




 本文描述了一项毕业设计项目,涉及天猫历史订单数据的爬取、清洗、存储、数据分析(包括情感分析和预测)、可视化以及系统设计,使用了DrissionPage、Pandas、Spark等IT技术,旨在探索电商数据的价值和潜在应用。
本文描述了一项毕业设计项目,涉及天猫历史订单数据的爬取、清洗、存储、数据分析(包括情感分析和预测)、可视化以及系统设计,使用了DrissionPage、Pandas、Spark等IT技术,旨在探索电商数据的价值和潜在应用。
一、毕业设计的内容
1.DrissionPage自动化爬虫框架采集天猫历史开源订单数据约1万亿条存入mysql数据库、.csv文件作为数据集(或使用开源数据集10TB大小);
2.使用pandas+numpy或MapReduce对数据进行数据清洗,生成最终的.csv文件并上传到hdfs(含nlp情感分析);
3.使用hive数仓技术建表建库,导入.csv数据集;
4.离线分析采用hive_sql完成,实时分析利用Spark之Scala完成;
5.统计指标使用sqoop导入mysql数据库;
6.使用flask+echarts进行可视化大屏开发;
7.使用CNN、KNN卷积神经网络、TensorFlow、PyTorch、线性回归算法进行订单量预测;
二、毕业设计的要求
- 选题背景和目标:明确介绍电商数据挖掘的重要性和应用背景,明确设计与实现电商数据挖掘系统的目标和意义。
- 文献综述:对于电商数据挖掘和Spark等相关技术进行较为全面的文献综述,介绍已有研究和方法。
- 系统设计:详细描述电商数据挖掘系统的整体架构、技术选型、功能模块划分等,包括数据采集、数据清洗、特征提取、模型训练和结果可视化等方面。
- 数据集与预处理:明确选择的电商数据集,并对数据进行适当的预处理,如去除异常值、处理缺失数据等。
- 算法和模型:选择合适的数据挖掘算法和模型,如关联规则挖掘、分类算法、聚类分析等,并详细描述其原理和实现过程。
- 实验与评估:设计实验方案,使用选定的数据集和算法进行实验,对系统进行性能评估和结果分析,包括准确性、效率等指标。
- 结果展示与分析:将挖掘到的电商数据结果进行可视化展示,通过图表、报表等形式呈现分析结果,并对结果进行解读和讨论。
- 总结与展望:总结毕业设计的工作和成果,提出对系统的改进和未来研究方向的展望。
三、毕业设计进程安排(表格栏数请依情况自定,宋体五号,时间安排要与毕业设计起止时间的保持一致)
|
序 号 |
阶段任务 |
日 期 |
|
1 |
需求分析和系统设计 |
2024-1-30到2024-2-10 |
|
2 |
电商订单数据准备和预处理 |
2024-2-10到2024-2-28 |
|
3 |
算法和模型选择 |
2024-3-1到2024-3-15 |
|
4 |
系统实现和测试 |
2024-3-16到2024-3-30 |
|
5 |
性能评估和结果分析 |
2024-4-1到2024-4-15 |
|
6 |
结果展示和总结 |
2024-4-15到2024-5-1 |
四、文献查询方向及范围
[1]田啸.大数据环境下计算机应用技术研究[J.]电脑知识与技术2022(14):246-247.
[2]侯聪聪.计算机软件技术在大数据时代的应用[J].电脑知识与技术2023(14):240-241.北京:清华大学出版社,2016.335-340
[3]于知言.计算机应用技术在大数据时代的运用前景研究[J].知识文库2021(15):107.
[4]李超科.计算机大数据分析及云计算网络技术发展探究[J].计算机产品与流通2020(11):12
[5]吴晓玲,邱珍珍.基于云存储架构的分布式大数据安全容错存储算法[J].中国电子科学研究院学报2022,13(6):720-724.
[6]张若愚.Python 科学计算[M].北京:清华大学出版社.2022
[7]RobertCimman,Eduart Rohan-Multiscale finite element calculations in Python using SfePy.-2022.vol.45
[8]Linwei He,Matthew Gibert-A Python script for adaptive layout optimization of trusses. -2022.vol.69
[9]Elservierjournal-Python programming on win64.-2022.6.2
[10]王磊. 对Mysql数据库的访问方法的研究[J]. 网络安全技术与应用,2021,(04):138-139.
[11]丛宏斌,魏秀菊,王柳,朱明,曾勰婷,刘丽英. 利用PYTHON解析网络上传数据[J]. 中国科技期刊研究,2023,24(04):736-739.
[12]卫启哲. 试论动态开发语言Python研究[J]. 电脑编程技巧与维护,2022,(14):23-24.
[13]陈威,韦佳,张洁. 海量地震数据移动存储设备的现状分析[J]. 物探装备,2023,23(05):291-293+299.
[14]许沫. 生活模块仪表详细设计浅析[J]. 内蒙古石油化工,2021,39(14):79-80.
[15]范晶. 模拟上行系统测试平台介绍[J]. 中国新技术新产品,2021,(01):31-32.
毕业设计起止时间: 202 年 月 日—— 202 年 月 日
指导教师(签字)
系 主 任(签字)
202 年 月 日
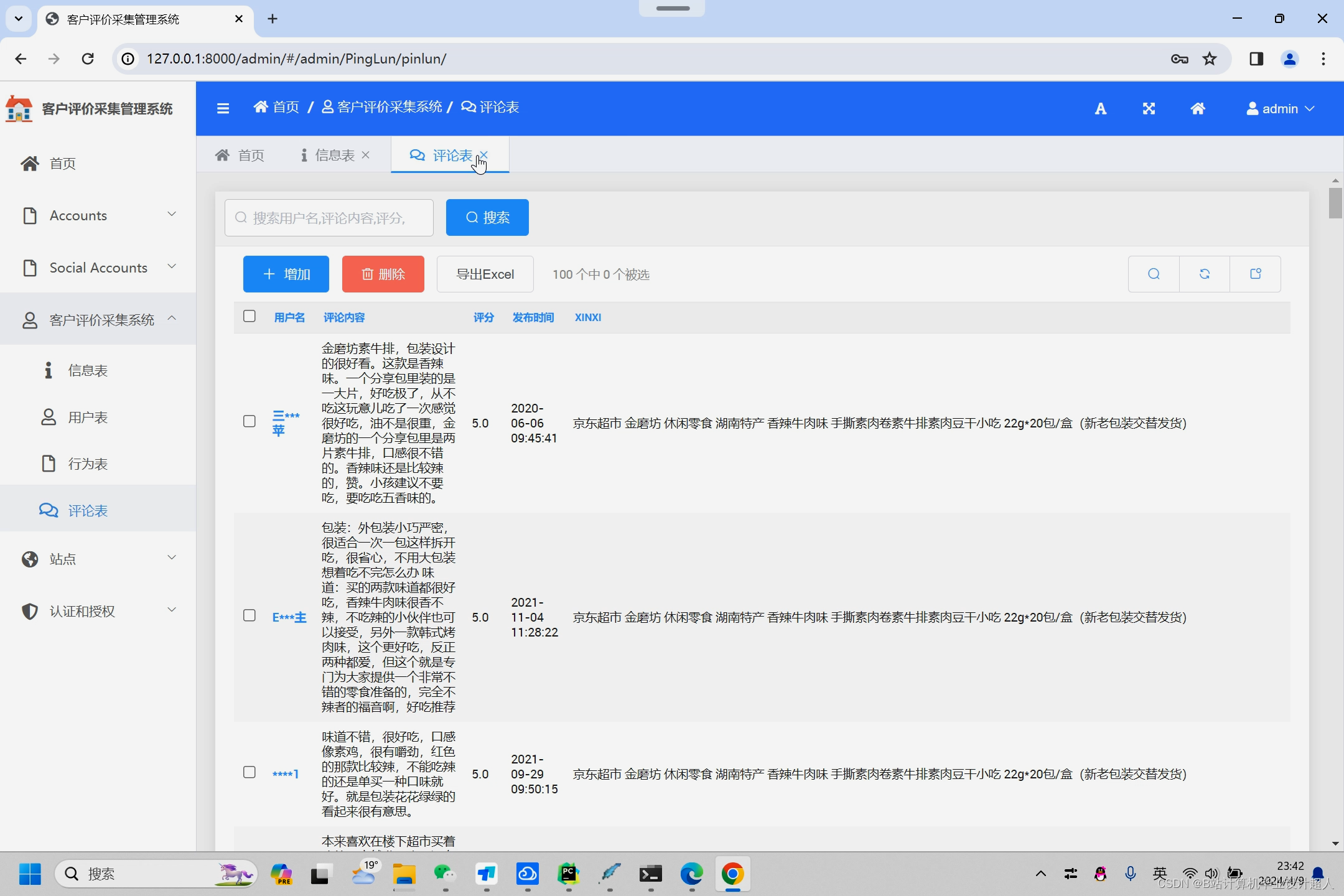
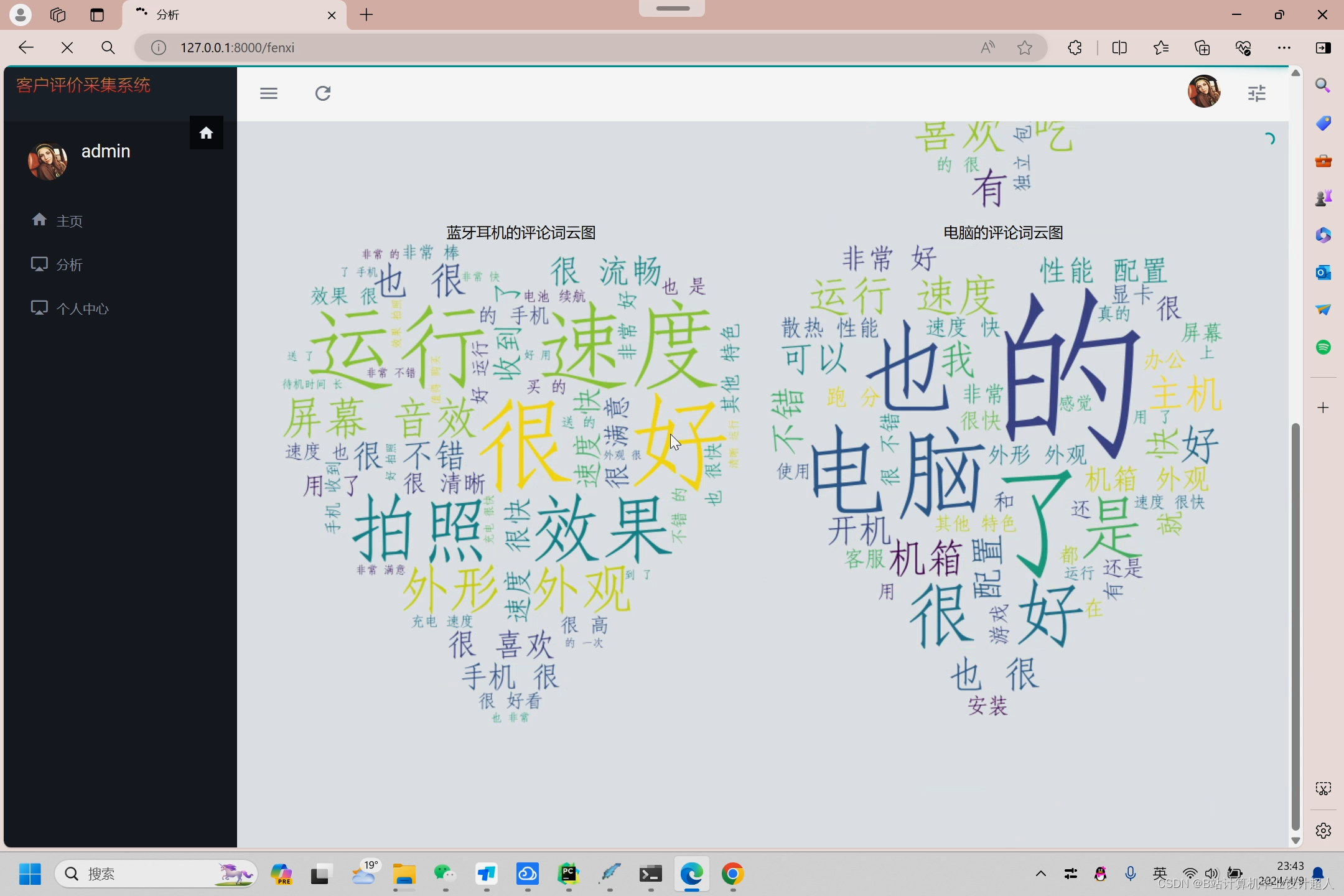
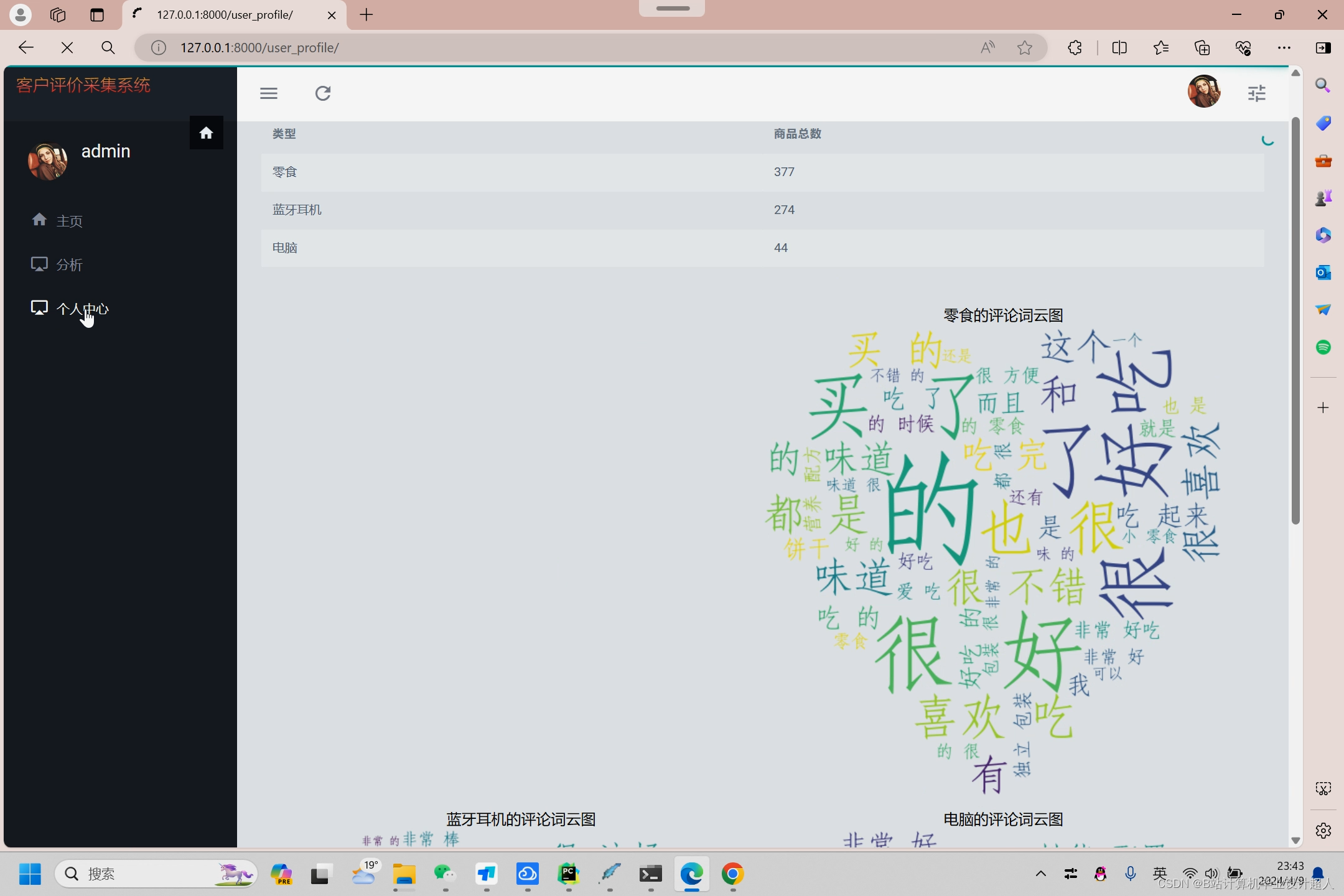
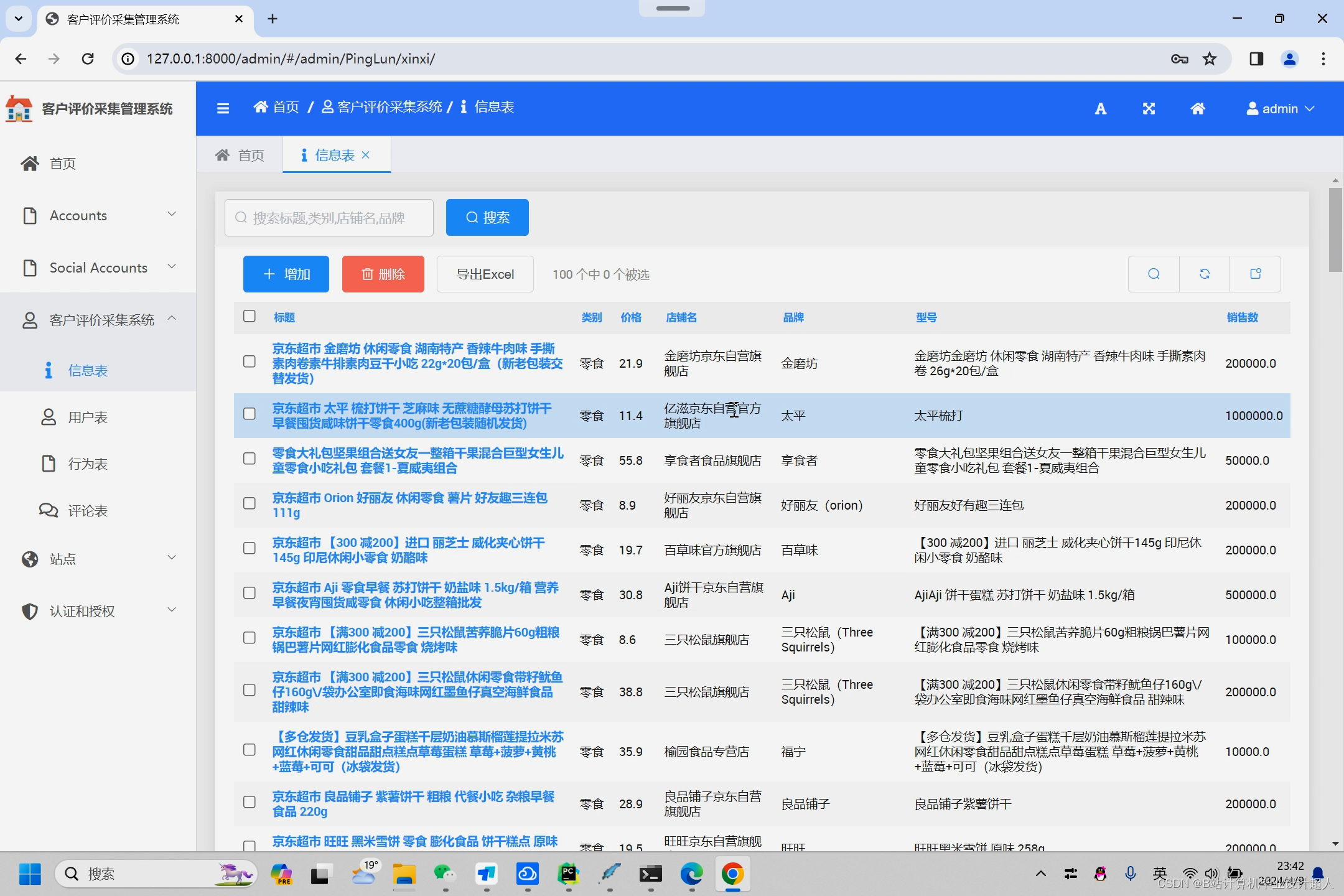
核心算法代码分享如下:
import pandas
from web.app import models
import traceback
from sqlalchemy import or_, and_
df = pandas.read_csv('./result.csv')
# def fun1(value):
# try:
# value = str(value).replace(' ','')
# return float(value)
# except:
# return 99.99
#
# df['价格'] = df['价格'].apply(fun1)
df.dropna(axis=0,inplace=True)
for i in range(df.shape[0]):
data = df[i:i + 1]
print(data)
try:
if not models.Case_item.query.filter(and_(models.Case_item.name == data['标题'].get(int(data.index.values[0])), models.Case_item.url == data['链接'].get(int(data.index.values[0]) ))).all():
models.db.session.add(
models.Case_item(
name = data['标题'].get(int(data.index.values[0])),
shopname = data['店铺名称'].get(int(data.index.values[0])),
price = data['价格'].get(int(data.index.values[0])),
url = data['链接'].get(int(data.index.values[0])),
pinbai = data['品牌'].get(int(data.index.values[0])),
xinghao = data['型号'].get(int(data.index.values[0])),
haoping = data['好评数'].get(int(data.index.values[0])),
chaping = data['差评数'].get(int(data.index.values[0])),
count = data['销售总数'].get(int(data.index.values[0])),
type1=data['类型1'].get(int(data.index.values[0])),
type2=data['类型2'].get(int(data.index.values[0])),
)
)
models.db.session.commit()
except:
print(traceback.format_exc())


















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











