




 本文介绍了生成对抗网络(GAN)的基本概念,包括生成器和鉴别器的作用。GAN通过相互竞争的训练过程,使生成器能生成与真实数据分布相近的样本。文章讨论了JS散度及其问题,并提及CycleGAN用于图像转换。此外,还概述了两种评估GAN模型的方法:InceptionScore和Fréchet Inception Distance。
本文介绍了生成对抗网络(GAN)的基本概念,包括生成器和鉴别器的作用。GAN通过相互竞争的训练过程,使生成器能生成与真实数据分布相近的样本。文章讨论了JS散度及其问题,并提及CycleGAN用于图像转换。此外,还概述了两种评估GAN模型的方法:InceptionScore和Fréchet Inception Distance。
目录
2.Fréchet Inception Distance (FID)
李宏毅2022ML第六周课程笔记 GAN(生成对抗网络)
GAN的基本概念
GAN全称为Generative Adversarial Network(生成对抗网络),其主要的目的是为了让训练机器让机器能够自主生成相对应类型的data,其中生成器generator就是GAN中进行生成相对应类似分布的网络,而鉴别器Discriminator就是判别生成器生成的data是否为真假的网络。
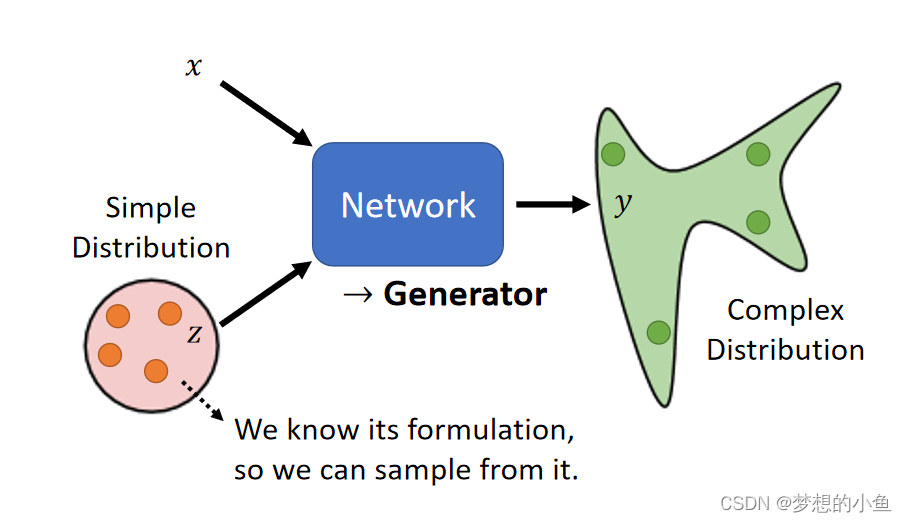
GAN的基本思想
GAN的基本架构为一个generator和一个discriminator,生成器的任务是产生大量data,然后根据判别器的反馈不断更新自己,期望自己产生的数据不会被判别器判假,而判别器是不断训练自己的判断真伪的能力,两者相反相成,相成相反。
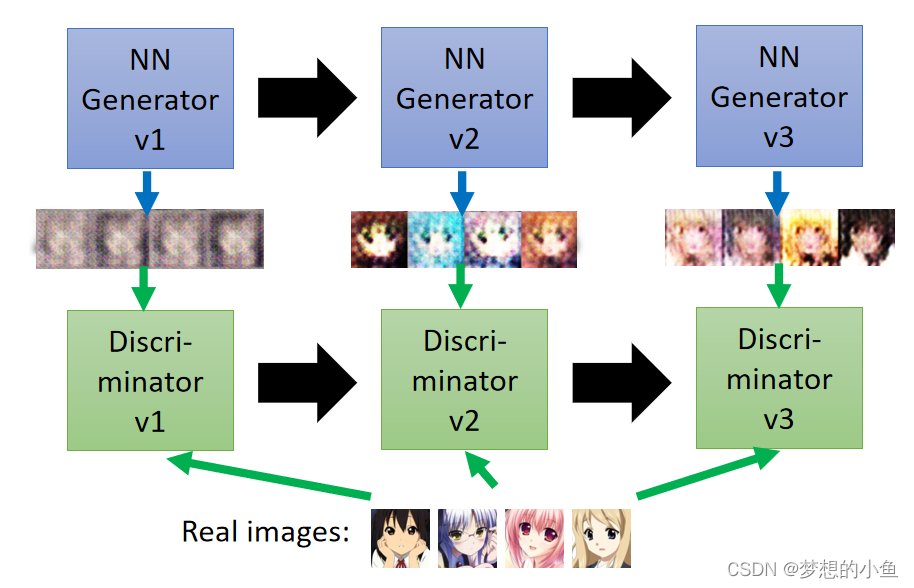
GAN的算法基本流程
初始化生成器和判别器的参数,首先固定生成器的参数,不断产生图片喂给判别器,从而训练判别器的网络,之后固定判别器,更新生成器的网络。
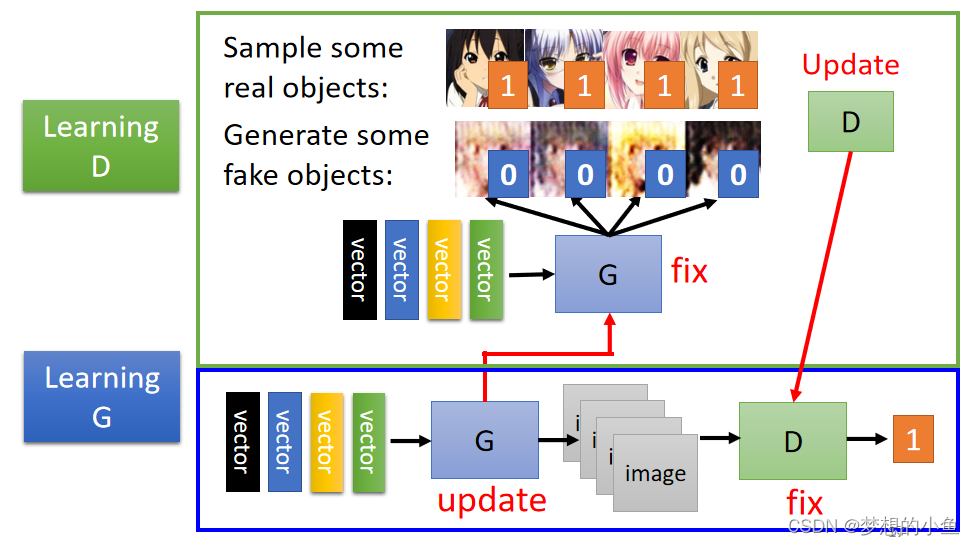
训练目标
希望最终能够让我们的生成器输出的数据分布能和期望的数据分布越接近越好。
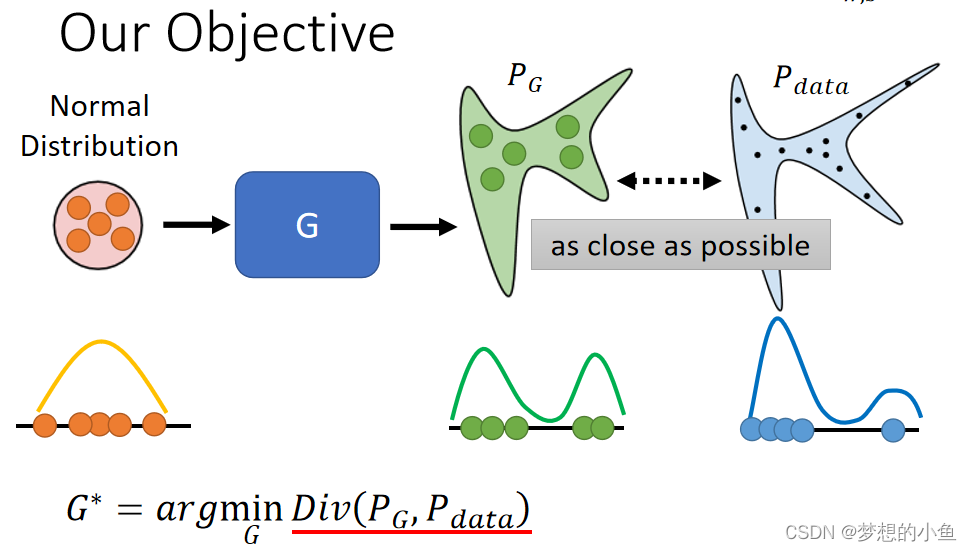
怎么判断两个数据集的分布接近程度?
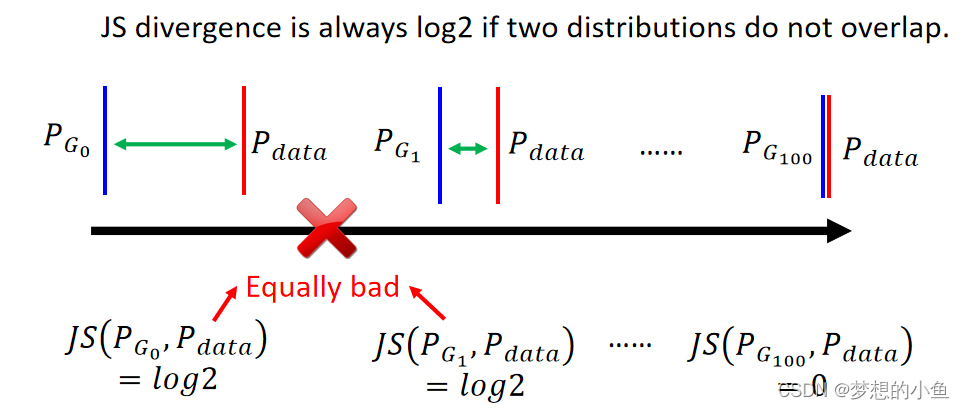
JS divergence:JS散度是对称的,其取值是0到1之间。如果两个分布P,Q离得很远,完全没有重叠的时候,那么KL散度值是没有意义的,而JS散度值是一个常数。
KL散度:用来衡量两个分布之间的差异,等于一个交叉熵减去一个信息熵。

能否使用其它散度呢?
可以选择你喜欢的使用,以下是一些参考。


JS散度存在的问题
当两个分布足够接近时,不管此时再怎么变化,JS散度值为常数,梯度为0,无法更新。在图像所在的高维空间中,生成的图像分布和真实图像的分布可能是完全没有重叠的,比如在三维空间举一个例子,可以理解为两者的分布是三维空间中的两个面,那么他们重叠的部分几乎为零。
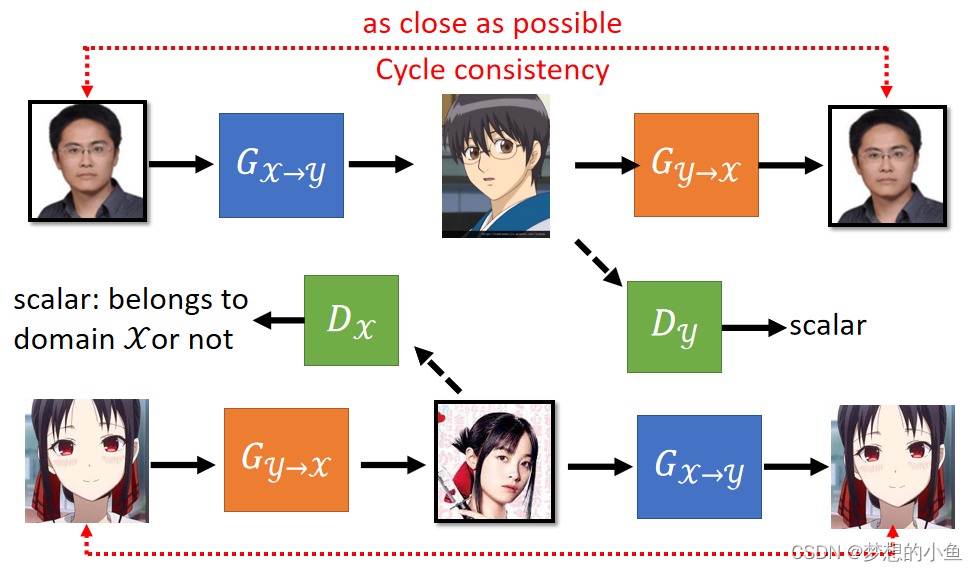
Cycle GAN
基本原理:使用两个生成网络,将原图像生成两次,希望最后生成的结果和原始数据尽可能接近。
怎么对于GAN模型进行评估?
Evaluation of Generation:目前来说没有很系统的评价体系。
1. Inception Score (IS)
针对我们GAN生成的图片,我们套用一个预先训练好的Inception模型来获得概率分布p。我们希望我们的GAN生成接近真实的数据,同时也希望GAN生成多样的数据,所以我们希望概率分布p有着低entropy,评分公式为:
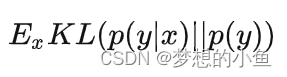
2.Fréchet Inception Distance (FID)
FID是在IS的基础上的改良版,计算 IS 时只考虑了生成样本,没有考虑真实数据,即 IS 无法反映真实数据和样本之间的距离,IS 判断数据真实性的依据,FID距离计算真实样本,生成样本在特征空间之间的距离。首先利用Inception网络来提取特征,然后使用高斯模型对特征空间进行建模,再去求解两个特征之间的距离,较低的FID意味着较高图片的质量和多样性,公式(越小越好):
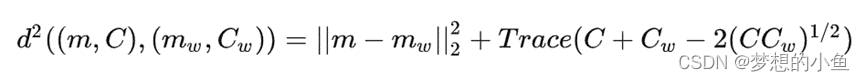




















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











