




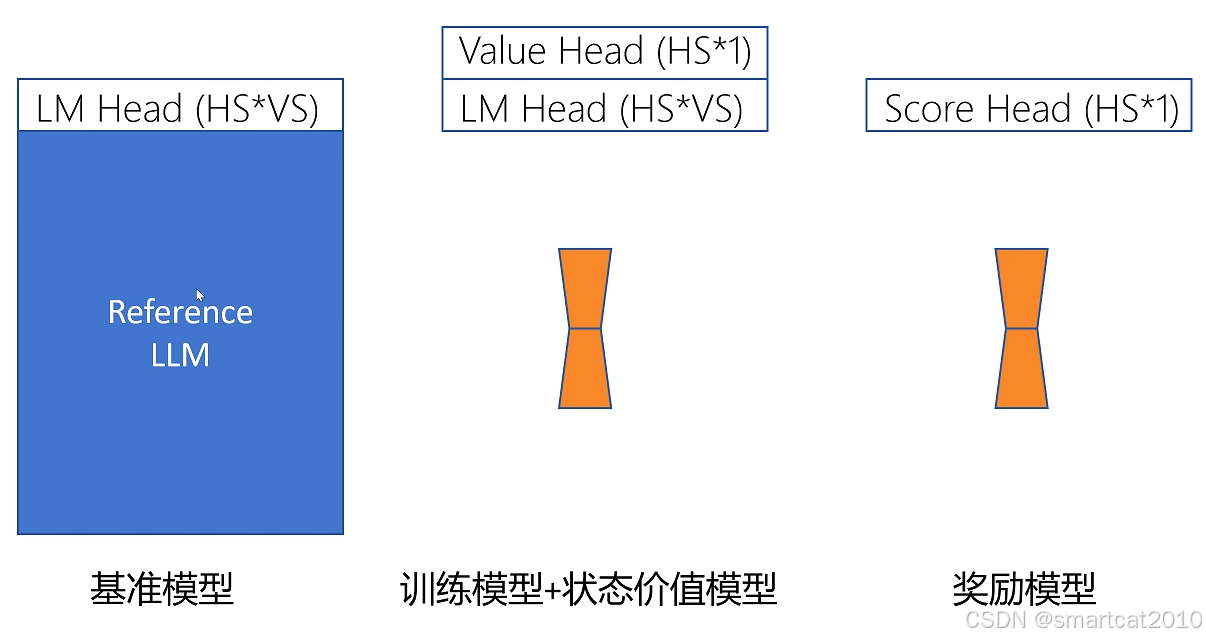
涉及多个模型:
HS: Hidden-Size
VS: Vocabulary-Size
奖励模型:事先训练好的。PPO训练期间不发生任何变化。给整个<Question,Answer>句子打1个分数,放到最后1个token的Reward里。
基准模型: PPO期间,该模型也是只读的,不变。确保训练模型和基准模型偏离不要太大。具体通过把二者对相同token的预测分布的KL散度,加到Loss里,实现的。
训练模型、状态价值模型:
二者可共用前面所有层的权重,只是最后一层Head不同。
外层循环:用参考模型采样一个序列(并得到每个token的P'),用状态价值模型得到每个token的状态价值V, 结合Reward打分和KL散度得到的加和Reward,得到每个token的GAE优势。
内层循环:GAE优势和P'保持不变,用训练模型计算该序列,得到每个token的P,加和至PPO loss里;状态价值模型计算该序列,得到每个token的状态价值V,用外循环计算好的Return做label, 计算L2损失,加入V的loss里。这2个loss加和,就是总loss。更新一次模型(训练模型和状态价值模型因为是共享参数,都被更新了)。再进行下一轮内层循环。

减少显存占用
如果同时加载4个大模型的参数,显存占用太大了。
解决:使用LoRA
基准模型是全参的。
训练模型、状态模型:前面所有层,共用同一份LoRA参数;最后一层Head层,各自保留给自的。
奖励模型:用自己的一份LoRA参数和自己的Head。
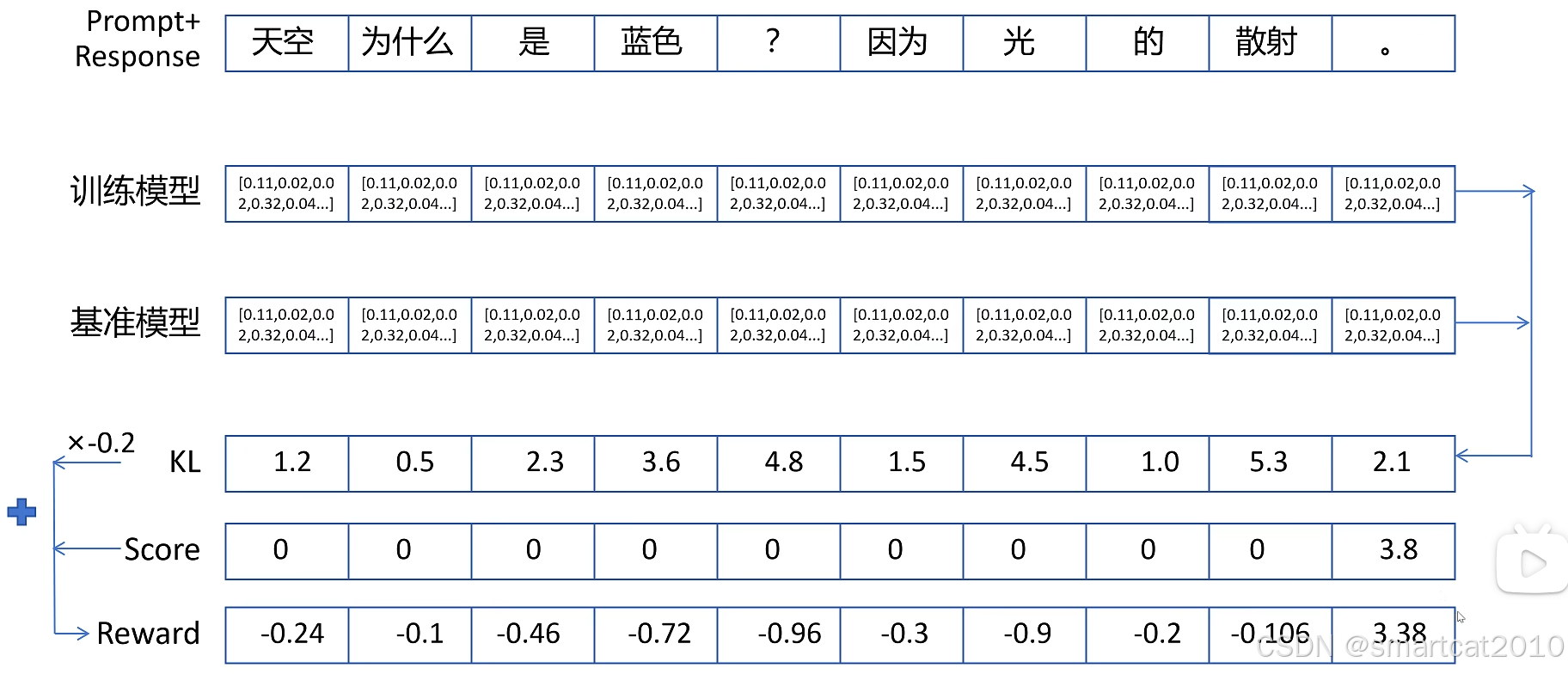
序列生成任务和强化学习概念的对应关系:
State: 已经生成的第1~t个token构成的序列;
Action: 即将生成的下一个token;
Reward: 奖励模型给出的分数,是给到最后1个token(前面的token都给0);和基准模型分布的KL散度,给到每个token。
KL*(-0.2) + Score ==> Reward
GAE优势
实际代码中,从后往前递推来计算:
GAE优势,用在了2处:1. 状态价值V的loss计算中(做V的label)。2.action的loss计算中(做优势)。
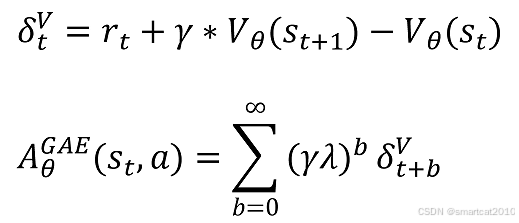
状态价值
每个token都有1个V。
如何计算状态价值?3种方式:
蒙特卡洛法,用1次采样序列,方差太大;
时序差分法,用1步采样,受V函数的准确性,偏差太大;
PPO里使用GAE,即广义优势法,平衡考虑了方差和偏差。
状态价值Loss的代码:
L2平方误差损失函数。

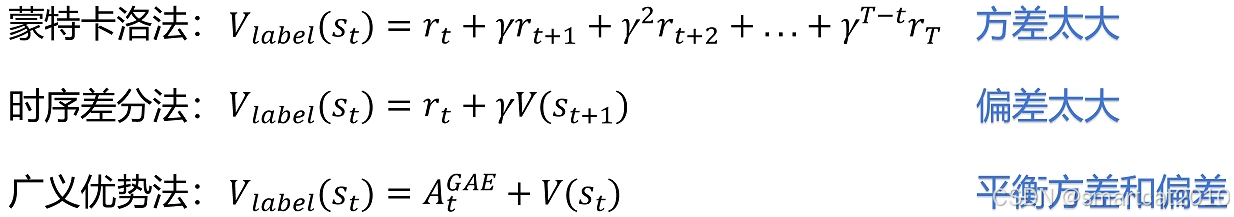
原始的PPO loss:
代码实现对公式的改动:
重要性采样、GAE、
,用的都是训练模型、价值状态模型,只在外层循环计算一次;内层循环复用之。
扔掉第2项。
最终的PPO loss:
用到3个模型:
一直只读保持不变的基准模型
,之产生每个token的概率分布,和
的分布,计算KL散度,放到Reward里,计算GAE使用。
训练模型
,会在内层循环进行更新,即多次更新。
重要性采样模型
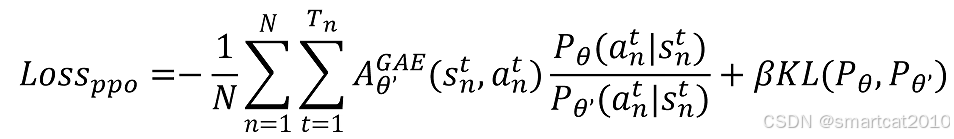
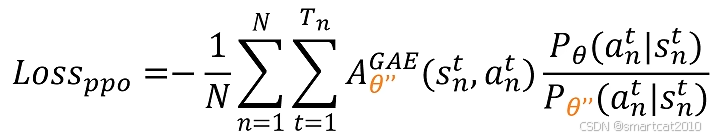

总的loss = 状态价值V的loss + PPO的loss
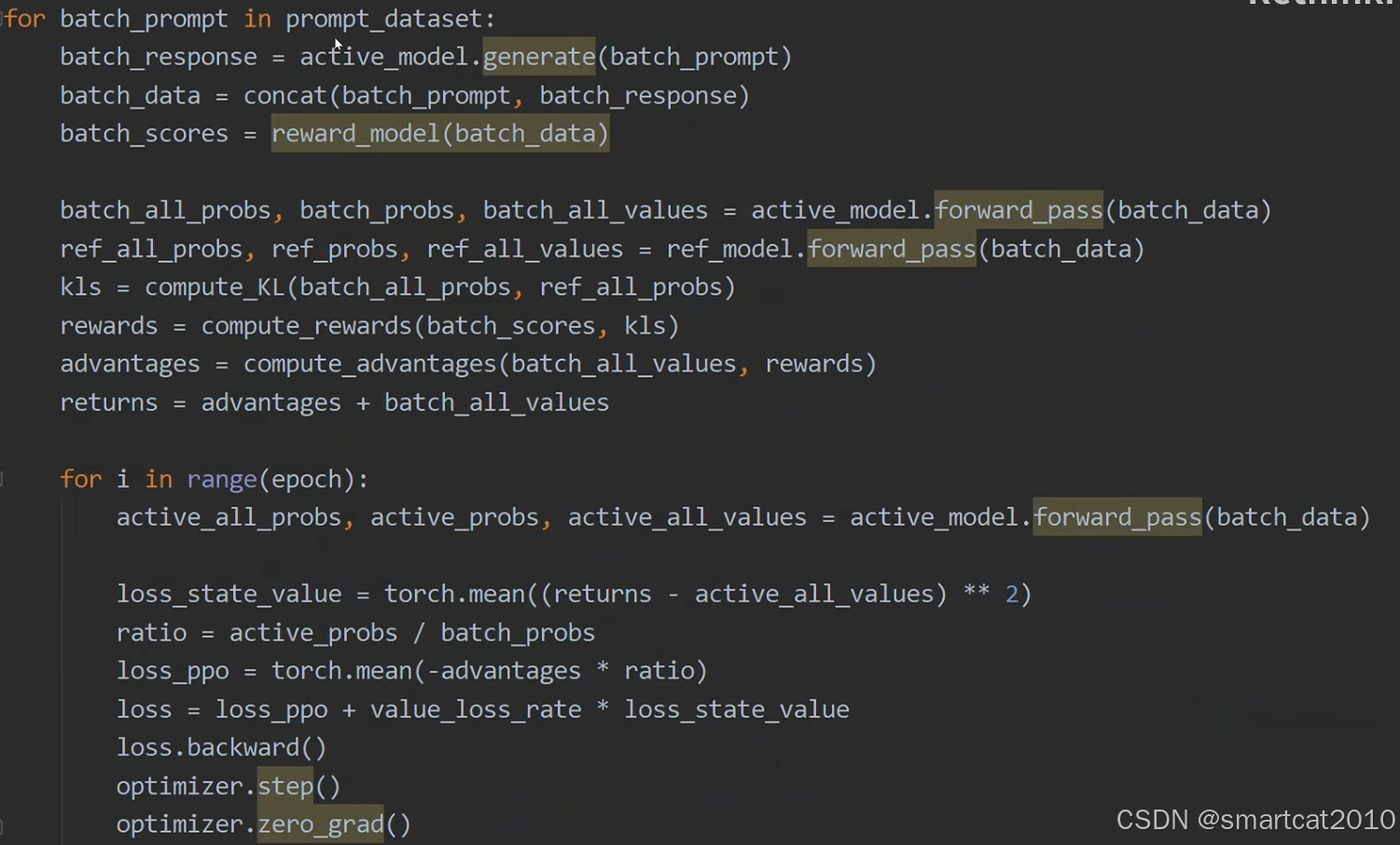
代码实现:
batch_all_probs: 每个token的概率分布,计算KL散度使用。
batch_probs: 每个token的生成概率,即P。
batch_all_values: 每个token的状态价值V。
huggingface的trl库
创建模型
model_path: 基准模型
reward_adapter: reward模型。复用共享基准模型的参数,只有最后head层是自己的
peft_config: 状态价值模型+训练模型。复用共享基准模型的参数,且只有1套LoRA参数,2个Head。
重要性采样模型,生成answer:
用reward模型,对每个句子进行打分:
用PPOTrainer,传入query、answer、reward分数,更新训练模型和状态价值模型(二者复用前面层的参数):


















 5487
5487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









