




python django django-simpleui scrapy mysql vue3 element-plus echarts vue-router pinia
1. scrapy爬虫抓取“懂车帝”网站的汽车及销量数据,还有“车质网”的汽车投诉数据
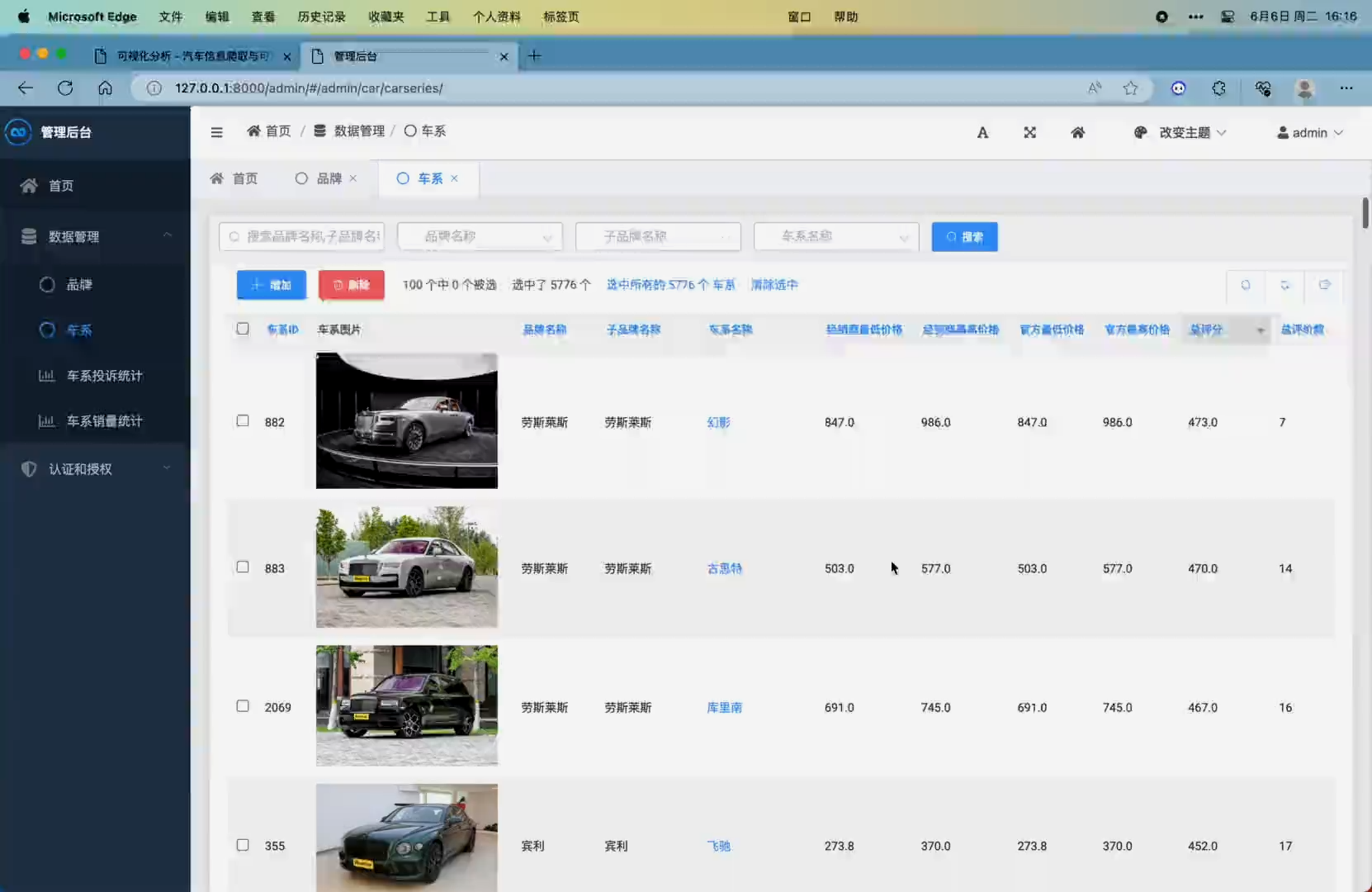
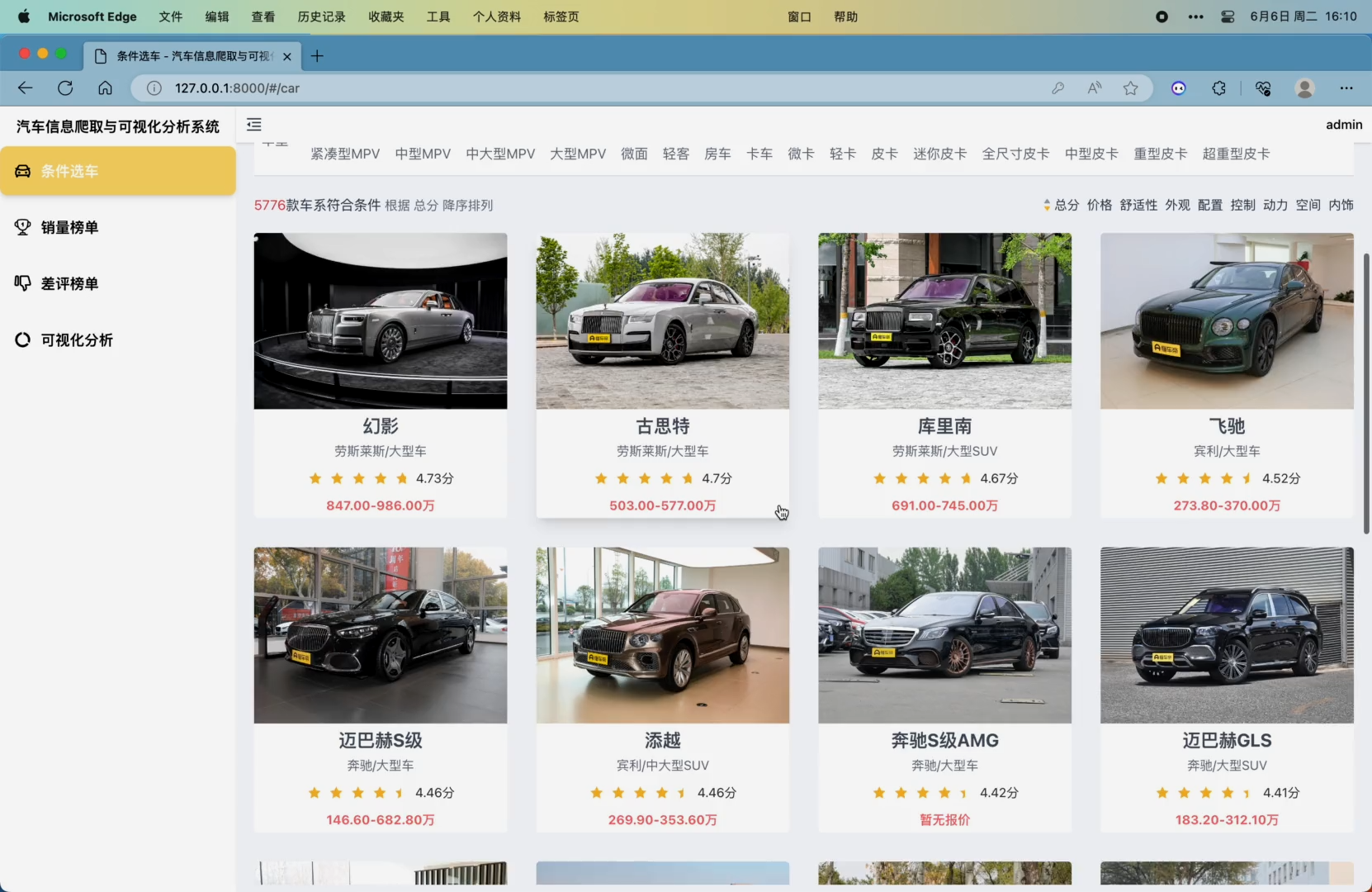
2. 条件选车模块,可根据关键词、品牌、价格、燃料类型、座位、车型等条件对车系进行筛选,同时可以按照总分、价格、舒适性、外观、配置、控制、动力、空间、内饰进行排序,该页面在滚动至底部时会自动翻页
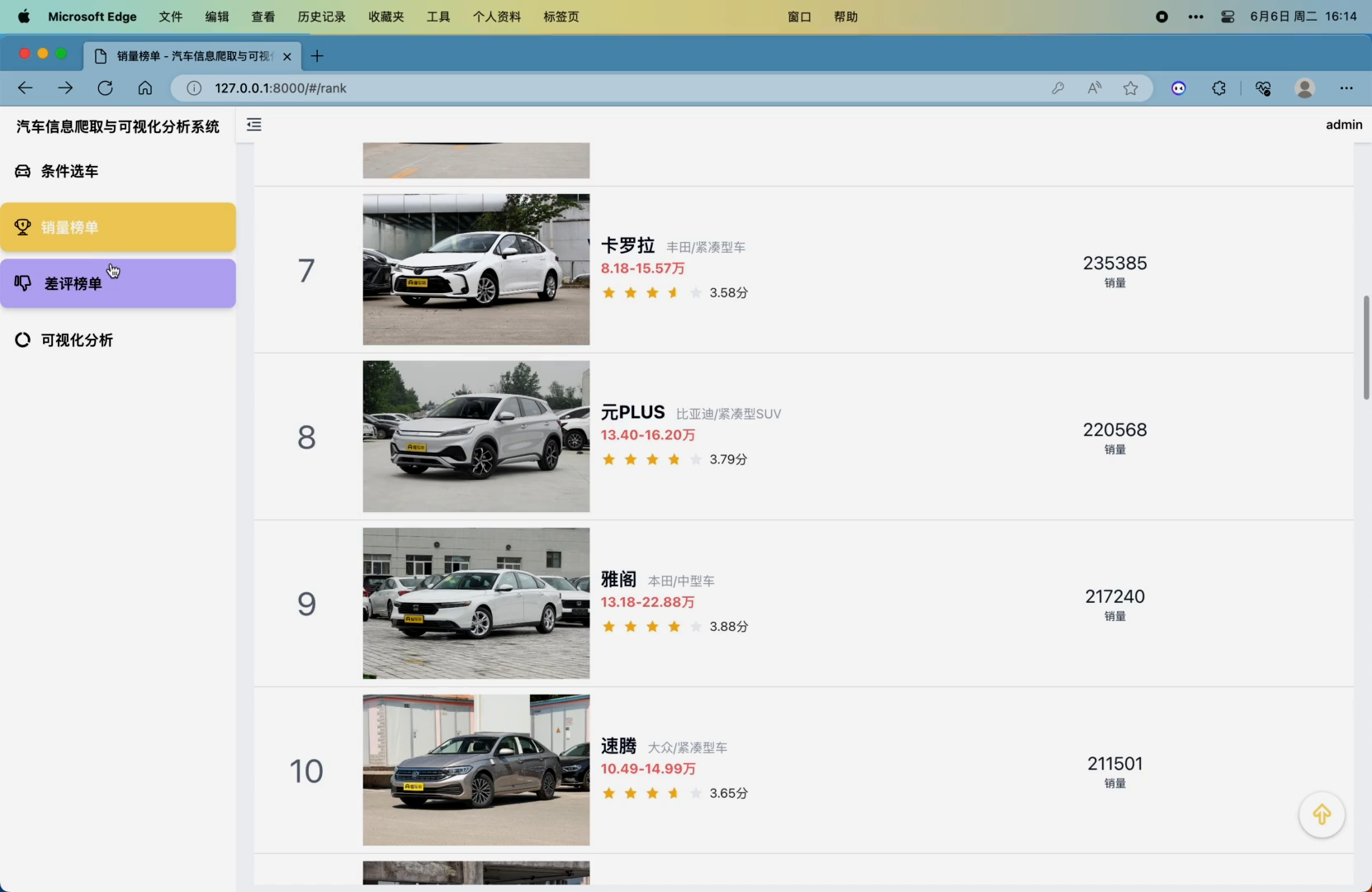
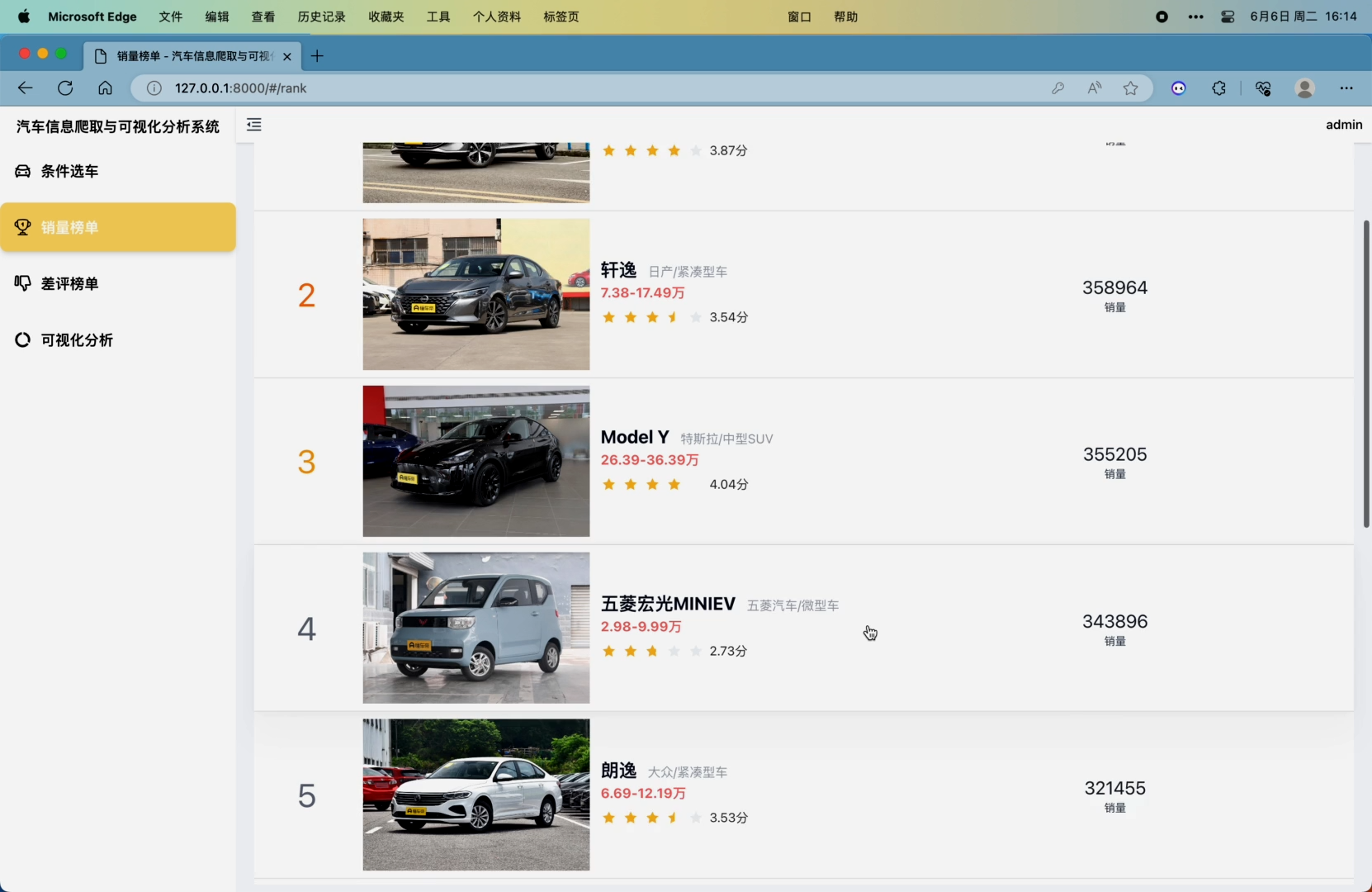
3. 销量榜单模块,可对抓取到的近一年、近半年以及每个月的车系销量数据进行统计并展示排名
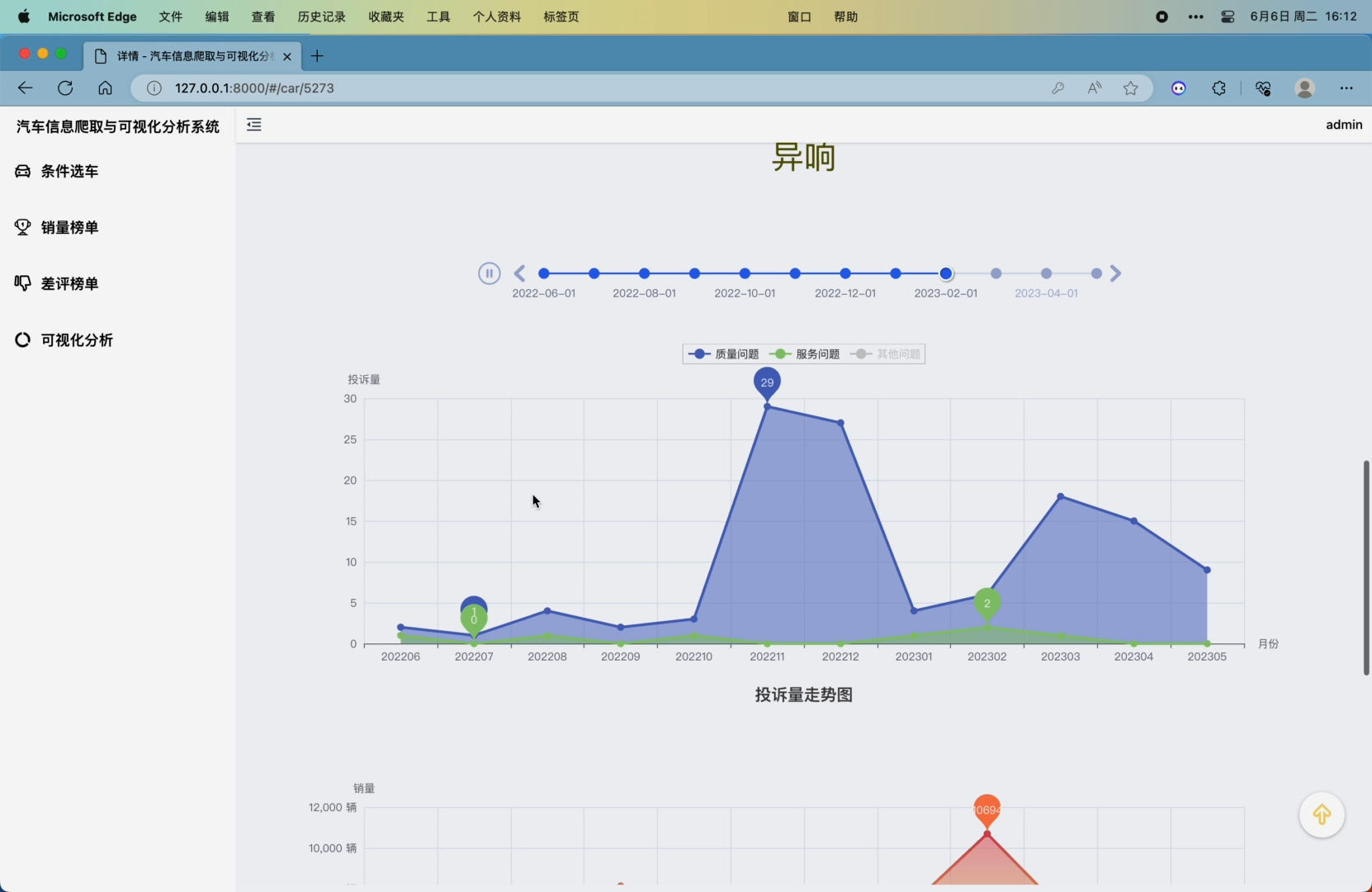
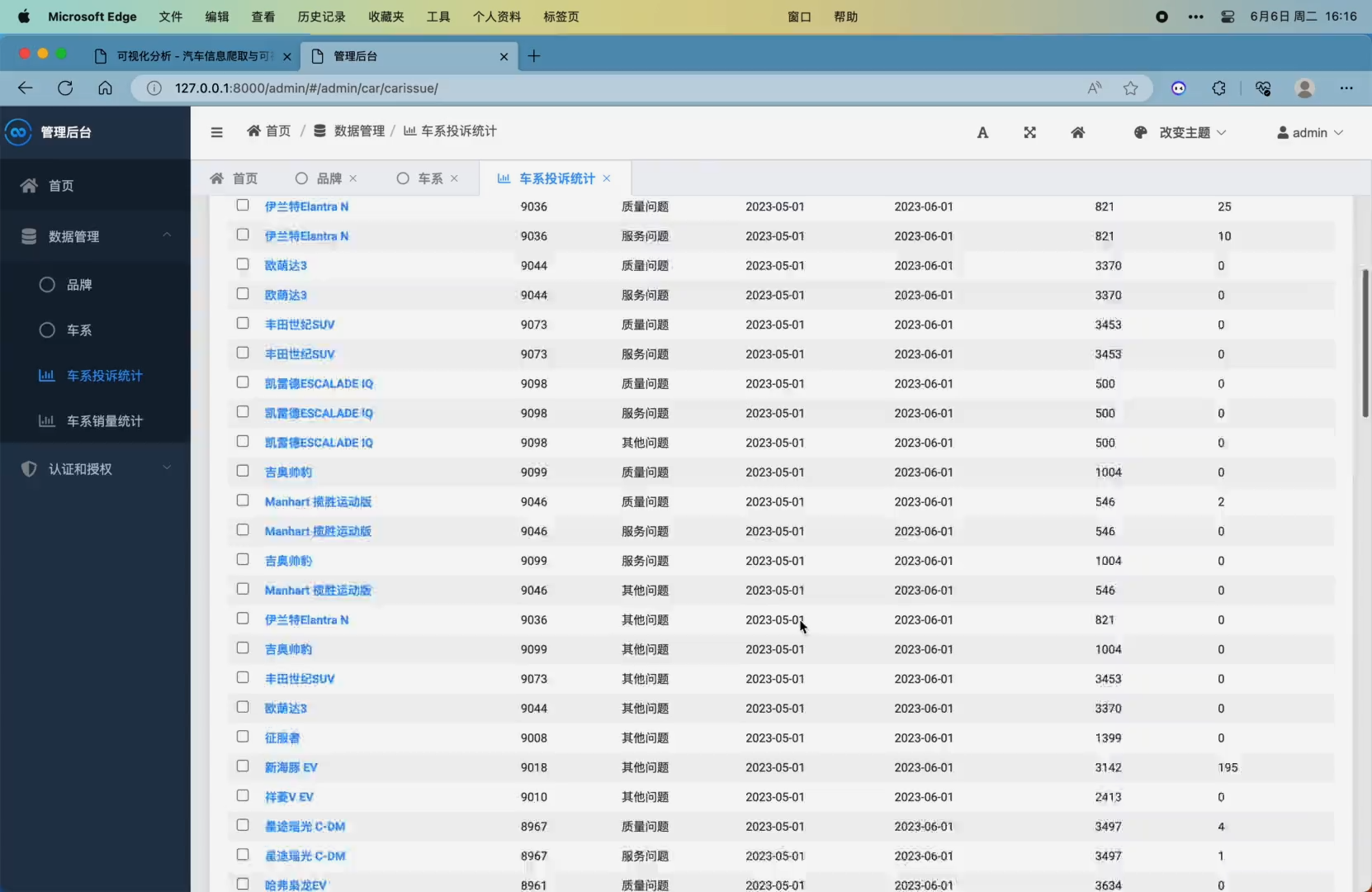
4. 差评榜单模块,可对抓取到的近一年、近半年以及每个月的车系问题投诉数据进行统计并展示排名,可以筛选三种不同的问题,分别是质量问题、服务问题、其他问题
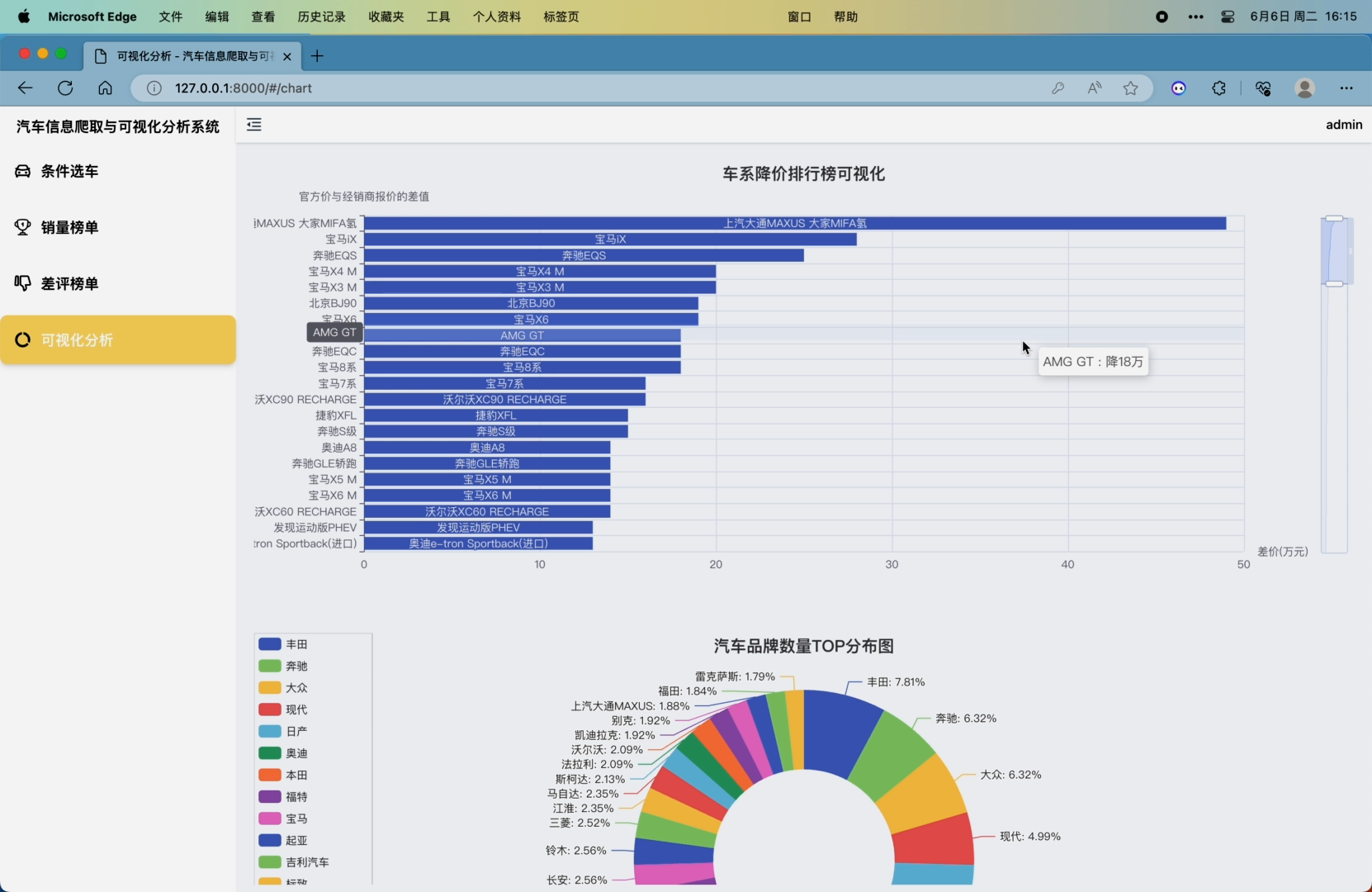
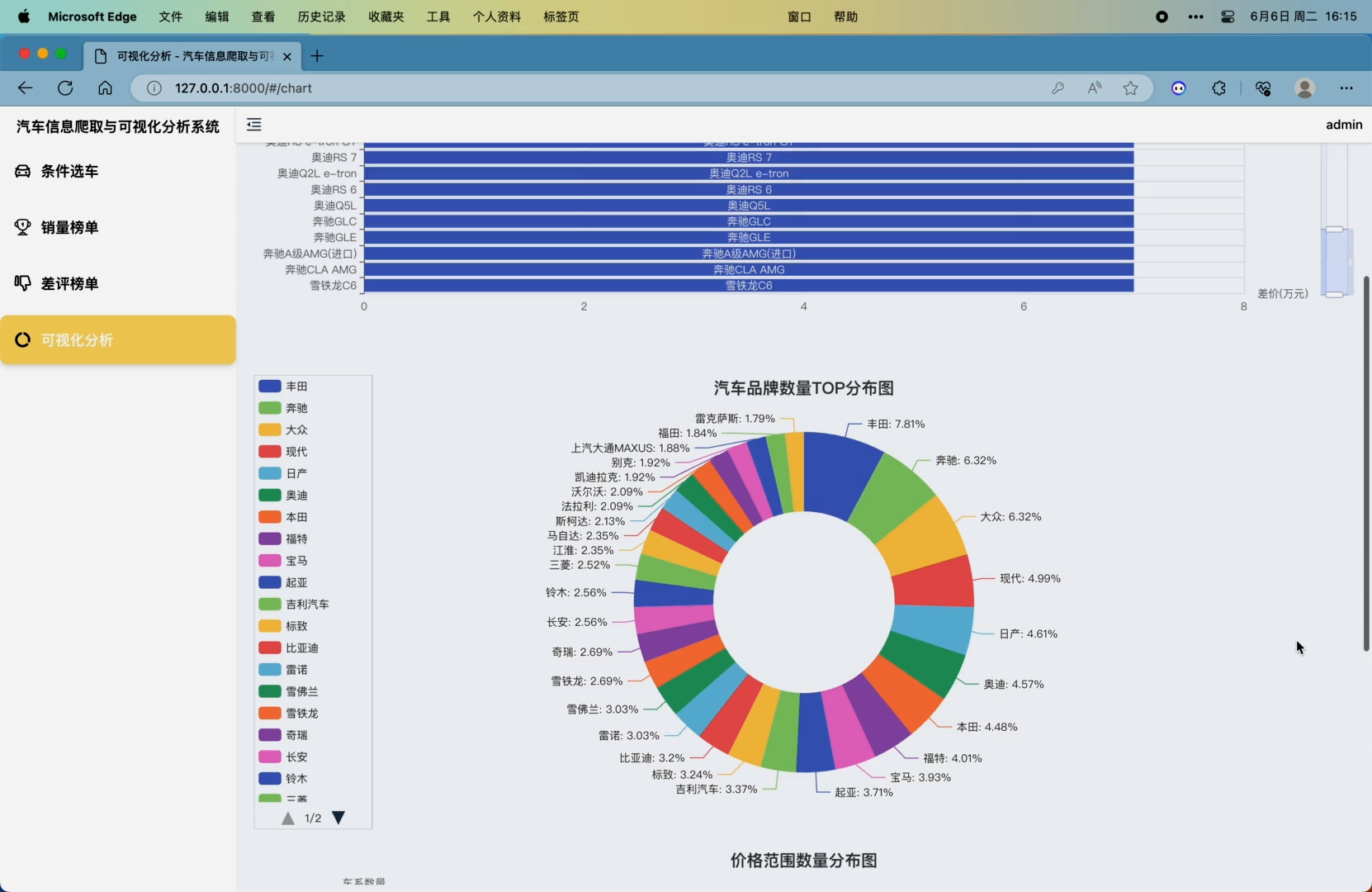
5. 可视化分析模块,包括车系降价排行榜柱状图可视化(官方价减去经销商价格得到降差价)、汽车品牌数量TOP分布图(分析前30个品牌的车系数量的分布)、价格范围数量分布图(对分布在0-10万 10-15万 15-20万 20-25万 25-30万 30-40万 50万以上价格范围的车系数量进行分析)
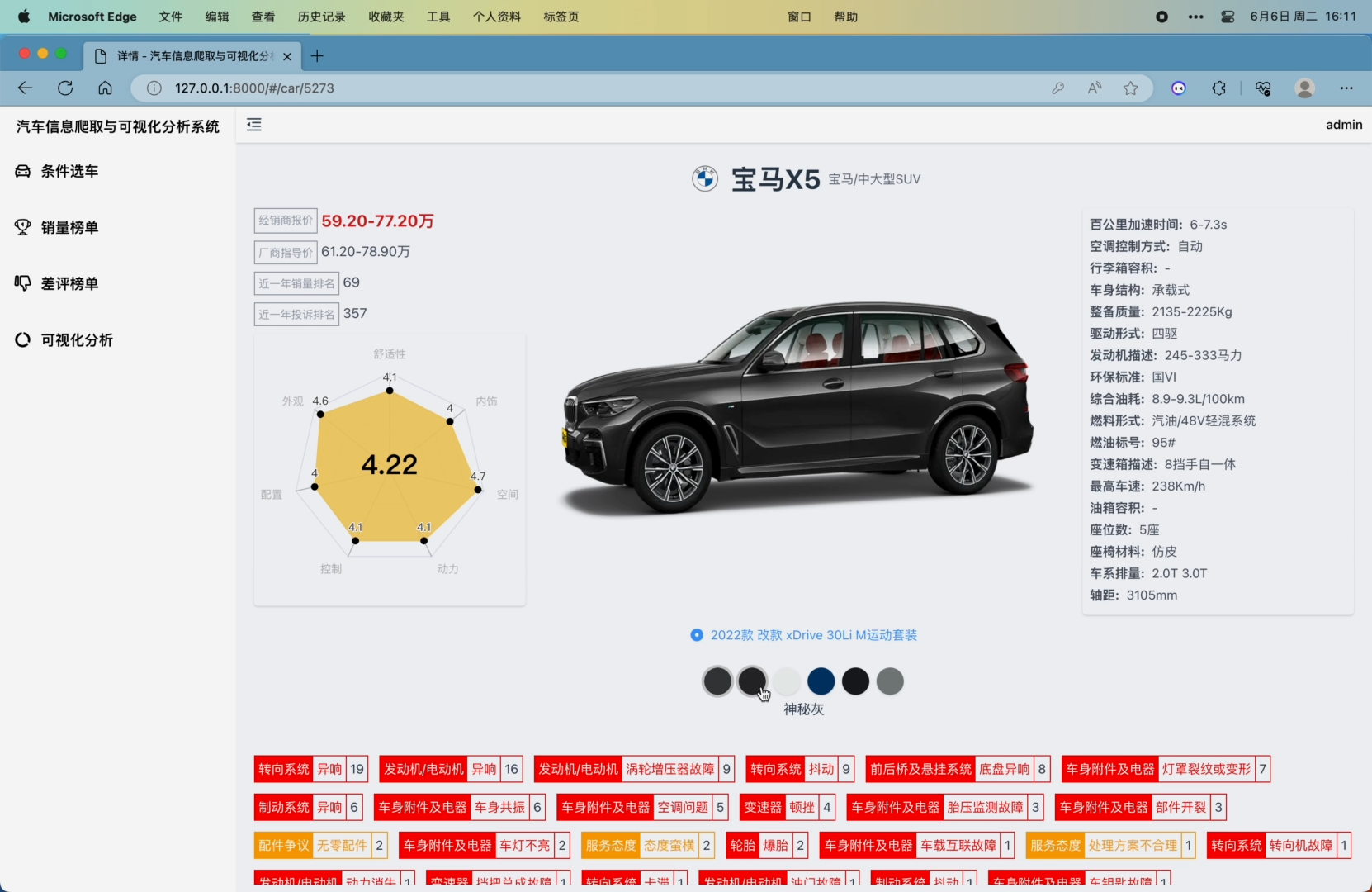
6. 车系详情页面,展示了品牌、车系名、经销商报价、厂商报价、近一年销量排名、投诉量排名、评分雷达图分析面板(舒适性 外观 配置 控制 动力 空间 内饰 这6个维度,雷达图中间显示总分)、汽车数据面板展示(百公里加速时间 空调控制方式 行李箱容积 车身结构 整备质量 驱动形式 发动机描述 环保标准 综合油耗 燃料形式 燃油标号 变速箱描述 最高车速 油箱容积 座位数 座椅材料 车系排量 轴距)、
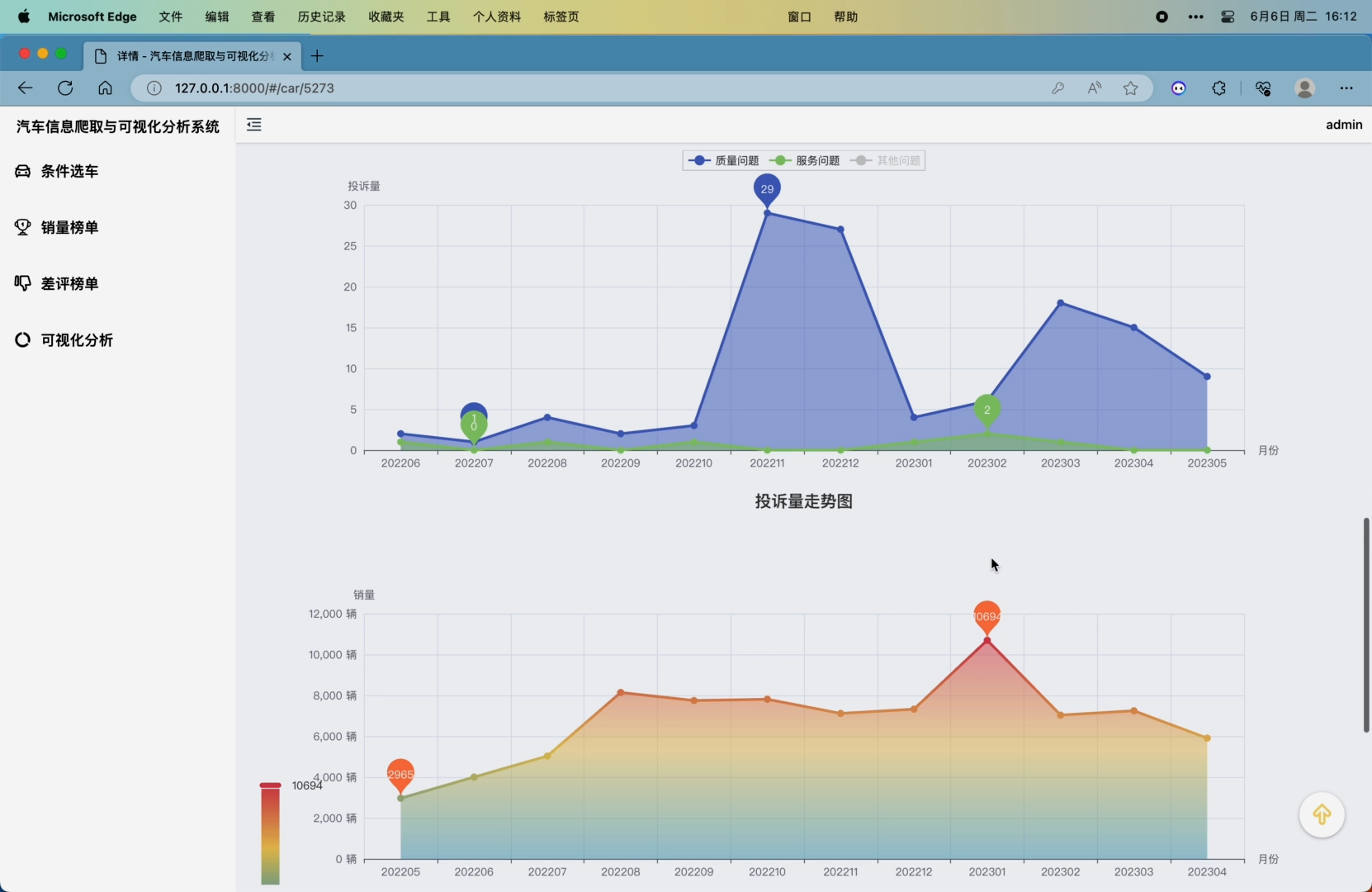
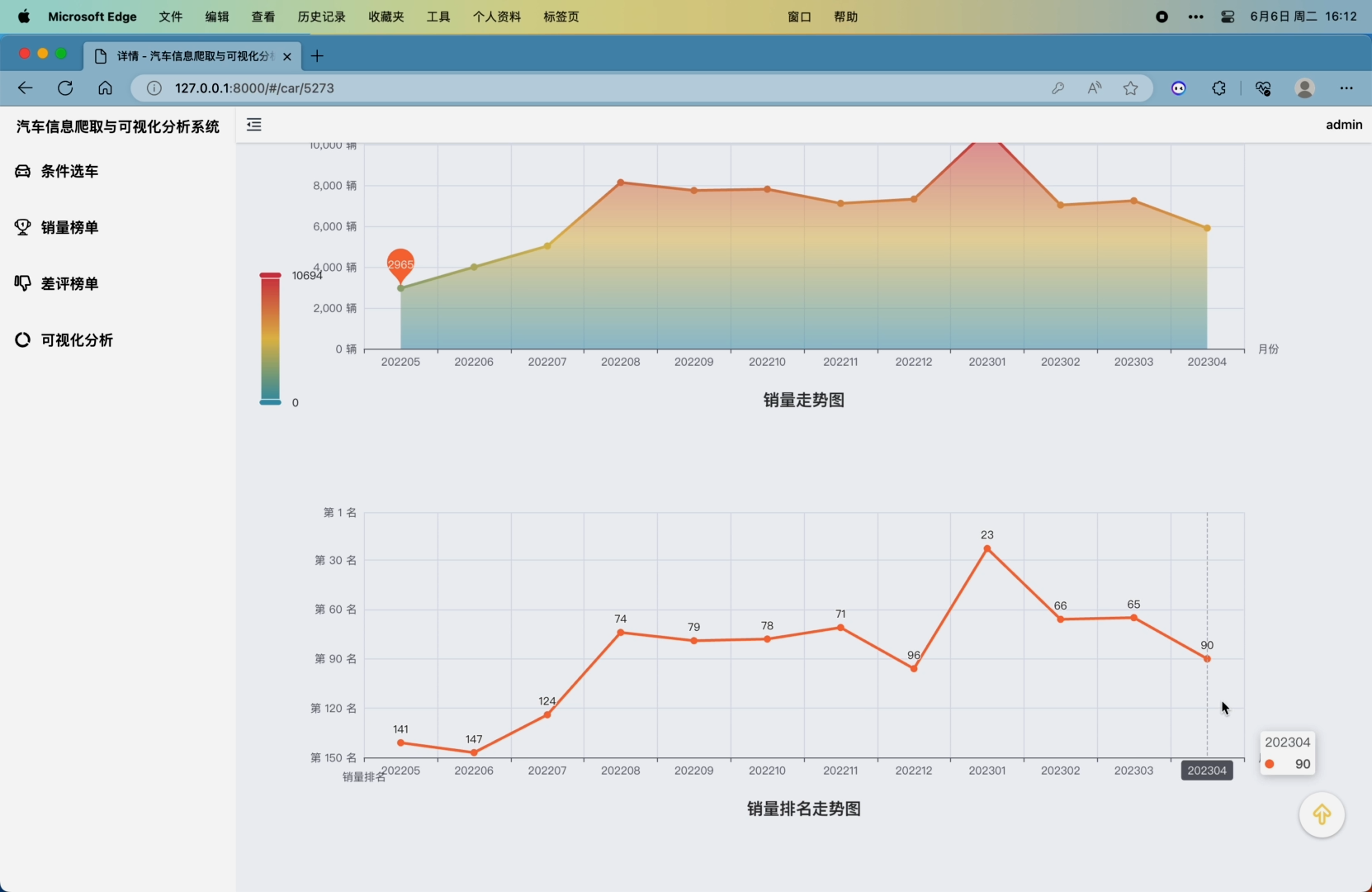
可以通过鼠标左键拖拽或键盘左右键360度查看车系外观图片、以标签形式展示了该车系所有的投诉问题(点击可查看问题详情)、用echarts的Timeline+Wordcloud展示了每个月的质量问题关键词、三种问题的每月投诉量走势图、每月车系销量走势图、每月销量排名走势图
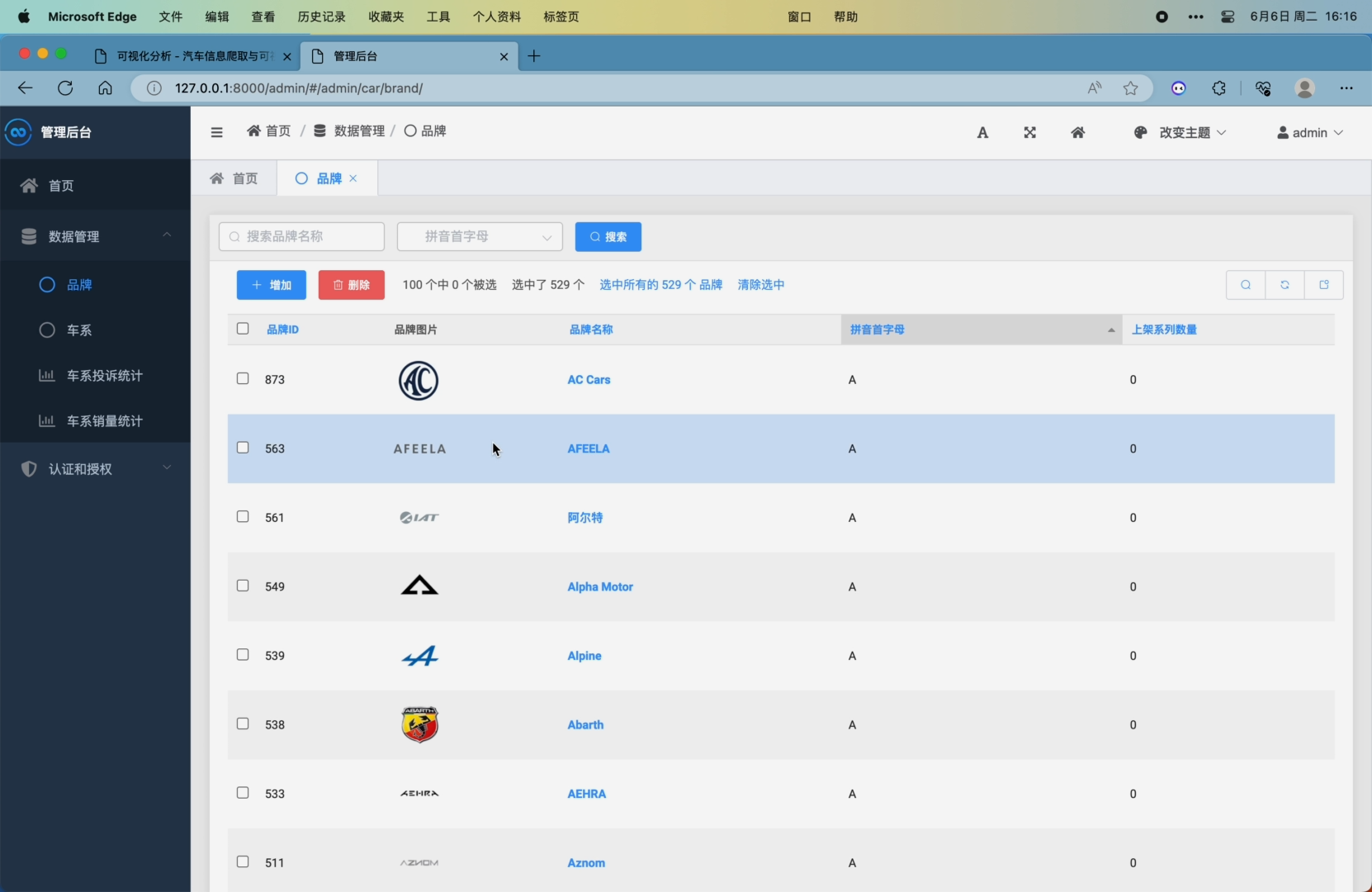
7. 可在后台增删改查管理所有数据
8. 用户登陆注册
核心算法代码分享如下:
import requests
import parsel
import xlwt
import time
import csv
import pandas as pd
import numpy as np
#f = open("医院2.0.csv", "a", encoding='utf_8_sig',newline="")
name = ['医院名称','医院性质','医院等级','联系电话','联系地址','特色专科','日门诊量','床位数量','主要设备','医院网址','电子邮件','交通指南']
url = "https://www.yaofangwang.com/yiyuan/r0/"
cookie = "SECKEY_ABVK=mJFLIkqf/i6U7ccnrJ4ta/0319KCr4mqxKOoDBgVIHU%3D; BMAP_SECKEY=mJFLIkqf_i6U7ccnrJ4ta6dBg-5T_SmB5h8i6DcBazRIPU2aXXvKt45uwRiFk_pc_j4DDAVrcKgiQYnH1G92pW379t0gLZEV53zXzYf3b5lEQeAOn1yGHuCqvukFlecCVf7HP5KXQyU9QjmNcrwyrkw_nU7Ey5jiviZscbfu1yWtZdtkfiWpzh6KYVaBBmqF; HMF_CI=cb40c3bac11b81cc93aa05156b1a5b38bbf2cd9e29ad799c1db9abe90d6d58ac50; Hm_lvt_e5f454eb1aa8e839f8845470af4667eb=1655723303,1655789225; isContact=0; historysearch=%E4%B8%9C%E9%98%BF%E9%98%BF%E8%83%B6__%E4%BB%81%E5%92%8C__%E8%83%83%E8%8D%AF__; real_ip=183.190.120.157; hotkeywords=%E9%98%BF%E8%83%B6%23%231%23%231%23%2311442%40%40%E5%AE%89%E5%AE%AB%E7%89%9B%E9%BB%84%E4%B8%B8%23%230%23%231%23%2310799%40%40%E9%BE%9F%E9%BE%84%E9%9B%86%23%230%23%231%23%2325686%40%40%E6%8B%9C%E6%96%B0%E5%90%8C%23%230%23%231%23%2310189%40%40%E6%8B%9C%E5%94%90%E8%8B%B9%23%230%23%231%23%2314441; Hm_lpvt_e5f454eb1aa8e839f8845470af4667eb=1655807803"
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36',
'Cookie':cookie
}
i=0 #行
l=0 # 列
title = {
"医院名称":0,
"医院性质":1,
"医院等级":2,
"联系电话":3,
"联系地址":4,
"特色专科":5,
"日门诊量":6,
"床位数量":7,
"主要设备":8,
"医院网址":9,
"电子邮件":10,
"交通指南":11
}
# 957
#n=957
#m=1
#n=20
m=600
n=700
for page in range(m,n+1):
page = str(page)
res = requests.get(url=url, headers=headers)
res.encoding = res.apparent_encoding
se = parsel.Selector(res.text)
url04 = "https://www.yaofangwang.com/yiyuan/r0/p" + page + "/"
ye = requests.get(url=url04, headers=headers)
ye.encoding = ye.apparent_encoding
ye_se = parsel.Selector(ye.text)
tt = ye_se.xpath('//li[@class="clearfix"]')
for txt in tt.extract():
# time.sleep(3)
se02 = parsel.Selector(txt)
row=[]
# 医院名称
name = se02.xpath('//div[@class="info"]/strong/a/text()').extract()[0]
row.append(name)
sid = se02.xpath('//div[@class="info"]/strong/a/@href').extract()[0][8:14]
url03 = "https://www.yaofangwang.com/yiyuan/" + sid + ".html"
xq = requests.get(url=url03, headers=headers)
xq.encoding = xq.apparent_encoding
xq_se = parsel.Selector(xq.text)
# 医院等级 联系电话 联系地址 特色专科
canshu = xq_se.xpath('//div[@class="info"]/p')
data = canshu.xpath('string(.)').extract()[0:5]
for dat in data:
dat_list = dat.split(":")
if dat_list[0] in title:
l = title[dat_list[0]]
val = dat_list[1]
val = val.replace(",", '')
val = val.replace("'", '')
val = val.replace('"', '')
val = val.replace("\n", '')
val = val.replace("\r", '')
val=val.strip()
row.append(val)
# 日门诊量
menzhen = canshu.xpath('string(.)').extract()[5]
menzhen1 = menzhen.split(" ")
menzhen2 = menzhen1[0]
menzhen3 = menzhen2.split(":")
val = menzhen3[1]
row.append(val)
# 床位数量
cw = menzhen1[1]
cw1 = cw.split(":")
val = cw1[1]
row.append(val)
# 主要设备
txxt = xq_se.xpath('//div[@class="tbock"]/div[@class="txt"]')
shebei1 = txxt.xpath('string(.)').extract()[1]
shebei2 = shebei1.replace(" ", "")[1:-1]
shebei2 = shebei2.strip()
row.append(shebei2)
# 医院网址 电子邮件 交通指南
data2 = txxt.xpath('string(.)').extract()[2]
data2 = data2.replace(" ", "")[1:-1]
datas2 = data2.split('\n')
for dat in datas2:
dat_list = dat.split(":")
if dat_list[0] in title:
l = title[dat_list[0]]
val = dat_list[1]
val = val.replace("'", '')
val = val.replace(",", '')
val = val.replace('"', '')
val = val.replace("\n", '')
val = val.replace("\r", '')
val = val.strip()
row.append(val)
print(row)
with open('data.csv', mode='a', newline='', encoding='utf-8') as data_file:
data_writer = csv.writer(data_file)
# 写入CSV文件
data_writer.writerow(row)
data_file.close()
with open('specialized_in.csv', mode='a', newline='', encoding='utf-8') as ss_file:
ss_writer = csv.writer(ss_file)
# 写入CSV文件
ss=row[5].split("、")
for i in ss:
print(i)
ss_writer.writerow([i])
ss_file.close()
with open('equipment.csv', mode='a', newline='', encoding='utf-8') as es_file:
es_writer = csv.writer(es_file)
# 写入CSV文件
es=row[8].split("、")
for i in es:
print(i)
es_writer.writerow([i])
es_file.close()
print('第'+page+"页爬取完成!")
#f.close()
print('爬取成功!')


















 1830
1830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











