









Table of Contents
DeepDive是一种新型数据管理系统,能够从非结构化的文本中提取出结构化的数据,可以在单个系统中解决提取,集成和预测问题,使用户能够快速构建复杂的端到端数据管道,例如黑暗数据BI(商业智能)系统。通过允许用户端到端构建系统,DeepDive允许用户专注于系统中最能直接提高应用程序质量的部分。相比之下,以前基于流水线的系统要求开发人员构建提取器,集成代码和其他组件 - 而不清楚他们的更改如何提高其数据产品的质量。这种简单的洞察力是DeepDive系统如何在更短的时间内生成更高质量数据的关键。
通过DeepDive,可以提取实体间复杂的关系,并推断涉及这些实体的事实。
1.数据处理
1.1 加载原始输入数据
我们的第一个任务是下载巨潮资讯网提供的公告文章集的原始文本并将其加载到我们数据库的articles表格中。我们创建一个简单的shell脚本,以TSV格式下载和输出新闻文章。DeepDive将自动创建表,执行脚本并加载表,如果我们将其保存为:input/articles.tsv.sh
上述脚本读取语料库的样本(作为JSON对象的行提供),然后使用jq语言提取字段id(对于文档id)和content每个条目并将它们转换为TSV格式。
接下来,我们需要声明本架构articles表中我们的app.ddlog文件 ; 我们添加以下行:
articles(id text, content text)
1.2 添加自然语言标记
deepdive默认用standford nlp进行文本处理,可以返回句子的分词、lemma、POS、NER。
分词:首先是中文分词,在一句话中,我们要把词分出来,而不是光看单独的字。比如,“我 今天 很 高兴”。选择合适的字组成合适的词来构成句子
lemma:词元或者词性还原,这个是指这个词实质上的含义,比如cat,cats他们有相同词元。
pos:词性标注,最基本的是动词、名词等等
NER:Named Entity Recognition,可以识别出地名、人名、组织等等
1.3 抽取候选关系
前面都是通用的步骤,不论抽取什么样的关系,什么类型的实体,都要先对文章进行处理,分词、标记。但是到了这一步,我们就是要按照我们的任务去安排了。
既然我们要抽取公司间的交易信息,首先要得到文本中的公司是谁,才能进一步知道他们有没有关系,这一步就是要抽取这些公司啦。一共分两步:
- 抽取候选实体
- 得到实体间的候选关系
2.抽取候选关系
2.1 抽取候选实体
如何从这一堆文本里得到公司的名字。在nlp处理中有一个步骤是命名实体识别(NER),这个东西会把每个词的实体识别出来,比如公司名字就应是属于ORG类的实体。所以我们只要在每个sentence中找到其中的ner_tags 为连续的ORG标记的就可以了。
2.2 抽取候选关系
候选实体已经有了,就是文中出现的公司名,我们要找的是公司之间的交易关系。所以这里候选关系简单来说,就是把不同的公司名两两组合,最终得到的关系表其实就相当于对两个候选实体表进行笛卡尔积(当然,我们还需要一些简单的过滤的处理,比如两个公司名不能相同啊等等)了。
A:a1,a2,a3 B:b1,b2
A×B:(a1,b1),(a1,b2),(a2,b1),(a2,b2),(a3,b1),(a3,b2)
现在定义一个表来存储候选关系
transaction_candidate(
p1_id text,
p1_name text,
p2_id text,
p2_name text
).
2.3 特征提取
对于前面提取出来的公司间的候选关系,要使用机器学习的算法,通过训练集,让计算机去分类。根据特征判断哪个关系可能有交易关系,
对于自然语言来说,特征就是上下文。
所以定义一个特征表:
transaction_feature(
p1_id text,
p2_id text,
feature text
).
feature
————————————————————————————
WORD_SEQ_[郴州市 城市 建设 投资 发展 集团 有限 公司]
LEMMA_SEQ_[郴州市 城市 建设 投资 发展 集团 有限 公司]
NER_SEQ_[ORG ORG ORG ORG ORG ORG ORG ORG]
POS_SEQ_[NR NN NN NN NN NN JJ NN]
W_LEMMA_L_1_R_1_[为]_[提供]
W_NER_L_1_R_1_[O]_[O]
W_LEMMA_L_1_R_2_[为]_[提供 担保]
W_NER_L_1_R_2_[O]_[O O]
W_LEMMA_L_1_R_3_[为]_[提供 担保 公告]
W_NER_L_1_R_3_[O]_[O O O]
W_LEMMA_L_2_R_1_[公司 为]_[提供]
W_NER_L_2_R_1_[ORG O]_[O]
W_LEMMA_L_2_R_2_[公司 为]_[提供 担保]
W_NER_L_2_R_2_[ORG O]_[O O]
##下面最长的就是左2右3,或者左3右2的格式,最长是五个。
W_LEMMA_L_2_R_3_[公司 为]_[提供 担保 公告]
W_NER_L_2_R_3_[ORG O]_[O O O]
W_LEMMA_L_3_R_1_[有限 公司 为]_[提供]
W_NER_L_3_R_1_[ORG ORG O]_[O]
W_LEMMA_L_3_R_2_[有限 公司 为]_[提供 担保]
W_NER_L_3_R_2_[ORG ORG O]_[O O]
2.4 对关系样本加标签
对于监督学习,必然需要标注数据,那么已标注数据是怎么来的呢?当然正经的来说,应该是我们给这个系统提供大量的我们之前已经标注好了的数据,但是现在我们没有。所以我们可以对前面几步我们抽取出来的关系,利用一些先验的数据(比如人工标记的关系,还有先验的规则)对那些关系进行标记(标注出某些标记是已知的存在交易关系的,还有已知不存在交易关系的候选关系)。
所以对于这里来说,我们同样需要数据库中有一个表,来存储我们的被标记数据。在app.ddlog中定义一个表来存储关系的规则名和权重:
transaction_label(
p1_id text,
p2_id text,
label int,
rule_id text
).
其中rule_id代表在标记决定相关性的规则名称。label为正值表示正相关,负值表示负相关。绝对值越大,相关性越大。初始化定义,复制 transaction_candidate表到transaction_label中,label均定义为零。
3.模型构建
首先简单介绍一下关系抽取,关系抽取就是判断一个一句话中出现的两个实体是否存在某种已经定义好的关系。比如下面这个句子:
对于这样一次判断的过程,输入是句子+实体对。输出是夫妻关系这样一个类别。传统的关系抽取过程可以看成是对目标实体对和句子的一个多分类问题。
deepdive (http://deepdive.stanford.edu/) 是斯坦福大学开发的信息抽取系统,系统集成了文件分析、信息提取、信息整合、概率预测等功能。deepdive系统运行过程中包括一个重要的迭代环节。即每轮输出生成后,用户需要对运行结果进行错误分析,通过特征调整、更新知识库信息、修改规则等手段干预系统的学习,这样的交互与迭代计算能使得系统的输出不断得到改进。
首先来简单介绍一下deepdive的算法原理,主要分为以下3个内容:
- 因子图模型
- 吉布斯采样
- 权重学习
3.1 因子图概述
因子图是概率图模型的一种, DeepDive的概率推测(Probabilistic inference)就是在因子图上执行的。在因子图中,有两类节点,变量节点( Variables )和因子节点( Factor )。每一个变量节点表示一个特定事件发生的概率。比如我们可以将小明是否抽烟看成一个变量节点,如果他抽烟。则节点值为1,否则则节点取值为0。在deepdive中,所有的变量节点都是布尔类型的。因子节点表示一种一阶谓词逻辑和其对应的特定的权重w,定义了变量节点之间的关系。我们可以把他们看成一些关于变量节点的函数。
接下来看一个例子,构造如上所示的一个因子图:
变量节点(V):
v1:小明是否有癌症
v2:小明是否抽烟
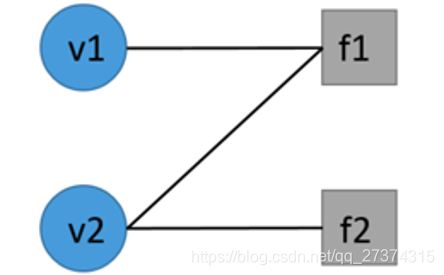
Variables:如果这种结点的值已知,它就可以当作一个证据变量(用来推断别的值);这个值也可以是未知的,这事就叫做查询变量,就是我们需要进行预测得到的值,比如图中的v1,v2;
Factor:每个因子都可以连接到多个变量,并用因子函数定义它们之间的关系,比如图中的f1,f2 ;每个因子(或者说因子函数)都有一个权重值,来表示这个因子影响力的大小。换个说法,这个权重值表示了某个因子的可信程度,正数越大则越正确,负数越小则越错误(错误表示某种不可能,比如一个人的亲儿子同时是他的亲兄弟,这就是一个错误,所以这个因子的权重就应该是一个很小的负值)。因子函数的权重可以通过训练学习得到,也可以手动赋值(通过脚本或者app.ddlog)。
因子节点(F,W):
定义:f1(v2, v1), w1:小明如果抽烟那么他有癌症
f2(v2), w2:我们认为小明是抽烟的
那么:f1(0,0) = 1, f1(0,1) =1, f1(1,0) = 0 , f1(1,1) = 1
f2(1) = 1, f2(0) = 0
概率计算:

3.2 DDlog概述
DDlog是一种更高级的语言,用于以简洁的Datalog类语法编写DeepDive应用程序。在这里,我们专注于描述在DeepDive应用程序中定义数据流的一般语言功能。
DDlog程序是声明和规则的集合。每个声明和规则都以句点(.)结尾。DDlog中的注释以hash(#)字符开头。
所有DDlog代码都应放在app.ddlog(DeepDive应用程序下命名的文件)中。
3.3 DDlog架构声明
首先,在app.ddlog中应声明在整个程序中定义和使用的关系的模式。这些关系映射到为DeepDive应用程序配置的数据库中的表。如下所示:
relation_name(
column1_name column1_type,
column2_name column2_type,
...
).与SQL表定义类似,模式声明只是关系的名称,后跟逗号分隔的列名列表及其类型。目前,DDlog将类型直接映射到SQL,因此可以使用底层数据库支持的任何类型,例如PostgreSQL的类型。
下面是一个现实的例子。
article(
id int,
length int,
author text,
words text[]
).
这里我们定义了一个名为“article”的关系,它有四列,分别命名为“id”,“length”,“author”和“words”。每列都有它自己的类型,在这里利用int,text和text[]。
3.4 DDlog正态推导规则
典型的类似数据目录的规则用于定义如何从其他关系派生关系。例如,以下规则规定关系的元组Q是从关系R和S派生的.
Q(x, y) :- R(x, y), S(y).
这里Q(x, y)是head原子,R(x, y)和S(y)是body原子。 X和y是规则中的变量。head是被定义的关系,body是谓词或条件的结合,它们用于绑定定义的变量,用逗号(,)分隔。在这个例子中,R的第二列是统一用的S第一列,即,主体是R和S之间相等联接关系。
3.5 DDlog布尔变量
变量关系的定义方法,就是在普通关系的关系名后面加上一个问号:?,就可以表示这个表是变量表,而不是用于加载或处理数据以供模型稍后使用的常规关系。变量关系的列用作关键字。以下是布尔变量关系的示例声明。
has_spouse?(
p1_id text,
p2_id text
).
这声明了一个名为变量的关系has_spouse,其中每个唯一的一对(p1_id, p2_id)代表模型中的一个不同的随机变量。
3.6 DDlog指定相关性
现在,在几乎每个问题中,变量都以特殊的方式相互关联,并且希望用这种领域知识来丰富模型。可以通过创建将多个相关变量连接在一起的某些类型的因子来建模这种相关性。这是FACTOR_HEAD中更丰富的语法发挥作用的地方。DDlog借用了Markov Logic Networks的大量语法,因此也使用了一阶逻辑。
例如,smoke示例中的以下规则关联两个变量关系。
@weight(3)
smoke(x) => cancer(x) :-
person(x).
这条规则表明,如果一个人抽烟,就会暗示他/她会患上癌症。这里,常量3用于@weight表示该规则的某种程度的置信度,而不是从数据中学习权重。
3.7 模型构建
(1) 我们最终想要得到的是什么。是判断某两家公司之间是否存在交易。就像前面的数据一样,我们的推理数据同样需要存储他们的数据表,因为他是算出来的,所以这些是变量,故DeepDive给它取了个名字:Variable Relation(变量关系)。
我们要求的是是否有交易,所以可以按照下边例子定义一个变量关系:
@extraction
has_transaction?(
p1_id text,
p2_id text).
这里的变量关系结合到因子图,应该是变量这一部分,变量即可以包含已知的知识,也可是未知的要抽取的知识,所以这个变量关系其实就是定义了因子图中的一部分变量节点,下一小部分就是填入因子和已知知识的过程。当然一个DeepDive项目中可以有很多种变量节点,构建一个复杂的因子图来实现更准确的抽取。
(2). 在前面部分已经对数据进行了简单的打标,也就是相当于机器学习任务中,我们有了已标记数据。把已经标记了的数据,输入到has_transaction表中,也就是可以得到因子图中的已知的变量节点。如下所示:
has_transaction(p1_id, p2_id) = if l > 0 then TRUE
else if l < 0 then FALSE
else NULL end :- transaction_label_resolved(p1_id, p2_id, l).
此时变量表中的部分变量label已知,成为了先验变量。
(3). 最后编译执行这个表,可以得到带有已知结果的变量节点:
deepdive compile && deepdive do has_transaction
4.因子图构建
4.1 指定特征
前面已经定义了因子图中的基本节点,下面应该定义其中的因子了,还有用来学习的特征。transaction_candidate这个表中,我们存储了所有候选的公司的匹配对,transaction_feature中存储了每个公司对之间的语言特征。现在我们告诉因子图,如何训练权重,就是根据我们之前抽取到的特征来训练。比如下面:
将每一对has_transaction中的实体对和特征表连接起来,通过特征的连接,全局学习这些特征的权重。在app.ddlog中定义:
@weight(f)
has_transaction(p1_id, p2_id) :-
transaction_candidate(p1_id, _, p2_id, _),
transaction_feature(p1_id, p2_id, f).
4.2 指定变量间的依赖性
定义一个简单的因子,指定变量间的依赖性,也是一个简单的推理规则:
在当前的工作中,甲公司和乙公司发生交易,那么必定乙公司和甲公司也发生了交易,交易是一个双向的关系,所以我们现在按照下面的例子来定义一个推理的因子,表示这种关系,其中weight中的3.0认为赋予这个规则的权重,不用学习。
@weight(3.0)
has_transaction(p1_id, p2_id) => has_transaction(p2_id, p1_id) :-
transaction_candidate(p1_id, _, p2_id, _).
变量表间的依赖性使得deepdive很好地支持了多关系下的抽取。
最后,编译,并生成最终的概率模型:
deepdive compile && deepdive do probabilities

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









