 深入理解Embedding:原理与代码实践
深入理解Embedding:原理与代码实践





今天我们要聊一个AI领域的关键技术——Embedding(嵌入)。不要被术语吓到,接下来我会用最直观的方式,配合代码示例,让你彻底明白它是什么!
什么是Embedding?
简单来说,Embedding就是把文字、图片或其他数据转换成数字的形式,让计算机能够理解和处理。就像我们给每个单词分配一个「数字身份证」,但这个身份证不是简单的编号,而是包含丰富信息的「多维特征向量」。
先举一个生动的栗子
想象一下,我们要给世界上所有食物编码:
汉堡:[-0.2, 0.8, 0.3]
沙拉:[0.5, -0.3, 0.1]
冰淇淋:[0.1, 0.9, -0.4]
数字的正负和大小代表了食物的特征(如甜度、健康程度、温度)。这样计算机就能通过数字计算发现「汉堡和冰淇淋都是高热量食物」。
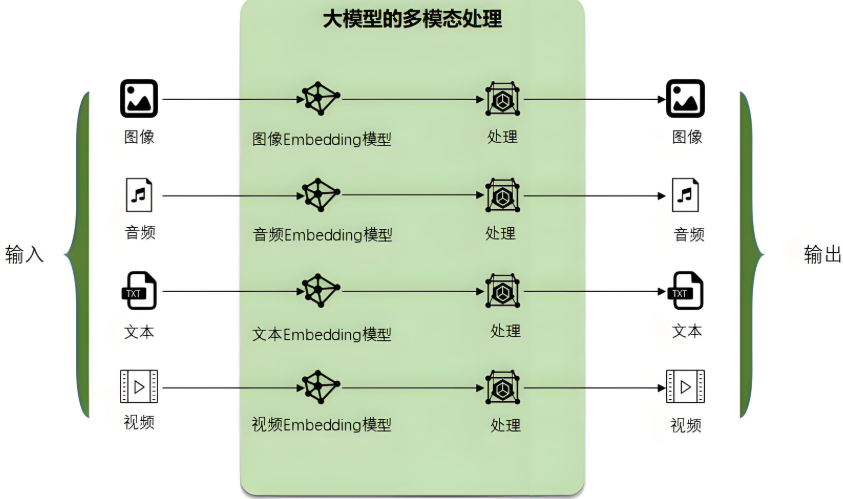
Embedding就是大模型自己的语言,任何需要跟大模型沟通的文字、图像、视频都需要转换为大模型所能理解的语言:Embedding,它才能处理。处理完成后,它再翻译成人类能理解的文字、图像等。这也是大模型最强大的核心能力之一,多模态处理能力。
重点:代码实战
好,接下来直接上代码,看Embedding如何工作
# 导入必要的库
from sentence_transformers import SentenceTransformer
# 加载模型
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
# 定义句子列表
sentences = [
'我喜欢吃苹果',
'苹果公司9月要发布新手机iPhone 17',
'今天的天气真好,蓝天白云',
"香蕉是一种热带水果"
]
# 生成Embedding向量
embeddings = model.encode(sentences)
print("生成的Embedding的向量维度:", embeddings.shape)
# 输出全部
# print("Embedding向量的具体内容:", embeddings)
# 输出上面句子的向量前10维
for i, sentence in enumerate(sentences):
print(f"'{sentence}': {embeddings[i][:10]} ...")
# 计算句子间的相似度
from sklearn.metrics.pairwise import cosine_similarity
# 计算余弦相似度
similarities = cosine_similarity(embeddings)
print("句子相似度矩阵:")
for i in range(len(sentences)):
for j in range(len(sentences)):
if i <= j: # 避免重复输出
sim = similarities[i][j]
print(f"'{sentences[i]}' vs '{sentences[j]}': {sim:.3f}")
输出如下:
生成的Embedding的向量维度: (4, 384)
'我 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1623
1623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











