




现象:
1. 有些文本词语,小模型也是有推理正确的能力的。不需要大模型这样能力强的模型。
2. decode阶段是memory-bound,不是计算密集,远远没有打满GPU算力。

基本原理
先用小且快的draft模型,生成几个tokens。再用大而慢的模型,将这些input+output tokens批量输入,一次forward得到每个token的下一个token,只保留前面和draft结果完全相同的部分,不同的部分扔弃。
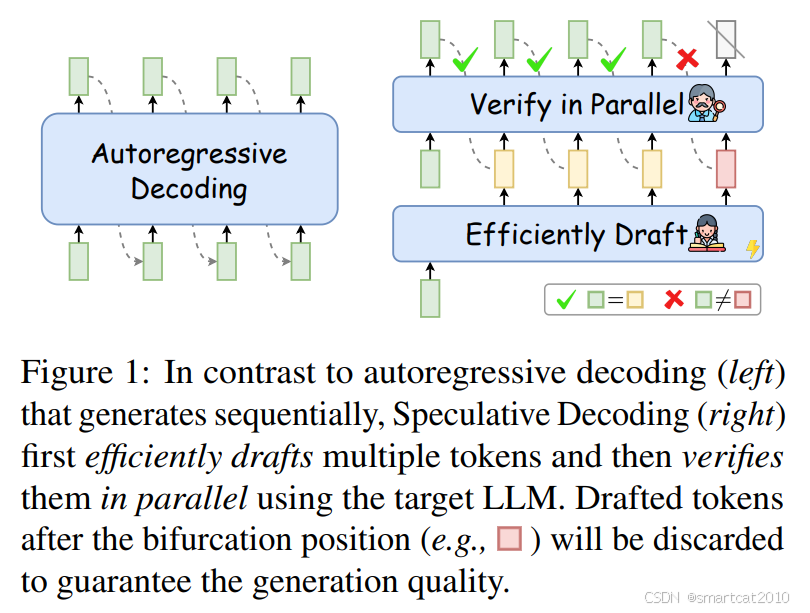
SpecInfer
痛点:强调了传统decode方法每次都要读1遍模型参数的memory-bound。
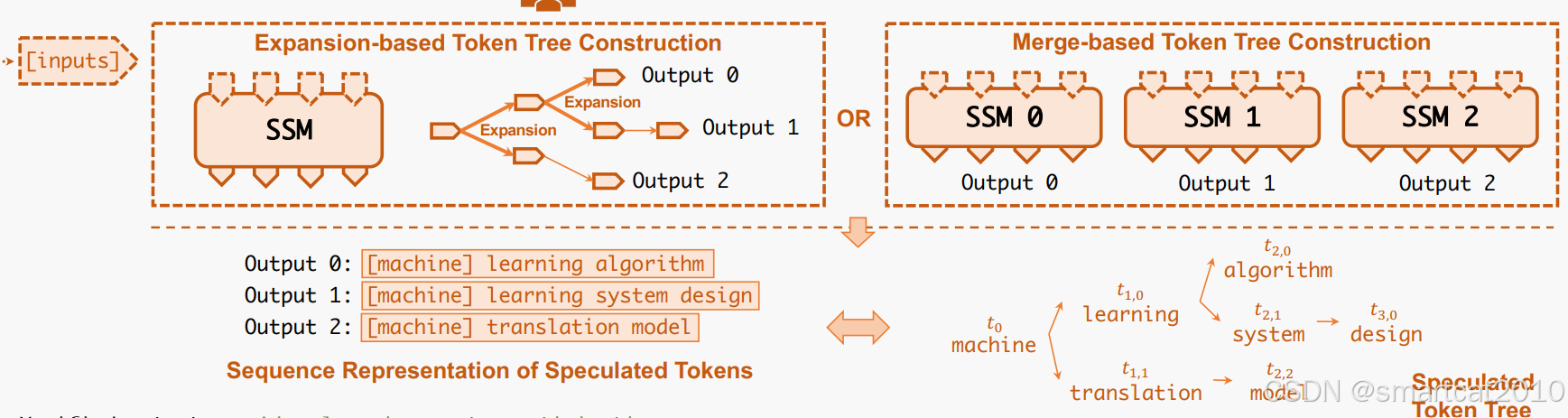
1个小模型每次采样几个tokens,OR,多个小模型每个采样1个序列;
生成多个候选序列的目的:增大命中几率。
将多个候选序列,合并成1棵树的目的:避免公共前缀tokens的KV cache的重复计算,减少显存占用。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1767
1767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









