




 本文描述了一个毕业设计项目,通过爬虫抓取网易云音乐数据作为基础,构建了一个离线推荐系统,使用Python和机器学习(如协同过滤和皮尔逊相似度)进行个性化推荐。系统还包含了SpringBoot的在线应用和Vue.js界面,以及Spark的大屏统计功能。整个项目遵循软件工程流程,包括需求分析、设计、开发和测试。
本文描述了一个毕业设计项目,通过爬虫抓取网易云音乐数据作为基础,构建了一个离线推荐系统,使用Python和机器学习(如协同过滤和皮尔逊相似度)进行个性化推荐。系统还包含了SpringBoot的在线应用和Vue.js界面,以及Spark的大屏统计功能。整个项目遵循软件工程流程,包括需求分析、设计、开发和测试。
|
任务书:
第一部分:爬虫爬取音乐数据(网易云音乐网站),作为测试的数据集; 第二部分:离线推荐系统:python+机器学习离线推荐(基于物品的协同过滤算法,相似度衡量方法:皮尔逊相似度) ,必要时可以集成算法框架比如tensflow pytroch等,推荐结果通过pymysql写入mysql; 第三部分:在线应用系统: springboot进行在线推荐 vue.js构建推荐页面; 第四部分:使用Spark构建大屏统计;
毕业设计和论文要按照软件工程过程,包括系统分析与设计、系统实现及系统测试的过程来完成,符合软件工程要求。论文应并配有中英文摘要,绪论和结论, 配有英译汉文章,正文达到一万字以上。格式符合沈阳工学院毕业设计(论文)管理规定要求。
第 1-2 周:搜集查阅资料,对项目进行调研,完成开题报告。 第 3-4 周:进行系统需求分析、功能设计、开发环境准备和论文部分初稿内容撰写。 第 5 周:进行数据库设计、界面设计以及论文初稿内容的撰写。 第 6-11 周:进行系统管理员模块、教师模块以及学生模块的代码编写和论文初稿内容的撰写。 第 12-13 周:进行系统测试,撰写此部分论文初稿。 第 14-15 周:修改与完善论文,参加答辩。 |










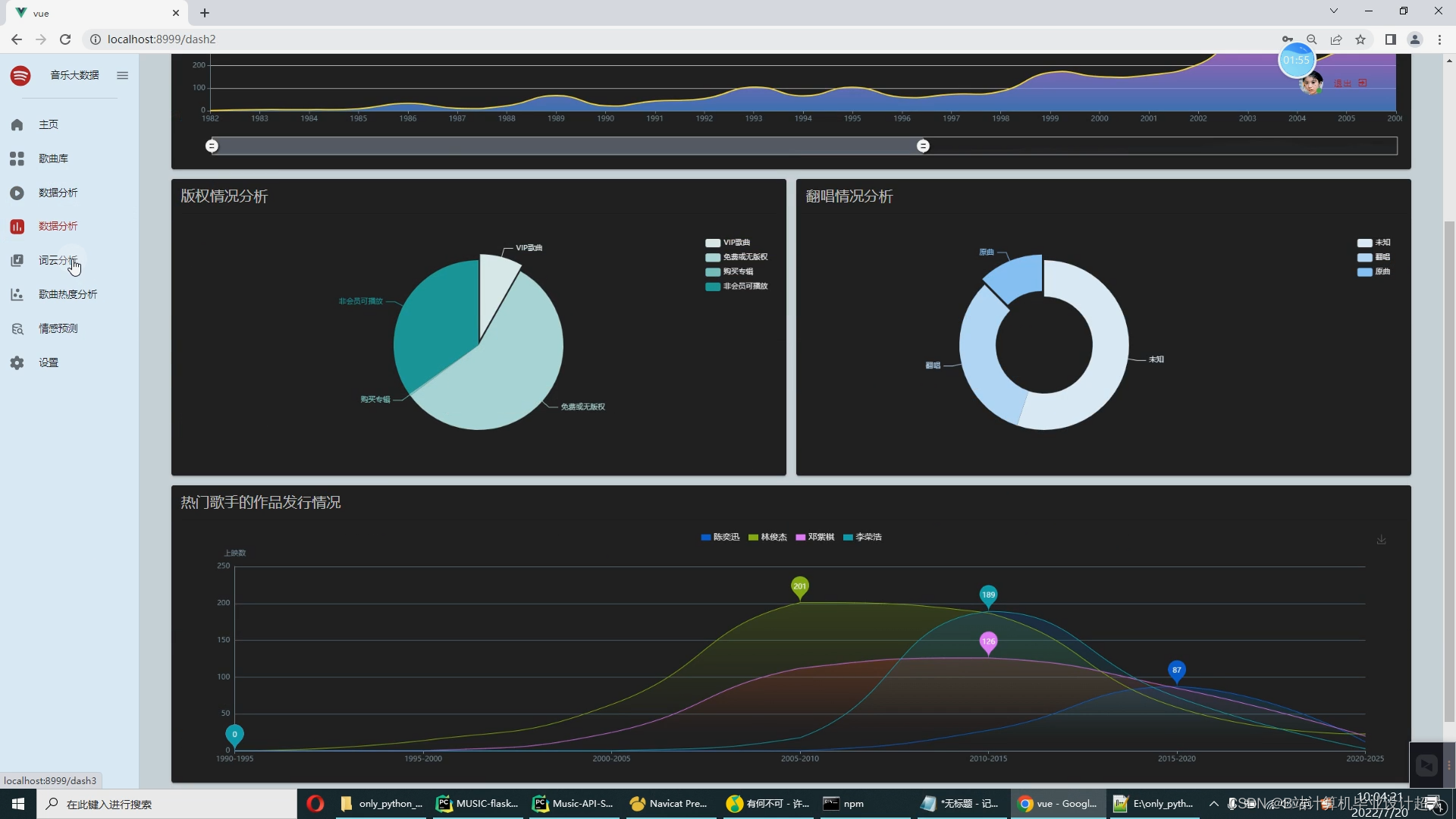
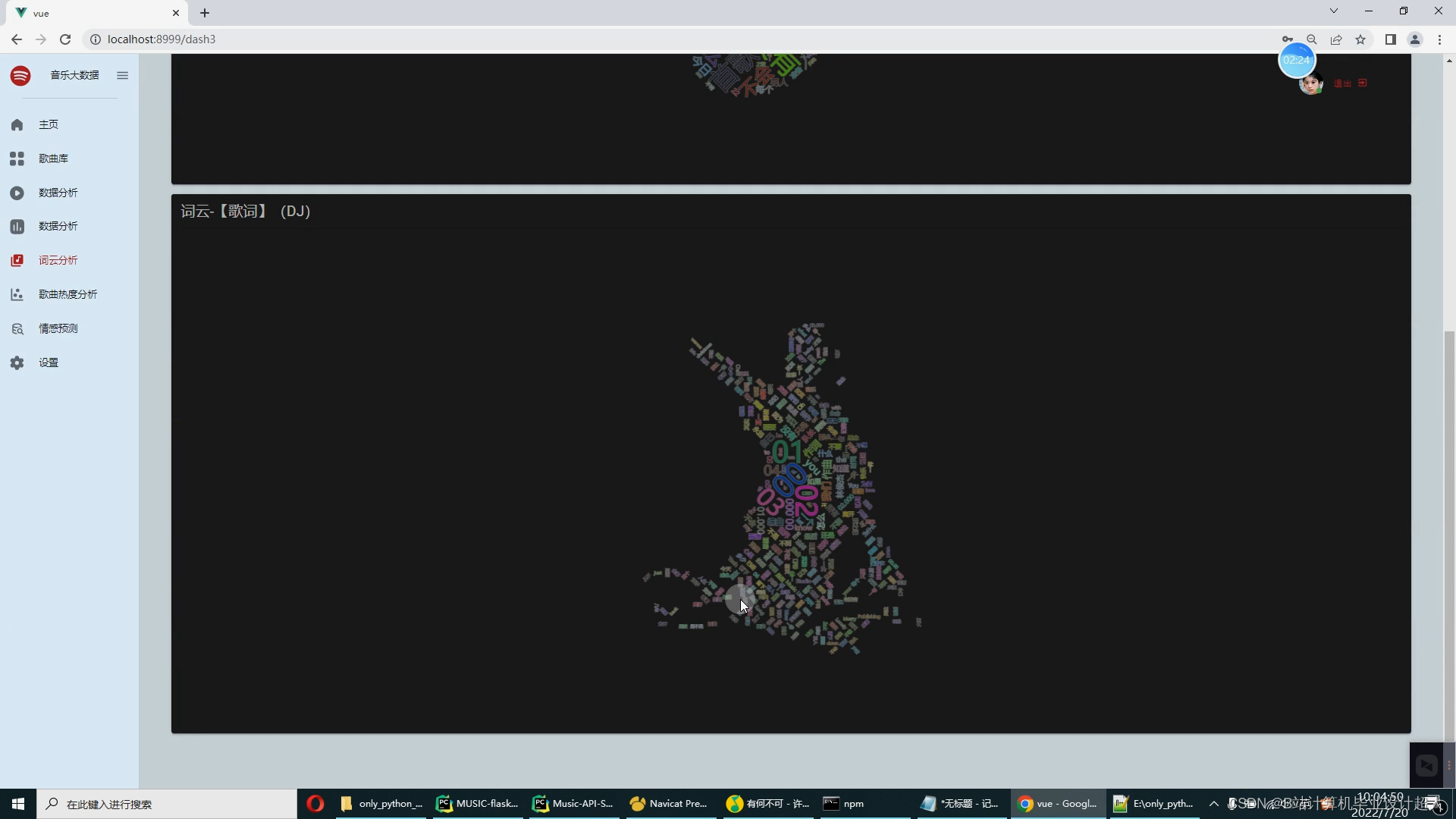
核心算法代码分享如下:
from flask import Flask, request
import json
from flask_mysqldb import MySQL
# 创建应用对象
app = Flask(__name__)
app.config['MYSQL_HOST'] = 'bigdata'
app.config['MYSQL_USER'] = 'root'
app.config['MYSQL_PASSWORD'] = '123456'
app.config['MYSQL_DB'] = 'lvyou'
mysql = MySQL(app) # this is the instantiation
@app.route('/renshu')
def price_datas():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM renshu''')
row_headers = [x[0] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/riqi')
def price_data():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM riqi''')
row_headers = [x[0] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/shengfengeshu')
def mileage_data():
cur = mysql.connection.cursor()
cur.execute('''select * from shengfengeshu''')
row_headers = [x[1] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tianshu')
def spjine_data():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM tianshu''')
row_headers = [x[0] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/wanfa10')
def wg_data():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM wanfa10''')
row_headers = [x[0] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/zuozhe5')
def plzd_data():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM zuozhe5''')
row_headers = [x[1] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route("/shengfengeshu")
def shengfengeshu():
# file_path = "d:\\hadoop_spark_tour2024\\page\\riqi.json"
# with open(file_path, "r", encoding='utf-8') as f:
# data = json.load(f)
# return json.dumps(data, ensure_ascii=False)
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM shengfengeshu''')
#row_headers = [x[1] for x in cur.description] # this will extract row headers
row_headers = ['shengfen','geshu'] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route("/getmapcountryshowdata")
def getmapcountryshowdata():
filepath = r"d:\\hadoop_spark_tour2024\\page\\data\\maps\\china.json"
with open(filepath, "r", encoding='utf-8') as f:
data = json.load(f)
return json.dumps(data, ensure_ascii=False)
@app.route("/nbdata")
def nb_data7():
# file_path = "d:\\hadoop_spark_tour2024\\page\\riqi.json"
# with open(file_path, "r", encoding='utf-8') as f:
# data = json.load(f)
# return json.dumps(data, ensure_ascii=False)
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM riqi''')
#row_headers = [x[1] for x in cur.description] # this will extract row headers
row_headers = ['yue','geshu'] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
if __name__ == "__main__":
app.run(debug=True)


















 2318
2318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











