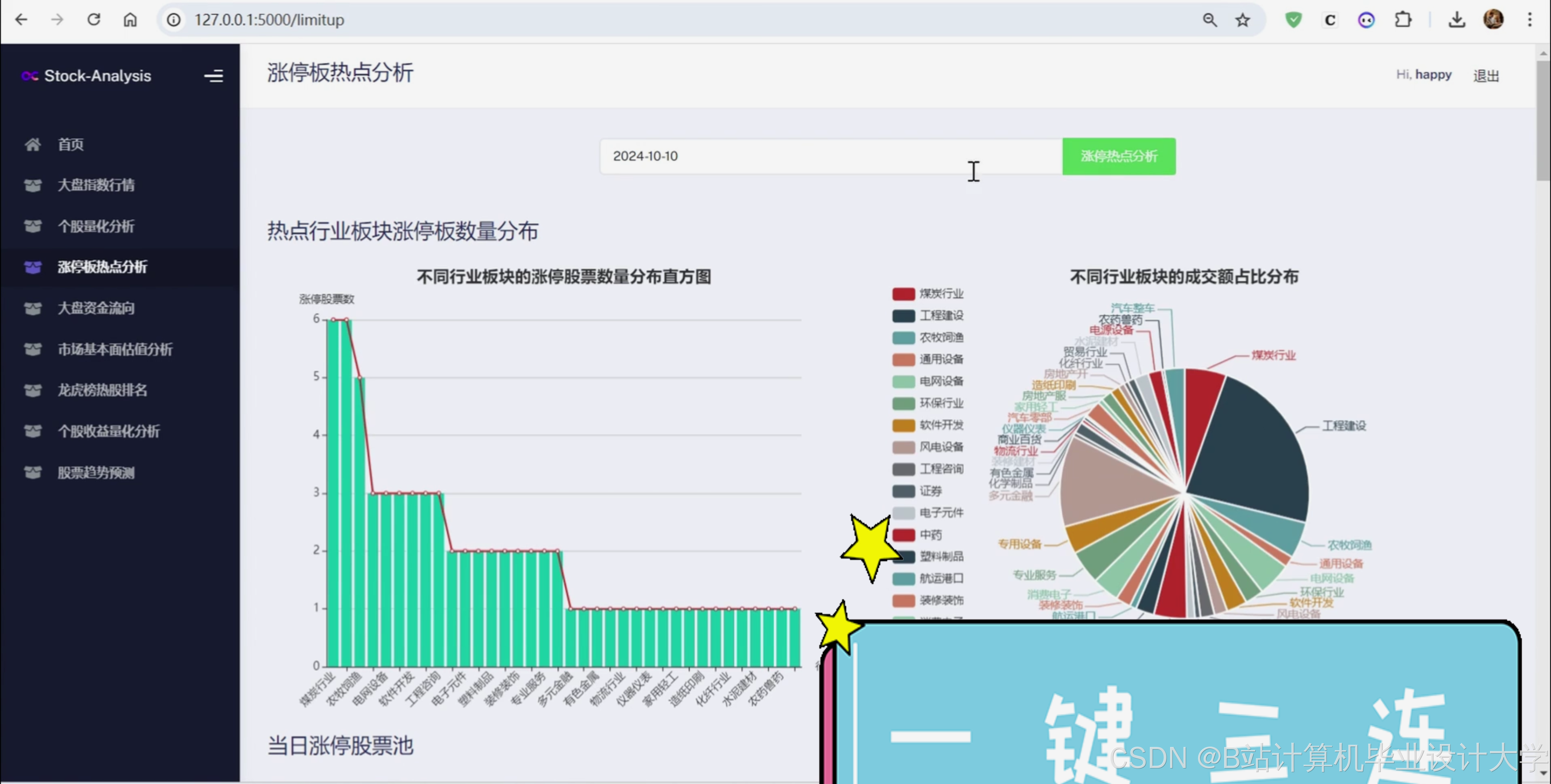
7、交易日的涨停板数据;
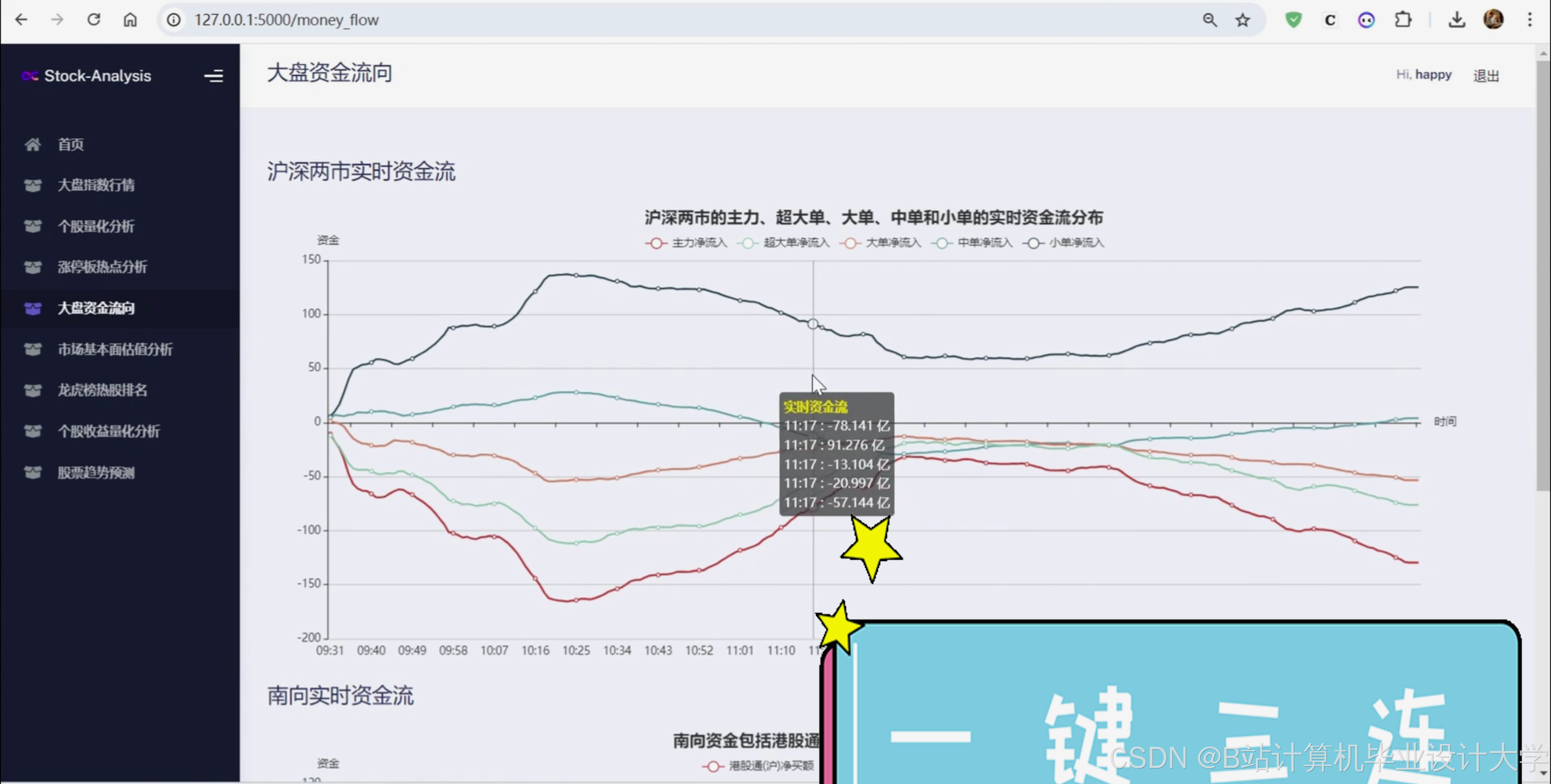
8、沪深两市实时资金流;
9、获取南向实时资金流;
10、获取市场的市盈率和市净率的估值数据
11、A 股的所有股票最新排名榜单
12、......
核心算法代码分享如下:
def get_limit_up_stocks(self, trade_date, page_index=0, pagesize=100):
"""
获取交易日的涨停板数据,注意网站中收录的涨停板不包含 ST 股
http://quote.eastmoney.com/ztb/detail#type=ztgc
Args:
trade_date: 交易日期,%Y%m%d 格式,20230901
page_index: 当前页下标
pagesize: 分页大小,默认最大千股涨停。。。
"""
time_token = int(time.time() * 1000)
base_url = 'https://push2ex.eastmoney.com/getTopicZTPool?ut=7eea3edcaed734bea9cbfc24409ed989&dpt=wz.ztzt&Pageindex={}&pagesize={}&sort=fbt%3Aasc&date={}&_={}'
url = base_url.format(page_index, pagesize, trade_date, time_token)
print(url)
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
"Cookie": "Your cookie",
"Host": "push2ex.eastmoney.com",
"Referer": "https://quote.eastmoney.com/ztb/detail",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36",
}
resp = requests.get(url, headers=headers)
resp.encoding = 'utf8'
resp = json.loads(resp.text)['data']
if resp is None:
return []
stock_datas = resp['pool']
columns_map = {
'c': '证券代码',
'n': '证券名称',
'zdp': '涨跌幅',
'p': '最新价',
'amount': '成交额',
'ltsz': '流通市值',
'tshare': '流通市值',
'hs': '换手率',
'fund': '封板资金',
'zbc': '炸板次数',
'zttj': '涨停统计',
'hybk': '行业板块'
}
limit_up_stocks = []
for stock_info in stock_datas:
limit_up_stock = {}
for c in stock_info:
if c in columns_map:
value = stock_info[c]
if c == 'zttj':
value = '{}天{}板'.format(stock_info[c]['days'], stock_info[c]['ct'])
limit_up_stock[columns_map[c]] = value
limit_up_stock['交易日期'] = trade_date
limit_up_stocks.append(limit_up_stock)
return limit_up_stocks



















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











