







 超级会员免费看
超级会员免费看
 本文探讨Flink的DataSet和DataStream的区别,强调DataStream API在实时计算中的广泛应用。详细介绍了DataStream的自定义数据源、Map、FlatMap、Filter、KeyBy、Aggregations和Reduce等操作,帮助理解其工作原理和用法。
本文探讨Flink的DataSet和DataStream的区别,强调DataStream API在实时计算中的广泛应用。详细介绍了DataStream的自定义数据源、Map、FlatMap、Filter、KeyBy、Aggregations和Reduce等操作,帮助理解其工作原理和用法。
现状
在前面的课程中,曾经提到过,Flink 很重要的一个特点是“流批一体”,然而事实上 Flink 并没有完全做到所谓的“流批一体”,即编写一套代码,可以同时支持流式计算场景和批量计算的场景。目前截止 1.10 版本依然采用了 DataSet 和 DataStream 两套 API 来适配不同的应用场景。
DataSet 和 DataStream 的区别和联系
在官网或者其他网站上,都可以找到目前 Flink 支持两套 API 和一些应用场景,但大都缺少了“为什么”这样的思考。
Apache Flink 在诞生之初的设计哲学是:用同一个引擎支持多种形式的计算,包括批处理、流处理和机器学习等。尤其是在流式计算方面,Flink 实现了计算引擎级别的流批一体。那么对于普通开发者而言,如果使用原生的 Flink ,直接的感受还是要编写两套代码。
整体架构如下图所示:
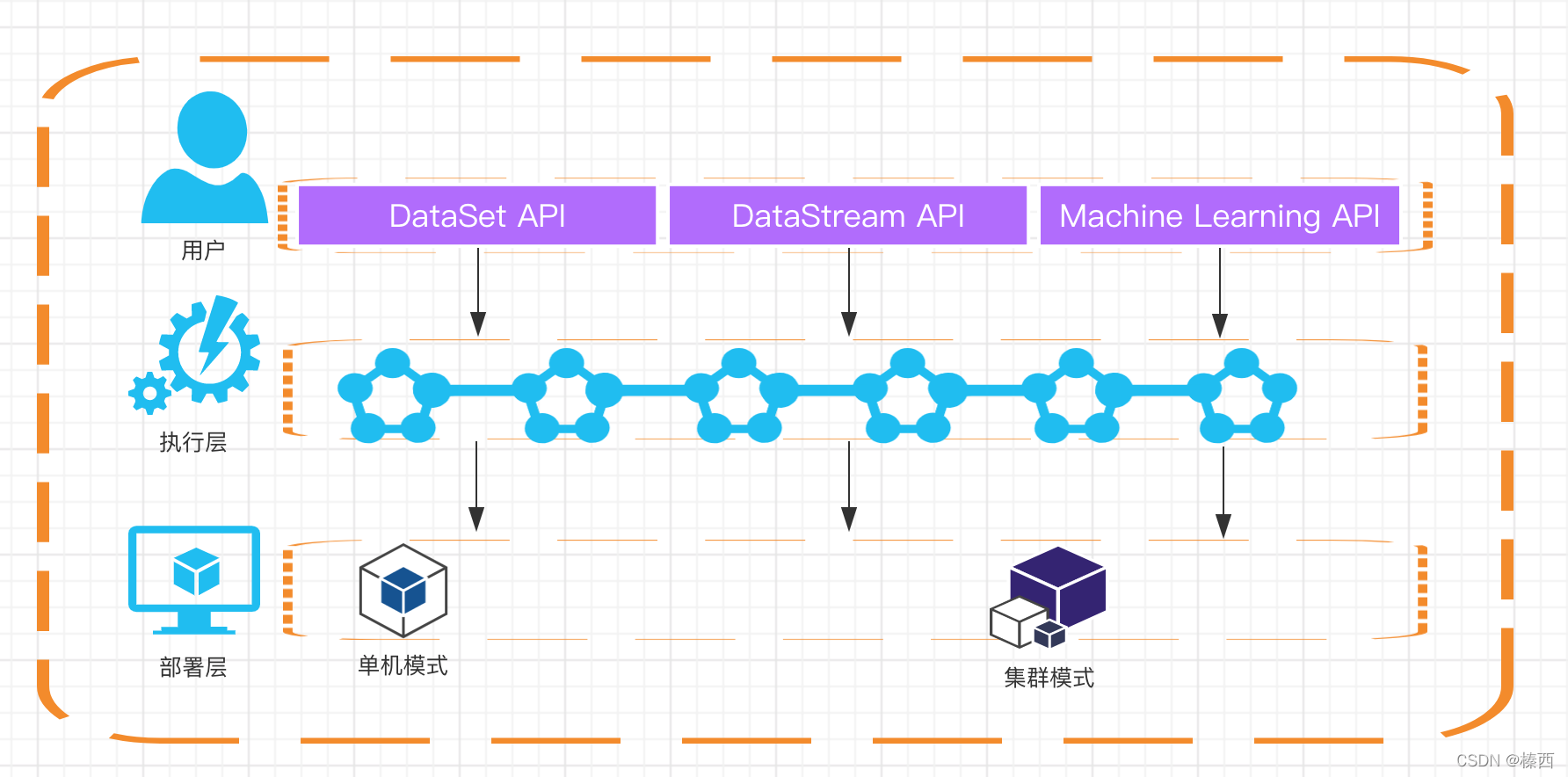
在 Flink 的源代码中,我们可以在 flink-java 这个模块中找到所有关于 DataSet 的核心类,DataStream 的核心实现类则在 flink-streaming-java 这个模块。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









