



导读让机器人“听得懂、想得清、动得准”,一直是具身智能研究的重要目标。然而,许多现有的视觉-语言-动作模型(VLA)在提升操作能力时,往往牺牲了原有的语言理解和推理能力,导致泛化性变差、适应能力下降。为了解决这个问题,InstructVLA 提出了一种新范式:在保留大模型强大语言推理能力的同时,用指令微调方式训练机器人完成复杂操作。这一方法构建了 65 万条人机交互数据,统一优化语言生成与动作规划,让模型既能“对话”,又能“动手”。实验表明,它在多个任务中大幅超越现有模型,甚至超过了结合 GPT-4o 的专家模型,展现出强大的理解力与可控性。InstructVLA 的出现,为通用机器人打开了一条从“理解人话”到“动手做事”的新路径。
论文出处:arXiv
论文标题:Vision-Language-Action Instruction Tuning:From Understanding to Manipulation
论文作者:Shuai Yang, Hao Li, Yilun Chen, Bin Wang, Yang Tian, Tai Wang, Hanqing Wang, Feng Zhao, Yiyi Liao, Jiangmiao Pang

近年来,大模型在计算机视觉和自然语言处理领域取得了显著进展,受此启发,越来越多的视觉-语言-动作(Vision-Language-Action, VLA)模型开始以大规模预训练的视觉-语言模型(VLM)为基础,在大规模具身交互数据上进行训练,从而提升在机器人操作任务中的泛化能力。
尽管这些 VLA 模型在操作任务中展现出良好的性能,但在微调过程中仍面临“灾难性遗忘”问题,即原本继承自预训练 VLM 的多模态推理能力逐渐衰退。这一问题的根源主要有两点:其一,现有的大规模真实机器人数据集在任务场景与语言指令的多样性上严重不足,训练往往局限于模板化的简单指令(如“打开抽屉”);其二,仅使用具身操作数据进行微调容易破坏模型原有的通用语义理解能力,削弱其对多样化输入、用户反馈和自然语言指令的适应性。
为缓解这一问题,已有研究主要采取两类策略。一类是联合训练方式,力图在保留通用多模态能力的同时学习操作技能,例如 ChatVLA 和 Magma 通过联合视觉语言数据与机器人操作数据进行训练;但这种方式往往忽视了具身推理的复杂性。另一类方法则专注于将具身推理能力嵌入操作数据中以迁移 VLM 的推理能力,例如 ECoT 和 Emma-X 引入 chain-of-thought(CoT)推理结构,通过预设的计划与子任务结构增强模型的操作能力。然而这类方法通常依赖于预训练的动作模型并嵌入固定的推理模板,限制了模型的多模态泛化能力。
针对上述挑战,本文提出了一种通用型 VLA 框架 InstructVLA,在保留大型 VLM 的强大语义理解能力的同时,增强其在动作生成上的准确性与泛化性。如图 1 所示,InstructVLA 引入了一种全新的训练范式,将语言引导下的动作生成视为指令跟随的一部分,并围绕这一目标构建了VLA-IT(Vision-Language-Action Instruction Tuning)数据集,包含约 65 万条人机交互数据,涵盖多样化的任务指令、场景描述与问答对,均基于高质量操作场景标注。
该模型训练流程分为两阶段:第一阶段为动作预训练,利用语言描述提炼出的动作表示训练动作专家;第二阶段为指令微调,通过可训练的专家混合(MoE)框架统一语言与动作生成,并在通用多模态数据集、操作数据与 VLA-IT 数据集上联合训练,实现语言推理与动作生成的自动切换,从而充分激发 VLM 的多模态能力。
为验证 InstructVLA 的泛化性能,作者构建了一个包含 80 个零样本任务的评估集 SimplerEnv-Instruct,覆盖闭环操作任务与高阶指令推理任务,既考验语境理解能力,也考验任务分解与执行能力。结果显示,InstructVLA 在该基准上优于微调版 OpenVLA 92%,也超过了由 GPT-4o 辅助的动作专家 29%。此外,InstructVLA 在多模态任务上超越了同等规模的 VLM 模型,在闭环操作上较 Magma 提升了 27%。
本文的主要贡献如下:
● 提出 InstructVLA 架构与训练流程,强调语言能力在 VLA 系统中的核心地位,在保留预训练视觉语言能力的同时,将机器人操作纳入指令跟随体系;
● 构建了完整的 VLA 指令跟随数据与评估流程,包括 65 万条标注的 VLA-IT 数据集与一个人工设计的基准测试套件,用于评估 VLA 模型的指令泛化能力;
● 在机器人操作、多模态基准测试与真实部署中取得领先性能,为实现直观、可控的机器人操作提供新路径。
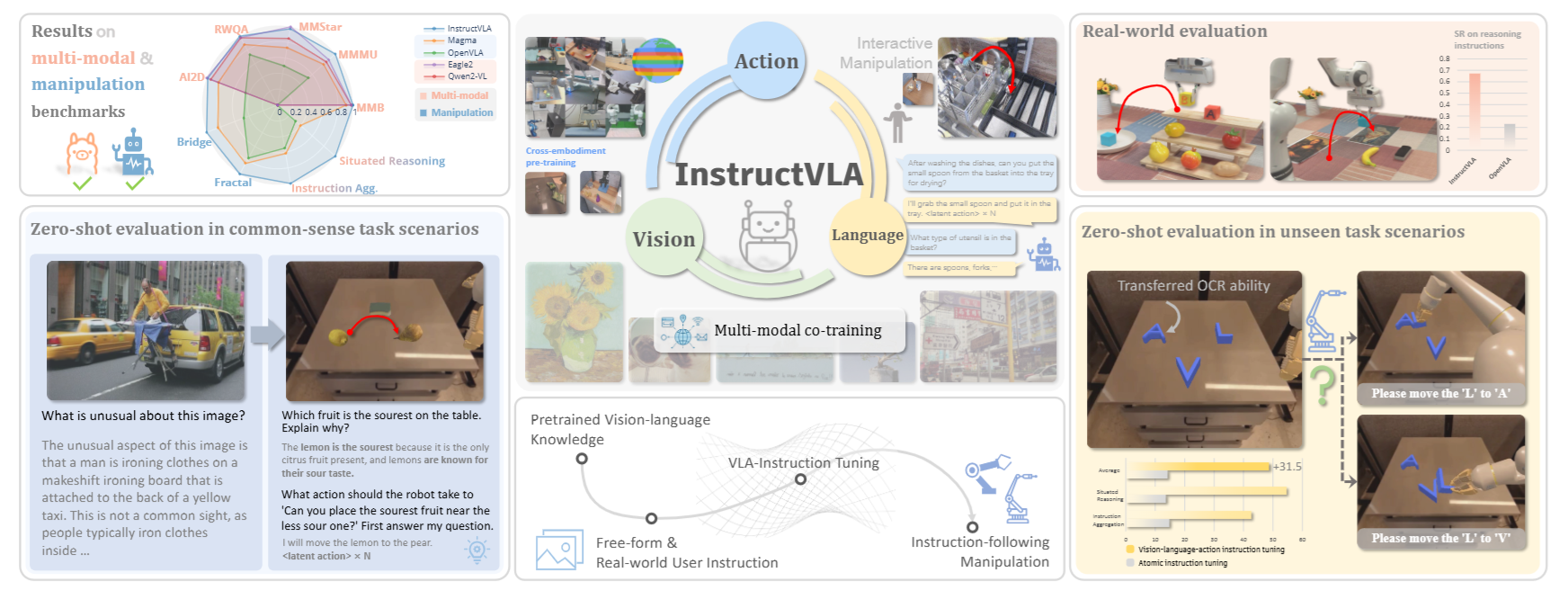
图1|InstructVLA 将强大的多模态理解能力与精准的指令驱动机器人控制相结合,充分利用了视觉语言模型(VLM)所蕴含的世界知识。其核心训练策略——视觉-语言-动作指令微调(vision-language-action instruction tuning)——通过在动作生成之前先进行视觉语言推理,有效提升了机器人操控能力

模型架构
作者设计了一个统一的框架,能够借助单一的视觉语言模型(VLM)同时执行多模态推理与受语言引导的潜在动作规划(见图2中的模块1和2)。该模型首先输出文本,用以保持预训练 VLM 的语言理解与多模态推理能力,随后生成潜在动作向量,用于下游的操作任务。为支持动作规划,作者引入了 N 个可学习的动作查询(action queries),通过注意机制提取 VLM 的隐状态中与任务相关的潜在动作表示。作者的实现基于 Eagle2-2B 主干网络构建,并结合定制的训练策略。语言生成部分采用交叉熵损失进行监督。
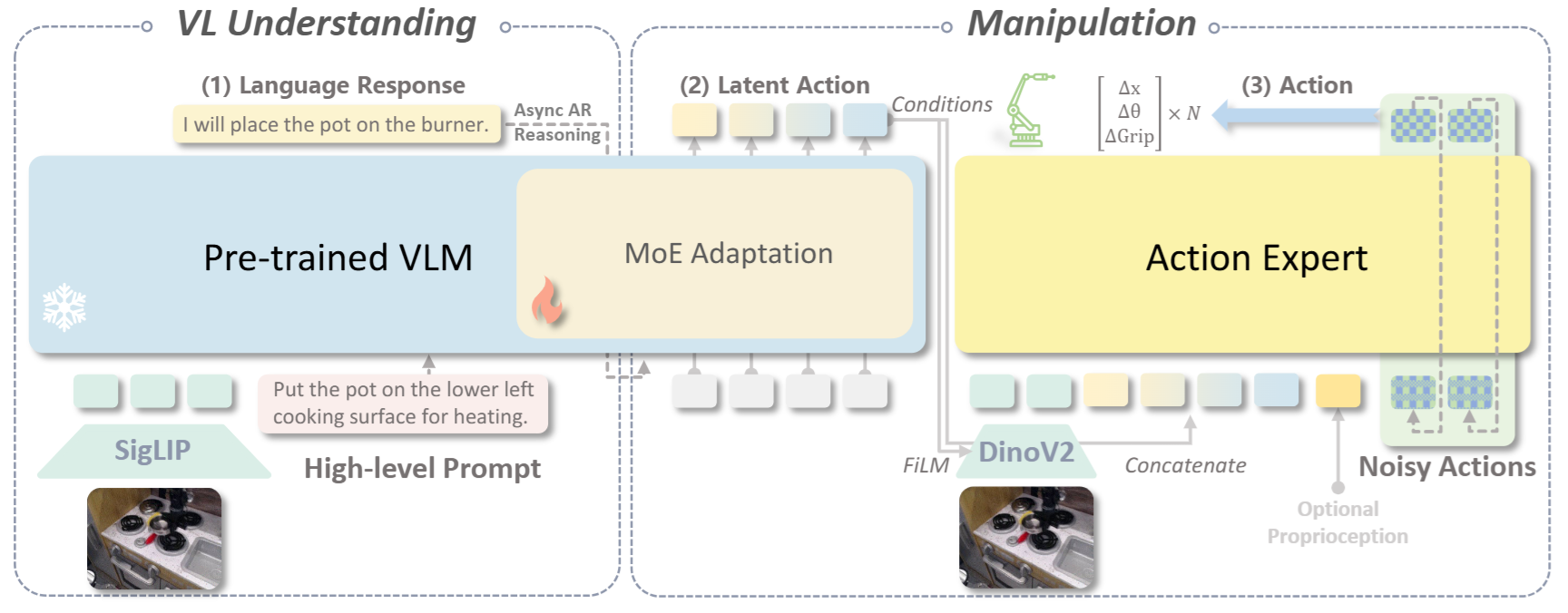
图2|模型架构总览
用于语言引导动作生成的专家混合模块
关键挑战在于使模型在推理与操作之间灵活切换。为此,作者采用了专家混合机制(Mixture-of-Experts, MoE),根据输入语境与推理模式自适应地调整各专家模块的权重,实现多模态推理与语言驱动操作之间的融合。在具体实现中,作者使用 LoRA 模块作为 LLM 主干中的多个专家,既保留预训练能力,又保证推理效率。一个“scale head”模块根据隐状态预测每个专家的门控系数,从而对多个专家输出进行加权融合。
流匹配模型作为高效动作专家
为了进一步解耦高层理解与低层控制,InstructVLA 引入了一个独立的动作专家模块,该模块从图像观察中生成具体动作,前提是已有 VLM 推理结果。该模块输入包括:来自 DINOv2 的图像特征、VLM 的潜在动作向量、添加扰动的动作嵌入,以及可选的本体感知信息。模型结构为一个简单的 Transformer,内部采用分块式因果注意力机制:在每类输入内部使用非因果注意力,不同输入类型之间使用因果注意力。此外,DINOv2 编码器还加入了 FiLM 模块以增强空间感知与上下文对齐。动作学习的目标采用 flow matching 机制进行监督。
推理机制
InstructVLA 将语言与动作生成整合为一个单模型,并通过如下策略提升推理效率:
解码方式优化: 文本响应采用贪婪解码,直到出现第一个动作查询标记为止,随后所有动作查询在 VLM 中并行处理完成;
结果缓存机制: 将语言输出与动作生成解耦,并对语言结果进行跨多个动作步骤的缓存,以利用其时间稳定性;同样,也支持缓存潜在动作,从而减少前向推理次数,推理速度优于 ECoT。
双阶段训练流程
该训练策略包括两个阶段:首先是动作专家的高效预训练,使其能够拟合 VLM 中的潜在动作;接着是结合指令微调的视觉-语言-动作训练过程,重新激活模型的多模态推理能力。
第一阶段:动作预训练
InstructVLA 首先在多个操控任务数据上进行预训练。训练目标是让模型既能生成动作,又能生成基于规则注释的语言描述,后者通过交叉熵损失进行监督。最终的损失函数是语言损失与 flow matching 损失之和。在该阶段,仅对动作查询的输入/输出嵌入和 LLM 中的动作 LoRA 适配器进行微调,约 6.5 亿参数。该阶段训练后的模型被称为“Expert”。
第二阶段:指令微调
作者基于视觉指令微调的思路,提出了一种简洁的训练方式。在动作专家已经具备模仿 VLM 潜在动作的能力之后,进一步微调 LLM 主干,使其能处理更复杂的操作指令并生成合理响应。在此阶段,动作专家保持冻结,仅新增语言 LoRA 模块和 MoE 模块中的 scale head。MoE 模块是唯一的可训练部分,共约 2.2 亿参数。本阶段使用的数据将 VLM 预训练能力与具身任务桥接,并融合多个多模态数据集联合训练,最终得到的模型被称为“Generalist”,即具备通用语言理解与操作能力的模型。
数据集及评估基准
为实现语言与动作的统一建模,InstructVLA 构建了涵盖感知、推理与操控的多层次数据体系。在数据构建方面,作者整理了 65 万条人机交互数据,结合操控轨迹与语言动作标注,形成了 VLA-IT 数据集,不仅包含基础末端动作的语言描述,还通过场景字幕、问答对、指令改写与语境构造四类任务,模拟机器人在复杂语境中对用户意图的理解与响应。
在评估方面,作者提出 SimplerEnv-Instruct 基准套件,从零样本角度测试模型在指令多样性与情境推理上的泛化能力,覆盖动词扩展、指令重构、多语言表达及任务推理等共 1100 项挑战任务。该评估遵循“技能迁移性”与“指令可解释性”两大原则,确保任务既具挑战性又贴近真实人机协作场景。通过这一系统化的数据与评估设计,InstructVLA 实现了从理解到执行的完整链路训练与测试,为通用 VLA 系统的构建奠定了基础。
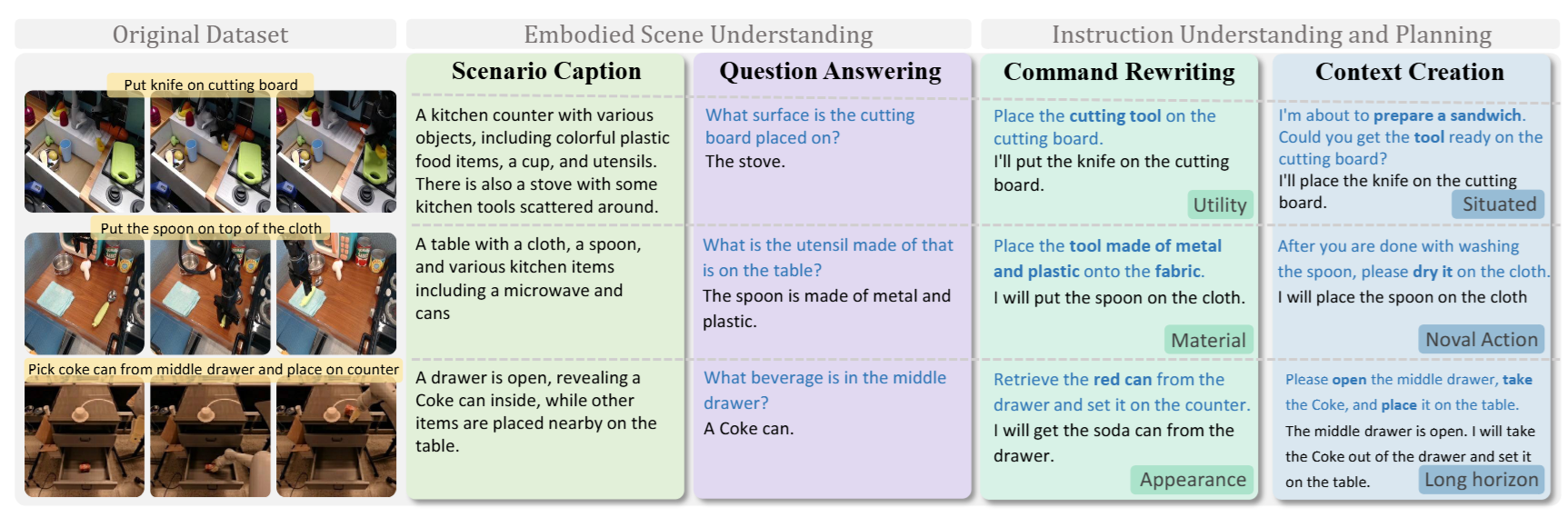
图3|VLA的微调数据示例

在多项基准测试中,InstructVLA 展现出显著的性能优势。其通用模型在多个多模态任务中全面超越现有主流 VLM(如 Bunny、Eagle2),并在 MMMU、MMB、RWQA 等基准上表现领先。操控方面,InstructVLA 在 SimplerEnv 中比 SpatialVLA 提升了 30.5%,在更具挑战性的 SimplerEnv-Instruct 中,比集成 GPT-4o 的 OpenVLA 提高了近 30%。值得注意的是,即便引入 GPT-4o 对 OpenVLA 进行任务重构,仍无法超越 InstructVLA 的端到端表现,显示出其在“思考-理解-执行”闭环中的稳健性。

图4|多模态理解定量实验结果
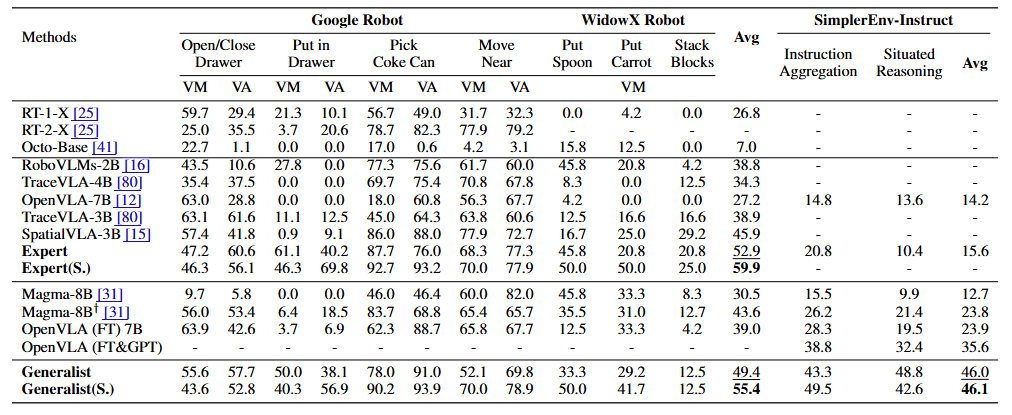
图5|机器人操作任务定量实验结果
在真实机器人实验中,InstructVLA 分别在 WidowX250 和 Franka 机器人平台上进行零样本与少样本操控测试。在复杂指令理解任务中,如名人识别、工具使用等,InstructVLA 的成功率分别比 OpenVLA 高出 41.7% 和 46.7%,进一步验证了其泛化与推理能力。

图6|真实机器人实验结果展示
消融实验方面,作者从语言运动预训练、潜在动作 token 数量、视觉编码器结构等多个角度进行了深入对比。实验发现,使用语言引导的动作预训练可提升操控成功率 10.5%,而引入 FiLM 增强的视觉-动作对齐机制,可在基础 ViT 编码上带来额外 15% 提升。此外,作者也探讨了在仅微调语言模型的前提下依然能保持推理性能,验证了其模型结构在效率与能力间的优雅平衡。
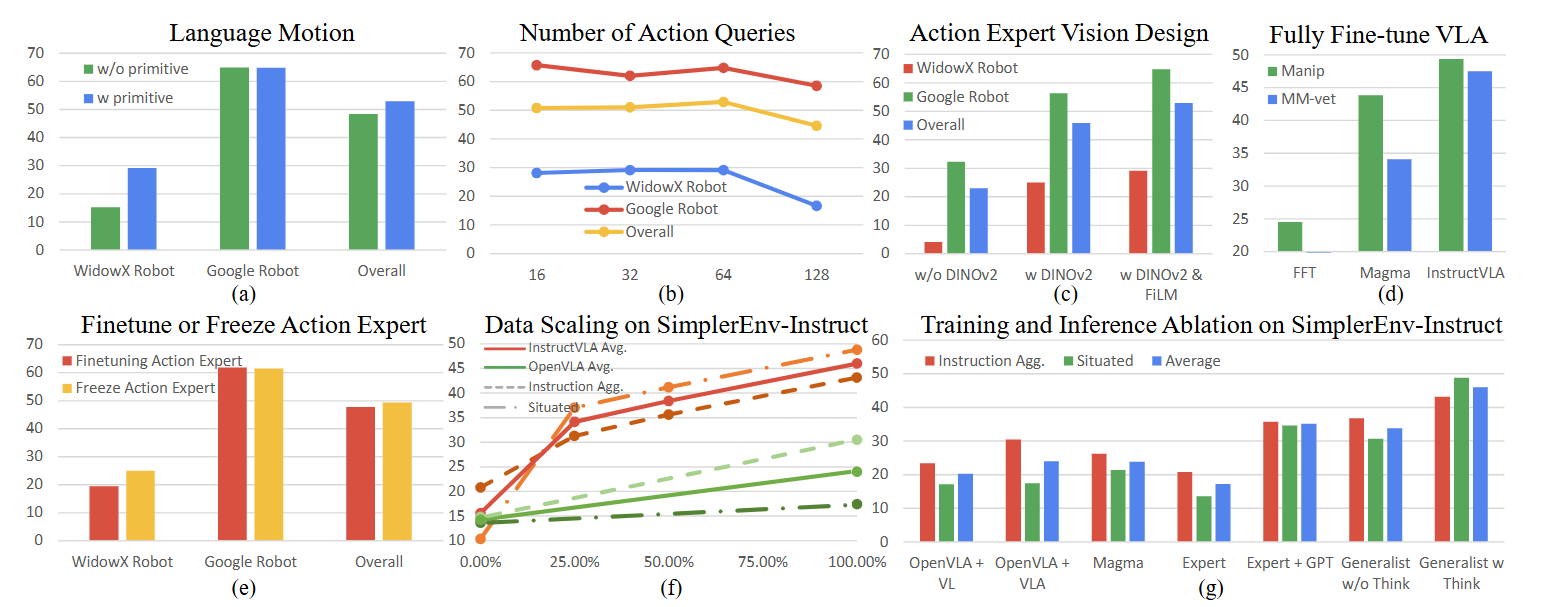
图7|消融实验从两个角度展开分析:(a-d) 动作能力集成:评估在数据设计(如语言引导的运动描述)、表示方式(如潜在动作 token)、视觉编码器结构以及微调策略等方面的设计选择,如何影响机器人操控性能。(e-g) 多模态能力迁移:探讨视觉语言理解能力是如何通过“从视觉语言到动作”的学习方式、指令数据规模扩展,以及推理时的“思考”机制,在操控任务中发挥作用的
综上,InstructVLA 在端到端指令理解、多模态融合操控、真实部署与可解释“思考式”交互等方面均展现出强大的性能与潜力,具备作为下一代通用机器人大模型核心组件的能力。

本文提出了 InstructVLA,一种统一的视觉-语言-动作(VLA)模型,能够融合多模态推理与动作生成。通过保留预训练视觉语言模型(VLM)的泛化能力,并将语言、感知与控制整合为一个协调的流程,InstructVLA 有效解决了 VLA 模型中常见的灾难性遗忘问题与推理脱节现象。尽管当前版本仅使用了最简化的输入(单张图像与一条指令),但未来若引入更多感知模态(如深度信息)将有望进一步提升性能。即便如此,作者构建的端到端数据与训练流程,已在操控任务、多模态基准评测及真实部署中实现了领先表现,为打造更具泛化性、可解释性与交互性的机器人系统奠定了基础。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









