







关于深度学习的基础知识
首先以线性回归入手。
引用《动手学深度学习(pytorch)》3.1.1.1 模型定义

一些名词
- 模型训练:就是通过学习寻找特定的模型参数值(在这个例子中就是 w 1 w_1 w1和 w 2 w_2 w2和b),使得数据上的误差尽可能小。
- 训练数据集:(training data set)或训练集(training set)
- 一个样本(sample):一栋房屋
- 标签(label):真实售出价格
- 特征(feature):用来预测标签的两个因素,特征用来表征样本的特点。
- 损失函数(loss function):衡量价格预测值与真实值之间的误差。 有很多中损失函数,eg:平方误差函数,交叉熵函数…
- 解析解:比较简单的问题,可以直接用公式表达出
- 数值解:有限次的迭代,尽可能的降低损失函数的值,这类解叫做数值解
- 超参数(hyperparameter):
1.∣B∣代表每个小批量中的样本个数(批量大小,batch size),
2.η 学习率(learning rate)并取正数。
这里的批量大小和学习率的值是人为设定的,并不是通过模型训练学出的,因此叫作超参数(hyperparameter)。我们通常所说的“调参”指的正是调节超参数,例如通过反复试错来找到超参数合适的值。
迭代过程

模型预测
训练完成后,我们得到了参数,w1,w2,b,这样我们就可以得到了一个方程,对于输入的(x1,x2),可以预测出其对应的y
线性回归简单的神经网络
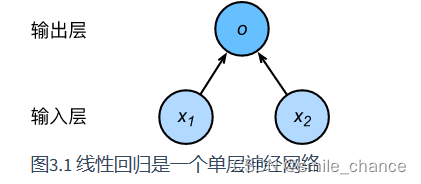
- 特征数或特征向量纬度:输入的个数,在这里就是2。
- **全连接层:**输出层中的神经元和输入层中各个输入完全连接。因此,这里的输出层又叫全连接层(fully-connected layer)或稠密层(dense layer)。


















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









