




 本文介绍了博主拥有大量粉丝的专业团队,专注于计算机毕业设计实战,分享了使用Hadoop、Spark和Hive进行高考数据分析的案例,并展示了如何用Keras实现高考志愿填报推荐系统的机器学习模型。
本文介绍了博主拥有大量粉丝的专业团队,专注于计算机毕业设计实战,分享了使用Hadoop、Spark和Hive进行高考数据分析的案例,并展示了如何用Keras实现高考志愿填报推荐系统的机器学习模型。
博主介绍:✌全网粉丝100W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
🍅由于篇幅限制,想要获取完整文章或者源码,或者代做,可以给我留言或者找我聊天。🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
文章包含:项目选题 + 项目展示图片 (必看)
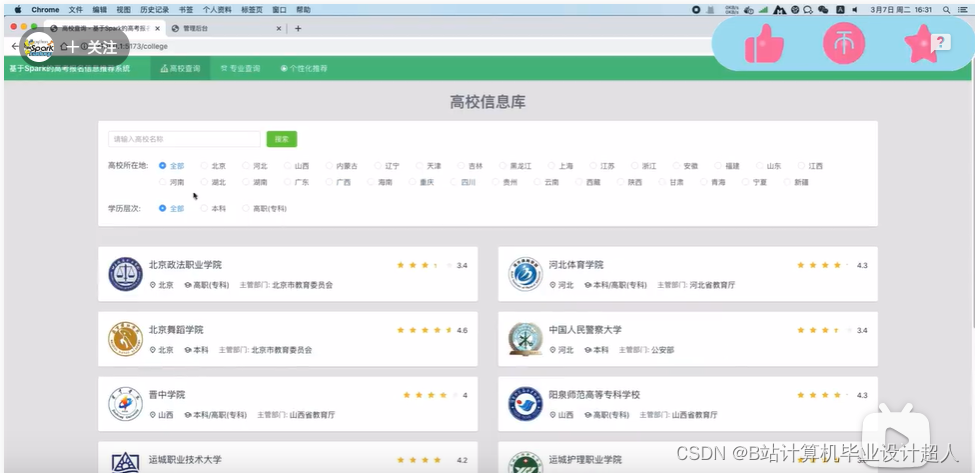
计算机毕业设计吊炸天hadoop+spark+hive高考数据分析可视化大屏 高考爬虫 高考志愿填报推荐推荐系统 高考分数线预测 数据仓库 大数据毕业设计
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import to_categorical
# 生成模拟数据
# X_train: 训练输入数据,y_train: 训练标签,X_test: 测试输入数据,y_test: 测试标签
X_train = np.random.rand(1000, 20)
y_train = np.random.randint(0, 2, 1000)
y_train = to_categorical(y_train)
X_test = np.random.rand(100, 20)
y_test = np.random.randint(0, 2, 100)
y_test = to_categorical(y_test)
# 创建模型
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=20))
model.add(Dense(64, activation='relu'))
model.add(Dense(2, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Test Loss: {loss}')
print(f'Test Accuracy: {accuracy}')


















 2880
2880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











