




 博客分享了核心算法代码,涉及知识图谱、人工智能、大数据等领域,相关技术包括 Hadoop、Spark、Hive 等,还关联推荐算法。
博客分享了核心算法代码,涉及知识图谱、人工智能、大数据等领域,相关技术包括 Hadoop、Spark、Hive 等,还关联推荐算法。
|
研究目的(选题的意义和预期应用价值) 意义 随着旅游业的快速发展,酒店行业的竞争越来越激烈。在如此激烈的市场竞争中,如何提供个性化、精准的酒店推荐服务成为了一个重要的问题。知识图谱是一种以图形化的方式呈现出来的知识库,它能够将不同来源、不同类型的数据融合在一起,并通过自然语言处理、机器学习等技术进行处理,从而提供更加精准、个性化的推荐服务。基于Spark的分布式计算和处理能力,可以处理大规模的数据,提高系统的运行效率,使得推荐系统能够在短时间内给出准确的推荐结果。总之,如下:
预期应用价值
|
|
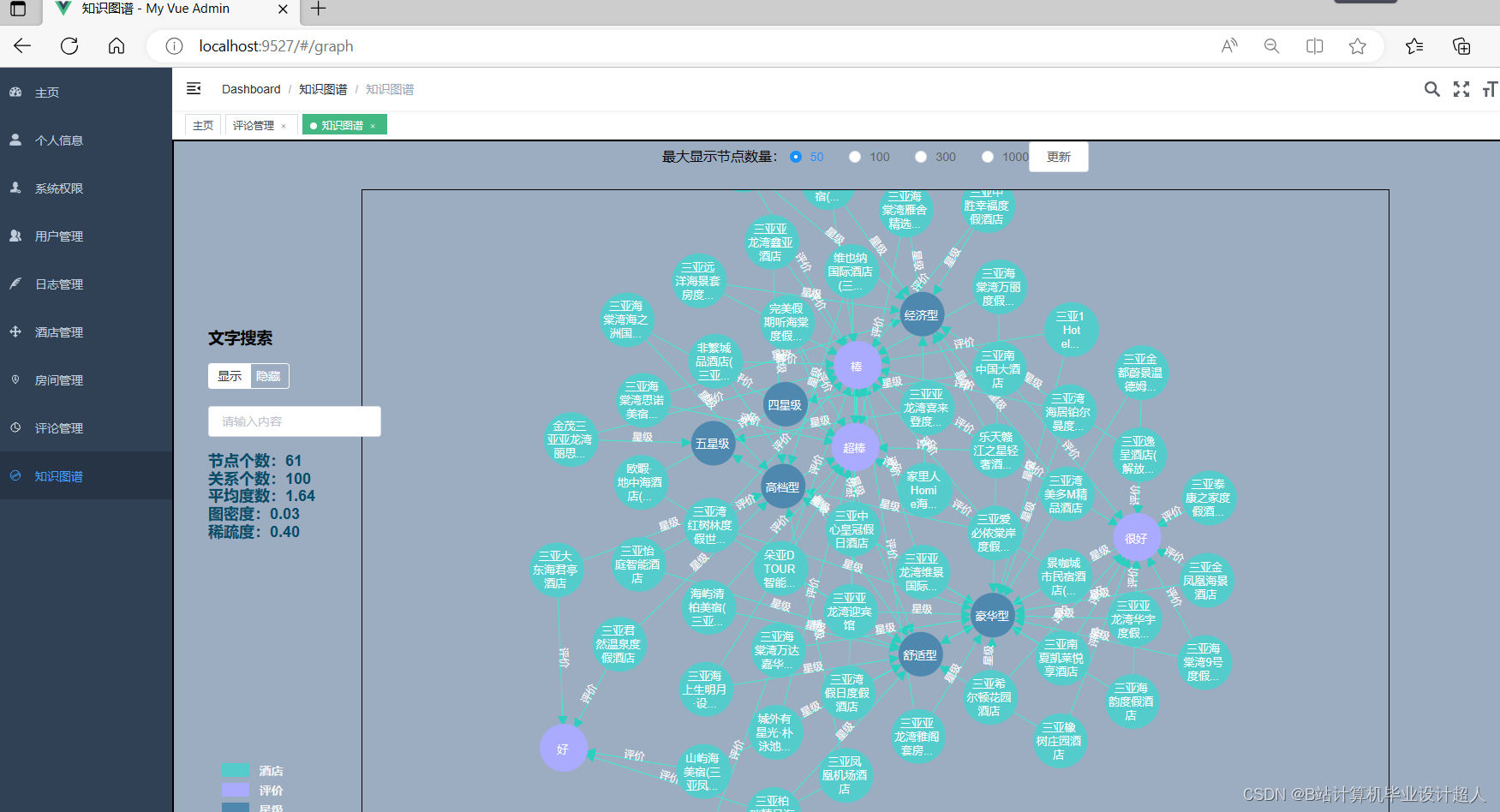
与本课题相关的国内外研究现状(文献综述),预计可能创新的方面 国内外研究现状(文献综述) 研究现状 酒店推荐系统是一种基于用户偏好和需求的语言学习系统,能够为用户提供个性化的酒店推荐服务。近年来,研究者们在酒店推荐系统方面进行了广泛的研究。其中,基于协同过滤的方法和基于内容的方法是最为常见的。 基于协同过滤的方法主要是通过分析用户的历史行为和其他用户的行为,找出与目标用户兴趣相似的其他用户,然后根据这些相似用户的行为推荐酒店。基于内容的方法则是根据用户对酒店的评价和描述,提取出其中的关键词和语义信息,构建一个酒店的内容向量,然后计算目标用户与这些内容向量的相似度,推荐相似度最高的酒店。 然而,传统的推荐方法存在一些不足之处。例如,它们往往只考虑用户历史行为或物品属性,忽略了语义信息。此外,传统的推荐方法难以处理大规模数据,无法实时更新推荐结果。 挑战与不足 酒店推荐系统面临的挑战主要包括如何提高推荐的准确性和个性化程度,如何处理大规模数据,如何提高系统的实时性等。然而,现有的推荐方法在处理这些挑战时存在一些不足。 首先,传统的推荐方法无法有效利用语义信息。现有的推荐方法往往只考虑用户历史行为和酒店属性等较为结构化的数据,忽略了大量的文本评论和描述等语义信息。这些信息对于理解用户需求和酒店特点至关重要。 其次,现有的推荐方法难以处理大规模数据。随着数据的不断增长,传统的推荐方法往往会出现计算速度慢、内存消耗大等问题。此外,传统的推荐方法通常是离线运行的,无法实时更新推荐结果。这使得它们无法及时响应用户需求的变化和酒店信息的更新。 最后,现有推荐方法的个性化程度有限。虽然许多推荐方法声称能够根据用户的偏好和需求提供个性化的服务,但在实际应用中,它们的个性化程度仍显不足。这主要是因为这些方法往往只考虑了用户的历史行为和酒店属性等较为简单的信息,忽略了用户的兴趣爱好、行为习惯等更为深入的信息。 为了解决这些不足,本文提出了一种基于Spark和知识图谱的酒店推荐系统。该系统能够有效利用语义信息、处理大规模数据、提高系统的实时性,并为用户提供更加个性化的服务。 Spark和知识图谱的应用 Spark是一个大规模数据处理框架,具有高效的分布式计算能力,可以处理大规模的数据集。Spark的分布式计算能力可以大大提高酒店推荐系统的处理速度和效率,使其能够处理更多的数据和实现实时的推荐。 知识图谱是一种语义网络技术,能够将各种实体、概念及其之间的关系以图形化的方式呈现出来。在酒店推荐系统中,知识图谱可以用于提取和整合各种酒店和用户信息,提供更加精准的推荐。例如,通过分析酒店的知识图谱,可以获取酒店的类型、设施、价格等信息,从而更加准确地理解用户的需求;通过分析用户的知识图谱,可以了解用户的喜好、行为习惯等信息,从而提供更加个性化的服务。 未来研究方向 尽管本文提出的基于Spark和知识图谱的酒店推荐系统具有一定的创新性和实用性,但仍存在一些不足之处和需要进一步探讨的问题。例如,如何构建更加精准的用户画像、如何更加有效地提取和整合语义信息、如何提高系统的实时性等,将是未来研究的重要方向。 预计可能创新的方面
|
|
研究的主要内容与可行性分析 主要内容
可行性分析 一、技术可行性 基大数据的酒店推荐系统采用了先进的大数据处理技术和自然语言处理技术,可以高效地处理大规模的数据,并能够从文本中提取出丰富的语义信息。 大数据处理技术 Spark是一个大规模数据处理框架,具有高效的分布式计算能力,可以处理大规模的数据集。使用Spark可以大大提高酒店推荐系统的处理速度和效率,使其能够处理更多的数据和实现实时的推荐。 自然语言处理技术 知识图谱是一种语义网络技术,能够将各种实体、概念及其之间的关系以图形化的方式呈现出来。在酒店推荐系统中,知识图谱可以用于提取和整合各种酒店和用户信息,提供更加精准的推荐。例如,通过分析酒店的知识图谱,可以获取酒店的类型、设施、价格等信息,从而更加准确地理解用户的需求;通过分析用户的知识图谱,可以了解用户的喜好、行为习惯等信息,从而提供更加个性化的服务。 二、经济可行性 基大数据的酒店推荐系统采用了先进的大数据处理技术和自然语言处理技术,可以高效地处理大规模的数据,并能够从文本中提取出丰富的语义信息。相比传统的推荐系统,该系统可以减少人工参与和提高效率,从而降低成本。此外,该系统的实施可以帮助酒店提高用户满意度和提升竞争力,从而带来经济效益。 三、政治可行性 基大数据的酒店推荐系统采用了先进的大数据处理技术和自然语言处理技术,可以高效地处理大规模的数据,并能够从文本中提取出丰富的语义信息。推荐系统在政治方面有着重要的应用价值。通过基于用户行为等数据对用户进行推荐,可以有效地引导用户的消费行为和意识形态。这种推荐方式有可能被一些不法分子所利用,从而对国家政治稳定产生负面影响。因此,在设计和实现基大数据的酒店推荐系统的过程中,需要采取一些措施来确保系统的安全性。例如,可以采用数据加密、权限控制等措施来保护用户隐私和系统安全。此外,对于敏感信息的处理,必须严格遵守国家的法律法规和相关政策,以确保该系统的政治可行性。 四、社会可行性 基大数据的酒店推荐系统采用了先进的大数据处理技术和自然语言处理技术,可以高效地处理大规模的数据,并能够从文本中提取出丰富的语义信息。随着旅游业和酒店业的快速发展,用户对酒店推荐服务的需求越来越高。传统的推荐方法已经无法满足用户的需求。基大数据的酒店推荐系统可以根据用户的兴趣爱好、行为习惯等信息进行个性化推荐,从而提升用户体验和服务质量。此外,该系统的实施可以帮助酒店提高用户满意度和提升竞争力,促进旅游业和酒店业的发展。因此,基大数据的酒店推荐系统具有广泛的社会应用价值和社会效益,是可行的。 总之,基大数据的酒店推荐系统具有广泛的应用前景和实用性。采用先进的大数据处理技术和自然语言处理技术使得该系统在技术上可行;能够减少人工参与和提高效率使得该系统在经济上可行;同时政治可行性和社会可行性也得到了充分保障。因此,设计和实现基大数据的酒店推荐系统是可行的,具有重要的理论意义和实践价值。 |
|
本课题研究的主要方法和步骤
|
|
研究进度安排 第1-3周熟悉题目,对的开发流程和使用进行熟悉和分析,完成开题报告、文献综述以及需求分析。 第4-5周完成总体设计,根据系统需要建立数据库。 第6-9周初步完成系统详细设计,实现基本功能。 第10-12周对系统进行细节完善。 第13-16周根据系统设计过程中的记录文挡及其功能编写毕业论文。 |
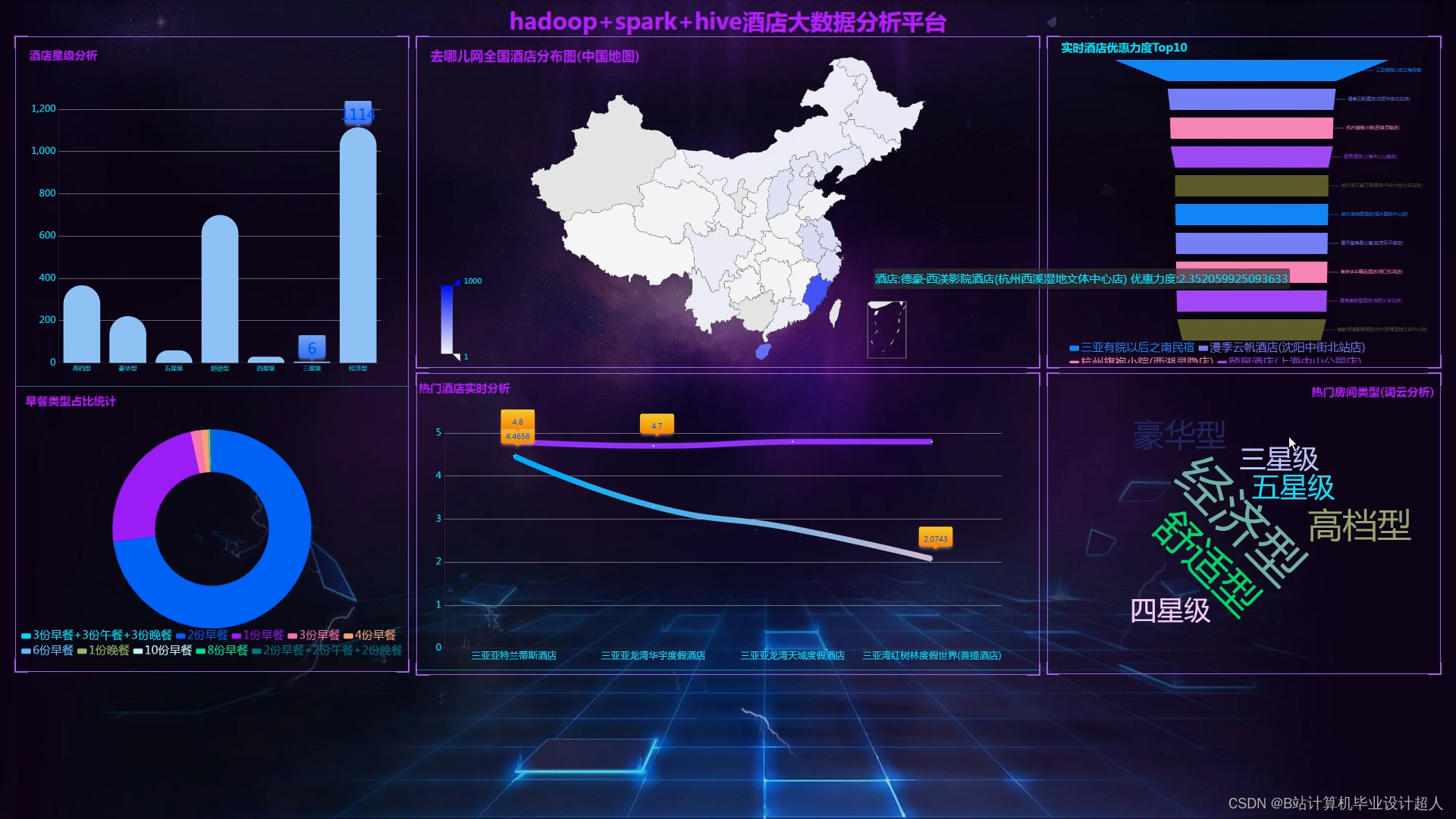
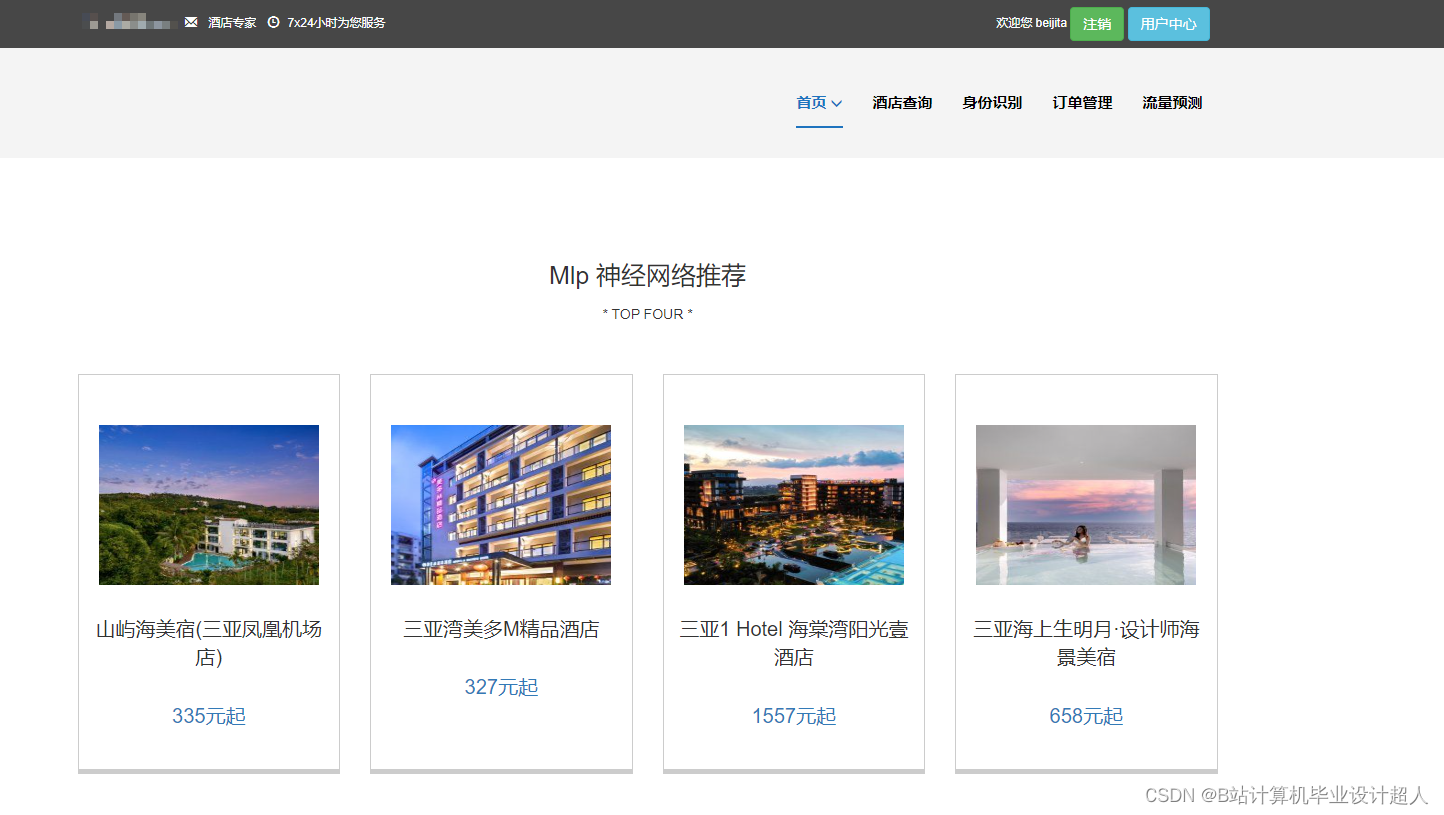
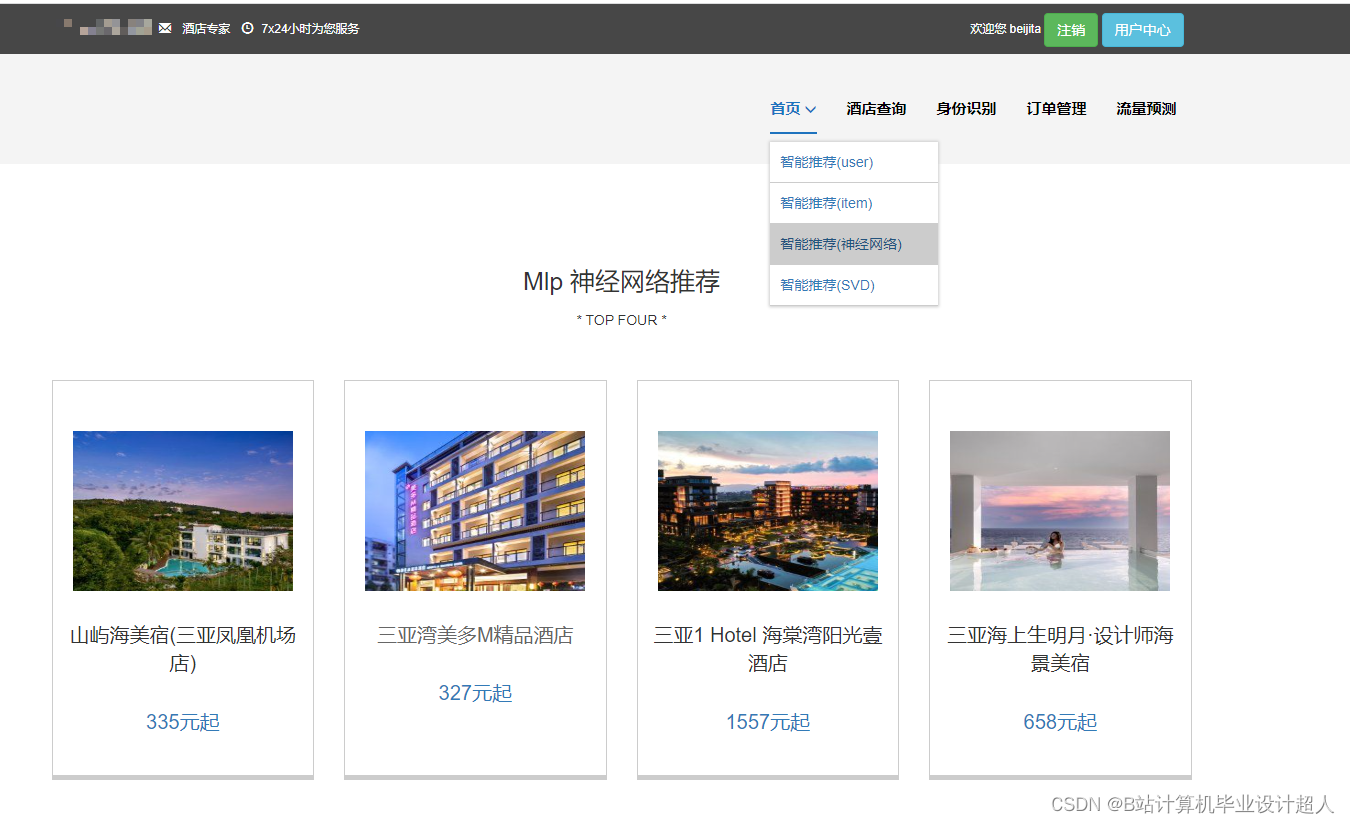
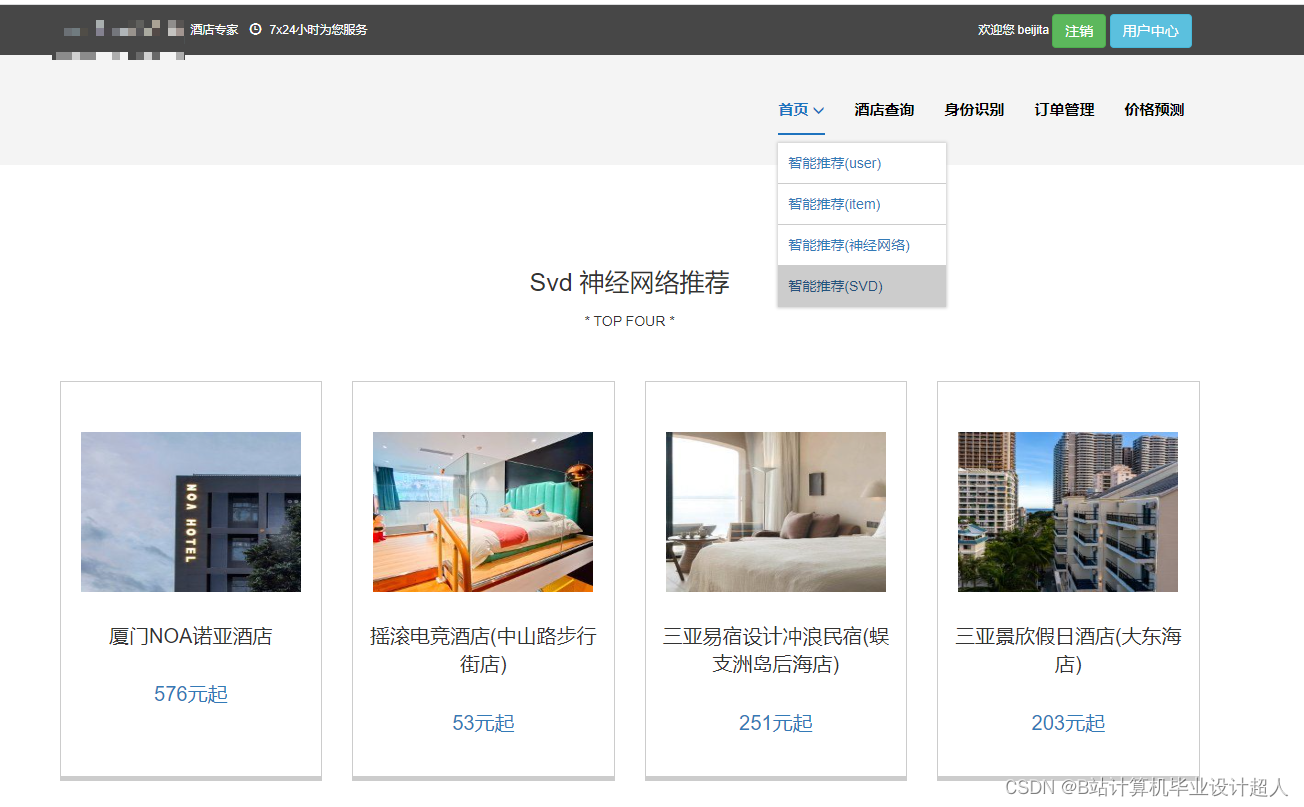
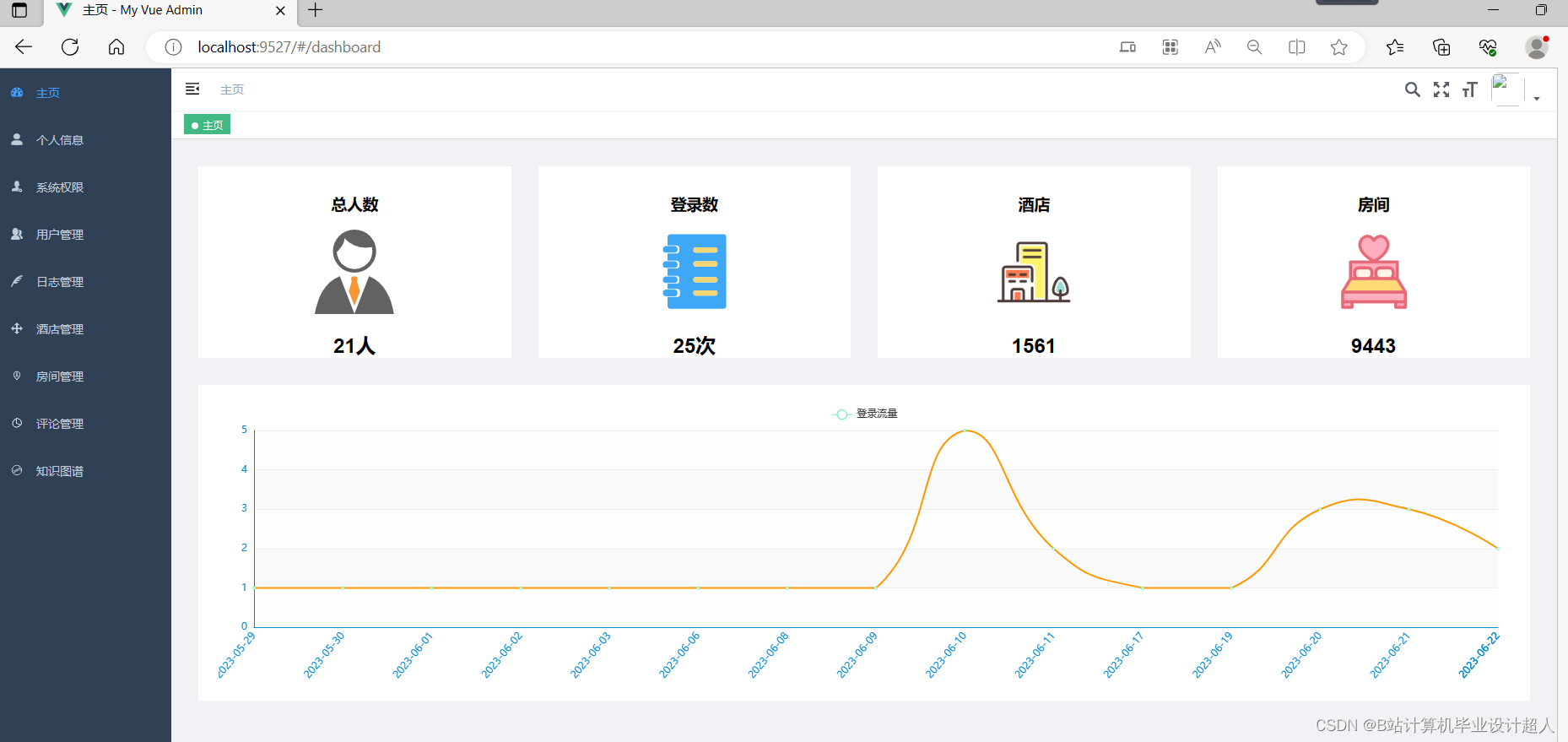
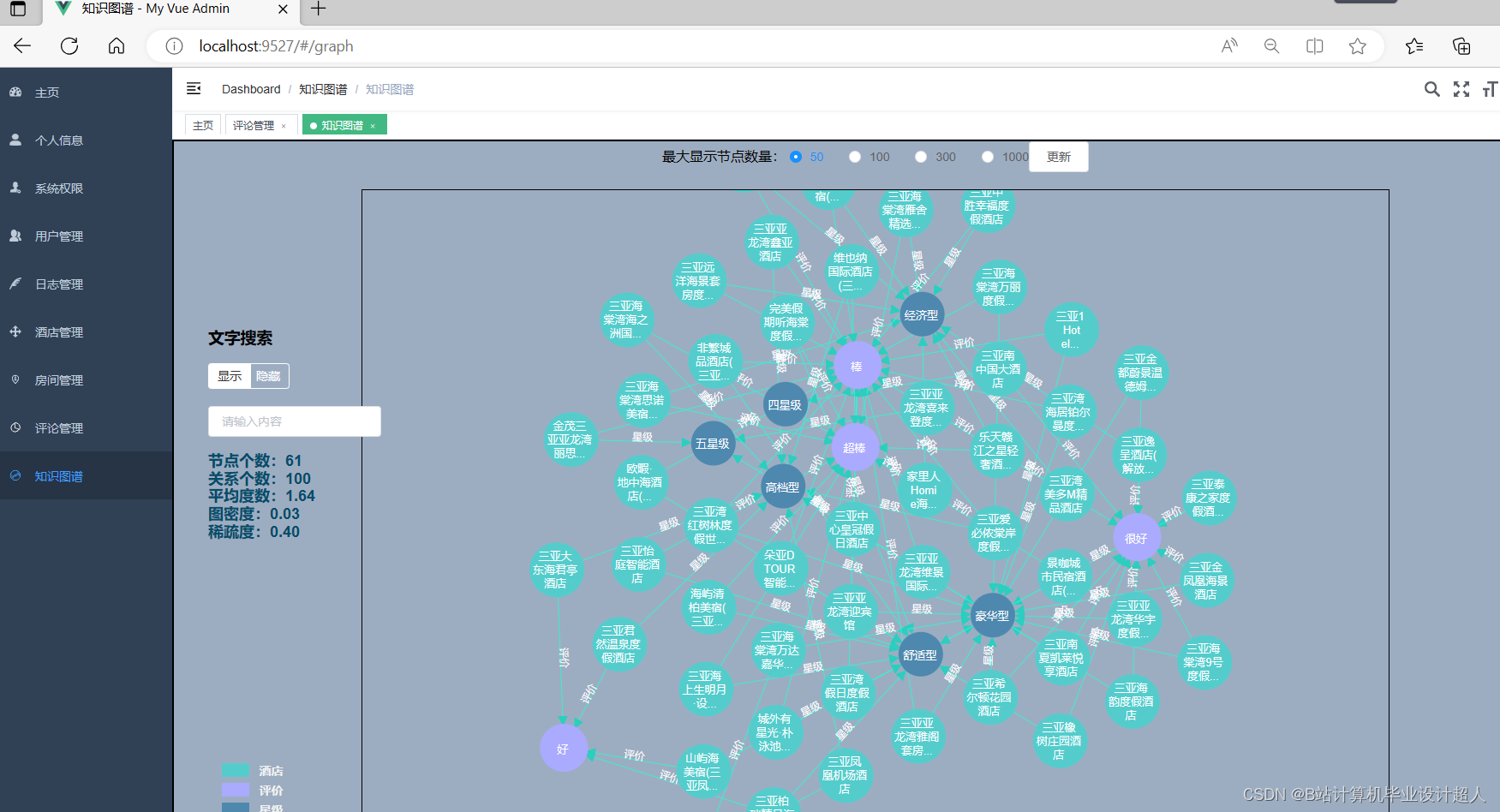
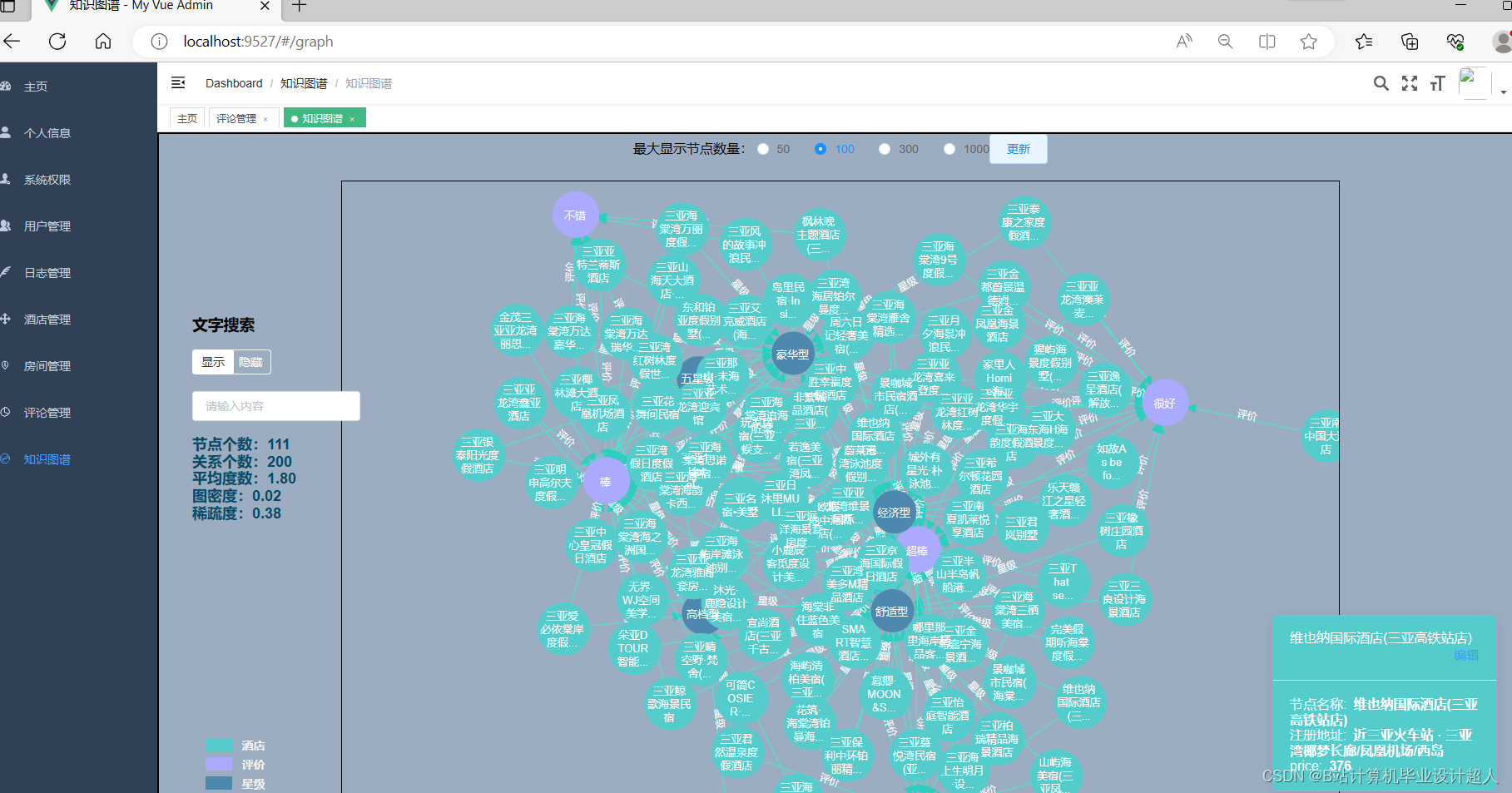
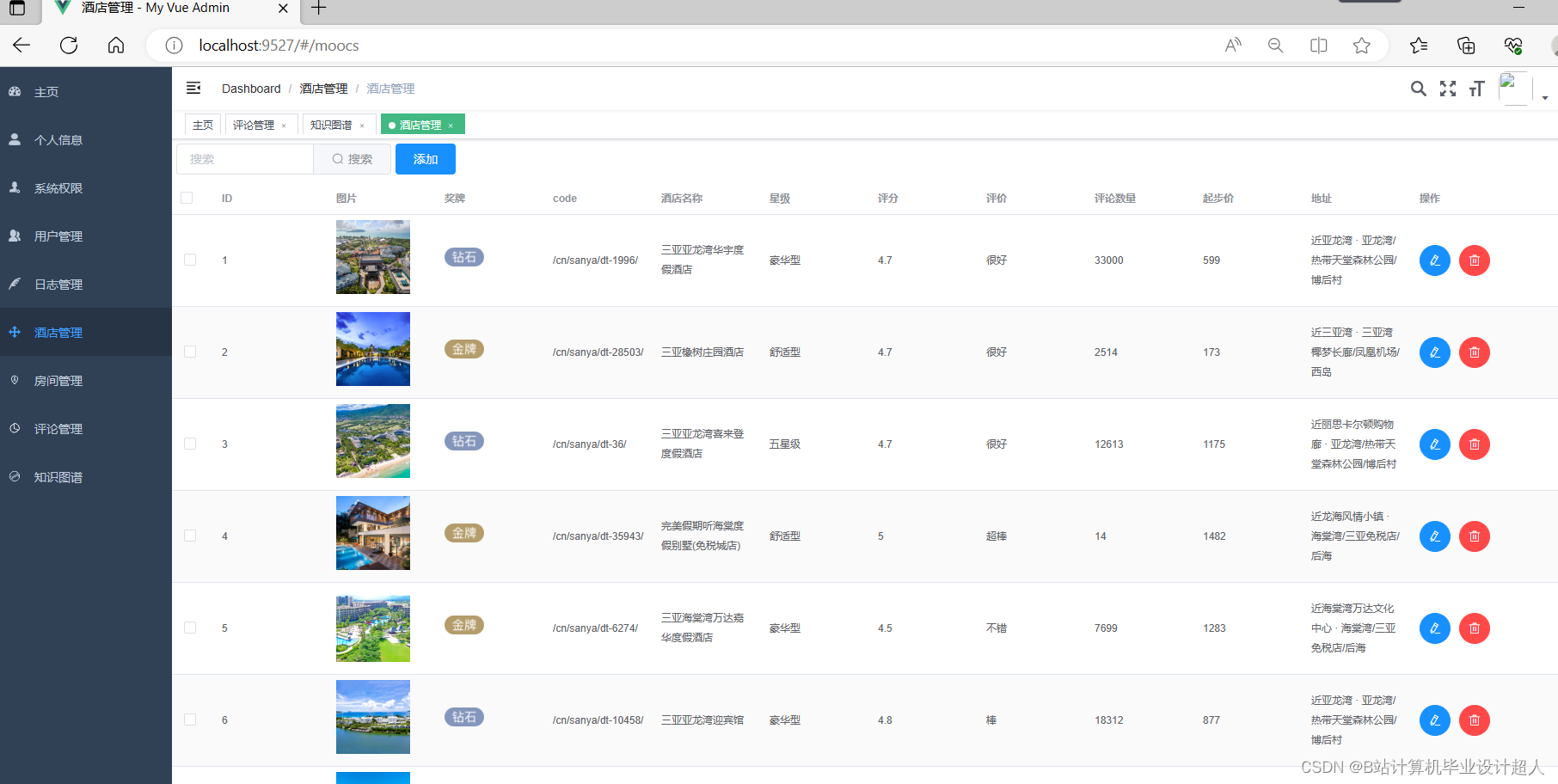
核心算法代码分享如下:
import pandas as pd
from pyspark import Row, SparkContext
from pyspark.sql import SQLContext, SparkSession
class Calculator():
def __init__(self):
# spark 初始化
self.sql_spark = SparkSession. \
Builder(). \
appName('sql'). \
master('local'). \
getOrCreate()
# mysql 配置
self.prop = {'user': 'sql_bs_sju_site',
'password': 'xzDPV7JL79w3Epg',
'driver': 'com.mysql.cj.jdbc.Driver'}
self.url = 'jdbc:mysql://127.0.0.1:3306/sql_bs_sju_site'
def __del__(self):
# 关闭spark会话
self.sql_spark.stop()
del self.sql_spark
def show(self):
# 读取表
data = self.sql_spark.read.jdbc(url=self.url, table='(select user_id,tag_type,tag_weight,tag_name from user_usertag) aaa', properties=self.prop)
# data.
# 打印data数据类型
print(type(data))
# 展示数据
data.show()
if __name__ == '__main__':
Calculator().show()
def writ():
# spark 初始化
sc = SparkContext(master='local', appName='sql')
spark = SQLContext(sc)
# mysql 配置(需要修改)
prop = {'user': 'sql_bs_sju_site',
'password': 'xzDPV7JL79w3Epg',
'driver': 'com.mysql.cj.jdbc.Driver'}
url = 'jdbc:mysql://127.0.0.1:3306/sql_bs_sju_site'
# 创建spark DataFrame
# 方式1:list转spark DataFrame
l = [(1, 12), (2, 22)]
# 创建并指定列名
list_df = spark.createDataFrame(l, schema=['id', 'value'])
# 方式2:rdd转spark DataFrame
rdd = sc.parallelize(l) # rdd
col_names = Row('id', 'value') # 列名
tmp = rdd.map(lambda x: col_names(*x)) # 设置列名
rdd_df = spark.createDataFrame(tmp)
# 方式3:pandas dataFrame 转spark DataFrame
df = pd.DataFrame({'id': [1, 2], 'value': [12, 22]})
pd_df = spark.createDataFrame(df)
# 写入数据库
pd_df.write.jdbc(url=url, table='new', mode='append', properties=prop)
# 关闭spark会话
sc.stop()
# 创建DataFrame
## read.json
# df = spark.read.json("examples/src/main/resources/people.json")
# df = spark.read.load("examples/src/main/resources/people.json", format="json") # format: Default to ‘parquet’
# ## read.csv
# df_csv = spark.read.csv("examples/src/main/resources/people.csv", sep=';', header=True)
# ## read.text
# df_txt = spark.read.text("examples/src/main/resources/people.txt")
# ## read.parquet
# df_parquet = spark.read.parquet("examples/src/main/resources/users.parquet")
# ## orc
# df_orc = spark.read.orc("examples/src/main/resources/users.orc")
# ## rdd
# sc = spark.sparkContext
# rdd = sc.textFile('examples/src/main/resources/people.json')
# df_rdd1 = spark.read.json(rdd)
# createDataFrame: rdd, list, pandas.DataFrame
# df_list = spark.createDataFrame([('Tom', 80), ('Alice', None)], ["name", "height"])
# l = [('Alice', 1)]
# rdd = sc.parallelize(l)
# df_rdd2 = spark.createDataFrame(rdd, ['name', 'age'])
# df_rdd2.show()
# +-----+---+
# | name | age |
# +-----+---+
# | Alice | 1 |
# +-----+---+
# ## with scheme
# from pyspark.sql.types import *
# schema = StructType([
# StructField("name", StringType(), True),
# StructField("age", IntegerType(), True)])
# df3 = spark.createDataFrame(rdd, schema)
# # from pandas
# import pandas
# df_pandas = spark.createDataFrame(pandas.DataFrame([[1, 2]]))
# df_pandas.show()
# +---+---+
# | 0 | 1 |
# +---+---+
# | 1 | 2 |
# +---+---+
# 创建DataFrame, customers, products, sales
# customers = [(1, 'James', 21, 'M'), (2, "Liz", 25, "F"), (3, "John", 31, "M"), \
# (4, "Jennifer", 45, "F"), (5, "Robert", 41, "M"), (6, "Sandra", 45, "F")]
# df_customers = spark.createDataFrame(customers, ["cID", "name", "age", "gender"]) # list -> DF
# products = [(1, "iPhone", 600, 400), (2, "Galaxy", 500, 400), (3, "iPad", 400, 300), \
# (4, "Kindel", 200, 100), (5, "MacBook", 1200, 900), (6, "Dell", 500, 400)]
# df_products = sc.parallelize(products).toDF(["pId", "name", "price", "cost"]) # List-> RDD ->DF
# sales = [("01/01/2015", "iPhone", "USA", 40000), ("01/02/2015", "iPhone", "USA", 30000), \
# ("01/02/2015", "iPhone", "China", 10000), ("01/02/2015", "iPhone", "China", 5000), \
# ("01/01/2015", "S6", "USA", 20000), ("01/02/2015", "S6", "USA", 10000), \
# ("01/01/2015", "S6", "China", 9000), ("01/02/2015", "S6", "China", 6000)]
# df_sales = spark.createDataFrame(sales, ["date", "product", "country", "revenue"])
# 基本操作
# df_customers.cache() # 以列式存储在内存中
# df_customers.persist() # 缓存到内存中
# df_customers.unpersist() # 移除所有的blocks
# df_customers.coalesce(numPartitions=1) # 返回一个有着numPartition的DataFrame
# df_customers.repartition(10) ##repartitonByRange
# df_customers.rdd.getNumPartitions() # 查看partitons个数
# df_customers.columns # 查看列名
# ['cID', 'name', 'age', 'gender']
# df_customers.dtypes # 返回列的数据类型
# df_customers.explain() # 返回物理计划,调试时应用
# 执行操作actions
# df_customers.show(n=2, truncate=True, vertical=False) # n是行数,truncate字符限制长度。
# df_customers.collect() # 返回所有记录的列表, 每一个元素是Row对象
# df_customers.count() # 有多少行,
# df_customers.head(n=1) # df_customers.limit(), 返回前多少行; 当结果比较小的时候使用
# df_customers.describe() # 探索性数据分析
# df_customers.first() # 返回第一行
# df_customers.take(2) # 以Row对象的形式返回DataFrame的前几行
# df_customers.printSchema() # 以树的格式输出到控制台
# root
# | -- cID: long(nullable=true)
# | -- name: string(nullable=true)
# | -- age: long(nullable=true)
# | -- gender: string(nullable=true)
# df_customers.corr('cID', "age") # df_customers.cov('cID', 'age') 计算两列的相关系数
# 转换:查询常用方法,合并,抽样,聚合,分组聚合,子集选取
# 返回一个有新名的DataFrame
# df_as1 = df_customers.alias("df_as1")
# 聚合操作.agg: 一列或多列上执行指定的聚合操作,返回一个新的DataFrame
# from pyspark.sql import functions as F
# df_agg = df_products.agg(F.max(df_products.price), F.min(df_products.price), F.count(df_products.name))
# 访问列
# df_customers['age'] # 访问一列, 返回Column对象
# df_customers[['age', 'gender']].show()
# df_customers.cov('cID', 'age') 计算两列的相关系数
# 去重,删除列
# df_withoutdup = df_customers.distinct() #distinct 去除重复行,返回一个新的DataFram, 包含不重复的行
# df_drop = df_customers.drop('age', 'gender') # drop: 丢弃指定的列,返回一个新的DataFrame
# df_dropDup = df_sales.dropDuplicates(['product', 'country']) # dropDuplicates: 根据指定列删除相同的行
# filter 筛选元素, 过滤DataFrame的行, 输入参数是一个SQL语句, 返回一个新的DataFrame
# 行筛选和列选择
# df_filter = df_customers.filter(df_customers.age > 25)
# select 返回指定列的数据,返回一个DataFrame
# df_select = df_customers.select('name','age') # | name|age|
# df_select1 = df_customers.select(df_customers['name'], df_customers['age'] + 1) # | name|(age + 1)|
# df_select2 = df_customers.selectExpr('name', 'age +1 AS new_age') # | name|new_age| 可以接收SQL表达式
# 增加列,替换列
## withColumn 对源DataFrame 做新增一列或替换一原有列的操作, 返回DataFrame
# df_new = df_products.withColumn("profit", df_products.price - df_products.cost)
## withColumnRenamed (existing, new)
# df_customers.withColumnRenamed('age', 'age2')
# 分组groupby
# groupby/groupBy 根据参数的列对源DataFrame中的行进行分组
# groupByGender = df_customers.groupBy('gender').count()
# revenueByproduct = df_sales.groupBy('product').sum('revenue')
# 替换replace
# df_replace = df_customers.replace(["James", "Liz"], ["James2", "Liz2"], subset=["name"])
# 缺失值处理(参数pandas.DataFrame类似)
# from pyspark.sql import Row
# df = sc.parallelize([ \
# Row(name='Alice', age=5, height=80), \
# Row(name=None, age=5, height=70), \
# Row(name='Bob', age=None, height=80)]).toDF()
# dropna #na.drop删除包含缺失值的列,
# df.na.drop(how='any', thresh=None, subset=None).show() # df.dropna().show()
# fillna # na.fill #
# df.na.fill({'age': 5, 'name': 'unknown'}).show()
# 遍历循环
# ##foreach: 对DataFrame的每一行进行操作
# def f(customer):
# print(customer.age)
# df_customers.foreach(f)
# ##foreachPartition, 对每一个Partition进行遍历操作
# 合并
# ## intersect 取交集,返回一个新的DataFrame
# customers2 = [(11, 'Jackson', 21, 'M'), (12, "Emma", 25, "F"), (13, "Olivia", 31, "M"), \
# (4, "Jennifer", 45, "F"), (5, "Robert", 41, "M"), (6, "Sandra", 45, "F")]
# df_customers2 = spark.createDataFrame(customers2, ["cID", "name", "age", "gender"]) # list -> DF
# df_common = df_customers.intersect(df_customers2)
## union: 返回一个新的DataFrame, 合并行.
# 一般后面接着distinct()
# df_union = df_customers.union(df_customers2) # 根据位置合并
# df_union_nodup = df_union.distinct()
# unionByName 根据列名进行行合并
# df1 = spark.createDataFrame([[1, 2, 3]], ["col0", "col1", "col2"])
# df2 = spark.createDataFrame([[4, 5, 6]], ["col1", "col2", "col0"])
# df_unionbyname = df1.unionByName(df2)
## join: 与另一个DataFrame 上面执行SQL中的连接操作。 参数:DataFrame, 连接表达式,连接类型
# transactions = [(1, 5, 3, "01/01/2015", "San Francisco"), (2, 6, 1, "01/02/2015", "San Jose"), \
# (3, 1, 6, "01/01/2015", "Boston"), (4, 200, 400, "01/02/2015", "Palo Alto"), \
# (6, 100, 100, "01/02/2015", "Mountain View")]
# df_transactions = spark.createDataFrame(transactions, ['tId', "custId", "date", "city"])
# df_join_inner = df_transactions.join(df_customers, df_transactions.custId == df_customers.cID, "inner")
# df_join_outer = df_transactions.join(df_customers, df_transactions.custId == df_customers.cID, "outer")
# df_join_left = df_transactions.join(df_customers, df_transactions.custId == df_customers.cID, "left_outer")
# df_join_right = df_transactions.join(df_customers, df_transactions.custId == df_customers.cID, "right_outer")
##left_semi 返回在两个表都有的行,只返回左表
##left_anti 返回只在左表有的行
# 排序
# ## orderBy/sort 返回按照指定列排序的DataFrame. 默认情况下按升序(asc)排列
# df_sort1 = df_customers.orderBy("name")
# df_sort2 = df_customers.orderBy(['age', 'name'], ascending=[0, 1])
# df_sort3 = df_customers.sort("name")
# df_sort4 = df_customers.sort("name", ascending=False)
# 抽样与分割
# ## sample, 返回一个DataFrame, 包含源DataFrame 指定比例行数的数据
# df_sample = df_customers.sample(withReplacement=False, fraction=0.2, seed=1)
## sampleBy 按指定列,分层无放回抽样
# df_sample2 = df_sales.sampleBy('product', fractions={"iPhone": 0.5, "S6": 0.5}, seed=1)
## randomSplit: 把DataFrame分割成多个DataFrame
# df_splits = df_customers.randomSplit([0.6, 0.2, 0.2])
# 转化成其他常用数据对象, Json, DF, pandas.DF
# df_json = df_customers.toJSON() ## 返回RDD, RDD每个元素是JSON对象
# df_json.first()
# '{"cID":1,"name":"James","age":21,"gender":"M"}'
# df_pandas = df_customers.toPandas() ## 返回pandas.DataFrame
# rdd = df_customers.rdd # 然后可以使用RDD的操作
# df = rdd.toDF().first()
# 生成临时查询表
# # registerTempTable. 给定名字的临时表, 用SQL进行查询
# df_customers.registerTempTable("customers_temp")
# df_search = spark.sql('select * from customers_temp where age > 30')
# createGlobalTempView
# createOrReplaceGlobalTempView 创建一个临时永久表,与Spark应该绑定
# createOrReplaceTempView 生命周期与SparkSession绑定
# createTempView
# 其他函数
# crossJion, crosstab, cube, rollup
# 输出write,保存DataFrame到文件中
# ## json, parquet, orc, csv,text 格式, 可以写入本地文件系统, HDFS, S3上
# import os
# df_customers0 = df_customers.coalesce(numPartitions=1) # 设置NumPartition为1
# # df_customers0.write.format('json').save("savepath")
# # df_customers0.write.orc("savepath")
# df_customers0.write.csv("savepath", header=True, sep=",", mode='overwrite')
# # mode: 默认error/ append(追加)/ overwrite(重写)/ ignore(不写)
# # df_customers0.write.parquet("savepath")


















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











