




|
学生姓名 |
专业 |
学号 | |||
|
设计题目 |
基于大数据技术的头条推荐系统的设计与实现 | ||||
1.选题背景及意义 在信息时代,人们每天都面临着庞大的信息流,如何高效、个性化地推送信息成为互联网平台的重要任务。推荐系统作为一种解决方案,通过利用大数据技术对用户行为进行深入分析,为用户提供个性化的头条新闻推荐,成为提高用户体验的有效途径。本项目旨在设计并实现一个基于大数据技术的头条推荐系统。通过此系统的设计与实现,我们旨在提高信息推送的准确性和用户满意度,为互联网新闻平台的发展提供有力支持。
(1)数据采集与处理 通过抓取、清洗、整合多种数据源,包括但不限于用户浏览历史、点击记录、社交网络信息等,建立完整的用户行为数据集。 (2)用户画像构建 基于采集到的数据,运用大数据分析技术,构建用户画像,深入挖掘用户的兴趣、偏好,为后续推荐算法提供有力支持。 (3)推荐算法设计与实现 设计并实现一套高效的推荐算法,结合用户画像和实时行为,为用户推荐个性化、感兴趣的头条新闻。 (4)系统架构设计 基于大数据处理框架,搭建推荐系统的整体架构,实现数据的实时处理、存储和分析,确保系统的高性能和可扩展性。 (5)用户反馈与优化 设计用户反馈机制,通过用户行为反馈和用户满意度调查等手段,不断优化推荐算法,提高系统的精准度和用户满意度。 3.研究方法 (1)数据采集与处理 设计数据采集方案,包括数据源的选择、数据获取、数据清洗等步骤。 (2)用户画像构建 利用大数据分析技术,深入挖掘用户行为数据,构建用户画像的方法和模型。 (3)推荐算法设计与实现 选择并实现适用于头条推荐系统的推荐算法,如协同过滤、深度学习等。 (4)系统架构设计 搭建基于大数据技术的系统架构,确保系统能够高效处理实时数据。 4.研究计划 (1)需求分析:明确系统的功能和性能需求,为后续的设计和实现奠定基础。 (2)系统设计:根据需求设计系统的架构和模块,包括数据收集、数据处理和用户界面等模块。 (3)系统实现:使用Hadoop和相关模块实现系统的各个功能模块,并进行测试和调试。 (4)性能评估:通过实验测试和数据分析,评估头条推荐系统的性能,并根据评估结果进行优化和改进。 5.预期研究成果 通过本研究,预计将实现一个基于大数据技术的头条推荐系统,并达到以下成果: (1)实现了可靠的数据采集和处理功能; (2)开发了直观、用户友好的可视化界面; (3)提供了基本的数据分析和报告生成功能。 6.主要参考文献 [1] 徐凡婷.《今日头条》算法机制的风险与治理研究[J].上海师范大学,2022. [2] 宋佳琳.聚合类新闻客户端个性化推荐研究——以今日头条为例[J].成都理工大学,2021. [3] 石德馨.智媒时代新闻个性化推荐的把关机制研究[J].长春工业大学,2021. [4] Wang Yi. An Analysis of the Information Cocoon Effect of News Clients: Today’s Headlines as an Example,2023. [5] 杨睿婷.聚合型新闻APP个性化推荐机制研究——以今日头条APP为例[J].山西大学,2020. [6] 钱婉玲.算法推荐媒体的用户与内容关系研究——以《趣头条》为例[J].上海师范大学,2020. [7] 刘波.今日头条推荐系统背后的技术原理[J].信息安全研究,2019. [8] 王思佳.“今日头条”客户端存在的问题与优化策略[J].传媒与艺术研究,2019. [9] 张莉莉.聚合类新闻客户端个性化推荐内容研究[J].渤海大学,2019. [10] Kuai Joanne,Lin Bibo,Karlsson Michael,Lewis Seth C.From Wild East to Forbidden City: Mapping Algorithmic News Distribution in China through a Case Study of Jinri Toutiao[J].Digital Journalism,2023 二、指导教师意见 xxx同学撰写的开题报告内容较为详实,论证合理,分析较为深入,对相关研究有一定的了解,设计方案可行,同意开题。 指导教师签名: 2023 年 12 月 19 日 | |||||
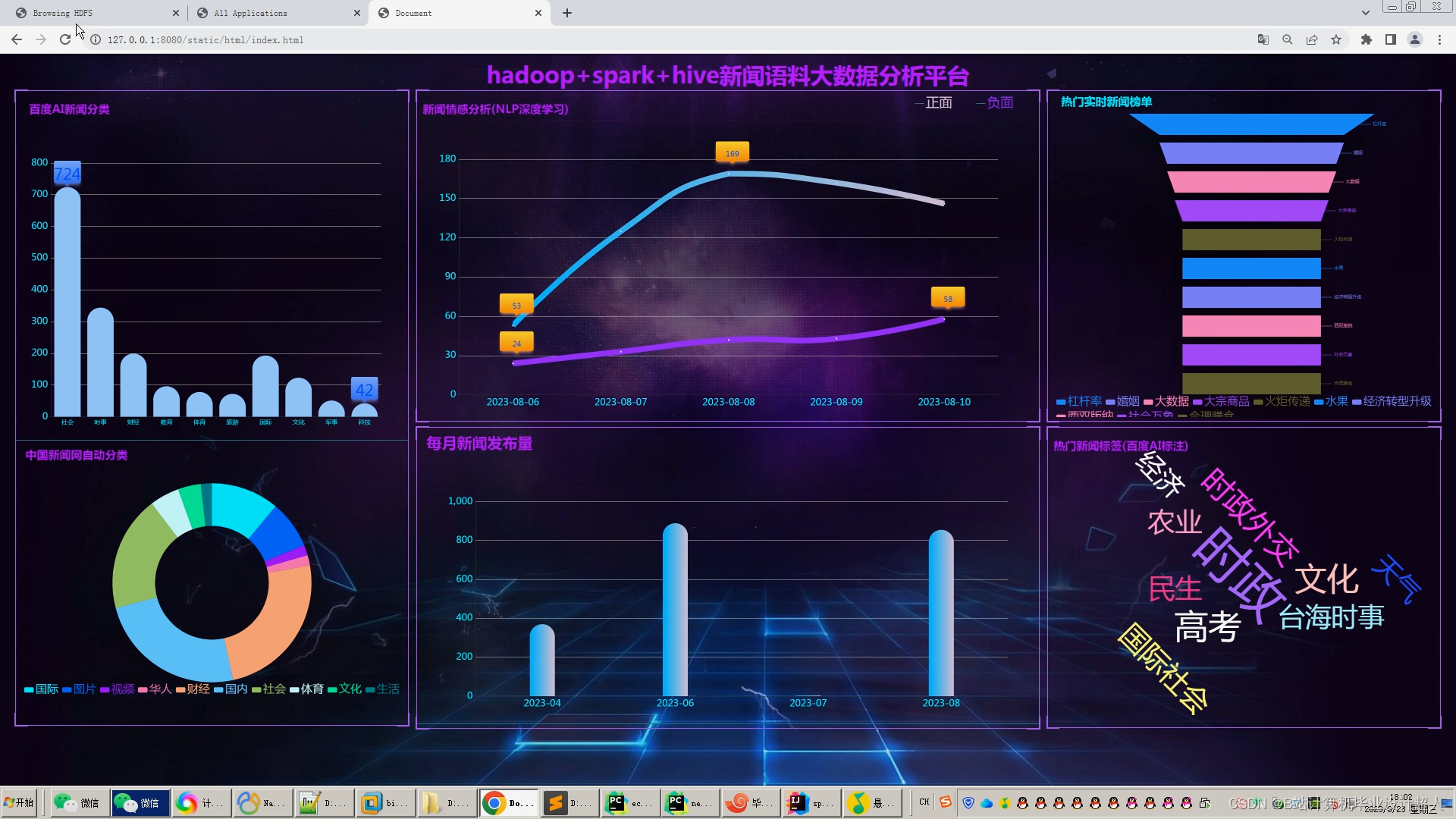

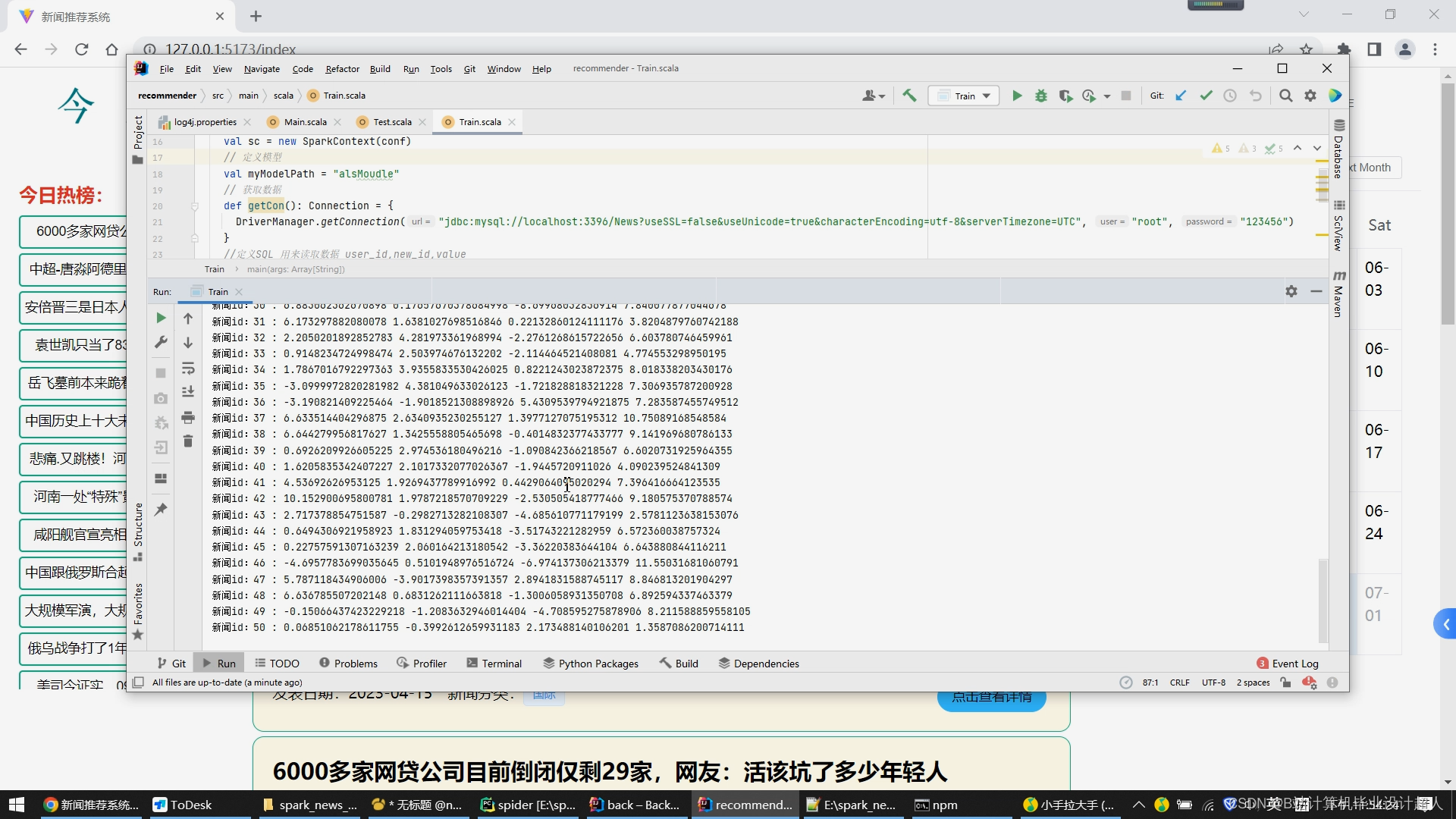

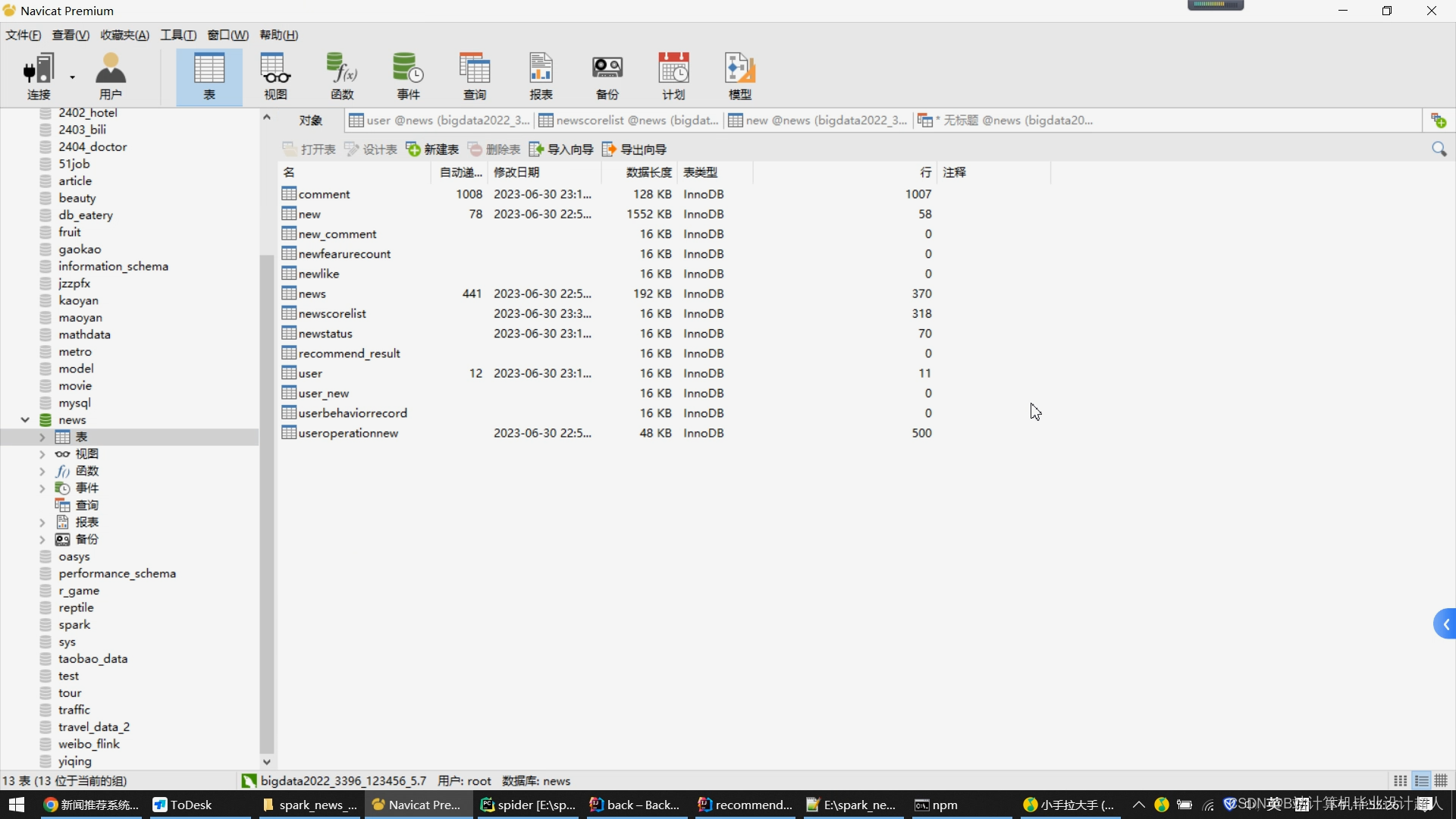

核心算法代码分享如下:
#使用PySpark完成部分机票指标分析
from pyspark.sql.types import StringType, StructField, IntegerType, DoubleType, StructType
from pyspark.sql.functions import col
from pyspark.sql import SparkSession
csv_format = 'com.databricks.spark.csv'
mysql_url = "jdbc:mysql://bigdata:3306/Flink_Fliggy_Flight"
prop = {'user': 'root', 'password': '123456', 'driver': "com.mysql.jdbc.Driver"}
# 1.创建SparkSession
spark = SparkSession.builder.appName("tables02_task").getOrCreate()
fields = [
StructField("start_city", StringType(), True),
StructField("end_city", StringType(), True),
StructField("stime", StringType(), True),
StructField("airline_name", StringType(), True),
StructField("flight_info", StringType(), True),
StructField("flight_type1", StringType(), True),
StructField("flight_type2", StringType(), True),
StructField("setup_time", StringType(), True),
StructField("arr_time", StringType(), True),
StructField("start_airport", StringType(), True),
StructField("arr_airport", StringType(), True),
StructField("ontime_rate", IntegerType(), True),
StructField("flight_total_time", StringType(), True),
StructField("price", IntegerType(), True),
StructField("price_desc", StringType(), True),
StructField("flight_company", StringType(), True),
StructField("flight_type3", StringType(), True),
StructField("setup_time_math", DoubleType(), True),
StructField("arr_time_math", DoubleType(), True),
StructField("arr_time2", StringType(), True),
StructField("start_airport_simple", StringType(), True),
StructField("arr_airport_simple", StringType(), True),
StructField("flight_total_time_math", IntegerType(), True),
StructField("price_desc_math", DoubleType(), True),
]
schema= StructType(fields)
# 2.读取本地文件路径
# flights_data = spark.read.format(csv_format).options( ending='utf-8').load(
# "hdfs://bigdata:9000/flink_fliggy_flight/flight/hdfs_flights.csv")
flights_data=spark.read.option("header", "false").schema(schema).csv("hdfs://bigdata:9000/flink_fliggy_flight/flight/hdfs_flights.csv")
# 3.创建临时表
flights_data.createOrReplaceTempView("ods_flight")
# 4.工作经验与薪水的关系
tables02_sql='''
select start_airport_simple,count(1) num
from ods_flight
group by start_airport_simple
order by num desc
limit 10
'''
spark.sql(tables02_sql).write.jdbc(mysql_url, 'tables02', 'overwrite', prop)


















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











