




 本文深入探讨GPU与CPU在架构上的显著差异,强调GPU擅长并行处理,而CPU则聚焦于降低延迟。文章解析了GPU的SIMT特性,并非传统SIMD,以及其在吞吐量优化方面的优势。同时,介绍了GPU编程的三种主要方式:调用库函数、使用OpenACC以及手动编写kernel,特别提及cudaDeviceSynchronize函数的作用。此外,还强调了内存对齐的重要性,以避免不必要的访存开销。
本文深入探讨GPU与CPU在架构上的显著差异,强调GPU擅长并行处理,而CPU则聚焦于降低延迟。文章解析了GPU的SIMT特性,并非传统SIMD,以及其在吞吐量优化方面的优势。同时,介绍了GPU编程的三种主要方式:调用库函数、使用OpenACC以及手动编写kernel,特别提及cudaDeviceSynchronize函数的作用。此外,还强调了内存对齐的重要性,以避免不必要的访存开销。
GPU擅长执行可并行的代码(data-parallel),CPU用来执行其他对延迟敏感的串行代码;
GPU:throughput-bound(以提升吞吐量为目标); CPU:latency-bound(以减少延迟为目标)
GPU属于SIMT,不是SIMD
CPU的时钟周期高,为了跟上处理器的步伐,必须加快访存速度,需要:1. 数据cache;2.指令预取;
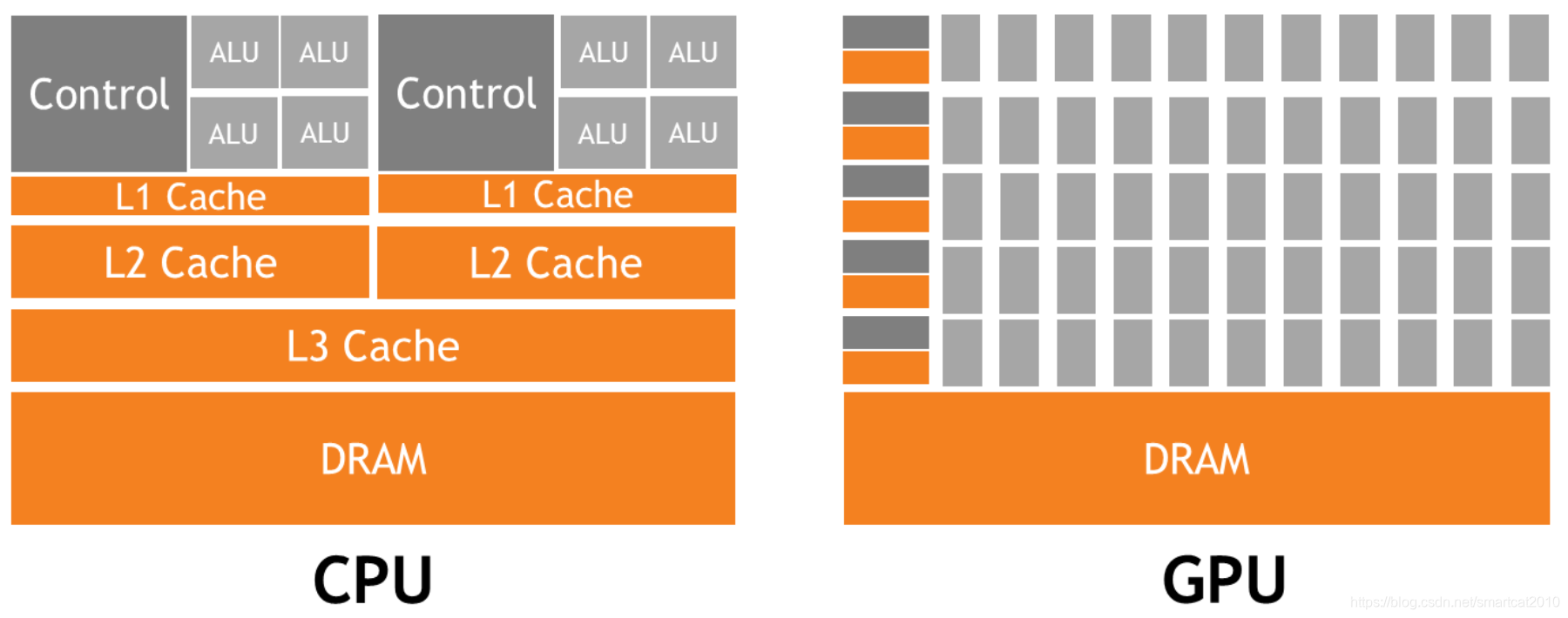
GPU的线程上下文在寄存器中,所以线程切换快;GPU寄存器多(可达几十MB);CPU寄存器少,线程上下文都在内存/cache中,所以线程切换慢;GPU线程切换快-->可以用一部分线程占用处理器来隐藏另一部分线程的访存延迟;
GPU的3大编程方式:1. 调库;2.OpenACC;3.手写kernel
cudaDeviceSynchronize: 一般用来等待kernel执行结束,CPU线程再往下走;
注意内存对齐,否则可能会产生冗余访存指令和次数。自定义struct可以用__align__(bytes)关键词来让编译器给对齐;


















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









