







1、集成学习模型简介
1.1、什么是集成学习
集成学习的思想,是通过建立几个模型组合,来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单一单分类作出预测(俗话说“三个臭皮匠,顶个诸葛亮”)。
1.2、什么是随机森林
随机森林是一种强大的机器学习算法,它通过构建大量的决策树并进行“投票”或“平均”来做出预测,其结果通常比单棵决策树更准确、更稳定。
2、集成学习经典的常见算法
集成学习模型使用一系列弱学习器进行学习,通过对各个弱学习器的结果进行整合,从而获得比单个学习器更好的学习效果(强学习器)。
集成学习模型的常见算法,主要有Bagging算法和Boosting算法两类。
2.1、Bagging算法
Bagging算法的原理类似投票,每个弱学习器都有一票,最终根据所有弱学习器的投票,按“少数服从多数”的原则产生最终的预测结果。以下是通过自助采样(Bootstrap Sampling)生成多个数据子集,并行训练多个学习器,最终投票或平均过程。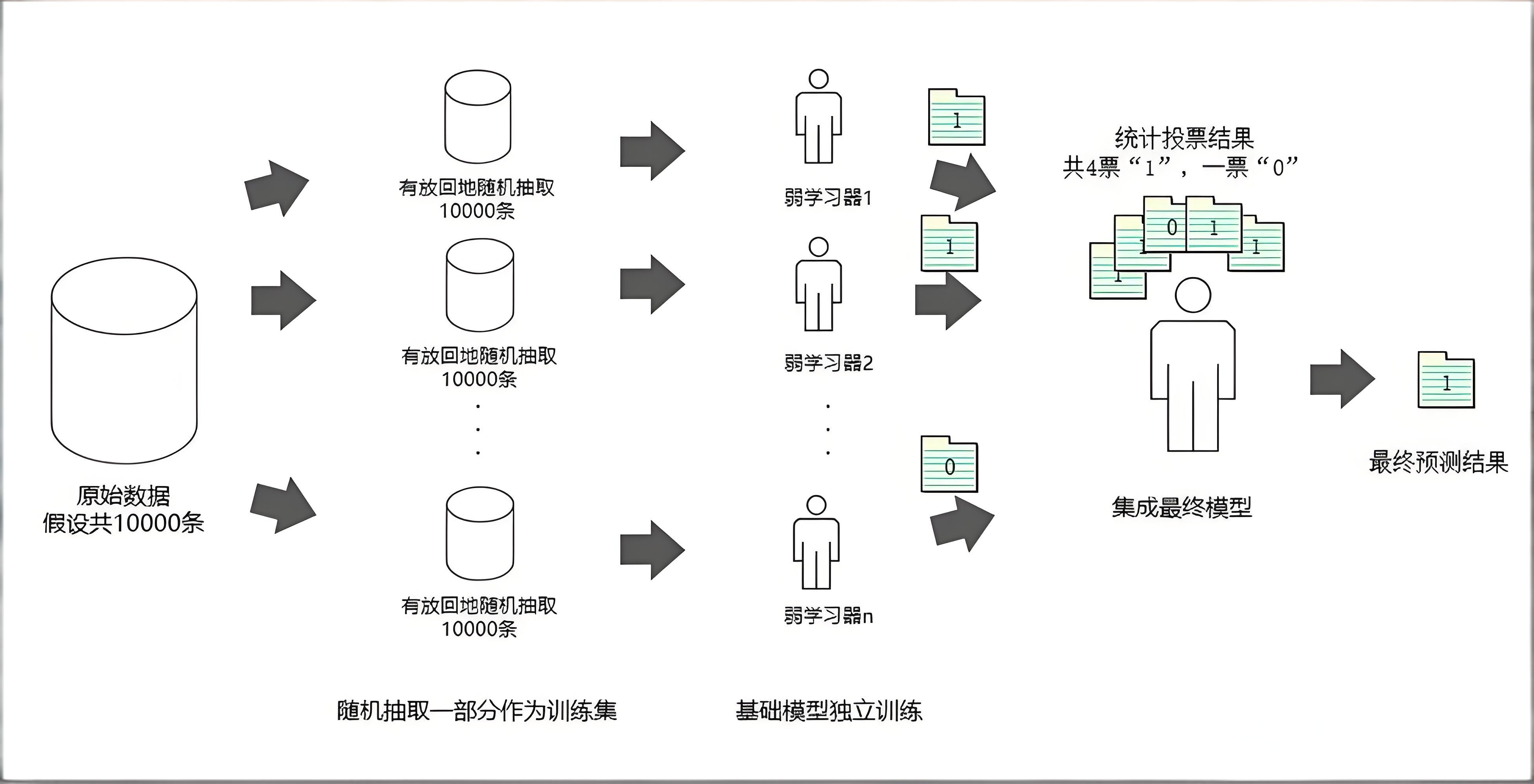
特点:降低方差,适合高方差模型(如决策树);适合数据不一样,模型一样。
2.2、Boosting算法
Boosting算法的本质,是将弱学习器提升为强学习器。Boosting算法则会对弱学习器“区别对待”,它会对预测准确的弱学习器给予较大的权重,同时提高对预测错误数据的重视程度。它的思想迭代训练基学习器,每次调整样本权重和模型权重,关注前一轮的误差。
| 特性 | Bagging (Bootstrap Aggregating) | Boosting |
|---|---|---|
| 核心思想 | 通过并行训练多个基学习器,然后平均或投票来减少方差 | 通过顺序训练多个基学习器,每个都尝试纠正前一个的错误来减少偏差 |
| 训练方式 | 并行训练,各模型相互独立 | 顺序训练,每个模型依赖于前一个模型的表现 |
| 数据使用 | 使用自助采样法(Bootstrap),每个模型看到不同的数据子集 | 每个模型都使用全部数据,但关注被前一个模型错误分类的样本 |
| 样本权重 | 所有样本权重相等 | 错误分类的样本权重会增加 |
| 模型权重 | 所有基学习器权重相等 | 表现更好的基学习器获得更高权重 |
| 主要目标 | 减少方差,防止过拟合 | 减少偏差,提高准确性 |
| 典型算法 | 随机森林(Random Forest) | AdaBoost, Gradient Boosting, XGBoost, LightGBM, CatBoost |
3、随机森林模型介绍
随机森林(Random Forest,简称RF)是一种决策树模型的Bagging优化版本。
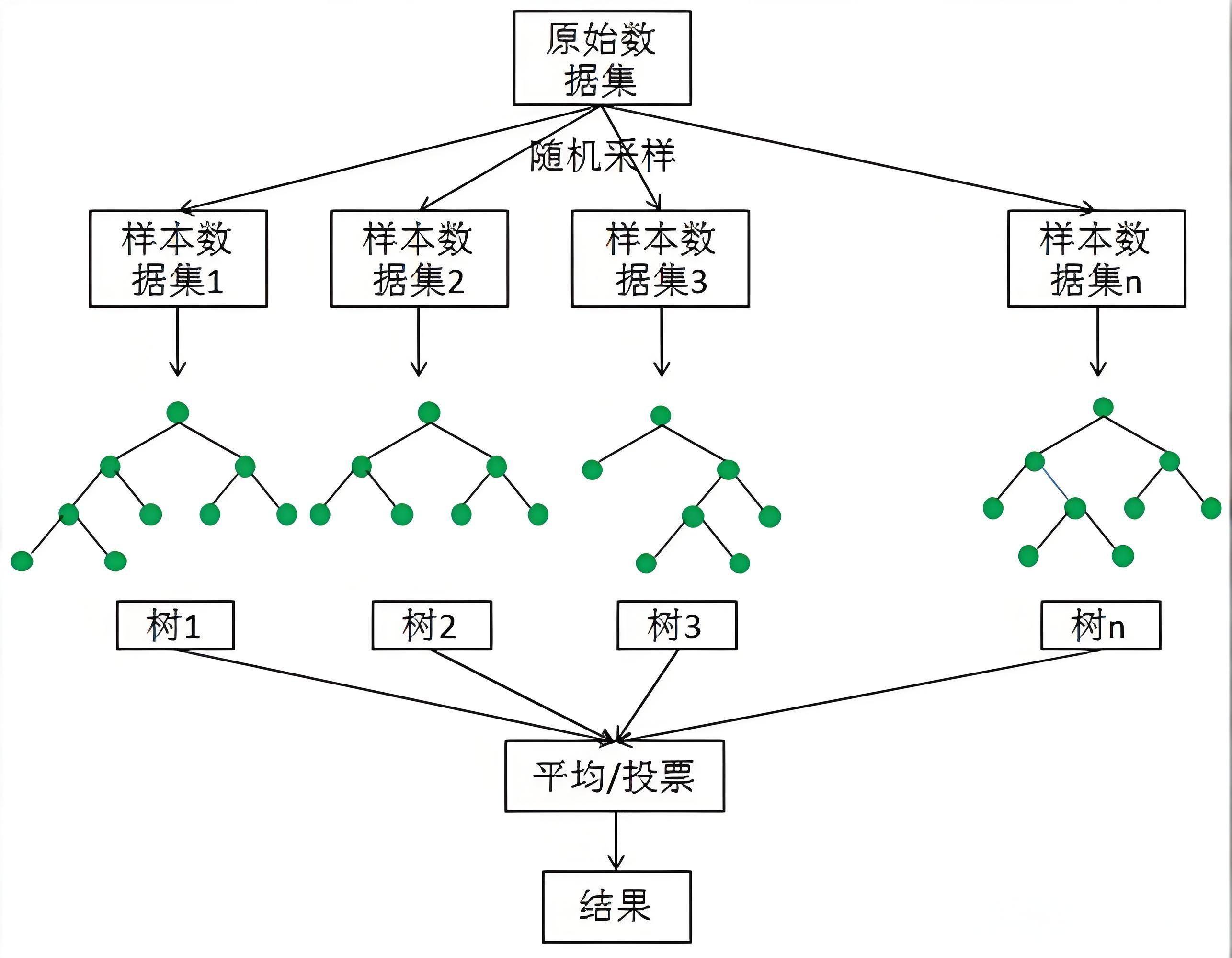
随机森林模型的实现原理如下:
- 在原始数据集中随机抽样,构成n个不同的样本数据集
- 根据这些数据集,搭建n个不同的决策树模型
- 根据决策树模型的平均值(针对回归模型)或投票情况(针对分类模型),获取最终的结果。
为了保证模型的泛化能力(是指由该算法构建的模型,对未知数据的预测能力),随机森林在建立每棵树时,往往会遵循两个基本原则:
- 数据随机:行级采样,从所有数据当中,有放回地随机抽取数据,作为其中一个决策树模型的训练数据。
- 特征随机:列级采样,指定一个常数k,随机从每个样本的特征维度M中,选取k个特征(k<M),在使用Python构造随机森林模型时,默认选取特征的个数k为√M。
4、随机森林使用
随机森林模型既能进行分类分析,又能进行回归分析。
4.1、分类任务 (Classification)
当你的目标变量是离散的类别(如“是/否”、“猫/狗/鸟”)时,使用RandomForestClassifier。
# 分类模型
from sklearn.ensemble import RandomForestclassifier
# 初始化随机森林分类模型
# n_estimators: 森林中决策树的数量
# random_state: 随机种子,用于确保每次运行的结果一致,便于复现
model = RandomForestClassifier(n_estimators=10, random_state=123)
model.fit(X, y)
4.2、回归任务 (Regression)
当你的目标变量是连续的数值(如房价、温度、销售额)时,使用RandomForestRegressor。
# 回归模型
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=10, random_state=123)
model.fit(X, y)
参数n_estimators,对应设置的弱学习器(决策树模型)的数量。
4.3、核心参数解析
在初始化模型时,调整参数是优化性能的关键。以下是两个最常用且重要的参数,以及其他几个关键参数:
-
n_estimators(弱学习器数量)-
定义:森林中决策树的数量。
-
作用:树的数量越多,模型的性能通常越稳定,越不容易过拟合。但与此同时,计算成本和训练时间也会增加。
-
建议:初始值可以设置为100。在实践中,可以通过交叉验证在100到500之间寻找一个最佳值。并不是越大越好,达到一定数量后性能提升会微乎其微。
-
-
random_state(随机种子)-
定义:控制模型训练过程中的随机性(如Bootstrap抽样和特征随机选择的随机数生成)。
-
作用:设置一个固定的值可以确保每次运行代码时,生成的模型和结果都是完全一致的,这对于重现实验结果是必不可少的。
-
-
max_depth(树的最大深度)-
定义:每棵决策树允许生长的最大深度。
-
作用:有效控制模型的复杂度,是防止过拟合最重要的参数之一。如果不设置(
None),树会一直生长直到所有叶子节点都是纯的,这极易导致过拟合。 -
建议:可以从
None开始,如果发现过拟合,再尝试设置一个较小的值(如5, 10, 15)进行限制。
-
-
min_samples_split(内部节点再划分所需最小样本数)-
定义:一个节点必须至少包含这么多样本,才会被允许继续分裂。
-
作用:另一个防止过拟合的有效手段。值越大,树生长得越保守,越不容易捕捉到数据的局部细节(噪声)。
-
建议:默认值为2。如果样本量非常大,可以增加这个值(如5, 10)。
-
5、经典案例
经典的鸢尾花案例,我们可以通过随机森林分类分析。
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
# 1.加载鸢尾花数据集
iris=load_iris()
X= iris.data
y=iris.target
print(type(X)
print(type(y)
print(X)
# 2.划分测试集和训练集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 3.创建随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=200,
max_depth=10,
min_samples_split=5,
random_state=123)
# 4.训练模型
rf_classifier.fit(X_train, y_train)
# 5.模型预测
y_pred = rf_classifier.predict(X_test)
# 6.评估模型性能
accuracy = accuracy_score(y_test, y_pred)print(f'Accuracy: {accuracy:.3f}')
# 7.输出详细分类报告
report = classification_report(y_test, y_pred)print('Classification Report:\n', report)



















 2228
2228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











