



目录
数据是深度学习的基础,高质量的数据输入将在整个深度神经网络中起到积极作用。MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。其中Dataset是Pipeline的起始,用于加载原始数据。mindspore.dataset提供了内置的文本、图像、音频等数据集加载接口,并提供了自定义数据集加载接口。
数据集加载
mindspore.dataset提供的接口仅支持解压后的数据文件,因此使用download库下载数据集并解压。
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
压缩文件删除后,直接加载,可以看到其数据类型为MnistDataset。
train_dataset = MnistDataset("MNIST_Data/train", shuffle=False)
print(type(train_dataset))
数据集迭代
数据集加载后,一般以迭代方式获取数据,然后送入神经网络中进行训练。
下面定义一个可视化函数,迭代9张图片进行展示。
def visualize(dataset):
figure = plt.figure(figsize=(4, 4))
cols, rows = 3, 3
plt.subplots_adjust(wspace=0.5, hspace=0.5)
for idx, (image, label) in enumerate(dataset.create_tuple_iterator()):
figure.add_subplot(rows, cols, idx + 1)
plt.title(int(label))
plt.axis("off")
plt.imshow(image.asnumpy().squeeze(), cmap="gray")
if idx == cols * rows - 1:
break
plt.show()visualize(train_dataset)
数据集常用操作
Pipeline的设计理念使得数据集的常用操作采用dataset = dataset.operation()的异步执行方式,执行操作返回新的Dataset,此时不执行具体操作,而是在Pipeline中加入节点,最终进行迭代时,并行执行整个Pipeline。
shuffle
数据集随机shuffle可以消除数据排列造成的分布不均问题。
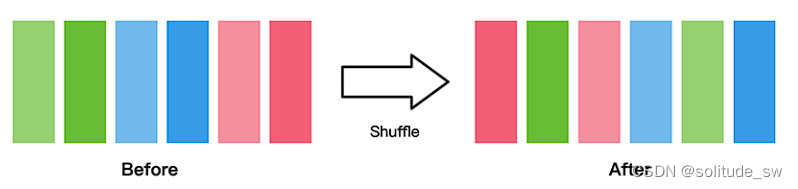
train_dataset = train_dataset.shuffle(buffer_size=64)
visualize(train_dataset) 
map
map操作是数据预处理的关键操作,可以针对数据集指定列(column)添加数据变换(Transforms),将数据变换应用于该列数据的每个元素,并返回包含变换后元素的新数据集
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)![]()
将图像统一除以255,数据类型由uint8转为了float32。
train_dataset = train_dataset.map(vision.Rescale(1.0 / 255.0, 0), input_columns='image')对比map前后的数据,可以看到数据类型变化。
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)batch
将数据集打包为固定大小的batch是在有限硬件资源下使用梯度下降进行模型优化的折中方法,可以保证梯度下降的随机性和优化计算量。
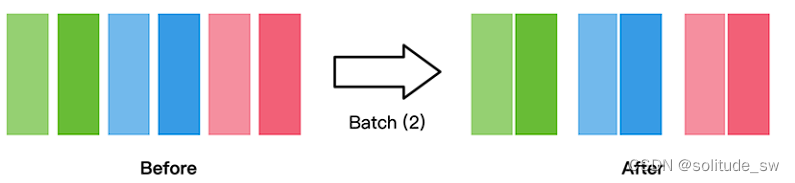
一般我们会设置一个固定的batch size,将连续的数据分为若干批(batch)。
train_dataset = train_dataset.batch(batch_size=32) batch后的数据增加一维,大小为batch_size。
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype) 
自定义数据集
mindspore.dataset模块提供了一些常用的公开数据集和标准格式数据集的加载API。
可以构造自定义数据加载类或自定义数据集生成函数的方式来生成数据集,然后通过GeneratorDataset接口实现自定义方式的数据集加载。
可随机访问数据集
可随机访问数据集是实现了__getitem__和__len__方法的数据集,表示可以通过索引/键直接访问对应位置的数据样本。
# Random-accessible object as input source
class RandomAccessDataset:
def __init__(self):
self._data = np.ones((5, 2))
self._label = np.zeros((5, 1))
def __getitem__(self, index):
return self._data[index], self._label[index]
def __len__(self):
return len(self._data)
loader = RandomAccessDataset()
dataset = GeneratorDataset(source=loader, column_names=["data", "label"])
for data in dataset:
print(data)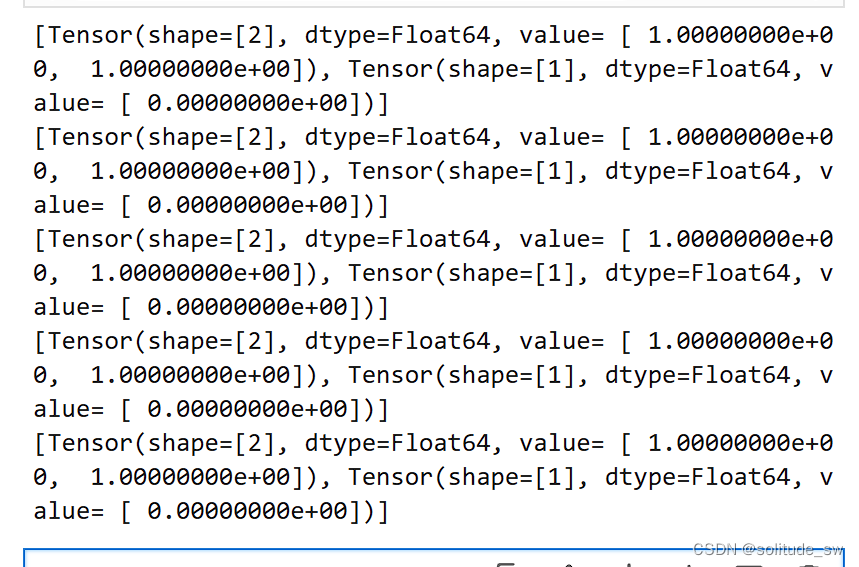
# list, tuple are also supported.
loader = [np.array(0), np.array(1), np.array(2)]
dataset = GeneratorDataset(source=loader, column_names=["data"])
for data in dataset:
print(data)
可迭代数据集
可迭代的数据集是实现了__iter__和__next__方法的数据集,表示可以通过迭代的方式逐步获取数据样本。这种类型的数据集特别适用于随机访问成本太高或者不可行的情况。
# Iterator as input source
class IterableDataset():
def __init__(self, start, end):
'''init the class object to hold the data'''
self.start = start
self.end = end
def __next__(self):
'''iter one data and return'''
return next(self.data)
def __iter__(self):
'''reset the iter'''
self.data = iter(range(self.start, self.end))
return self
loader = IterableDataset(1, 5)
dataset = GeneratorDataset(source=loader, column_names=["data"])
for d in dataset:
print(d)
生成器
生成器也属于可迭代的数据集类型,其直接依赖Python的生成器类型generator返回数据,直至生成器抛出StopIteration异常。
# Generator
def my_generator(start, end):
for i in range(start, end):
yield i
# since a generator instance can be only iterated once, we need to wrap it by lambda to generate multiple instances
dataset = GeneratorDataset(source=lambda: my_generator(3, 6), column_names=["data"])
for d in dataset:
print(d)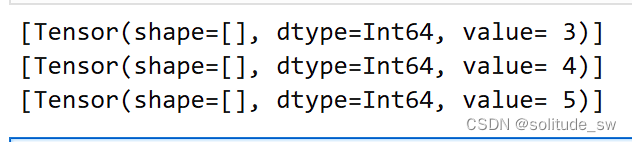
时间打卡
学习心得
在第三天的内容中,学习了MindSpore的数据处理功能,使用Pipeline数据引擎进行高效的数据预处理。了解到了数据集加载、数据迭代、数据变换以及自定义数据集等多个方面的知识。
在数据集迭代内容中,通过可视化函数清晰的展示迭代后数据,留下较深的印象为理解数据集迭代很有帮助。
其后提供三种数据集常用操作
- Shuffle:随机打乱数据集以消除数据排列造成的分布不均问题,这对于模型的泛化能力有重要影响。
- Map:这是数据预处理的关键操作,通过对数据集的特定列应用变换,可以高效地进行数据预处理。例如,将图像数据进行归一化处理。
- Batch:通过设置固定的batch size,可以在有限的硬件资源下有效地进行模型优化。
并展示了如何自定义数据集。
学习内容层层递进,在学习完今天的内容对数据集有了跟好的了解。

















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









