






 提出一种关系感知全局注意力模块(RGA),充分利用全局相关性来推断注意力,增强特征表示能力。RGA通过学习特征间的关系,使注意力集中于有区分度的区域。广泛应用于行人再识别、场景分割和图像分类等任务。
提出一种关系感知全局注意力模块(RGA),充分利用全局相关性来推断注意力,增强特征表示能力。RGA通过学习特征间的关系,使注意力集中于有区分度的区域。广泛应用于行人再识别、场景分割和图像分类等任务。
Relation-Aware Global Attention
论文:Relation-Aware Global Attention for Person Re-identification,CVPR,2020.
链接:paper
代码:github
摘要
注意力机制通过关注重要特征和抑制不重要的特征来提到表示能力。在卷积神经网络中,注意力通常是通过局部卷积来学习的,它忽略了全局信息和隐藏关系。如何有效的利用远程上下文信息来全局的学习注意力还没有得到充分的研究。文中提出了一个有效的关系感知全局注意力模块,以充分利用全局相关性来推断注意。具体来说,在计算某个特征位置的注意力时,为了掌握全局范围的信息,我们建议这些关系,即它与所有特征位置的成对相关性/亲和性,以及特征本身堆叠在一起,以便通过卷积运算来学习注意力。给定一个中间特征图,我们已经验证了在空间和通道上的有效性。当应用于人的再识别任务时,我们的模型实现了最先进的性能。广泛的消融研究表明,我们的RGA可以显著提高特征表示能力。我们通过将RGA应用于场景分割和图像分类任务,进一步证明了RGA对视觉任务的普遍适用性,从而实现了一致的性能改进。
介绍
**动机:**在行人重识别研究中,注意力机制可以强化区分特征,抑制无关特征。之间的方法主要通过使用局部卷积和编码器-解码器结构的卷积堆叠的方式来学习注意力,忽略了从全局结构模式中挖掘知识。文中为了更好的进行Attention 学习,提出了Relation-Aware Global Attention Module。
解决方法:
- 作者通过设计attention,让网络提取更具有区别度的特征信息。简单来说,就是给行人不同部位的特征加上一个权重,从而达到对区分特征的增强,无关特征的抑制。
- 作者在这篇论文中提出了一个Relation-Aware Global Attention (RGA) 模型挖掘全局结构相关信息,使得attention集中在有区分度的人体部位,并且考虑到每个特征节点和全局特征之间的关系。用来模拟人的视觉系统,对不同的特征付出不同的注意力。
- 对于每一个代表空间位置的特征向量节点,取所有节点之间的成对关系,加上当前节点来表征全局结构信息。对于一个特征集合V = {xi ∈ R d , i = 1, · · · , N},有N个相关特征,通过学习一个表示的mask矩阵,用a=(a1, · · · , aN )表示,用来衡量每个特征的重要程度,通过attention更新的特征为 z i = a i ∗ x i z_i = a_i*x_i zi=ai∗xi,主要任务就是学习ai的值。
方法亮点:
如下图所示,之前的attention学习中,有两种普遍的学习方法,分别为下图a 和 b。a1, · · · , a5 对应于五个特征向量 x1, · · · , x5的attention值。
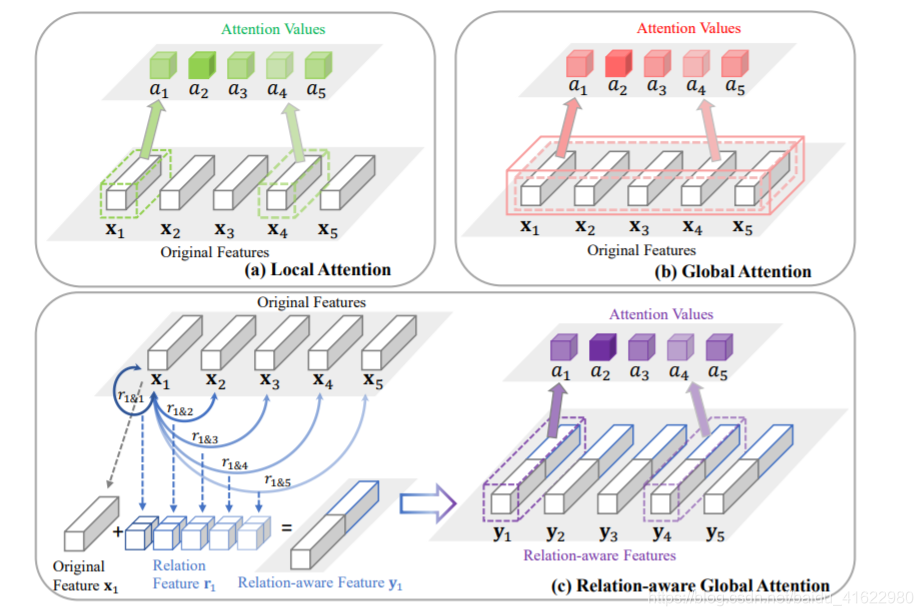
- a 图使用卷积神经网络,对每一个特征x,学习一个attention值,因此只能学习到局部特征,而忽视了全局特征。
- b 图使用全连接网络,学习到的attention值来自于所有特征向量的连接,虽然学习到了全局特征,但参数量过大,计算量太大。
- c 图通过考虑全局的相关信息学习attention值,即对每一个特征向量,全局的关联信息用一个关系对ri = [ri,1, · · · , ri,5, r1,i, · · · , r5,i]表示,其中ri,1表示第i个特征节点和第一个特征节点的关系,以此类推。用一个符号ri&j = [ri,j , rj,i]表示,所有的ri&j组合可以得到x1一个关联特征,组合在一起得到下图中的特征向量r1,再和原始特征向量x1拼接,得到一个relation-aware feature y1, y1 = [x1, r1 ],作为提取attention的特征向量。因此可以看出,基于特征x1得到的attention值a1既包含了局部特征x1,又包含了全局所有特征之间的关系。
模型结构
模型结构图如下:
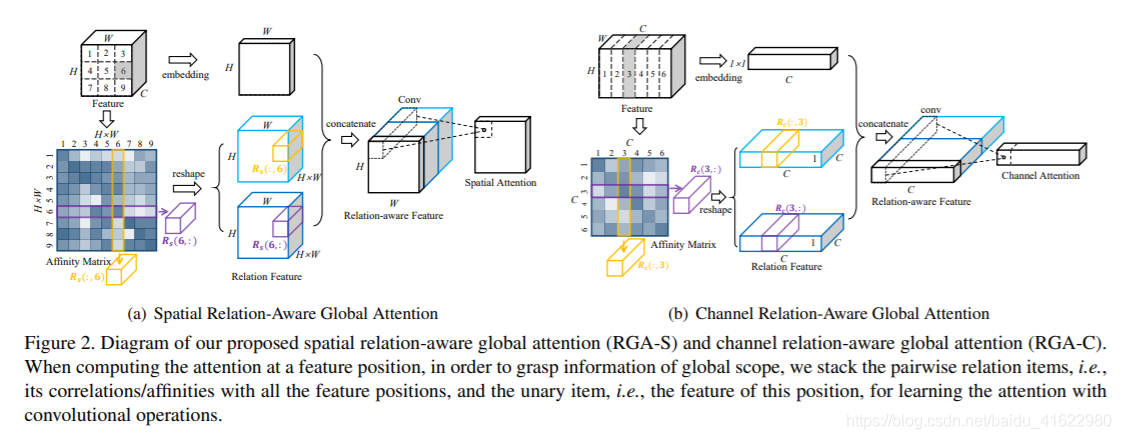
a 图为RGA-S,用来提取空间注意力,b图为RGA-C,用来提取通道注意力。
空间注意力:
对于一个输入的特征向量 CxHxW ,在上图中,可以表示为Cx3x3 大小。分别输入到两个卷积层c1 和 c2。经过c1卷积层后转化为向量[9,c],两者矩阵相乘,等到[9x9]的矩阵,代表每个向量之间的关系。再将得到的9x9 矩阵经过reshape 操作分别得到两个[9,3,3] 和 [9,3,3,]矩阵。得到的两个relation feature矩阵可以通俗的理解为我和你之间的关系,你和我之间的关系。原始的输入值在经过一个卷积层取所有通道特征图的均值得到一个[1,3,3]的矩阵,因为只需要提取空间信息,所以将通道数变为1。再将三个特征矩阵连接到一起[9+9+1,3,3]。因为卷积网络权值共享,将其压缩为[1,3,3],从而得到每一个位置的权重值,最后与输入x相乘。
通道注意力:
和空间注意力相似,只不过通道做卷积和reshape操作,获得每个通道的权重值,,即判断哪一个特征图重要。
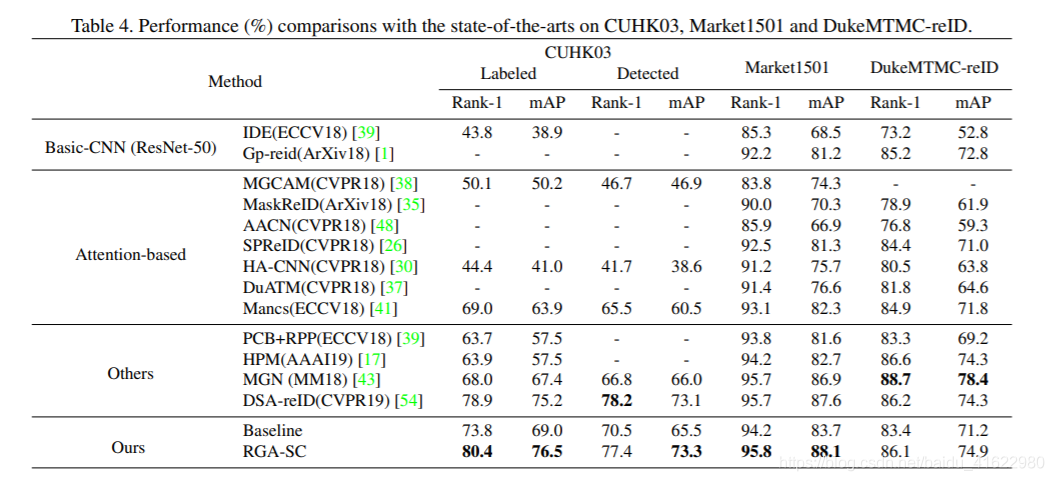
主要结果:
- 从全局的角度来学习每个特征节点的注意力的特性,通过一个学习函数得到attention关系进行语义挖掘。对每个特征节点,通过叠加节点构建一个紧凑的表示所有特征节点的成对关系的矢量,从中学习注意力,也就是权重。
- 设计了基于关系的紧凑表示和浅层卷积的RGA模型,分别应用于空间特征和通道维度信息。
实验

















 1547
1547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









