




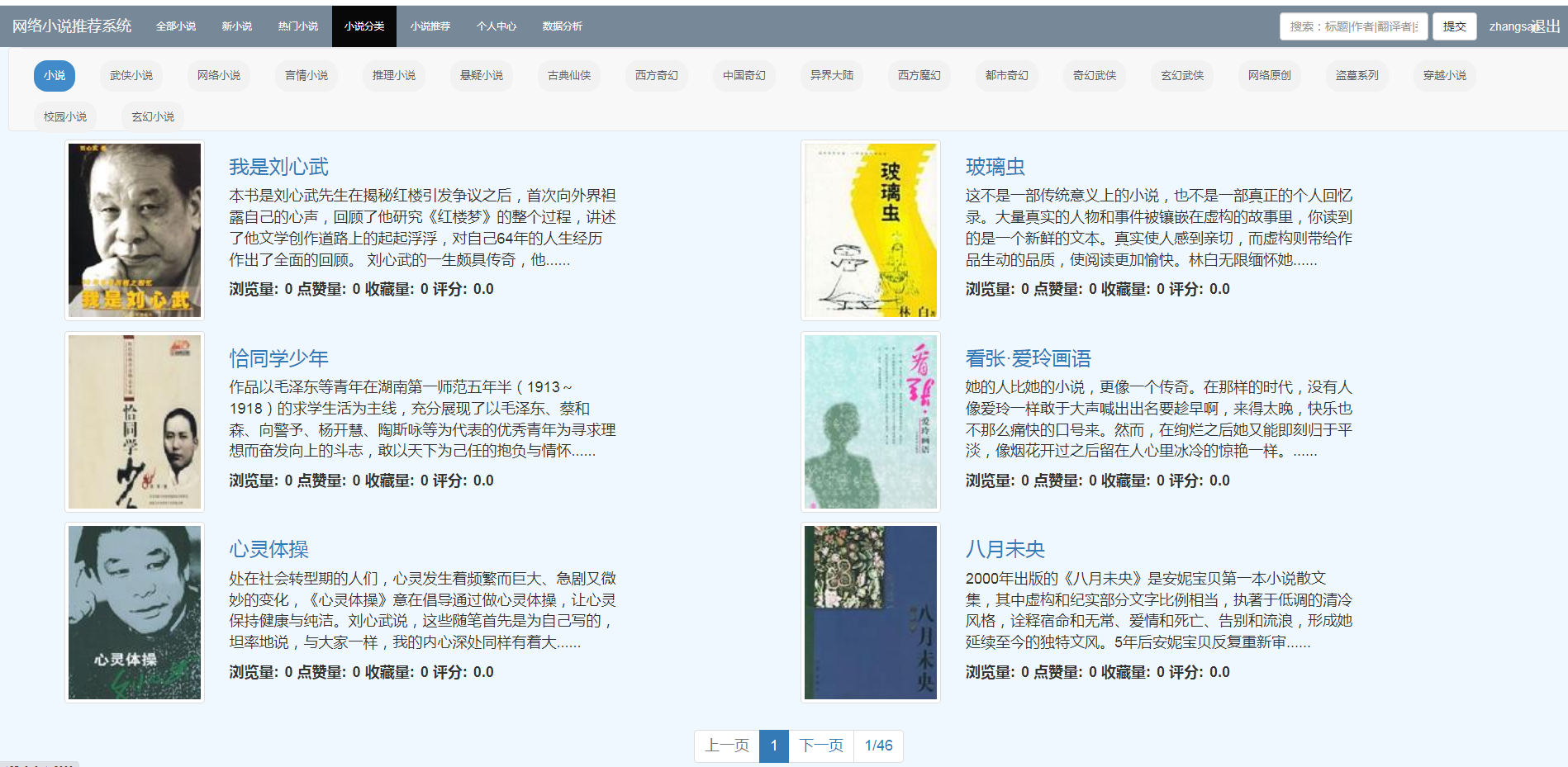
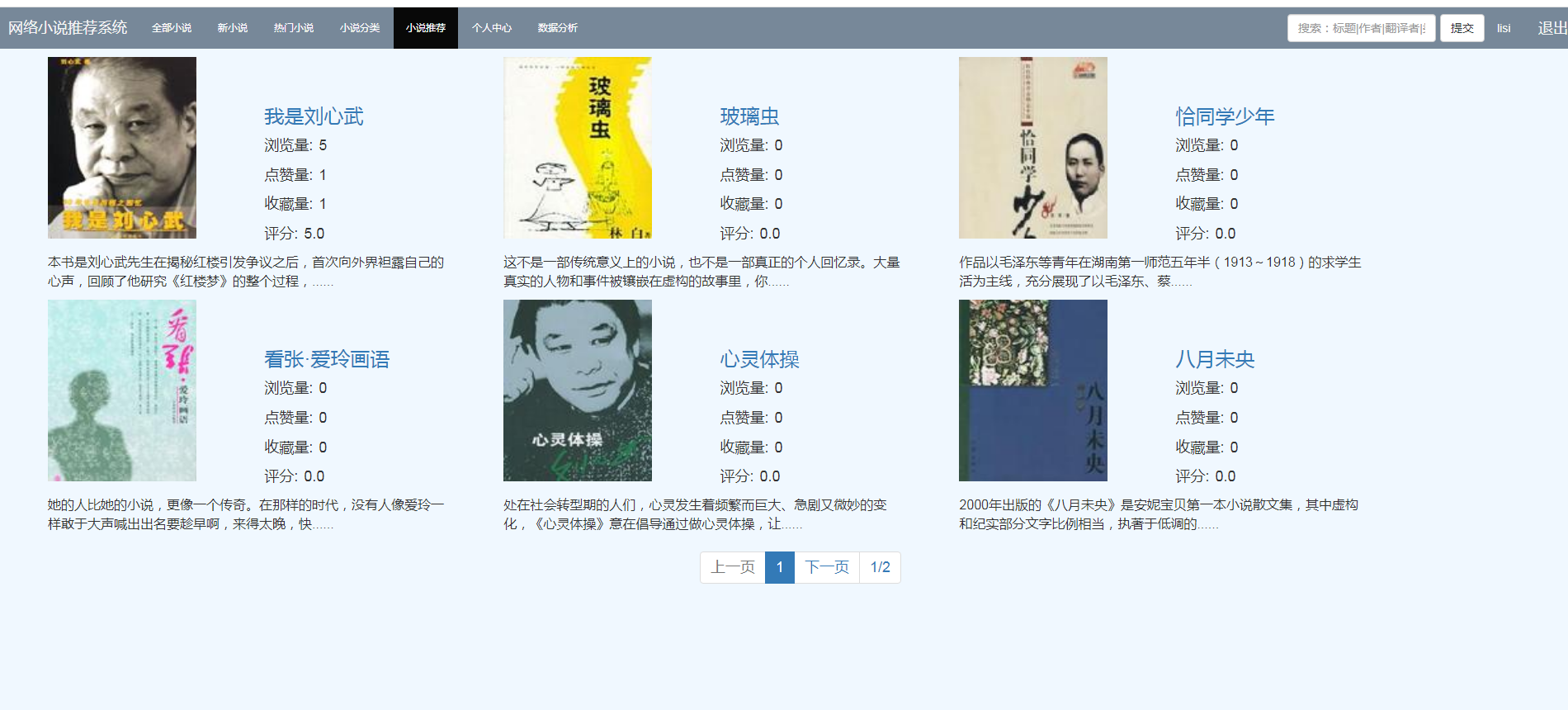
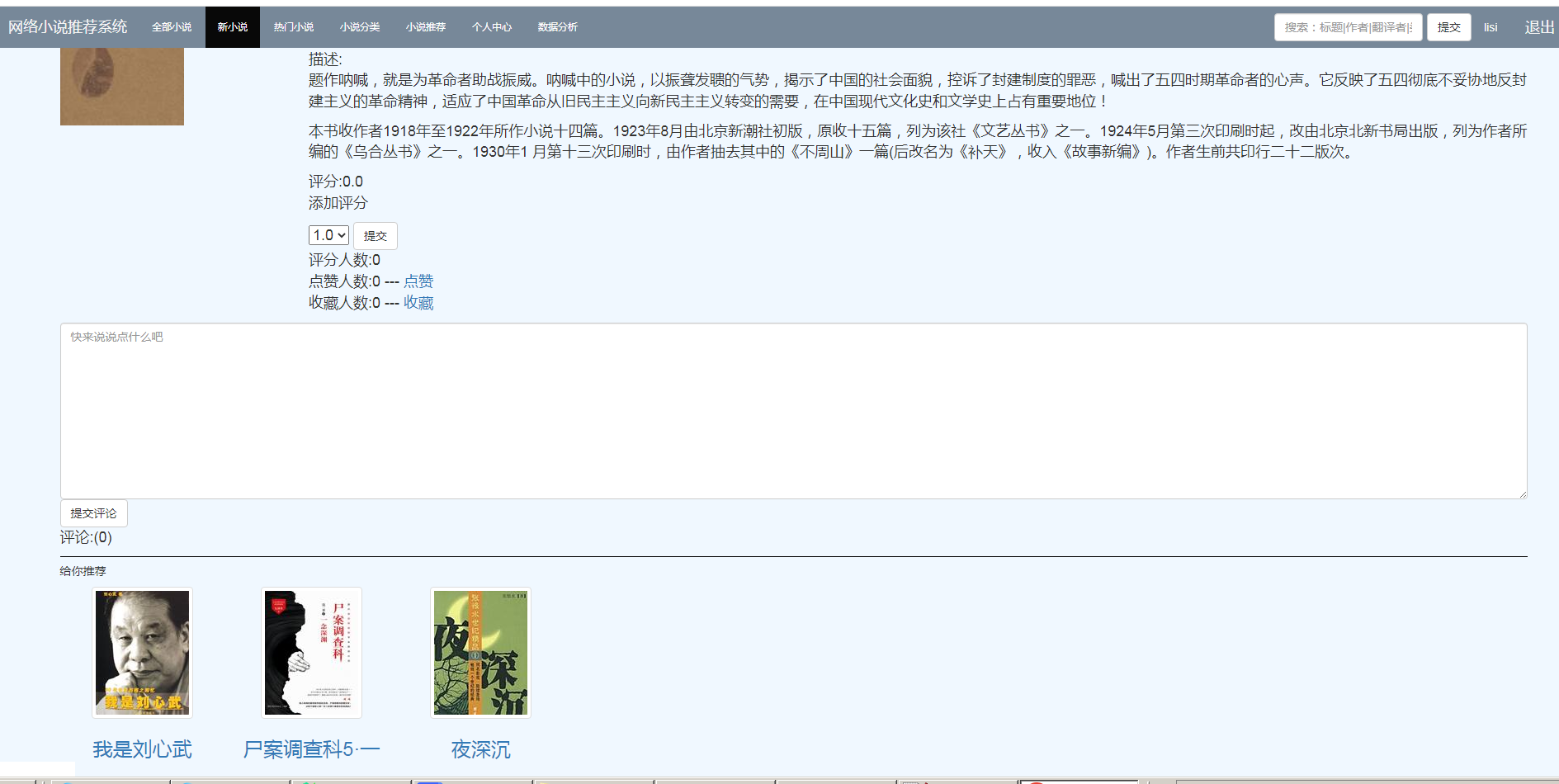
本系统基于推荐算法给用户实现精准推荐图书。
根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然后再基于这些关联性进行推荐,种被称为基于协同过滤的推荐。
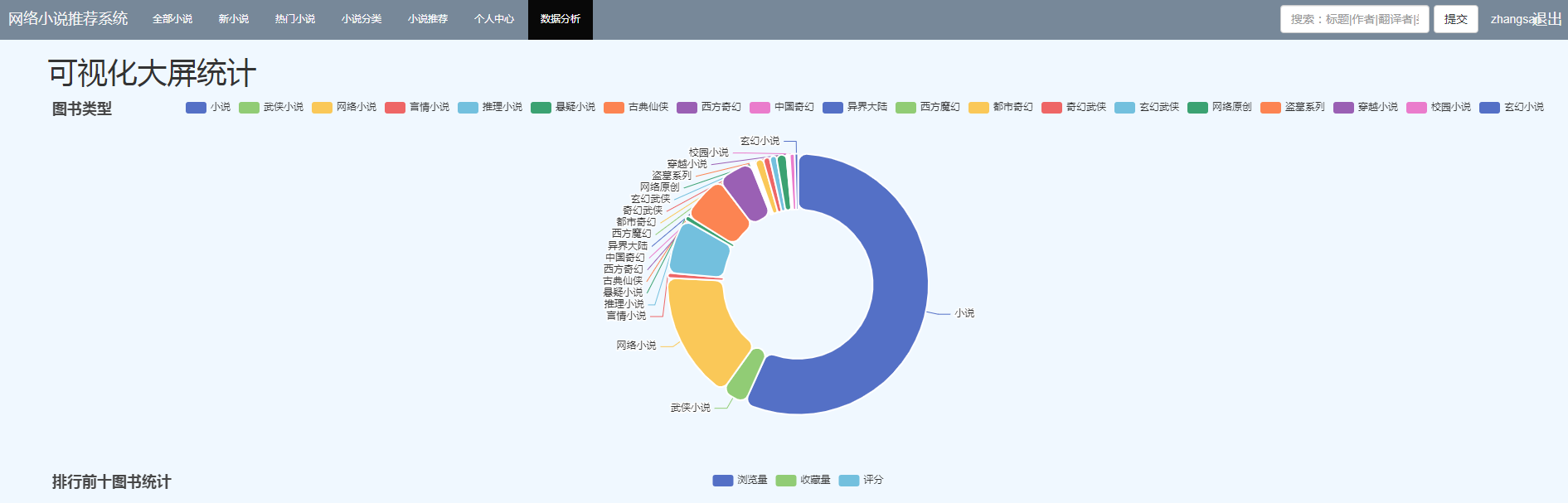
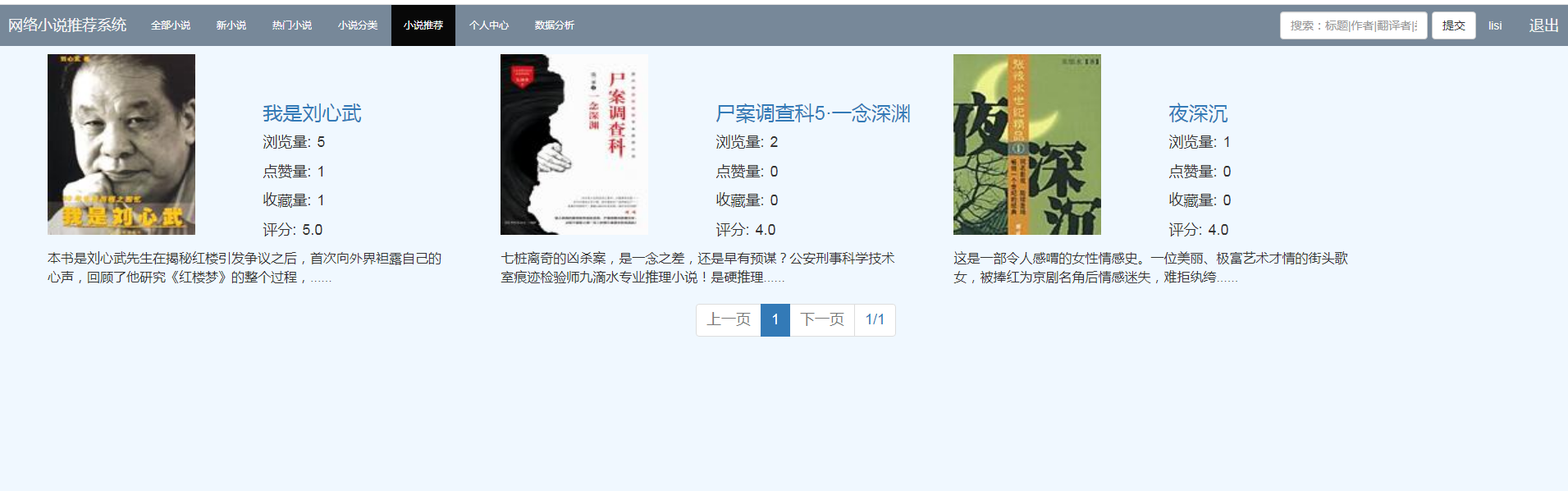
本系统使用了三种推荐算法:基于用户的协同过滤算法、基于物品的协同过滤算法、基于机器学习k-means聚类的过滤算法,以及三种算法的混合推荐算法。
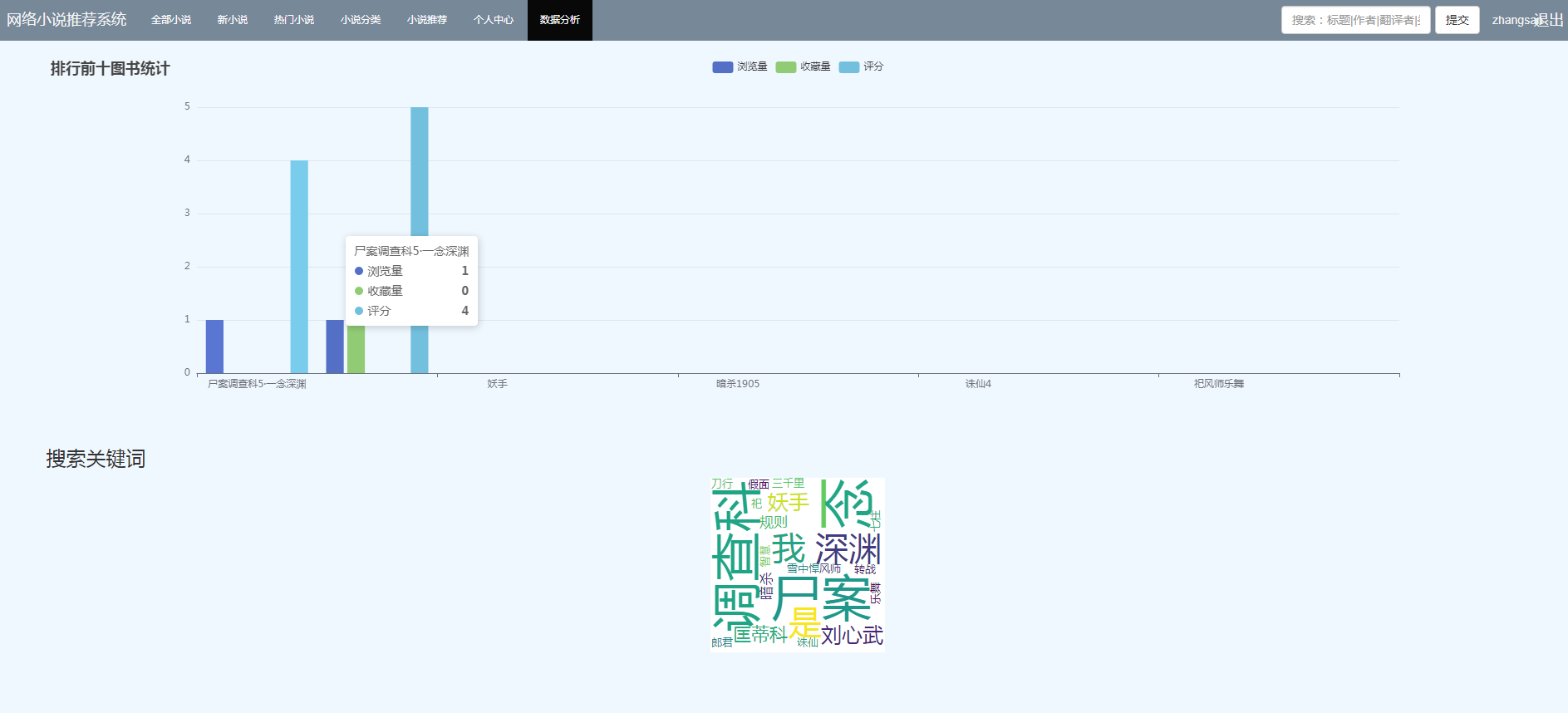
主要功能如下图:
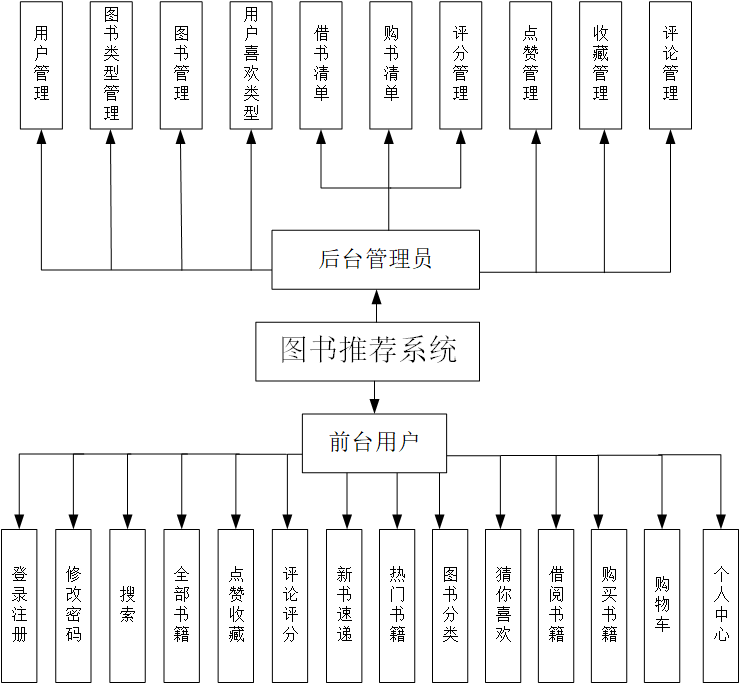
开发语言是python3.7,框架是Django3.0,采用的是djanog前后端相结合的技术,后台管理系统是xadmin,数据库是Mysql5.7。
1、Django的MTV架构
所谓MTV就是:数据模型(M)-前端界面(T)-调度控制器(V).
用户在浏览器发起一个请求:通过V对M和T进行连接,用户通过T(界面)对服务器进行访问(发送请求),T把请求传给V(调度),V调用M(数据模型)获取数据,把数据给模板T进行渲染,然后再把渲染后的模板返回给用户。
MTV框架是一种 把业务逻辑、数据、界面显示分离而设计创建的Web应用程序的开发模式。在web开发中应该尽量使代码高内聚低耦合,这样利于代码复用、维护、管理,MTV框架就是这样分层的。
M对应于Model,即数据模型(数据层),用于管理数据库,对数据进行增删改查;
T对应于视图,template(即T),模板,用于管理html文件,呈现给用户的界面;
V对应于控制层,views(即V),视图调度器,用于访问数据层,获取数据,把数据调度给模板进行渲染,把渲染的结果返回给客户端。
MTV框架的大体流程是:
1、客户端发起请求,路由对客户发起的请求进行统一处理和分发给控制层;
2、控制层获取请求,访问数据层;
3、数据层对数据进行增删改查,把数据返回给控制层;
4、控制层获取数据,把数据调度给视图(模板);
5、视图(模板)对数据进行渲染,形成html文件返回给控制层;
6、控制层把渲染后的视图(模板)返回给客户端。
三、开发流程
1、环境搭建:创建虚拟环境、创建数据库
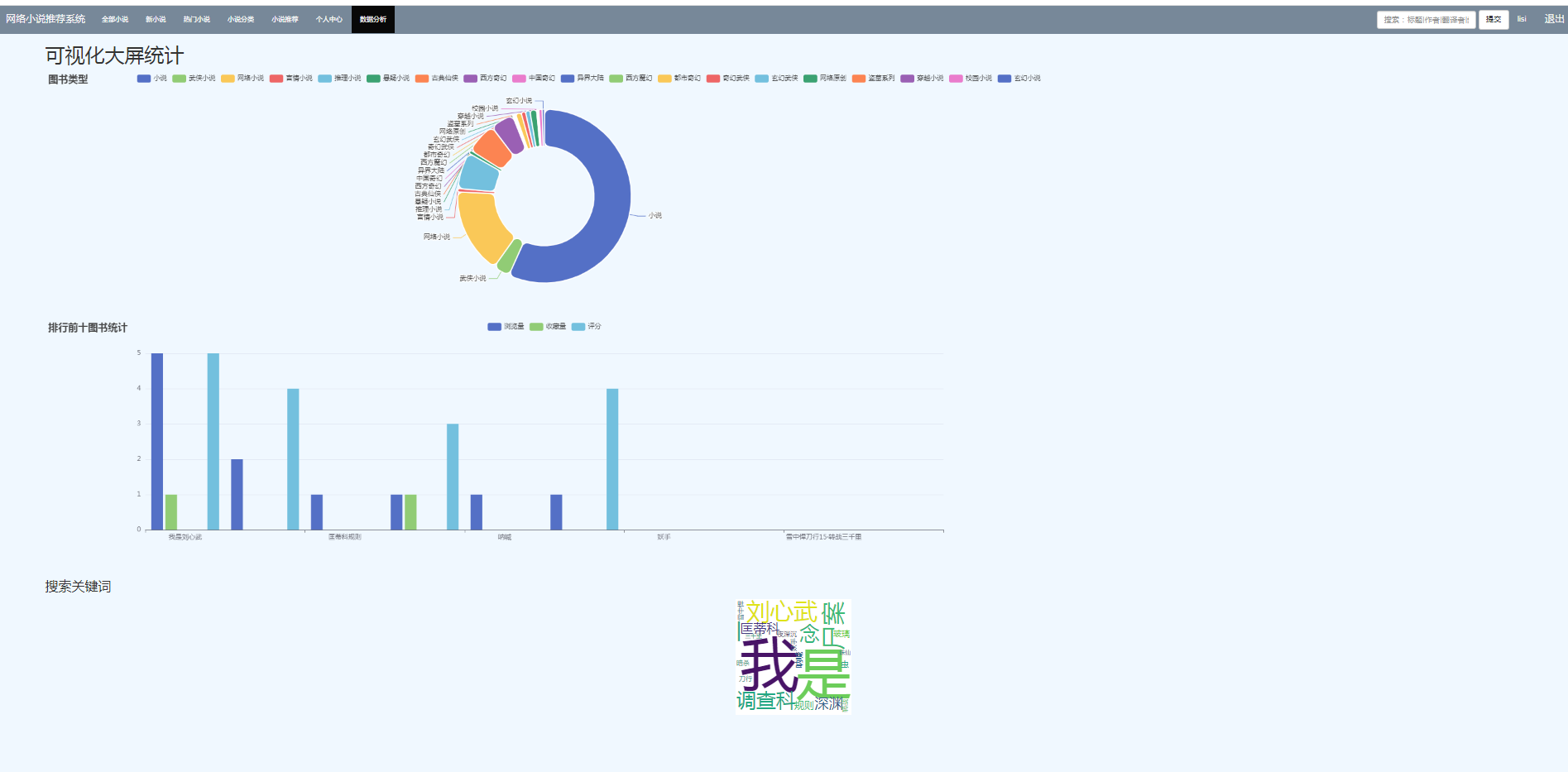
2、创建数据库模型:用户表、图书标签表、用户选择类型表(用户解决推荐算法冷启动问题)、借书清单表、购书清单表、评分表、收藏表、点赞表、评论表、推荐反馈表。然后数据迁移,把表映射到数据库中。
3、爬取数据,然后把数据经过预处理存放到数据库中。
4、编写用户界面框架,完成各种功能点击响应事件
5、编写后台管理文件,管理数据。
6、系统测试,检验完成的功能。
具体开发过程可以查看【开发文档.pdf】
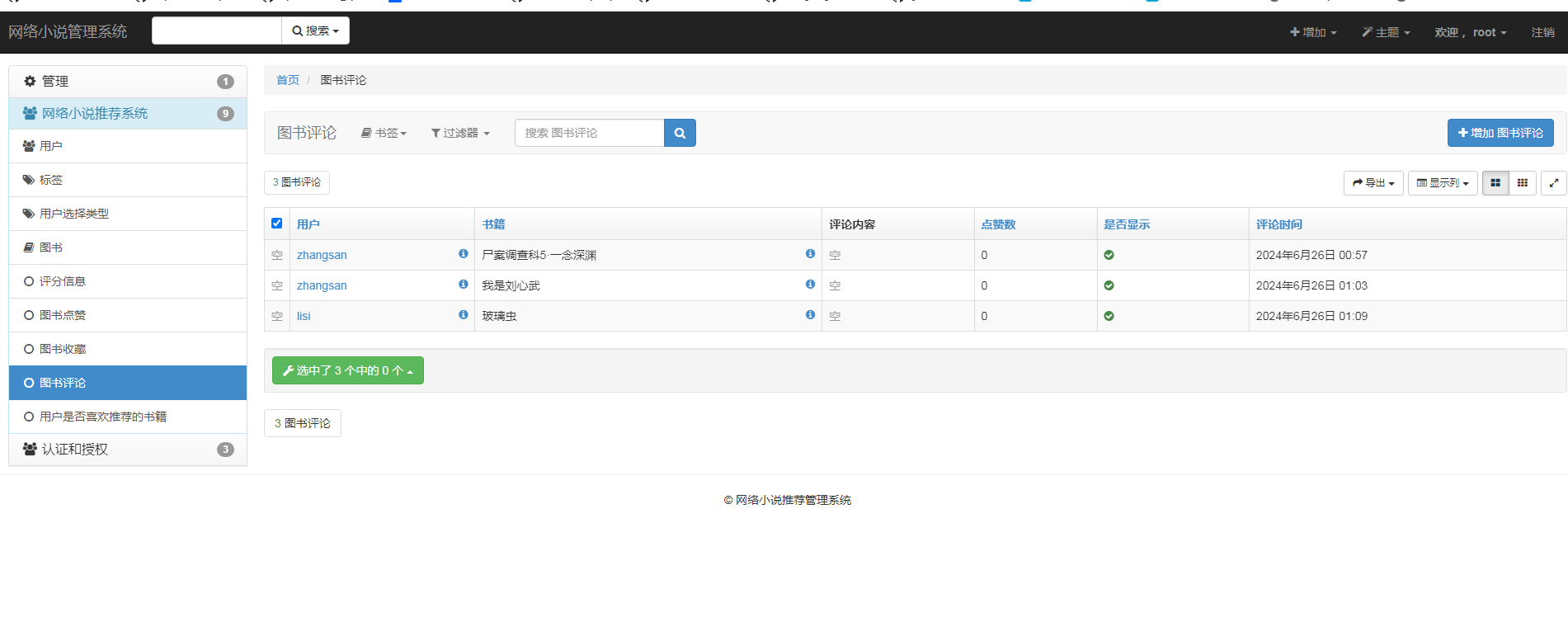
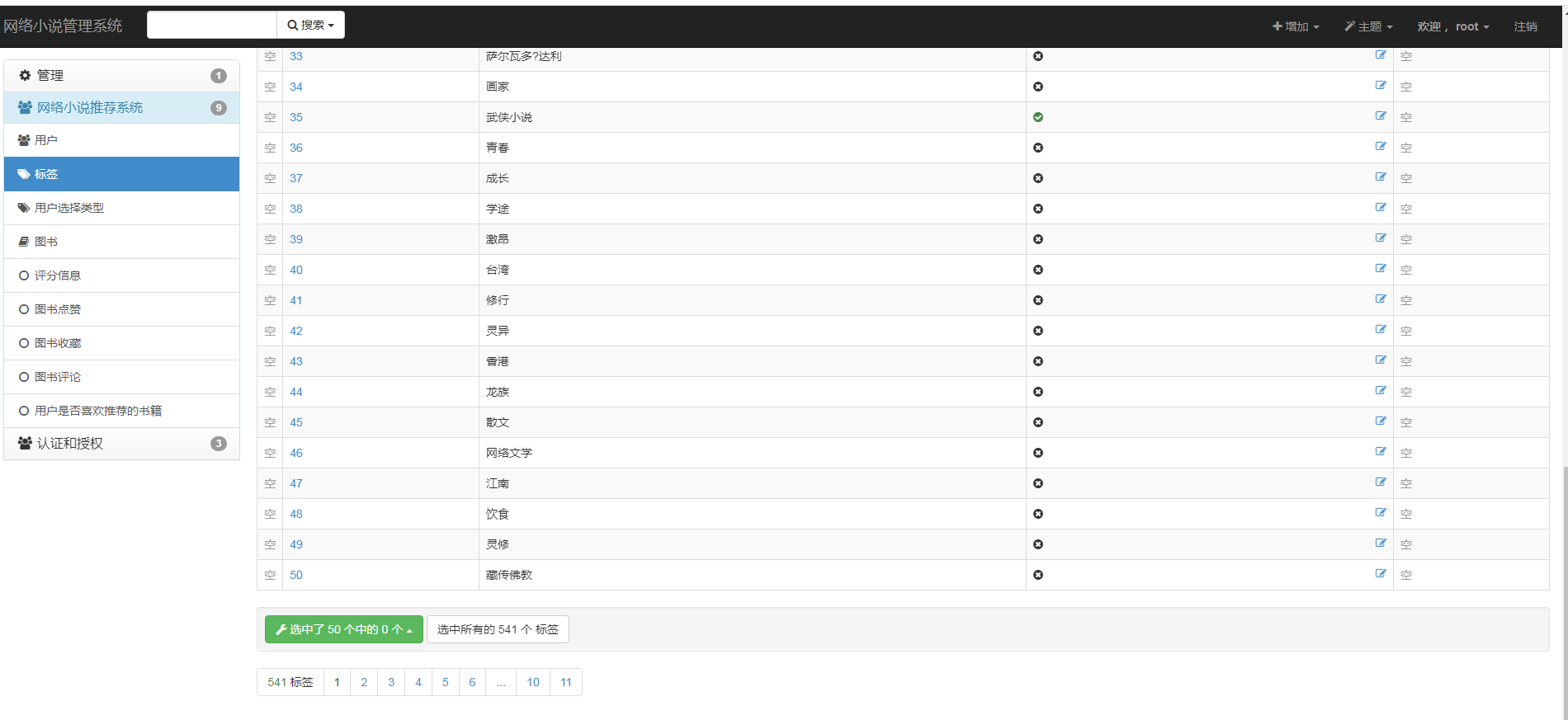
核心算法代码分享如下:
# -*-coding:utf-8-*-
import collections
import numpy as np
import os
import django
os.environ["DJANGO_SETTINGS_MODULE"] = "book_manager.settings"
django.setup()
import random
import operator
import math
from book.models import *
from math import sqrt, pow
from collections import Counter
from k_means_utils import predict
from operator import itemgetter
from collections import defaultdict
def get_select_tag_book(user_id, book_id=None):
# 获取用户注册时选择的书籍类别各返回10门书籍
category_ids = []
us = UserSelectTypes.objects.get(user_id=user_id)
for category in us.category.all():
category_ids.append(category.id)
unlike_book_ids = [d['book_id'] for d in
LikeRecommendBook.objects.filter(user_id=user_id, is_like=0).values('book_id')]
if book_id and book_id not in unlike_book_ids:
unlike_book_ids.append(book_id)
book_list = Book.objects.filter(tags__in=category_ids).exclude(id__in=unlike_book_ids).distinct().order_by(
"-like_num")[:10]
return book_list
# 基于用户推荐
class UserCf:
# 基于用户协同算法来获取推荐列表
"""
利用用户的群体行为来计算用户的相关性。
计算用户相关性的时候我们就是通过对比他们对相同物品打分的相关度来计算的
举例:
--------+--------+--------+--------+--------+
| X | Y | Z | R |
--------+--------+--------+--------+--------+
a | 5 | 4 | 1 | 5 |
--------+--------+--------+--------+--------+
b | 4 | 3 | 1 | ? |
--------+--------+--------+--------+--------+
c | 2 | 2 | 5 | 1 |
--------+--------+--------+--------+--------+
a用户给X物品打了5分,给Y打了4分,给Z打了1分
b用户给X物品打了4分,给Y打了3分,给Z打了1分
c用户给X物品打了2分,给Y打了2分,给Z打了5分
那么很容易看到a用户和b用户非常相似,但是b用户没有看过R物品,
那么我们就可以把和b用户很相似的a用户打分很高的R物品推荐给b用户,
这就是基于用户的协同过滤。
"""
# 获得初始化数据
def __init__(self, data, is_print=True):
self.data = data
self.user_sim_mat = {} # 用户之间的兴趣相似度矩阵
self.is_print = is_print # 是否在控制台输出
# 通过用户名获得书籍列表,仅调试使用
def getItems(self, username1, username2):
return self.data[username1], self.data[username2]
# 计算两个用户的皮尔逊相关系数
def pearson(self, current_user, other_user): # 数据格式为:书籍id,评分
'''
current_user: 当前用户
other_user: 其他用户
'''
current_user_vector = [] # 当前用户向量
other_user_vector = [] # 其他用户向量
# 循环当前用户的评分信息
for book_id, score in current_user.items():
current_user_vector.append(score) # 当前用户的评分入栈
if book_id in other_user.keys():
# 如果其他用户也评分过这本书,则把评分入栈,否则入栈0
other_user_vector.append(other_user[book_id])
else:
other_user_vector.append(0)
# 根据公式获取皮尔逊系数
x = np.array(current_user_vector)
y = np.array(other_user_vector)
if all(x == y):
return 1
n = len(x)
sum_xy = np.sum(np.sum(x * y))
sum_x = np.sum(np.sum(x))
sum_y = np.sum(np.sum(y))
sum_x2 = np.sum(np.sum(x * x))
sum_y2 = np.sum(np.sum(y * y))
numerator = n * sum_xy - sum_x * sum_y # 分子
denominator = np.sqrt((n * sum_x2 - sum_x * sum_x) * (n * sum_y2 - sum_y * sum_y)) # 分母
if denominator == 0:
return 0
pc = round(float(numerator / denominator), 2)
print("p氏距离:", pc)
return pc
# 计算N维向量的夹角
def calc_vector_cos(self, current_user, other_user):
'''
current_user: 当前用户
other_user: 其他用户
cos=(ab的内积)/(|a||b|)
:param a: 向量a
:param b: 向量b
:return: 夹角值
'''
current_user_vector = [] # 当前用户向量
other_user_vector = [] # 其他用户向量
# 循环当前用户的评分信息
for item_id, score in current_user.items():
current_user_vector.append(1) # 当前用户有评分,入栈1
if other_user.get(item_id, 0) > 0:
# 如果其他用户也评分过这本书,入栈1
other_user_vector.append(1)
else:
other_user_vector.append(0)
a_n = np.array(current_user_vector)
b_n = np.array(other_user_vector)
if any(b_n) == 0:
if self.is_print:
print('值为0')
return 0
cos_ab = a_n.dot(b_n) / (np.linalg.norm(a_n) * np.linalg.norm(b_n))
if self.is_print:
print('值为', round(cos_ab, 2))
return round(cos_ab, 2)
# 计算与当前用户的距离,获得最临近的用户
def nearest_user(self, username, n=1):
distances = {}
# 用户,相似度
# 遍历整个数据集
for user, rate_set in self.data.items():
# 非当前的用户
if user != username:
if self.is_print:
print('获取{}与{}的向量夹角'.format(username, user))
distance = self.calc_vector_cos(self.data[username], self.data[user])
# 计算两个用户的相似度
if distance > 0:
distances[user] = distance
closest_distance = sorted(distances.items(), key=operator.itemgetter(1), reverse=True)
# 最相似的N个用户
closest_users = []
for cd in closest_distance:
if cd[1] == 1:
closest_users.append(cd)
else:
if len(closest_users) >= n:
break
closest_users.append(cd)
if self.is_print:
print("最相近的{}位用户:".format(n), closest_users)
return closest_users
# 给用户推荐书籍
def recommend_cos(self, username, n=1):
recommend = {}
nearest_user = self.nearest_user(username, n)
for user, score in dict(nearest_user).items(): # 最相近的n个用户
for book_id, scores in self.data[user].items(): # 推荐的用户的书籍列表
if book_id not in self.data[username].keys(): # 当前username没有看过
# 如果推荐用户评分低于3分,则表明用户不喜欢此书籍,则不推荐给别的用户
# rate_rec = RateBook.objects.filter(book_id=book_id, user__username=user) # 推荐用户的评分
# if rate_rec and rate_rec.first().mark < 3:
# continue
if book_id not in recommend.keys(): # 添加到推荐列表中
recommend[book_id] = scores
# 对推荐的结果按照书籍浏览次数排序
return sorted(recommend.items(), key=operator.itemgetter(1), reverse=True)
def calc_user_sim(self, username):
# 计算用户之间的兴趣相似度
print ('计算用户之间的兴趣相似度')
item2users = dict()
for user, items in self.data.items():
for item in items: # 遍历每一个物品
if item not in item2users:
item2users[item] = set() # 每个物品用户评过分的集合
item2users[item].add(user) # 将该用户加入到该物品用户评过分的集合中
self.item_count = len(item2users) # 获得物品的数量
print ('物品 number = %d' % self.item_count)
# count co-rated items between users
usersim_mat = self.user_sim_mat # 用户之间的兴趣相似度矩阵
print ('创建用户之间的兴趣相似度矩阵')
for item, users in item2users.items(): # 循环每一个键值对,即 for key,values in xxx.items()
for u in users: # u、v用户是否在同一个物品的评分集合里面
usersim_mat.setdefault(u, defaultdict(int))
for v in users:
if u == v:
continue
usersim_mat[u][v] += 1 # 如果在同一个物品的评分集合里面,则兴趣点加1
for u, related_users in usersim_mat.items():
for v, count in related_users.items():
sim_value = round(count / math.sqrt(len(self.data[u]) * len(self.data[v])), 2)
usersim_mat[u][v] = sim_value #计算两个用户的兴趣相似度
if u == username:
print('{}与{}的兴趣相似度值为'.format(username, v), sim_value)
def recommend(self, user, k=20, N=10):
'''
k:兴趣度最近的20个用户,
N:最适合的10个物品
找到兴趣最近的前20个用户,从中找到最适合的前10个物品
'''
self.calc_user_sim(user) # 计算用户相似度
rank = dict()
watched_items = self.data[user] # 当前用户评分过的物品
for similar_user, similarity_factor in sorted(self.user_sim_mat[user].items(), key=itemgetter(1), reverse=True)[0:k]:
# 排序,找出兴趣相似度最高的前20个用户
print(similar_user, self.data[similar_user])
for item in self.data[similar_user]:
if item in watched_items: # 如果该物品被该用户评分过,则跳过
continue
rank.setdefault(item, 0)
rank[item] += round(similarity_factor, 2)
# 返回最好的N个物品
return sorted(rank.items(), key=itemgetter(1), reverse=True)[0:N]
def recommend_by_user_id(user_id, book_id=None, is_rec_list=False):
'''
通过用户协同算法来进行推荐
user_id: 用户id
book_id: 用户已经评分过的书籍id,需要在推荐列表中去除
is_rec_list: 值为True:返回推荐[用户-评分]列表,值为False:返回推荐的书籍列表
'''
#
current_user = User.objects.get(id=user_id)
# 如果当前用户没有打分 则按照热度顺序返回
if current_user.ratebook_set.count() == 0:
if is_rec_list:
return []
# 推荐列表为空,按用户注册时选择的书籍类别各返回10门
return get_select_tag_book(user_id, book_id)
# 方式1
user_item_rate = {} # 用户-物品-评分字典
for rate in RateBook.objects.all():
user = rate.user.username # 用户id
item_id = rate.book.id # 物品id
rating = rate.mark # 评分
if user not in user_item_rate:
user_item_rate.setdefault(user, {})
user_item_rate[user][item_id] = int(rating) # 建立用户-物品-评分的字典
user_cf = UserCf(data=user_item_rate)
recommend_list = user_cf.recommend(current_user.username, k=10) # 只取最相似的10位用户
# 方式2
# users = User.objects.all()
# all_user = {}
# for user in users:
# rates = user.ratebook_set.all()
# rate = {}
# # 用户有给图书打分
# if rates:
# for i in rates:
# rate.setdefault(i.book.id, i.mark)
# all_user.setdefault(user.username, rate)
# else:
# # 用户没有为书籍打过分,设为0
# all_user.setdefault(user.username, {})
#
# print("this is all user:", all_user)
# user_cf = UserCf(data=user_item_rate)
# recommend_list = user_cf.recommend_cos(current_user.username, n=10) # 只取最相似的10位用户
if not recommend_list:
# 推荐列表为空,且is_rec_list: 值为True:返回推荐[用户-评分]列表
if is_rec_list:
return []
# 推荐列表为空,按用户注册时选择的书籍类别
return get_select_tag_book(user_id, book_id)
if is_rec_list:
# 推荐列表不为空,且且is_rec_list: 值为True:返回推荐[用户-评分]列表
return recommend_list
book_ids = [s[0] for s in recommend_list]
# 过滤掉用户反馈过不喜欢的书籍
unlike_book_ids = [d['book_id'] for d in LikeRecommendBook.objects.filter(user_id=user_id, is_like=0).values('book_id')]
if book_id and book_id not in unlike_book_ids:
unlike_book_ids.append(book_id)
book_list = Book.objects.filter(id__in=book_ids).exclude(id__in=unlike_book_ids).distinct().order_by("-like_num")
return book_list
# 基于物品推荐
class ItemCf:
# 基于物品协同算法来获取推荐列表
'''
1.构建⽤户–>物品的对应表
2.构建物品与物品的关系矩阵(同现矩阵)
3.通过求余弦向量夹角计算物品之间的相似度,即计算相似矩阵
4.根据⽤户的历史记录,给⽤户推荐物品
'''
def __init__(self, data, user_id, is_print=True):
self.user_id = user_id # 用户id
self.data = data # 用户id
self.is_print = is_print # 是否在控制台输出
def similarity(self, data):
# 1 构造物品:物品的共现矩阵
N = {} # 喜欢物品i的总⼈数
C = {} # 喜欢物品i也喜欢物品j的⼈数
for user, item in data.items():
for i, score in item.items():
N.setdefault(i, 0)
N[i] += 1
C.setdefault(i, {})
for j, scores in item.items():
if j != i:
C[i].setdefault(j, 0)
C[i][j] += 1
if self.is_print:
print("---1.构造的共现矩阵---")
print('N:', N)
print('C', C)
# 2 计算物品与物品的相似矩阵
W = {}
for i, item in C.items():
W.setdefault(i, {})
for j, item2 in item.items():
W[i].setdefault(j, 0)
W[i][j] = C[i][j] / sqrt(N[i] * N[j])
if self.is_print:
print("---2.构造的相似矩阵---")
print(W)
return W
def recommand_list(self, data, W, user, k=3, N=10):
'''
# 3.根据⽤户的历史记录,给⽤户推荐物品
:param data: 用户数据
:param W: 相似矩阵
:param user: 推荐的用户
:param k: 相似的k个物品
:param N: 推荐物品数量
:return:
'''
rank = {}
for i, score in data[user].items(): # 获得⽤户user历史记录,如A⽤户的历史记录为{'唐伯虎点秋香': 5, '逃学威龙1': 1, '追龙': 2}
for j, w in sorted(W[i].items(), key=operator.itemgetter(1), reverse=True)[0:k]: # 获得与物品i相似的k个物品
if j not in data[user].keys(): # 该相似的物品不在⽤户user的记录⾥
rank.setdefault(j, 0)
rank[j] += float(score) * w # 预测兴趣度=评分*相似度
if self.is_print:
print("---3.推荐----")
print(sorted(rank.items(), key=operator.itemgetter(1), reverse=True)[0:N])
return sorted(rank.items(), key=operator.itemgetter(1), reverse=True)[0:N]
def recommendation(self, k=3, N=10):
"""
给用户推荐相似书籍
:param k: 相似的k个物品
:param N: 推荐物品数量
"""
if not self.data or self.user_id not in self.data:
# 用户没有评分过任何书籍,就返回空列表
return []
W = self.similarity(self.data) # 计算物品相似矩阵
sort_rank = self.recommand_list(self.data, W, self.user_id, k, N) # 推荐
return sort_rank
def recommend_by_item_id(user_id, book_id=None, is_rec_list=False, k=3, N=10):
'''
通过物品协同算法来进行推荐
user_id: 用户id
book_id: 用户已经评分过的书籍id,需要在推荐列表中去除
is_rec_list: 值为True:返回推荐[用户-评分]列表,值为False:返回推荐的书籍列表
k: 相似的k个物品
N: 推荐物品数量
'''
user_item_rate = {} # 用户-物品-评分字典
for rate in RateBook.objects.all():
user = rate.user.id # 用户id
item_id = rate.book.id # 物品id
rating = rate.mark # 评分
if user not in user_item_rate:
user_item_rate.setdefault(user, {})
user_item_rate[user][item_id] = int(rating) # 建立用户-物品-评分的字典
recommend_list = ItemCf(user_item_rate, user_id).recommendation(k=k, N=N) # 物品协同过滤得到的推荐列表
if not recommend_list:
# 推荐列表为空
# 推荐列表为空,且is_rec_list: 值为True:返回推荐[用户-评分]列表
if is_rec_list:
return []
# 推荐列表为空,按用户注册时选择的书籍类别
return get_select_tag_book(user_id, book_id)
if is_rec_list:
# 推荐列表不为空,且且is_rec_list: 值为True:返回推荐[用户-评分]列表
return recommend_list
book_ids = [s[0] for s in recommend_list]
# 过滤掉用户反馈过不喜欢的书籍
unlike_book_ids = [d['book_id'] for d in
LikeRecommendBook.objects.filter(user_id=user_id, is_like=0).values('book_id')]
if book_id and book_id not in unlike_book_ids:
unlike_book_ids.append(book_id)
book_list = Book.objects.filter(id__in=book_ids).exclude(id__in=unlike_book_ids).distinct().order_by("-like_num")
return book_list
def recommend_by_mixture(user_id, book_id=None):
# 混合推荐算法
# 推荐列表 = w*P_cu + (1-w)* p_cf
cu_list = recommend_by_user_id(user_id, book_id=book_id, is_rec_list=True) # 用户协同过滤得到的推荐列表
cf_list = recommend_by_item_id(user_id, book_id=book_id, is_rec_list=True) # 物品协同过滤得到的推荐列表
if not cu_list:
# 用户协同过滤推荐列表为空
if not cf_list:
# 物品协同过滤列表也为空,则按用户注册时选择的书籍类别各返回10门
return get_select_tag_book(user_id, book_id)
# 返回物品协同过滤列表中的书籍
book_ids = [s[0] for s in cf_list]
unlike_book_ids = [d['book_id'] for d in
LikeRecommendBook.objects.filter(user_id=user_id, is_like=0).values('book_id')]
if book_id and book_id not in unlike_book_ids:
unlike_book_ids.append(book_id)
book_list = Book.objects.filter(id__in=book_ids).exclude(id__in=unlike_book_ids).distinct().order_by(
"-like_num")[:10]
if not book_list:
# 推荐列表为空
return get_select_tag_book(user_id, book_id)
return book_list
else:
if not cf_list:
# 物品协同过滤列表为空,则返回用户协同过滤列表中的书籍
book_ids = [s[0] for s in cu_list]
unlike_book_ids = [d['book_id'] for d in
LikeRecommendBook.objects.filter(user_id=user_id, is_like=0).values('book_id')]
if book_id and book_id not in unlike_book_ids:
unlike_book_ids.append(book_id)
book_list = Book.objects.filter(id__in=book_ids).exclude(id__in=unlike_book_ids).distinct().order_by(
"-like_num")[:10]
if not book_list:
# 推荐列表为空
return get_select_tag_book(user_id, book_id)
return book_list
# 混合推荐
# 权重因子,通过统计用户对推荐列表中喜欢的书籍数量来给出权重因子的值
like_list = [d['is_like'] for d in LikeRecommendBook.objects.filter(user_id=user_id).values('is_like')]
if len(like_list):
w = 1 - round(Counter(like_list)[0] / len(like_list), 2)
else:
w = 0.5
if w == 0:
w = 0.5
print('权重因子', w)
# 从cu_list取w%个值,从cf_list取(1-w)个值然后合并
cu_len = int(len(cu_list) * w)
cf_len = int(len(cf_list) * (1 - w))
# 从用户推荐列表中获取cu_len个值,从物品推荐列表中获取cf_len个值,然后并起来形成推荐列表
recommend_list = [cu[0] for cu in cu_list[:cu_len]] + [cf[0] for cf in cf_list[:cf_len]]
if recommend_list:
unlike_book_ids = [d['book_id'] for d in LikeRecommendBook.objects.filter(user_id=user_id, is_like=0).values('book_id')]
if book_id and book_id not in unlike_book_ids:
unlike_book_ids.append(book_id)
book_list = Book.objects.filter(id__in=recommend_list).exclude(id__in=unlike_book_ids).distinct().order_by("-like_num")
if not book_list:
# 推荐列表为空
return get_select_tag_book(user_id, book_id)
return book_list
# 混合推荐集合为空,则按用户注册时选择的书籍类别各返回10门
return get_select_tag_book(user_id, book_id)
# 基于机器学习推荐
def recommend_by_k_mean(user_id, book_id=None, book_data=None, is_rec_list=False, is_print=True):
# 使用机器学习K-means聚类算法推荐用户喜欢的书籍
data = [] # 用户书籍类型挑选列表
tag_dict = collections.OrderedDict() # 书籍类型字典(有序字典)
# 获取所有类型,并设置值为0
for tag in Tags.objects.filter(is_show=True):
tag_dict[tag.name] = 0
# 获取用户喜欢的书籍类型
us = UserSelectTypes.objects.get(user_id=user_id)
for category in us.category.filter(is_show=True):
# 在类型字典中设置用户喜欢的类型为1
tag_dict[category.name] = 1
data.append(list(tag_dict.values()))
tag_like_list = predict(data) # 预测数据
if not tag_like_list:
# 预测推荐书籍集合为空,则按用户注册时选择的书籍类别各返回3门
return get_select_tag_book(user_id, book_id)[:3]
index = 0
recommend_tag = []
for tag, value in tag_dict.items():
if tag_like_list[index] == 1:
# 用户喜欢的书籍类型
recommend_tag.append(tag)
index += 1
if is_print:
print('推荐的书籍类型', recommend_tag)
rank_set = set() # 推荐书籍id集合
rank_list = []
# 获取各推荐书籍类型中排行前三的书籍推荐给用户,其中排行按照收藏量来计算
for tag in recommend_tag:
books = Book.objects.filter(tags__name=tag).order_by("-collect_num")[:3]
for book in books:
rank_set.add(book.id)
if book_data and book.id in book_data:
if (book.id, 5) not in rank_list:
rank_list.append((book.id, 5))
if is_print:
print('推荐的书籍列表id', rank_set)
if is_rec_list:
return rank_list
if rank_set:
book_list = Book.objects.filter(id__in=rank_set).exclude(id=book_id).distinct().order_by("-like_num")[:3]
return book_list
# 预测推荐书籍集合为空,则按用户注册时选择的书籍类别各返回3门
return get_select_tag_book(user_id, book_id)[:3]
# 算法评价指标:召回率,准确率,覆盖率,新颖度
class EvaluateIndicator:
def __init__(self):
self.trainset = {} # 训练数据集
self.testset = {} # 测试数据集
self.n_sim_user = 20 # 兴趣最近的20个用户
self.n_rec_item = 10 # 系统推荐的10个物品
self.user_sim_mat = {} # 用户兴趣相似度矩阵
self.item_popular = {} # 物品的欢迎系数
self.item_count = 0 # 物品的数量
self.precision_data = [] # 准确率
self.recall_data = [] # 召回率
self.coverage_data = [] # 覆盖率
self.popularity_data = [] # 新颖度
self.f1_score_data = [] # f1_score
def generate_dataset(self, pivot=0.7):
'''
从用户评分数据表中划分训练集与测试集
'''
# 获取评分表中是所有数据
for rate in RateBook.objects.all():
user = rate.user.id # 用户id
item_id = rate.book.id # 物品id
rating = rate.mark # 评分
# 加入训练集,训练集和测试集七三开
if random.random() < pivot:
self.trainset.setdefault(user, {})
self.trainset[user][item_id] = int(rating) # 建立用户-物品-评分的字典
else: # 加入测试集
self.testset.setdefault(user, {})
self.testset[user][item_id] = int(rating)
print('训练集数量', len(self.trainset))
print('测试集数量', len(self.testset))
self.item2users = dict()
for user, items in self.trainset.items():
for item in items: # 遍历每一个物品
if item not in self.item2users:
self.item2users[item] = set() # 每个物品用户评过分的集合
self.item2users[item].add(user) # 将该用户加入到该物品用户评过分的集合中
if item not in self.item_popular: # 如果该物品不在物品流行度数组
self.item_popular[item] = 0 # 将该物品的流行度初始化为0
self.item_popular[item] += 1 # 每个物品的评分人数加1
self.item_count = len(self.item2users) # 获得物品的数量
def calc_user_sim(self):
# 用户协同过滤:计算用户之间的兴趣相似度
usersim_mat = self.user_sim_mat # 用户之间的兴趣相似度矩阵
for item, users in self.item2users.items(): # 循环每一个键值对,即 for key,values in xxx.items()
for u in users: # u、v用户是否在同一个物品的评分集合里面
usersim_mat.setdefault(u, defaultdict(int))
for v in users:
if u == v:
continue
usersim_mat[u][v] += 1 # 如果在同一个物品的评分集合里面,则兴趣点加1
simfactor_count = 0
for u, related_users in usersim_mat.items():
for v, count in related_users.items():
usersim_mat[u][v] = count / math.sqrt(len(self.trainset[u]) * len(self.trainset[v])) # 计算两个用户的兴趣相似度
simfactor_count += 1
def recommend(self, user):
''' 找到兴趣最近的前20个用户,从中找到最适合的前10个物品'''
self.calc_user_sim() # 计算用户的相似度
K = self.n_sim_user # 前面给出是20
N = self.n_rec_item # 前面给出是10
rank = dict()
watched_items = self.trainset[user] # 当前用户评分过的物品
print('最相似的用户', sorted(self.user_sim_mat[user].items(), key=itemgetter(1), reverse=True)[0:K])
for similar_user, similarity_factor in sorted(self.user_sim_mat[user].items(), key=itemgetter(1), reverse=True)[
0:K]:
# 排序,找出兴趣相似度最高的前20个用户
for item in self.trainset[similar_user]:
if item in watched_items: # 如果该物品被该用户评分过,则跳过
continue
rank.setdefault(item, 0)
rank[item] += round(similarity_factor, 2)
# 返回最好的N个物品
return sorted(rank.items(), key=itemgetter(1), reverse=True)[0:N]
def evaluate_ucf(self):
'''
输出用户协同过滤算法的评价指标:
precision, recall, coverage and popularity
召回率、准确率、覆盖率、新颖度
'''
K = self.n_sim_user # 前面给出是20
N = self.n_rec_item # 前面给出是10
# 召回率参数
hit = 0 # 成功推荐的物品数
rec_count = 0 # 总 共推荐了多少个物品
test_count = 0 # 测试集中的物品数
# 准确率参数
all_rec_items = set() # 成功推荐的物品
# 新颖度参数
popular_sum = 0
for i, user in enumerate(self.trainset):
# i为下标,user为训练集的内容
test_items = self.testset.get(user, {})
'''
推荐列表:示例 [(256, 4), (1840, 4), (10598, 3)]
(256, 4):第一个值表示物品Id,第二个值表示评分
这里按照同样的返回即可测试其他推荐算法的召回率,准确率,覆盖率,新颖度,F1-score
'''
rec_items = UserCf(data=self.trainset, is_print=False).recommend_cos(user, n=K)[:N] # 只取最相似的10位用户
# rec_items = self.recommend(user) # 获取针对用户user的推荐物品列表
for item, _ in rec_items:
if item in test_items:
hit += 1
all_rec_items.add(item)
popular_sum += math.log(1 + self.item_popular[item])
rec_count += len(rec_items)
test_count += len(test_items)
if rec_count == 0:
precision = 0
else:
precision = hit / (1.0 * rec_count) # 准确率
recall = hit / (1.0 * test_count) # 召回率
coverage = len(all_rec_items) / (1.0 * self.item_count) # 覆盖率
if rec_count == 0:
popularity = 0
else:
popularity = popular_sum / (1.0 * rec_count) # 新颖度
if (precision + recall) > 0:
f1_score = round(2 * (precision * recall) / (precision + recall), 2)
else:
f1_score = 0
print('用户协同过滤推荐算法的评价指标:')
print('准确率=%.4f\t召回率=%.4f\t覆盖率=%.4f\t新颖度=%.4f' % (precision, recall, coverage, popularity))
print('F1-score', f1_score)
self.precision_data.append(precision)
self.recall_data.append(recall)
self.coverage_data.append(coverage)
self.popularity_data.append(popularity)
self.f1_score_data.append(f1_score)
def evaluate_icf(self):
'''
输出物品协同过滤算法的评价指标:
precision, recall, coverage and popularity
召回率、准确率、覆盖率、新颖度
'''
K = self.n_sim_user # 前面给出是20
N = self.n_rec_item # 前面给出是10
# 召回率参数
hit = 0 # 成功推荐的物品数
rec_count = 0 # 总 共推荐了多少个物品
test_count = 0 # 测试集中的物品数
# 准确率参数
all_rec_items = set() # 成功推荐的物品
# 新颖度参数
popular_sum = 0
for i, user in enumerate(self.trainset):
# i为下标,user为训练集的内容
test_items = self.testset.get(user, {})
rec_items = ItemCf(self.trainset, user, is_print=False).recommendation(k=K, N=N)[:N] # 物品协同过滤得到的推荐列表
for item, _ in rec_items:
if item in test_items:
hit += 1
all_rec_items.add(item)
popular_sum += math.log(1 + self.item_popular[item])
rec_count += len(rec_items)
test_count += len(test_items)
if rec_count == 0:
precision = 0
else:
precision = hit / (1.0 * rec_count) # 准确率
recall = hit / (1.0 * test_count) # 召回率
coverage = len(all_rec_items) / (1.0 * self.item_count) # 覆盖率
if rec_count == 0:
popularity = 0
else:
popularity = popular_sum / (1.0 * rec_count) # 新颖度
if (precision + recall) > 0:
f1_score = round(2 * (precision * recall) / (precision + recall), 2)
else:
f1_score = 0
print('物品协同过滤推荐算法的评价指标:')
print('准确率=%.4f\t召回率=%.4f\t覆盖率=%.4f\t新颖度=%.4f' % (precision, recall, coverage, popularity))
print('F1-score', f1_score)
self.precision_data.append(precision)
self.recall_data.append(recall)
self.coverage_data.append(coverage)
self.popularity_data.append(popularity)
self.f1_score_data.append(f1_score)
def evaluate_mix(self):
'''
输出混合推荐过滤算法的评价指标:
precision, recall, coverage and popularity
召回率、准确率、覆盖率、新颖度
'''
K = self.n_sim_user # 前面给出是20
N = self.n_rec_item # 前面给出是10
# 召回率参数
hit = 0 # 成功推荐的物品数
rec_count = 0 # 总 共推荐了多少个物品
test_count = 0 # 测试集中的物品数
# 准确率参数
all_rec_items = set() # 成功推荐的物品
# 新颖度参数
popular_sum = 0
book_data = []
for _, value in self.testset.items():
for name, _ in value.items():
if name not in book_data:
book_data.append(name)
for i, user in enumerate(self.trainset):
# i为下标,user为训练集的内容
test_items = self.testset.get(user, {})
rec_ucf = UserCf(data=self.trainset, is_print=False).recommend_cos(user, n=K)
rec_icf = ItemCf(self.trainset, user, is_print=False).recommendation(k=K, N=N) # 物品协同过滤得到的推荐列表
w = 0.5
# 权重因子,通过统计用户对推荐列表中喜欢的书籍数量来给出权重因子的值 is_like=0表示不喜欢,is_like=1表示喜欢
like_list = [d['is_like'] for d in LikeRecommendBook.objects.filter(user_id=user).values('is_like')]
if len(like_list):
# 列表中值为1的数量/列表总数量,然后取两位小数点
w = round(Counter(like_list)[1] / len(like_list), 2)
if w == 0:
w = 0.5
# 从cu_list取w%个值,从cf_list取(1-w)个值然后合并
cu_len = int(len(rec_ucf) * w)
cf_len = int(len(rec_icf) * (1 - w))
rec_items = [cu for cu in rec_ucf[:cu_len]] + [cf for cf in rec_icf[:cf_len]]
rec_items = rec_items[:N]
for item, _ in rec_items:
if item in test_items:
hit += 1
all_rec_items.add(item)
if item in self.item_popular:
popular_sum += math.log(1 + self.item_popular[item])
rec_count += len(rec_items)
test_count += len(test_items)
if rec_count == 0:
precision = 0
else:
precision = hit / (1.0 * rec_count) # 准确率
recall = hit / (1.0 * test_count) # 召回率
coverage = len(all_rec_items) / (1.0 * self.item_count) # 覆盖率
if rec_count == 0:
popularity = 0
else:
popularity = popular_sum / (1.0 * rec_count) # 新颖度
if (precision + recall) > 0:
f1_score = round(2 * (precision * recall) / (precision + recall), 2)
else:
f1_score = 0
print('混合协同过滤推荐算法的评价指标:')
print('准确率=%.4f\t召回率=%.4f\t覆盖率=%.4f\t新颖度=%.4f' % (precision, recall, coverage, popularity))
print('F1-score', f1_score)
self.precision_data.append(precision)
self.recall_data.append(recall)
self.coverage_data.append(coverage)
self.popularity_data.append(popularity)
self.f1_score_data.append(f1_score)
def evaluate_kmean(self):
'''
输出k-mean过滤算法的评价指标:
precision, recall, coverage and popularity
召回率、准确率、覆盖率、新颖度
'''
K = self.n_sim_user # 前面给出是20
N = self.n_rec_item # 前面给出是10
# 召回率参数
hit = 0 # 成功推荐的物品数
rec_count = 0 # 总 共推荐了多少个物品
test_count = 0 # 测试集中的物品数
# 准确率参数
all_rec_items = set() # 成功推荐的物品
# 新颖度参数
popular_sum = 0
book_data = []
for _, value in self.testset.items():
for name, _ in value.items():
if name not in book_data:
book_data.append(name)
for i, user in enumerate(self.trainset):
# i为下标,user为训练集的内容
test_items = self.testset.get(user, {})
rec_items = recommend_by_k_mean(user, book_data=book_data, is_rec_list=True, is_print=False)[:N] # k-mean过滤
for item, _ in rec_items:
if item in test_items:
hit += 1
all_rec_items.add(item)
if item in self.item_popular:
popular_sum += math.log(1 + self.item_popular[item])
rec_count += len(rec_items)
test_count += len(test_items)
if rec_count == 0:
precision = 0
else:
precision = hit / (1.0 * rec_count) # 准确率
recall = hit / (1.0 * test_count) # 召回率
coverage = len(all_rec_items) / (1.0 * self.item_count) # 覆盖率
if rec_count == 0:
popularity = 0
else:
popularity = popular_sum / (1.0 * rec_count) # 新颖度
if (precision + recall) > 0:
f1_score = round(2 * (precision * recall) / (precision + recall), 2)
else:
f1_score = 0
print('k-means过滤推荐算法的评价指标:')
print('准确率=%.4f\t召回率=%.4f\t覆盖率=%.4f\t新颖度=%.4f' % (precision, recall, coverage, popularity))
print('F1-score', f1_score)
self.precision_data.append(precision)
self.recall_data.append(recall)
self.coverage_data.append(coverage)
self.popularity_data.append(popularity)
self.f1_score_data.append(f1_score)
def show_plt(self):
'''
显示四种算法的折线对比图
'''
from matplotlib import pyplot as plt
from matplotlib.pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
mpl.rcParams['axes.unicode_minus'] = False # 显示负号
x = ['用户协同', '物品协同', '混合协同', 'k-means']
plt.plot(x, self.precision_data, c='blue', marker='o', linestyle=':', label='准确率')
plt.plot(x, self.recall_data, c='red', marker='o', linestyle=':', label='召回率')
plt.plot(x, self.coverage_data, c='green', marker='o', linestyle=':', label='覆盖率')
plt.plot(x, self.popularity_data, c='yellow', marker='o', linestyle=':', label='新颖度')
plt.plot(x, self.f1_score_data, c='black', marker='o', linestyle=':', label='f1_score')
# 图例展示位置,数字代表第几象限
plt.legend(loc=4)
plt.show()
if __name__ == '__main__':
# 参考 https://blog.51cto.com/u_13403836/5674687
random.seed(0) # 设置好随机种子,即相同的随机种子seed
ei = EvaluateIndicator()
ei.generate_dataset() # 划分训练集、测试集
ei.evaluate_ucf() # 用户协同过滤推荐
ei.evaluate_icf() # 物品协同过滤
ei.evaluate_mix() # 混合协同过滤
ei.evaluate_kmean() # k-means过滤
ei.show_plt() # 四种协同算法图像对比


















 1144
1144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











