



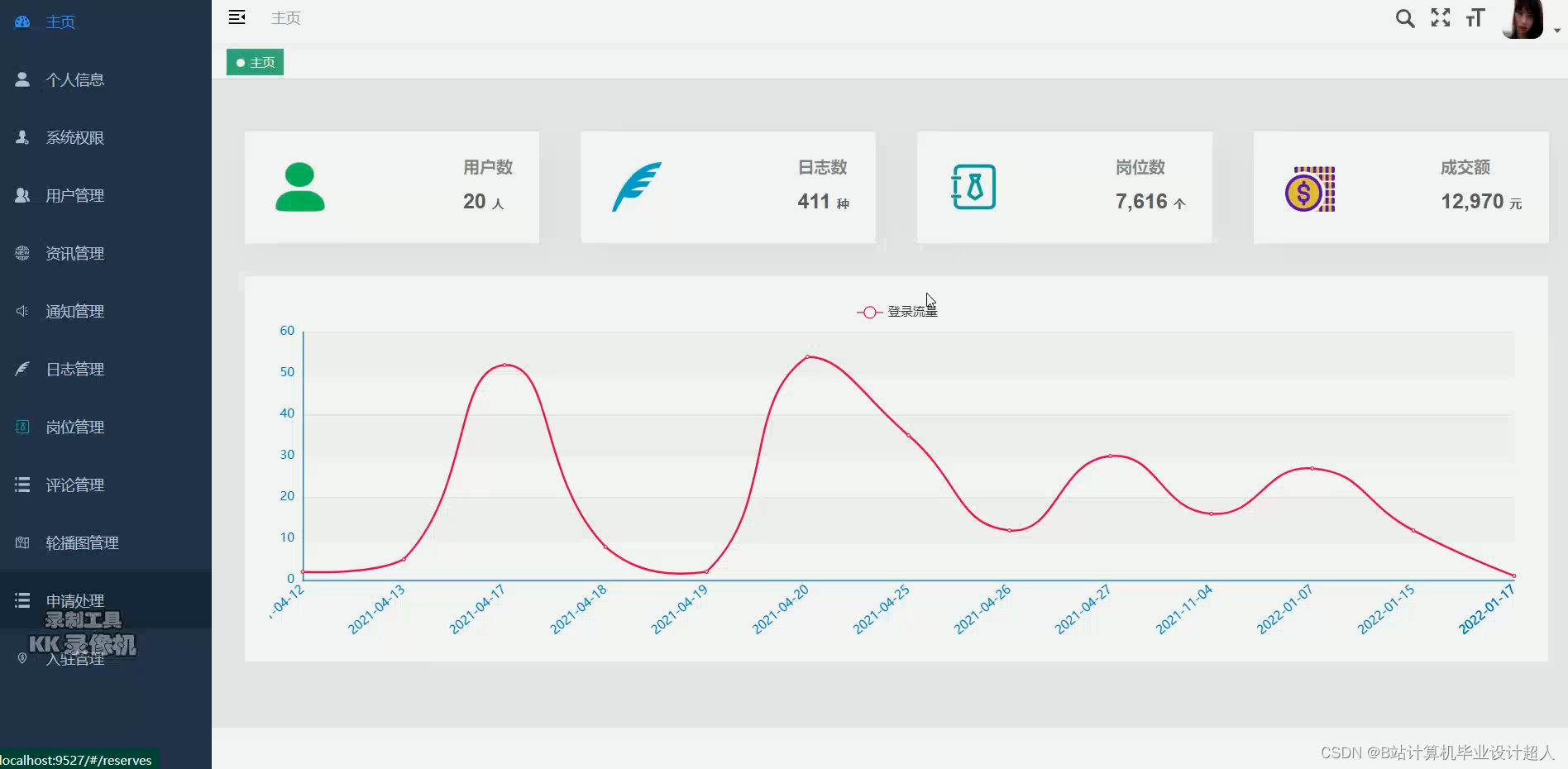
 本文介绍了使用ApacheMahout构建推荐系统的方法,包括使用JDBCDataModel从MySQL数据库获取数据,以及处理PearsonCorrelationSimilarity和UserNeighborhood进行个性化推荐。同时,文章涉及如何通过Python爬虫抓取拉勾网招聘数据,并讨论了数据仓库建设、数据清洗和可视化面临的挑战及解决方案。
本文介绍了使用ApacheMahout构建推荐系统的方法,包括使用JDBCDataModel从MySQL数据库获取数据,以及处理PearsonCorrelationSimilarity和UserNeighborhood进行个性化推荐。同时,文章涉及如何通过Python爬虫抓取拉勾网招聘数据,并讨论了数据仓库建设、数据清洗和可视化面临的挑战及解决方案。
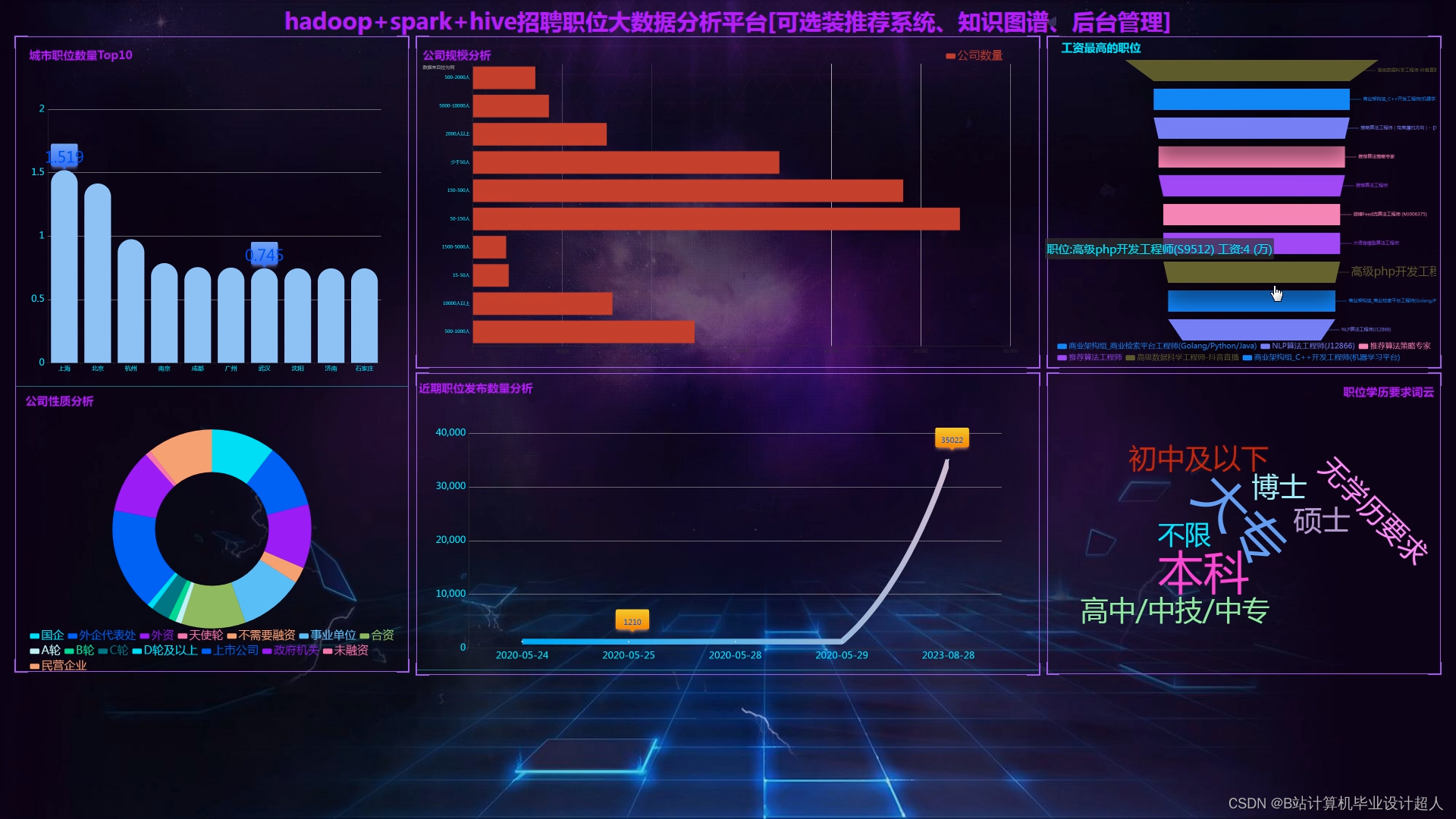
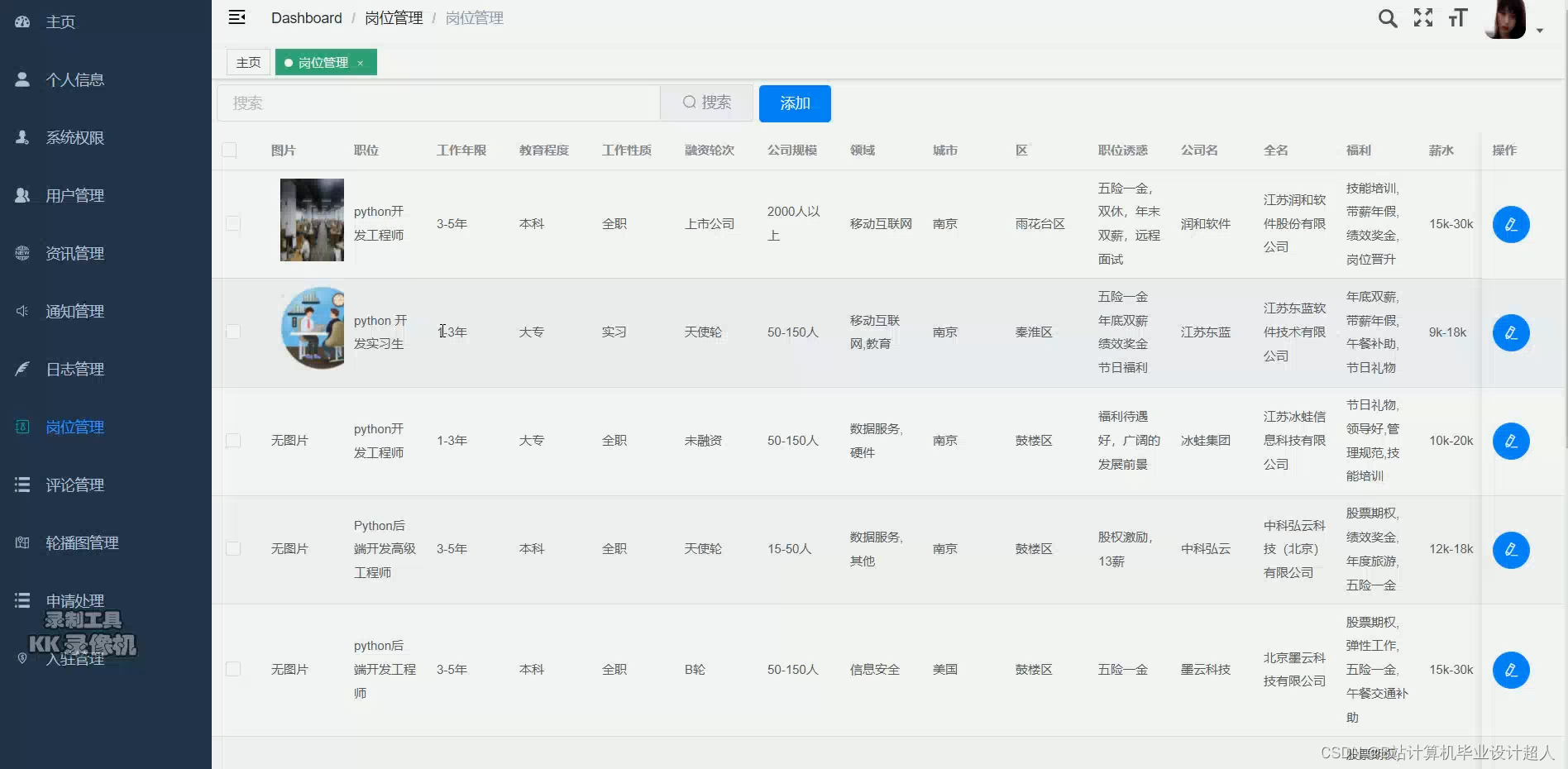
核心算法代码分享如下:
package com.university.demo.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.mysql.cj.jdbc.MysqlDataSource;
import com.university.demo.dao.RateDao;
import com.university.demo.entity.Rate;
import com.university.demo.service.RateService;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.impl.model.jdbc.MySQLJDBCDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.JDBCDataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
@Service
public class RateServiceImpl extends ServiceImpl<RateDao, Rate> implements RateService {
@Override
public void updateRate(Integer uid, Integer iid, Double modifyValue) {
QueryWrapper<Rate> wrapper = new QueryWrapper<>();
wrapper.eq("uid", uid).eq("iid", iid);
List<Rate> rates = baseMapper.selectList(wrapper);
if(rates == null){
Rate newRate = new Rate();
newRate.setUid(uid);
newRate.setIid(iid);
newRate.setRate(modifyValue);
baseMapper.insert(newRate);
}else{
Rate oldRate = rates.get(0);
Double old = oldRate.getRate();
oldRate.setRate(old + modifyValue);
baseMapper.updateById(oldRate);
}
}
@Override
public void setupRate(Integer uid, Integer iid, Double rate) {
QueryWrapper<Rate> wrapper = new QueryWrapper<>();
wrapper.eq("uid", uid).eq("iid", iid);
List<Rate> rates = baseMapper.selectList(wrapper);
if(rates == null || rates.size()==0){
Rate newRate = new Rate();
newRate.setUid(uid);
newRate.setIid(iid);
newRate.setRate(rate);
baseMapper.insert(newRate);
}else{
Rate oldRate = rates.get(0);
oldRate.setRate(rate);
baseMapper.updateById(oldRate);
}
}
@Override
public List<RecommendedItem> getRecommendItemIds(Integer userId , Integer howMany) {
MysqlDataSource datasource = new MysqlDataSource();
datasource.setUrl("jdbc:mysql://localhost:3396/job?useSSL=false&serverTimezone=UTC&characterEncoding=utf-8&serverTimezone=Asia/Shanghai");
// datasource.setServerName("localhost");
datasource.setUser("root");
datasource.setPassword("123456");
// datasource.setDatabaseName("job");
JDBCDataModel dataModel = new MySQLJDBCDataModel(datasource, "tb_rate",
"uid", "iid", "rate", null);
UserSimilarity similarity;
try {
similarity = new PearsonCorrelationSimilarity(dataModel);
UserNeighborhood neighbourhood = new NearestNUserNeighborhood(2,
similarity, dataModel);
Recommender recommender = new GenericUserBasedRecommender(
dataModel, neighbourhood, similarity);
long start = System.currentTimeMillis();
List<RecommendedItem> recommendations = recommender.recommend(
userId, howMany);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
long stop = System.currentTimeMillis();
System.out.println("Took: " + (stop - start) + " millis");
return recommendations;
} catch (TasteException e) {
e.printStackTrace();
return new ArrayList<>();
}
}
}
|
学 号 |
XXX |
学生姓名 |
XXX |
|
届 别 |
24届 |
专 业 |
数据科学与大数据技术 |
|
指导教师 姓名及职称 |
XXX | ||
|
毕业设计 (论文)题目 |
基于Hadoop+Hive的招聘数据仓库的设计与实现 | ||
|
开 题 报 告 内 容 |
随着大数据时代的到来,在今天这个高度竞争的经济环境下,之前采用人工进行数据采集,之后进行统一数据分析的工作所带来的效果已经不能满足人们对于职业分析的要求了,现在需要通过一种实时对海量招聘数据进行分析的软件来帮助求职者或相关领域工作人员解决对现有各个行业的疑惑。通过大数据智能分析所取得的成果可以应用与各行各业,社交媒体网站和其他公共服务领域。以一种开放的姿态展现在万千用户面前,这种关于职业招聘数据信息分析之后所取得的理论可以帮用户解决一些切实的问题,例如薪资,公司规模等信息,并且能够切实地帮助用户解决对于求职道路上的一些疑惑。
在过去,“智能分析”这一技术被应用于商业智能世界,提供理论方法和高效的解决速度,通过迅速、一致和能够交互地访问各种类型的信息透视图来得到对应的结果。与分析的基本理论十分相似,数据挖掘已经实施于商业,从而对大量的数据进行分析。现在最困难的就是怎么获得躲在大数据底层的知识。分析传统的数据存储与各公司的海量数据,我们会得到相比之前不一样的特殊结果,慢慢的智能分析的道路于传统理论分析道路会相差更大。 传统的分析是对已经存在于很久的数据范围进行分析处理。大多数数据存储空间都有一个极为繁琐的提取、转换和加载过程和数据空间限制,这就是说上传到数据空间的分析结果会更加简易易懂。大数据的最为优秀的长处是,除了可以用之前的操作来捕获数据,它还可以对结构复杂的数据进行处理。这也就是在告诉我们大数据所要分析的数据可以是各种各样的。这也会使这项技术实施起来更有难度,但是同时相比于传统方法我们会见到不一样的效果。 传统的分析会依赖于一个已经产生的数据结构体,在这个结构体中,事物与事物之间的大致关系已经存在,并在原有的关系中进行分析。因此,对于大数据分析,一个已经存在已久的世界里,很难找到事物与事物之间的独特关系,因此,在大数据分析中会考虑到图像、视频、运动生成的信息、射频识别等形式的结构化信息。这会使得大数据分析更有远见。 传统的分析方法是按照一定次序进行的,在获得不可缺少的知识理论前,我们必须每天晚上等待提取、加工和装载以及加工工作的完成。大数据分析任何时间任何地点都可以分析的,只需要使用一些特定工具即可。在传统的分析系统中,实时分析是非常麻烦的,费钱费时间,如大型并行处理系统或对称多处理系统。而大数据则是通过一些大数据分析软件进行数据分析,从而获得对应的理论知识。
内容:
拟解决的问题:
| ||
|
开 题 报 告 内 容 |
学生签名: 年 月 日 | ||
|
指导 教师 对 开题 报告 意见 |
指导教师签名: 年 月 日 | ||



















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











