






 本文深入讲解Scrapy框架的构成与工作流程,包括引擎、爬虫、调度器、下载器及中间件的角色与交互,揭示异步非阻塞网络库Twisted在其中的应用。
本文深入讲解Scrapy框架的构成与工作流程,包括引擎、爬虫、调度器、下载器及中间件的角色与交互,揭示异步非阻塞网络库Twisted在其中的应用。
上期我们简单讲述了Scrapy 框架的基本构成,本期文章主要以一种简单的对话形式介绍一下Scrapy流程图。Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向):
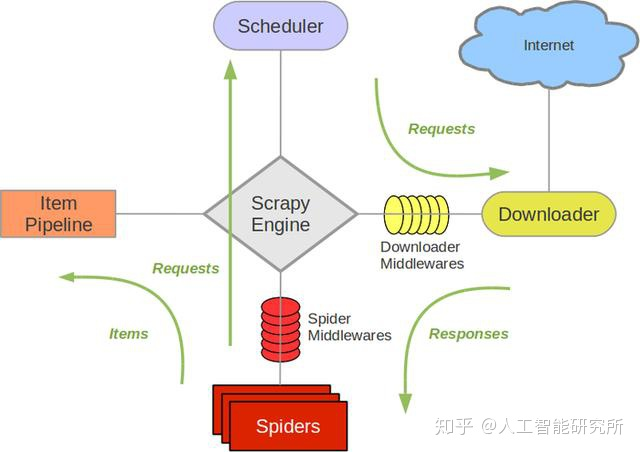
从Scrapy的流程图,我们知道Scrapy Engine(引擎)作为Scrapy的大脑,主要负责spider的协调工作,当spider运行时:
Scrapy Engine(引擎):spider,你好,你好爬取那个网站?
Spider(爬虫): 你好,引擎,我要爬取HTTP:\\http://www.XXXXXX.COM
Scrapy Engine(引擎): 那你把你需要爬取的第一个URL地址给我吧
Spider(爬虫): 好的,这个是第一个URL地址:http://www.xxxx.com
Scrapy Engine(引擎): hello Scheduler(调度器),spider提供了一个request(请求),你 协助排队处理一下
Scheduler(调度器): 好的,等待处理,你稍等一下
Scrapy Engine(引擎):hello Scheduler(调度器),request(请求)处理好的给我一下
Scheduler(调度器): 已经OK,这是处理好的request,给你
Scrapy Engine(引擎):hello Downloader(下载器),你按照Downloader Middlewares(下载中间件,主要设置下载的一些参数)的设置,协助下载一下这个 request
Downloader(下载器):OK,等待下载,已经完成,给你下载好的资料(若下载失败,Engine会告诉Scheduler,记录失败的位置,等待后期重新下载)
Scrapy Engine(引擎):hello Spider Middlewares(Spider中间件),这是下载器下载的资料,你按照设置的参数处理一下
Scrapy Engine(引擎):hello spider 这是下载且处理好的资料,你再处理一下
Spider(爬虫):hello engine,这是我获取到的Item, 还有需要跟进的URL ,你再跟进一下
Scrapy Engine(引擎):hello Item Pipeline(主要负责item的数据保存), 这是spider获取的Item,你处理一下,hello Scheduler(调度器),这是spider要求需要跟进的URL,你处理一下。然后回到第五步,开始循环执行,直到所有的URL处理完毕。
当所有的URL执行完成后,engine会通知Scheduler里面是否有以前下载失败的URL,若有程序会重新下载,直到结束。
1. 安装Scrapy
若你习惯了pychram,在安装scrapy前,你需要安装pywin32、pyOpenSSL、Twisted、lxml 、 zope.interface等第三方依赖库,但是不建议使用pycharm来安装scrapy,推荐使用anaconda(参考往期的文章)安装,避免遗漏第三方依赖库。
2. 架构图与数据流
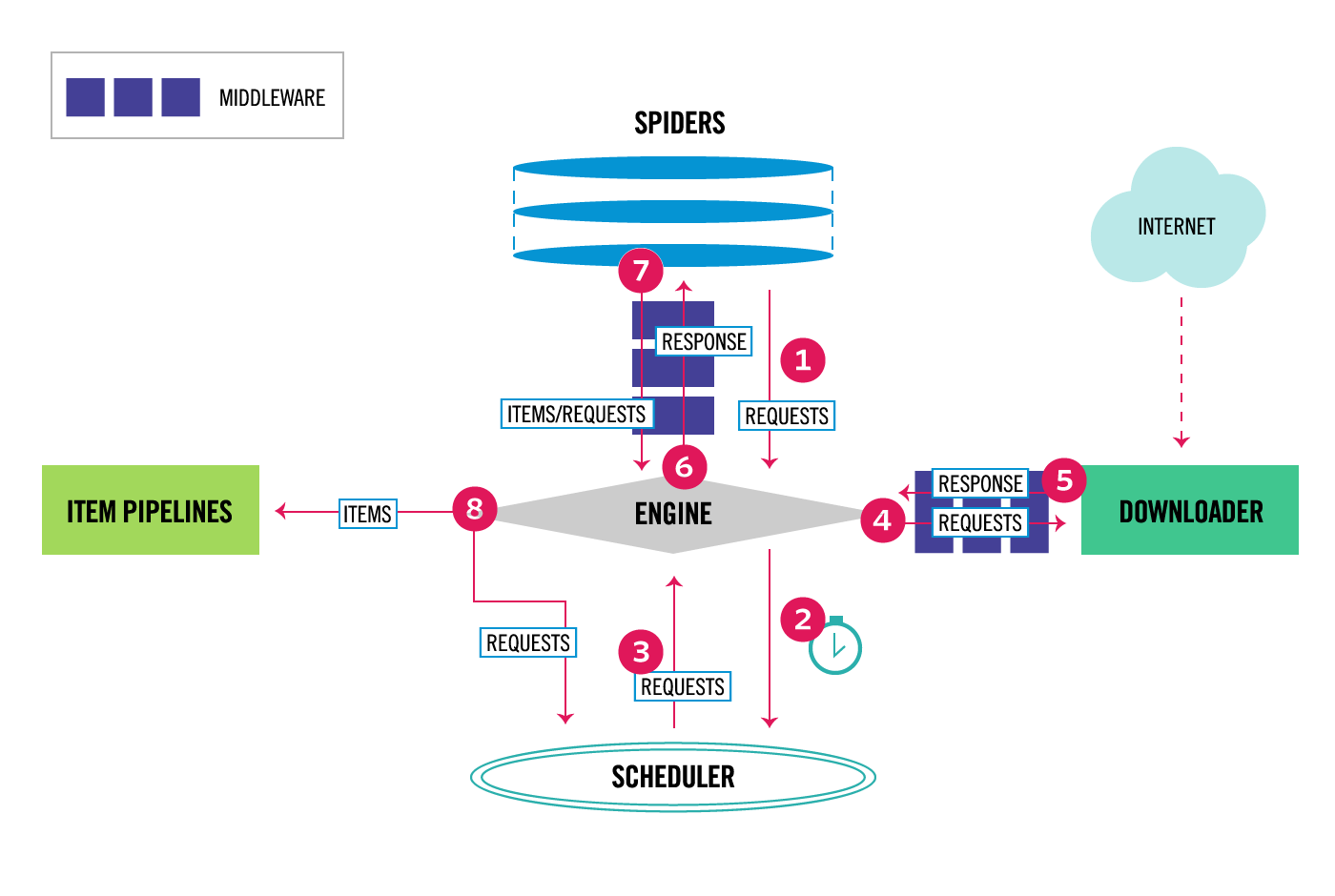
上图中各个数字与箭头代表数据的流动方向和流动顺序,具体执行流程如下:
0. Scrapy将会实例化一个Crawler对象,在Crawler中:
创建spider对象----_create_spider
创建engine对象----_create_engine
通过engine对象打开spider并生成第一个request---- yield self.engine.open_spider(self.spider, start_requests)
实例化调度器对象----Scheduler
启动引擎---- yield defer.maybeDeferred(self.engine.start)
1. 引擎从Spider获取初始请求
----_next_request
----_next_request_from_scheduler
2. 引擎把初始请求给调度器,并向调度器询问下一次请求
----scheduler.next_request
3. 调度器会对url进行指纹去重,如果是未爬取过的url,就把它放到队列中等待,并把下一个request返回给引擎
把url放入到队列中----enqueue_request
返回下一个request----next_request
4. 引擎把从调度器返回的request途径下载中间件交给下载器
----download
5. 一旦页面完成下载,下载器将会生成一个响应,途径下载中间件,再把它交给引擎
----download
6. 引擎接收到响应,并把它途径爬虫中间件,再交给spider
----_handle_downloader_output
7. spdier接收到响应,并对它进行解析,解析出Items或者新的Request,再把它们途径爬虫中间件,提交给引擎
----parse
8. 引擎把接收到的items提交给Item Pipeline,把接收到的Request提交给调度器
9. 从步骤1开始重复该过程,直到不在有request
3. 一些重要的命令
创建项目:scrapy startproject proname
进入项目:cd proname
创建爬虫:scrapy genspider spiname(爬虫名) xxx.com (爬取域)
创建规则爬虫:scrapy genspider -t crawl spiname(爬虫名) xxx.com (爬取域)
运行爬虫:scrapy crawl spiname (-o file.json)
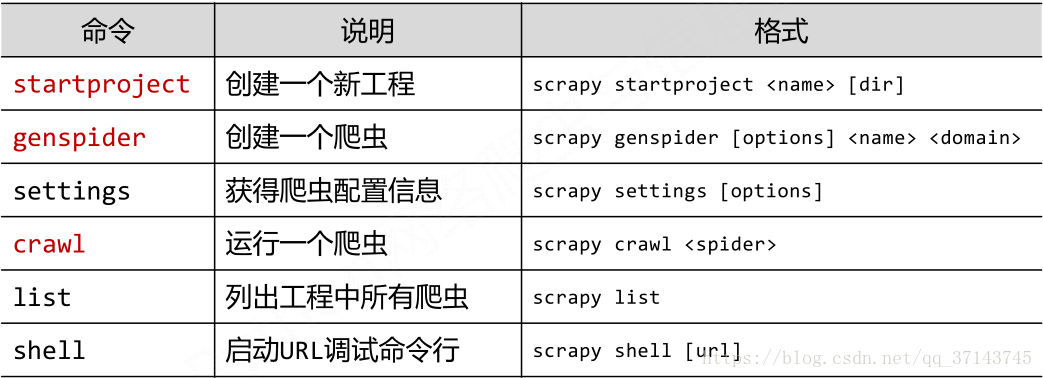
4. 开发Scrapy爬虫的步骤
- 创建项目:scrapy startproject proname(项目名字,不区分大小写)
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 设计数据库
- 存储内容 (pipelines.py):设计管道存储爬取内容
- 添加启动程序文件(start.py):等同于此命令(scrapy crawl xxx -o xxx.json),
from scrapy import cmdline cmdline.execute("scrapy crawl 项目名".split())
5. parse()方法的工作机制
- 因为使用的yield,而不是return。parse函数将会被当做一个生成器使用。scrapy会逐一获取parse方法中生成的结果,并判断该结果是一个什么样的类型;
- 如果是request则加入爬取队列,如果是item类型则使用pipeline处理,其他类型则返回错误信息;
- scrapy取到第一部分的request不会立马就去发送这个request,只是把这个request放到队列里,然后接着从生成器里获取;
- 取尽第一部分的request,然后再获取第二部分的item,取到item了,就会放到对应的pipeline里处理;
- parse()方法作为回调函数(callback)赋值给了Request,指定parse()方法来处理这些请求 scrapy.Request(url, callback=self.parse);
- Request对象经过调度,执行生成 scrapy.http.response()的响应对象,并送回给parse()方法,直到调度器中没有Request(递归的思路);
- 取尽之后,parse()工作结束,引擎再根据队列和pipelines中的内容去执行相应的操作;
- 程序在取得各个页面的items前,会先处理完之前所有的request队列里的请求,然后再提取items;
- 这一切的一切,Scrapy引擎和调度器将负责到底。
6. 下期预告
通过以上的学习,我们了解了scrapy的基本组件与整个spider的流程,下期我们新建一个spider,爬取第一个网页。

















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









