




 本文介绍了博主及其团队专注于计算机专业毕业设计项目,包括使用Python爬取药房网医院数据,数据清洗,存储在HDFS,Hive分析,以及将数据迁移至MySQL,后端采用SpringBoot,前端通过Echarts实现可视化。提供代码示例展示了整个流程。
本文介绍了博主及其团队专注于计算机专业毕业设计项目,包括使用Python爬取药房网医院数据,数据清洗,存储在HDFS,Hive分析,以及将数据迁移至MySQL,后端采用SpringBoot,前端通过Echarts实现可视化。提供代码示例展示了整个流程。
博主介绍:✌全网粉丝100W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
🍅由于篇幅限制,想要获取完整文章或者源码,或者代做,可以给我留言或者找我聊天。🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
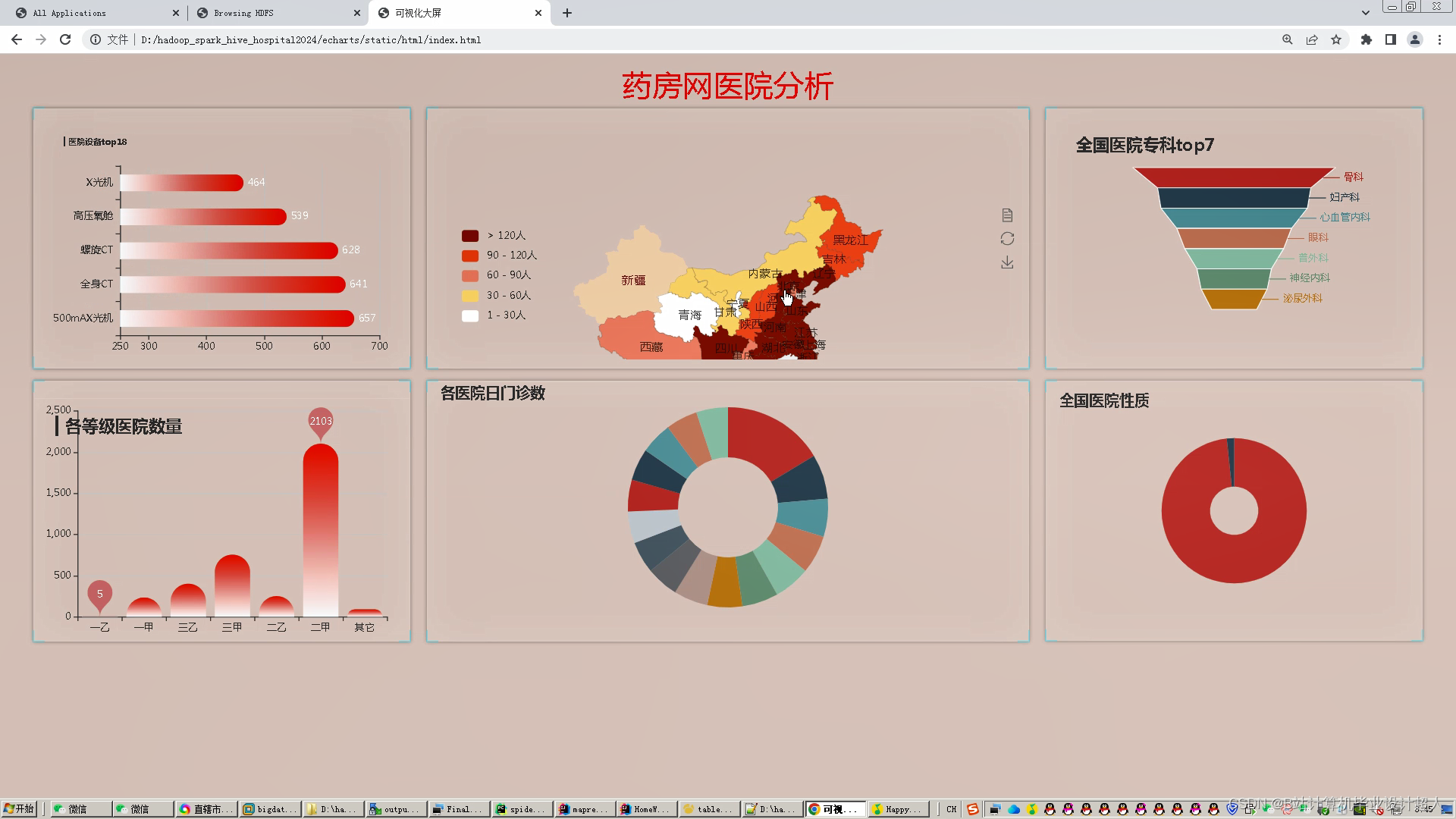
文章包含:项目选题 + 项目展示图片 (必看)
技术栈:使用python爬取药房网医院数据,清洗后上传hdfs,使用hive集群进行数据分析,sqoop迁移到mysql,springboot作为后端,前端echarts驾驶舱可视化
数据分析代码分享如下:
import requests
from bs4 import BeautifulSoup
def get_hospital_info(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code != 200:
print(f"Failed to retrieve page. Status code: {response.status_code}")
return None
soup = BeautifulSoup(response.content, 'html.parser')
# 根据医院网站的HTML结构提取信息
# 假设医院名称在一个具有特定类的标题标签内
hospital_name = soup.find('h1', class_='hospital-name').text.strip()
# 假设地址在一个具有特定类的段落标签内
hospital_address = soup.find('p', class_='hospital-address').text.strip()
# 假设联系电话在一个具有特定类的段落标签内
hospital_phone = soup.find('p', class_='hospital-phone').text.strip()
# 构建并返回医院信息字典
hospital_info = {
'name': hospital_name,
'address': hospital_address,
'phone': hospital_phone
}
return hospital_info
# 示例:爬取某个医院网站的信息
hospital_url = 'https://example.com/hospital' # 替换为实际的医院网站URL
hospital_data = get_hospital_info(hospital_url)
if hospital_data:
print("Hospital Information:")
print("Name:", hospital_data['name'])
print("Address:", hospital_data['address'])
print("Phone:", hospital_data['phone'])


















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











