




 本文介绍了如何使用Python和scikit-learn库构建一个简单的逻辑回归模型来预测心血管疾病,涉及数据预处理、特征选择和模型训练的步骤,以及在实际应用中的注意事项。
本文介绍了如何使用Python和scikit-learn库构建一个简单的逻辑回归模型来预测心血管疾病,涉及数据预处理、特征选择和模型训练的步骤,以及在实际应用中的注意事项。
博主介绍:✌全网粉丝100W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
🍅由于篇幅限制,想要获取完整文章或者源码,或者代做,可以给我留言或者找我聊天。🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
文章包含:项目选题 + 项目展示图片 (必看)

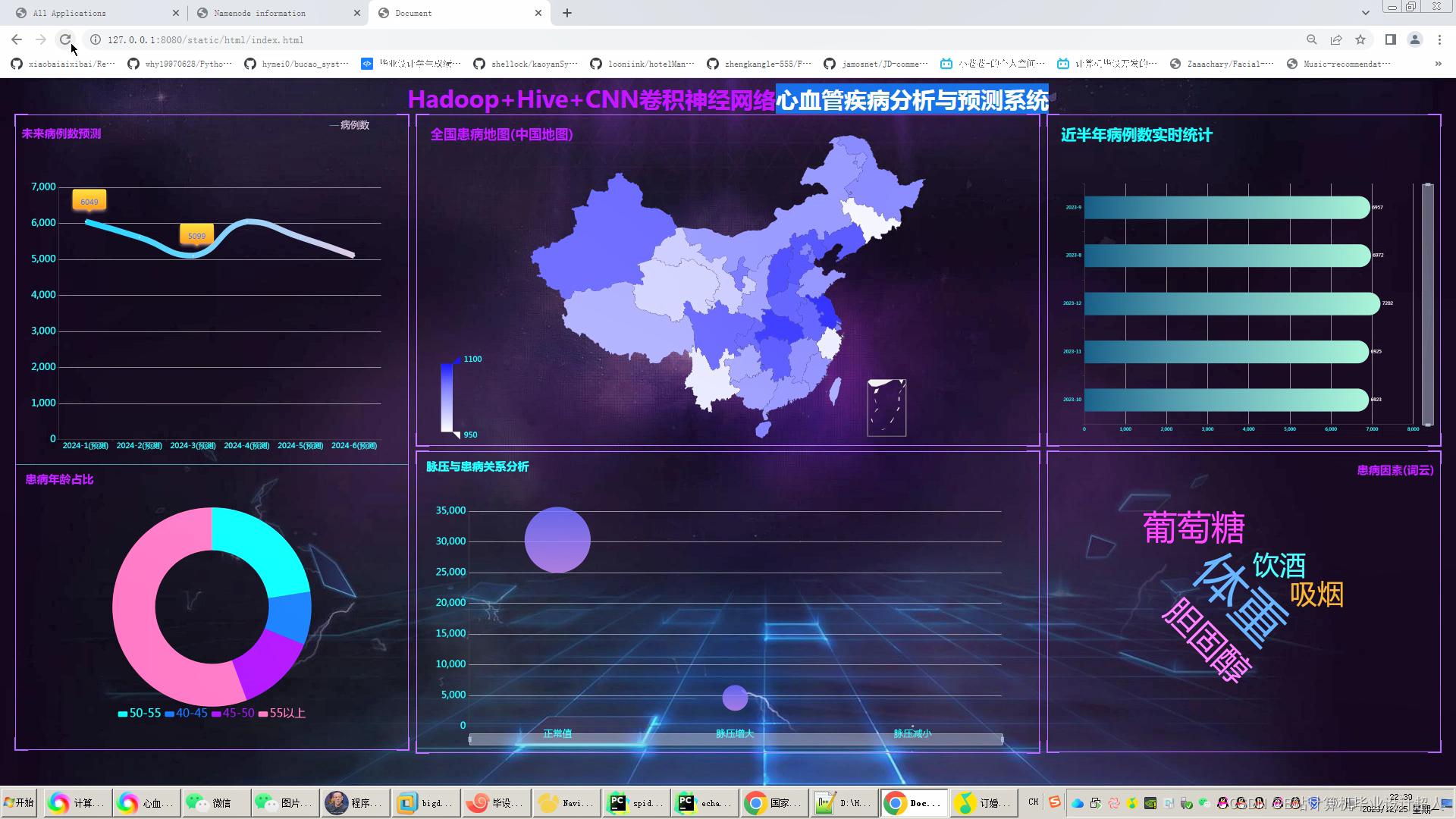
为了预测心血管疾病,我们通常会使用机器学习模型,比如逻辑回归、随机森林、梯度提升树或神经网络等。这里,我将给出一个使用Python和scikit-learn库的逻辑回归模型的简单示例。请注意,实际应用中,您需要使用真实的医疗数据集,并可能需要进行更复杂的数据预处理、特征选择和模型调优。
首先,确保您已经安装了必要的库:
bash
pip install numpy pandas scikit-learn
然后,您可以使用以下代码作为起点:
python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
# 假设您有一个CSV文件,其中包含用于预测心血管疾病的特征和目标变量
# CSV文件的列可能包括:年龄、性别、血压、胆固醇水平等
data = pd.read_csv('cardiovascular_disease_dataset.csv')
# 分离特征和目标变量
X = data.drop('CVD', axis=1) # 假设'CVD'列是目标变量,表示是否患有心血管疾病
y = data['CVD']
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征缩放(对于逻辑回归很重要)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 创建逻辑回归模型
model = LogisticRegression()
# 训练模型
model.fit(X_train_scaled, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test_scaled)
# 评估模型
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
print("\nClassification Report:")
print(classification_report(y_test, y_pred))
print("\nAccuracy Score:")
print(accuracy_score(y_test, y_pred))
请注意,这只是一个非常基本的示例。在现实世界的应用中,您可能需要进行以下步骤:
数据清洗和预处理:处理缺失值、异常值、编码分类变量等。
特征选择:选择对预测目标最有影响的特征。
超参数调优:通过交叉验证、网格搜索等技术找到模型的最佳超参数。
评估模型性能:使用不同的评估指标和交叉验证策略来评估模型的泛化能力。
部署模型:将训练好的模型部署到生产环境中,并持续监控其性能。
务必确保您遵守所有相关的隐私和伦理准则,特别是在处理医疗数据时。在实际应用中,您可能需要与医疗专家合作,并遵循相关法律法规。


















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











