






数据湖介绍:
数据湖是基于很多细小河流汇集的一个湖泊,在企业内部,其实就是通过各种通道流入的数据。通过积少成多,汇集成一个支持各种类型(结构化,非结构化,日志,json,图片,IOT,图数据)等。多样式的集合点。
我们模拟一个物流仓库,从收集货物,到物流中转站,到商品的整个过程,流程如下:

举个例子:类似目前的物流系统。
我们的货物:有文件,有食品,有材料,有电子设备等。
我们的渠道:包括快递小哥,快送,本地物流等
我们的数据湖:就是货物的集中地。或者叫自由市场(统一转运站),很多快递公司在此收敛自家快递。
搬运方式:可以走顺丰(实时)或者邮政(离线)
使用场景:超市(数据集市),水果超市,建材市场等
市场加工人员:设计师,工程师,AI,科学院,分析师,安检员等
市场租户:市场管理员给每家分配场地和货物的权限。
元数据:记录货物信息,从哪里来,到哪里去。
数据仓库介绍:
通过上图,可以清晰的看到数据湖的作用。那大家会问,数据湖根数仓到底有啥区别,那我们首先要看一下,数据仓库长什么样子。
下图是数据仓库的的流程:我们以我们的工厂举例:
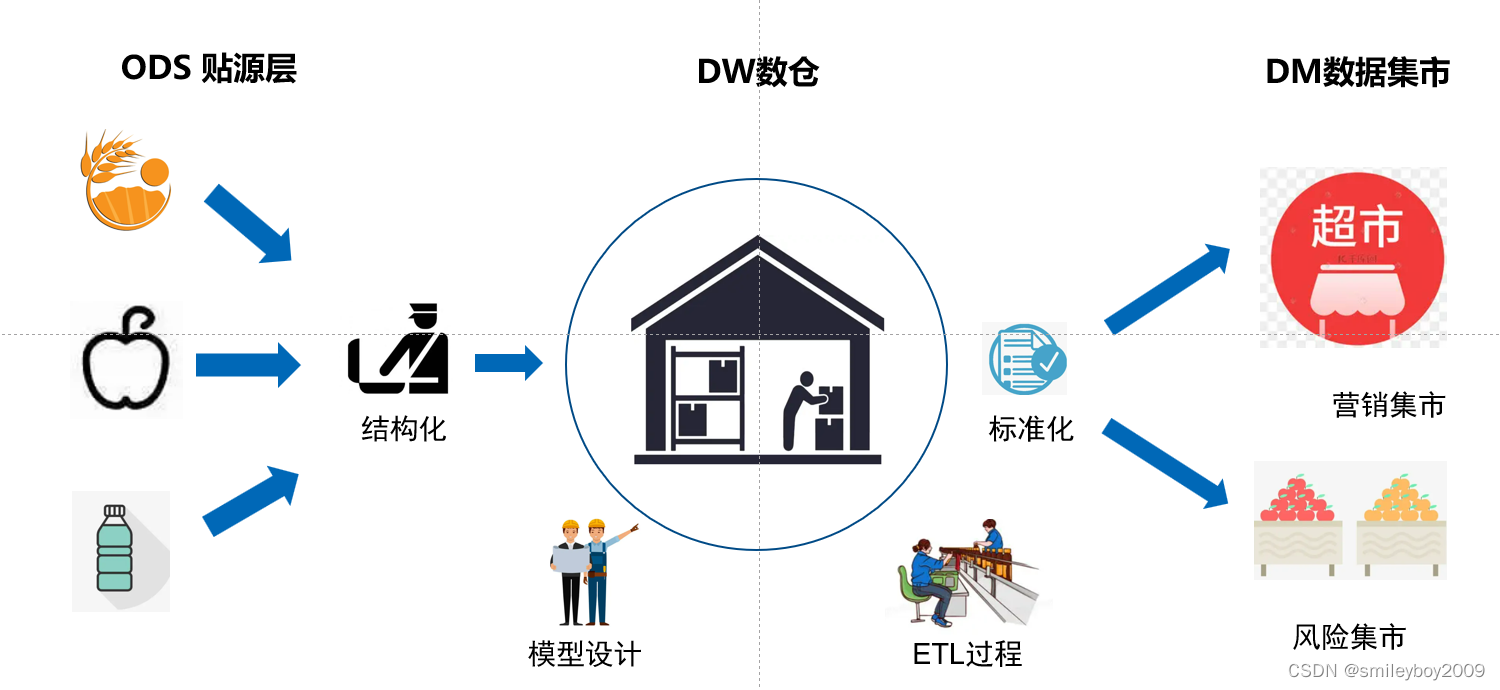
工厂的加工流程:
我们的原材料:各种食材来源。
我们采购渠道:统一的采购和过滤,按需采购
我们的工厂:先产品设计(模型设计),在根据设计进行加工(ETL过程),行程标准化(数据治理(要质量验证))
我们的集市:产品标准的专门店(专业的营业员,专业的介绍,统一的口径)。
对比总结:
通过以上的两个场景的对比,可以看出数据湖和数仓的区别,完全是两个不同的主体,一个是标准的数据工厂,一个是货物的集散中心。各自有各种的分工。那怎么知道我们要的是数据湖,还是数据仓库。
可以自身的情况进行构建,一般一个公司两个都需要构建,但是也有单建数据湖,或者单建数据仓库。
我们从上面可以得出结论:
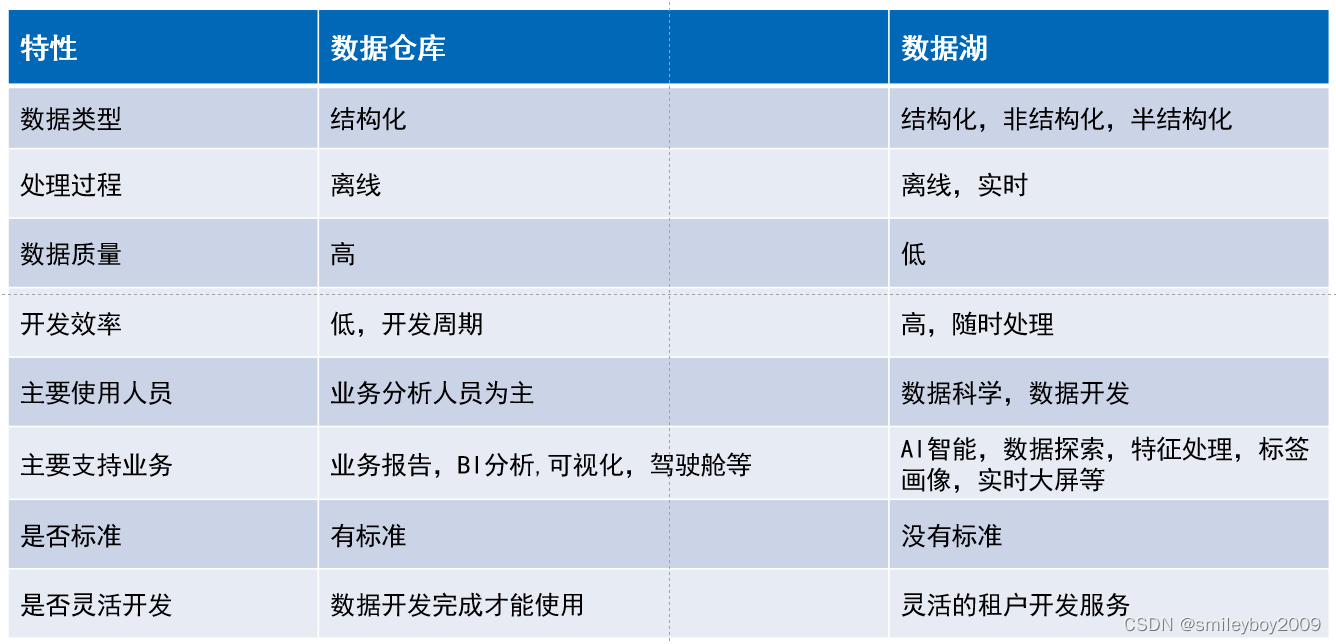
1.数据湖是杂乱无章的数据汇集,数据仓库是有需求的获取数据。
2.数据入湖,只要记录数据元数据,记录数据属性信息和数据来源,但是数仓需要先设计再入仓。
3.数据湖是自由市场,数据仓库是私有领地
4.数据湖不需要标准化,数据仓库必须标准化,而且需要统一口径(指标统一)。
由此,我们可以根据二维表得出以下结论:

















 572
572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









