



 本文探讨了数据可视化中的关键概念,如统计图、数据变换、归一化及曲线拟合,阐述了数据采样的影响因素,并介绍了K-Means聚类与K-medoids的算法原理。此外,还讨论了不同倾斜方法在统计图表中的应用,以及Log尺度和尺度中断在数据展示中的优劣。
本文探讨了数据可视化中的关键概念,如统计图、数据变换、归一化及曲线拟合,阐述了数据采样的影响因素,并介绍了K-Means聚类与K-medoids的算法原理。此外,还讨论了不同倾斜方法在统计图表中的应用,以及Log尺度和尺度中断在数据展示中的优劣。
统计图可视化
数据变换

归一化
目的:
根据分布映射数据
颜色/尺寸/坐标位置编码
归一化区间:
[-1 , 1]
[0 , 1]
曲线拟合/光滑
目的:展示数据趋势
不同的拟合方式:
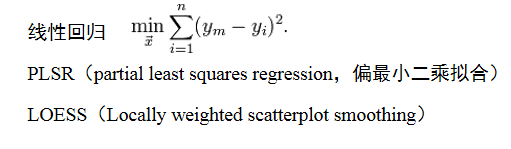
统计采样
从统计分布中选出的样本,用于近似原分布中的特征
影响采样的因素:
分布本身的特性
数据的测量精度
是否需要分析样本细节(样本精细度)
采样成本
K-Means聚类
K-means
随机产生K个中心位置
将每个数据点归为距离最近的中心位置所属的类
根据新的类别划分重新计算中心位置
回到第二步,直到满足一定约束
K-medoids – 改进
中心位置必须在数据点所在位置上
中心位置满足“到类内所有数据点的距离之和最小”
统计图表
中值斜率倾斜:
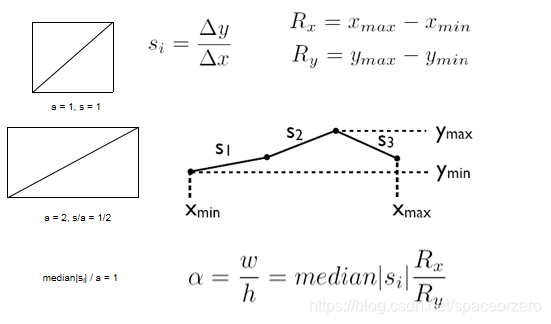
平均斜率倾斜:

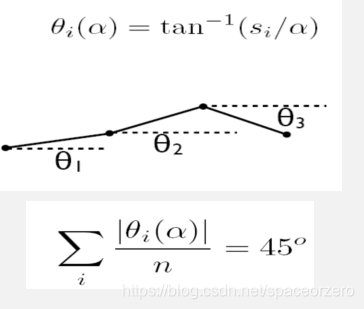
平均方向倾斜:
横纵比倾斜:
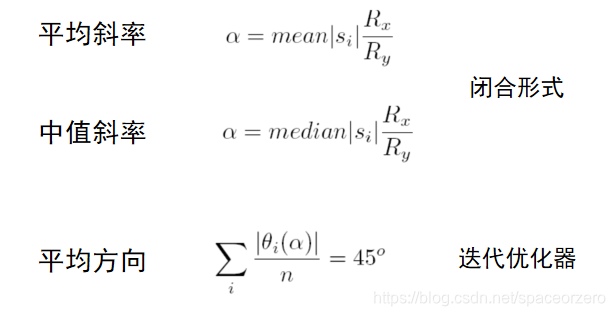
多尺度45°倾斜
为不同的规模优化横纵比
方法:
鉴别感兴趣数据的尺度
生成特定规模的趋势线
把这些线向45°倾斜
过滤生成的横纵比
Log尺度:容易比较所有数据
尺度中断:很难跨越中断比较所有数据

















 1566
1566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









