



 本文深入解析了机器学习中的过拟合与欠拟合问题,阐述了两者的基本概念及其对模型泛化性能的影响。同时,介绍了三种常见的数据集处理方法:留出法、交叉验证法及自助法,帮助读者理解如何有效评估和优化模型。
本文深入解析了机器学习中的过拟合与欠拟合问题,阐述了两者的基本概念及其对模型泛化性能的影响。同时,介绍了三种常见的数据集处理方法:留出法、交叉验证法及自助法,帮助读者理解如何有效评估和优化模型。
两个常见概念:
过拟合:是指为了得到一致假设而使假设变得过度严格。当机器学习把训练样本学习得“太好”,可能把训练样本自身的一些特点当成了所有潜在样本都具有的一本性质,这样旧会导致泛化性能下降,这种现象在机器学习中成为过拟合overfitting.
欠拟合:是指模型拟合程度不高,即模型没有很好地捕捉到数据特征,不能够很好地拟合数据。通常是由于学习能力低下而造成的。
一个直观化的类比,如下图所示:

常见的三种数据集处理方法:
通常,我们在“训练集”training set来对算法进行训练,在“测试集”tesing set上对算法进行测试,通过得到的误差,来对算法进行评估。这就要求,测试集和训练集互斥,用new data去测试old data上训练处的算法。
所以,当我们拿到一个数据集D时,为了得到训练集S,测试集T,通过有下面几种做法:
1.留出法:
D=S∪T,S∩T=∅
同时,S和T的划分也要使用“分层采样”,使数据分布尽量平均,避免因数据划分引起的额外误差。
2.交叉验证法:
将D划分为n个大小相似的互斥子集,每次用n-1个做训练集,剩下那个做测试集。
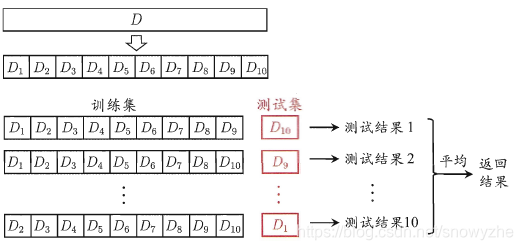
3.自助法:
上面两种方法的训练集都小于D,这样可能会引入一下因训练样本规模不同而导致的估计偏差,这时可以采用自助法。
它以自主采样法为基础,例如数据集D中有m个样本,则采样m次,放入D',作为训练集。然后拿没在训练集中出现的数据,用于测试集。然而,自助法产生的数据集改变了初识数据集的分布,可能会引入估计偏差,因为,在数据量足够时,前两种方法更加常用。
Reference: 西瓜书

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









