







 这篇博客介绍了如何使用朴素贝叶斯算法根据人员姓名预测性别,通过拉普拉斯平滑处理零概率问题,提高预测准确性。首先,博主展示了数据集的结构,并导入相关模块。接着,数据被读取并按性别分类。然后,计算每个汉字在男性和女性名字中出现的概率。最后,应用拉普拉斯平滑解决零概率问题,从而实现更准确的性别预测。
这篇博客介绍了如何使用朴素贝叶斯算法根据人员姓名预测性别,通过拉普拉斯平滑处理零概率问题,提高预测准确性。首先,博主展示了数据集的结构,并导入相关模块。接着,数据被读取并按性别分类。然后,计算每个汉字在男性和女性名字中出现的概率。最后,应用拉普拉斯平滑解决零概率问题,从而实现更准确的性别预测。
本篇博客利用朴素贝叶斯根据人员姓名来作性别预测,代码实现并不复杂。
准备
-
使用的数据集结构(共120000条数据):
.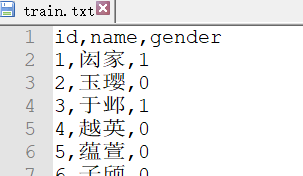
该数据集已上传至优快云:https://download.youkuaiyun.com/download/smile_shujie/11051825 -
导入模块:
import pandas as pd
import math
from collections import defaultdict
读取数据
train=pd.read_csv('train.txt')
train.head(5)
这里只展示出前五条,效果:
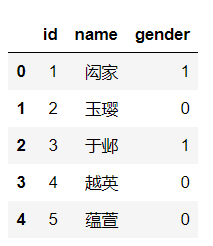
根据性别进行分类
names_female=train[train['gender']==0]
names_male=train[train['gender']==1]
print(names_female.head(2))
print(names_male.head(2))
通过这段代码, 把所有女性数据放入names_female中,男性放入names_male中,以便于在后面计算概率时使用。它们的类型都为Da
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









