



导读
在机器人研究中,如何让“看到的”顺利转化为“做到的”,一直是一个难题。虽然近年来的视觉语言模型(VLM)和视觉语言动作模型(VLA)大幅提升了机器人理解场景与指令的能力,但当机器人真正要操作物体时,性能常常大打折扣,这就是研究者口中的 seeing-to-doing gap。
来自天津大学的团队提出了 Embodied-R1,一个专为机器人推理与操作设计的 30 亿参数模型。它引入了一个非常直观的中间表示——“指点”(pointing),并围绕这一表示定义了四种关键能力:指代表达理解(REG)、空间区域指点(RRG)、功能部位指点(OFG)、视觉轨迹生成(VTG)。通过这种方式,模型能够把复杂的视觉语言理解转化为通用、可迁移的操作指令。
研究团队不仅构建了规模达 20 万样本的 Embodied-Points-200K 数据集,还设计了强化学习驱动的两阶段训练策略。最终,Embodied-R1 在 11 项空间推理与指点任务中取得了领先成绩,并在模拟和真实环境的机器人任务中展现出强大的零样本泛化能力:在 SIMPLEREnv 中成功率达到 56.2%,在 8 个真实任务中更是高达 87.5%。这一成果意味着,借助“指点”这种跨形态、跨任务的统一表达,机器人有望真正跨越从感知到行动的鸿沟。
论文标题:Embodied-R1: Reinforced Embodied Reasoningfor General Robotic Manipulation
论文作者:Yifu Yuan, Haiqin Cui, Yaoting Huang, Yibin Chen, Fei Ni, Zibin Dong, Pengyi Li Yan Zheng, Jianye Hao
项目主页:https://embodied-r1.github.io/
代码链接:https://github.com/pickxiguapi/Embodied-R1

近年来,视觉语言模型的崛起让机器人看懂世界的能力大幅提升,也带动了一批视觉语言动作模型的出现。这类模型不仅能理解画面和指令,还能输出动作,看似给机器人操作插上了“智慧的翅膀”。然而,真正落到执行时,问题就暴露出来了:在新环境里,它们的表现往往大幅下滑。研究者把这一现象称为 “从看见到做到的鸿沟”——机器人虽然能理解场景,却难以将理解转化为可靠的操作。
造成这一鸿沟的原因主要有两个:一是数据不足。现有的具身数据规模有限,很难支撑模型把语言、视觉和物理动作三者真正融合起来;二是机器人之间的差异。不同形态的机器人动作方式差别很大,导致知识迁移困难。
过去,学界尝试过几种路线。端到端方法直接把输入和动作硬绑在一起,但在现实世界里,这样的匹配存在天然缺陷,往往导致模型遗忘旧知识或在任务间产生冲突。模块化方法则把操作拆成若干步骤,用一系列专门模型来完成物体检测、抓取等任务,但链条过长容易出错,推理速度也慢,还缺少全局的空间理解。另一类是 可供性方法,通过预测中间的视觉辅助信号来指导机器人执行,但这些辅助往往不够全面,很难覆盖复杂任务的所有需求。
在这样的背景下,天津大学团队提出了一个新的切入点:“指点”。所谓指点,就是把复杂的操作指令,统一转化为图像上的一个或一串点。这种方式直观而灵活:它既能标出“要操作的物体”,也能指示“该怎么抓”“放在哪里”,甚至还能通过轨迹点序列来表达“操作的过程”。
基于这一思路,团队研发了 Embodied-R1。这个模型在生成答案前,会先给出完整的推理过程,再通过“指点”输出操作目标。凭借 30 亿参数的轻量规模,Embodied-R1 已经在多个空间理解和操作基准上取得了领先成绩,并且能直接把“指点”结果交给机器人,完成实际操作。相比直接预测动作,这种中间表示不仅保留了预训练模型强大的视觉泛化能力,也让模型能够在全新场景下实现真正的零样本控制。实验表明,Embodied-R1 在模拟环境中的成功率超过五成,在 8 个真实机器人任务中更是达到 87.5%,远超现有方法。同时,它在面对光照、背景等变化时依然保持了稳健表现。
为了实现这一突破,研究团队设计了 两阶段强化微调(RFT) 策略:第一阶段专注于空间推理,打好基础;第二阶段则利用他们自建的 Embodied-Points-200K 大规模数据集,系统训练模型的“指点”能力。值得一提的是,指点问题往往存在“多解”现象,比如“抽屉右侧”可能有很多合格点。有监督微调容易让模型死记硬背,而 RFT 则能为所有正确答案提供奖励,促使模型形成真正的理解。
最终,Embodied-R1 展现出强大的零样本泛化能力,也让我们看到了一个清晰的方向:用“指点”作为桥梁,打通从感知到决策,再到行动的全过程。
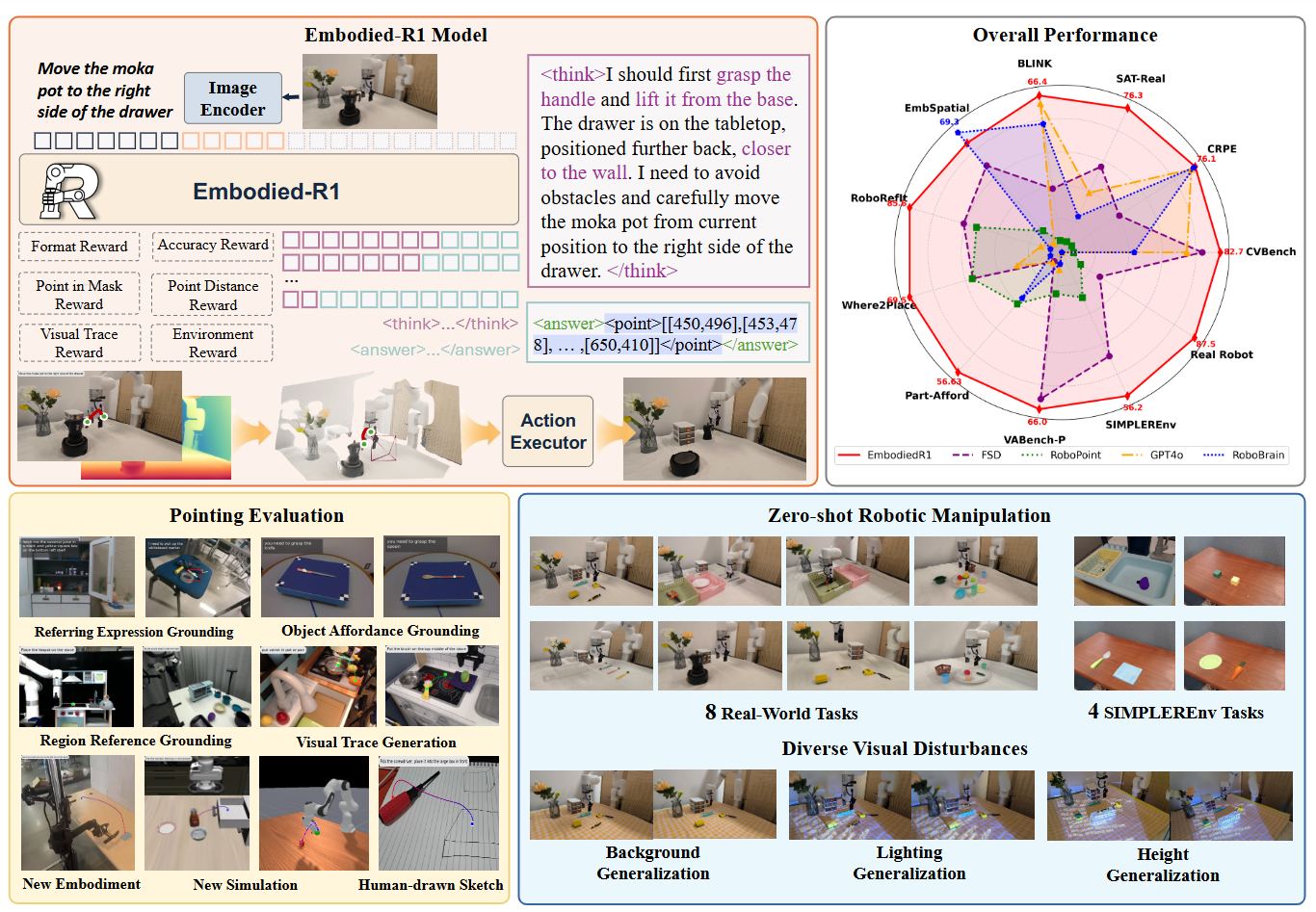
图1|Embodied-R1 接收视觉和文本指令,先进行显式推理,然后生成一条视觉轨迹,作为通用的操作指令。另一侧展示了我们全面的评估结果,包括空间推理、具身指点基准测试,以及真实机器人任务

模型架构与核心能力
Embodied-R1 的整体结构延续了大模型的经典框架,由视觉编码器、投影层和语言模型三部分组成。输入是一张图像和一条文本指令,模型最终会生成推理过程和答案。与传统视觉语言模型不同,Embodied-R1 专为机器人操作设计,重点在于增强空间推理和“指点”能力。
所谓“指点”,就是在图像上生成坐标点。这些点不是简单的像素,而是承载了任务语义。研究团队将其归纳为四种核心能力:
● 指代表达理解(REG):通过语言描述锁定目标物体,在物体区域内输出一个点。比如“把杯子拿起来”,模型会在图像中精确指向那个杯子。
● 空间区域指点(RRG):理解相对空间关系,输出合适的空白区域坐标,例如“放在碗和杯子之间”。
● 功能部位指点(OFG):识别物体的功能性部位,比如刀柄或杯把,生成落在这些区域的点,指导机器人抓取。
● 视觉轨迹生成(VTG):输出一系列有序点,形成一条轨迹,表达操作过程。例如“把勺子搅拌到碗的右侧”,模型会生成一条曲线轨迹。
这种以点为核心的表示方式,有两个好处:一是摆脱了具体机器人形态的限制,点本身对任何机器人都是通用的;二是既能用互联网大规模数据训练,也能与真实机器人数据结合,从而在新任务和新场景中保持泛化能力。

图2|四项Pointing任务图解
数据集与训练流程
为了培养这些能力,团队设计了一个三类数据组合:
● 空间推理数据:用来建立模型的空间感知基础,让它能理解“在……旁边”“在……上面”这类关系。
● 通用推理数据:避免在专门训练时遗忘已有知识,保证模型保留通用的推理能力。
● 具身指点数据:核心部分,涵盖了四大指点任务。
其中最重要的是团队自建的Embodied-Points-200K数据集,包含约 20 万条样本,覆盖物体定位、区域关系、功能部位和轨迹生成等场景。为了应对“多解”问题(比如“抽屉右侧”有多个正确点),他们没有采用传统的“问答式”数据,而是设计了“问题-验证”对,通过强化学习来给所有合理答案正向奖励。
具体来说:
● 在REG数据中,模型必须在物体分割区域内输出一个点,精确性远超边界框。
● 在RRG数据中,研究者通过大规模仿真与过滤,生成了数万条“物体相对摆放”的样本,让模型学会根据关系词指向正确位置。
● 在OFG数据中,提供了数万条功能性抓取点的标注,例如“刀的手柄应该被握住”。
● 在VTG数据中,利用关键点跟踪技术提取物体的运动轨迹,再将其投射到图像中,形成轨迹监督信号。
训练采用两阶段策略:
● 阶段一:集中强化空间推理能力,打好基础。
● 阶段二:在多任务混合数据上训练具身指点能力
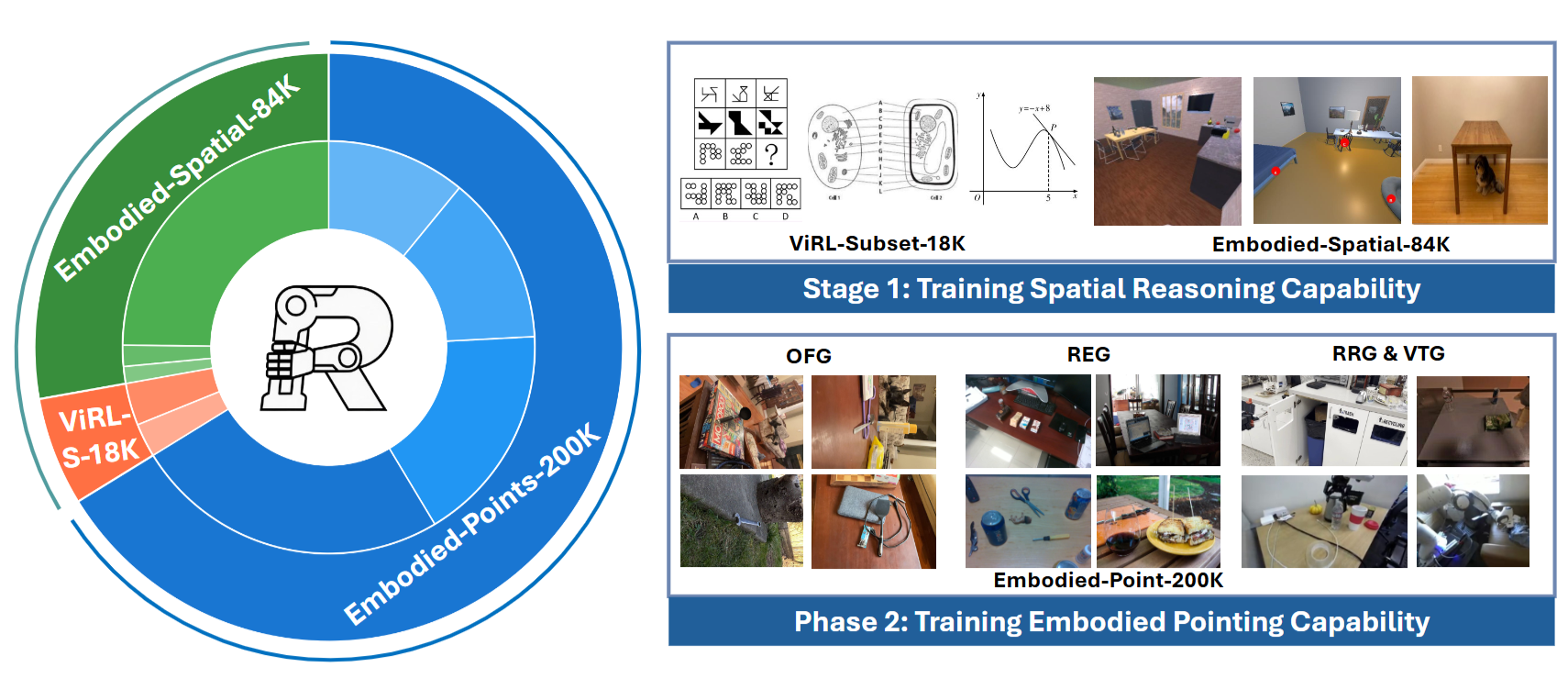
图3|训练数据概览: 在第一阶段,重点提升模型的空间推理能力,同时加入少量通用推理数据。第二阶段则训练模型的具身指点能力,涵盖四个不同的子能力
多任务奖励机制
强化学习中的奖励设计至关重要。为了让 Embodied-R1 在多任务环境中学得更稳健,团队设计了多维度的奖励函数:
● 格式奖励:确保输出遵循统一格式,例如 <point> 标签中必须包含标准坐标。
● 准确率奖励:判断答案是否与标准一致。
● 掩膜奖励:预测点是否落在正确区域。
● 距离奖励:预测点与目标区域中心的距离越近,奖励越高。
● 轨迹奖励:根据预测轨迹和真实轨迹的相似度来打分。
● 环境奖励:在模拟器中直接执行预测,如果任务完成就加分。
小编觉得,这种奖励组合就像是一套评分体系,每个任务都有不同的“考核标准”,通过权重分配来平衡训练过程。例如在“区域指点”任务中,模型必须同时满足格式、区域正确性和距离接近度,才能获得高分。
任务执行方案
最后,Embodied-R1 需要把“指点”结果转化为真实机器人的动作。研究者提出了两条分支:
● 可供性点分支:通过 REG、RRG 和 OFG 得到关键抓取点或放置点,再结合运动规划器生成无碰撞路径,指导机械臂完成操作。
● 轨迹分支:利用 VTG 生成的轨迹点,把二维点映射到三维坐标,插值生成连续轨迹,直接让机器人跟随执行。
这意味着 Embodied-R1 不仅能回答“抓哪里”“放哪里”,还能直接给出“怎么做”的全过程。

为了验证 Embodied-R1 在机器人操作中的泛化能力,研究团队从“看”(空间推理与指点能力)和“做”(真实操作任务)两个维度进行了全面评估。实验覆盖了11 个空间推理基准、4 个仿真操作任务(SIMPLEREnv)以及 8 个真实机器人任务(xArm 平台)
空间推理能力
研究者首先在 5 个常用的空间推理基准上测试 Embodied-R1。结果显示:
● Embodied-R1 在所有开源模型中表现最佳,平均排名 2.1;
● 加入常识数据后,性能进一步提升;
● 相比单纯的监督微调(SFT)模型,采用强化微调(RFT)的 Embodied-R1 明显更强。
小编认为,这说明 Embodied-R1 不仅具备空间理解能力,还能通过合理的数据与奖励机制,激发更强的“探索式推理”能力
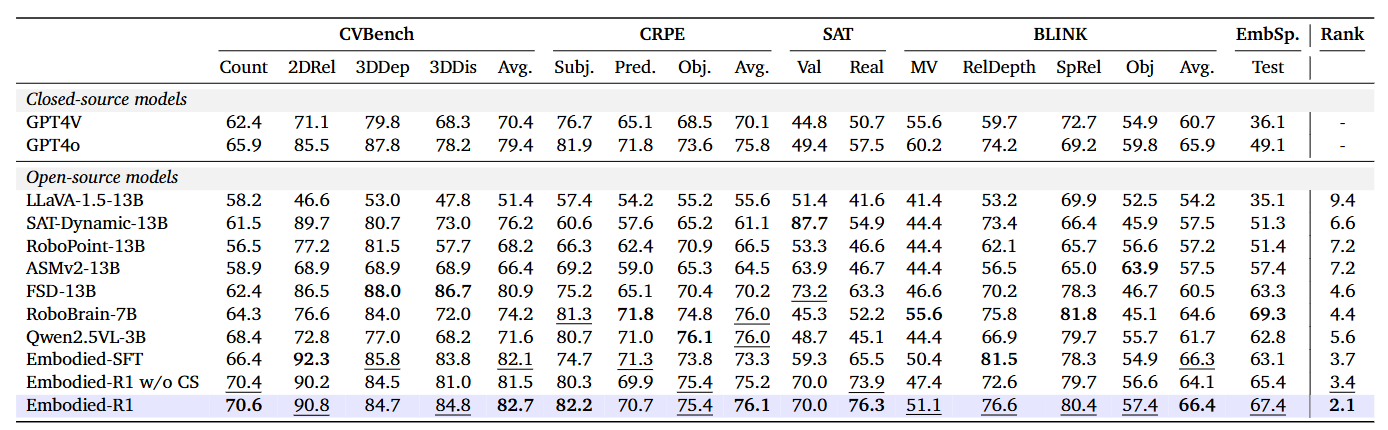
图4|在推理数据集上的数值定量实验结果
Pointing任务能力
在四大能力(REG、RRG、OFG、VTG)上,Embodied-R1 同样展现出优势:
● 物体定位(REG):在 RoboRefIt 数据集上大幅领先,尤其在相似物体混杂场景下准确率更高。
● 区域指点(RRG):在 Where2Place 和 VABench-P 上表现优异,能准确理解“放在 A 和 B 之间”这类复杂空间关系。
● 功能部位指点(OFG):在 Part-Afford 基准中取得最优结果,能正确识别刀柄、杯把等操作部位。
● 轨迹生成(VTG):在 VABench-V 上获得最低误差,生成的轨迹序列更精确、更贴近实际操作需求。
此外,团队还测试了RGB-D 输入的版本,结果显示在三维空间定位中表现突出,说明多模态输入对机器人任务有额外帮助。
小编总结:在各种复杂场景下,Embodied-R1 不仅能“指对物”,还能“指得准、指得细”,甚至能画出可靠的“行动轨迹”
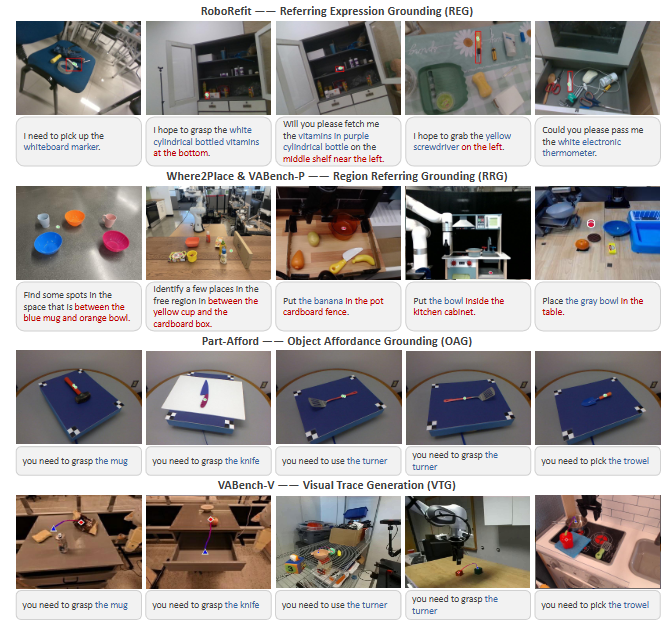
图5|Embodied-R1在不同的pointing任务上表现可视化
仿真与真实机器人实验
在SIMPLEREnv 仿真环境中,Embodied-R1 的平均成功率达到 56.2%,超过了端到端、模块化和可供性 VLA 方法。更重要的是,它不需要额外微调,就能实现零样本部署。
在8个真实机器人任务(xArm 平台)中,Embodied-R1 的零样本成功率达到 87.5%,比现有方法提升超过 60%。在需要空间推理或抓取难度较大的任务中(如操作螺丝刀、摩卡壶),Embodied-R1 的表现尤为突出。
研究者还在任务中加入光照变化、背景干扰等挑战,结果显示Embodied-R1几乎不受影响,依然能稳定完成任务。这证明“指点”这种中间表示,确实增强了机器人策略的鲁棒性。
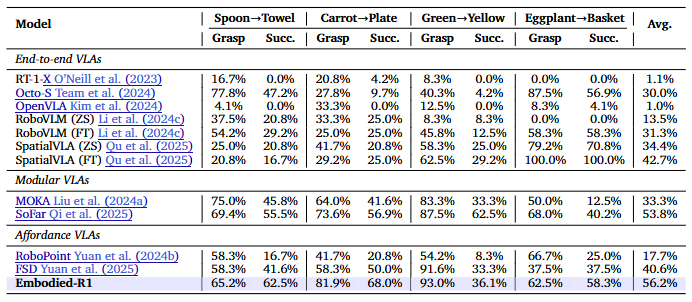
图6|SIMPLEREnv仿真平台实验结果


图7|真实机器人实验结果(展示前5个任务的可视化及综合的定量实验数据)
消融实验与进一步分析
团队还进行了几项关键分析:
● RFT vs SFT:结合推理链的强化学习(RL w/ Think)效果最好,直接输出答案的版本反而性能下降。这说明强化学习+推理机制的组合是提升泛化的关键。
● 混合训练的优势:在第二阶段同时训练多种指点任务,比单任务训练表现更佳。混合训练促进了语义空间和坐标空间的知识共享,从而增强了整体泛化能力。
小编认为,这些消融结果验证了 Embodied-R1 的核心理念:通过强化推理和多任务共享,模型才能真正学会“举一反三”,而不是死记硬背
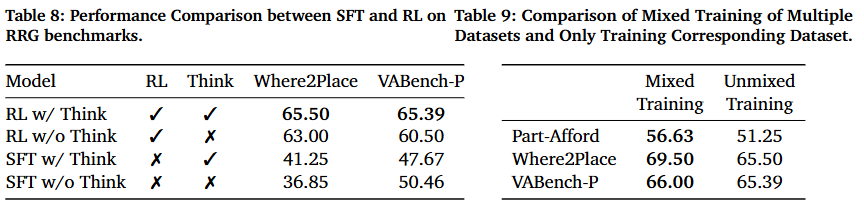
图8|Table8展示了RFT vs SFT的对比效果;Table 9 展示了消融混合训练模块的对比结果

从实验结果可以看到,Embodied-R1 并不仅仅是“性能更高一点”的模型,而是提出了一种全新的思路:用“指点”作为桥梁,把感知和行动真正连接起来。它既能理解复杂的空间关系,又能生成精确的抓取点和操作轨迹,在真实机器人任务中实现了前所未有的零样本成功率。小编认为,这种思路最大的意义在于,它不依赖具体的机器人形态,而是提供了一种通用的中间表示,让机器人从“看懂”到“做到”更进一步。未来,随着更多真实数据的补充,这种“点式推理”或许会成为机器人操作的标配能力。


















 1785
1785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









